Optical Character Recognition (OCR), metoden for å konvertere håndskrevne / trykte tekster til maskinkodet tekst, har alltid vært et stort forskningsområde innen datasyn på grunn av sine mange applikasjoner på tvers av forskjellige domener - Banker bruker OCR for å sammenligne utsagn; Regjeringer bruker OCR for samlinger av tilbakemeldinger fra undersøkelser.

På grunn av mangfoldet i håndskrift og trykte tekststiler, inkluderer nylige tilnærminger til OCR dyp læring for å få høyere nøyaktighet. Ettersom dyp læring krever store mengder data for modellopplæring, tar selskaper som Google en fordel med å produsere lovende resultater med sine OCR-tjenester.
Denne artikkelen dykker ned i detaljene i Google Vision OCR, inkludert en enkel opplæring i python, utvalget av applikasjoner, priser og andre alternativer.
- Hva er Google Cloud Vision OCR?
- En enkel opplæring
- Hvorfor OCR?
- Eksempel på brukstilfeller
- Priser
- Fremtredende funksjoner i Google Cloud Vision OCR
- Alternatives
- Vanlige problemer
Hva er Google Cloud Vision?

Google Cloud Vision OCR er en del av Google cloud vision API for å trekke ut tekst fra bilder. Spesielt er det to merknader som hjelper med karaktergjenkjenningen:
- Tekst_annotasjon: Den trekker ut og sender ut maskinkodede tekster fra hvilket som helst bilde (f.eks. Bilder av gatevisning eller landskap). Siden den opprinnelig ble designet for å være brukbar under forskjellige lyssituasjoner, er modellen på en eller annen måte mer robust når det gjelder å lese ord i forskjellige stiler, men bare på et mer sparsomt nivå. Den returnerte JSON-filen inkluderer hele strengene, samt de enkelte ordene og deres tilhørende avgrensningsbokser.
- Document_Text_Annotation: Dette er spesielt designet for tett presenterte tekstdokumenter (f.eks. Skannede bøker). Selv om den støtter lesing av mindre og mer konsentrerte tekster, er den mindre tilpassbar til naturen. Informasjon som avsnitt, blokker og pauser er inkludert i JSON-utdatafilen.
Ser du etter en OCR-løsning som overvinner manglene til Google Cloud Vision eller sone OCR? Gi nanonetter™ et spinn for høyere nøyaktighet, større fleksibilitet og bredere dokumenttyper!
En enkel opplæring
Den følgende delen introduserer en enkel opplæring i å komme i gang med Google Vision API, spesielt om hvordan du bruker den til Google Cloud Vision OCR-tjenesten.
Enkel oversikt
Ideen bak dette er veldig intuitiv og enkel.
1) Du sender i hovedsak et bilde (eksternt eller fra din lokale lagring) til Google Cloud Vision API.
2) Bildet behandles eksternt i Google Cloud og produserer de tilsvarende JSON-formatene med hensyn til funksjonen du ringte.
3) JSON-filen returneres som utdata etter at funksjonen er kalt.
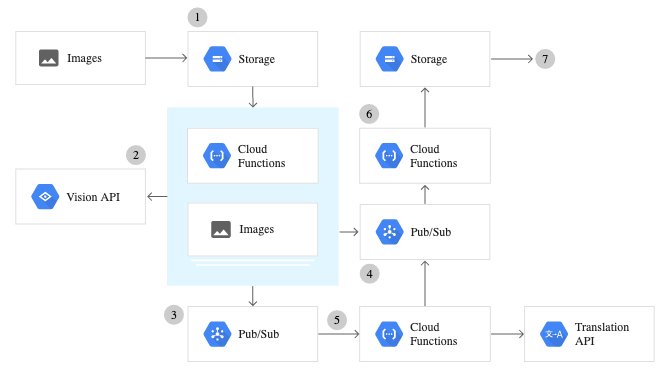
Sette opp Google Cloud Vision API
For å bruke tjenester levert av Google Vision API, må man konfigurere Google Cloud Console og utføre en serie trinn for autentisering. Følgende er en trinnvis oversikt over hvordan du konfigurerer hele Vision API-tjenesten.
- Opprett et prosjekt i Google Cloud Console - Et prosjekt må opprettes for å kunne begynne å bruke en hvilken som helst Vision-tjeneste. Prosjektet organiserer ressurser som samarbeidspartnere, API-er og prisinformasjon.
- Aktiver fakturering - For å aktivere visjonen API, må du først aktivere fakturering for prosjektet ditt. Prisdetaljene vil bli behandlet i senere seksjoner.
- Aktiver Vision API
- Opprett servicekonto - Opprett en tjenestekonto og lenke til prosjektet som er opprettet, og opprett deretter en tjenestekontonøkkel. Nøkkelen sendes ut og lastes ned som en JSON-fil til datamaskinen din.
- Sett opp miljøvariabel GOOGLE_APPLICATION_CREDENTIALS; For å sette opp denne miljøvariabelen, kjør denne på Mac/Linux eller Windows.
- Kodeblokker for Mac / Linux
- Kodeblokker for Windows
En mer detaljert prosedyre for de ovennevnte trinnene finner du i den offisielle dokumentasjonen gitt av Google Cloud herfra:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Enkel Google Vision OCR-funksjon i Python
Google Cloud Vision API fungerer med mange populære språk, alt fra Java, Node.js, Python, til Googles eget språk Go. For enkelhets skyld introduserer vi en enkel anropsmetode i Python.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) Med andre ord kaller metoden følgelig funksjonen tekst_annotasjon, trekk deretter ut svarene ytterligere og skriv ut informasjonen. document_text_annotation kan også kalles på samme måte for å hente tette tekster. Man kan også oppdage bilder eksternt ved å stille inn bildet via:
image.source.image_uri = urihvor uri er bildets uri.
Flere detaljer om kodene kan hentes her:
https://cloud.google.com/vision
Leter du etter en OCR-løsning som overvinner manglene ved Google Cloud Vision? Gi Nanonets™ et spinn for høyere nøyaktighet, større fleksibilitet og bredere dokumenttyper!
Tilbudt utgangsnivå
For å hjelpe deg med ytterligere dataanalyse av teksten, gir de to Google OCR-funksjonene forskjellige utgangsnivåer for brukere å bruke: for tekst_annotasjon, både hele strengene (hvis Google anser det som en setning eller setning) og de enkelte ordene i; til document_text_annotation, ettersom modellen er optimalisert for tett tekst, blir side, blokk, avsnitt, ord og pause tilbudt som en del av utdataene.
Hvor bra fungerer det skjønt?
Hvor robuste er modellene?
Som nevnt tidligere tilbyr Google to funksjoner for OCR i to forskjellige situasjoner. Følgende beskriver evnen til to funksjoner for å hente forskjellige typer data.
Trykte data
Den enkleste typen data å tolke er trykte tekstdata, dvs. datamaskinskrevet tekst som skrives ut og skannes. OCR kreves når vi bare har den trykte kopien av disse dataene i stedet for de originale maskinkodede tekstene. Siden de fleste av disse tekstene er stramme og pakket på sider, document_text_annotation ville være et bedre alternativ.
Håndskrevne data
Innholdet kan inneholde håndskrevet tekst, og stiler av håndskrevne data kan variere drastisk. Ikke desto mindre gir Google Vision OCR anstendig nøyaktighet så lenge de håndskrevne notatene ikke er for rotete. Avhengig av hvor pakket mediet av de håndskrevne dataene blir presentert, bruker vi en av de to funksjonene fra sak til sak.
Rotated / In-The-Wild Data
Når bildene eller de skannede bildene presenteres i uortodokse eller ujusterte vinkler, anser vi dem som in-the-wild data. Tekster kan potensielt være vanskeligere å oppdage i utgangspunktet, og derfor bruker vi vanligvis tekst_annotasjon funksjon som ble designet for å behandle in-the-wild data i utgangspunktet. Basert på noen eksperimenter med å gå gjennom vertikale tekster og veiskilt fanget i forskjellige vinkler, viser vi at Google Vision OCR faktisk utfører anstendig på data fra forskjellige miljøer.
Hvorfor OCR?
Mange av dataene vi har i dag er i ustrukturert format. For eksempel, gitt et bilde, et skannet dokument eller et fotografi, mens mennesker raskt kan gjenkjenne tekstene og ytterligere tolke betydninger, er all tekstdata bare piksler med farger, noe som ikke gir maskiner noen reell betydning.

Når selskaper eller store selskaper har å gjøre med store mengder papirarbeid, vil det store datavolumet gjøre det umulig for noen klassifisering eller databehandling å gjøres med menneskelig innsats - dette er når maskinkodet tekst blir nyttig.
Etter OCR-konvertering kan informasjon deretter analyseres med flere forskjellige metoder, avhengig av dataenes art:
- For numeriske data kan statistiske metoder brukes direkte for å analysere for eventuelle sammenhenger. Vi kunne også ta i bruk tradisjonelle maskinlæringsmetoder (f.eks. KNN, K-Means, Lineær regresjon) eller dyplæringsmetoder for å lage prediktive modeller for regresjon og / eller klassifisering.
- For tekstdata kan det være behov for flere stadier av behandlingen. Prosessen med å analysere og tolke tekstdata til meningsfull statistikk blir ofte referert til som NLP (Natural Language Processing). Spesielt kan vi trekke ut tall eller til og med semantikk / atmosfære basert på gitt innhold.
Alle disse analysene kan gjøre det mulig for selskaper, spesielt de med store mengder nye data hver dag, å lage robuste modeller og til og med automatisere mange prosesser og erstatte de tradisjonelle arbeidskrevende og feilfylte tilnærmingene. Følgende avsnitt graver inn i noen detaljerte eksempler på hvordan OCR kan brukes.
Leter du etter en OCR-løsning som overvinner manglene ved Google Cloud Vision? Gi Nanonets™ et spinn for høyere nøyaktighet, større fleksibilitet og bredere dokumenttyper!
Eksempel på brukstilfeller
Lisensskiltlesing

Kanskje en av de vanligste bruken av OCR i dag er applikasjonen i lisensplateavlesning. I utviklede land blir parkeringsplasser ofte ledsaget av lesemodeller for lisensplater for å bestemme inngangstid, utgangstid og til og med den nøyaktige parkerte plasseringen per bil. Noen parkeringsplasser er til og med koblet til det offentlige nettverket for å belaste parkeringsavgiftene direkte til familier - som alle lindrer overflødig menneskelig innsats.
Registreringsskilt-OCR-modeller kan også tas i bruk for deteksjoner i trafikkbrudd, noe som letter tiden for politiet å manuelt taste inn dataene til den krenkende bilen.
Mottak og fakturaskanning

Finansielle anslag og balansering av eiendeler og gjeld i selskaper er viktige aktiviteter for ethvert firma. Ettersom store selskaper kjøper store mengder fra flere sektorer gjennom hele året, må de omhyggelig samle inn og behandle alle fakturaer og kvitteringer når de oppretter regnskaper.
Ved hjelp av OCR kan vi lage automatiserte rørledninger som gjenkjenne en rekke fakturaformater og konverter dem til tall. Arbeidsinnsats er kun nødvendig for å sjekke, og de strukturerte dataene og tallene kan tillate selskapet å raskt balansere inn- og utstrømmer, lage økonomiske anslag, samt se opp for eventuelle ondsinnede manipulasjoner av selskapets økonomi.
Elektriske medisinske poster

Pasientens data er ofte spredt rundt i en region, et land eller til og med over land, avhengig av individers livsstil. På grunn av forskjellige stiler på klinikker og sykehus (store sykehus kan ha organisert databaser, mens leger i mindre klinikker bare kan skrive ned postene for hånd), kan pasientens alder (eldre pasienter settes inn i en bestemt database før renovering og innlemmelse av datamaskiner), og hvor enkeltpersoner befinner seg (folk kan flytte til en annen by eller til og med i utlandet), det kan faktisk være veldig vanskelig å beholde en universell medisin.
En godt trent OCR blir dermed nyttig når du overfører EMR fra ett sykehus til et annet, eller omformer håndskrevne data til maskintekst - som begge kan fremskynde prosessen med å forstå pasienters medisinske historie på en rask og kortfattet måte.
Skjemaer og undersøkelser

Organisasjoner (enten statlige eller ikke-statlige) kan ofte kreve tilbakemelding fra kunder eller borgere for å forbedre sine nåværende salgsfremmende planer og produkter. Siden skjemaer vanligvis skrives for hånd, ville det være potensielt vanskelig å utføre direkte statistisk analyse. Derfor kan prosessen med å konvertere ustrukturerte data og håndskrevne undersøkelser til numeriske figurer for å lette beregninger bli hjulpet og akselerert av OCR.
Leter du etter en OCR-løsning som overvinner manglene ved Google Cloud Vision? Gi Nanonets™ et spinn for høyere nøyaktighet, større fleksibilitet og bredere dokumenttyper!
Cloud Vision-priser
I følge Google nettsted, både tekst_annotasjon og document_text_annotation tilbys til samme prisnivå som følgende:
For hver måned gis de første 1000 enhetene gratis, med 1000-5000000 belastet $ 1.5 per 1000 enheter. Etter å ha truffet 5000000-merket, synker prisen til $ 0.6 per 1000 enheter (Hvert bilde sendt via Google Vision API regnes som en enhet).
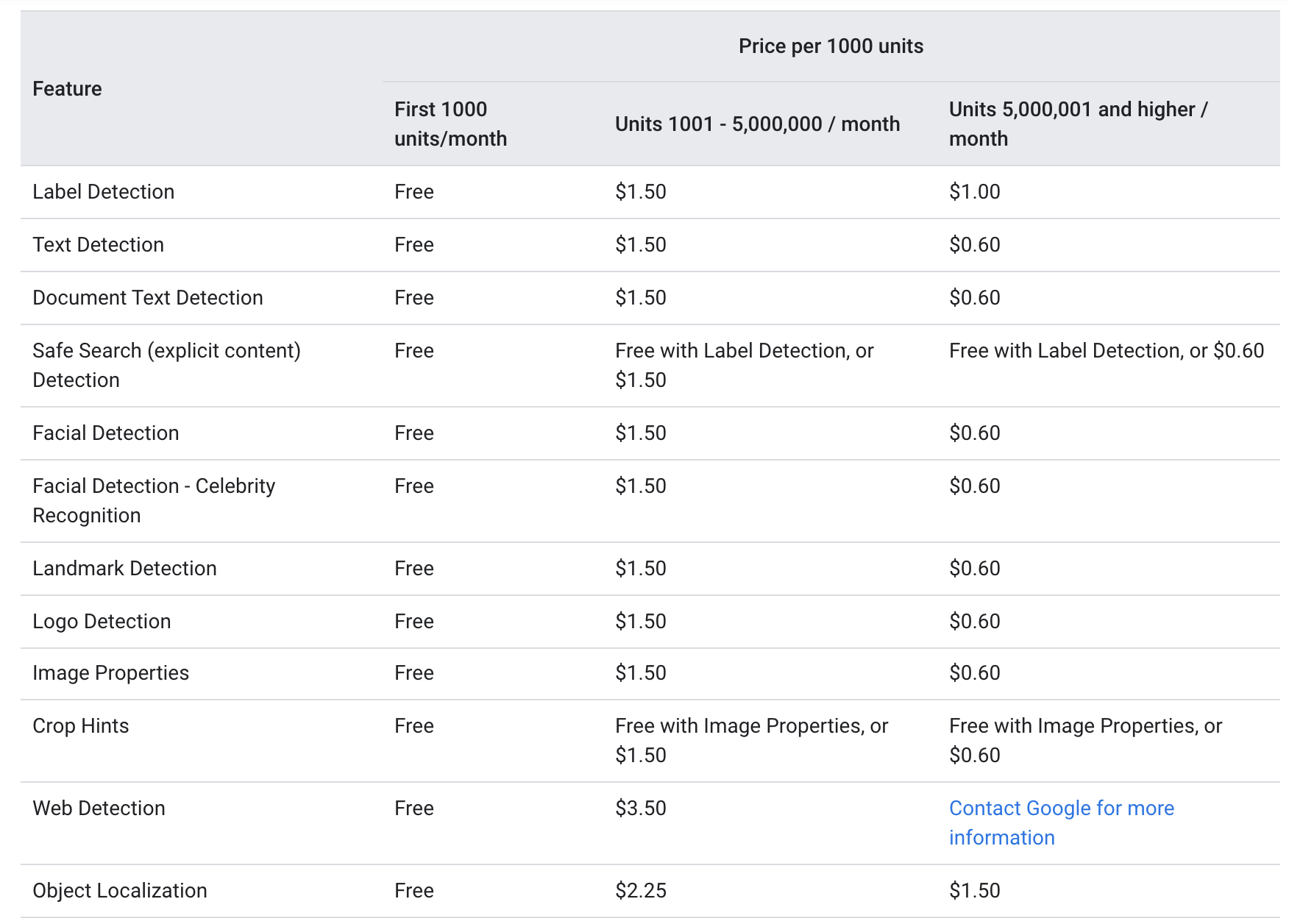
Ovennevnte priser antyder at OCR-tjenesten er relativt rimelig for både små selskaper med mindre hyppige bruksområder, så vel som store selskaper der tjenesten kreves mye mer enn 5000000 ganger per måned.
Fremtredende funksjoner i Google Cloud Vision OCR
Google OCR har forskjellige fordeler, her beskriver vi noen av de viktigste fordelene:
- Robust - De to funksjonene, som serverer to typer tekstdokumenter, avhengig av brukernes beslutning, gjør Google Vision OCR relativt mer robust enn enkeltmodell OCR-motorer.
- Språkstøtte - Med kanskje den største språkdatabasen, har Google gitt råd om at OCR-en gjelder for mer enn 60 språk, eksperimenterer med noen få dusinvis til, og kartlegger mange av de andre til en annen språkkode eller generell språkgjenkjenning.
- Brukervennlighet - Selve modellen er en del av det innebygde Google Vision-biblioteket. Etter den litt mer plagsomme prosessen med å konfigurere API-nøkkelen (som kreves av nesten alle OCR-motorer), kan funksjonskallingsmetoden brukes på flere språk på en veldig grei måte.
- Skalerbarhet - Googles prisstrategi oppfordrer brukerne til å øke bruken av API, ettersom mer bruk fører til en billigere gjennomsnittspris.
- Hastighet - Google Clouds lagringsplattform følger fantastisk API-bruken. Ved å laste opp bildene til stasjonen, kan svartiden til API være veldig rask og skalerbar.

Leter du etter en OCR-løsning som overvinner manglene ved Google Cloud Vision? Gi Nanonets™ et spinn for høyere nøyaktighet, større fleksibilitet og bredere dokumenttyper!
Alternatives
Følgende er noen andre OCR-tjenester enn Google Vision API, sammen med fordelene og ulempene ved hver tjeneste.
ABBYY
ABBYY FineReader PDF er en OCR utviklet av ABBYY, som spesielt fokuserer på pdf-lesing.
- Pros: ABBYY er mye mer kostnadsvennlig for enkeltbrukere ettersom prisingen er delt inn i mindre sektorer (1000, 2000 sider osv.). Det er også rettet mot ikke-tekniske kunder, da det er en kommersialisert app.
- Cons: Programvaren fokuserer kun på PDF-format, og prisen blir veldig dyr når du gjør storstilt OCR.
- Når skal du bruke: For individuelle brukere som bare vil håndtere PDF-filer, kan ABBYY være et mer levedyktig alternativ enn Google Vision API, som gir mer fleksibilitet, men krever ekstra koder.
Microsoft
Microsoft Azure tilbyr også Read API for OCR.
- Pros: Microsoft gir en billigere pris for et enda større antall data som skal brukes. Azure cloud storage tilbyr lignende tjenester som Google Cloud.
- Cons: Det er ingen gratis nivå, mens andre alternativer gir gratis API-samtaler for lav bruk.
- Når skal du bruke: Veldig store OCR-produksjonsrørledninger kan dra nytte av Microsofts priser.
cofax
I likhet med ABBYY tilbyr Kofax også OCR-lesing av PDF-filer
- Pros: Prisen er fast for individuell bruk, og det tilbys rabatter for bedrifter. Kundesupport er tilgjengelig døgnet rundt.
- Cons: Kvaliteten hevdes å være ikke så høy som ABBYYs.
- Når skal du bruke: Små bedrifter med lave brukskrav.
AWS Textract
AWS Textract har en veldig lignende rolle sammenlignet med Google Vision API. Tjenestene og prisene deres er veldig like, og den som skal adopteres er helt basert på kundens preferanser.
Nanonetter
I motsetning til de tidligere omtalte tjenestene, kategoriseres Nanonets OCR-er ytterligere i spesifikke kategorier, med robuste modeller trent på hver datatype (f.eks. Kvitteringer, fakturaer, førerkort).
- Pros: Kategorispesifikke OCR-er, og gir dermed enda bedre resultater når det gjelder nøyaktighet når bedrifter krever OCR for målspesifikke applikasjoner.
- Cons: Nanonets OCR kan være mindre anvendelig i naturen på grunn av de svært spesifikke og skreddersydde modellene
- Når skal du bruke: Hvis bedrifter krever OCR for en bestemt type data, for eksempel fakturaer, kan Nanonets være et kostnadsvennlig og svært nøyaktig alternativ.
Du kan prøv ut Nanonets Online OCR her.
Vanlige problemer med Cloud Vision
I denne siste delen tar vi sikte på å ta opp noen spørsmål fra Stackoverflow angående dokumentskanning og OCR
Gjenkjenne dokumenter ved hjelp av nevrale nettverk
Dette er den nøyaktige bruken av Google OCR! Følg trinnene ovenfor for å skanne i dokumenter og utføre tekstinnhenting.
Å ta tak i de viktigste detaljene etter OCR
Ideen om å analysere det mest betydningsfulle innholdet i alle dokumenter kalles naturlig språkbehandling. Siden hvert dokument inneholder slik informasjon i forskjellige formater, vil det anbefales å bruke noen ML-tilnærminger for å gjøre det. Hvis alle kortene er i samme format, bør selvfølgelig regelbaserte metoder for å hente tekstene med bestemte nøkkeltegn (f.eks. Hvis det inneholder @ det være en e-post) også fungere.
Kan den kjøre frakoblet?
Link: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Dessverre ikke. API-et kaller Google Cloud OCR eksternt, og du kan ikke jobbe frakoblet, da API-en koster penger.
Kan den oppdage om en tekst er i fet skrift eller kursiv?
Nei. Google OCR vil mest sannsynlig oppdage tekstinnholdet selv når det er i fet skrift eller kursiv, men OCR-modellen er ikke laget for å forstå skrifttyper.
Oppdatering: Lagt til mer informasjon basert på spørsmål fra lesere.
- &
- a
- akselerert
- Logg inn
- nøyaktig
- tvers
- Aktiviteter
- adresse
- fordeler
- Alle
- alternativ
- alternativer
- alltid
- beløp
- analyse
- analysere
- En annen
- api
- APIer
- app
- aktuelt
- Søknad
- søknader
- anvendt
- tilnærminger
- AREA
- rundt
- Artikkel
- Eiendeler
- Autentisering
- automatisere
- Automatisert
- gjennomsnittlig
- Azure
- Azure Cloud
- bakgrunn
- Banker
- basis
- før du
- nytte
- Fordeler
- fakturering
- Blokker
- pin
- bøker
- grensen
- pauser
- bil
- Kort
- viss
- tegn
- kostnad
- ladet
- billigere
- kontroll
- City
- klassifisering
- Cloud
- sky lagring
- kode
- Felles
- Selskaper
- Selskapet
- sammenlignet
- helt
- datamaskin
- datamaskiner
- tilkoblet
- Vurder
- Konsoll
- inneholder
- innhold
- innhold
- Konvertering
- Corporations
- Tilsvarende
- Kostnader
- kunne
- land
- land
- skape
- opprettet
- Opprette
- Gjeldende
- kunde
- Kundeservice
- Kunder
- dato
- dataanalyse
- databehandling
- Database
- databaser
- dag
- håndtering
- avgjørelse
- dyp
- avhengig
- avhengig
- beskrive
- designet
- detaljert
- detaljer
- oppdaget
- Bestem
- utviklet
- forskjellig
- vanskelig
- direkte
- direkte
- Mangfold
- leger
- dokumenter
- domener
- ned
- stasjonen
- kjøring
- hver enkelt
- lettelser
- Edge
- innsats
- innsats
- emalje
- dukket
- muliggjøre
- oppmuntrer
- bedrifter
- Miljø
- spesielt
- hovedsak
- etc
- eksempler
- Utgang
- ekstrakter
- familier
- FAST
- Egenskaper
- tilbakemelding
- avgifter
- økonomi
- finansiell
- Firm
- Først
- fikset
- fleksibilitet
- fokuserer
- følge
- etter
- format
- skjemaer
- funnet
- Gratis
- fra
- funksjon
- funksjoner
- videre
- general
- få
- statlig
- regjeringer
- større
- håndtere
- hjelpe
- her.
- Høy
- høyere
- svært
- historie
- sykehus
- Hvordan
- Hvordan
- HTTPS
- menneskelig
- Mennesker
- Tanken
- bilde
- bilder
- viktig
- umulig
- forbedre
- inkludert
- inkluderer
- Inkludert
- individuelt
- individer
- info
- informasjon
- f.eks
- intuitiv
- saker
- IT
- selv
- Java
- holde
- nøkkel
- arbeidskraft
- Språk
- språk
- stor
- større
- største
- Fører
- læring
- Nivå
- nivåer
- Bibliotek
- Tillatelse
- lisenser
- livsstil
- Sannsynlig
- LINK
- lokal
- plassering
- steder
- Lang
- maskin
- maskinlæring
- maskiner
- større
- gjøre
- måte
- manuelt
- Kart
- merke
- massive
- betyr
- meningsfylt
- medisinsk
- medium
- nevnt
- metoder
- Microsoft
- ML
- modell
- modeller
- penger
- Måned
- mer
- mest
- flytte
- flere
- Naturlig
- Natur
- behov
- nettverk
- likevel
- Merknader
- Antall
- tall
- mange
- tilbudt
- Tilbud
- offisiell
- offline
- på nett
- optimalisert
- Alternativ
- alternativer
- rekkefølge
- Organisert
- Annen
- egen
- pakket
- parkering
- del
- Spesielt
- spesielt
- Passerer
- Ansatte
- kanskje
- planer
- plattform
- Politiet
- Populær
- kraftig
- pris
- prising
- prosess
- Prosesser
- prosessering
- Produksjon
- Produkter
- prosjekt
- Anslagene
- lovende
- reklame
- gi
- forutsatt
- gir
- gi
- kjøp
- kvalitet
- raskt
- område
- spenner
- RE
- lesere
- Lesning
- nylig
- gjenkjenne
- poster
- om
- region
- fjernkontroll
- krever
- påkrevd
- Krav
- Krever
- forskning
- Ressurser
- svar
- REST
- Resultater
- vei
- Rolle
- Kjør
- samme
- skalerbar
- Skala
- skanne
- skanning
- sektorer
- forstand
- Serien
- tjeneste
- Tjenester
- servering
- sett
- innstilling
- signifikant
- Skilt
- lignende
- Enkelt
- siden
- liten
- So
- Software
- solid
- løsning
- noen
- spesifikk
- spesielt
- Snurre rundt
- stadier
- startet
- uttalelser
- statistisk
- statistikk
- lagring
- Strategi
- gate
- strukturert
- støtte
- Støtter
- Survey /Inspeksjonsfartøy
- vilkår
- De
- derfor
- Gjennom
- hele
- tid
- ganger
- i dag
- mot
- tradisjonelle
- trafikk
- Kurs
- Overføre
- transformere
- typer
- etter
- forstå
- forståelse
- lomper
- Universell
- bruke
- Brukere
- vanligvis
- ulike
- syn
- volum
- Se
- om
- mens
- HVEM
- bredere
- vinduer
- innenfor
- ord
- Arbeid
- virker
- ville
- X
- år
- Din