I løpet av de siste årene har store språkmodeller (LLM) blitt fremtredende som fremragende verktøy som er i stand til å forstå, generere og manipulere tekst med enestående dyktighet. Deres potensielle applikasjoner spenner fra samtaleagenter til innholdsgenerering og informasjonsinnhenting, og holder løftet om å revolusjonere alle bransjer. Men å utnytte dette potensialet samtidig som man sikrer ansvarlig og effektiv bruk av disse modellene, avhenger av den kritiske prosessen med LLM-evaluering. En evaluering er en oppgave som brukes til å måle kvaliteten og ansvaret for produksjonen til en LLM eller generativ AI-tjeneste. Evaluering av LLM-er er ikke bare motivert av ønsket om å forstå en modellytelse, men også av behovet for å implementere ansvarlig AI og av behovet for å redusere risikoen for å gi feilinformasjon eller partisk innhold og for å minimere genereringen av skadelig, utrygg, ondsinnet og uetisk innhold. Videre kan evaluering av LLM-er også bidra til å redusere sikkerhetsrisikoer, spesielt i sammenheng med umiddelbar manipulering av data. For LLM-baserte applikasjoner er det avgjørende å identifisere sårbarheter og implementere sikkerhetstiltak som beskytter mot potensielle brudd og uautoriserte manipulasjoner av data.
Ved å tilby viktige verktøy for å evaluere LLM-er med en enkel konfigurasjon og ett-klikks tilnærming, Amazon SageMaker Clarify LLM-evalueringsevner gir kundene tilgang til de fleste av de nevnte fordelene. Med disse verktøyene i hånden er neste utfordring å integrere LLM-evaluering i livssyklusen for maskinlæring og drift (MLOps) for å oppnå automatisering og skalerbarhet i prosessen. I dette innlegget viser vi deg hvordan du integrerer Amazon SageMaker Clarify LLM-evaluering med Amazon SageMaker Pipelines for å aktivere LLM-evaluering i stor skala. I tillegg gir vi kodeeksempel i dette GitHub repository for å gjøre det mulig for brukere å utføre parallell multi-modell evaluering i skala, ved å bruke eksempler som Llama2-7b-f, Falcon-7b og finjusterte Llama2-7b-modeller.
Hvem trenger å utføre LLM-evaluering?
Alle som trener, finjusterer eller bare bruker en forhåndstrent LLM, må evaluere den nøyaktig for å vurdere oppførselen til applikasjonen drevet av den LLM. Basert på dette prinsippet kan vi klassifisere generative AI-brukere som trenger LLM-evalueringsevner i 3 grupper som vist i følgende figur: modellleverandører, finjustere og forbrukere.
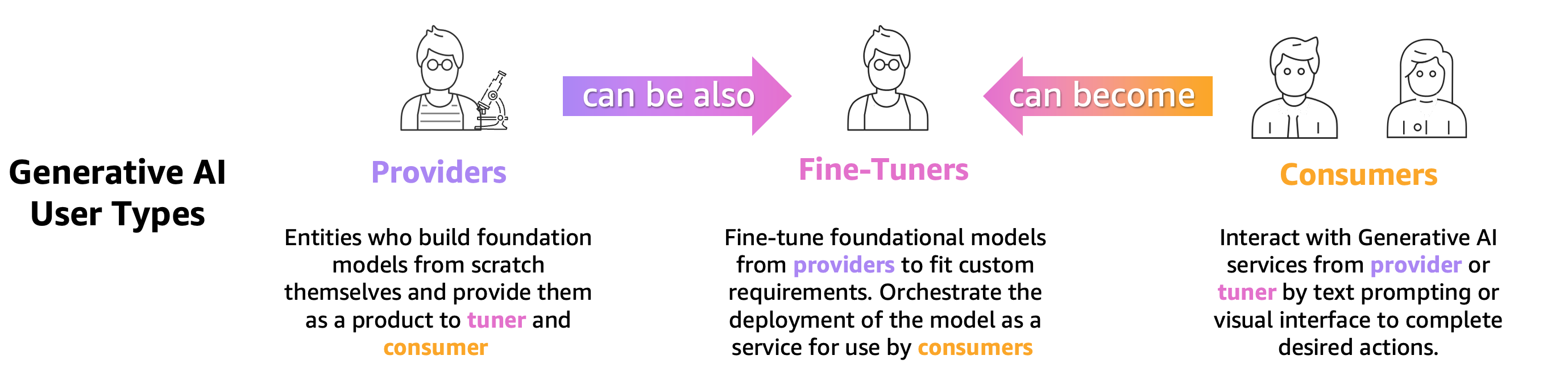
- Tilbydere av grunnleggende modell (FM). togmodeller som er generelle. Disse modellene kan brukes til mange nedstrømsoppgaver, for eksempel funksjonsutvinning eller til å generere innhold. Hver trent modell må måles mot mange oppgaver, ikke bare for å vurdere ytelsen, men også for å sammenligne den med andre eksisterende modeller, for å identifisere områder som trenger forbedringer og til slutt for å holde styr på fremskritt i feltet. Modellleverandører må også sjekke tilstedeværelsen av eventuelle skjevheter for å sikre kvaliteten på startdatasettet og den riktige oppførselen til modellen deres. Innsamling av evalueringsdata er avgjørende for modellleverandører. Videre må disse dataene og beregningene samles inn for å overholde kommende forskrifter. ISO 42001den Biden Administration Executive Orderog EUs AI-lov utvikle standarder, verktøy og tester for å sikre at AI-systemer er trygge, sikre og pålitelige. For eksempel har EU AI Act i oppgave å gi informasjon om hvilke datasett som brukes til opplæring, hvilken datakraft som kreves for å kjøre modellen, rapportere modellresultater mot offentlige/bransjestandarder og dele resultater fra intern og ekstern testing.
- Modell fininnstillere ønsker å løse spesifikke oppgaver (f.eks. sentimentklassifisering, oppsummering, svar på spørsmål) samt forhåndstrente modeller for å ta i bruk domenespesifikke oppgaver. De trenger evalueringsmålinger generert av modellleverandører for å velge riktig forhåndsopplært modell som utgangspunkt.
De må evaluere sine finjusterte modeller mot ønsket brukssituasjon med oppgavespesifikke eller domenespesifikke datasett. Ofte må de kurere og lage sine private datasett siden offentlig tilgjengelige datasett, selv de som er designet for en spesifikk oppgave, kanskje ikke fanger opp nyansene som kreves for deres spesielle brukstilfelle.
Finjustering er raskere og billigere enn en full opplæring og krever raskere operativ iterasjon for distribusjon og testing fordi mange kandidatmodeller vanligvis genereres. Evaluering av disse modellene tillater kontinuerlig modellforbedring, kalibrering og feilsøking. Merk at finjustere kan bli forbrukere av sine egne modeller når de utvikler applikasjoner i den virkelige verden. - Modell forbrukerne eller modellutviklere betjener og overvåker generelle formål eller finjusterte modeller i produksjon, med sikte på å forbedre deres applikasjoner eller tjenester gjennom å ta i bruk LLM-er. Den første utfordringen de har er å sikre at den valgte LLM stemmer overens med deres spesifikke behov, kostnader og ytelsesforventninger. Å tolke og forstå modellens resultater er en vedvarende bekymring, spesielt når personvern og datasikkerhet er involvert (f.eks. for revisjon av risiko og samsvar i regulerte bransjer, som finanssektoren). Kontinuerlig modellevaluering er avgjørende for å forhindre spredning av skjevheter eller skadelig innhold. Ved å implementere et robust overvåkings- og evalueringsrammeverk kan modellforbrukere proaktivt identifisere og adressere regresjon i LLM-er, og sikre at disse modellene opprettholder sin effektivitet og pålitelighet over tid.
Hvordan utføre LLM-evaluering
Effektiv modellevaluering involverer tre grunnleggende komponenter: en eller flere FM-er eller finjusterte modeller for å evaluere input-datasettene (forespørsler, samtaler eller vanlige input) og evalueringslogikken.
For å velge modellene for evaluering, må ulike faktorer vurderes, inkludert datakarakteristikker, problemkompleksitet, tilgjengelige beregningsressurser og ønsket resultat. Inndatalageret gir dataene som er nødvendige for trening, finjustering og testing av den valgte modellen. Det er viktig at denne datalageret er godt strukturert, representativt og av høy kvalitet, siden modellens ytelse i stor grad avhenger av dataene den lærer av. Til slutt definerer evalueringslogikk kriteriene og beregningene som brukes for å vurdere modellens ytelse.
Sammen danner disse tre komponentene et sammenhengende rammeverk som sikrer en streng og systematisk vurdering av maskinlæringsmodeller, som til slutt fører til informerte beslutninger og forbedringer i modelleffektivitet.
Modellevalueringsteknikker er fortsatt et aktivt forskningsfelt. Mange offentlige benchmarks og rammeverk ble laget av forskerfellesskapet de siste årene for å dekke et bredt spekter av oppgaver og scenarier som f.eks. LIM, Superlim, ROR, MMLU og STOR-benk. Disse benchmarkene har ledertavler som kan brukes til å sammenligne og kontrastere evaluerte modeller. Benchmarks, som HELM, tar også sikte på å vurdere beregninger utover nøyaktighetsmål, som presisjon eller F1-poengsum. HELM-referansen inkluderer beregninger for rettferdighet, skjevhet og toksisitet som har like stor betydning i den samlede modellevalueringsskåren.
Alle disse benchmarkene inkluderer et sett med beregninger som måler hvordan modellen presterer på en bestemt oppgave. De mest kjente og vanligste beregningene er RED (Recall-Oriented Understudy for Gisting Evaluation), BLUE (Tospråklig evalueringsstudie), eller METEOR (Beregning for evaluering av oversettelse med eksplisitt bestilling). Disse beregningene fungerer som et nyttig verktøy for automatisert evaluering, og gir kvantitative mål på leksikalsk likhet mellom generert tekst og referansetekst. De fanger imidlertid ikke hele bredden av menneskelignende språkgenerering, som inkluderer semantisk forståelse, kontekst eller stilistiske nyanser. For eksempel gir ikke HELM evalueringsdetaljer som er relevante for spesifikke brukstilfeller, løsninger for å teste tilpassede forespørsler og lett tolkede resultater brukt av ikke-eksperter, fordi prosessen kan være kostbar, ikke lett å skalere, og kun for spesifikke oppgaver.
Videre krever å oppnå menneskelignende språkgenerering ofte inkorporering av menneske-i-løkken for å bringe kvalitative vurderinger og menneskelig dømmekraft for å utfylle de automatiserte nøyaktighetsmålingene. Menneskelig evaluering er en verdifull metode for å vurdere LLM-utganger, men den kan også være subjektiv og utsatt for skjevhet fordi forskjellige menneskelige evaluatorer kan ha forskjellige meninger og tolkninger av tekstkvalitet. Videre kan menneskelig evaluering være ressurskrevende og kostbar, og det kan kreve betydelig tid og krefter.
La oss dykke dypt inn i hvordan Amazon SageMaker Clarify sømløst kobler sammen punktene, og hjelper kundene med å gjennomføre grundig modellevaluering og valg.
LLM-evaluering med Amazon SageMaker Clarify
Amazon SageMaker Clarify hjelper kunder med å automatisere beregningene, inkludert men ikke begrenset til nøyaktighet, robusthet, toksisitet, stereotyping og faktakunnskap for automatiserte, og stil, sammenheng, relevans for menneskebasert evaluering og evalueringsmetoder ved å tilby et rammeverk for å evaluere LLM-er og LLM-baserte tjenester som Amazon Bedrock. Som en fullt administrert tjeneste forenkler SageMaker Clarify bruken av evalueringsrammeverk med åpen kildekode i Amazon SageMaker. Kunder kan velge relevante evalueringsdatasett og beregninger for sine scenarier og utvide dem med sine egne spørredatasett og evalueringsalgoritmer. SageMaker Clarify leverer evalueringsresultater i flere formater for å støtte ulike roller i LLM-arbeidsflyten. Dataforskere kan analysere detaljerte resultater med SageMaker Clarify-visualiseringer i Notebooks, SageMaker Model Cards og PDF-rapporter. I mellomtiden kan driftsteam bruke Amazon SageMaker GroundTruth til å gjennomgå og kommentere høyrisikoelementer som SageMaker Clarify identifiserer. For eksempel ved stereotyping, toksisitet, unnslippet PII eller lav nøyaktighet.
Merknader og forsterkende læring blir deretter brukt for å redusere potensielle risikoer. Menneskevennlige forklaringer av de identifiserte risikoene fremskynder den manuelle gjennomgangsprosessen, og reduserer dermed kostnadene. Sammendragsrapporter tilbyr forretningsinteressenter komparative referanser mellom ulike modeller og versjoner, noe som letter informert beslutningstaking.
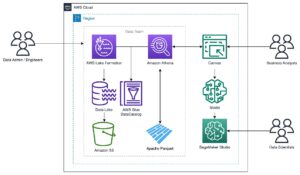
Følgende figur viser rammeverket for å evaluere LLM-er og LLM-baserte tjenester:

Amazon SageMaker Clarify LLM-evaluering er et åpen kildekode Foundation Model Evaluation (FMEval)-bibliotek utviklet av AWS for å hjelpe kunder med å enkelt evaluere LLM-er. Alle funksjonene er også integrert i Amazon SageMaker Studio for å muliggjøre LLM-evaluering for brukerne. I de følgende delene introduserer vi integrasjonen av Amazon SageMaker Clarify LLM-evalueringsfunksjoner med SageMaker Pipelines for å muliggjøre LLM-evaluering i stor skala ved å bruke MLOps-prinsipper.
Amazon SageMaker MLOps livssyklus
Som innlegget "MLOps foundation roadmap for bedrifter med Amazon SageMaker” beskriver, MLOps er kombinasjonen av prosesser, mennesker og teknologi for å produsere ML use cases effektivt.
Følgende figur viser ende-til-ende MLOps livssyklus:

En typisk reise starter med at en dataforsker lager en proof-of-concept (PoC) notatbok for å bevise at ML kan løse et forretningsproblem. Gjennom utviklingen av Proof of Concept (PoC) er det dataviteren som skal konvertere virksomhetens nøkkelytelsesindikatorer (KPIer) til beregninger for maskinlæringsmodeller, for eksempel presisjon eller falsk positiv rate, og bruke et begrenset testdatasett for å evaluere disse beregninger. Dataforskere samarbeider med ML-ingeniører for å overføre kode fra bærbare datamaskiner til depoter, og skaper ML-pipelines ved hjelp av Amazon SageMaker Pipelines, som kobler sammen ulike prosesseringstrinn og oppgaver, inkludert forbehandling, opplæring, evaluering og etterbehandling, alt mens de kontinuerlig inkorporerer ny produksjon data. Utrulling av Amazon SageMaker Pipelines er avhengig av repository-interaksjoner og CI/CD-pipelineaktivering. ML-pipelinen opprettholder toppytende modeller, containerbilder, evalueringsresultater og statusinformasjon i et modellregister, der modellinteressenter vurderer ytelse og bestemmer progresjon til produksjon basert på ytelsesresultater og benchmarks, etterfulgt av aktivering av en annen CI/CD-pipeline for iscenesettelse og produksjonsdistribusjon. Når de er i produksjon, bruker ML-forbrukere modellen via applikasjonsutløst inferens gjennom direkte påkalling eller API-kall, med tilbakemeldingsløkker til modelleiere for løpende ytelsesevaluering.
Amazon SageMaker Clarify og MLOps-integrasjon
Etter MLOps livssyklus produserer finjustere eller brukere av åpen kildekode-modeller finjusterte modeller eller FM ved å bruke Amazon SageMaker Jumpstart og MLOps-tjenester, som beskrevet i Implementering av MLOps-praksis med Amazon SageMaker JumpStart forhåndstrente modeller. Dette førte til et nytt domene for grunnmodelloperasjoner (FMOps) og LLM Operations (LLMOps) FMOps/LLMOps: Operasjonaliser generativ AI og forskjeller med MLOps.
Følgende figur viser ende-til-ende LLMOPS-livssyklus:
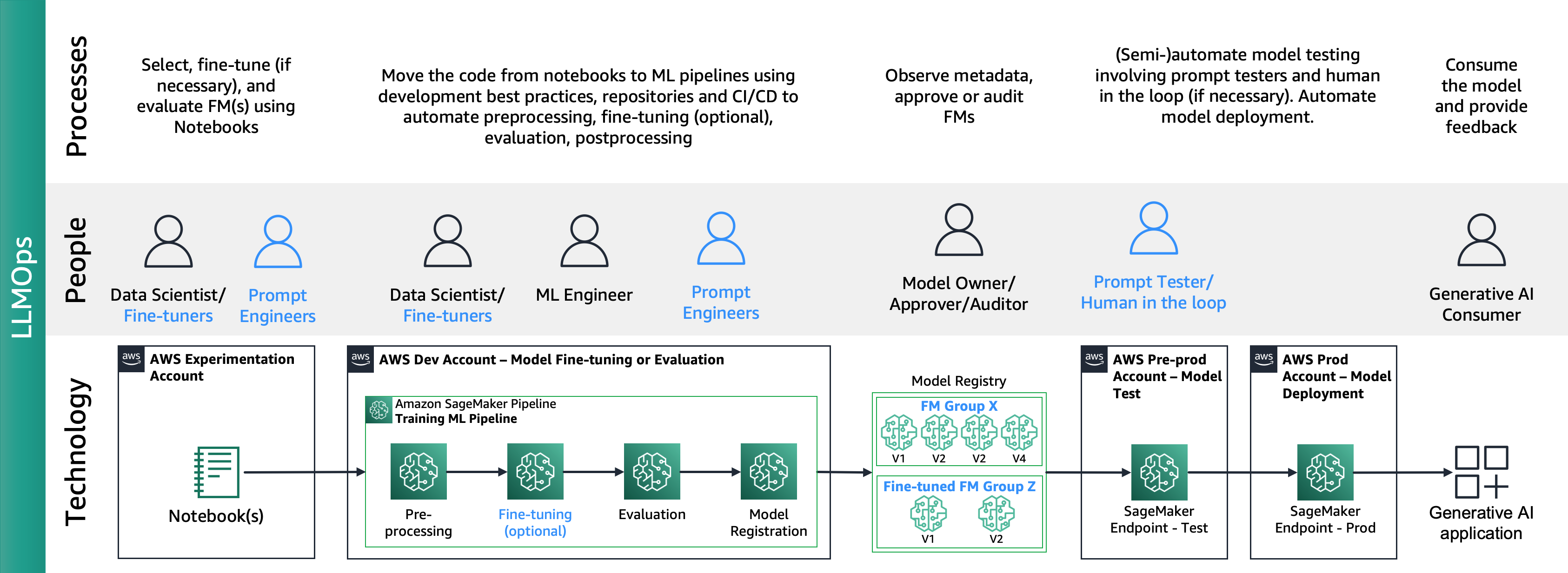
I LLMOps er hovedforskjellene sammenlignet med MLOps modellvalg og modellevaluering som involverer forskjellige prosesser og beregninger. I den innledende eksperimenteringsfasen velger dataforskerne (eller fininnstillere) FM-en som skal brukes for en spesifikk Generativ AI-brukstilfelle.
Dette resulterer ofte i testing og finjustering av flere FM-er, hvorav noen kan gi sammenlignbare resultater. Etter valget av modellen(e), er prompte ingeniører ansvarlige for å forberede de nødvendige inputdataene og forventet utdata for evaluering (f.eks. inputspørsmål som omfatter inputdata og spørring) og definere beregninger som likhet og toksisitet. I tillegg til disse beregningene, må dataforskere eller finjustere validere resultatene og velge riktig FM ikke bare på presisjonsmålinger, men på andre funksjoner som ventetid og kostnader. Deretter kan de distribuere en modell til et SageMaker-endepunkt og teste ytelsen i liten skala. Mens eksperimenteringsfasen kan innebære en enkel prosess, krever overgang til produksjon at kundene automatiserer prosessen og øker robustheten til løsningen. Derfor må vi dykke dypt i hvordan vi kan automatisere evaluering, slik at testere kan utføre effektiv evaluering i stor skala og implementere sanntidsovervåking av modellinndata og utdata.
Automatiser FM-evaluering
Amazon SageMaker Pipelines automatiserer alle fasene av forbehandling, FM-finjustering (valgfritt) og evaluering i stor skala. Gitt de valgte modellene under eksperimentering, må prompte ingeniører dekke et større sett med saker ved å forberede mange spørsmål og lagre dem i et angitt lagringssted kalt prompt catalog. For mer informasjon, se FMOps/LLMOps: Operasjonaliser generativ AI og forskjeller med MLOps. Deretter kan Amazon SageMaker Pipelines struktureres som følger:
Scenario 1 – Vurder flere FM-er: I dette scenariet kan FM-ene dekke forretningsbrukssaken uten finjustering. Amazon SageMaker Pipeline består av følgende trinn: dataforbehandling, parallell evaluering av flere FM-er, modellsammenligning og valg basert på nøyaktighet og andre egenskaper som kostnad eller latens, registrering av utvalgte modellartefakter og metadata.
Følgende diagram illustrerer denne arkitekturen.

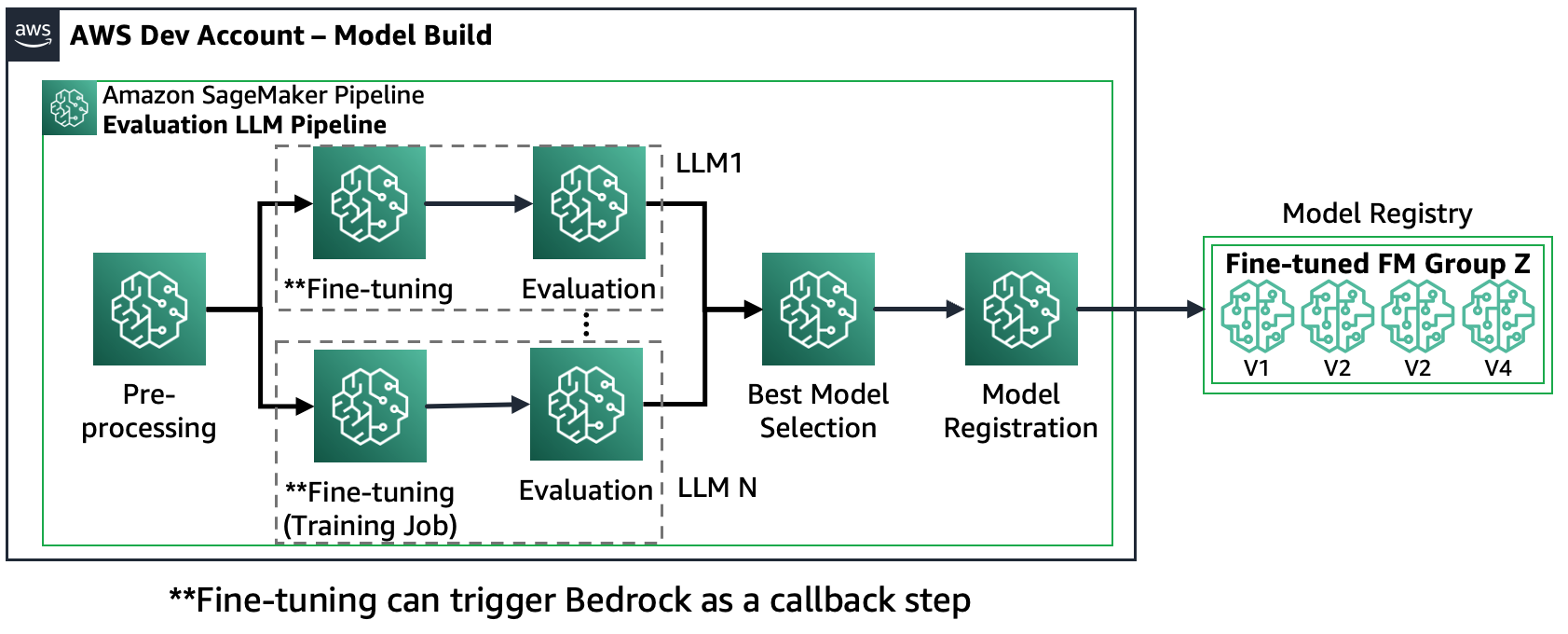
Scenario 2 – Finjuster og evaluer flere FM-er: I dette scenariet er Amazon SageMaker Pipeline strukturert omtrent som Scenario 1, men den kjører parallelt med både finjusterings- og evalueringstrinn for hver FM. Den best finjusterte modellen vil bli registrert i modellregisteret.
Følgende diagram illustrerer denne arkitekturen.
Scenario 3 – Evaluer flere FM-er og finjusterte FM-er: Dette scenariet er en kombinasjon av evaluering av generelle FM-er og finjusterte FM-er. I dette tilfellet ønsker kundene å sjekke om en finjustert modell kan yte bedre enn en generell FM.
Følgende figur viser de resulterende SageMaker Pipeline-trinnene.
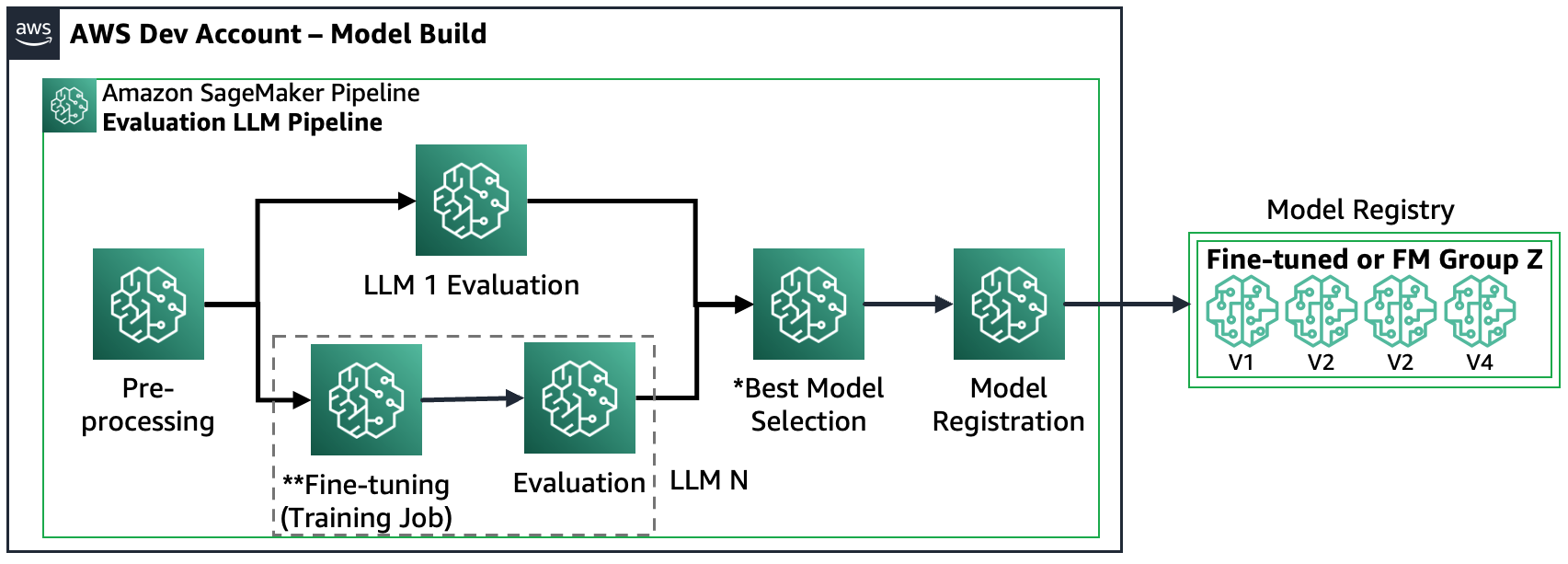
Merk at modellregistrering følger to mønstre: (a) lagre en åpen kildekode-modell og artefakter eller (b) lagre en referanse til en proprietær FM. For mer informasjon, se FMOps/LLMOps: Operasjonaliser generativ AI og forskjeller med MLOps.
Løsningsoversikt
For å akselerere reisen din til LLM-evaluering i stor skala, har vi laget en løsning som implementerer scenariene ved å bruke både Amazon SageMaker Clarify og den nye Amazon SageMaker Pipelines SDK. Kodeeksemplet, inkludert datasett, kildenotatbøker og SageMaker Pipelines (trinn og ML-pipeline), er tilgjengelig på GitHub. For å utvikle denne eksempelløsningen har vi brukt to FM-er: Llama2 og Falcon-7B. I dette innlegget er vårt primære fokus på nøkkelelementene i SageMaker Pipeline-løsningen som er knyttet til evalueringsprosessen.
Evalueringskonfigurasjon: For å standardisere evalueringsprosedyren har vi laget en YAML-konfigurasjonsfil, (evaluation_config.yaml), som inneholder de nødvendige detaljene for evalueringsprosessen, inkludert datasettet, modellen(e) og algoritmene som skal kjøres under evalueringstrinn av SageMaker Pipeline. Følgende eksempel illustrerer konfigurasjonsfilen:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Evalueringstrinn: Den nye SageMaker Pipeline SDK gir brukerne fleksibiliteten til å definere tilpassede trinn i ML-arbeidsflyten ved å bruke '@step' Python-dekoratoren. Derfor må brukerne lage et grunnleggende Python-skript som utfører evalueringen, som følger:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultSageMaker Pipeline: Etter å ha opprettet de nødvendige trinnene, for eksempel dataforbehandling, modelldistribusjon og modellevaluering, må brukeren koble trinnene sammen ved å bruke SageMaker Pipeline SDK. Den nye SDK-en genererer automatisk arbeidsflyten ved å tolke avhengighetene mellom ulike trinn når en SageMaker Pipeline-opprettings-API påkalles som vist i følgende eksempel:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()Eksemplet implementerer evalueringen av en enkelt FM ved å forhåndsbehandle det innledende datasettet, distribuere modellen og kjøre evalueringen. Den genererte rørledningsrettede asykliske grafen (DAG) er vist i følgende figur.
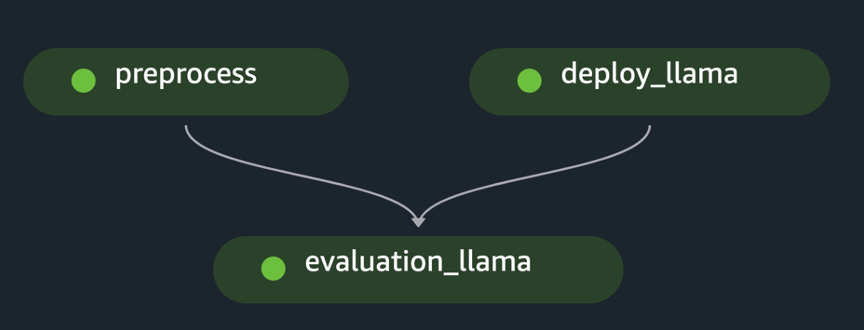
Følge en lignende tilnærming og ved å bruke og skreddersy eksemplet i Finjuster LLaMA 2-modeller på SageMaker JumpStart, laget vi rørledningen for å evaluere en finjustert modell, som vist i følgende figur.

Ved å bruke de tidligere SageMaker Pipeline-trinnene som "Lego"-blokker, utviklet vi løsningen for Scenario 1 og Scenario 3, som vist i de følgende figurene. Nærmere bestemt GitHub repository gjør det mulig for brukeren å evaluere flere FM-er parallelt eller å utføre mer kompleks evaluering som kombinerer evaluering av både grunnlagsmodeller og finjusterte modeller.

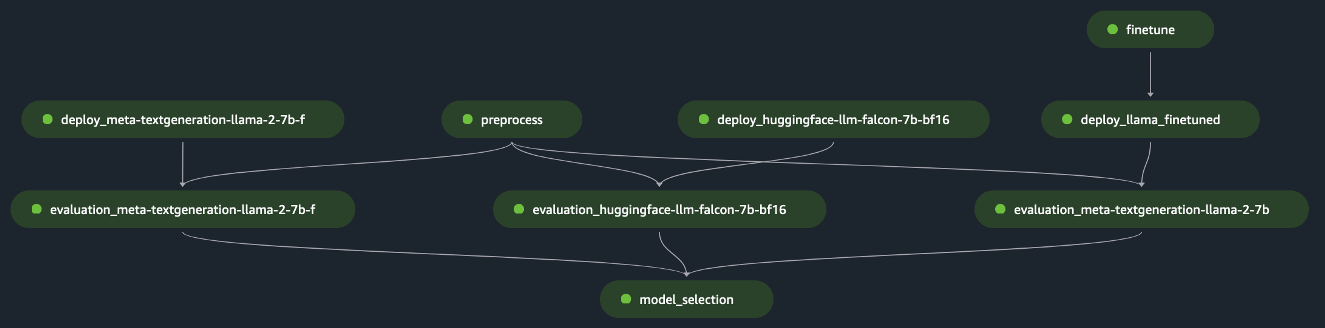
Ytterligere funksjoner tilgjengelig i depotet inkluderer følgende:
- Generering av dynamisk evalueringstrinn: Vår løsning genererer alle nødvendige evalueringstrinn dynamisk basert på konfigurasjonsfilen for å gjøre det mulig for brukere å evaluere et hvilket som helst antall modeller. Vi har utvidet løsningen til å støtte en enkel integrasjon av nye typer modeller, som Hugging Face eller Amazon Bedrock.
- Forhindre omplassering av endepunkt: Hvis et endepunkt allerede er på plass, hopper vi over distribusjonsprosessen. Dette lar brukeren gjenbruke endepunkter med FM-er for evaluering, noe som resulterer i kostnadsbesparelser og redusert distribusjonstid.
- Sluttpunktopprydding: Etter fullføringen av evalueringen tar SageMaker Pipeline demontert de utplasserte endepunktene. Denne funksjonaliteten kan utvides for å holde det beste modellens endepunkt i live.
- Trinn for valg av modell: Vi har lagt til en plassholder for trinn for modellvalg som krever forretningslogikken til det endelige modellvalget, inkludert kriterier som kostnad eller ventetid.
- Modellregistreringstrinn: Den beste modellen kan registreres i Amazon SageMaker Model Registry som en ny versjon av en bestemt modellgruppe.
- Varmt basseng: SageMaker-administrerte varme bassenger lar deg beholde og gjenbruke klargjort infrastruktur etter fullføring av en jobb for å redusere ventetiden for gjentatte arbeidsbelastninger
Følgende figur illustrerer disse egenskapene og et flermodellevalueringseksempel som brukerne kan lage enkelt og dynamisk ved å bruke vår løsning i denne GitHub oppbevaringssted.

Vi holdt dataforberedelsen med vilje utenfor omfanget, da den vil bli beskrevet i et annet innlegg i dybden, inkludert hurtigkatalogdesign, ledetekstmaler, promptoptimalisering. For mer informasjon og relaterte komponentdefinisjoner, se FMOps/LLMOps: Operasjonaliser generativ AI og forskjeller med MLOps.
konklusjonen
I dette innlegget fokuserte vi på hvordan man automatiserer og operasjonaliserer LLM-evaluering i stor skala ved å bruke Amazon SageMaker Clarify LLM-evalueringsfunksjoner og Amazon SageMaker Pipelines. I tillegg til teoretiske arkitekturdesign har vi eksempelkode i denne GitHub repository (med Llama2 og Falcon-7B FM-er) for å gjøre det mulig for kunder å utvikle sine egne skalerbare evalueringsmekanismer.
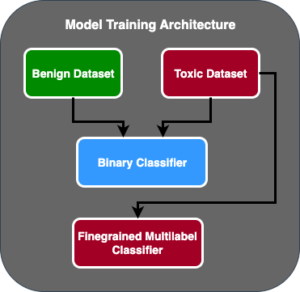
Følgende illustrasjon viser modellevalueringsarkitektur.
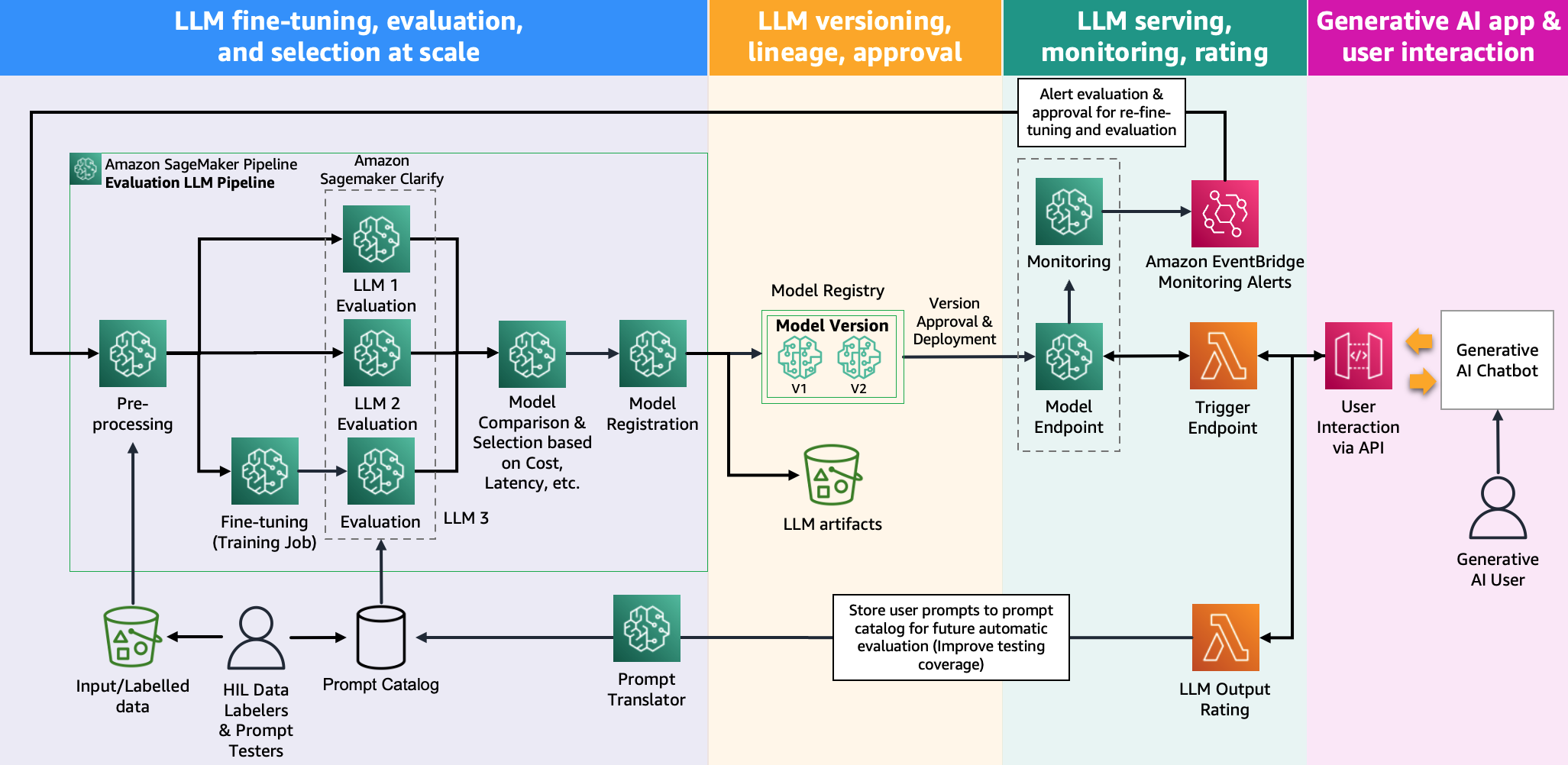
I dette innlegget fokuserte vi på å operasjonalisere LLM-evalueringen i skala som vist på venstre side av illustrasjonen. I fremtiden vil vi fokusere på å utvikle eksempler som oppfyller ende-til-ende-livssyklusen til FM-er til produksjon ved å følge retningslinjene beskrevet i FMOps/LLMOps: Operasjonaliser generativ AI og forskjeller med MLOps. Dette inkluderer LLM-servering, overvåking, lagring av utgangsvurdering som til slutt vil utløse automatisk re-evaluering og finjustering, og til slutt, bruk av mennesker-i-løkken for å arbeide med merkede data eller ledetekstkatalog.
Om forfatterne
 Dr. Sokratis Kartakis er en hovedløsningsarkitekt for maskinlæring og operasjoner for Amazon Web Services. Sokratis fokuserer på å gjøre bedriftskunder i stand til å industrialisere sine Machine Learning (ML) og generative AI-løsninger ved å utnytte AWS-tjenester og forme deres driftsmodell, dvs. MLOps/FMOps/LLMOps-fundamenter, og transformasjonsveikart som utnytter beste utviklingspraksis. Han har brukt 15+ år på å finne opp, designe, lede og implementere innovative ende-til-ende produksjonsnivå ML- og AI-løsninger innen domenene energi, detaljhandel, helse, finans, motorsport etc.
Dr. Sokratis Kartakis er en hovedløsningsarkitekt for maskinlæring og operasjoner for Amazon Web Services. Sokratis fokuserer på å gjøre bedriftskunder i stand til å industrialisere sine Machine Learning (ML) og generative AI-løsninger ved å utnytte AWS-tjenester og forme deres driftsmodell, dvs. MLOps/FMOps/LLMOps-fundamenter, og transformasjonsveikart som utnytter beste utviklingspraksis. Han har brukt 15+ år på å finne opp, designe, lede og implementere innovative ende-til-ende produksjonsnivå ML- og AI-løsninger innen domenene energi, detaljhandel, helse, finans, motorsport etc.
 Jagdeep Singh Soni er Senior Partner Solutions Architect hos AWS med base i Nederland. Han bruker lidenskapen sin for DevOps, GenAI og byggeverktøy for å hjelpe både systemintegratorer og teknologipartnere. Jagdeep bruker sin applikasjonsutvikling og arkitekturbakgrunn for å drive innovasjon i teamet sitt og fremme nye teknologier.
Jagdeep Singh Soni er Senior Partner Solutions Architect hos AWS med base i Nederland. Han bruker lidenskapen sin for DevOps, GenAI og byggeverktøy for å hjelpe både systemintegratorer og teknologipartnere. Jagdeep bruker sin applikasjonsutvikling og arkitekturbakgrunn for å drive innovasjon i teamet sitt og fremme nye teknologier.
 Dr. Riccardo Gatti er en Senior Startup Solution Architect basert i Italia. Han er en teknisk rådgiver for kunder, og hjelper dem med å utvide virksomheten sin ved å velge de riktige verktøyene og teknologiene for å innovere, skalere raskt og bli global på få minutter. Han har alltid vært lidenskapelig opptatt av maskinlæring og generativ AI, etter å ha studert og brukt disse teknologiene på tvers av forskjellige domener gjennom hele arbeidskarrieren. Han er vert og redaktør for AWS italienske podcast "Casa Startup", dedikert til historier om oppstartsgründere og nye teknologiske trender.
Dr. Riccardo Gatti er en Senior Startup Solution Architect basert i Italia. Han er en teknisk rådgiver for kunder, og hjelper dem med å utvide virksomheten sin ved å velge de riktige verktøyene og teknologiene for å innovere, skalere raskt og bli global på få minutter. Han har alltid vært lidenskapelig opptatt av maskinlæring og generativ AI, etter å ha studert og brukt disse teknologiene på tvers av forskjellige domener gjennom hele arbeidskarrieren. Han er vert og redaktør for AWS italienske podcast "Casa Startup", dedikert til historier om oppstartsgründere og nye teknologiske trender.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 100
- 9
- a
- Om oss
- akselerere
- adgang
- nøyaktighet
- nøyaktig
- Oppnå
- oppnå
- tvers
- Handling
- Aktivering
- aktiv
- asyklisk
- la til
- tillegg
- I tillegg
- adresse
- tilstrekkelig
- administrasjon
- vedta
- Adopsjon
- fremskritt
- rådgiver
- Etter
- mot
- agenter
- AI
- AI-loven
- AI-systemer
- sikte
- Sikter
- algoritme
- algoritmer
- Justerer
- live
- Alle
- tillater
- allerede
- også
- alltid
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon SageMaker-rørledninger
- Amazon SageMaker Studio
- Amazon Web Services
- an
- analysere
- og
- En annen
- besvare
- noen
- api
- Søknad
- Applikasjonutvikling
- søknader
- anvendt
- gjelder
- tilnærming
- hensiktsmessig
- arkitektur
- ER
- områder
- argument
- AS
- vurdere
- vurdere
- evaluering
- vurderingene
- At
- revisjon
- automatisere
- Automatisert
- Automatisk
- automatisk
- Automatisering
- tilgjengelig
- AWS
- b
- bakgrunn
- basert
- grunnleggende
- BE
- fordi
- bli
- vært
- atferd
- benchmark
- benchmarked
- benchmarks
- Fordeler
- BEST
- Bedre
- mellom
- Beyond
- Bias
- forutinntatt
- skjevheter
- Blocks
- både
- brudd
- bredde
- bringe
- bygge
- bygger
- virksomhet
- men
- by
- som heter
- Samtaler
- CAN
- kandidat
- evner
- stand
- fangst
- Kort
- Karriere
- saken
- saker
- katalog
- viss
- utfordre
- egenskaper
- billigere
- sjekk
- Velg
- valgt ut
- klassifisering
- Klassifisere
- ren
- kode
- sammenhengende
- samarbeide
- kombinasjon
- kombinere
- Felles
- samfunnet
- sammenlign
- sammenligne
- sammenlignet
- sammenligning
- Kompletter
- ferdigstillelse
- komplekse
- kompleksitet
- samsvar
- overholde
- komponent
- komponenter
- omfattende
- beregnings
- Beregn
- konsept
- Bekymring
- Gjennomføre
- gjennomføre
- dirigerer
- Konfigurasjon
- Koble
- forbinder
- ansett
- består
- konstruere
- Forbrukere
- Container
- inneholder
- innhold
- kontekst
- kontinuerlig
- kontinuerlig
- kontrast
- conversational
- samtaler
- konvertere
- korrigere
- Kostnad
- kostnadsbesparelser
- kostbar
- Kostnader
- dekke
- skape
- opprettet
- Opprette
- skaperverket
- kriterier
- kritisk
- avgjørende
- skikk
- Kunder
- DAG
- dato
- Dataklargjøring
- dataforsker
- datasikkerhet
- datasett
- tukling av data
- datasett
- dato tid
- bestemme
- Beslutningstaking
- avgjørelser
- dedikert
- dyp
- dypdykk
- Misligholde
- definere
- definisjoner
- leverer
- Etterspørsel
- avhengig
- avhenger
- utplassere
- utplassert
- utplasserings
- distribusjon
- dybde
- beskrevet
- utpekt
- designet
- utforme
- design
- ønske
- ønsket
- detaljert
- detaljer
- utvikle
- utviklet
- utvikle
- Utvikling
- DevOps
- forskjeller
- forskjellig
- direkte
- regissert
- dykk
- diverse
- do
- ikke
- domene
- domener
- stasjonen
- under
- dynamisk
- e
- hver enkelt
- lett
- lett
- redaktør
- Effektiv
- effektivitet
- effektiv
- effektivt
- innsats
- enten
- elementer
- ellers
- ansatt
- muliggjøre
- muliggjør
- muliggjør
- ende til ende
- Endpoint
- endepunkter
- energi
- Ingeniører
- forbedre
- sikre
- sikrer
- sikrer
- Enterprise
- bedriftskunder
- bedrifter
- epoke
- like
- spesielt
- avgjørende
- etc
- Eter (ETH)
- EU
- evaluere
- evaluert
- evaluere
- evaluering
- Selv
- etter hvert
- eksempel
- eksempler
- utøvende
- eksisterende
- forventninger
- forventet
- fremskynde
- utvide
- utvidet
- utvendig
- utdrag
- f1
- Face
- tilrettelegging
- faktorer
- fakta
- rettferdighet
- Falls
- falsk
- berømt
- FAST
- raskere
- Trekk
- Featuring
- tilbakemelding
- Noen få
- felt
- Figur
- tall
- filet
- slutt~~POS=TRUNC
- Endelig
- finansiere
- finansiell
- Finansiell sektor
- Først
- fleksibilitet
- Fokus
- fokuserte
- fokuserer
- fulgt
- etter
- følger
- Til
- skjema
- Fundament
- Foundations
- grunnleggere
- Rammeverk
- rammer
- ofte
- fra
- oppfylle
- fullt
- funksjonalitet
- funksjonalitet
- fundamental
- Dess
- framtid
- samle
- general
- generell
- generere
- generert
- genererer
- genererer
- generasjonen
- generative
- Generativ AI
- få
- gitt
- Global
- Go
- innvilge
- graf
- Gruppe
- Gruppens
- Økende
- hånd
- skadelig
- Utnyttelse
- Ha
- å ha
- he
- Helse
- tungt
- hjelpe
- hjelpe
- hjelper
- Høy
- høy risiko
- hengsler
- hans
- holder
- vert
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- menneskelig
- i
- IAM
- identifisert
- identifiserer
- identifisere
- if
- illustrerer
- bilder
- iverksette
- implementere
- redskaper
- importere
- betydning
- forbedring
- forbedringer
- in
- inkludere
- inkluderer
- Inkludert
- Incorporated
- innlemme
- indikatorer
- bransjer
- informasjon
- informert
- Infrastruktur
- innledende
- innovere
- Innovasjon
- innovative
- inngang
- innganger
- integrere
- integrering
- med hensikt
- interaksjoner
- intern
- inn
- introdusere
- påkalt
- involvere
- involvert
- innebærer
- involverer
- ISO
- IT
- Italiensk
- Italia
- varer
- køyring
- DET ER
- Jobb
- reise
- jpg
- Hold
- holdt
- nøkkel
- kunnskap
- Språk
- stor
- større
- Siste
- til slutt
- Ventetid
- føre
- leder
- ledende
- læring
- venstre
- la
- utnytte
- Bibliotek
- Livssyklus
- i likhet med
- Begrenset
- LINK
- Llama
- plassering
- logikk
- Lav
- maskin
- maskinlæring
- Hoved
- vedlikeholde
- opprettholder
- fikk til
- manipulere
- manipulasjoner
- håndbok
- mange
- Kan..
- Mellomtiden
- måle
- målinger
- mekanismer
- metadata
- metode
- metoder
- metrisk
- Metrics
- minimere
- minutter
- feil~~POS=TRUNC
- Minske
- formildende
- ML
- MLOps
- modell
- modeller
- moduler
- Overvåke
- overvåking
- mer
- mest
- motivert
- Motorsport
- mye
- flere
- må
- navn
- nødvendig
- Trenger
- behov
- Nederland
- Ny
- Ny teknologi
- neste
- ikke-eksperter
- note
- bærbare
- notatbøker
- skyggelegging
- Antall
- of
- tilby
- ofte
- on
- gang
- ONE
- pågående
- bare
- åpen kildekode
- drift
- drift
- Drift
- Meninger
- optimalisering
- or
- OS
- Annen
- vår
- ut
- Utfallet
- utfall
- produksjon
- utganger
- enestående
- enn
- samlet
- egen
- eiere
- Parallel
- parametere
- Spesielt
- spesielt
- partner
- partnere
- lidenskap
- lidenskapelig
- banen
- mønstre
- Ansatte
- utføre
- ytelse
- forestillinger
- utfører
- fase
- PII
- rørledning
- Sted
- placeholder
- plato
- Platon Data Intelligence
- PlatonData
- PoC
- podcast
- Point
- basseng
- pools
- Post
- post-prosessering
- potensiell
- makt
- powered
- praksis
- Precision
- forberedelse
- forbereder
- tilstedeværelse
- forebygge
- forrige
- primære
- Principal
- prinsipper
- privatliv
- privat
- Problem
- prosedyren
- prosess
- Prosesser
- prosessering
- Produksjon
- progresjon
- fremtredende
- løfte
- fremme
- ledetekster
- bevis
- proof of concept
- forplantning
- egenskaper
- proprietær
- beskytte
- Bevis
- gi
- tilbydere
- gir
- gi
- offentlig
- offentlig
- formål
- Python
- kvalitativ
- kvalitet
- kvantitativ
- spørsmål
- område
- Sats
- vurdering
- ekte
- virkelige verden
- sanntids
- redusere
- Redusert
- redusere
- referere
- referanse
- registrert
- Registrering
- registret
- regresjon
- regelmessig
- regulert
- regulerte næringer
- forskrifter
- forsterkning læring
- i slekt
- relevans
- relevant
- pålitelighet
- repeterende
- rapporterer
- Rapportering
- Rapporter
- Repository
- representant
- påkrevd
- Krever
- forskning
- forskere
- ressurskrevende
- Ressurser
- ansvar
- ansvarlig
- resulterende
- Resultater
- detaljhandel
- beholde
- retur
- gjenbruk
- anmeldelse
- revolusjonerer
- ikke sant
- streng
- Risen
- Risiko
- risikoer
- veikart
- robust
- robusthet
- Rolle
- roller
- Kjør
- rennende
- går
- s
- trygge
- sikringstiltak
- sagemaker
- SageMaker-rørledninger
- Besparelser
- skalerbarhet
- skalerbar
- Skala
- scenario
- scenarier
- Forsker
- forskere
- omfang
- Resultat
- script
- SDK
- sømløst
- seksjoner
- sektor
- sikre
- sikkerhet
- sikkerhetsrisiko
- velg
- valgt
- velge
- utvalg
- senior
- sentiment
- betjene
- tjeneste
- Tjenester
- servering
- Session
- sett
- forme
- Del
- Vis
- vist
- Viser
- side
- signifikant
- lignende
- forenkler
- ganske enkelt
- siden
- enkelt
- liten
- løsning
- Solutions
- LØSE
- noen
- kilde
- span
- spesialist
- spesifikk
- spesielt
- brukt
- iscenesettelse
- interessenter
- standardisere
- standarder
- stanford
- Start
- starter
- oppstart
- status
- Trinn
- Steps
- Still
- lagring
- oppbevare
- Stories
- rett fram
- strukturert
- studert
- studio
- stil
- I ettertid
- slik
- SAMMENDRAG
- støtte
- system
- Systemer
- sying
- Oppgave
- oppgaver
- lag
- lag
- Teknisk
- teknikker
- teknologisk
- Technologies
- Teknologi
- maler
- test
- testere
- Testing
- tester
- tekst
- enn
- Det
- De
- Fremtiden
- deres
- Dem
- deretter
- teoretiske
- derved
- derfor
- Disse
- de
- denne
- De
- tre
- Gjennom
- hele
- tid
- til
- sammen
- verktøy
- verktøy
- spor
- Tog
- trent
- Kurs
- Togene
- Transformation
- overgang
- overgangen
- Oversettelse
- Trender
- utløse
- sant
- troverdig
- to
- typer
- typisk
- Til syvende og sist
- uautorisert
- forstå
- forståelse
- enestående
- kommende
- bruke
- bruk sak
- brukt
- Bruker
- Brukere
- bruker
- ved hjelp av
- vanligvis
- bruke
- VALIDERE
- Verdifull
- ulike
- versjon
- av
- vital
- Sikkerhetsproblemer
- ønsker
- varm
- we
- web
- webtjenester
- VI VIL
- var
- Hva
- når
- hvilken
- mens
- HVEM
- bred
- Bred rekkevidde
- Wikipedia
- vil
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- arbeid
- verden
- yaml
- år
- Utbytte
- du
- Din
- zephyrnet