Sponsede Post

Utfordringene med å bygge multimodale modeller fra bunnen av
For mange brukstilfeller for maskinlæring stoler organisasjoner utelukkende på tabelldata og trebaserte modeller som XGBoost og LightGBM. Dette er fordi dyp læring rett og slett er for vanskelig for de fleste ML-team. Vanlige utfordringer inkluderer:
- Mangel på ekspertkunnskap som trengs for å utvikle komplekse dyplæringsmodeller
- Rammer som PyTorch og Tensorflow krever at team skriver tusenvis av linjer med kode som er utsatt for menneskelige feil
- Treningsdistribuerte DL-rørledninger krever dyp kunnskap om infrastruktur og kan ta uker å trene modeller
Som et resultat går team glipp av verdifulle signaler skjult i ustrukturerte data som tekst og bilder.
Rask modellutvikling med deklarative systemer
Nye deklarative maskinlæringssystemer – som åpen kildekode Ludwig startet hos Uber – gir en lavkodetilnærming til automatisering av ML som gjør det mulig for datateam å bygge og distribuere toppmoderne modeller raskere med en enkel konfigurasjonsfil. Spesielt gjør Predibase – den ledende lavkodedeklarative ML-plattformen – sammen med Ludwig det enkelt å bygge multimodale dyplæringsmodeller i < 15 linjer med kode.
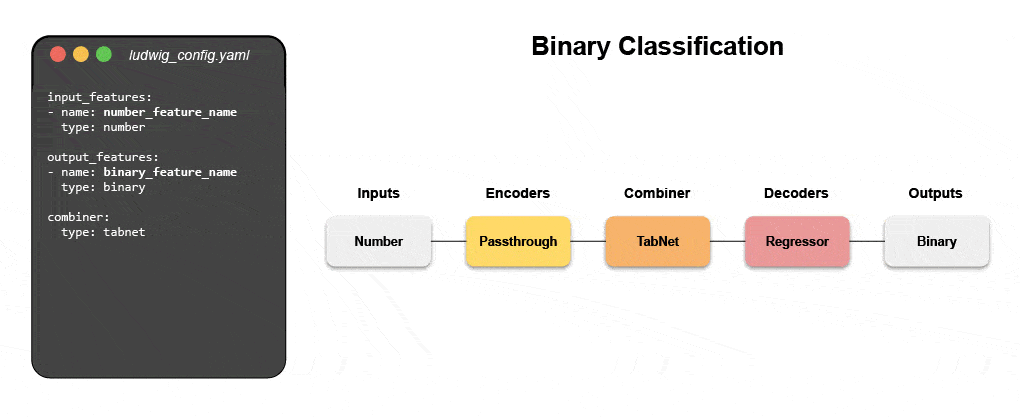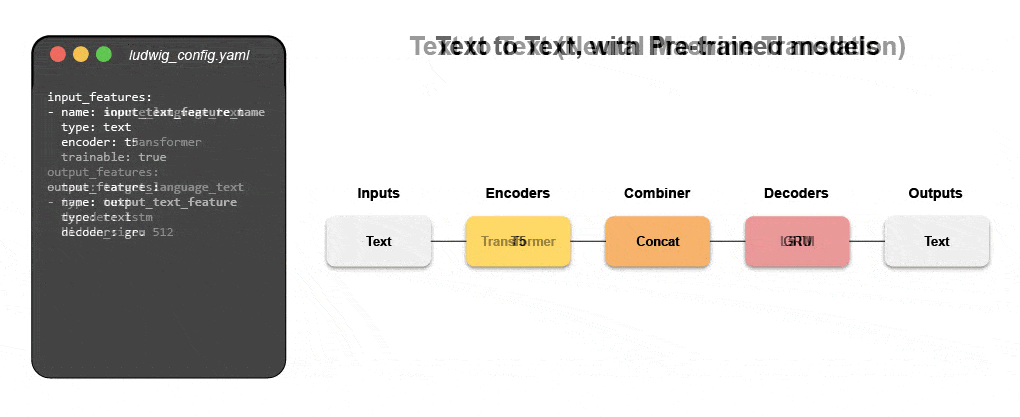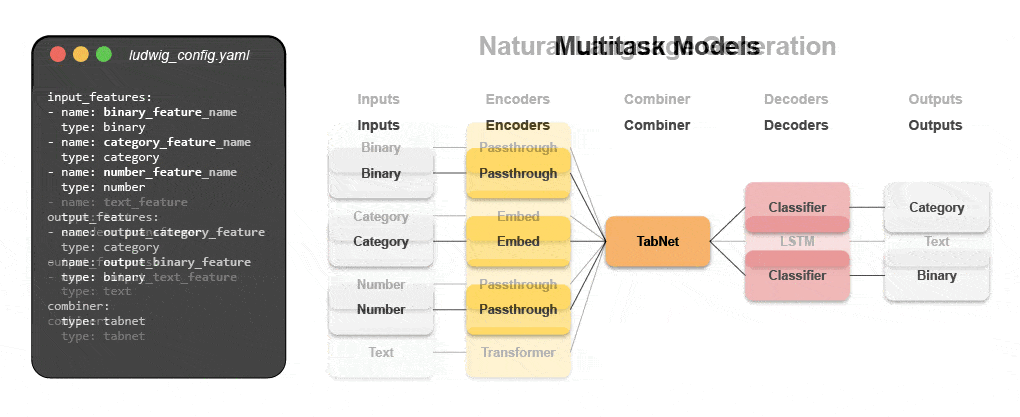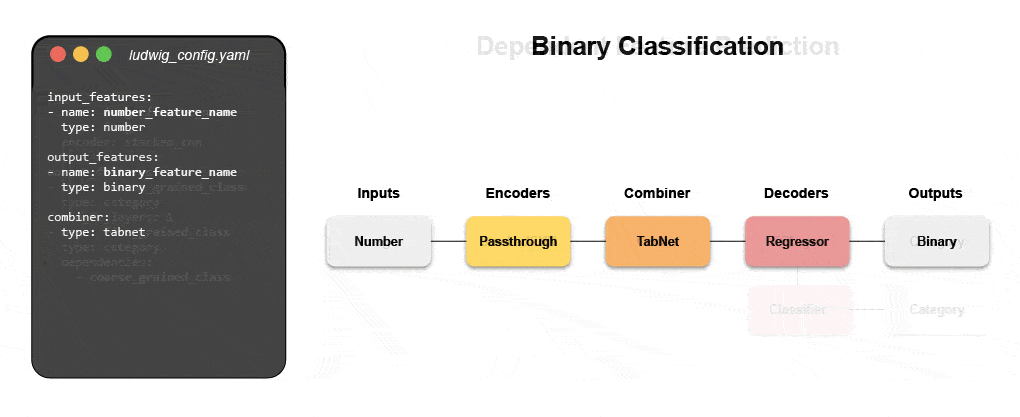
Lær hvordan du bygger en multimodal modell med deklarativ ML
Bli med på vårt kommende webinar og live tutorial for å lære om deklarative systemer som Ludwig og følge trinnvise instruksjoner for å bygge en multimodal kundevurderingsprediksjonsmodell som utnytter tekst og tabelldata.
I denne økten lærer du hvordan du:
- Tren, iterer og distribuer raskt en multimodal modell for kundevurderingsspådommer,
- Bruk deklarative ML-verktøy med lav kode for å dramatisk redusere tiden det tar å bygge flere ML-modeller,
- Utnytt ustrukturerte data like enkelt som strukturerte data med åpen kildekode Ludwig og Predibase
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- Om oss
- og
- tilnærming
- Automatisere
- fordi
- bygge
- Bygning
- utfordringer
- kode
- Felles
- komplekse
- Konfigurasjon
- kunde
- dato
- dyp
- dyp læring
- utplassere
- utvikle
- Utvikling
- distribueres
- dramatisk
- lett
- muliggjør
- feil
- Expert
- raskere
- filet
- følge
- fra
- gif
- Hard
- skjult
- Hvordan
- Hvordan
- HTML
- HTTPS
- menneskelig
- bilder
- in
- inkludere
- Infrastruktur
- instruksjoner
- IT
- KDnuggets
- kunnskap
- ledende
- LÆRE
- læring
- utnytte
- linjer
- leve
- maskin
- maskinlæring
- gjøre
- mange
- ML
- modell
- modeller
- mest
- flere
- nødvendig
- åpen kildekode
- organisasjoner
- plato
- Platon Data Intelligence
- PlatonData
- prediksjon
- Spådommer
- pytorch
- redusere
- krever
- Krever
- resultere
- anmeldelse
- Session
- signaler
- Enkelt
- ganske enkelt
- spesielt
- startet
- state-of-the-art
- Trinn
- strukturert
- Systemer
- Ta
- tar
- lag
- tensorflow
- De
- tusener
- tid
- til
- også
- verktøy
- Tog
- tutorial
- kommende
- bruk-tilfeller
- Verdifull
- uker
- vil
- innenfor
- skrive
- Xgboost
- Din
- zephyrnet





