I dagens digitale tidsalder er data kjernen i enhver organisasjons suksess. Et av de mest brukte formatene for utveksling av data er XML. Å analysere XML-filer er avgjørende av flere grunner. For det første brukes XML-filer i mange bransjer, inkludert finans, helsevesen og myndigheter. Å analysere XML-filer kan hjelpe organisasjoner med å få innsikt i dataene deres, slik at de kan ta bedre beslutninger og forbedre driften. Analyse av XML-filer kan også hjelpe med dataintegrasjon, fordi mange applikasjoner og systemer bruker XML som standard dataformat. Ved å analysere XML-filer kan organisasjoner enkelt integrere data fra forskjellige kilder og sikre konsistens på tvers av systemene deres. Men XML-filer inneholder semistrukturerte, svært nestede data, noe som gjør det vanskelig å få tilgang til og analysere informasjon, spesielt hvis filen er stor og har komplekst, svært nestet skjema.
XML-filer er godt egnet for applikasjoner, men de er kanskje ikke optimale for analysemotorer. For å forbedre søkeytelsen og muliggjøre enkel tilgang i nedstrøms analysemotorer som Amazonas Athena, er det avgjørende å forhåndsbehandle XML-filer til et kolonneformat som Parquet. Denne transformasjonen tillater forbedret effektivitet og brukervennlighet i analysearbeidsflyter. I dette innlegget viser vi hvordan du behandler XML-data ved hjelp av AWS Lim og Athena.
Løsningsoversikt
Vi utforsker to distinkte teknikker som kan strømlinjeforme arbeidsflyten for XML-filbehandling:
- Teknikk 1: Bruk en AWS Glue crawler og AWS Glue visuelle editor – Du kan bruke AWS Glue-brukergrensesnittet sammen med en crawler for å definere tabellstrukturen for XML-filene dine. Denne tilnærmingen gir et brukervennlig grensesnitt og er spesielt egnet for personer som foretrekker en grafisk tilnærming til å administrere dataene sine.
- Teknikk 2: Bruk AWS Glue DynamicFrames med utledede og faste skjemaer – Crawleren har en begrensning når det gjelder å behandle en enkelt rad i XML-filer større enn 1 MB. For å overvinne denne begrensningen bruker vi en AWS Glue notatbok for å konstruere AWS Glue
DynamicFrames, ved å bruke både utledede og faste skjemaer. Denne metoden sikrer effektiv håndtering av XML-filer med rader som er større enn 1 MB.
I begge tilnærmingene er vårt endelige mål å konvertere XML-filer til Apache Parkett-format, noe som gjør dem lett tilgjengelige for spørring ved hjelp av Athena. Med disse teknikkene kan du forbedre behandlingshastigheten og tilgjengeligheten til XML-dataene dine, slik at du enkelt kan utlede verdifull innsikt.
Forutsetninger
Før du starter denne opplæringen, fullfør følgende forutsetninger (disse gjelder for begge teknikkene):
- Last ned XML-filene teknikk1.xml og teknikk2.xml.
- Last opp filene til en Amazon enkel lagringstjeneste (Amazon S3) bøtte. Du kan laste dem opp til samme S3-bøtte i forskjellige mapper eller til forskjellige S3-bøtter.
- Lag en AWS identitets- og tilgangsadministrasjon (IAM)-rolle for din ETL-jobb eller notatbok som instruert i Sett opp IAM-tillatelser for AWS Glue Studio.
- Legg til en integrert policy til rollen din med allerede: PassRole handling:
- Legg til en tillatelsespolicy til rollen med tilgang til S3-bøtten din.
Nå som vi er ferdige med forutsetningene, la oss gå videre til å implementere den første teknikken.
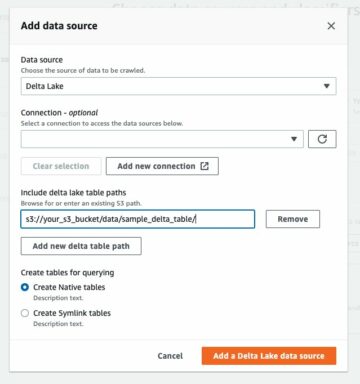
Teknikk 1: Bruk en AWS Glue-crawler og den visuelle editoren
Følgende diagram illustrerer den enkle arkitekturen du kan bruke for å implementere løsningen.
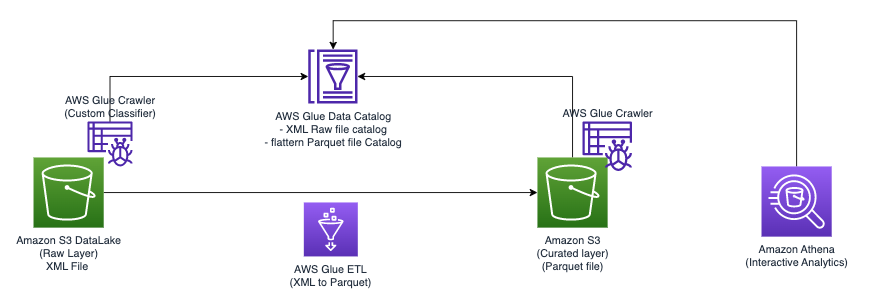
For å analysere XML-filer lagret i Amazon S3 ved hjelp av AWS Glue og Athena, fullfører vi følgende trinn på høyt nivå:
- Opprett en AWS Glue-crawler for å trekke ut XML-metadata og lag en tabell i AWS Glue Data Catalog.
- Bearbeid og transformer XML-data til et format (som Parkett) som er egnet for Athena ved å bruke en AWS Glue extract, transform, and load (ETL) jobb.
- Sett opp og kjør en AWS Glue-jobb via AWS Glue-konsollen eller AWS kommandolinjegrensesnitt (AWS CLI).
- Bruk de behandlede dataene (i Parkett-format) med Athena-tabeller, som muliggjør SQL-spørringer.
- Bruk det brukervennlige grensesnittet i Athena til å analysere XML-dataene med SQL-spørringer på dataene dine som er lagret i Amazon S3.
Denne arkitekturen er en skalerbar, kostnadseffektiv løsning for å analysere XML-data på Amazon S3 ved hjelp av AWS Glue og Athena. Du kan analysere store datasett uten kompleks infrastrukturadministrasjon.
Vi bruker AWS Glue-crawler for å trekke ut XML-filmetadata. Du kan velge standard AWS Glue-klassifisering for generell XML-klassifisering. Den oppdager automatisk XML-datastruktur og -skjema, noe som er nyttig for vanlige formater.
Vi bruker også en tilpasset XML-klassifisering i denne løsningen. Den er designet for spesifikke XML-skjemaer eller formater, og tillater presis metadatautvinning. Dette er ideelt for ikke-standard XML-formater eller når du trenger detaljert kontroll over klassifisering. En tilpasset klassifisering sikrer at bare nødvendige metadata trekkes ut, noe som forenkler nedstrømsbehandling og analyseoppgaver. Denne tilnærmingen optimaliserer bruken av XML-filene dine.
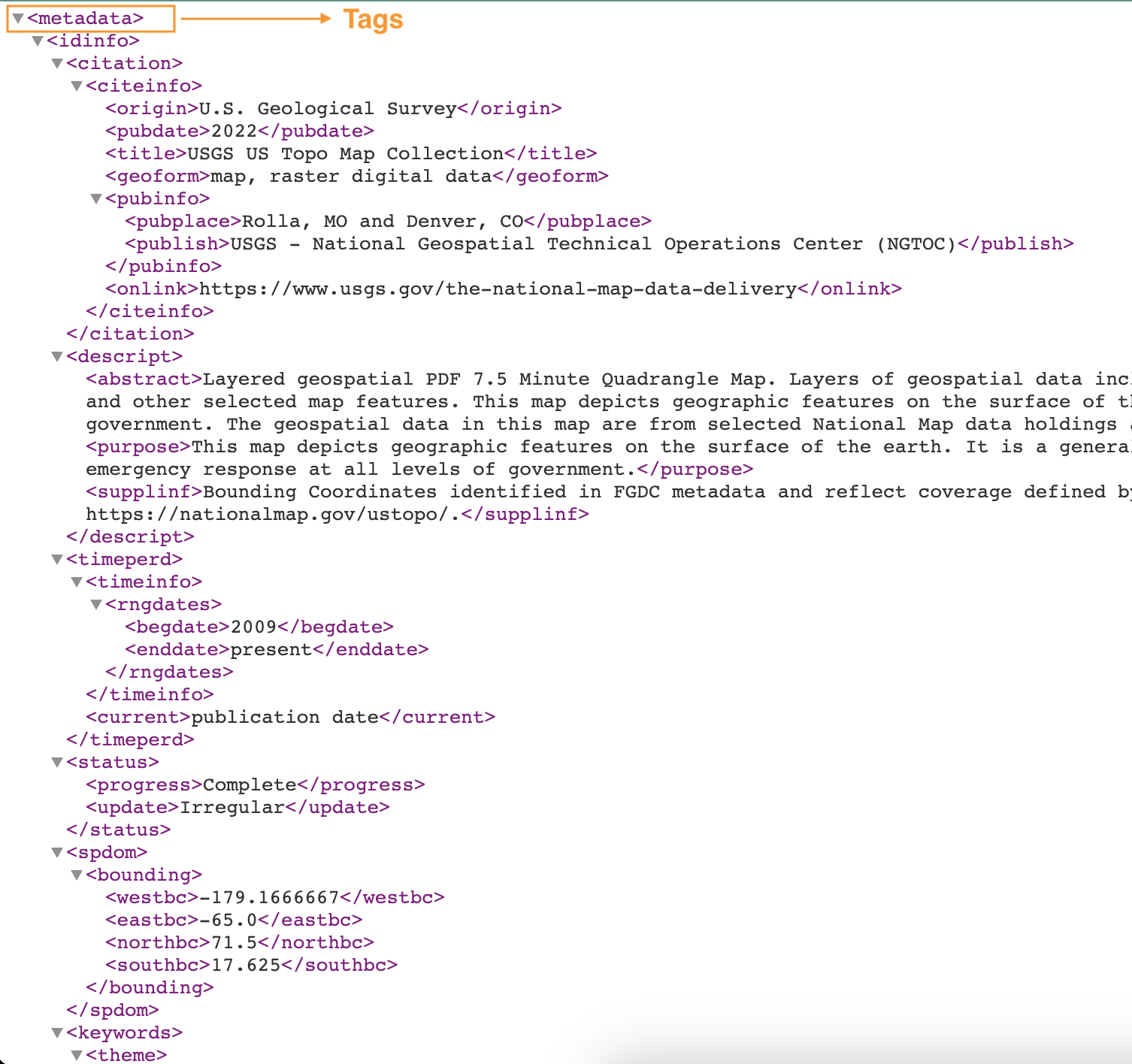
Følgende skjermbilde viser et eksempel på en XML-fil med tagger.
Lag en egendefinert klassifiserer
I dette trinnet oppretter du en tilpasset AWS Glue-klassifisering for å trekke ut metadata fra en XML-fil. Fullfør følgende trinn:
- På AWS Limkonsoll, under crawlers Velg navigasjonsruten Klassifikatorer.
- Velg Legg til klassifikator.
- Plukke ut XML som klassifiseringstype.
- Skriv inn et navn for klassifisereren, for eksempel
blog-glue-xml-contact. - Til Radmerke, skriv inn navnet på rotkoden som inneholder metadataene (f.eks.
metadata). - Velg Opprett.
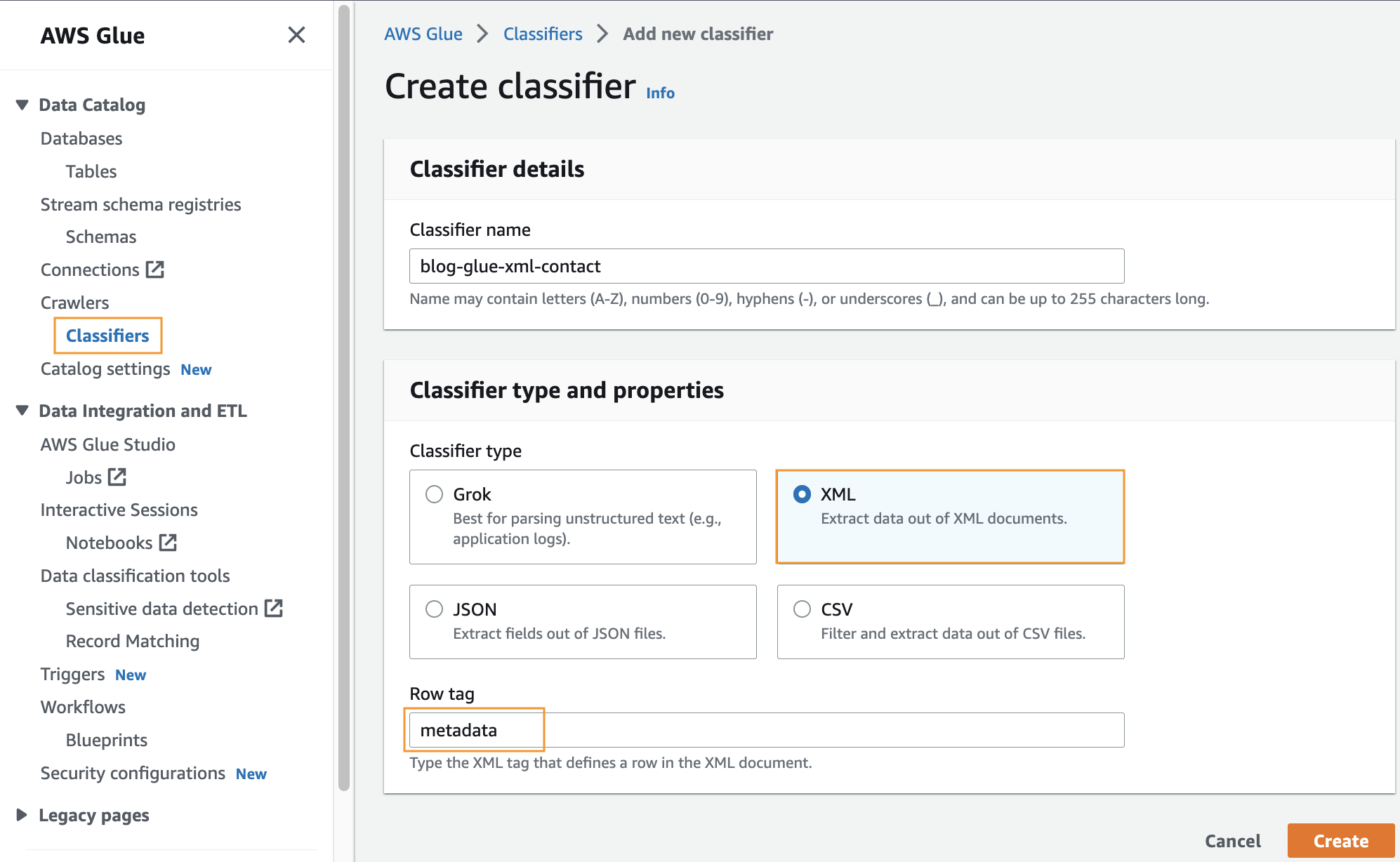
Opprett en AWS Glue Crawler for å gjennomgå xml-fil
I denne delen lager vi en Glue Crawler for å trekke ut metadataene fra XML-filen ved å bruke kundeklassifikatoren opprettet i forrige trinn.
Lag en database
- Gå til AWS Limkonsoll, velg databaser i navigasjonsruten.
- Klikk på Legg til database.
- Oppgi et navn som f.eks
blog_glue_xml - Velg Opprett Database
Opprett en Crawler
Fullfør følgende trinn for å lage din første robotsøkerobot:
- Velg på AWS Lim-konsollen crawlers i navigasjonsruten.
- Velg Opprett crawler.
- På Angi crawler-egenskaper side, oppgi et navn for den nye søkeroboten (som f.eks
blog-glue-parquet), og velg deretter neste. - På Velg datakilder og klassifikatorer side, velg Ikke ennå etter Datakildekonfigurasjon.
- Velg Legg til en datalager.
- Til S3 sti, bla til
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Pass på at du velger XML-mappen i stedet for filen inne i mappen.
- La resten av alternativene være standard og velg Legg til en S3-datakilde.
- Expand Egendefinerte klassifiseringer – valgfritt, velg blog-lim-xml-contact, og velg deretter neste og behold resten av alternativene som standard.
- Velg din IAM-rolle eller velg Opprett ny IAM-rolle, legg til suffikset
glue-xml-contact(for eksempel,AWSGlueServiceNotebookRoleBlog), og velg neste. - På Angi utgang og planlegging side, under Konfigurasjon av utdata, velg
blog_glue_xmlforum Måldatabase. - Enter
console_som prefikset lagt til i tabeller (valgfritt) og under Crawler tidsplan, hold frekvensen satt til On demand. - Velg neste.
- Se gjennom alle parameterne og velg Opprett crawler.
Kjør søkeroboten
Når du har opprettet søkeroboten, fullfører du følgende trinn for å kjøre den:
- Velg på AWS Lim-konsollen crawlers i navigasjonsruten.
- Åpne søkeroboten du opprettet og velg Kjør.
Søkeroboten vil ta 1–2 minutter å fullføre.
- Når søkeroboten er fullført, velg databaser i navigasjonsruten.
- Velg databasen du opprettet, og velg tabellnavnet for å se skjemaet hentet ut av robotsøkeprogrammet.
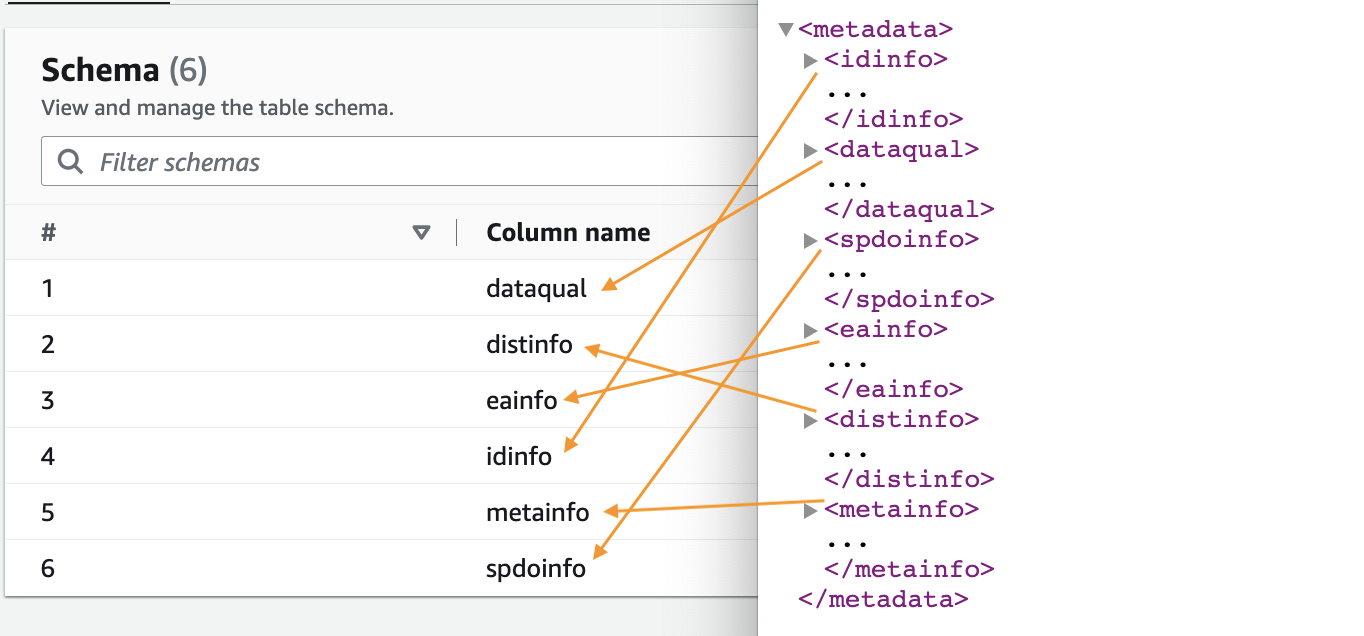
Opprett en AWS Lim-jobb for å konvertere XML til Parkett-format
I dette trinnet oppretter du en AWS Glue Studio-jobb for å konvertere XML-filen til en Parkett-fil. Fullfør følgende trinn:
- Velg på AWS Lim-konsollen Jobb i navigasjonsruten.
- Under Lag jobb, plukke ut Visuelt med et tomt lerret.
- Velg Opprett.
- Gi jobben nytt navn til
blog_glue_xml_job.
Nå har du en tom AWS Glue Studio visuell jobbredigerer. Øverst i redigeringsprogrammet er fanene for forskjellige visninger.
- Velg Script for å se et tomt skall av AWS Glue ETL-skriptet.
Etter hvert som vi legger til nye trinn i den visuelle editoren, vil skriptet bli oppdatert automatisk.
- Velg Jobbdetaljer fanen for å se alle jobbkonfigurasjonene.
- Til IAM-rolle, velg
AWSGlueServiceNotebookRoleBlog. - Til Lim versjon, velg Lim 4.0 – Support Spark 3.3, Scala 2, Python 3.
- Sett Ønsket antall arbeidere til 2.
- Sett Antall nye forsøk til 0.
- Velg Visual for å gå tilbake til det visuelle redigeringsprogrammet.
- På kilde rullegardinmenyen, velg AWS Lim Data Catalog.
- På Datakildeegenskaper – Datakatalog oppgi følgende informasjon:
- Til Database, velg
blog_glue_xml. - Til Bord, velg tabellen som starter med navnet console_ som søkeroboten opprettet (f.eks.
console_geologicalsurvey).
- Til Database, velg
- På Nodeegenskaper oppgi følgende informasjon:
- Endring Navn til
geologicalsurveydatasett. - Velg Handling og transformasjonen Endre skjema (bruk kartlegging).
- Velg Nodeegenskaper og endre navnet på transformasjonen fra Change Schema (Apply Mapping) til
ApplyMapping. - På Target meny, velg S3.
- Endring Navn til
- På Datakildeegenskaper - S3 oppgi følgende informasjon:
- Til dannet, plukke ut parkett.
- Til Komprimeringstype, plukke ut ukomprimert.
- Til S3 kildetype, plukke ut S3 beliggenhet.
- Til S3 URL, Tast inn
s3://${BUCKET_NAME}/output/parquet/. - Velg Nodeegenskaper og endre navnet til
Output.
- Velg Spar for å redde jobben.
- Velg Kjør å kjøre jobben.
Følgende skjermbilde viser jobben i den visuelle editoren.
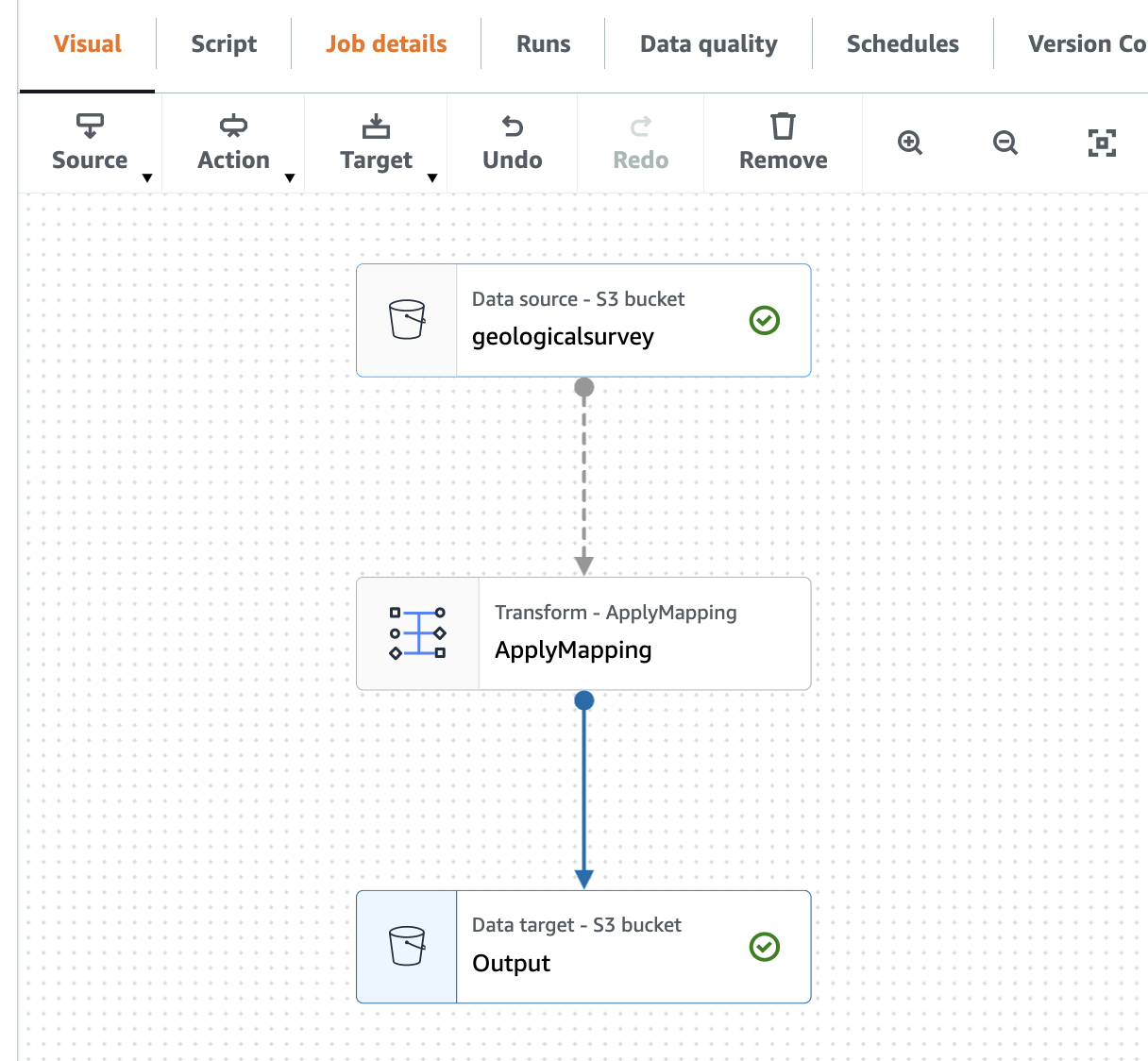
Opprett en AWS Gue Crawler for å gjennomsøke Parkett-filen
I dette trinnet oppretter du en AWS Glue-crawler for å trekke ut metadata fra Parkett-filen du opprettet ved hjelp av en AWS Glue Studio-jobb. Denne gangen bruker du standardklassifisereren. Fullfør følgende trinn:
- Velg på AWS Lim-konsollen crawlers i navigasjonsruten.
- Velg Opprett crawler.
- På Angi crawler-egenskaper side, oppgi et navn for den nye søkeroboten, for eksempel blogg-lim-parkett-kontakt, og velg deretter neste.
- På Velg datakilder og klassifikatorer side, velg Ikke ennå forum Datakildekonfigurasjon.
- Velg Legg til en datalager.
- Til S3 sti, bla til
s3://${BUCKET_NAME}/output/parquet/.
Pass på at du velger parquet mappen i stedet for filen inne i mappen.
- Velg din IAM-rolle opprettet under forutsetningsdelen eller velg Opprett ny IAM-rolle (for eksempel,
AWSGlueServiceNotebookRoleBlog), og velg neste. - På Angi utgang og planlegging side, under Konfigurasjon av utdata, velg
blog_glue_xmlforum Database. - Enter
parquet_som prefikset lagt til i tabeller (valgfritt) og under Crawler tidsplan, hold frekvensen satt til On demand. - Velg neste.
- Se gjennom alle parameterne og velg Opprett crawler.
Nå kan du kjøre søkeroboten, som tar 1–2 minutter å fullføre.

Du kan forhåndsvise det nyopprettede skjemaet for Parquet-filen i AWS Glue Data Catalog, som ligner på skjemaet til XML-filen.
Vi har nå data som er egnet for bruk med Athena. I neste avsnitt utfører vi dataspørringer ved hjelp av Athena.
Spør etter Parkett-filen med Athena
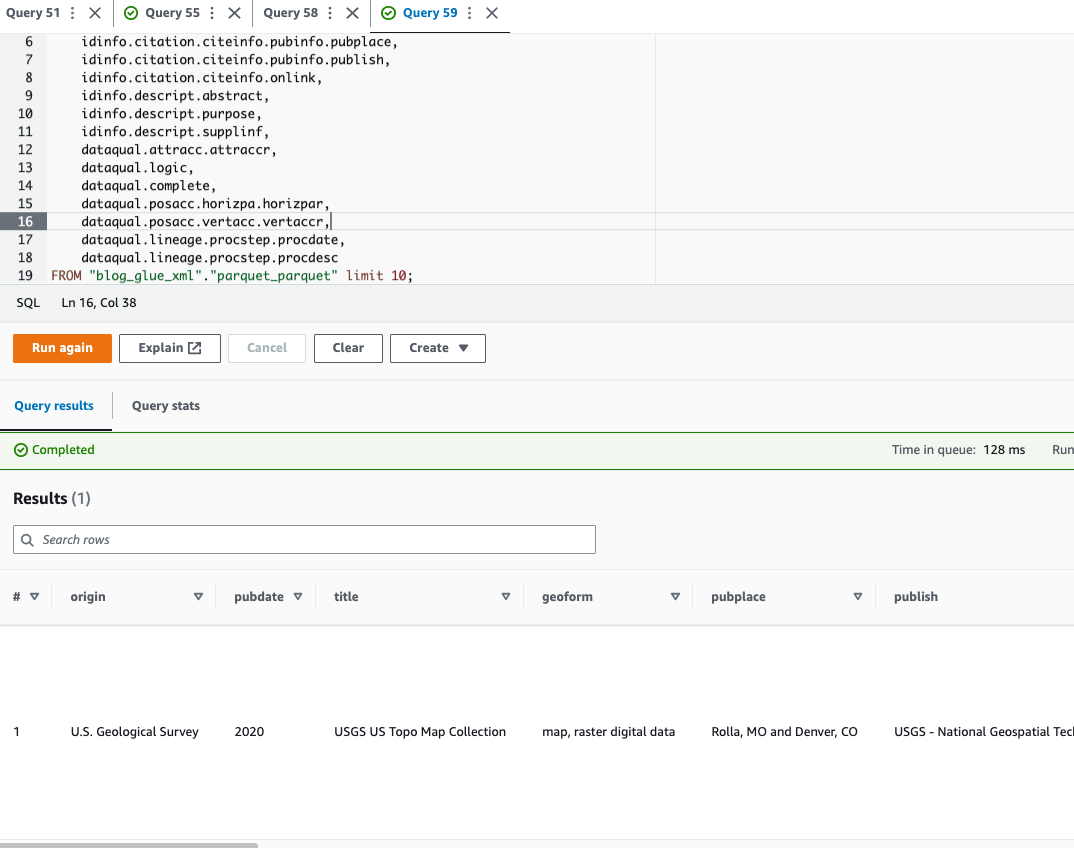
Athena støtter ikke spørring av XML-filformat, som er grunnen til at du konverterte XML-filen til Parkett for mer effektiv dataspørring og bruk punktnotasjon for å søke etter komplekse typer og nestede strukturer.
Følgende eksempelkode bruker punktnotasjon for å spørre nestede data:
Nå som vi har fullført teknikk 1, la oss gå videre for å lære om teknikk 2.
Teknikk 2: Bruk AWS Glue DynamicFrames med utledede og faste skjemaer
I forrige avsnitt dekket vi prosessen med å håndtere en liten XML-fil ved å bruke en AWS Glue-crawler for å generere en tabell, en AWS Glue-jobb for å konvertere filen til Parkett-format, og Athena for å få tilgang til Parkett-dataene. Søkeroboten møter imidlertid begrensninger når det gjelder å behandle XML-filer som overskrider 1 MB i størrelse. I denne delen fordyper vi oss i emnet batchbehandling av større XML-filer, noe som krever ytterligere analysering for å trekke ut individuelle hendelser og utføre analyser ved hjelp av Athena.
Vår tilnærming innebærer å lese XML-filene gjennom AWS Glue DynamicFrames, som bruker både utledede og faste skjemaer. Deretter trekker vi ut de enkelte hendelsene i Parkett-format ved hjelp av relasjonalisere transformasjon, slik at vi kan spørre og analysere dem sømløst ved hjelp av Athena.
For å implementere denne løsningen, fullfører du følgende trinn på høyt nivå:
- Lag en AWS Glue-notisbok for å lese og analysere XML-filen.
- Bruk
DynamicFramesmedInferSchemafor å lese XML-filen. - Bruk relasjonaliseringsfunksjonen for å fjerne arrays.
- Konverter dataene til parkettformat.
- Spør etter parkettdataene ved hjelp av Athena.
- Gjenta de forrige trinnene, men denne gangen gir du et skjema til
DynamicFramesi stedet for å brukeInferSchema.
XML-filen for befolkningsdata for elektriske kjøretøy har en response tag på rotnivået. Denne taggen inneholder en rekke av row koder, som er nestet i den. Radetiketten er en matrise som inneholder et sett med andre radetiketter, som gir informasjon om et kjøretøy, inkludert merke, modell og andre relevante detaljer. Følgende skjermbilde viser et eksempel.

Lag en AWS Glue Notebook
For å lage en AWS Glue notatbok, fullfør følgende trinn:
- Åpne AWS Lim Studio konsoll, velg Jobb i navigasjonsruten.
- Plukke ut Jupyter Notebook Og velg Opprett.
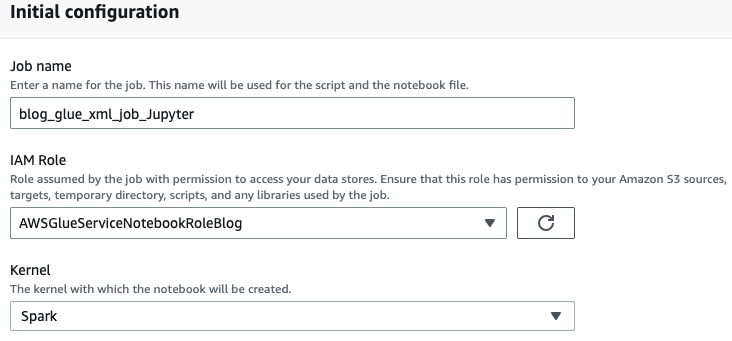
- Skriv inn et navn for AWS-limjobben din, for eksempel
blog_glue_xml_job_Jupyter. - Velg rollen du opprettet i forutsetningene (
AWSGlueServiceNotebookRoleBlog).
AWS Glue-notisboken kommer med et eksisterende eksempel som viser hvordan du spør etter en database og skriver utdataene til Amazon S3.
- Juster tidsavbruddet (i minutter) som vist i følgende skjermbilde og kjør cellen for å lage den interaktive AWS Glue-økten.
Lag grunnleggende variabler
Etter at du har opprettet den interaktive økten, på slutten av notatboken, oppretter du en ny celle med følgende variabler (oppgi ditt eget bøttenavn):
Les XML-filen som utleder skjemaet
Hvis du ikke sender et skjema til DynamicFrame, vil det utlede skjemaet til filene. For å lese dataene ved hjelp av en dynamisk ramme, kan du bruke følgende kommando:
Skriv ut DynamicFrame-skjemaet
Skriv ut skjemaet med følgende kode:
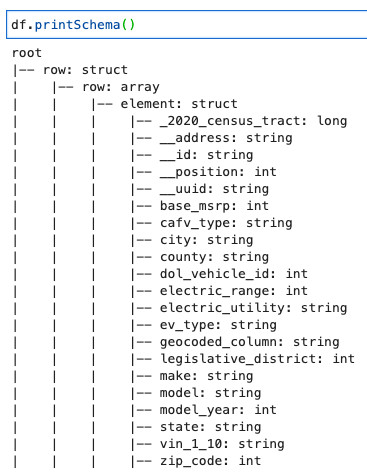
Skjemaet viser en nestet struktur med en row array som inneholder flere elementer. For å fjerne denne strukturen i linjer, kan du bruke AWS-limet relasjonalisere transformasjon:
Vi er bare interessert i informasjonen i radarrayen, og vi kan se skjemaet ved å bruke følgende kommando:
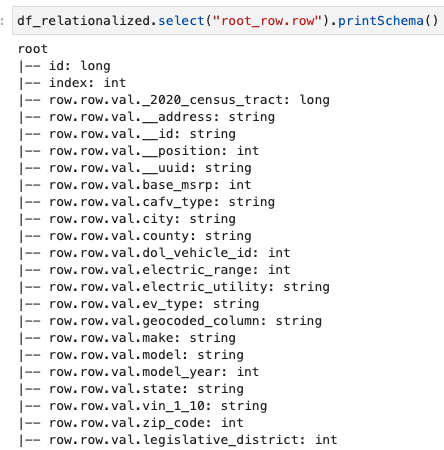
Kolonnenavnene inneholder row.row, som tilsvarer matrisestrukturen og matrisekolonnen i datasettet. Vi gir ikke nytt navn til kolonnene i dette innlegget; for instruksjoner for å gjøre dette, se Automatiser dynamisk kartlegging og omdøp av kolonnenavn i datafiler ved hjelp av AWS Glue: Del 1. Deretter kan du konvertere dataene til Parkett-format og lage AWS Glue-tabellen ved å bruke følgende kommando:
AWS Lim DynamicFrame gir funksjoner som du kan bruke i ETL-skriptet for å opprette og oppdatere et skjema i datakatalogen. Vi bruker updateBehavior parameter for å lage tabellen direkte i datakatalogen. Med denne tilnærmingen trenger vi ikke å kjøre en AWS Glue-crawler etter at AWS Glue-jobben er fullført.

Les XML-filen ved å angi et skjema
En alternativ måte å lese filen på er å forhåndsdefinere et skjema. For å gjøre dette, fullfør følgende trinn:
- Importer AWS Glue-datatypene:
- Lag et skjema for XML-filen:
- Send skjemaet når du leser XML-filen:
- Fjern datasettet som før:
- Konverter datasettet til Parkett og lag AWS Glue-tabellen:
Spør tabellene ved hjelp av Athena
Nå som vi har opprettet begge tabellene, kan vi spørre tabellene ved hjelp av Athena. Vi kan for eksempel bruke følgende spørring:
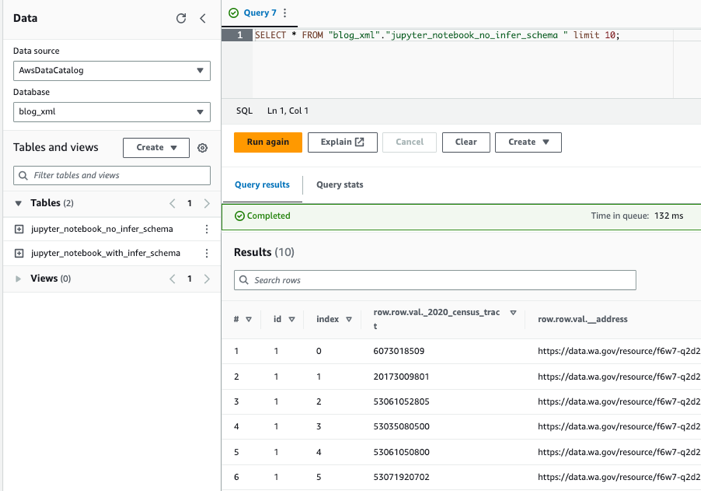
Rydd opp
I dette innlegget opprettet vi en IAM-rolle, en AWS Glue Jupyter-notisbok og to tabeller i AWS Glue Data Catalog. Vi lastet også opp noen filer til en S3-bøtte. For å rydde opp i disse objektene, fullfør følgende trinn:
- Slett rollen du opprettet på IAM-konsollen.
- På AWS Glue Studio-konsollen sletter du den tilpassede klassifisereren, søkeroboten, ETL-jobbene og Jupyter-notatboken.
- Naviger til AWS Glue Data Catalog og slett tabellene du opprettet.
- På Amazon S3-konsollen, naviger til bøtta du opprettet og slett mappene som er navngitt
temp,infer_schemaogno_infer_schema.
Nøkkelfunksjoner
I AWS Glue er det en funksjon som heter InferSchema i AWS Lim DynamicFrames. Den finner automatisk ut strukturen til en dataramme basert på dataene den inneholder. I motsetning til dette betyr å definere et skjema eksplisitt å angi hvordan datarammens struktur skal være før du laster inn dataene.
XML, som er et tekstbasert format, begrenser ikke datatypene til kolonnene. Dette kan forårsake problemer med InferSchema-funksjonen. For eksempel, i den første kjøringen, resulterer en fil med kolonne A som har en verdi på 2 i en Parkett-fil med kolonne A som et heltall. I den andre kjøringen har en ny fil kolonne A med verdien C, noe som fører til en Parkettfil med kolonne A som en streng. Nå er det to filer på S3, hver med en kolonne A med forskjellige datatyper, som kan skape problemer nedstrøms.
Det samme skjer med komplekse datatyper som nestede strukturer eller matriser. For eksempel, hvis en fil har én kodeoppføring kalt transaction, antas det som en struktur. Men hvis en annen fil har samme tag, antas den som en matrise
Til tross for disse datatypeproblemene, InferSchema er nyttig når du ikke kjenner skjemaet eller det er upraktisk å definere et manuelt. Det er imidlertid ikke ideelt for store eller stadig skiftende datasett. Å definere et skjema er mer presist, spesielt med komplekse datatyper, men har sine egne problemer, som å kreve manuell innsats og å være lite fleksibel for dataendringer.
InferSchema har begrensninger, som feil datatypeslutning og problemer med å håndtere nullverdier. Å definere et skjema har også begrensninger, som manuell innsats og potensielle feil.
Valget mellom å utlede og definere et skjema avhenger av prosjektets behov. InferSchema er flott for rask utforskning av små datasett, mens å definere et skjema er bedre for større, komplekse datasett som krever nøyaktighet og konsistens. Vurder avveiningene og begrensningene for hver metode for å velge det som passer ditt prosjekt best.
konklusjonen
I dette innlegget utforsket vi to teknikker for å administrere XML-data ved hjelp av AWS Glue, hver skreddersydd for å møte spesifikke behov og utfordringer du kan støte på.
Teknikk 1 tilbyr en brukervennlig vei for de som foretrekker et grafisk grensesnitt. Du kan bruke en AWS Glue-crawler og den visuelle editoren for å enkelt definere tabellstrukturen for XML-filene dine. Denne tilnærmingen forenkler databehandlingsprosessen og er spesielt tiltalende for de som leter etter en enkel måte å håndtere dataene sine på.
Vi erkjenner imidlertid at søkeroboten har sine begrensninger, spesielt når det gjelder XML-filer som har rader større enn 1 MB. Det er her teknikk 2 kommer til unnsetning. Ved å utnytte AWS Glue DynamicFrames med både utledede og faste skjemaer, og ved å bruke en AWS Glue-notatbok, kan du effektivt håndtere XML-filer i alle størrelser. Denne metoden gir en robust løsning som sikrer sømløs behandling selv for XML-filer med rader som overskrider 1 MB-begrensningen.
Når du navigerer i dataadministrasjonens verden, gir disse teknikkene i verktøysettet deg mulighet til å ta informerte beslutninger basert på de spesifikke kravene til prosjektet ditt. Enten du foretrekker enkelheten til teknikk 1 eller skalerbarheten til teknikk 2, gir AWS Glue fleksibiliteten du trenger for å håndtere XML-data effektivt.
Om forfatterne
 Navnit Shuklafungerer som AWS spesialistløsningsarkitekt med fokus på Analytics. Han har en sterk entusiasme for å hjelpe klienter med å oppdage verdifull innsikt fra deres data. Gjennom sin ekspertise konstruerer han innovative løsninger som gir bedrifter mulighet til å komme frem til informerte, datadrevne valg. Spesielt er Navnit Shukla den dyktige forfatteren av boken med tittelen "Data Wrangling on AWS.
Navnit Shuklafungerer som AWS spesialistløsningsarkitekt med fokus på Analytics. Han har en sterk entusiasme for å hjelpe klienter med å oppdage verdifull innsikt fra deres data. Gjennom sin ekspertise konstruerer han innovative løsninger som gir bedrifter mulighet til å komme frem til informerte, datadrevne valg. Spesielt er Navnit Shukla den dyktige forfatteren av boken med tittelen "Data Wrangling on AWS.
 Patrick Muller jobber som Senior Data Lab Architect hos AWS. Hans hovedansvar er å bistå kundene med å gjøre ideene deres til et produksjonsklart dataprodukt. På fritiden liker Patrick å spille fotball, se filmer og reise.
Patrick Muller jobber som Senior Data Lab Architect hos AWS. Hans hovedansvar er å bistå kundene med å gjøre ideene deres til et produksjonsklart dataprodukt. På fritiden liker Patrick å spille fotball, se filmer og reise.
 Amogh Gaikwad er seniorløsningsutvikler hos Amazon Web Services. Han hjelper globale kunder med å bygge og distribuere AI/ML-løsninger på AWS. Arbeidet hans er hovedsakelig fokusert på datasyn og naturlig språkbehandling og å hjelpe kunder med å optimalisere AI/ML-arbeidsmengdene for bærekraft. Amogh har mottatt sin mastergrad i informatikk med spesialisering i maskinlæring.
Amogh Gaikwad er seniorløsningsutvikler hos Amazon Web Services. Han hjelper globale kunder med å bygge og distribuere AI/ML-løsninger på AWS. Arbeidet hans er hovedsakelig fokusert på datasyn og naturlig språkbehandling og å hjelpe kunder med å optimalisere AI/ML-arbeidsmengdene for bærekraft. Amogh har mottatt sin mastergrad i informatikk med spesialisering i maskinlæring.
 Sheela Sonone er Senior Resident Architect ved AWS. Hun hjelper AWS-kunder med å ta informerte valg og avveininger om å akselerere data-, analyse- og AI/ML-arbeidsbelastninger og implementeringer. På fritiden liker hun å tilbringe tid med familien – vanligvis på tennisbaner.
Sheela Sonone er Senior Resident Architect ved AWS. Hun hjelper AWS-kunder med å ta informerte valg og avveininger om å akselerere data-, analyse- og AI/ML-arbeidsbelastninger og implementeringer. På fritiden liker hun å tilbringe tid med familien – vanligvis på tennisbaner.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Om oss
- ABSTRACT
- akselerer
- adgang
- tilgjengelighet
- oppnådd
- nøyaktighet
- tvers
- Handling
- legge til
- la til
- Ytterligere
- adresse
- Etter
- alder
- AI / ML
- Alle
- tillate
- tillate
- tillater
- også
- alternativ
- Amazon
- Amazonas Athena
- Amazon Web Services
- an
- analyse
- analytics
- analysere
- analyserer
- og
- En annen
- noen
- Apache
- tiltrekkende
- søknader
- Påfør
- tilnærming
- tilnærminger
- arkitektur
- ER
- Array
- AS
- bistå
- bistå
- At
- forfatter
- automatisk
- tilgjengelig
- AWS
- AWS Lim
- tilbake
- basert
- grunnleggende
- BE
- fordi
- før du
- begynne
- være
- BEST
- Bedre
- mellom
- blank
- bok
- både
- bygge
- bedrifter
- men
- by
- som heter
- CAN
- katalog
- Årsak
- celle
- utfordringer
- endring
- Endringer
- endring
- valg
- Velg
- City
- klassifisering
- klienter
- kode
- Kolonne
- kolonner
- COM
- kommer
- Felles
- vanligvis
- fullføre
- Terminado
- komplekse
- datamaskin
- informatikk
- Datamaskin syn
- tilstand
- Gjennomføre
- sammen
- Vurder
- Konsoll
- stadig
- begrensninger
- konstruere
- inneholde
- inneholdt
- inneholder
- kontrast
- kontroll
- konvertere
- konvertert
- kostnadseffektiv
- kostnadseffektiv løsning
- fylke
- Baner
- dekket
- crawler
- skape
- opprettet
- Opprette
- avgjørende
- skikk
- kunde
- Kunder
- dato
- dataintegrasjon
- Dataledelse
- data-drevet
- Database
- datasett
- håndtering
- avgjørelser
- Misligholde
- definere
- definere
- dybden
- demonstrerer
- avhenger
- utplassere
- designet
- detaljert
- detaljer
- Utvikler
- forskjellig
- vanskelig
- digitalt
- digital tidsalder
- direkte
- oppdage
- distinkt
- do
- ikke
- gjort
- ikke
- DOT
- under
- dynamisk
- hver enkelt
- lette
- lett
- lett
- redaktør
- effekt
- effektivt
- effektivitet
- effektiv
- effektivt
- innsats
- uanstrengt
- Elektrisk
- elbil
- elementer
- ansette
- bemyndige
- bemyndiger
- tom
- muliggjøre
- muliggjør
- møte
- slutt
- Motorer
- forbedre
- sikre
- sikrer
- Enter
- entusiasme
- entry
- feil
- spesielt
- Eter (ETH)
- Selv
- hendelser
- Hver
- eksempel
- stige
- utveksling
- ekspertise
- leting
- utforske
- utforsket
- trekke ut
- utdrag
- familie
- Trekk
- Egenskaper
- tall
- filet
- Filer
- finansiere
- Først
- fikset
- fleksibilitet
- Fokus
- fokuserte
- etter
- Til
- format
- RAMME
- Gratis
- Frekvens
- fra
- funksjon
- Gevinst
- generell
- generere
- Global
- Go
- mål
- Regjeringen
- flott
- håndtere
- Håndtering
- skjer
- Utnyttelse
- Ha
- å ha
- he
- helsetjenester
- Hjerte
- hjelpe
- hjelpe
- hjelper
- her
- høyt nivå
- svært
- hans
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- ideell
- Ideer
- Identitet
- if
- illustrerer
- iverksette
- implementeringer
- implementere
- importere
- forbedre
- forbedret
- in
- Inkludert
- individuelt
- individer
- bransjer
- informasjon
- informert
- Infrastruktur
- innovative
- innsiden
- innsikt
- i stedet
- instruksjoner
- integrere
- integrering
- interaktiv
- interessert
- Interface
- inn
- innebærer
- saker
- IT
- DET ER
- Jobb
- Jobb
- jpg
- JSON
- Jupyter Notebook
- Hold
- Vet
- lab
- Språk
- stor
- større
- ledende
- LÆRE
- læring
- Nivå
- i likhet med
- BEGRENSE
- begrensning
- begrensninger
- linje
- linjer
- laste
- lasting
- logikk
- ser
- maskin
- maskinlæring
- Hoved
- hovedsakelig
- gjøre
- Making
- ledelse
- administrerende
- håndbok
- manuelt
- mange
- kartlegging
- mestere
- Kan..
- midler
- Meny
- metadata
- metode
- minutter
- modell
- mer
- mer effektivt
- mest
- flytte
- Filmer
- flere
- navn
- oppkalt
- navn
- Naturlig
- Naturlig språk
- Natural Language Processing
- Naviger
- Navigasjon
- nødvendig
- Trenger
- behov
- Ny
- nylig
- neste
- spesielt
- bærbare
- nå
- Antall
- gjenstander
- of
- Tilbud
- on
- ONE
- bare
- Drift
- optimal
- Optimalisere
- Optimaliserer
- alternativer
- or
- rekkefølge
- organisasjoner
- Origin
- Annen
- vår
- ut
- produksjon
- enn
- Overcome
- egen
- side
- brød
- parameter
- parametere
- del
- spesielt
- passere
- banen
- Patrick
- utføre
- ytelse
- tillatelser
- plukke
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- politikk
- befolkningen
- besitter
- Post
- potensiell
- presis
- trekker
- forutsetninger
- Forhåndsvisning
- forrige
- problemer
- prosess
- behandlet
- prosessering
- Produkt
- prosjekt
- prosjekter
- egenskaper
- gi
- gir
- publisere
- formål
- Python
- spørsmål
- Rask
- heller
- Lese
- lett
- Lesning
- grunner
- mottatt
- gjenkjenne
- referere
- relevant
- Krav
- redde
- ressurs
- svar
- ansvar
- REST
- begrense
- begrensning
- Resultater
- robust
- Rolle
- root
- RAD
- Kjør
- samme
- Spar
- Skala
- skalerbarhet
- skalerbar
- Vitenskap
- script
- sømløs
- sømløst
- Sekund
- Seksjon
- se
- senior
- Tjenester
- Session
- sett
- innstilling
- flere
- hun
- Shell
- bør
- Vis
- vist
- Viser
- lignende
- Enkelt
- enkelhet
- forenkle
- enkelt
- Størrelse
- liten
- So
- Fotball
- løsning
- Solutions
- noen
- kilde
- Kilder
- Spark
- spesialist
- spesialisert
- spesifikk
- spesielt
- fart
- utgifter
- SQL
- Standard
- starter
- Tilstand
- Uttalelse
- sier
- Trinn
- Steps
- lagring
- lagret
- rett fram
- effektivisere
- String
- sterk
- struktur
- strukturer
- studio
- suksess
- slik
- egnet
- støtte
- sikker
- Bærekraft
- Systemer
- bord
- TAG
- skreddersydd
- Ta
- tar
- oppgaver
- teknikker
- tennis
- enn
- Det
- De
- informasjonen
- verden
- deres
- Dem
- deretter
- Der.
- Disse
- de
- denne
- De
- Gjennom
- tid
- Tittel
- tittelen
- til
- dagens
- verktøykasse
- topp
- Tema
- Transform
- Transformation
- Traveling
- Turning
- tutorial
- to
- typen
- typer
- ultimate
- etter
- Oppdater
- oppdatert
- lastet opp
- us
- brukervennlighet
- bruke
- brukt
- Bruker
- Brukergrensesnitt
- brukervennlig
- bruker
- ved hjelp av
- vanligvis
- utnytte
- Verdifull
- verdi
- Verdier
- kjøretøy
- versjon
- av
- Se
- visninger
- syn
- se
- Vei..
- we
- web
- webtjenester
- Hva
- når
- mens
- om
- hvilken
- HVEM
- hvorfor
- vil
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- arbeidsflyt
- virker
- verden
- skrive
- XML
- du
- Din
- zephyrnet