Amazon RedShift, et mye brukt skydatavarehus, har utviklet seg betydelig for å møte ytelseskravene til de mest krevende arbeidsbelastningene. Dette innlegget dekker en slik ny funksjon – sorteringsnøkkelen for flerdimensjonal datalayout.
Amazon Redshift forbedrer nå søkeytelsen din ved å støtte flerdimensjonale datalayoutsorteringsnøkler, som er en ny type sorteringsnøkkel som sorterer en tabells data etter filterpredikater i stedet for fysiske kolonner i tabellen. Flerdimensjonale datalayoutsorteringsnøkler vil forbedre ytelsen til tabellskanninger betydelig, spesielt når spørringsarbeidsmengden inneholder gjentatte skanningsfiltre.
Amazon Redshift gir allerede muligheten til automatisk tabelloptimalisering (ATO), som automatisk optimaliserer utformingen av tabeller ved å bruke sorterings- og distribusjonsnøkler uten behov for administratorinngrep. I dette innlegget introduserer vi flerdimensjonale datalayoutsorteringsnøkler som en tilleggsfunksjon som tilbys av ATO og forsterket av Amazon Redshifts sorteringsnøkkelrådgiveralgoritme.
Flerdimensjonale datalayout sorteringsnøkler
Når du definerer en tabell med AUTO-sorteringsnøkkelen, vil Amazon Redshift ATO analysere søkehistorikken din og automatisk velge enten en enkeltkolonne sorteringsnøkkel eller flerdimensjonal datalayoutsorteringsnøkkel for tabellen din, basert på hvilket alternativ som er best for arbeidsmengden din. Når flerdimensjonal datalayout er valgt, vil Amazon Redshift konstruere en flerdimensjonal sorteringsfunksjon som samlokaliserer rader som vanligvis åpnes av de samme spørringene, og sorteringsfunksjonen blir deretter brukt under spørringskjøringer for å hoppe over datablokker og til og med hoppe over skanning av det individuelle predikatet kolonner.
Tenk på følgende brukerspørring, som er et dominerende spørringsmønster i brukerens arbeidsmengde:
Amazon Redshift lagrer data for hver kolonne i 1 MB diskblokker og lagrer minimums- og maksimumsverdiene i hver blokk som en del av tabellens metadata. Hvis en spørring bruker en rekkeviddebegrenset predikat, Amazon Redshift kan bruke minimums- og maksimumsverdiene for raskt å hoppe over et stort antall blokker under tabellskanning. Dette søkets filter på underregionkolonnen kan imidlertid ikke brukes til å bestemme hvilke blokker som skal hoppes over basert på minimums- og maksimumsverdier, og som et resultat skanner Amazon Redshift alle rader fra titteltabellen:
Når brukerens spørring ble kjørt med titles ved å bruke en enkelt-kolonne sorteringsnøkkel på subregion, er resultatet av den foregående spørringen som følger:
Dette viser at tabellskanningen leste 2,164,081,640 rader.
For å forbedre skanninger på titles tabell, kan Amazon Redshift automatisk bestemme seg for å bruke en flerdimensjonal datalayoutsorteringsnøkkel. Alle rader som tilfredsstiller lower(subregion) like '%United States%' Predikat vil være samlokalisert til en dedikert region av tabellen, og derfor vil Amazon Redshift kun skanne datablokker som tilfredsstiller predikatet.
Når brukerens spørring kjøres med titles ved hjelp av en flerdimensjonal datalayoutsorteringsnøkkel som inkluderer lower(subregion) like '%United States%' som et predikat, resultatet av sys_query_detail spørringen er som følger:
Dette viser at tabellskanningen leste 152,324,046 7 XNUMX rader, som bare er XNUMX % av originalen, og den brukte sorteringsnøkkelen for flerdimensjonal dataoppsett.
Merk at dette eksemplet bruker en enkelt spørring for å vise frem funksjonen for flerdimensjonal datalayout, men Amazon Redshift vil vurdere alle spørringene som kjører mot tabellen og kan opprette flere regioner for å tilfredsstille de mest brukte predikatene.
La oss ta et annet eksempel, med mer komplekse predikater og flere spørringer denne gangen.
Tenk deg å ha et bord items (cost int, available int, demand int) med fire rader som vist i følgende eksempel.
| #id | koste | tilgjengelig | etterspørsel |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Din dominerende arbeidsmengde består av to spørringer:
- 70 % spørringsmønster:
- 20 % spørringsmønster:
Med tradisjonelle sorteringsteknikker kan du velge å sortere tabellen over kostnadskolonnen, slik at evalueringen av cost > 3 vil ha nytte av sorteringen. Så, varene tabellen etter sortering ved hjelp av en enkelt cost kolonnen vil se slik ut.
| #id | koste | tilgjengelig | etterspørsel |
| Region #1, med kostnad <= 3 | |||
| Region #2, med kostnad > 3 | |||
| #id | koste | tilgjengelig | etterspørsel |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Ved å bruke denne tradisjonelle sorteringen kan vi umiddelbart ekskludere de to øverste (blå) radene med ID 4 og ID 2, fordi de ikke tilfredsstiller cost > 3.
På den annen side, med en flerdimensjonal sorteringsnøkkel for dataoppsett, vil tabellen sorteres basert på en kombinasjon av de to vanlig forekommende predikatene i brukerens arbeidsmengde, som er cost > 3 og available < demand. Som et resultat blir tabellens rader sortert i fire regioner.
| #id | koste | tilgjengelig | etterspørsel |
| Region #1, med kostnad <= 3 og tilgjengelig < etterspørsel | |||
| Region #2, med kostnad <= 3 og tilgjengelig >= etterspørsel | |||
| Region #3, med kostnad > 3 og tilgjengelig < etterspørsel | |||
| Region #4, med kostnad > 3 og tilgjengelig >= etterspørsel | |||
| #id | koste | tilgjengelig | etterspørsel |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Dette konseptet er enda kraftigere når det brukes på hele blokker i stedet for enkeltrader, når det brukes på komplekse predikater som bruker operatorer som ikke er egnet for tradisjonelle sorteringsteknikker (som f.eks. like), og når den brukes på mer enn to predikater.
Systemtabeller
Følgende Amazon Redshift-systemtabeller vil vise brukere om flerdimensjonale dataoppsett brukes på tabellene og spørringene deres:
- For å finne ut om en bestemt tabell bruker en flerdimensjonal datalayoutsorteringsnøkkel, kan du sjekke om
sortkey1in svv_tabellinfo er likAUTO(SORTKEY(padb_internal_mddl_key_col)). - For å finne ut om en bestemt spørring bruker flerdimensjonal dataoppsett for å akselerere tabellskanning, kan du sjekke
step_attributei sys_query_detail utsikt. Verdien vil være likmulti-dimensionalhvis tabellens flerdimensjonale datalayoutsorteringsnøkkel ble brukt under skanningen.
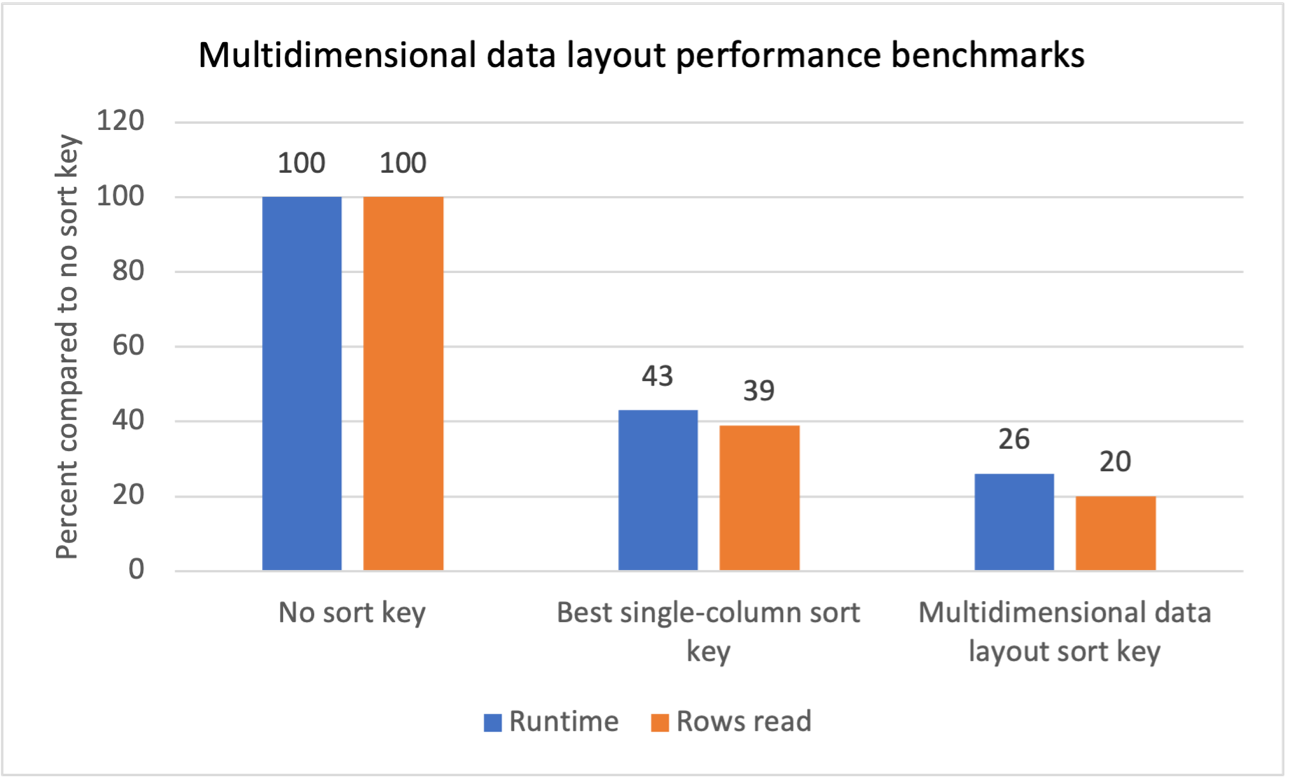
Ytelsesbenchmarks
Vi utførte intern benchmark-testing for flere arbeidsbelastninger med repeterende skanningsfiltre og ser at introduksjonen av flerdimensjonale datalayoutsorteringsnøkler ga følgende resultater:
- En total reduksjon på 74 % kjøretid sammenlignet med å ikke ha noen sorteringsnøkkel.
- 40 % total kjøretidsreduksjon sammenlignet med å ha den beste sorteringsnøkkelen med én kolonne på hver tabell.
- En 80 % reduksjon i antall rader som leses fra tabeller sammenlignet med å ikke ha noen sorteringsnøkkel.
- En reduksjon på 47 % i det totale antallet rader som er lest fra tabeller sammenlignet med å ha den beste sorteringsnøkkelen med én kolonne på hver tabell.
Funksjonssammenligning
Med introduksjonen av flerdimensjonale sorteringsnøkler for datalayout kan tabellene dine nå sorteres etter uttrykk basert på de vanlige filterpredikatene i arbeidsmengden din. Tabellen nedenfor gir en funksjonssammenligning for Amazon Redshift med to konkurrenter.
| Trekk | Amazon RedShift | Konkurrent A | Konkurrent B |
| Støtte for sortering på kolonner | Ja | Ja | Ja |
| Støtte for sortering etter uttrykk | Ja | Ja | Nei |
| Automatisk kolonnevalg for sortering | Ja | Nei | Ja |
| Automatisk valg av uttrykk for sortering | Ja | Nei | Nei |
| Automatisk valg mellom kolonnesortering eller uttrykkssortering | Ja | Nei | Nei |
| Automatisk bruk av sorteringsegenskaper for uttrykk under skanninger | Ja | Nei | Nei |
betraktninger
Husk følgende når du bruker et flerdimensjonalt dataoppsett:
- Flerdimensjonalt dataoppsett er aktivert når du setter tabellen som SORTKEY AUTO.
- Amazon Redshift Advisor vil automatisk velge enten en enkeltkolonne sorteringsnøkkel eller flerdimensjonal dataoppsett for tabellen ved å analysere den historiske arbeidsmengden din.
- Amazon Redshift ATO justerer de flerdimensjonale datalayoutsorteringsresultatene basert på måten pågående spørringer samhandler med arbeidsbelastningen.
- Amazon Redshift ATO opprettholder flerdimensjonale datalayoutsorteringsnøkler på samme måte som for eksisterende sorteringsnøkler. Referere til Arbeider med automatisk tabelloptimalisering for mer informasjon om ATO.
- Multidimensjonale datalayoutsorteringsnøkler vil fungere med både klargjorte klynger og serverløse arbeidsgrupper.
- Multidimensjonale datalayoutsorteringsnøkler vil fungere med dine eksisterende data så lenge AUTO SORTKEY er aktivert på tabellen og en arbeidsbelastning med repeterende skanningsfiltre oppdages. Tabellen vil bli omorganisert basert på resultatene av flerdimensjonal sorteringsfunksjon.
- For å deaktivere flerdimensjonale datalayoutsorteringsnøkler for en tabell, bruk endre tabell:
ALTER TABLE table_name ALTER SORTKEY NONE. Dette deaktiverer funksjonen AUTO sorteringsnøkkel på tabellen. - Flerdimensjonale sorteringsnøkler for dataoppsett bevares når du gjenoppretter eller migrerer den klargjorte klyngen til en serverløs klynge eller omvendt.
konklusjonen
I dette innlegget viste vi at flerdimensjonale datalayoutsorteringsnøkler kan forbedre ytelsen for spørringskjøring betydelig for arbeidsbelastninger der dominerende spørringer har repeterende skanningsfiltre.
For å opprette en forhåndsvisningsklynge fra Amazon Redshift-konsollen, naviger til klynger siden og velg Opprett forhåndsvisningsklynge. Du kan opprette en klynge i regionene øst for USA (Ohio), øst for USA (N. Virginia), vest i USA (Oregon), Asia Pacific (Tokyo), Europa (Irland) og Europa (Stockholm) og teste arbeidsmengdene dine.
Vi vil gjerne høre tilbakemeldingen din om denne nye funksjonen og ser frem til dine kommentarer til dette innlegget.
Om forfatterne
 Milind Oke er en Data Warehouse Specialist Solutions Architect basert i New York. Han har bygget datavarehusløsninger i over 15 år og spesialiserer seg på Amazon Redshift.
Milind Oke er en Data Warehouse Specialist Solutions Architect basert i New York. Han har bygget datavarehusløsninger i over 15 år og spesialiserer seg på Amazon Redshift.
 Jialin Ding er en Applied Scientist i Learned Systems Group, som spesialiserer seg på å bruke maskinlæring og optimaliseringsteknikker for å forbedre ytelsen til datasystemer som Amazon Redshift.
Jialin Ding er en Applied Scientist i Learned Systems Group, som spesialiserer seg på å bruke maskinlæring og optimaliseringsteknikker for å forbedre ytelsen til datasystemer som Amazon Redshift.
 Yanzhu Ji er produktsjef i Amazon Redshift-teamet. Hun har erfaring innen produktvisjon og strategi i bransjeledende dataprodukter og plattformer. Hun har enestående ferdigheter i å bygge betydelige programvareprodukter ved å bruke webutvikling, systemdesign, database og distribuerte programmeringsteknikker. I sitt personlige liv liker Yanzhu å male, fotografere og spille tennis.
Yanzhu Ji er produktsjef i Amazon Redshift-teamet. Hun har erfaring innen produktvisjon og strategi i bransjeledende dataprodukter og plattformer. Hun har enestående ferdigheter i å bygge betydelige programvareprodukter ved å bruke webutvikling, systemdesign, database og distribuerte programmeringsteknikker. I sitt personlige liv liker Yanzhu å male, fotografere og spille tennis.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- : har
- :er
- :ikke
- :hvor
- 1
- 100
- 15 år
- 15%
- 152
- 7
- 8
- 9
- a
- akselerere
- aksesseres
- Ytterligere
- rådgiver
- Etter
- mot
- algoritme
- Alle
- allerede
- Amazon
- Amazon Web Services
- an
- analysere
- analyserer
- og
- En annen
- anvendt
- påføring
- ER
- AS
- asia
- asia-stillehavet
- auto
- Automatisk
- automatisk
- tilgjengelig
- AWS
- basert
- BE
- fordi
- vært
- benchmark
- nytte
- BEST
- Bedre
- mellom
- Blokker
- Blocks
- Blå
- både
- Bygning
- men
- by
- CAN
- evne
- sjekk
- Velg
- Cloud
- Cluster
- Kolonne
- kolonner
- kombinasjon
- kommentarer
- vanligvis
- sammenlignet
- sammenligning
- konkurrenter
- komplekse
- konsept
- Vurder
- består
- Konsoll
- konstruere
- inneholder
- Kostnad
- dekker
- skape
- I dag
- dato
- datalager
- Database
- bestemme
- dedikert
- definere
- Etterspørsel
- krevende
- utforming
- detaljer
- oppdaget
- Bestem
- Utvikling
- distribueres
- distribusjon
- gjør
- dominerende
- ikke
- under
- hver enkelt
- øst
- enten
- aktivert
- Hele
- lik
- spesielt
- Eter (ETH)
- Europa
- evaluering
- Selv
- utviklet seg
- eksempel
- eksisterende
- erfaring
- uttrykkene
- Trekk
- tilbakemelding
- filtrere
- filtre
- etter
- følger
- Til
- Forward
- fire
- fra
- funksjon
- Gruppe
- hånd
- Ha
- å ha
- he
- høre
- her
- historisk
- historie
- Men
- HTML
- HTTPS
- ID
- if
- umiddelbart
- forbedre
- forbedrer
- in
- inkluderer
- individuelt
- bransjeledende
- i stedet
- samhandle
- intern
- intervensjon
- inn
- introdusere
- innføre
- Introduksjon
- Irland
- IT
- varer
- nøkkel
- nøkler
- stor
- Layout
- lært
- læring
- Life
- i likhet med
- liker
- Lang
- Se
- ser ut som
- elsker
- maskin
- maskinlæring
- opprettholder
- leder
- måte
- maksimal
- Møt
- metadata
- kunne
- Migrere
- tankene
- minimum
- mer
- mest
- flere
- Naviger
- Trenger
- Ny
- ny funksjon
- New York
- Nei.
- nå
- tall
- forekommende
- of
- off
- tilbudt
- Ohio
- on
- ONE
- pågående
- bare
- operatører
- optimalisering
- Optimaliserer
- Alternativ
- or
- rekkefølge
- Oregon
- original
- Annen
- ut
- enestående
- enn
- Pacific
- maleri
- del
- Spesielt
- Mønster
- ytelse
- utført
- personlig
- fotografering
- fysisk
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Post
- kraftig
- bevart
- Forhåndsvisning
- produsert
- Produkt
- Produktsjef
- Produkter
- Programmering
- egenskaper
- gir
- spørsmål
- raskt
- Lese
- reduksjon
- referere
- region
- regioner
- repeterende
- Krav
- gjenopprette
- resultere
- Resultater
- Kjør
- rennende
- går
- samme
- skanne
- skanning
- skanner
- Forsker
- Årstid
- se
- velg
- valgt
- utvalg
- server~~POS=TRUNC
- Tjenester
- sett
- hun
- Vis
- presentere
- viste
- vist
- Viser
- betydelig
- enkelt
- ferdighet
- So
- Software
- Solutions
- spesialist
- spesialisert
- spesialisert
- butikker
- Strategi
- I ettertid
- betydelig
- slik
- egnet
- Støtte
- system
- Systemer
- bord
- Ta
- lag
- teknikker
- tennis
- test
- Testing
- enn
- Det
- De
- deres
- derfor
- de
- denne
- tid
- titler
- til
- tokyo
- topp
- Totalt
- tradisjonelle
- to
- typen
- typisk
- us
- bruke
- brukt
- Bruker
- Brukere
- bruker
- ved hjelp av
- verdi
- Verdier
- vice
- Se
- Virginia
- syn
- Warehouse
- var
- Vei..
- we
- web
- Webutvikling
- webtjenester
- Vest
- når
- om
- hvilken
- allment
- vil
- med
- uten
- Arbeid
- ville
- år
- york
- du
- Din
- zephyrnet