Amazon RedShift er et raskt, fullt administrert datavarehus i petabyte-skala som gir fleksibiliteten til å bruke klargjort eller serverløs databehandling for dine analytiske arbeidsbelastninger. Ved hjelp av Amazon Redshift Serverløs og Query Editor v2, du kan laste inn og søke etter store datasett med bare noen få klikk og betale kun for det du bruker. Den frakoblede beregnings- og lagringsarkitekturen til Amazon Redshift lar deg bygge svært skalerbare, spenstige og kostnadseffektive arbeidsbelastninger. Mange kunder migrerer datavarehusarbeidsmengdene sine til Amazon Redshift og drar nytte av de rike mulighetene den tilbyr. Følgende er bare noen av de bemerkelsesverdige egenskapene:
- Amazon Redshift integreres sømløst med bredere analysetjenester på AWS. Dette gjør at du kan velge riktig verktøy for riktig jobb. Moderne analyser er mye bredere enn SQL-basert datavarehus. Amazon Redshift lar deg bygge innsjøhusarkitektur og deretter utføre alle slags analyser, som f.eks interaktive analyser, operasjonell analyse, stor databehandling, klargjøring av visuelle data, prediktiv analyse, maskinlæring (ML) og mer.
- Du trenger ikke å bekymre deg for arbeidsbelastninger, som ETL, dashbord, ad-hoc-spørringer og så videre, som forstyrrer hverandre. Du kan isolere arbeidsbelastninger ved hjelp av datadeling, mens du bruker de samme underliggende datasettene.
- Når brukere kjører mange søk på topptider, beregner sømløst skalerer i løpet av sekunder for å gi konsistent ytelse ved høy samtidighet. Du får én times gratis samtidighetsskaleringskapasitet for 24 timers bruk. Denne gratis kreditten oppfyller samtidig etterspørselen til 97 % av Amazon Redshift-kundebasen.
- Amazon Redshift er enkel å bruke med selvjustering og selvoptimalisering evner. Du kan få raskere innsikt uten å bruke verdifull tid på å administrere datavarehuset ditt.
- Feiltoleranse er innebygd. Alle data som er skrevet til Amazon Redshift, blir automatisk og kontinuerlig replikert til Amazon Simple Storage Service (Amazon S3). Eventuelle maskinvarefeil erstattes automatisk.
- Amazon Redshift er enkel å samhandle med. Du kan få tilgang til data med tradisjonelle, skybaserte, containeriserte og serverløse nettjenesterbaserte eller hendelsesdrevne applikasjoner og så videre.
- Rødforskyvning ML gjør det enkelt for dataforskere å lage, trene og distribuere ML-modeller ved å bruke kjent SQL. De kan også kjøre spådommer ved hjelp av SQL.
- Amazon Redshift gir omfattende datasikkerhet uten ekstra kostnad. Du kan sette opp ende-til-ende datakryptering, konfigurere brannmurregler, definere granulære sikkerhetskontroller på rad- og kolonnenivå på sensitive data, og så videre.
- Amazon RedShift integreres sømløst med andre AWS-tjenester og tredjepartsverktøy. Du kan flytte, transformere, laste inn og forespørre store datasett raskt og pålitelig.
I dette innlegget gir vi en gjennomgang for å migrere et datavarehus fra Google BigQuery til Amazon Redshift ved hjelp av AWS Schema Conversion Tool (AWS SCT) og AWS SCT dataekstraksjonsagenter. AWS SCT er en tjeneste som gjør heterogene databasemigrasjoner forutsigbare ved automatisk å konvertere størstedelen av databasekoden og lagringsobjektene til et format som er kompatibelt med måldatabasen. Alle objekter som ikke kan konverteres automatisk er tydelig merket slik at de kan konverteres manuelt for å fullføre migreringen. Videre kan AWS SCT skanne applikasjonskoden din for innebygde SQL-setninger og konvertere dem.
Løsningsoversikt
AWS SCT bruker en tjenestekonto for å koble til BigQuery-prosjektet ditt. Først lager vi en Amazon Redshift-database som BigQuery-data migreres til. Deretter lager vi en S3-bøtte. Deretter bruker vi AWS SCT til å konvertere BigQuery-skjemaer og bruke dem på Amazon Redshift. Til slutt, for å migrere data, bruker vi AWS SCT-dataekstraksjonsagenter, som trekker ut data fra BigQuery, laster dem opp i S3-bøtten og deretter kopierer til Amazon Redshift.

Forutsetninger
Før du starter denne gjennomgangen, må du ha følgende forutsetninger:
- En arbeidsstasjon med AWS SCT, Amazon Corretto 11, og Amazon Redshift-drivere.
- Du kan bruke en Amazon Elastic Compute Cloud (Amazon EC2)-forekomst eller ditt lokale skrivebord som en arbeidsstasjon. I denne gjennomgangen bruker vi Amazon EC2 Windows-forekomst. For å lage den, bruk Denne guiden.
- For å laste ned og installere AWS SCT på EC2-forekomsten du tidligere opprettet, bruk Denne guiden.
- Last ned Amazon Redshift JDBC-driveren fra denne plasseringen.
- Last ned og installer Amazon Corretto 11.
- En GCP-tjenestekonto som AWS SCT kan bruke for å koble til BigQuery-kildeprosjektet ditt.
- Grant BigQuery Admin og Lagringsadmin roller til tjenestekontoen.
- Kopier tjenestekontonøkkelfilen, som ble opprettet i Googles skyadministrasjonskonsoll, til EC2-forekomsten som har AWS SCT.
- Opprett en Cloud Storage-bøtte i GCP for å lagre kildedataene dine under migrering.
Denne gjennomgangen dekker følgende trinn:
- Opprett en Amazon Redshift Serverless Workgroup and Namespace
- Lag AWS S3 bøtte og mappe
- Konverter og bruk BigQuery Schema til Amazon Redshift ved hjelp av AWS SCT
- Kobler til Google BigQuery-kilden
- Koble til Amazon Redshift Target
- Konverter BigQuery-skjemaet til en Amazon Redshift
- Analyser vurderingsrapporten og ta opp handlingspunktene
- Bruk konvertert skjema for å målrette Amazon Redshift
- Migrer data ved å bruke AWS SCT-dataekstraksjonsagenter
- Generering av tillit og nøkkellager (valgfritt)
- Installer og start datautvinningsagent
- Registrer datautvinningsagent
- Legg til virtuelle partisjoner for store bord (valgfritt)
- Opprett en lokal migreringsoppgave
- Start den lokale dataoverføringsoppgaven
- Se data i Amazon Redshift
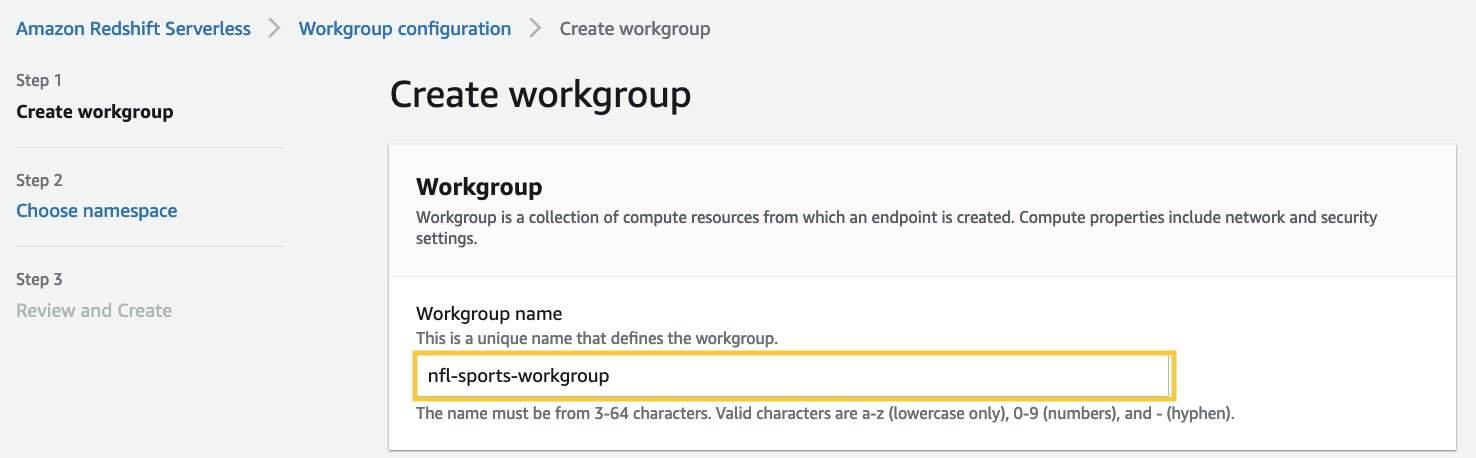
Opprett en Amazon Redshift Serverless Workgroup and Namespace
I dette trinnet oppretter vi en Amazon Redshift Serverless-arbeidsgruppe og navneområde. Workgroup er en samling av dataressurser og navneområde er en samling av databaseobjekter og brukere. For å isolere arbeidsbelastninger og administrere forskjellige ressurser i Amazon Redshift Serverless, kan du opprette navneområder og arbeidsgrupper og administrere lagrings- og dataressurser separat.
Følg disse trinnene for å opprette Amazon Redshift Serverless arbeidsgruppe og navneområde:
- Naviger til Amazon Redshift-konsoll.
- Øverst til høyre velger du AWS-regionen du vil bruke.
- Utvid Amazon Redshift-ruten til venstre og velg Redshift serverløs.
- Velg Opprett arbeidsgruppe.
- Til Arbeidsgruppenavn, angi et navn som beskriver beregningsressursene.
- Bekreft at VPC-en er den samme som VPC-en som EC2-forekomsten med AWS SCT.
- Velg neste.
- Til Navneområdenavn, skriv inn et navn som beskriver datasettet ditt.
- In Databasenavn og passord seksjon, merk av i avmerkingsboksen Tilpass admin brukerlegitimasjon.
- Til Admin brukernavn, skriv inn et brukernavn etter eget valg, for eksempel awsuser.
- Til Admin brukerpassord: skriv inn et passord du ønsker, for eksempel MyRedShiftPW2022.
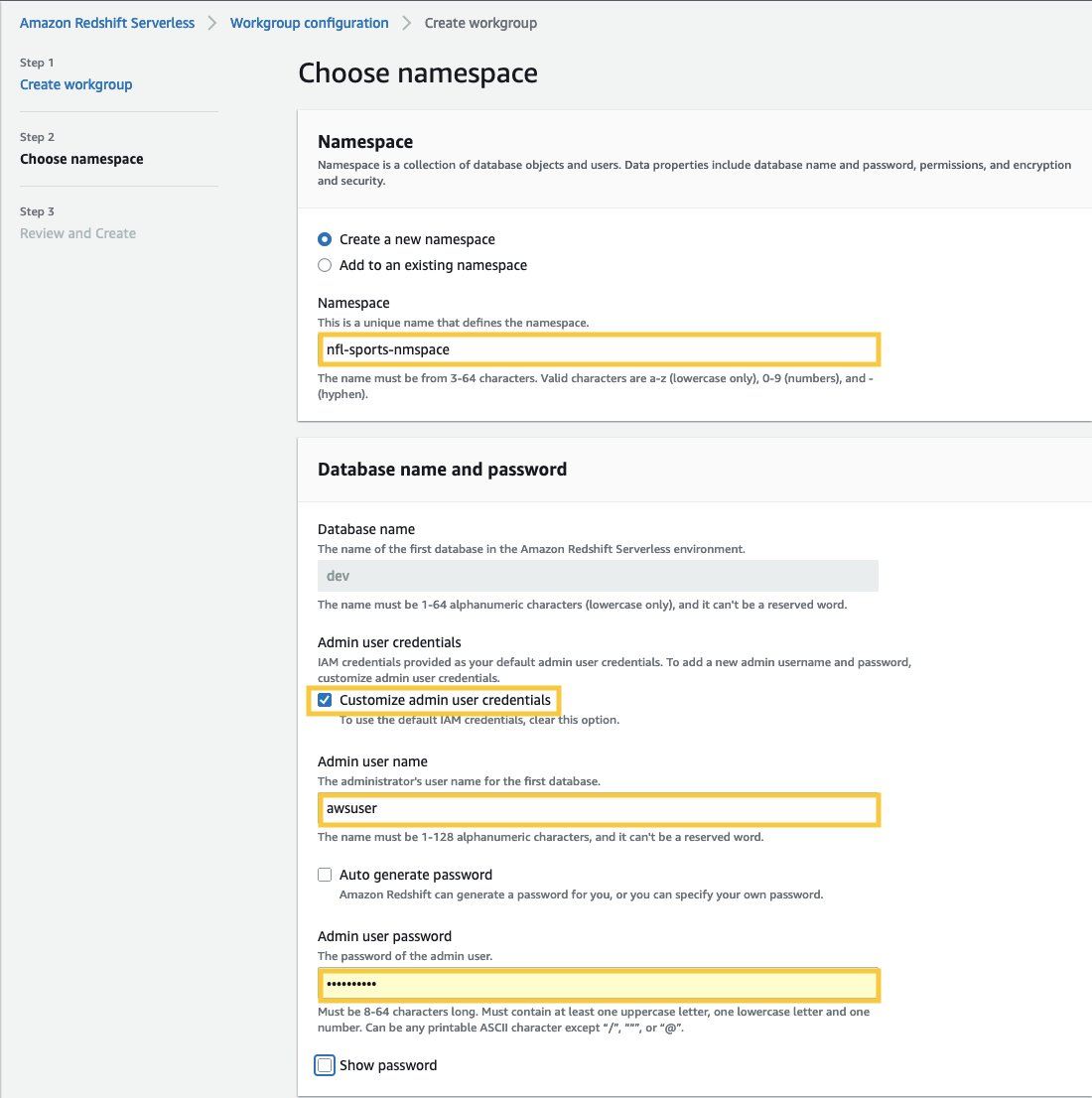
- Velg Neste. Merk at data i Amazon Redshift Serverless navneområde er kryptert som standard.
- på Gjennomgå og lag side, velg Opprett.
- Lag en AWS Identity and Access Management (IAM) rolle og angi den som standard på navneområdet ditt, som beskrevet i det følgende. Merk at det bare kan være én standard IAM-rolle.
- Naviger til Amazon Redshift Serverless Dashboard.
- Under Navneområder / arbeidsgrupper, velg navneområdet du nettopp opprettet.
- naviger tilSikkerhet og kryptering.
- Under Tillatelser, velg Administrer IAM-roller.
- naviger til Administrer IAM-roller. Deretter velger du Administrer IAM-roller rullegardinmenyen og velg Lag IAM-rolle.
- Under Spesifiser en Amazon S3-bøtte for IAM-rollen, velg en av følgende metoder:
- Velg Ingen ekstra Amazon S3-bøtte for å la den opprettede IAM-rollen bare få tilgang til S3-bøttene med et navn som begynner med rødforskyvning.
- Velg En hvilken som helst Amazon S3-bøtte for å gi den opprettede IAM-rollen tilgang til alle S3-bøttene.
- Velg Spesifikke Amazon S3-bøtter for å spesifisere én eller flere S3-bøtter for tilgang til den opprettede IAM-rollen. Velg deretter en eller flere S3-bøtter fra tabellen.
- Velg Opprett IAM-rolle som standard. Amazon Redshift oppretter og angir automatisk IAM-rollen som standard.
- Fang endepunktet for Amazon Redshift Serverless-arbeidsgruppen du nettopp opprettet.
Lag S3-bøtten og mappen
Under datamigreringsprosessen bruker AWS SCT Amazon S3 som et oppsamlingsområde for de utpakkede dataene. Følg disse trinnene for å lage S3-bøtten:
- Naviger til Amazon S3-konsoll
- Velg Lag bøtte. De Lag bøtte veiviseren åpnes.
- Til Bøtte navn, skriv inn et unikt DNS-kompatibelt navn for bøtten din (f.eks. unikt navn-bq-rs). Se regler for navn på bøtte når du velger navn.
- For AWS Region, velg regionen der du opprettet Amazon Redshift Serverless-arbeidsgruppen.
- Plukke ut Lag bøtte.
- på Amazon S3-konsoll, naviger til S3-bøtten du nettopp opprettet (f.eks. unikt navn-bq-rs).
- Velg "Lag mappe" for å opprette en ny mappe.
- Til Mappenavn, skriv innkommende Og velg Lag mappe.
Konverter og bruk BigQuery Schema til Amazon Redshift ved hjelp av AWS SCT
For å konvertere BigQuery-skjemaet til Amazon Redshift-formatet bruker vi AWS SCT. Start med å logge på EC2-forekomsten som vi opprettet tidligere, og start deretter AWS SCT.
Følg disse trinnene ved å bruke AWS SCT:
Koble til BigQuery-kilden
- Fra fil velge Opprett nytt prosjekt.
- Velg en plassering for å lagre prosjektfilene og dataene dine.
- Gi et meningsfylt, men minneverdig navn for prosjektet ditt, for eksempel BigQuery til Amazon Redshift.
- For å koble til BigQuery-kildedatavarehuset, velg Legg til kilde fra hovedmenyen.
- Velg BigQuery Og velg neste. De Legg til kilde dialogboksen vises.
- Til Tilkoblingsnavn, skriv inn et navn for å beskrive BigQuery-tilkoblingen. AWS SCT viser dette navnet i treet i venstre panel.
- Til Nøkkelvei, oppgi banen til tjenestekontonøkkelfilen som tidligere ble opprettet i Googles skyadministrasjonskonsoll.
- Velg Test Connection for å bekrefte at AWS SCT kan koble til BigQuery-kildeprosjektet ditt.
- Når tilkoblingen er validert, velger du Koble.

Koble til Amazon Redshift Target
Følg disse trinnene for å koble til Amazon Redshift:
- I AWS SCT velger du Legg til mål fra hovedmenyen.
- Velg Amazon RedShift, velg deretter Neste. De Legg til mål dialogboksen vises.
- Til Tilkoblingsnavn, skriv inn et navn for å beskrive Amazon Redshift-tilkoblingen. AWS SCT viser dette navnet i treet i høyre panel.
- Til Server navn, angi Amazon Redshift Serverless-arbeidsgruppeendepunktet som ble fanget tidligere.
- Til Serverport, skriv 5439.
- Til Database, skriv dev.
- Til Brukernavn, skriv inn brukernavnet som ble valgt når du opprettet Amazon Redshift Serverless-arbeidsgruppen.
- Til Passord, skriv inn passordet du valgte når du opprettet Amazon Redshift Serverless-arbeidsgruppe.
- Fjern merkingen boksen "Bruk AWS-lim".
- Velg Test Connection for å verifisere at AWS SCT kan koble til din målrettede Amazon Redshift-arbeidsgruppe.
- Velg Koble for å koble til Amazon Redshift-målet.
Merk at du alternativt kan bruke tilkoblingsverdier som er lagret i AWS Secrets Manager.

Konverter BigQuery-skjemaet til en Amazon Redshift
Etter at kilde- og målforbindelsene er opprettet, ser du kilde-BigQuery-objekttreet i venstre rute og mål-Amazon Redshift-objekttreet i høyre rute.
Følg disse trinnene for å konvertere BigQuery-skjemaet til Amazon Redshift-formatet:
- Høyreklikk på skjemaet du vil konvertere i venstre rute.
- Velg Konverter skjema.
- En dialogboks vises med et spørsmål, Objektene kan allerede eksistere i måldatabasen. Erstatte?. Velg Ja.
Når konverteringen er fullført, ser du et nytt skjema opprettet i Amazon Redshift-ruten (høyre rute) med samme navn som BigQuery-skjemaet ditt.

Eksempelskjemaet vi brukte har 16 tabeller, 3 visninger og 3 prosedyrer. Du kan se disse objektene i Amazon Redshift-formatet i høyre rute. AWS SCT konverterer all BigQuery-kode og dataobjekter til Amazon Redshift-formatet. Videre kan du bruke AWS SCT til å konvertere eksterne SQL-skript, applikasjonskode eller tilleggsfiler med innebygd SQL.
Analyser vurderingsrapporten og ta opp handlingspunktene
AWS SCT lager en vurderingsrapport for å vurdere migrasjonskompleksiteten. AWS SCT kan konvertere de fleste kode- og databaseobjekter. Noen av objektene kan imidlertid kreve manuell konvertering. AWS SCT fremhever disse objektene i blått i konverteringsstatistikkdiagrammet og lager handlingselementer med en kompleksitet knyttet til dem.
For å se vurderingsrapporten, bytt fra Hovedvisning til Vurderingsrapportvisning som følger:
De Oppsummering fanen viser objekter som ble konvertert automatisk, og objekter som ikke ble konvertert automatisk. Grønn representerer automatisk konvertert eller med enkle handlingselementer. Blå representerer middels og komplekse handlingselementer som krever manuell intervensjon.
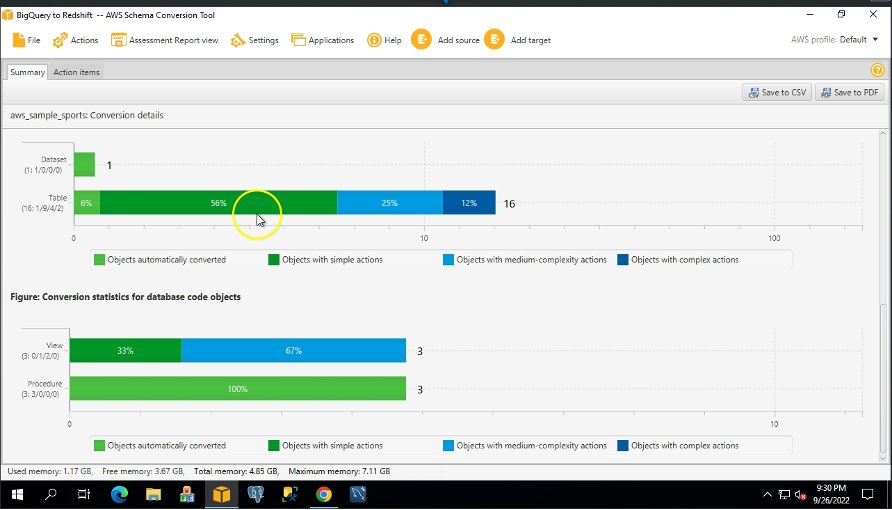
De Handlingselementer fanen viser de anbefalte handlingene for hvert konverteringsproblem. Hvis du velger et handlingselement fra listen, uthever AWS SCT objektet som handlingselementet gjelder for.
Rapporten inneholder også anbefalinger for hvordan du manuelt konverterer skjemaelementet. For eksempel, etter at vurderingen er kjørt, viser detaljerte rapporter for databasen/skjemaet deg innsatsen som kreves for å designe og implementere anbefalingene for konvertering av handlingselementer. For mer informasjon om å bestemme hvordan du skal håndtere manuelle konverteringer, se Håndtering av manuelle konverteringer i AWS SCT. Amazon Redshift utfører noen handlinger automatisk mens skjemaet konverteres til Amazon Redshift. Objekter med disse handlingene er merket med et rødt varselskilt.

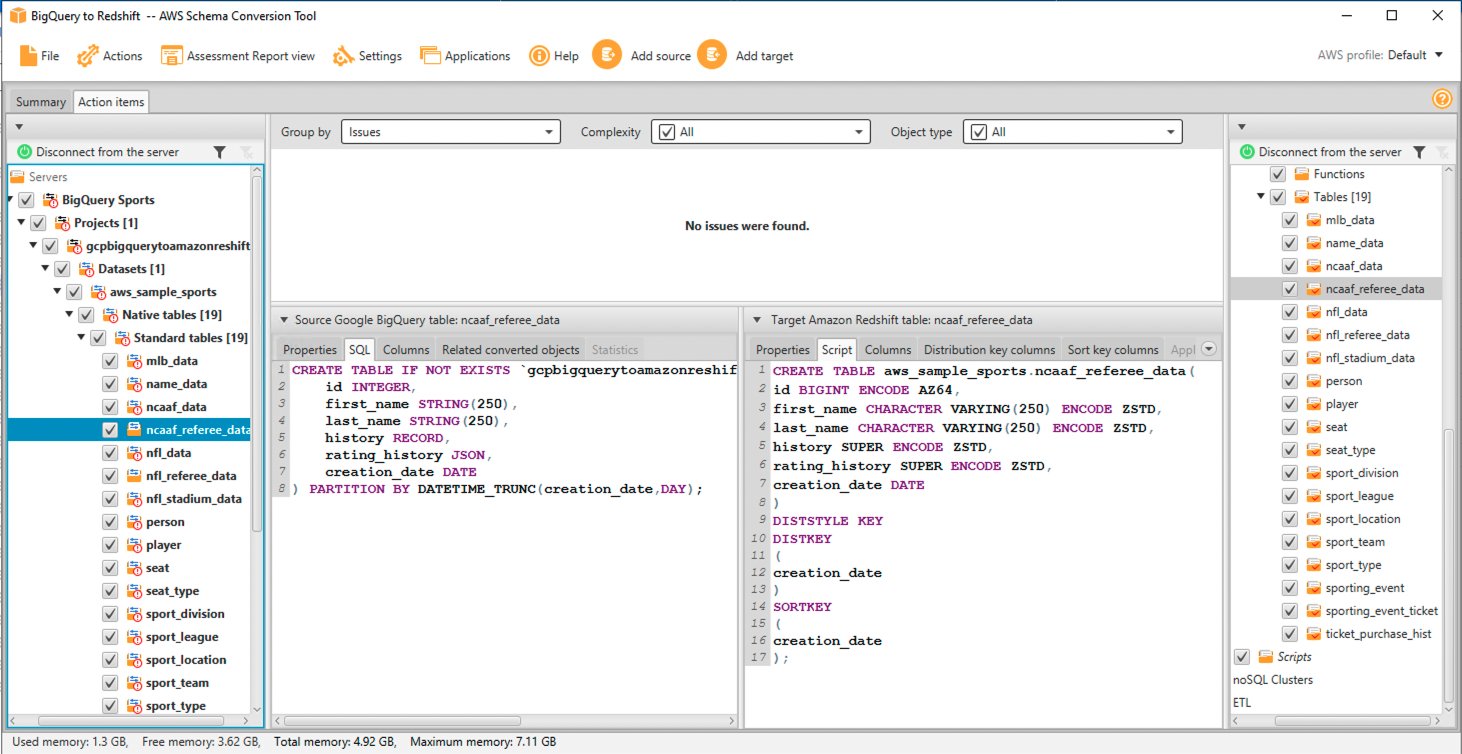
Du kan evaluere og inspisere det individuelle DDL-objektet ved å velge det fra høyre rute, og du kan også redigere det etter behov. I det følgende eksempelet endrer AWS SCT RECORD- og JSON-datatypekolonnene i BigQuery-tabellen ncaaf_referee_data til SUPER-datatypen i Amazon Redshift. Partisjonsnøkkelen i tabellen ncaaf_referee_data konverteres til distribusjonsnøkkelen og sorteringsnøkkelen i Amazon Redshift.
Bruk konvertert skjema for å målrette Amazon Redshift
For å bruke det konverterte skjemaet til Amazon Redshift, velg det konverterte skjemaet i høyre rute, høyreklikk og velg Bruk på database.
Migrer data fra BigQuery til Amazon Redshift ved å bruke AWS SCT-dataekstraksjonsagenter
AWS SCT-utvinningsagenter trekker ut data fra kildedatabasen din og migrerer dem til AWS Cloud. I denne gjennomgangen viser vi hvordan du konfigurerer AWS SCT-ekstraksjonsagenter til å trekke ut data fra BigQuery og migrere til Amazon Redshift.
Installer først AWS SCT-ekstraksjonsagent på samme Windows-forekomst som har AWS SCT installert. For bedre ytelse anbefaler vi at du bruker en separat Linux-instans for å installere ekstraksjonsagenter hvis mulig. For store datasett kan du bruke flere dataekstraksjonsagenter for å øke datamigreringshastigheten.
Generering av tillit og nøkkelbutikker (valgfritt)
Du kan bruke Secure Socket Layer (SSL) kryptert kommunikasjon med AWS SCT-datauttrekkere. Når du bruker SSL, forblir all data som sendes mellom applikasjonene private og integrerte. For å bruke SSL-kommunikasjon, må du generere tillit og nøkkellagre ved hjelp av AWS SCT. Du kan hoppe over dette trinnet hvis du ikke vil bruke SSL. Vi anbefaler å bruke SSL for produksjonsarbeidsbelastninger.
Følg disse trinnene for å generere tillit og nøkkelbutikker:
- I AWS SCT, naviger til Innstillinger → Globale innstillinger → Sikkerhet.
- Velg Skap tillit og nøkkellager.

- Skriv inn navn og passord for tillits- og nøkkelbutikker, og velg et sted du vil lagre dem.

- Velg Generere.
Installer og konfigurer Data Extraction Agent
I installasjonspakken for AWS SCT finner du en undermappeagent (aws-schema-conversion-tool-1.0.latest.zipagents). Finn og installer den kjørbare filen med et navn som aws-schema-conversion-tool-extractor-xxxxxxxx.msi.
Følg disse trinnene i installasjonsprosessen for å konfigurere AWS SCT Data Extractor:
- Til Lytteport, skriv inn portnummeret som agenten lytter til. Det er 8192 som standard.
- Til Legg til en kildeleverandør, Tast inn nei, siden du ikke trenger drivere for å koble til BigQuery.
- Til Legg til Amazon Redshift-driveren, Tast inn JA.
- Til Skriv inn Redshift JDBC-driverfilen eller -filer, skriv inn plasseringen der du lastet ned Amazon Redshift JDBC-drivere.
- Til Arbeidsmappe, skriv inn banen der AWS SCT-datautvinningsagenten vil lagre de utpakkede dataene. Arbeidsmappen kan være på en annen datamaskin enn agenten, og en enkelt arbeidsmappe kan deles av flere agenter på forskjellige datamaskiner.
- Til Aktiver SSL-kommunikasjon, Tast inn ja. Velg Nei her hvis du ikke vil bruke SSL.
- Til Nøkkelbutikk, skriv inn lagringsstedet som ble valgt når du opprettet tillits- og nøkkellageret.
- Til Passord for nøkkellager, skriv inn passordet for nøkkellageret.
- Til Aktiver klient SSL-autentisering, Tast inn ja.
- Til Trust store, skriv inn lagringsstedet som ble valgt når du opprettet tillits- og nøkkellageret.
- Til Passord for Trust Store, skriv inn passordet for tillitsbutikken.
Starte datautvinningsagent(er)
Bruk følgende prosedyre for å starte ekstraksjonsmidler. Gjenta denne prosedyren på hver datamaskin som har en ekstraksjonsagent installert.
Ekstraksjonsmidler fungerer som lyttere. Når du starter en agent med denne prosedyren, begynner agenten å lytte etter instruksjoner. Du sender agentenes instruksjoner for å trekke ut data fra datavarehuset ditt i en senere seksjon.
For å starte utvinningsagenten, naviger til AWS SCT Data Extractor Agent-katalogen. For eksempel, i Microsoft Windows, dobbeltklikker du C:Program FilesAWS SCT Data Extractor AgentStartAgent.bat.
- På datamaskinen som har utvinningsagenten installert, fra en ledetekst eller terminalvindu, kjør kommandoen som er oppført etter operativsystemet ditt.
- For å sjekke statusen til agenten, kjør den samme kommandoen, men erstatt start med status.
- For å stoppe en agent, kjør den samme kommandoen, men erstatt start med stopp.
- For å starte en agent på nytt, kjør den samme RestartAgent.bat-filen.
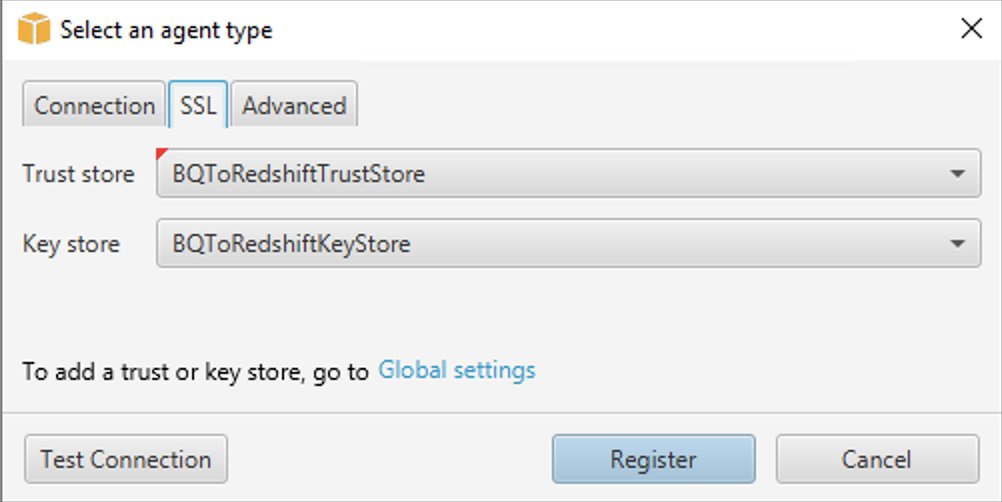
Registrer datautvinningsagenten
Følg disse trinnene for å registrere datautvinningsagenten:
- I AWS SCT endrer du visningen til Dataoverføringsvisning (annet) Og velg + Registrer deg.
- I tilkoblingsfanen:

- Til Beskrivelse, skriv inn et navn for å identifisere datautvinningsagenten.
- Til Vertsnavn, hvis du installerte Data Extraction Agent på samme arbeidsstasjon som AWS SCT, skriv inn 0.0.0.0 for å angi lokal vert. Ellers skriver du inn vertsnavnet til maskinen som AWS SCT Data Extraction Agent er installert på. Det anbefales å installere Data Extraction Agents på Linux for bedre ytelse.
- Til Havn, skriv inn nummeret som er angitt for Lytteport når du installerer AWS SCT Data Extraction Agent.
- Merk av i avmerkingsboksen for å bruke SSL (hvis du bruker SSL) for å kryptere AWS SCT-tilkoblingen til Data Extraction Agent.
- Hvis du bruker SSL, så i SSL-fanen:
- Til tillitsbutikk, velg navnet på tillitsbutikken opprettet når generere tillit og nøkkelbutikker (eventuelt kan du hoppe over dette hvis SSL-tilkobling ikke er nødvendig).
- Til Nøkkelbutikk, velg nøkkellagernavnet opprettet når generere tillit og nøkkelbutikker (eventuelt kan du hoppe over dette hvis SSL-tilkobling ikke er nødvendig).

- Velg Test Connection.
- Når tilkoblingen er validert, velg Registrere.
Legg til virtuelle partisjoner for store bord (valgfritt)
Du kan bruke AWS SCT til å lage virtuelle partisjoner for å optimalisere migreringsytelsen. Når virtuelle partisjoner opprettes, trekker AWS SCT ut dataene parallelt for partisjoner. Vi anbefaler å lage virtuelle partisjoner for store bord.
Følg disse trinnene for å lage virtuelle partisjoner:
- Fjern markeringen av alle objekter på kildedatabasevisningen i AWS SCT.
- Velg tabellen du vil legge til virtuell partisjonering for.
- Høyreklikk på tabellen, og velg Legg til virtuell partisjonering.

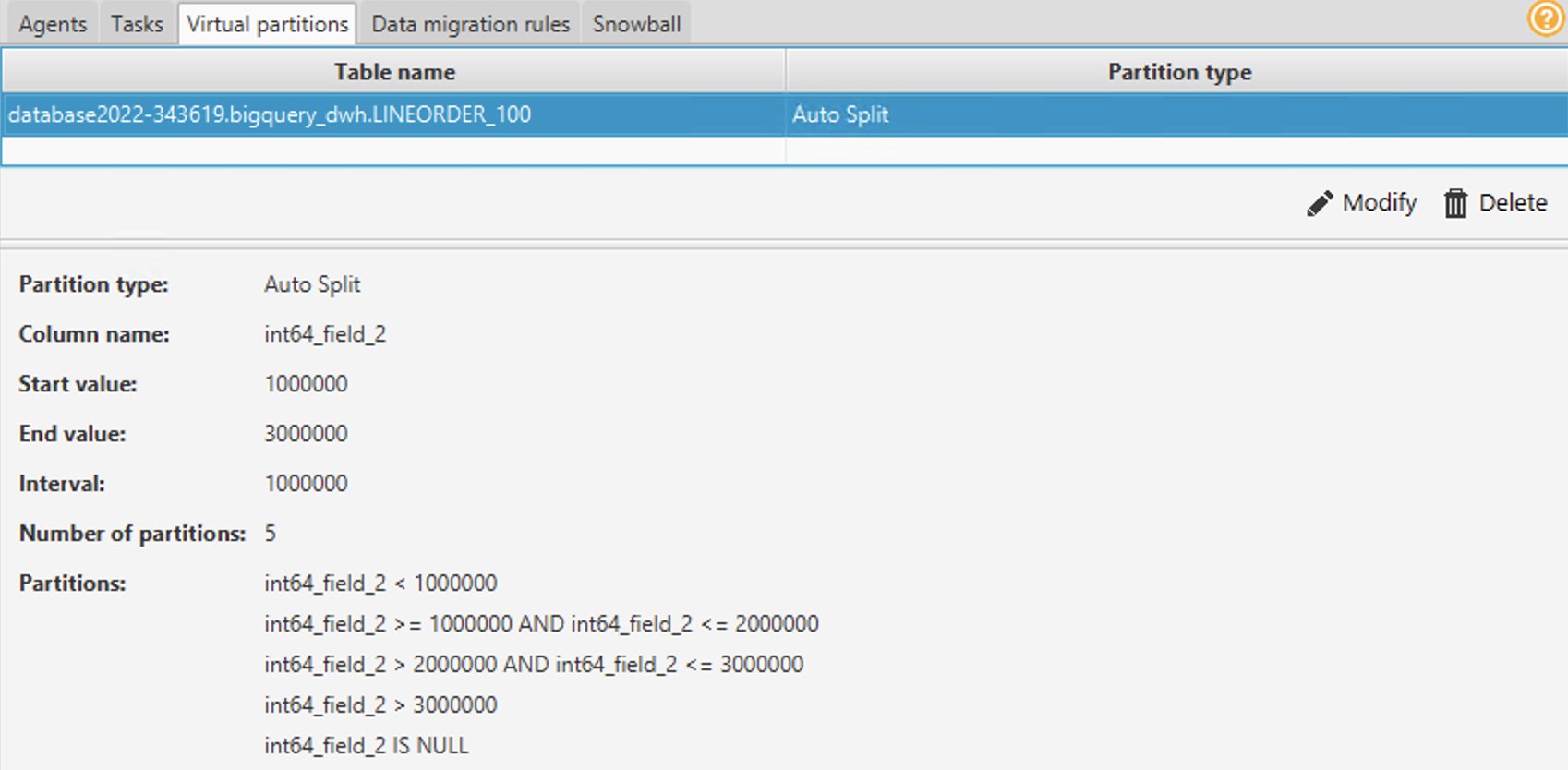
- Du kan bruke Liste-, Range- eller Auto Split-partisjoner. For å lære mer om virtuell partisjonering, se Bruk virtuell partisjonering i AWS SCT. I dette eksemplet bruker vi automatisk delt partisjonering, som genererer områdepartisjoner automatisk. Du vil spesifisere startverdien, sluttverdien og hvor stor partisjonen skal være. AWS SCT bestemmer partisjonene automatisk. For en demonstrasjon, på Lineorder-tabellen:
- Til Startverdi, skriv inn 1000000.
- Til Sluttverdi, skriv inn 3000000.
- Til Intervall, skriv inn 1000000 for å angi partisjonsstørrelse.
- Velg Ok.

Du kan se partisjonene som genereres automatisk under Virtuelle partisjoner fanen. I dette eksemplet opprettet AWS SCT automatisk følgende fem partisjoner for feltet:
-
- >=1000000 og <=2000000
- >2000000 og <=3000000
- > 3000000
- ER NULL
Opprett en lokal migreringsoppgave
For å migrere data fra BigQuery til Amazon Redshift, opprette, kjøre og overvåke den lokale migreringsoppgaven fra AWS SCT. Dette trinnet bruker datautvinningsagenten til å migrere data ved å opprette en oppgave.
Følg disse trinnene for å opprette en lokal migreringsoppgave:
- I AWS SCT, under skjemanavnet i venstre rute, høyreklikk på Standard bord.
- Velg Opprett lokal oppgave.

- Det er tre migreringsmoduser du kan velge mellom:
- Trekk ut kildedata og lagre dem på en lokal pc/virtuell maskin (VM) der agenten kjører.
- Trekk ut data og last det opp på en S3-bøtte.
- Velg Pakk ut last opp og kopier, som trekker ut data til en S3-bøtte og deretter kopierer til Amazon Redshift.

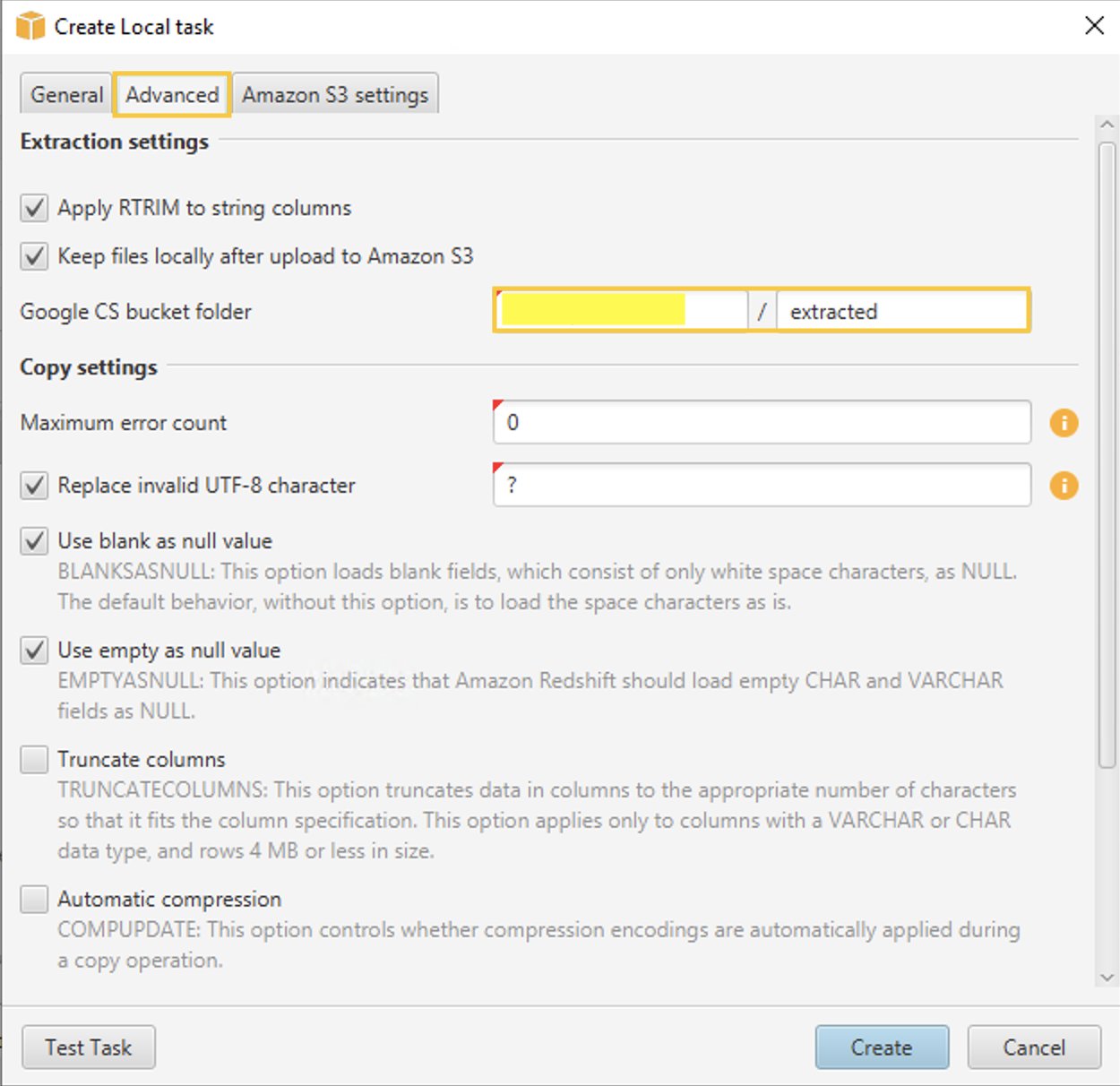
- på Avansert fanen, for Google CS bøttemappe skriv inn Google Cloud Storage-bøtten/mappen du opprettet tidligere i GCP Management Console. AWS SCT lagrer de utpakkede dataene på dette stedet.
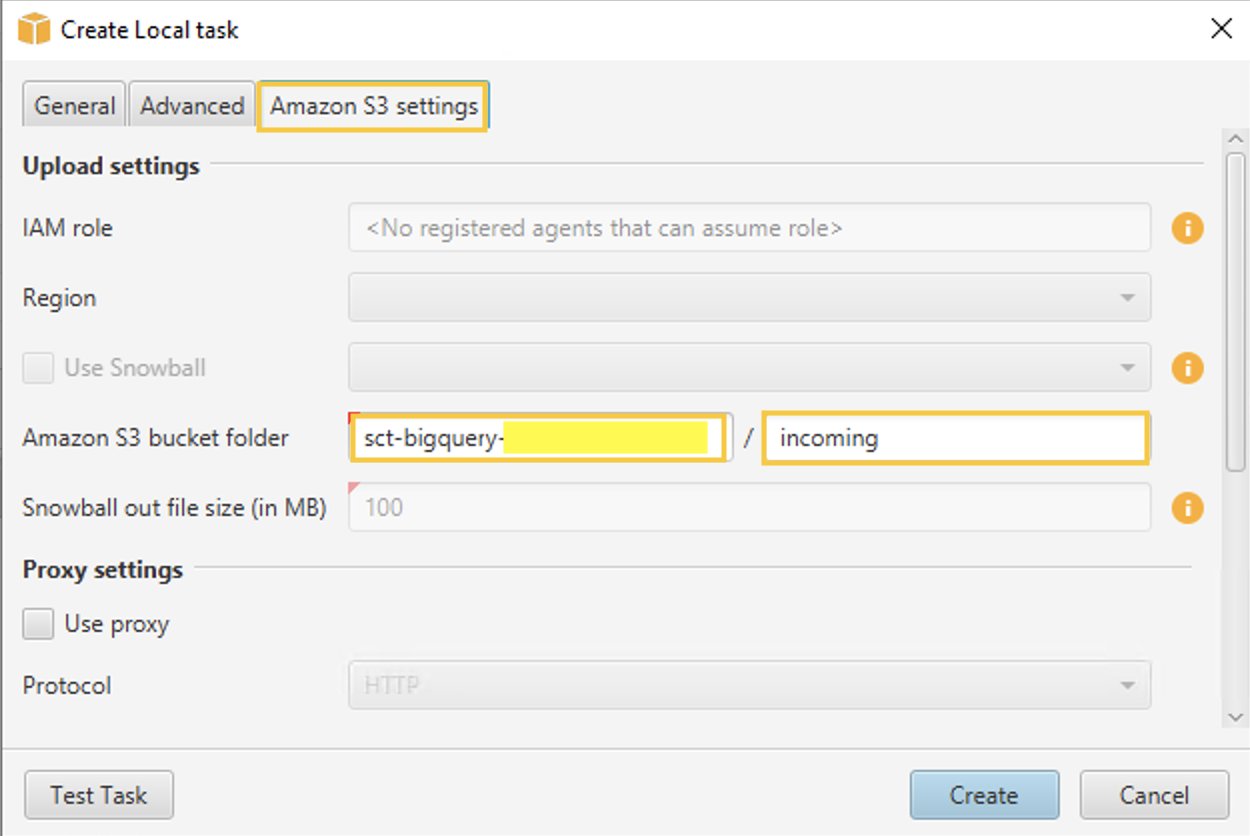
- på Amazon S3-innstillinger fanen, for Amazon S3 bøttemappe, oppgi bøtte- og mappenavnene til S3-bøtten du opprettet tidligere. AWS SCT-dataekstraksjonsagenten laster opp dataene til S3-bøtten/mappen før den kopieres til Amazon Redshift.
- Velg Test oppgave.
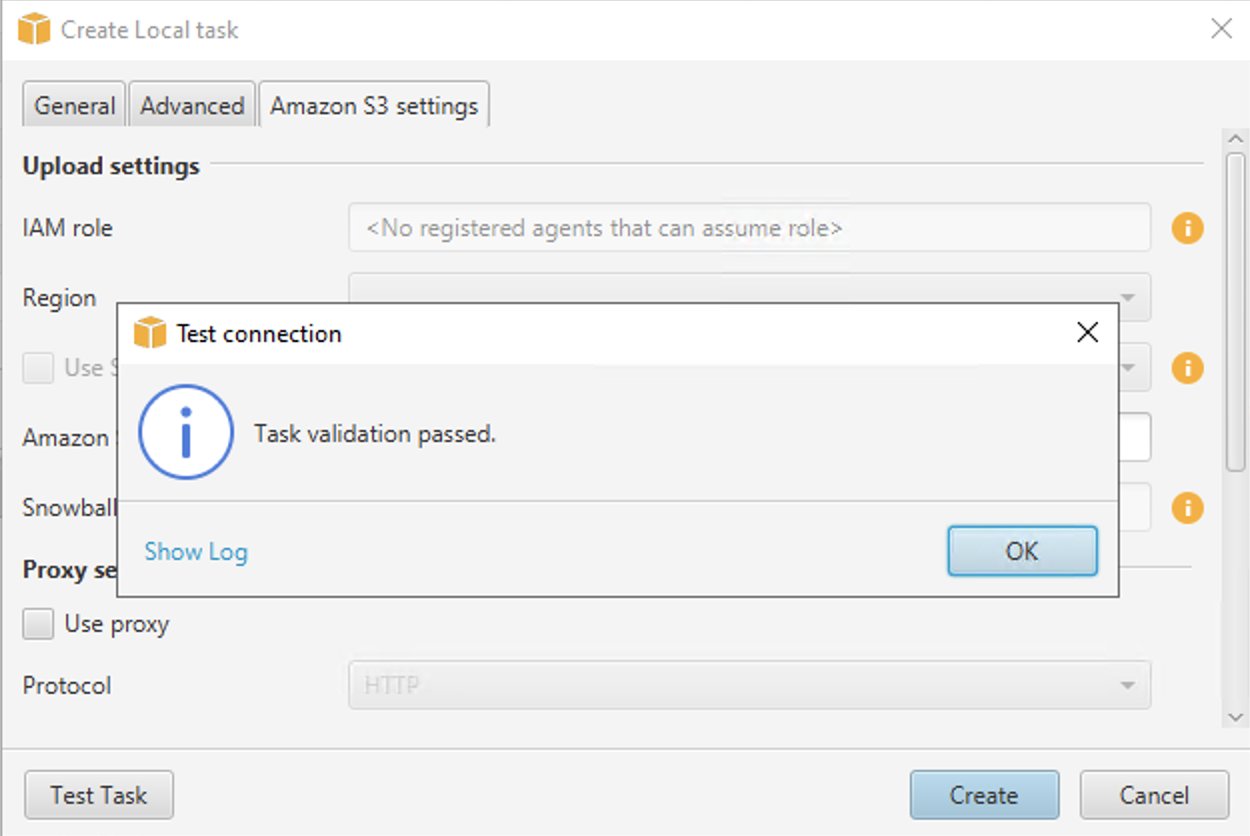
- Når oppgaven er vellykket validert, velg Opprett.
Start den lokale dataoverføringsoppgaven
For å starte oppgaven, velg Start knappen i Oppgaver fanen.

- Først trekker Data Extraction Agent ut data fra BigQuery inn i GCP-lagringsbøtten.
- Deretter laster agenten opp data til Amazon S3 og starter en kopikommando for å flytte dataene til Amazon Redshift.
- På dette tidspunktet har AWS SCT vellykket migrert data fra BigQuery-kildetabellen til Amazon Redshift-tabellen.
Se data i Amazon Redshift
Etter at datamigreringsoppgaven er utført, kan du koble til Amazon Redshift og validere dataene.
Følg disse trinnene for å validere dataene i Amazon Redshift:
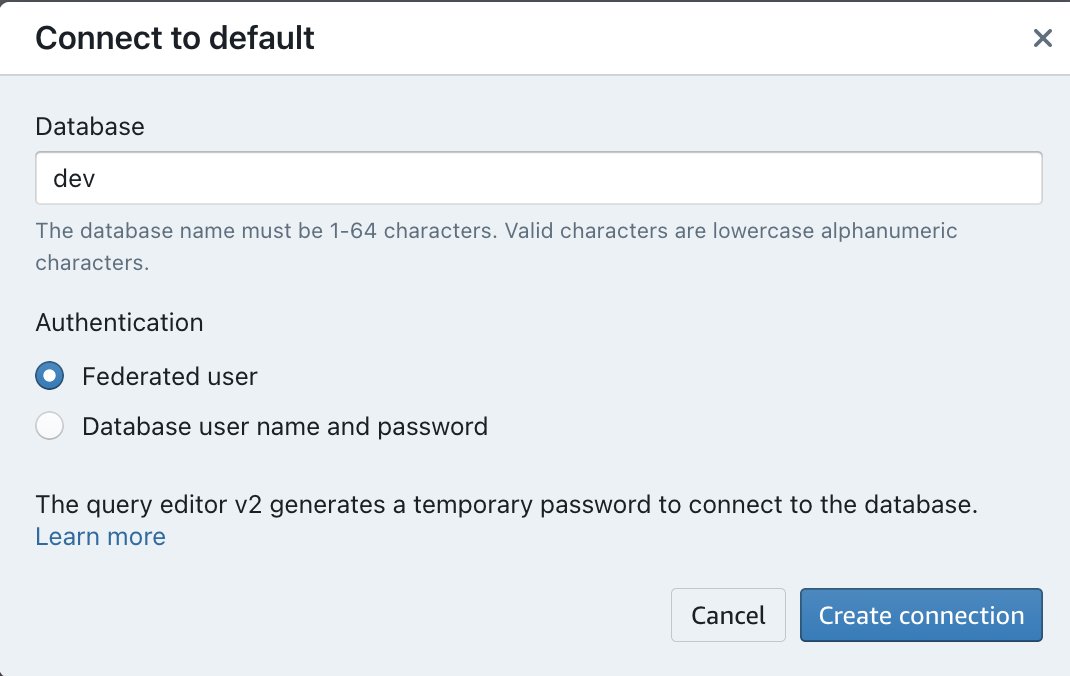
- Naviger til Amazon Redshift QueryEditor V2.
- Dobbeltklikk på Amazon Redshift Serverless-arbeidsgruppenavnet du opprettet.
- Velg Forent bruker alternativet under Autentisering.
- Velg Opprett tilkobling.
- Opprett en ny editor ved å velge + ikonet.
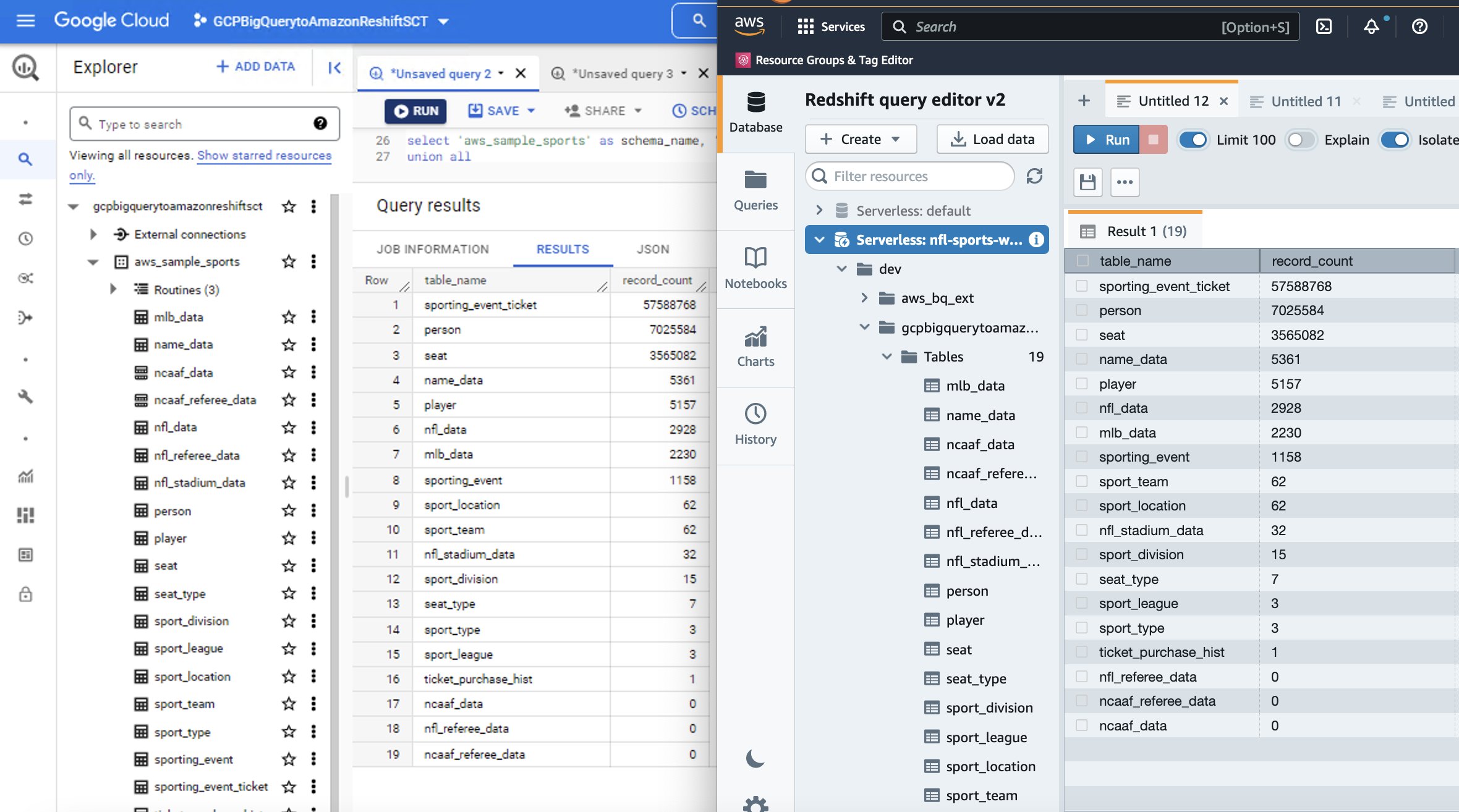
- I redigeringsprogrammet skriver du en spørring for å velge fra skjemanavnet og tabellnavnet/visningsnavnet du vil bekrefte. Utforsk dataene, kjør ad-hoc-spørringer og lag visualiseringer og diagrammer og visninger.

Følgende er en side-ved-side-sammenligning mellom kilden BigQuery og målet Amazon Redshift for sportsdatasettet som vi brukte i denne gjennomgangen.
Rydd opp i eventuelle AWS-ressurser du opprettet for denne øvelsen
Følg disse trinnene for å avslutte EC2-forekomsten:
- Naviger til Amazon EC2-konsoll.
- Velg i navigasjonsruten Forekomster.
- Merk av i avmerkingsboksen for EC2-forekomsten du opprettet.
- Velg Forekomsttilstand, Og deretter Avslutt forekomst.
- Velg Terminere når du blir bedt om bekreftelse.
Følg disse trinnene for å slette Amazon Redshift Serverless-arbeidsgruppe og navneområde
- naviger til Amazon Redshift Serverless Dashboard.
- Under Navneområder / arbeidsgrupper, velg arbeidsområdet du opprettet.
- Under handlinger, velg Slett arbeidsgruppe.
- Merk av i avmerkingsboksen Slett det tilknyttede navneområdet.
- Fjern merkingen Lag et endelig øyeblikksbilde.
- Enter slette i tekstboksen for bekreftelse av sletting og velg Slett.

Følg disse trinnene for å slette S3-bøtten
- naviger til Amazon S3-konsoll.
- Velg bøtten du har laget.
- Velg Delete.
- For å bekrefte sletting, skriv inn navnet på bøtten i tekstfeltet.
- Velg Slett bøtte.
konklusjonen
Migrering av et datavarehus kan være et utfordrende, komplekst og likevel givende prosjekt. AWS SCT reduserer kompleksiteten til datavarehusmigrering. Etter denne gjennomgangen kan du forstå hvordan en datamigreringsoppgave trekker ut, laster ned og deretter migrerer data fra BigQuery til Amazon Redshift. Løsningen som vi presenterte i dette innlegget utfører en engangsmigrering av databaseobjekter og data. Dataendringer som gjøres i BigQuery når migreringen pågår, gjenspeiles ikke i Amazon Redshift. Når datamigrering pågår, sett ETL-jobbene dine til BigQuery på vent eller spill ETL-ene på nytt ved å peke på Amazon Redshift etter migreringen. Vurder å bruke beste praksis for AWS SCT.
AWS SCT har noen begrensninger når du bruker BigQuery som kilde. AWS SCT kan for eksempel ikke konvertere underspørringer i analytiske funksjoner, geografifunksjoner, statistiske aggregerte funksjoner og så videre. Finn hele listen over begrensninger i AWS SCT brukerveiledning. Vi planlegger å ta tak i disse begrensningene i fremtidige utgivelser. Til tross for disse begrensningene kan du bruke AWS SCT til automatisk å konvertere de fleste av BigQuery-koden og lagringsobjektene dine.
Last ned og installer AWS SCT, logg inn på AWS-konsoll, sjekk Amazon Redshift Serverless, og begynn å migrere!
Om forfatterne
 Cedrick Hoodye er en løsningsarkitekt med fokus på databasemigrering ved bruk av AWS Database Migration Service (DMS) og AWS Schema Conversion Tool (SCT) hos AWS. Han jobber med DB-migreringsrelaterte utfordringer. Han jobber tett med EdTech, Energy og ISV forretningskunder for å hjelpe dem å realisere det sanne potensialet til DMS-tjenester. Han har hjulpet med å migrere hundrevis av databaser til AWS-skyen ved hjelp av DMS og SCT.
Cedrick Hoodye er en løsningsarkitekt med fokus på databasemigrering ved bruk av AWS Database Migration Service (DMS) og AWS Schema Conversion Tool (SCT) hos AWS. Han jobber med DB-migreringsrelaterte utfordringer. Han jobber tett med EdTech, Energy og ISV forretningskunder for å hjelpe dem å realisere det sanne potensialet til DMS-tjenester. Han har hjulpet med å migrere hundrevis av databaser til AWS-skyen ved hjelp av DMS og SCT.
 Amit Arora er en løsningsarkitekt med fokus på database og analyse hos AWS. Han jobber med våre Financial Technology og Global Energy-kunder og AWS-sertifiserte partnere for å gi teknisk assistanse og designe kundeløsninger på skymigrasjonsprosjekter, og hjelpe kunder med å migrere og modernisere sine eksisterende databaser til AWS Cloud.
Amit Arora er en løsningsarkitekt med fokus på database og analyse hos AWS. Han jobber med våre Financial Technology og Global Energy-kunder og AWS-sertifiserte partnere for å gi teknisk assistanse og designe kundeløsninger på skymigrasjonsprosjekter, og hjelpe kunder med å migrere og modernisere sine eksisterende databaser til AWS Cloud.
 Jagadish Kumar er en Analytics Specialist Solution Architect hos AWS med fokus på Amazon Redshift. Han er dypt lidenskapelig opptatt av dataarkitektur og hjelper kunder med å bygge analyseløsninger i stor skala på AWS.
Jagadish Kumar er en Analytics Specialist Solution Architect hos AWS med fokus på Amazon Redshift. Han er dypt lidenskapelig opptatt av dataarkitektur og hjelper kunder med å bygge analyseløsninger i stor skala på AWS.
 Anusha Challa er en Senior Analytics Specialist Solution Architect hos AWS med fokus på Amazon Redshift. Hun har hjulpet mange kunder med å bygge store datavarehusløsninger i skyen og i lokaler. Anusha er lidenskapelig opptatt av dataanalyse og datavitenskap og gjør det mulig for kunder å oppnå suksess med sine store dataprosjekter.
Anusha Challa er en Senior Analytics Specialist Solution Architect hos AWS med fokus på Amazon Redshift. Hun har hjulpet mange kunder med å bygge store datavarehusløsninger i skyen og i lokaler. Anusha er lidenskapelig opptatt av dataanalyse og datavitenskap og gjør det mulig for kunder å oppnå suksess med sine store dataprosjekter.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/migrate-google-bigquery-to-amazon-redshift-using-aws-schema-conversion-tool-sct/
- 1
- 10
- 100
- 9
- a
- Om oss
- adgang
- Logg inn
- Oppnå
- Handling
- Handling
- handlinger
- Ytterligere
- adresse
- admin
- Etter
- Agent
- agenter
- Alle
- allerede
- Amazon
- analytisk
- Analytisk
- analytics
- og
- Søknad
- søknader
- Påfør
- arkitektur
- AREA
- evaluering
- Assistanse
- assosiert
- Autentisering
- auto
- automatisk
- AWS
- basen
- BAT
- før du
- nytte
- Bedre
- mellom
- Stor
- Blå
- Eske
- bygge
- virksomhet
- knapp
- Kan få
- kan ikke
- evner
- Kapasitet
- Sertifisert
- utfordringer
- utfordrende
- endring
- Endringer
- Topplisten
- sjekk
- Sjekk ut
- valg
- Velg
- velge
- valgt ut
- klart
- kunde
- tett
- Cloud
- sky lagring
- kode
- samling
- Kolonne
- kolonner
- Kommunikasjon
- sammenligning
- kompatibel
- fullføre
- komplekse
- kompleksitet
- Beregn
- datamaskin
- datamaskiner
- Konfigurasjon
- Bekrefte
- Koble
- tilkobling
- Tilkoblinger
- Tilkobling
- Vurder
- konsistent
- Konsoll
- inneholder
- kontroller
- Konvertering
- konverteringer
- konvertere
- konvertert
- kopiering
- Kostnad
- kostnadseffektiv
- skape
- opprettet
- skaper
- Opprette
- kreditt
- kunde
- Kundeløsninger
- Kunder
- dato
- Data Analytics
- datavitenskap
- datadeling
- Database
- databaser
- datasett
- Avgjør
- Misligholde
- Etterspørsel
- utplassere
- beskrive
- beskrevet
- utforming
- desktop
- Til tross for
- detaljert
- bestemmes
- Dialog
- forskjellig
- skjermer
- distribusjon
- ikke
- nedlasting
- nedlastinger
- sjåfør
- drivere
- under
- hver enkelt
- Tidligere
- lett-å-bruke
- redaktør
- innsats
- innebygd
- muliggjøre
- muliggjør
- muliggjør
- kryptert
- kryptering
- ende til ende
- Endpoint
- energi
- Enter
- kom inn
- Miljø
- Eter (ETH)
- evaluere
- eksempel
- Utfører
- eksisterende
- utforske
- utvendig
- ekstra
- trekke ut
- ekstrakter
- kjent
- FAST
- raskere
- Noen få
- felt
- filet
- Filer
- slutt~~POS=TRUNC
- Endelig
- finansiell
- finansiell teknologi
- Finn
- brannmur
- Først
- fleksibilitet
- Fokus
- fokuserte
- følge
- etter
- følger
- format
- Gratis
- fra
- fullt
- funksjoner
- Dess
- framtid
- generere
- generert
- genererer
- geografi
- få
- Global
- Google Cloud
- Grønn
- håndtere
- maskinvare
- hjelpe
- hjulpet
- hjelpe
- hjelper
- her.
- Høy
- striper
- svært
- hold
- Hjemprodukt
- vert
- TIMER
- hus
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- ICON
- identifisere
- Identitet
- iverksette
- in
- Øke
- indikerer
- individuelt
- informasjon
- inngang
- innsikt
- installere
- installere
- f.eks
- instruksjoner
- integrert
- Integrerer
- samhandle
- forstyrrende
- intervensjon
- utstedelse
- IT
- varer
- Jobb
- Jobb
- JSON
- nøkkel
- Type
- stor
- storskala
- siste
- lansere
- lanseringer
- lag
- LÆRE
- Lar
- Nivå
- begrensninger
- linux
- Liste
- oppført
- Lytting
- laste
- lokal
- plassering
- maskin
- laget
- Hoved
- Flertall
- gjøre
- GJØR AT
- administrer
- ledelse
- leder
- administrerende
- håndbok
- manuelt
- mange
- meningsfylt
- medium
- møter
- Meny
- metoder
- Microsoft
- Microsoft Windows
- kunne
- migrere
- migrasjon
- ML
- modeller
- Moderne
- modern
- Overvåke
- mer
- mest
- flytte
- msi
- flere
- navn
- navn
- navngiving
- Naviger
- Navigasjon
- Trenger
- Ny
- neste
- bemerkelsesverdig
- Antall
- objekt
- gjenstander
- Tilbud
- ONE
- åpner
- drift
- operativsystem
- Optimalisere
- Annen
- ellers
- pakke
- brød
- panel
- Parallel
- partnere
- bestått
- lidenskapelig
- Passord
- banen
- Betale
- Topp
- utføre
- ytelse
- utfører
- fly
- plato
- Platon Data Intelligence
- PlatonData
- Point
- mulig
- Post
- potensiell
- praksis
- Forutsigbar
- Spådommer
- forutsetninger
- presentert
- tidligere
- privat
- prosedyrer
- prosess
- Produksjon
- program
- Progress
- prosjekt
- prosjekter
- gi
- gir
- sette
- spørsmål
- raskt
- område
- realisere
- anbefaler
- anbefalinger
- anbefales
- rekord
- Rød
- reduserer
- reflektert
- region
- registrere
- i slekt
- Utgivelser
- forblir
- gjenta
- erstatte
- erstattet
- replikert
- rapporterer
- Rapporter
- representerer
- forespørsler
- krever
- påkrevd
- spenstig
- Ressurser
- givende
- Rich
- Høyreklikk
- Rolle
- roller
- RAD
- regler
- Kjør
- samme
- skalerbar
- Skala
- vekter
- skalering
- skanne
- Vitenskap
- forskere
- skript
- sømløst
- sekunder
- Seksjon
- sektor
- sikre
- sikkerhet
- velge
- sensitive
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- sett
- innstilling
- innstillinger
- flere
- delt
- deling
- bør
- Vis
- Viser
- undertegne
- Enkelt
- enkelt
- Størrelse
- Snapshot
- So
- løsning
- Solutions
- noen
- kilde
- spesialist
- fart
- utgifter
- splittet
- Sports
- SSL
- iscenesettelse
- Begynn
- Start
- starter
- uttalelser
- statistisk
- statistikk
- status
- Trinn
- Steps
- Stopp
- lagring
- oppbevare
- lagret
- butikker
- suksess
- vellykket
- slik
- Super
- Bytte om
- system
- bord
- Ta
- tar
- Target
- Oppgave
- Teknisk
- Teknologi
- terminal
- De
- Kilden
- deres
- tredjeparts
- tre
- tid
- ganger
- til
- toleranse
- verktøy
- verktøy
- tradisjonelle
- Tog
- Transform
- sant
- Stol
- etter
- underliggende
- forstå
- unik
- bruk
- bruke
- Bruker
- Brukere
- VALIDERE
- validert
- Verdifull
- verdi
- Verdier
- leverandør
- leverandører
- verifisere
- versjon
- Se
- visninger
- virtuelle
- walkthrough
- advarsel
- web
- Hva
- hvilken
- mens
- bredere
- vil
- vinduer
- innenfor
- uten
- arbeidsgruppe
- arbeid
- virker
- arbeidsstasjon
- ville
- skrive
- skrevet
- Din
- zephyrnet