By David Wendt og Gregory Kimball
Effektiv behandling av strengdata er avgjørende for mange datavitenskapelige applikasjoner. For å trekke ut verdifull informasjon fra strengdata, RAPIDS libcudf gir kraftige verktøy for å akselerere strengdatatransformasjoner. libcudf er et C++ GPU DataFrame-bibliotek som brukes til å laste, slå sammen, samle og filtrere data.
I datavitenskap representerer strengdata tale, tekst, genetiske sekvenser, logging og mange andre typer informasjon. Når du arbeider med strengdata for maskinlæring og funksjonsteknikk, må dataene ofte normaliseres og transformeres før de kan brukes på spesifikke brukstilfeller. libcudf tilbyr både generelle API-er så vel som verktøy på enhetssiden for å muliggjøre et bredt spekter av tilpassede strengoperasjoner.
Dette innlegget demonstrerer hvordan du dyktig transformerer strengkolonner med libcudfs generelle API. Du vil få ny kunnskap om hvordan du låser opp toppytelse ved å bruke tilpassede kjerner og libcudf-verktøy på enhetssiden. Dette innlegget leder deg også gjennom eksempler på hvordan du best administrerer GPU-minne og effektivt konstruerer libcudf-kolonner for å øke hastigheten på strengtransformasjonene dine.
libcudf lagrer strengdata i enhetsminnet ved hjelp av Pilformat, som representerer strengkolonner som to underordnede kolonner: chars and offsets (Figur 1).
De chars kolonnen inneholder strengdataene som UTF-8-kodede tegnbyte som er lagret sammenhengende i minnet.
De offsets kolonne inneholder en økende sekvens av heltall som er byteposisjoner som identifiserer starten på hver enkelt streng i tegndatamatrisen. Det siste forskyvningselementet er det totale antallet byte i tegnkolonnen. Dette betyr størrelsen på en individuell streng på rad i er definert som (offsets[i+1]-offsets[i]).
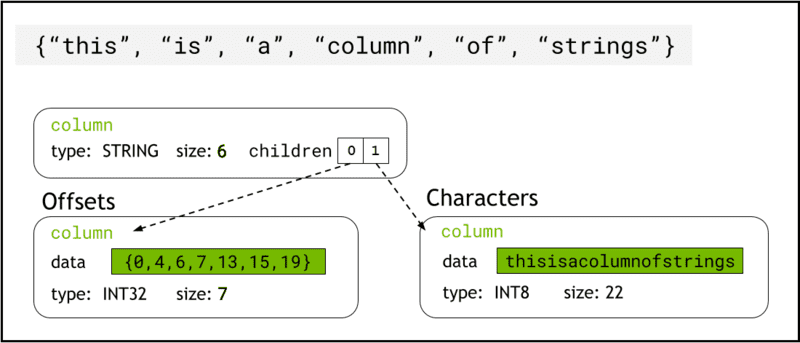 Figur 1. Skjematisk som viser hvordan pilformatet representerer strenger kolonner med
Figur 1. Skjematisk som viser hvordan pilformatet representerer strenger kolonner med chars og offsets underordnede kolonner
For å illustrere et eksempel på strengtransformasjon, bør du vurdere en funksjon som mottar to inndatastrengkolonner og produserer én redigert utdatastrengkolonne.
Inndataene har følgende form: en «navn»-kolonne som inneholder for- og etternavn atskilt med et mellomrom og en «synlighet»-kolonne som inneholder statusen «offentlig» eller «privat».
Vi foreslår "redact"-funksjonen som opererer på inngangsdataene for å produsere utdata som består av den første initialen til etternavnet etterfulgt av et mellomrom og hele fornavnet. Imidlertid, hvis den korresponderende synlighetskolonnen er "privat", bør utdatastrengen redigeres fullstendig som "X X."
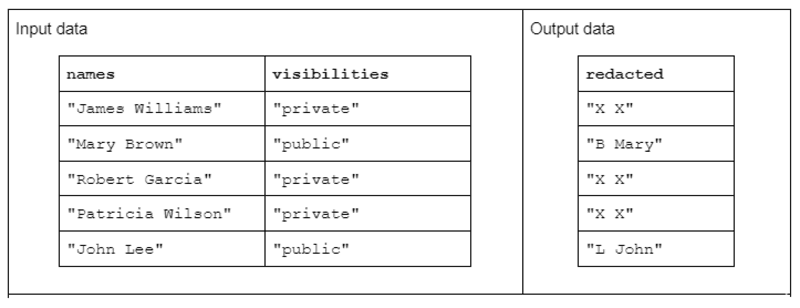 Tabell 1. Eksempel på en "redact"-strengtransformasjon som mottar navn- og synlighetsstrengkolonner som input og delvis eller fullstendig redigerte data som utdata
Tabell 1. Eksempel på en "redact"-strengtransformasjon som mottar navn- og synlighetsstrengkolonner som input og delvis eller fullstendig redigerte data som utdata
For det første kan strengtransformasjon oppnås ved å bruke libcudf strenger API. Den generelle API-en er et utmerket utgangspunkt og en god grunnlinje for å sammenligne ytelse.
API-funksjonene opererer på en hel strengkolonne, og starter minst én kjerne per funksjon og tildeler én tråd per streng. Hver tråd håndterer en enkelt rad med data parallelt over GPUen og sender ut en enkelt rad som en del av en ny utdatakolonne.
Følg disse trinnene for å fullføre redigeringseksempelfunksjonen ved å bruke generell API:
- Konverter "synlighet"-strengkolonnen til en boolsk kolonne ved å bruke
contains - Opprett en ny strengkolonne fra navnekolonnen ved å kopiere "XX" når den tilsvarende radoppføringen i den boolske kolonnen er "false"
- Del opp den "redigerte" kolonnen i kolonnene for fornavn og etternavn
- Del det første tegnet i etternavnene som initialene til etternavnet
- Bygg utdatakolonnen ved å sette sammen den siste initialkolonnen og fornavnskolonnen med mellomrom (" ")-skilletegn.
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Denne tilnærmingen tar omtrent 3.5 ms på en A6000 med 600 XNUMX rader med data. Dette eksemplet bruker contains, copy_if_else, split, slice_strings og concatenate for å utføre en tilpasset strengtransformasjon. En profileringsanalyse med Nsight-systemer viser at split funksjonen tar lengst tid, etterfulgt av slice_strings og concatenate.
Figur 2 viser profileringsdata fra Nsight Systems i redact-eksemplet, som viser ende-til-ende strengbehandling med opptil ~600 millioner elementer per sekund. Regionene tilsvarer NVTX-områder knyttet til hver funksjon. Lyseblå områder tilsvarer perioder der CUDA-kjerner kjører.
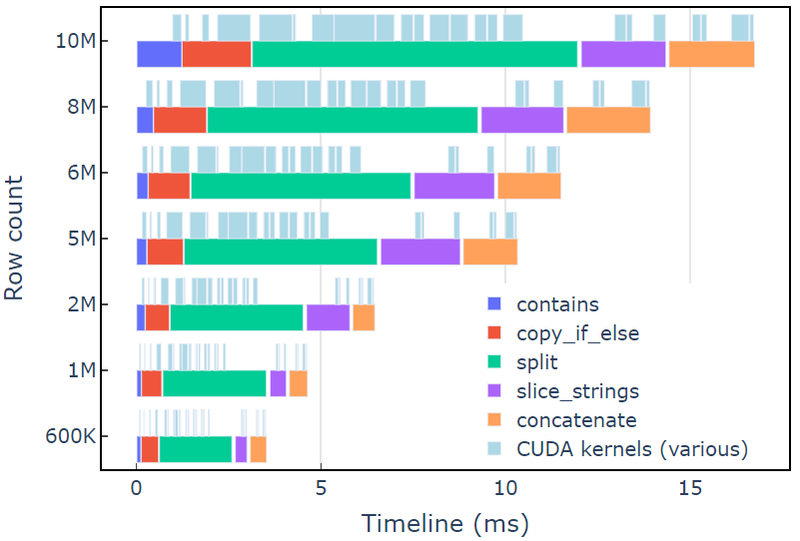 Figur 2. Profileringsdata fra Nsight Systems i redakteksemplet
Figur 2. Profileringsdata fra Nsight Systems i redakteksemplet
Libcudf strings API er et raskt og effektivt verktøysett for å transformere strenger, men noen ganger må ytelseskritiske funksjoner kjøre enda raskere. En nøkkelkilde til ekstra arbeid i libcudf strings API er opprettelsen av minst én ny strengkolonne i globalt enhetsminne for hvert API-kall, noe som åpner for muligheten til å kombinere flere API-kall til en tilpasset kjerne.
Ytelsesbegrensninger i kjernemalloc-kall
Først skal vi bygge en tilpasset kjerne for å implementere redigeringseksemplet. Når vi designer denne kjernen, må vi huske på at libcudf-strengkolonner er uforanderlige.
Stringskolonner kan ikke endres på plass fordi tegnbytene lagres sammenhengende, og eventuelle endringer i lengden på en streng vil ugyldiggjøre forskyvningsdataene. Derfor redact_kernel tilpasset kjerne genererer en ny strengkolonne ved å bruke en libcudf-kolonnefabrikk for å bygge begge offsets og chars underordnede kolonner.
I denne første tilnærmingen opprettes utdatastrengen for hver rad i dynamisk enhetsminne ved å bruke et malloc-kall inne i kjernen. Den tilpassede kjerneutgangen er en vektor av enhetspekere til hver radutgang, og denne vektoren fungerer som input til en strengkolonnefabrikk.
Den tilpassede kjernen godtar en cudf::column_device_view for å få tilgang til strengkolonnedataene og bruker element metode for å returnere en cudf::string_view som representerer strengdataene ved den angitte radindeksen. Kjerneutgangen er en vektor av typen cudf::string_view som holder pekere til enhetsminnet som inneholder utdatastrengen og størrelsen på den strengen i byte.
De cudf::string_view klassen ligner std::string_view-klassen, men er implementert spesifikt for libcudf og pakker en fast lengde av tegndata i enhetsminnet kodet som UTF-8. Den har mange av de samme funksjonene (find og substr funksjoner, for eksempel) og begrensninger (ingen nullterminator) som std motpart. EN cudf::string_view representerer en tegnsekvens som er lagret i enhetsminnet, så vi kan bruke den her til å registrere malloc'd-minnet for en utdatavektor.
Malloc kjerne
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Dette kan virke som en rimelig tilnærming, inntil kjerneytelsen er målt. Denne tilnærmingen tar omtrent 108 ms på en A6000 med 600 30 rader med data – mer enn XNUMX ganger langsommere enn løsningen gitt ovenfor ved bruk av libcudf-strenger API.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Den viktigste flaskehalsen er malloc/free kaller inne i de to kjernene her. CUDA dynamisk enhetsminne krever malloc/free kaller inn en kjerne som skal synkroniseres, noe som får parallell kjøring til å degenerere til sekvensiell kjøring.
Forhåndstildeling av arbeidsminne for å eliminere flaskehalser
Eliminer malloc/free flaskehals ved å erstatte malloc/free kaller inn kjernen med forhåndstildelt arbeidsminne før kjernen startes.
For redact-eksemplet bør utdatastørrelsen til hver streng i dette eksemplet ikke være større enn selve inngangsstrengen, siden logikken bare fjerner tegn. Derfor kan en enkelt enhetsminnebuffer brukes med samme størrelse som inngangsbufferen. Bruk inndataforskyvningene for å finne hver radposisjon.
Å få tilgang til strengkolonnens forskyvninger innebærer å pakke inn cudf::column_view med en cudf::strings_column_view og kaller det offsets_begin metode. Størrelsen på chars underordnet kolonne kan også nås ved å bruke chars_size metode. Så en rmm::device_uvector er forhåndstildelt før du kaller opp kjernen for å lagre tegnutdataene.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Forhåndstildelt kjerne
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Kjernen sender ut en vektor på cudf::string_view gjenstander som sendes til cudf::make_strings_column fabrikkfunksjon. Den andre parameteren til denne funksjonen brukes til å identifisere null-oppføringer i utdatakolonnen. Eksemplene i dette innlegget har ikke null-oppføringer, så en nullptr plassholder cudf::string_view{nullptr,0} benyttes.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Denne tilnærmingen tar omtrent 1.1 ms på en A6000 med 600 2 rader med data og slår derfor grunnlinjen med mer enn XNUMXx. Den omtrentlige fordelingen er vist nedenfor:
redact_kernel 66us make_strings_column 400us
Den resterende tiden brukes i cudaMalloc, cudaFree, cudaMemcpy, som er typisk for overhead for håndtering av midlertidige tilfeller av rmm::device_uvector. Denne metoden fungerer bra hvis alle utdatastrengene er garantert like store eller mindre som inngangsstrengene.
Totalt sett er bytte til en bulk arbeidsminnetildeling med RAPIDS RMM en betydelig forbedring og en god løsning for en tilpasset strengfunksjon.
Optimalisering av kolonneoppretting for raskere beregningstider
Er det en måte å forbedre dette enda mer på? Flaskehalsen er nå cudf::make_strings_column fabrikkfunksjon som bygger de to strengene kolonnekomponentene, offsets og chars, fra vektoren til cudf::string_view objekter.
I libcudf er mange fabrikkfunksjoner inkludert for å bygge strengsøyler. Fabrikkfunksjonen brukt i de foregående eksemplene tar en cudf::device_span of cudf::string_view objekter og konstruerer deretter kolonnen ved å utføre en gather på de underliggende tegndataene for å bygge forskyvninger og underordnede tegnkolonner. EN rmm::device_uvector er automatisk konverterbar til en cudf::device_span uten å kopiere noen data.
Imidlertid, hvis vektoren av tegn og vektoren av forskyvninger bygges direkte, kan en annen fabrikkfunksjon brukes, som ganske enkelt oppretter strengkolonnen uten å kreve innsamling for å kopiere dataene.
De sizes_kernel gjør en første pass over inngangsdataene for å beregne den nøyaktige utdatastørrelsen for hver utgangsrad:
Optimalisert kjerne: Del 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Utdatastørrelsene konverteres deretter til forskyvninger ved å utføre en på plass exclusive_scan. Merk at offsets vektor ble opprettet med names.size()+1 elementer. Den siste oppføringen vil være det totale antallet byte (alle størrelsene lagt sammen), mens den første oppføringen vil være 0. Begge disse håndteres av exclusive_scan anrop. Størrelsen på chars kolonnen hentes fra den siste oppføringen av offsets kolonne for å bygge tegnvektoren.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
De redact_kernel logikken er fortsatt veldig den samme bortsett fra at den aksepterer utdataene d_offsets vektor for å løse hver rads utdataplassering:
Optimalisert kjerne: Del 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
Størrelsen på utgangen d_chars kolonnen hentes fra den siste oppføringen av d_offsets kolonne for å tildele tegnvektoren. Kjernen starter med den forhåndsberegnede forskyvningsvektoren og returnerer den fylte tegnvektoren. Til slutt oppretter kolonnefabrikken libcudf-strenger utdatastrengene.
Dette cudf::make_strings_column fabrikkfunksjonen bygger strengkolonnen uten å lage en kopi av dataene. De offsets data og chars data er allerede i riktig, forventet format, og denne fabrikken flytter ganske enkelt dataene fra hver vektor og lager kolonnestrukturen rundt den. Når den er fullført, rmm::device_uvectors forum offsets og chars er tomme, og dataene deres er flyttet til utdatakolonnen.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Denne tilnærmingen tar omtrent 300 oss (0.3 ms) på en A6000 med 600 2 rader med data og forbedrer seg mer enn XNUMX ganger i forhold til den forrige tilnærmingen. Du vil kanskje legge merke til det sizes_kernel og redact_kernel deler mye av den samme logikken: én gang for å måle størrelsen på utdataene og så igjen for å fylle ut utdataene.
Fra et kodekvalitetsperspektiv er det fordelaktig å omstrukturere transformasjonen som en enhetsfunksjon som kalles av både størrelsene og redigere kjerner. Fra et ytelsesperspektiv kan du bli overrasket over å se at beregningskostnaden for transformasjonen blir betalt to ganger.
Fordelene for minneadministrasjon og mer effektiv kolonneoppretting oppveier ofte beregningskostnadene ved å utføre transformasjonen to ganger.
Tabell 2 viser beregningstiden, kjernetellingen og bytene behandlet for de fire løsningene som er diskutert i dette innlegget. "Total kjernelanseringer" gjenspeiler det totale antallet lanserte kjerner, inkludert både data- og hjelpekjerner. "Totalt behandlet byte" er den kumulative DRAM-lese-pluss-skrivegjennomstrømningen og "minimum bearbeidede byte" er et gjennomsnitt på 37.9 byte per rad for våre testinnganger og -utganger. Det ideelle "minnebåndbreddebegrenset"-dekselet antar 768 GB/s båndbredde, den teoretiske toppgjennomstrømningen til A6000.
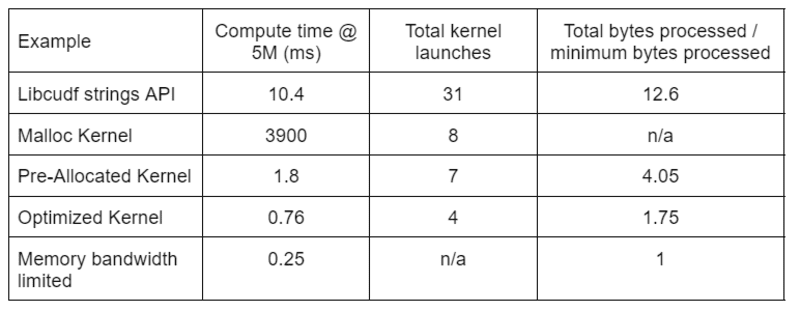 Tabell 2. Beregningstid, kjernetall og byte behandlet for de fire løsningene som er diskutert i dette innlegget
Tabell 2. Beregningstid, kjernetall og byte behandlet for de fire løsningene som er diskutert i dette innlegget
"Optimalisert kjerne" gir den høyeste gjennomstrømningen på grunn av redusert antall kjernelanseringer og færre totale byte som behandles. Med effektive tilpassede kjerner faller den totale kjernelanseringen fra 31 til 4, og de totale bytene behandlet fra 12.6x til 1.75x av input pluss output-størrelsen.
Som et resultat oppnår den tilpassede kjernen >10 ganger høyere gjennomstrømning enn strenger-API-en for generelle formål for redigeringstransformasjonen.
Bassengets minneressurs i Rapids Memory Manager (RMM) er et annet verktøy du kan bruke for å øke ytelsen. Eksemplene ovenfor bruker standard "CUDA-minneressurs" for å tildele og frigjøre globalt enhetsminne. Tiden som trengs for å tildele arbeidsminne gir imidlertid betydelig latens mellom trinnene i strengtransformasjonene. "Pool-minneressursen" i RMM reduserer ventetiden ved å allokere en stor pool med minne på forhånd, og tildele underallokeringer etter behov under behandlingen.
Med CUDA-minneressursen viser "Optimized Kernel" en 10x-15x speedup som begynner å falle av ved høyere radantall på grunn av den økende tildelingsstørrelsen (Figur 3). Bruk av pool-minneressursen reduserer denne effekten og opprettholder 15x-25x speedups i forhold til libcudf strings API-tilnærmingen.
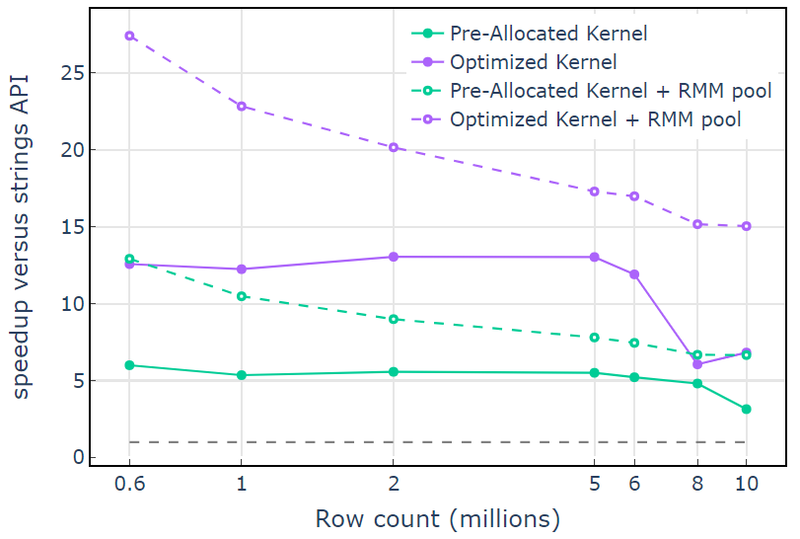 Figur 3. Speedup fra de tilpassede kjernene "Pre-Allocated Kernel" og "Optimized Kernel" med standard CUDA-minneressursen (solid) og pool-minneressursen (stiplet), kontra libcudf-streng-APIen som bruker standard CUDA-minneressursen
Figur 3. Speedup fra de tilpassede kjernene "Pre-Allocated Kernel" og "Optimized Kernel" med standard CUDA-minneressursen (solid) og pool-minneressursen (stiplet), kontra libcudf-streng-APIen som bruker standard CUDA-minneressursen
Med bassengminneressursen demonstreres en ende-til-ende minnegjennomstrømning som nærmer seg den teoretiske grensen for en to-pass algoritme. "Optimalisert kjerne" når 320-340 GB/s gjennomstrømning, målt ved hjelp av størrelsen på inngangene pluss størrelsen på utgangene og beregningstiden (Figur 4).
To-pass tilnærmingen måler først størrelsen på utgangselementene, tildeler minne og setter deretter minnet med utgangene. Gitt en to-pass prosesseringsalgoritme, utfører implementeringen i "Optimized Kernel" nær grensen for minnebåndbredde. "Ende-til-ende minnegjennomstrømning" er definert som inngang pluss utdatastørrelse i GB delt på beregningstiden. *RTX A6000 minnebåndbredde (768 GB/s).
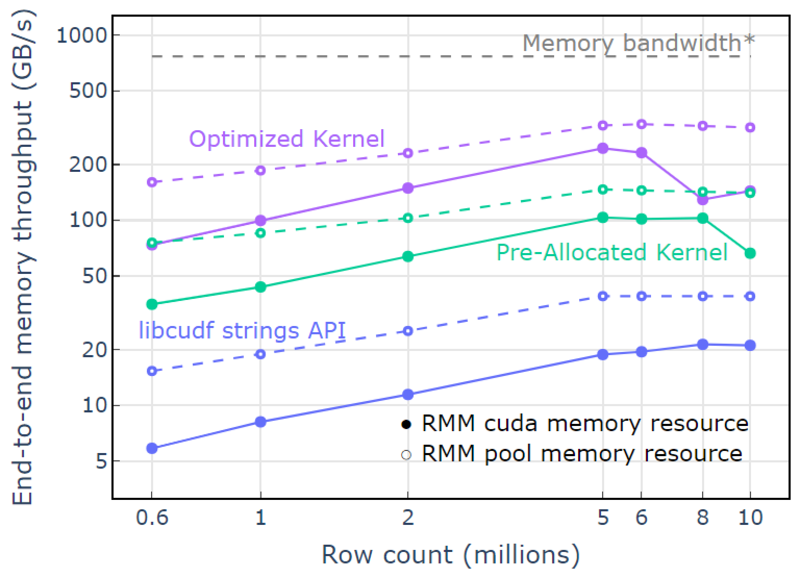 Figur 4. Minnegjennomstrømning for «Optimized Kernel», «Pre-Allocated Kernel» og «libcudf strings API» som en funksjon av antall input/output rader
Figur 4. Minnegjennomstrømning for «Optimized Kernel», «Pre-Allocated Kernel» og «libcudf strings API» som en funksjon av antall input/output rader
Dette innlegget demonstrerer to tilnærminger for å skrive effektive strengdatatransformasjoner i libcudf. libcudf generell API er rask og enkel for utviklere, og gir god ytelse. libcudf tilbyr også verktøy på enhetssiden designet for bruk med tilpassede kjerner, i dette eksemplet låser det opp >10 ganger raskere ytelse.
Bruk kunnskapen din
For å komme i gang med RAPIDS cuDF, besøk rapidsai/cudf GitHub repo. Hvis du ennå ikke har prøvd cuDF og libcudf for arbeidsbelastningene dine for strengbehandling, oppfordrer vi deg til å teste den siste utgivelsen. Dockerbeholdere er gitt for utgivelser så vel som nattlige bygg. Conda-pakker er også tilgjengelige for å gjøre testing og distribusjon enklere. Hvis du allerede bruker cuDF, oppfordrer vi deg til å kjøre det nye eksemplet med strengtransformasjon ved å besøke rapidsai/cudf/tree/HEAD/cpp/examples/strings på GitHub.
David Wendt er en senior systemprogramvareingeniør hos NVIDIA som utvikler C++/CUDA-kode for RAPIDS. David har en mastergrad i elektroteknikk fra Johns Hopkins University.
Gregory Kimball er en programvareingeniørsjef i NVIDIA som jobber med RAPIDS-teamet. Gregory leder utviklingen for libcudf, CUDA/C++-biblioteket for kolonnedatabehandling som driver RAPIDS cuDF. Gregory har en doktorgrad i anvendt fysikk fra California Institute of Technology.
original. Ompostet med tillatelse.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Om oss
- ovenfor
- akselerer
- godtar
- adgang
- aksesseres
- oppnådd
- tvers
- la til
- Legger
- algoritme
- Alle
- Tildeler
- allokering
- allerede
- beløp
- analyse
- og
- En annen
- Apache
- api
- APIer
- søknader
- anvendt
- tilnærming
- tilnærminger
- nærmer seg
- rundt
- Array
- assosiert
- auto
- automatisk
- tilgjengelig
- gjennomsnittlig
- Båndbredde
- Baseline
- fordi
- før du
- være
- under
- gunstig
- Fordeler
- BEST
- mellom
- Blå
- Breakdown
- buffer
- bygge
- Bygning
- bygger
- bygget
- C + +
- california
- ring
- som heter
- ringer
- Samtaler
- kan ikke
- saken
- saker
- forårsaker
- Endringer
- karakter
- tegn
- barn
- klasse
- Lukke
- kode
- Kolonne
- kolonner
- kombinere
- sammenligne
- fullføre
- Terminado
- komponenter
- beregningen
- Beregn
- Vurder
- Består
- konstruere
- inneholder
- konvertere
- konvertert
- kopiering
- Tilsvarende
- Kostnad
- skape
- opprettet
- skaper
- skaperverket
- skikk
- dato
- databehandling
- datavitenskap
- David
- Misligholde
- Grad
- leverer
- demonstrert
- distribusjon
- designet
- utforme
- utviklere
- utvikle
- Utvikling
- enhet
- forskjellig
- direkte
- diskutert
- Divided
- Docker
- Drop
- under
- dynamisk
- hver enkelt
- enklere
- effekt
- effektiv
- effektivt
- elektroteknikk
- elementer
- eliminere
- muliggjøre
- oppmuntre
- ende til ende
- ingeniør
- Ingeniørarbeid
- Hele
- entry
- Eter (ETH)
- Selv
- alt
- eksempel
- eksempler
- utmerket
- Unntatt
- gjennomføring
- forventet
- utvendig
- ekstra
- trekke ut
- fabrikk
- FAST
- raskere
- Trekk
- Egenskaper
- Figur
- filtrering
- slutt~~POS=TRUNC
- Endelig
- Først
- fikset
- følge
- fulgt
- etter
- skjema
- format
- Gratis
- ofte
- fra
- foran
- fullt
- funksjon
- funksjoner
- videre
- Gevinst
- general
- genererer
- få
- GitHub
- gitt
- Global
- god
- GPU
- garantert
- Håndterer
- å ha
- her.
- høyere
- høyest
- holder
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- ideell
- identifisering
- uforanderlige
- iverksette
- gjennomføring
- implementert
- forbedre
- forbedring
- forbedrer
- in
- inkludert
- Inkludert
- Øke
- økende
- indeks
- individuelt
- informasjon
- innledende
- inngang
- Institute
- intern
- IT
- selv
- Johns Hopkins
- Johns Hopkins University
- sammenføyning
- KDnuggets
- Hold
- nøkkel
- kunnskap
- Etiketten
- stor
- større
- Siste
- Ventetid
- siste
- siste utgivelsen
- lansert
- lanseringer
- lansere
- Fører
- læring
- Lengde
- Bibliotek
- lett
- BEGRENSE
- begrensninger
- lasting
- plassering
- maskin
- maskinlæring
- Hoved
- opprettholder
- gjøre
- GJØR AT
- Making
- administrer
- ledelse
- leder
- administrerende
- mange
- Master
- Maste
- Match
- midler
- måle
- målinger
- Minne
- metode
- kunne
- millioner
- tankene
- mer
- mer effektivt
- trekk
- MS
- flere
- navn
- navn
- Trenger
- nødvendig
- Ny
- Antall
- Nvidia
- gjenstander
- offset
- ONE
- åpning
- betjene
- opererer
- Drift
- Opportunity
- Annen
- betalt
- Parallel
- parameter
- del
- bestått
- Topp
- ytelse
- utfører
- utfører
- perioder
- tillatelse
- perspektiv
- Fysikk
- Sted
- plato
- Platon Data Intelligence
- PlatonData
- i tillegg til
- Point
- basseng
- befolket
- posisjon
- stillinger
- Post
- kraftig
- krefter
- forrige
- prosessering
- produsere
- profilering
- foreslå
- forutsatt
- gir
- offentlig
- formål
- kvalitet
- område
- Når
- Lese
- rimelig
- mottar
- rekord
- Redusert
- reduserer
- Refaktor
- Gjenspeiler
- regioner
- slipp
- Utgivelser
- gjenværende
- representerer
- representerer
- ressurs
- resultere
- retur
- avkastning
- RAD
- Kjør
- rennende
- samme
- Vitenskap
- Sekund
- senior
- Sequence
- serverer
- sett
- Del
- bør
- vist
- Viser
- signifikant
- lignende
- ganske enkelt
- siden
- enkelt
- Størrelse
- størrelser
- mindre
- So
- Software
- Software Engineer
- software engineering
- solid
- løsning
- Solutions
- kilde
- Rom
- spesifikk
- spesielt
- spesifisert
- tale
- fart
- brukt
- splittet
- Begynn
- startet
- Start
- status
- Steps
- Still
- oppbevare
- lagret
- butikker
- rett fram
- stream
- struktur
- overrasket
- Systemer
- tar
- lag
- Teknologi
- midlertidig
- test
- Testing
- De
- deres
- teoretiske
- derfor
- Gjennom
- gjennomstrømning
- tid
- til
- sammen
- verktøy
- verktøykasse
- verktøy
- Totalt
- Transform
- Transformation
- transformasjoner
- forvandlet
- transformere
- tv
- typer
- typisk
- underliggende
- universitet
- låse opp
- opplåsing
- us
- bruke
- verktøy
- Verdifull
- Verdifull informasjon
- Versus
- synlighet
- synlig
- vital
- hvilken
- mens
- bred
- Bred rekkevidde
- vil
- innenfor
- uten
- Arbeid
- arbeid
- virker
- ville
- skrive
- skriving
- X
- Din
- zephyrnet










