
Når AI migrerer fra skyen til Edge, ser vi at teknologien blir brukt i et stadig voksende utvalg brukstilfeller – alt fra avviksdeteksjon til applikasjoner inkludert smart shopping, overvåking, robotikk og fabrikkautomatisering. Derfor er det ingen løsning som passer alle. Men med den raske veksten av kameraaktiverte enheter, har AI blitt mest brukt for å analysere sanntids videodata for å automatisere videoovervåking for å øke sikkerheten, forbedre driftseffektiviteten og gi bedre kundeopplevelser, og til slutt oppnå et konkurransefortrinn i sine bransjer . For bedre å støtte videoanalyse, må du forstå strategiene for å optimalisere systemytelsen i edge AI-distribusjoner.
- Velge datamotorer i riktig størrelse for å møte eller overgå de nødvendige ytelsesnivåene. For en AI-applikasjon må disse beregningsmotorene utføre funksjonene til hele synsrørledningen (dvs. videofor- og etterbehandling, inferencing av nevrale nettverk).
En dedikert AI-akselerator, enten den er diskret eller integrert i en SoC (i motsetning til å kjøre AI-inferencing på en CPU eller GPU) kan være nødvendig.
- Forstå forskjellen mellom gjennomstrømning og latens; hvorved gjennomstrømning er hastigheten som data kan behandles i et system og latens måler databehandlingsforsinkelsen gjennom systemet og er ofte assosiert med sanntidsrespons. For eksempel kan et system generere bildedata med 100 bilder per sekund (gjennomstrømming), men det tar 100 ms (latency) for et bilde å gå gjennom systemet.
- Vurderer muligheten til enkelt å skalere AI-ytelse i fremtiden for å imøtekomme økende behov, endrede krav og utviklende teknologier (f.eks. mer avanserte AI-modeller for økt funksjonalitet og nøyaktighet). Du kan oppnå ytelsesskalering ved å bruke AI-akseleratorer i modulformat eller med ekstra AI-akseleratorbrikker.
De faktiske ytelseskravene er applikasjonsavhengige. Vanligvis kan man forvente at for videoanalyse må systemet behandle datastrømmer som kommer inn fra kameraer med 30-60 bilder per sekund og med en oppløsning på 1080p eller 4k. Et AI-aktivert kamera ville behandle en enkelt strøm; et kantapparat vil behandle flere strømmer parallelt. I begge tilfeller må edge AI-systemet støtte forbehandlingsfunksjonene for å transformere kameraets sensordata til et format som samsvarer med inngangskravene til AI-inferensdelen (Figur 1).
Forbehandlingsfunksjoner tar inn rådata og utfører oppgaver som å endre størrelse, normalisering og konvertering av fargerom, før inndata mates inn i modellen som kjører på AI-akseleratoren. Forbehandling kan bruke effektive bildebehandlingsbiblioteker som OpenCV for å redusere forbehandlingstiden. Etterbehandling innebærer å analysere resultatet av slutningen. Den bruker oppgaver som ikke-maksimal undertrykkelse (NMS tolker utdataene fra de fleste objektdeteksjonsmodeller) og bildevisning for å generere handlingsvennlig innsikt, for eksempel avgrensende bokser, klasseetiketter eller konfidenspoeng.

Figur 1. For AI-modellslutning utføres pre- og etterbehandlingsfunksjonene vanligvis på en applikasjonsprosessor.
AI-modellslutningen kan ha den ekstra utfordringen med å behandle flere nevrale nettverksmodeller per ramme, avhengig av applikasjonens muligheter. Datasynsapplikasjoner involverer vanligvis flere AI-oppgaver som krever en pipeline av flere modeller. Videre er den ene modellens utgang ofte den neste modellens input. Med andre ord, modeller i en applikasjon er ofte avhengige av hverandre og må kjøres sekvensielt. Det nøyaktige settet med modeller som skal kjøres er kanskje ikke statisk og kan variere dynamisk, selv på en ramme for ramme.
Utfordringen med å kjøre flere modeller dynamisk krever en ekstern AI-akselerator med dedikert og tilstrekkelig stort minne til å lagre modellene. Ofte er den integrerte AI-akseleratoren inne i en SoC ikke i stand til å håndtere flermodellarbeidsbelastningen på grunn av begrensninger pålagt av delt minnedelsystem og andre ressurser i SoC.
For eksempel er bevegelsesprediksjonsbasert objektsporing avhengig av kontinuerlige deteksjoner for å bestemme en vektor som brukes til å identifisere det sporede objektet i en fremtidig posisjon. Effektiviteten til denne tilnærmingen er begrenset fordi den mangler ekte reidentifikasjonsevne. Med bevegelsesprediksjon kan et objekts spor gå tapt på grunn av tapte deteksjoner, okklusjoner, eller at objektet forlater synsfeltet, til og med et øyeblikk. Når du er tapt, er det ingen måte å knytte objektets spor på nytt. Å legge til reidentifikasjon løser denne begrensningen, men krever innbygging av et visuelt utseende (dvs. et bildefingeravtrykk). Innebygging av utseende krever et andre nettverk for å generere en funksjonsvektor ved å behandle bildet inne i avgrensningsboksen til objektet som er oppdaget av det første nettverket. Denne innebyggingen kan brukes til å reidentifisere objektet igjen, uavhengig av tid eller rom. Siden innebygginger må genereres for hvert objekt som oppdages i synsfeltet, øker behandlingskravene etter hvert som scenen blir travlere. Objektsporing med reidentifikasjon krever nøye vurdering mellom å utføre deteksjon med høy nøyaktighet / høy oppløsning / høy bildefrekvens og å reservere tilstrekkelig overhead for skalerbarhet for innebygging. En måte å løse behandlingskravet på er å bruke en dedikert AI-akselerator. Som nevnt tidligere, kan SoCs AI-motor lide av mangelen på delte minneressurser. Modelloptimalisering kan også brukes til å senke behandlingskravet, men det kan påvirke ytelsen og/eller nøyaktigheten.
I et smart kamera eller edge-apparat henter den integrerte SoC (dvs. vertsprosessor) videorammene og utfører forbehandlingstrinnene vi beskrev tidligere. Disse funksjonene kan utføres med SoCs CPU-kjerner eller GPU (hvis en er tilgjengelig), men de kan også utføres av dedikerte maskinvareakseleratorer i SoC (f.eks. bildesignalprosessor). Etter at disse forbehandlingstrinnene er fullført, kan AI-akseleratoren som er integrert i SoC-en få direkte tilgang til denne kvantiserte inngangen fra systemminnet, eller i tilfelle av en diskret AI-akselerator, blir inngangen levert for slutning, typisk over USB- eller PCIe-grensesnitt.
En integrert SoC kan inneholde en rekke beregningsenheter, inkludert CPUer, GPUer, AI-akselerator, vision-prosessorer, videokodere/dekodere, bildesignalprosessor (ISP) og mer. Disse beregningsenhetene deler alle den samme minnebussen og har følgelig tilgang til det samme minnet. Videre kan CPU og GPU også måtte spille en rolle i slutningen, og disse enhetene vil være opptatt med å kjøre andre oppgaver i et distribuert system. Dette er hva vi mener med overhead på systemnivå (figur 2).
Mange utviklere evaluerer feilaktig ytelsen til den innebygde AI-akseleratoren i SoC uten å vurdere effekten av systemnivå overhead på total ytelse. Som et eksempel, vurder å kjøre en YOLO-referanse på en 50 TOPS AI-akselerator integrert i en SoC, som kan oppnå et benchmark-resultat på 100 slutninger/sekund (IPS). Men i et distribuert system med alle de andre beregningsenhetene aktive, kan disse 50 TOPS reduseres til noe sånt som 12 TOPS, og den totale ytelsen ville bare gi 25 IPS, forutsatt en sjenerøs 25% utnyttelsesfaktor. Systemoverhead er alltid en faktor hvis plattformen kontinuerlig behandler videostrømmer. Alternativt, med en diskret AI-akselerator (f.eks. Kinara Ara-1, Hailo-8, Intel Myriad X), kan utnyttelsen på systemnivå være større enn 90 % fordi når verts-SoC starter slutningsfunksjonen og overfører AI-modellens input data, kjører akseleratoren autonomt ved å bruke sitt dedikerte minne for å få tilgang til modellvekter og parametere.
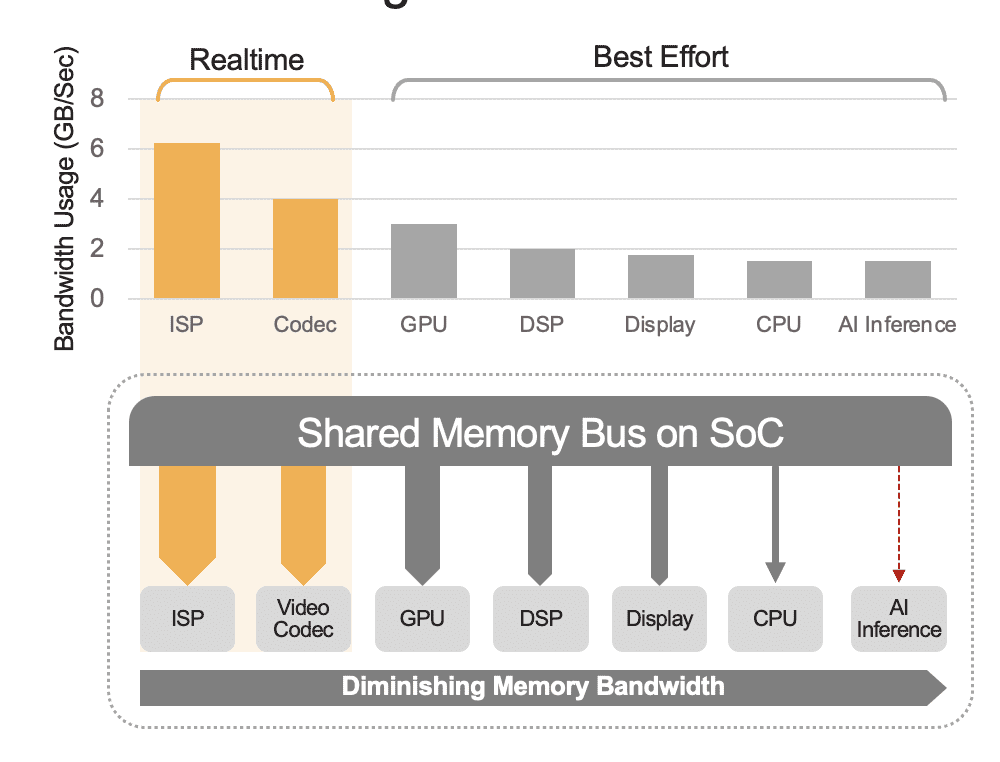
Figur 2. Den delte minnebussen vil styre ytelsen på systemnivå, vist her med estimerte verdier. Reelle verdier vil variere basert på applikasjonsbruksmodellen din og SoCs dataenhetskonfigurasjon.
Inntil dette punktet har vi diskutert AI-ytelse når det gjelder bilder per sekund og TOPS. Men lav ventetid er et annet viktig krav for å levere et systems sanntidsrespons. For eksempel, i spill, er lav latenstid avgjørende for en sømløs og responsiv spillopplevelse, spesielt i bevegelseskontrollerte spill og virtuell virkelighet (VR)-systemer. I autonome kjøresystemer er lav ventetid avgjørende for gjenkjenning av gjenstander i sanntid, fotgjengergjenkjenning, kjørefeltgjenkjenning og trafikkskiltgjenkjenning for å unngå å kompromittere sikkerheten. Autonome kjøresystemer krever vanligvis ende-til-ende-forsinkelse på mindre enn 150 ms fra deteksjon til den faktiske handlingen. Tilsvarende i produksjon er lav latens avgjørende for sanntidsdefektdeteksjon, anomaligjenkjenning og robotveiledning avhengig av videoanalyse med lav latens for å sikre effektiv drift og minimere produksjonsstans.
Generelt er det tre komponenter av latens i en videoanalyseapplikasjon (figur 3):
- Datafangstforsinkelse er tiden fra kamerasensoren fanger et videobilde til rammens tilgjengelighet for analysesystemet for behandling. Du kan optimalisere denne ventetiden ved å velge et kamera med en rask sensor og prosessor med lav latens, velge optimale bildefrekvenser og bruke effektive videokomprimeringsformater.
- Dataoverføringsforsinkelse er tiden for innfangede og komprimerte videodata å reise fra kameraet til kantene eller lokale servere. Dette inkluderer nettverksbehandlingsforsinkelser som oppstår ved hvert endepunkt.
- Databehandlingsforsinkelse refererer til tiden for kantenhetene til å utføre videobehandlingsoppgaver som rammedekompresjon og analytiske algoritmer (f.eks. bevegelsesprediksjonsbasert objektsporing, ansiktsgjenkjenning). Som påpekt tidligere, er behandlingsforsinkelse enda viktigere for applikasjoner som må kjøre flere AI-modeller for hver videoramme.
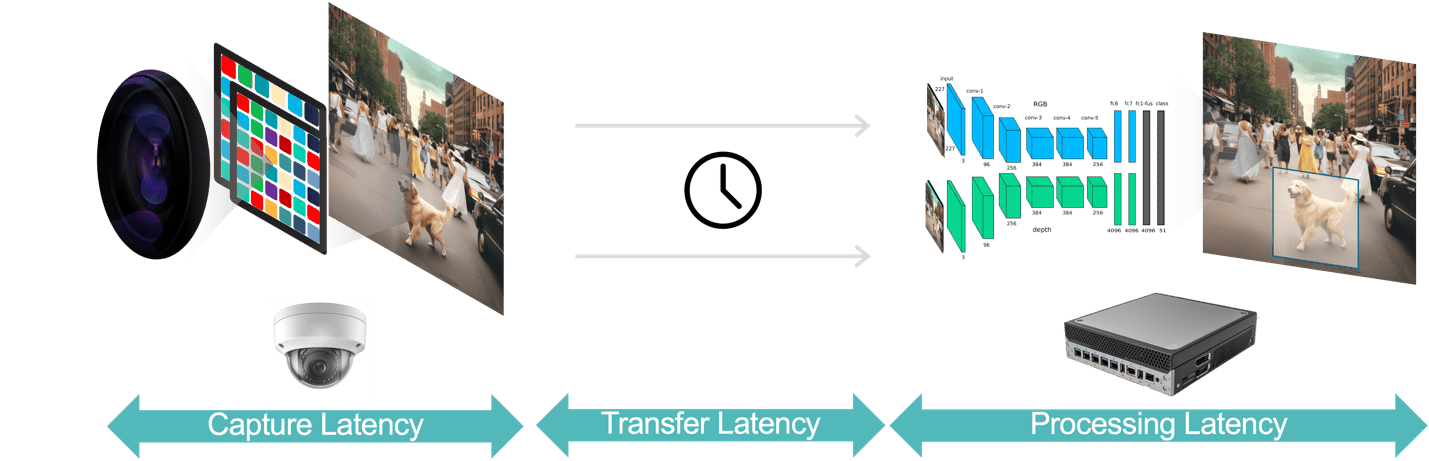
Figur 3. Videoanalysepipelinen består av datafangst, dataoverføring og databehandling.
Databehandlingsforsinkelsen kan optimaliseres ved hjelp av en AI-akselerator med en arkitektur designet for å minimere databevegelse over brikken og mellom databehandling og ulike nivåer i minnehierarkiet. Dessuten, for å forbedre latensen og effektiviteten på systemnivå, må arkitekturen støtte null (eller nesten null) byttetid mellom modeller, for bedre å støtte multi-modellapplikasjonene vi diskuterte tidligere. En annen faktor for både forbedret ytelse og latens er knyttet til algoritmisk fleksibilitet. Med andre ord, noen arkitekturer er designet for optimal oppførsel kun på spesifikke AI-modeller, men med det raskt skiftende AI-miljøet dukker det opp nye modeller for høyere ytelse og bedre nøyaktighet i det som virker som annenhver dag. Velg derfor en edge AI-prosessor uten praktiske begrensninger på modelltopologi, operatører og størrelse.
Det er mange faktorer som må vurderes for å maksimere ytelsen i en edge AI-enhet, inkludert ytelses- og latenskrav og systemoverhead. En vellykket strategi bør vurdere en ekstern AI-akselerator for å overvinne minne- og ytelsesbegrensninger i SoCs AI-motor.
CH Chee er en dyktig produktmarkedsførings- og ledelsesleder, Chee har lang erfaring med å markedsføre produkter og løsninger i halvlederindustrien, med fokus på visjonsbasert AI, tilkoblingsmuligheter og videogrensesnitt for flere markeder, inkludert bedrifter og forbrukere. Som gründer var Chee medgrunnlegger av to video-halvleder-oppstartsbedrifter som ble kjøpt opp av et offentlig halvlederselskap. Chee ledet produktmarkedsføringsteam og liker å jobbe med et lite team som fokuserer på å oppnå gode resultater.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- : har
- :er
- :ikke
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- evne
- akselerator
- akseleratorer
- adgang
- Tilgang
- imøtekomme
- utrette
- nøyaktighet
- oppnå
- ervervet
- kjøper
- tvers
- Handling
- aktiv
- faktiske
- legge
- Ytterligere
- vedtatt
- avansert
- Etter
- en gang til
- AI
- AI-motor
- AI-modeller
- algoritmisk
- algoritmer
- Alle
- også
- alltid
- an
- analyse
- analytics
- analyserer
- og
- anomali påvisning
- En annen
- Søknad
- søknader
- tilnærming
- arkitektur
- ER
- AS
- assosiert
- At
- automatisere
- Automatisering
- autonom
- autonomt
- tilgjengelighet
- tilgjengelig
- unngå
- basert
- basis
- BE
- fordi
- blir
- vært
- før du
- være
- benchmark
- Bedre
- mellom
- både
- Eske
- bokser
- innebygd
- buss
- opptatt
- men
- by
- rom
- kameraer
- CAN
- evner
- evne
- fangst
- fanget
- fange
- forsiktig
- saken
- saker
- utfordre
- endring
- chip
- chips
- velge
- klasse
- Cloud
- farge
- kommer
- Selskapet
- konkurranse
- Terminado
- komponenter
- kompromittere
- beregningen
- beregnings
- Beregn
- datamaskin
- Datamaskin syn
- Datasynsapplikasjoner
- selvtillit
- Konfigurasjon
- Tilkobling
- Følgelig
- Vurder
- hensyn
- ansett
- vurderer
- består
- begrensninger
- forbruker
- inneholde
- inneholdt
- kontinuerlig
- kontinuerlig
- Konvertering
- kunne
- prosessor
- kritisk
- kunde
- dato
- databehandling
- dag
- dedikert
- forsinkelse
- forsinkelser
- leverer
- levert
- avhengig
- avhengig
- utplassert
- distribusjoner
- beskrevet
- designet
- oppdaget
- Gjenkjenning
- Bestem
- utviklere
- Enheter
- forskjell
- direkte
- diskutert
- Vise
- nedetid
- kjøring
- to
- dynamisk
- e
- hver enkelt
- Tidligere
- lett
- Edge
- effekt
- effektivitet
- effektivitet
- effektivitet
- effektiv
- enten
- embedding
- slutt
- ende til ende
- Motor
- Motorer
- forbedre
- sikre
- Enterprise
- Hele
- Gründer
- Miljø
- avgjørende
- anslått
- evaluere
- Selv
- Hver
- utvikling
- eksempel
- stige
- henrette
- henrettet
- utøvende
- forvente
- erfaring
- Erfaringer
- omfattende
- Omfattende erfaring
- utvendig
- Face
- ansiktsgjenkjenning
- faktor
- faktorer
- fabrikk
- FAST
- Trekk
- fôring
- felt
- Figur
- fingeravtrykk
- Først
- fleksibilitet
- fokuserer
- fokusering
- Til
- format
- RAMME
- fra
- funksjon
- funksjonalitet
- funksjoner
- Dess
- framtid
- få
- Games
- gaming
- spillopplevelse
- general
- generere
- generert
- sjenerøs
- Go
- GPU
- GPU
- flott
- større
- Økende
- Vekst
- veiledning
- maskinvare
- Ha
- derav
- her.
- hierarki
- Høy
- høyere
- vert
- HTTPS
- i
- identifisere
- if
- bilde
- Påvirkning
- viktig
- pålagt
- forbedre
- forbedret
- in
- I andre
- inkluderer
- Inkludert
- Øke
- økt
- bransjer
- industri
- Starter
- inngang
- innsiden
- innsikt
- integrert
- Intel
- Interface
- grensesnitt
- inn
- involvere
- innebærer
- uansett
- ISP
- IT
- DET ER
- KDnuggets
- etiketter
- maling
- Lane
- stor
- Ventetid
- forlater
- Led
- mindre
- nivåer
- bibliotekene
- i likhet med
- begrensning
- begrensninger
- Begrenset
- lokal
- tapte
- Lav
- lavere
- administrer
- ledelse
- produksjon
- mange
- Marketing
- Markets
- Maksimer
- maksimere
- Kan..
- bety
- målinger
- Møt
- Minne
- nevnt
- kunne
- savnet
- modell
- modeller
- moduler
- overvåking
- mer
- mest
- bevegelse
- bevegelse
- flere
- må
- myriade
- Nær
- behov
- nettverk
- neural
- nevrale nettverket
- Ny
- neste
- Nei.
- objekt
- Objektdeteksjon
- forekomme
- of
- ofte
- on
- gang
- ONE
- bare
- OpenCV
- drift
- operasjonell
- operatører
- motsetning
- optimal
- optimalisering
- Optimalisere
- optimalisert
- optimalisere
- or
- Annen
- ut
- produksjon
- enn
- samlet
- Overcome
- Parallel
- parametere
- spesielt
- for
- utføre
- ytelse
- utført
- utfører
- utfører
- rørledning
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- Point
- posisjon
- post-prosessering
- Praktisk
- prediksjon
- prosess
- behandlet
- prosessering
- prosessor
- prosessorer
- Produkt
- Produksjon
- Produkter
- fremme
- gi
- offentlig
- område
- spenner
- rask
- raskt
- Sats
- priser
- Raw
- rådata
- ekte
- sanntids
- Reality
- anerkjennelse
- redusere
- refererer
- krever
- påkrevd
- behov
- Krav
- Krever
- oppløsning
- Ressurser
- responsive
- restriksjoner
- resultere
- Resultater
- robotikk
- Rolle
- Kjør
- rennende
- går
- Sikkerhet
- samme
- skalerbarhet
- Skala
- skala ai
- skalering
- scene
- score
- sømløs
- Sekund
- Seksjon
- se
- synes
- velge
- halvledere
- sett
- Del
- delt
- Shopping
- bør
- vist
- undertegne
- Signal
- på samme måte
- siden
- enkelt
- Størrelse
- liten
- Smart
- løsning
- Solutions
- LØSE
- løser
- noen
- noe
- Rom
- spesifikk
- start-ups
- Steps
- oppbevare
- strategier
- Strategi
- stream
- bekker
- vellykket
- slik
- tilstrekkelig
- støtte
- undertrykkelse
- overvåking
- system
- Systemer
- Ta
- tar
- oppgaver
- lag
- lag
- Technologies
- Teknologi
- vilkår
- enn
- Det
- De
- Fremtiden
- deres
- deretter
- Der.
- derfor
- Disse
- de
- denne
- De
- tre
- Gjennom
- gjennomstrømning
- tid
- ganger
- til
- Topper
- Totalt
- spor
- Sporing
- trafikk
- overføre
- overføringer
- Transform
- reiser
- sant
- to
- typisk
- Til syvende og sist
- ute av stand
- forstå
- enhet
- lomper
- bruk
- usb
- bruke
- brukt
- bruker
- ved hjelp av
- vanligvis
- utnytte
- Verdier
- variasjon
- ulike
- video
- Se
- virtuelle
- Virtuell virkelighet
- syn
- vital
- vr
- Vei..
- we
- var
- Hva
- om
- hvilken
- allment
- vil
- med
- uten
- ord
- arbeid
- ville
- X
- Utbytte
- Yolo
- du
- Din
- zephyrnet
- null







