Apache Hudi er et åpent tabellformat som bringer database- og datavarehusfunksjoner til datainnsjøer. Apache Hudi hjelper dataingeniører med å håndtere komplekse utfordringer, for eksempel å administrere datasett i kontinuerlig utvikling med transaksjoner samtidig som søkeytelsen opprettholdes. Dataingeniører bruker Apache Hudi for strømming av arbeidsbelastninger samt for å lage effektive inkrementelle datapipelines. Hudi gir tabeller, transaksjoner, effektive opp- og slettinger, avanserte indekser, tjenester for inntak av strømme, data gruppering og kompakte optimaliseringer, og samtidig kontroll, alt mens du holder dataene dine i åpen kildekode-filformater. Hudis avanserte ytelsesoptimaliseringer gjør analytiske arbeidsbelastninger raskere med alle de populære søkemotorene, inkludert Apache Spark, Presto, Trino, Hive, og så videre.
Mange AWS-kunder tok i bruk Apache Hudi på datainnsjøene deres bygget på toppen av Amazon S3 ved hjelp av AWS Lim, en serverløs dataintegrasjonstjeneste som gjør det enklere å oppdage, forberede, flytte og integrere data fra flere kilder for analyse, maskinlæring (ML) og applikasjonsutvikling. AWS limkryper er en komponent av AWS Glue, som lar deg lage tabellmetadata fra datainnhold automatisk uten å kreve manuell definisjon av metadataene.
AWS Glue-crawlere støtter nå Apache Hudi-tabeller, som forenkler innføringen av AWS Lim Data Catalog som katalogen for Hudi-bord. Et typisk brukstilfelle er å registrere Hudi-tabeller, som ikke har katalogtabelldefinisjon. Et annet typisk brukstilfelle er migrering fra andre Hudi-kataloger, for eksempel Hive metastore. Når du migrerer fra andre Hudi-kataloger, kan du opprette og planlegge en AWS Glue-crawler og gi en eller flere Amazon S3-baner der Hudi-tabellfilene er plassert. Du har muligheten til å gi den maksimale dybden til Amazon S3-baner som AWS Glue-crawleren kan krysse. Med hver kjøring vil AWS Glue-crawlere trekke ut skjema- og partisjonsinformasjon og oppdatere AWS Glue Data Catalog med skjema- og partisjonsendringene. AWS Glue crawlers oppdaterer den siste metadatafilplasseringen i AWS Glue Data Catalog som AWS analytiske motorer kan bruke direkte.
Med denne lanseringen kan du opprette og planlegge en AWS Glue-crawler for å registrere Hudi-tabeller i AWS Glue Data Catalog. Du kan deretter gi én eller flere Amazon S3-baner der Hudi-tabellene er plassert. Du har muligheten til å gi den maksimale dybden av Amazon S3-stier som robotsøkeprogrammer kan krysse. Med hver kjøring av crawler inspiserer crawleren hver av S3-banene og katalogiserer skjemainformasjonen, for eksempel nye tabeller, slettinger og oppdateringer av skjemaer i AWS Glue Data Catalog. Crawlere inspiserer partisjonsinformasjon og legger til nylig lagt til partisjoner i AWS Glue Data Catalog. Crawlere oppdaterer også den siste metadatafilplasseringen i AWS Glue Data Catalog som AWS analytiske motorer kan bruke direkte.
Dette innlegget viser hvordan denne nye muligheten til å gjennomgå Hudi-tabeller fungerer.
Hvordan AWS Glue crawler fungerer med Hudi-bord
Hudi-tabeller har to kategorier, med spesifikke implikasjoner for hver:
- Kopier på skriv (CoW) – Data lagres i et kolonneformat (Parquet), og hver oppdatering lager en ny versjon av filer under en skriving.
- Slå sammen ved lesing (MoR) – Data lagres ved hjelp av en kombinasjon av kolonneformater (parkett) og radbaserte (Avro) formater. Oppdateringer logges til radbasert
deltafiler og komprimeres etter behov for å lage nye versjoner av kolonnefilene.
Med CoW-datasett, hver gang det er en oppdatering av en post, skrives filen som inneholder posten om med de oppdaterte verdiene. Med et MoR-datasett, hver gang det er en oppdatering, skriver Hudi bare raden for den endrede posten. MoR er bedre egnet for skrive- eller endringstunge arbeidsbelastninger med færre lesninger. CoW er bedre egnet for lesetunge arbeidsbelastninger på data som endres sjeldnere.
Hudi tilbyr tre spørringstyper for tilgang til dataene:
- Øyeblikksbilder – Forespørsler som ser det siste øyeblikksbildet av tabellen som av en gitt forpliktelse eller komprimeringshandling. For MoR-tabeller avslører øyeblikksbildespørringer den nyeste tilstanden til tabellen ved å slå sammen basis- og deltafilene til det siste filstykket på tidspunktet for spørringen.
- Inkrementelle spørringer – Forespørsler ser bare nye data skrevet til tabellen, siden en gitt forpliktelse eller komprimering. Dette gir effektivt endringsstrømmer for å muliggjøre inkrementelle datapipelines.
- Les optimaliserte søk – For MoR-tabeller ser spørringer de siste dataene komprimert. For CoW-tabeller, se spørringer de siste dataene som er forpliktet.
For kopier-på-skriv-tabeller oppretter crawlere en enkelt tabell i AWS Glue Data Catalog med ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
For flette-på-les-tabeller oppretter crawlere to tabeller i AWS Glue Data Catalog for samme tabellplassering:
- En tabell med suffiks
_ro, som bruker ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - En tabell med suffiks
_rt, som bruker RealTime Serde som tillater Snapshot-spørringer:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Under hver gjennomgang, for hver oppgitt Hudi-bane, foretar robotsøkeprogrammer et Amazon S3-liste API-kall, filter basert på .hoodie mapper, og finn den nyeste metadatafilen under den Hudi-tabellens metadatamappen.
Gjennomgå et Hudi CoW-bord med AWS Glue crawler
I denne delen skal vi gå gjennom hvordan du crawler en Hudi CoW ved hjelp av AWS Glue crawlere.
Forutsetninger
Her er forutsetningene for denne opplæringen:
- Installer og konfigurer AWS Command Line Interface (AWS CLI).
- Lag din S3-bøtte hvis du ikke har den.
- Lag din IAM-rolle for AWS Glue hvis du ikke har det. Du trenger
s3:GetObjectforums3://your_s3_bucket/data/sample_hudi_cow_table/. - Kjør følgende kommando for å kopiere Hudi-eksemplet til S3-bøtten din. (Erstatte
your_s3_bucketmed navnet på S3-bøtte.)
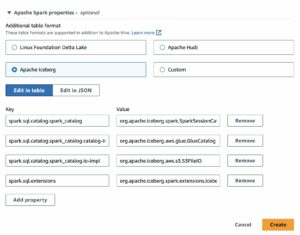
Denne instruksjonen veileder deg til å kopiere eksempeldata, men du kan enkelt lage alle Hudi-tabeller ved å bruke AWS Glue. Lær mer i Vi introduserer innfødt støtte for Apache Hudi, Delta Lake og Apache Iceberg på AWS Glue for Apache Spark, del 2: AWS Glue Studio Visual Editor.
Lag en Hudi-søkerobot
I denne instruksjonen oppretter du robotsøkeprogrammet gjennom konsollen. Fullfør følgende trinn for å lage en Hudi-søkerobot:
- Velg på AWS Lim-konsollen crawlers.
- Velg Opprett crawler.
- Til Navn, Tast inn
hudi_cow_crawler. Velg neste. - Under Datakildekonfigurasjon, velg Legg til datakilde.
- Til Datakilde, velg Hudi.
- Til Inkluder hudi-tabellbaner, Tast inn
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Erstatteyour_s3_bucketmed navnet på S3-bøtte.) - Velg Legg til Hudi-datakilde.
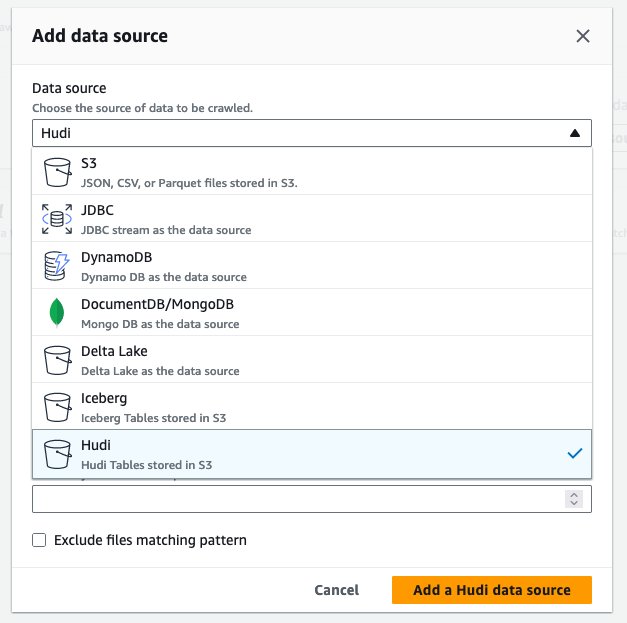
- Velg neste.
- Til Eksisterende IAM-rolle, velg din IAM-rolle, og velg deretter neste.
- Til Måldatabase, velg Legg til database, og så Legg til database dialogboksen vises. Til Databasens navn, Tast inn
hudi_crawler_blog, velg deretter Opprett. Velg neste. - Velg Opprett crawler.
Nå er en ny Hudi-crawler opprettet. Søkeroboten kan utløses til å kjøre gjennom konsollen eller gjennom SDK eller AWS CLI ved å bruke StartCrawl API. Det kan også planlegges gjennom konsollen for å utløse robotsøkeprogrammer på bestemte tidspunkter. I denne instruksjonen kjører du robotsøkeprogrammet gjennom konsollen.
- Velg Kjør bånd.
- Vent til robotsøkeprogrammet er fullført.
Etter at robotsøkeprogrammet har kjørt, kan du se Hudi-tabelldefinisjonen i AWS Glue-konsollen:
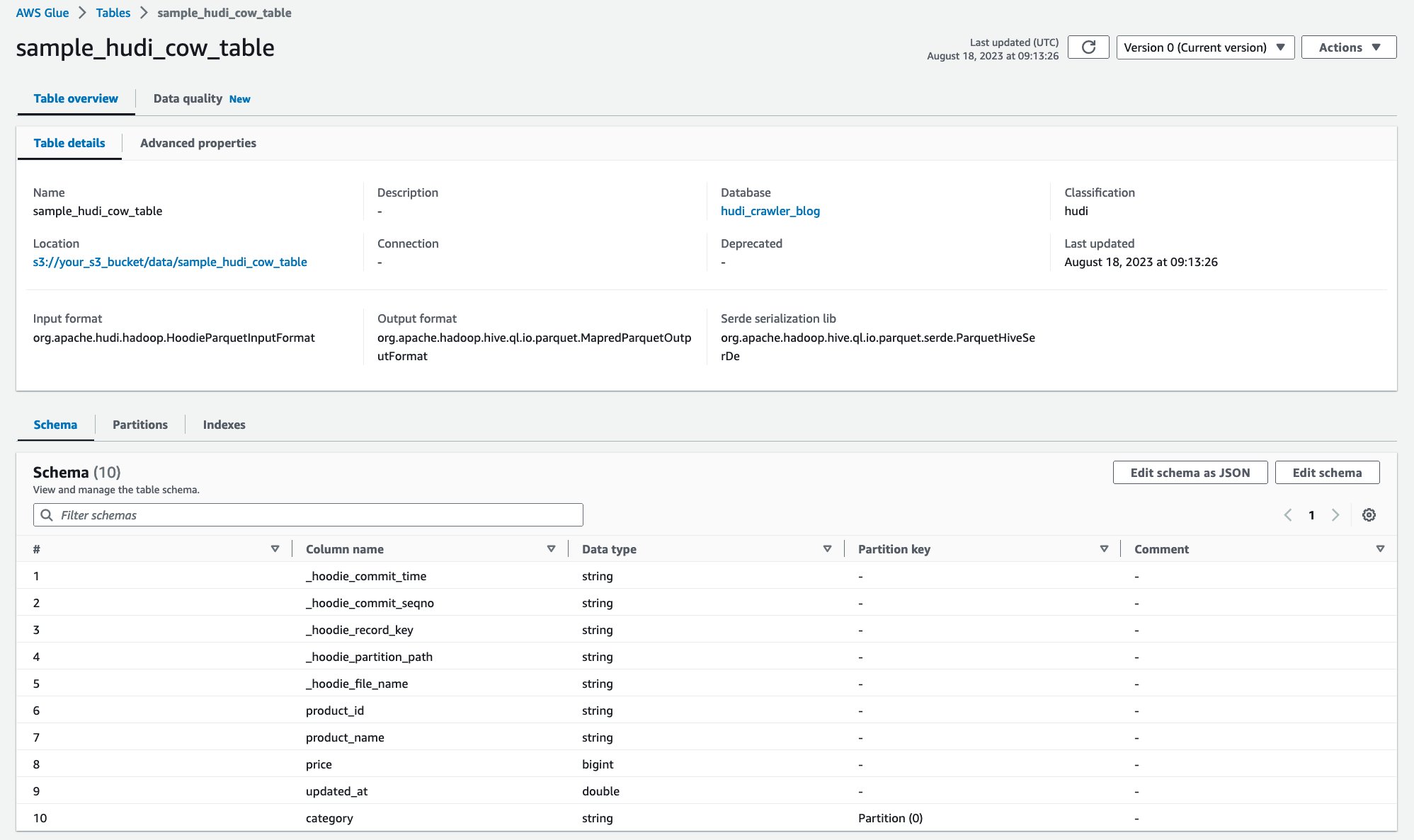
Du har gjennomsøkt Hudi CoR-tabellen med data på Amazon S3 og opprettet en AWS Glue Data Catalog-tabell med skjemaet fylt ut. Etter at du har opprettet tabelldefinisjonen på AWS Glue Data Catalog, kan AWS-analysetjenester som Amazon Athena spørre Hudi-tabellen.
Fullfør følgende trinn for å starte spørringer på Athena:
- Åpne Amazon Athena-konsollen.
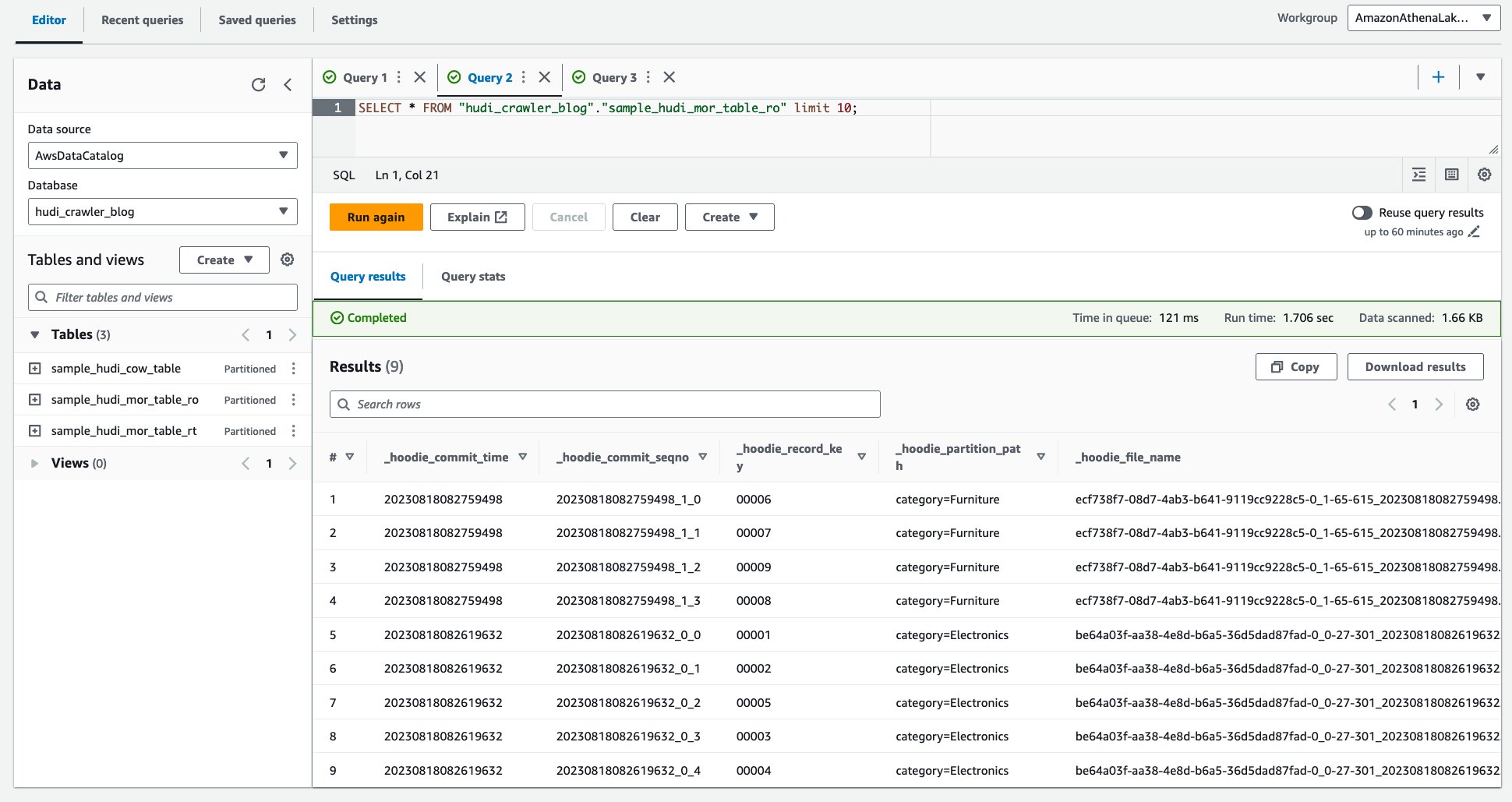
- Kjør følgende spørring.
Følgende skjermbilde viser produksjonen vår:
Gjennomgå en Hudi MoR-tabell med AWS Glue-crawler med AWS Lake Formation-datatillatelser
I denne delen, la oss gå gjennom hvordan man gjennomsøker et Hudi MoR-bord ved hjelp av AWS Glue. Denne gangen bruker du AWS Lake Formation-datatillatelsen for å gjennomsøke Amazon S3-datakilder i stedet for IAM- og Amazon S3-tillatelsen. Dette er valgfritt, men det forenkler tillatelseskonfigurasjoner når datainnsjøen din administreres av AWS Lake Formation-tillatelser.
Forutsetninger
Her er forutsetningene for denne opplæringen:
- Installer og konfigurer AWS Command Line Interface (AWS CLI).
- Lag din S3-bøtte hvis du ikke har den.
- Lag din IAM-rolle for AWS Glue hvis du ikke har det. Du trenger
lakeformation:GetDataAccess. Men du trenger ikkes3:GetObjectforums3://your_s3_bucket/data/sample_hudi_mor_table/fordi vi bruker Lake Formation-datatillatelse for å få tilgang til filene. - Kjør følgende kommando for å kopiere Hudi-eksemplet til S3-bøtten din. (Erstatte
your_s3_bucketmed navnet på S3-bøtte.)
I tillegg til behandlingstrinnene, fullfør følgende trinn for å oppdatere AWS Glue Data Catalog-innstillingene for å bruke Lake Formation-tillatelser til å kontrollere katalogressurser i stedet for IAM-basert tilgangskontroll:
- Logg på Lake Formation-konsollen som datainnsjø-administrator.
- Hvis dette er første gang du får tilgang til Lake Formation-konsollen, legg deg til som datainnsjø-administrator.
- Under Administrasjon, velg Datakataloginnstillinger.
- Til Standardtillatelser for nyopprettede databaser og tabeller, fjern merket Bruk kun IAM-tilgangskontroll for nye databaser og Bruk bare IAM-tilgangskontroll for nye tabeller i nye databaser.
- Til Versjonsinnstilling for flere kontoer, velg versjon 3.
- Velg Spar.
Det neste trinnet er å registrere S3-bøtten din i Lake Formation datainnsjøplasseringer:
- Velg på Lake Formation-konsollen Data lake steder, og velg Registrer sted.
- Til Amazon S3-bane, Tast inn
s3://your_s3_bucket/. (Erstatteyour_s3_bucketmed navnet på S3-bøtte.) - Velg Registrer sted.
Gi deretter Glue-crawler-rolletilgang til dataplassering slik at robotsøkeprogrammet kan bruke Lake Formation-tillatelse til å få tilgang til dataene og opprette tabeller på stedet:
- Velg på Lake Formation-konsollen Datasteder Og velg Grant.
- Til IAM-brukere og roller, velg IAM-rollen du brukte for søkeroboten.
- Til Lagringssted, Tast inn
s3://your_s3_bucket/data/. (Erstatteyour_s3_bucketmed navnet på S3-bøtte.) - Velg Grant.
Gi deretter crawler-rolle for å lage tabeller under databasen hudi_crawler_blog:
- Velg på Lake Formation-konsollen Datainnsjø-tillatelser.
- Velg Grant.
- Til Rektorer, velg IAM-brukere og roller, og velg robotsøkerollen.
- Til LF-tagger eller katalogressurser, velg Navngitte datakatalogressurser.
- Til Database, velg databasen
hudi_crawler_blog. - Under Database tillatelser, plukke ut Opprett tabell.
- Velg Grant.
Opprett en Hudi-søkerobot med Lake Formation-datatillatelser
Fullfør følgende trinn for å lage en Hudi-søkerobot:
- Velg på AWS Lim-konsollen crawlers.
- Velg Opprett crawler.
- Til Navn, Tast inn
hudi_mor_crawler. Velg neste. - Under Datakildekonfigurasjon, velg Legg til datakilde.
- Til Datakilde, velg Hudi.
- Til Inkluder hudi-tabellbaner, Tast inn
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Erstatteyour_s3_bucketmed navnet på S3-bøtte.) - Velg Legg til Hudi-datakilde.
- Velg neste.
- Til Eksisterende IAM-rolle, velg din IAM-rolle.
- Under Lake Formation-konfigurasjon – valgfritt, plukke ut Bruk Lake Formation-legitimasjonen for å gjennomsøke S3-datakilden.
- Velg neste.
- Til Måldatabase, velg
hudi_crawler_blog. Velg neste. - Velg Opprett crawler.
Nå er en ny Hudi-crawler opprettet. Søkeroboten bruker Lake Formation-legitimasjon for å gjennomsøke Amazon S3-filer. La oss kjøre den nye søkeroboten:
- Velg Kjør bånd.
- Vent til robotsøkeprogrammet er fullført.
Etter at robotsøkeprogrammet har kjørt, kan du se to tabeller med Hudi-tabelldefinisjonen i AWS Glue-konsollen:
sample_hudi_mor_table_ro(les optimalisert tabell)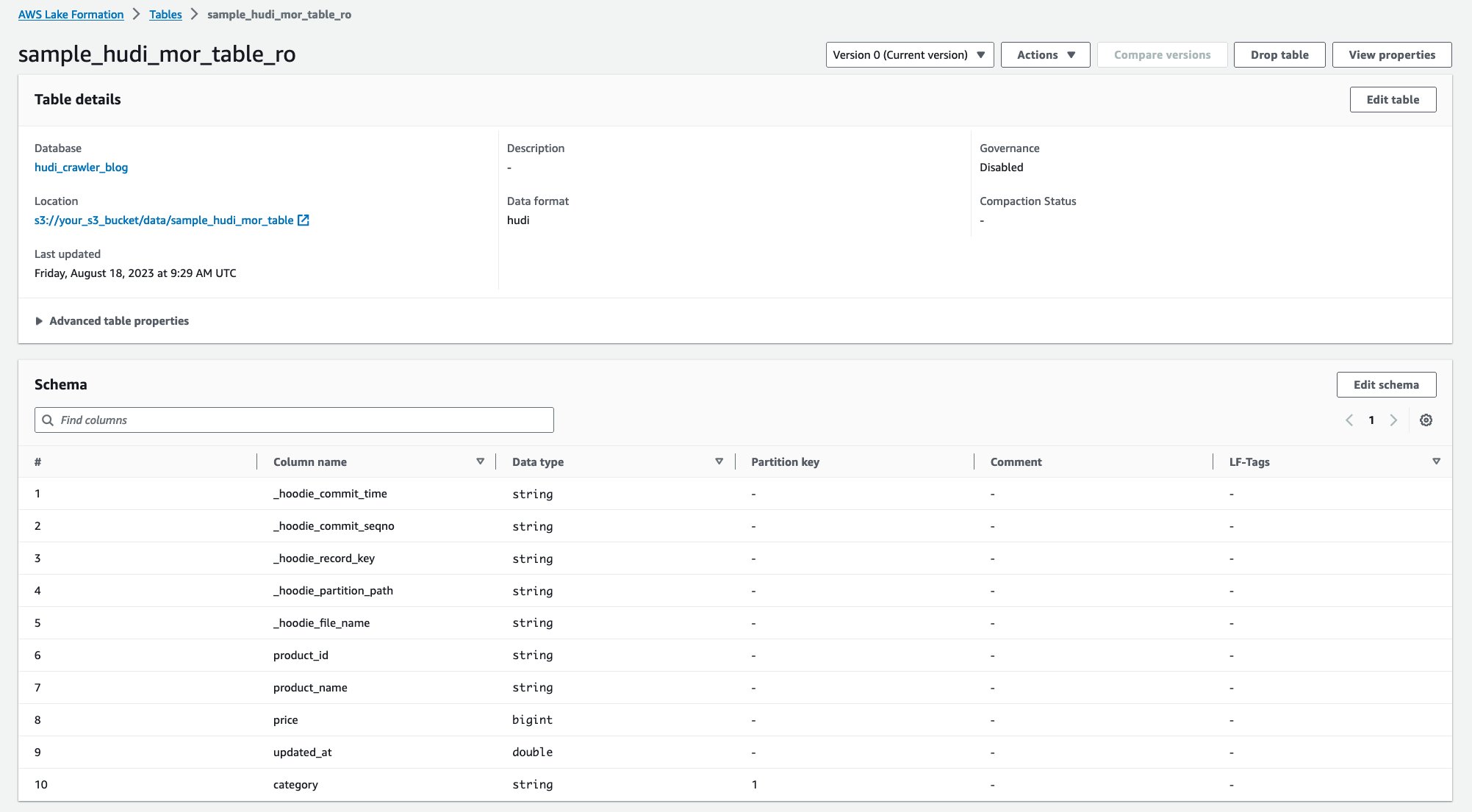
sample_hudi_mor_table_rt(sanntidstabell)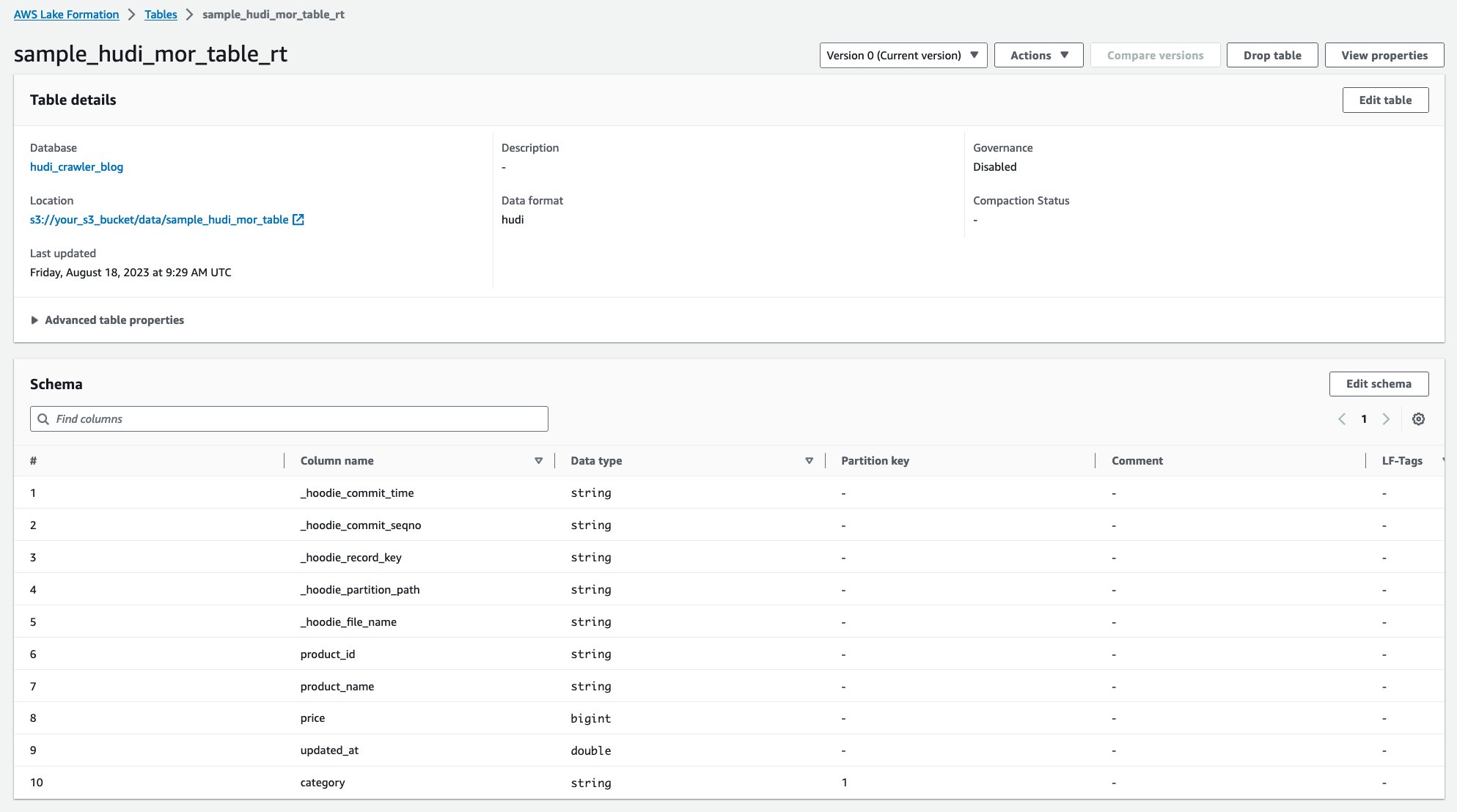
Du registrerte datainnsjø-bøtten med Lake Formation og aktivert gjennomsøkingstilgang til datasjøen ved hjelp av Lake Formation-tillatelser. Du har gjennomsøkt Hudi MoR-tabellen med data på Amazon S3 og opprettet en AWS Glue Data Catalog-tabell med skjemaet fylt ut. Etter at du har opprettet tabelldefinisjonene på AWS Glue Data Catalog, kan AWS-analysetjenester som Amazon Athena spørre etter Hudi-tabellen.
Fullfør følgende trinn for å starte spørringer på Athena:
- Åpne Amazon Athena-konsollen.
- Kjør følgende spørring.
Følgende skjermbilde viser produksjonen vår:
- Kjør følgende spørring.
Følgende skjermbilde viser produksjonen vår:
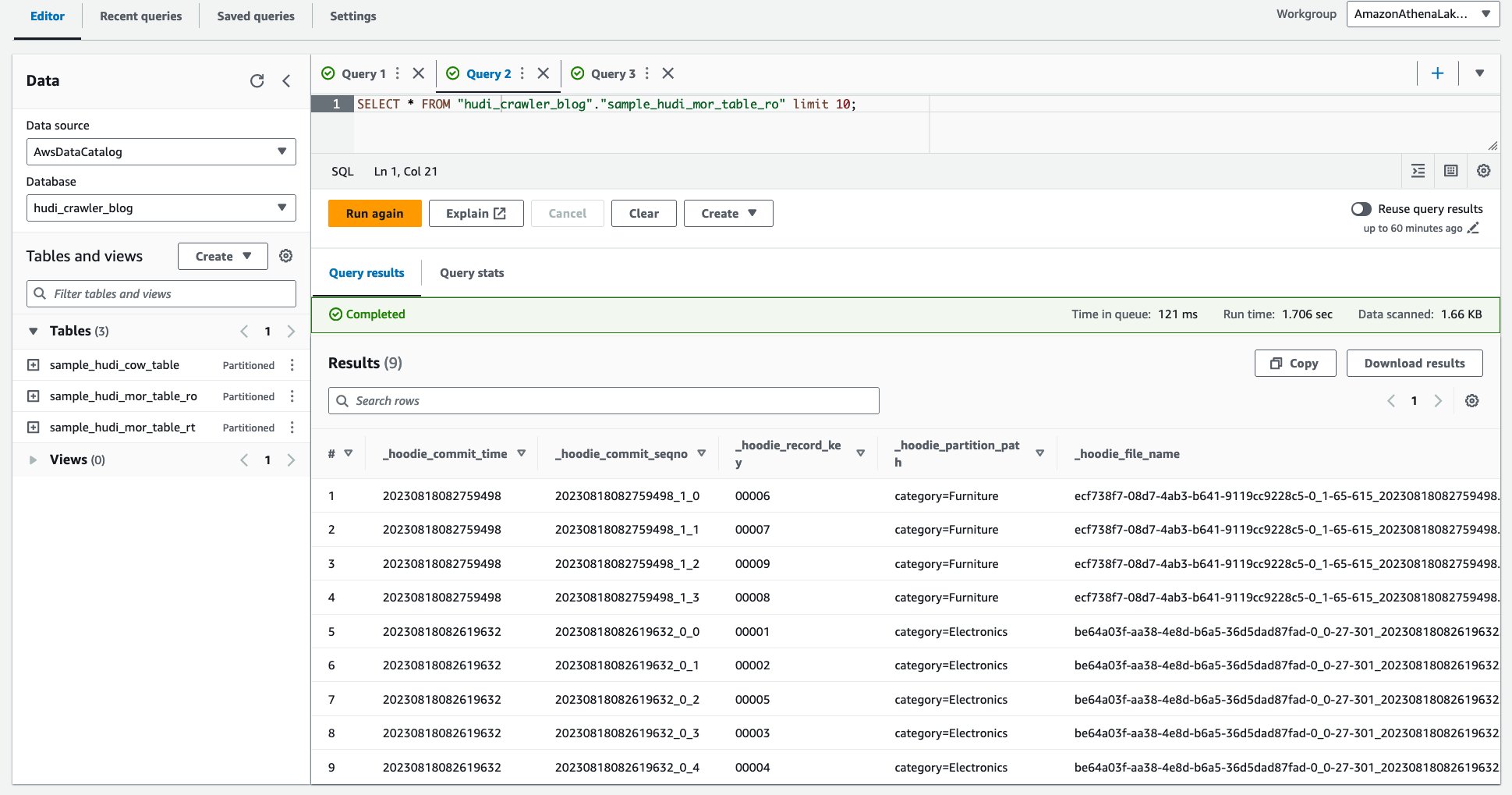
Finmasket tilgangskontroll med AWS Lake Formation-tillatelser
For å bruke finmasket tilgangskontroll på Hudi-bordet, kan du dra nytte av AWS Lake Formation-tillatelser. Lake Formation-tillatelser lar deg begrense tilgangen til bestemte tabeller, kolonner eller rader og deretter spørre Hudi-tabellene gjennom Amazon Athena med finmasket tilgangskontroll. La oss konfigurere Lake Formation-tillatelsen for Hudi MoR-tabellen.
Forutsetninger
Her er forutsetningene for denne opplæringen:
- Fullfør forrige avsnitt Gjennomgå en Hudi MoR-tabell med AWS Glue-crawler med AWS Lake Formation-datatillatelser.
- Opprett en IAM-bruker DataAnalyst, som har AWS-administrert policy AmazonAthena Full Access.
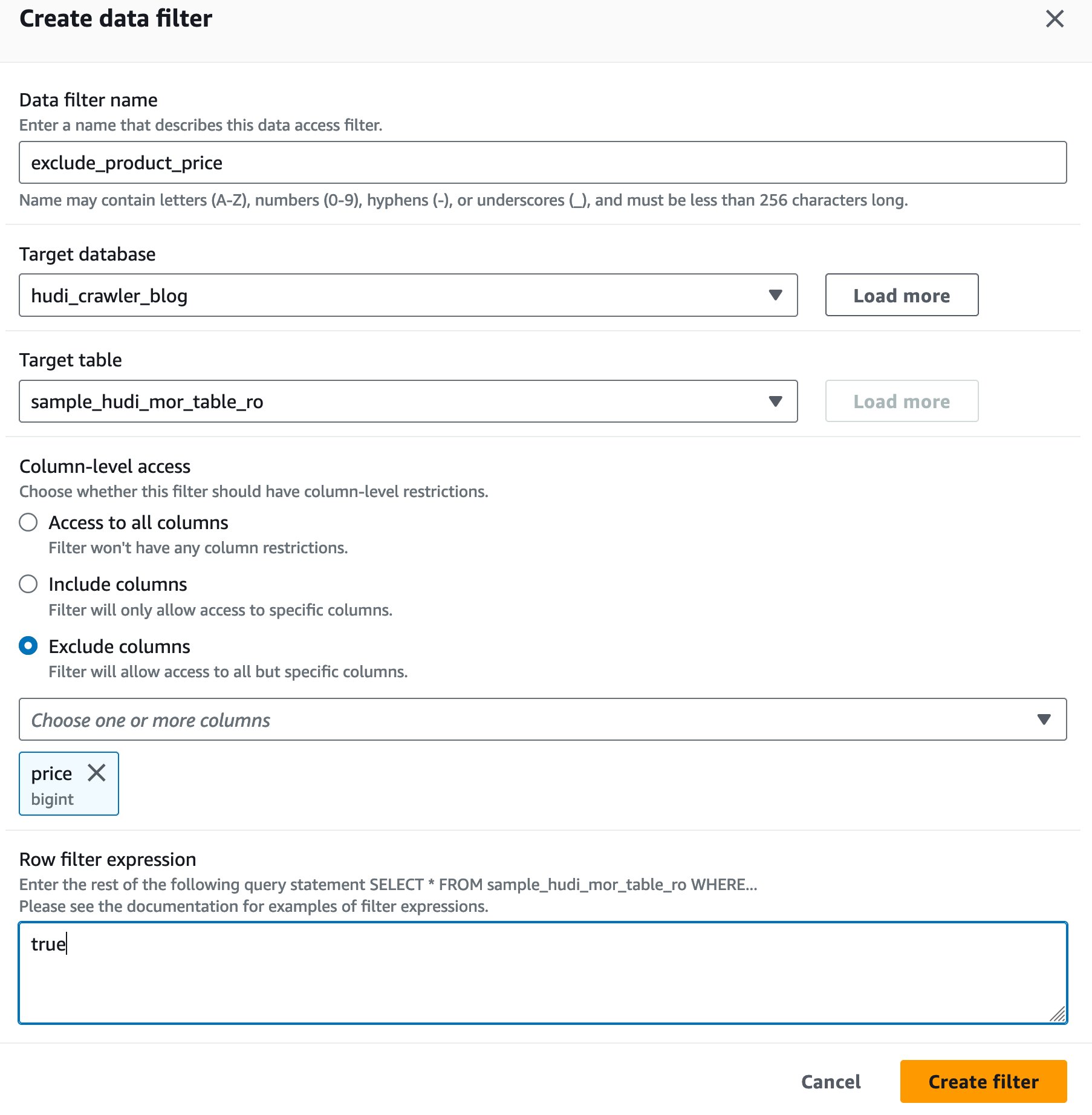
Lag et datacellefilter for Lake Formation
La oss først sette opp et filter for den MoR lese-optimaliserte tabellen.
- Logg på Lake Formation-konsollen som datainnsjø-administrator.
- Velg Datafiltre.
- Velg Lag et nytt filter.
- Til Datafilternavn, Tast inn
exclude_product_price. - Til Måldatabase, velg databasen
hudi_crawler_blog. - Til Måltabell, velg tabellen
sample_hudi_mor_table_ro. - Til Kolonnenivå tilgang, velg Ekskluder kolonner, og velg kolonneprisen.
- Til Radfilteruttrykk, Tast inn
true. - Velg Opprett filter.
Gi Lake Formation-tillatelser til DataAnalyst-brukeren
Fullfør følgende trinn for å gi Lake Formation tillatelse til DataAnalyst bruker
- Velg på Lake Formation-konsollen Datainnsjø-tillatelser.
- Velg Grant.
- Til Rektorer, velg IAM-brukere og roller, og velg brukeren
DataAnalyst. - Til LF-tagger eller katalogressurser, velg Navngitte datakatalogressurser.
- Til Database, velg databasen
hudi_crawler_blog. - Til Bord – valgfritt, velg tabellen
sample_hudi_mor_table_ro. - Til Datafiltre – valgfritt, plukke ut
exclude_product_price. - Til Tillatelser for datafilter, plukke ut Plukke ut.
- Velg Grant.
Du ga Lake Formation tillatelse til databasen hudi_crawler_blog og bordet sample_hudi_mor_table_ro, unntatt kolonnen price til DataAnalyst-brukeren. La oss nå validere brukertilgang til dataene ved hjelp av Athena.
- Logg på Athena-konsollen som DataAnalyst-bruker.
- Kjør følgende spørring i spørringsredigeringsprogrammet:
Følgende skjermbilde viser produksjonen vår:
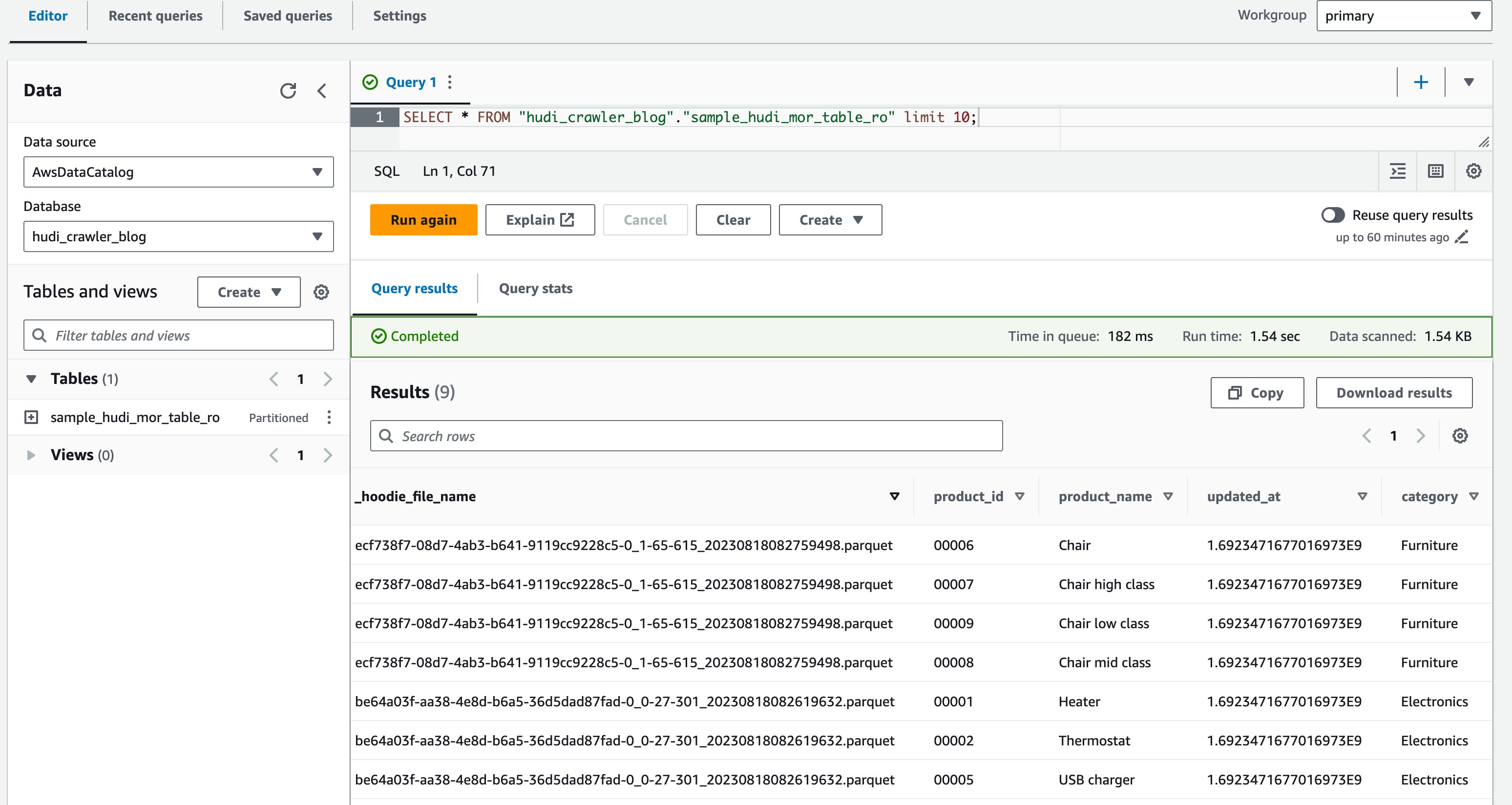
Nå har du bekreftet at kolonnen price vises ikke, men de andre kolonnene product_id, product_name, update_atog category er vist.
Rydd opp
For å unngå uønskede belastninger på AWS-kontoen din, slett følgende AWS-ressurser:
- Slett AWS Glue-database
hudi_crawler_blog. - Slett AWS Glue crawlers
hudi_cow_crawleroghudi_mor_crawler. - Slett Amazon S3-filer under
s3://your_s3_bucket/data/sample_hudi_cow_table/ogs3://your_s3_bucket/data/sample_hudi_mor_table/.
konklusjonen
Dette innlegget demonstrerte hvordan AWS Glue-crawlere fungerer for Hudi-bord. Med støtte for Hudi-crawler kan du raskt gå over til å bruke AWS Glue Data Catalog som din primære Hudi-tabellkatalog. Du kan begynne å bygge din serverløse transaksjonelle datainnsjø ved å bruke Hudi på AWS ved å bruke AWS Glue, AWS Glue Data Catalog og Lake Formation finkornede tilgangskontroller for tabeller og formater som støttes av AWS analytiske motorer.
Om forfatterne
 Noritaka Sekiyama er en rektor Big Data Architect i AWS Glue-teamet. Han jobber med base i Tokyo, Japan. Han er ansvarlig for å bygge programvareartefakter for å hjelpe kunder. På fritiden liker han å sykle med landeveissykkelen.
Noritaka Sekiyama er en rektor Big Data Architect i AWS Glue-teamet. Han jobber med base i Tokyo, Japan. Han er ansvarlig for å bygge programvareartefakter for å hjelpe kunder. På fritiden liker han å sykle med landeveissykkelen.
 Kyle Duong er en programvareutviklingsingeniør i AWS Glue and Lake Formation-teamet. Han brenner for å bygge big data-teknologier og distribuerte systemer.
Kyle Duong er en programvareutviklingsingeniør i AWS Glue and Lake Formation-teamet. Han brenner for å bygge big data-teknologier og distribuerte systemer.
 Sandeep Adwankar er senior teknisk produktsjef i AWS. Basert i California Bay Area jobber han med kunder over hele verden for å oversette forretningsmessige og tekniske krav til produkter som gjør det mulig for kundene å forbedre hvordan de administrerer, sikrer og får tilgang til data.
Sandeep Adwankar er senior teknisk produktsjef i AWS. Basert i California Bay Area jobber han med kunder over hele verden for å oversette forretningsmessige og tekniske krav til produkter som gjør det mulig for kundene å forbedre hvordan de administrerer, sikrer og får tilgang til data.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- I stand
- Om oss
- adgang
- Tilgang til data
- Tilgang
- Logg inn
- Handling
- legge til
- la til
- tillegg
- vedtatt
- Adopsjon
- avansert
- Etter
- Alle
- tillate
- tillate
- tillater
- også
- Amazon
- Amazonas Athena
- Amazon Web Services
- an
- Analytisk
- analytics
- og
- En annen
- noen
- Apache
- Apache Spark
- api
- vises
- Søknad
- Applikasjonutvikling
- Påfør
- ER
- AREA
- rundt
- AS
- At
- automatisk
- unngå
- AWS
- AWS Lim
- AWS Lake formasjon
- basen
- basert
- bukt
- BE
- fordi
- vært
- nytte
- Bedre
- Stor
- Store data
- Bringer
- Bygning
- bygget
- virksomhet
- men
- by
- california
- ring
- CAN
- evner
- evne
- saken
- katalog
- kataloger
- kategorier
- celle
- utfordringer
- endring
- endret
- Endringer
- avgifter
- Velg
- Kolonne
- kolonner
- kombinasjon
- forplikte
- forpliktet
- fullføre
- komplekse
- komponent
- Konfigurasjon
- Konsoll
- inneholder
- innhold
- kontinuerlig
- kontroll
- kontroller
- kunne
- crawler
- skape
- opprettet
- skaper
- Credentials
- Kunder
- dato
- dataintegrasjon
- Data Lake
- datalager
- Database
- databaser
- datasett
- definisjon
- definisjoner
- Delta
- demonstrert
- demonstrerer
- dybde
- Utvikling
- direkte
- oppdage
- distribueres
- distribuerte systemer
- do
- gjør
- under
- hver enkelt
- enklere
- lett
- redaktør
- effektivt
- effektiv
- muliggjøre
- aktivert
- ingeniør
- Ingeniører
- Motorer
- Enter
- Eter (ETH)
- utvikling
- Eksklusiv
- trekke ut
- raskere
- færre
- filet
- Filer
- filtrere
- filtre
- Finn
- Først
- første gang
- etter
- Til
- format
- formasjon
- ofte
- fra
- gitt
- globus
- Go
- innvilge
- innvilget
- Guider
- Hadoop
- Ha
- he
- hjelpe
- hjelper
- hans
- Hive
- Hvordan
- Hvordan
- HTML
- HTTPS
- IAM
- if
- implikasjoner
- forbedre
- in
- Inkludert
- inkrementell
- informasjon
- i stedet
- integrere
- integrering
- Interface
- inn
- innføre
- IT
- Japan
- jpg
- holde
- innsjø
- innsjøer
- siste
- lansere
- LÆRE
- læring
- mindre
- BEGRENSE
- linje
- Liste
- ligger
- plassering
- steder
- logget
- maskin
- maskinlæring
- opprettholde
- gjøre
- GJØR AT
- administrer
- fikk til
- leder
- administrerende
- håndbok
- maksimal
- sammenslåing
- metadata
- Migrere
- migrasjon
- ML
- mer
- mest
- flytte
- flere
- navn
- innfødt
- Trenger
- nødvendig
- Ny
- nylig
- neste
- nå
- of
- on
- ONE
- bare
- åpen
- åpen kildekode
- optimalisert
- Alternativ
- or
- Annen
- vår
- produksjon
- del
- lidenskapelig
- banen
- baner
- ytelse
- tillatelse
- tillatelser
- plato
- Platon Data Intelligence
- PlatonData
- Populær
- befolket
- Post
- Forbered
- forutsetninger
- forrige
- pris
- primære
- Principal
- prosessering
- Produkt
- Produktsjef
- Produkter
- gi
- forutsatt
- gir
- spørsmål
- raskt
- Lese
- ekte
- sanntids
- realtime
- nylig
- rekord
- registrere
- registrert
- erstatte
- Krav
- Ressurser
- ansvarlig
- begrense
- vei
- Rolle
- RAD
- Kjør
- samme
- planlegge
- planlagt
- SDK
- Seksjon
- sikre
- se
- velg
- senior
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- innstillinger
- vist
- Viser
- forenkler
- siden
- enkelt
- Slice
- Snapshot
- So
- Software
- programvareutvikling
- kilde
- Kilder
- Spark
- spesifikk
- Begynn
- Tilstand
- Trinn
- Steps
- lagret
- streaming
- bekker
- studio
- vellykket
- slik
- støtte
- Støttes
- synk.
- Systemer
- bord
- lag
- Teknisk
- Technologies
- Det
- De
- deres
- deretter
- Der.
- de
- denne
- tre
- Gjennom
- tid
- ganger
- til
- tokyo
- topp
- transaksjonell
- Transaksjoner
- oversette
- traversere
- utløse
- utløst
- tutorial
- to
- typer
- typisk
- etter
- uønsket
- Oppdater
- oppdatert
- oppdateringer
- bruke
- bruk sak
- brukt
- Bruker
- Brukere
- bruker
- ved hjelp av
- VALIDERE
- validert
- Verdier
- versjon
- visuell
- Warehouse
- we
- web
- webtjenester
- VI VIL
- når
- hvilken
- mens
- HVEM
- vil
- med
- uten
- Arbeid
- virker
- skrive
- skrevet
- du
- Din
- deg selv
- zephyrnet