University of Maryland, Baltimore County Bina lab er et tverrfaglig forskningslaboratorium for bruk av avansert datasyn, maskinlæring (ML) og fjernmålingsteknikker for å oppdage ny kunnskap om miljøet vårt, spesielt i de arktiske og antarktiske områdene. Laboratoriets arbeid støttes av NSF BIGDATA-priser (IIS-1947584, IIS-1838230), NSF HDR Institute-prisen (OAC-2118285), og Amazon ML forskning pris for klimaendringer. Nylig ble Bina Lab tildelt av National Science Foundations Harnessing the Data Revolution (NSF HDR) for å støtte instituttet for utnyttelse av data og modellrevolusjon i polarområdene (referert til som iHARP). For å lære mer og bidra til ML-forskningsaktiviteter, besøk iHARPs nettsted på i-harp.org.
iHARP samarbeider aktivt med NASA, Amazon Research og AWS for å utføre avansert forskning innen dataanalyse og modellering i de arktiske og antarktiske områdene ved bruk av datavitenskap, ML og AI. Teamet av forskere ved iHARP, under ledelse av Dr. Maryam Rahnemoonfar og Dr. Masoud Yari, jobber med å avdekke datainnsikt om trender knyttet til tykkelsen på isdekkene, nivået av snøakkumulering og smeltehastigheten. Alle disse faktorene gir viktige indikatorer på klimaendringer. Prosessen med datainnsamling og forberedelse fortsetter å være svært arbeidskrevende til tross for betydelige teknologiske fremskritt innen fjernmålingsteknikker. Utfordringene forsterkes av behovet for å sile gjennom enorme mengder bilder samlet over år for å oppdage meningsfulle mønsterendringer. Videre introduserer bilder av varierende kvalitet degradering i analyseprosessen. Mens de trente lokale semantiske segmenterings- og konturdeteksjonsmodeller, klarte ikke iHARP-forskerne å trekke ut laggrense- og konturforutsigelser med den nøyaktigheten de trengte til tross for omfattende bildeforbehandlingsoppgaver.
Med demokratisering av teknologier som gjør det mulig å drive dyplæringstrening i skyen til en brøkdel av kostnaden og tiden sammenlignet med lokale, bestemte iHARP-forskerne seg for å bygge ML-arbeidsflytene sine på Amazon SageMaker. Dette gjorde det mulig for teamet å adressere skalerbarhetskrav, forbedre deres eksisterende automerkingsmodeller og akselerere aktiv læring med mennesker i løkken, noe som muliggjorde samarbeid mellom domeneforskere og dataforskere. Sluttmålet var å gjøre sporing av polare islag mer nøyaktig og mindre tidkrevende. I dette innlegget dokumenterer vi resultatene av samarbeidet mellom forskere ved iHARP og AWS for å løse brukssaken for arktisk isanalyse. Spesifikt leder vi deg gjennom følgende emner:
- Hva er arktisk isanalyse?
- En tilnærming for bruk av ML for arktisk isanalyse
- Skalerbar ML med SageMaker
- Aktiv læringsarbeidsflyt med Amazon Augmented AI (Amazon A2I) og SageMaker
Hva er arktisk isanalyse?
Glaciologi er en gren av miljøvitenskap med fokus på is og dens egenskaper. 71 % av planeten vår består av vann, så is har en viktig rolle å spille når det gjelder å påvirke det globale klimaet (mer om emnet kan finnes i Seks måter tap av arktisk is påvirker alle). Smeltingen av polare iskapper (Arktis og Antarktis) fører til at planeten vår blir utsatt for økt varme fordi vi nå har mindre is til å reflektere varme tilbake til verdensrommet. Når isen smelter, forårsaker det en økning i havnivåstigning (SLR), som er en global bekymring. Økende vannstand kan føre til farlige flom, spesielt i kystområder og øyer.
Ifølge en FN-studie fra 2019 har mennesker en gjennomsnittlig levetid på 72.6 år. Vår tid på denne planeten er begrenset. Ifølge artikkelen Grunnleggende om iskjerne, har vi tilgang til iskjerne (sylindriske blokker boret gjennom isdekker, med det yngste islaget på toppen og det eldste laget nederst) rekorder som går tilbake med minst 800,000 XNUMX år. For at forskning skal være effektiv, må vi få tilgang til og analysere så mye data vi kan for å avdekke sammenhenger mellom islagsmønsterendringer og tidligere klimatiske hendelser. Det er imidlertid matematisk umulig for oss å analysere alle tilgjengelige data. Det er her ML og AI kommer inn for å låne ut et nevralt nett eller to for å få fart på sakene!
Så, hva mener vi egentlig med analyse av isdata? Det er den arbeidskrevende prosessen med å gå gjennom millioner eller til og med milliarder av radar-, spektroskopiske, fotografiske bilder, tabelldata og klimatologiske data for å kartlegge islagene, se etter endringer i islagene over tid, identifisere klimatiske hendelser og finne mønstre som beviser sammenhengen mellom hva som skjer med is og dens effekt på klimaet. For å akselerere denne oppgaven trenger vi en kraftig datamaskin, evnen til å lese, forstå og tolke bilder, evnen til å se etter tilsynelatende små endringer i disse bildene som skjer gradvis gjennom tusenvis av bilder, evnen til å relatere disse endringene til hendelser som er merkbare i matematiske, tabell- og sensoravlesninger og mer. Med de nylige fremskrittene innen ML-algoritmer og -teknikker, og tilgjengeligheten av superdatamaskiner til en brøkdel av prisen med cloud computing, er forskere ivrige etter å dra nytte av skybasert ML for å utforske og utvinne arktiske og antarktiske data.
Et av de første og kanskje viktigste trinnene i den arktiske isanalyseprosessen er å skille de forskjellige islagene med betydelig nøyaktighet. Dette er fordi dette trinnet informerer resten av trinnene i prosessen. Dette kan vi oppnå ved å trene en ML-modell ved hjelp av veiledet læring for å oppdage islag fra radarbilder, for eksempel. For å oppnå nøyaktigheten vi trenger, krever vi store mengder annoterte data. Utfordringen var ikke tilgjengeligheten av data; det er en stor mengde heterogene radardata fra polarområdene som er samlet inn gjennom dyre oppdrag. Men under eksperimenteringen innså vi at kvaliteten på merknadene for disse dataene ikke var tilstrekkelig til å trene en modell med den nøyaktigheten vi trengte. I de neste avsnittene viser vi deg hvordan vi løste denne utfordringen.
En tilnærming for arktisk isanalyse ved bruk av ML
På IEEE Big Data-konferansen i 2019 publiserte forskerne våre, Dr. Maryam og Dr. Masoud, sammen med kolleger fra University of Kansas og University of Colorado artikkelen. Smart sporing av interne islag i radardata via flerskalalæring. Denne artikkelen detaljerte eksperimentering med ML, spesielt kantdeteksjonsmodeller som bruker multi-skala dyplæringsmodeller (som Holistically-Nested Edge Detection (HED)), for å spore laggrensene i radarbilder av islag. Den utvidede versjonen av denne forskningen er publisert i Dyp flerskalalæring for automatisk sporing av interne islag i radardata i Journal of Glaciology i 2020.
NASA har samlet inn data fra polare områder i mange tiår. NASA sine ICESat og ICESat-2 og Drift IceBridge er fremtredende eksempler på denne innsatsen. Operasjon IceBridge ble utført som en bro mellom de to ICESat-oppdragene i 11 år for å samle inn polarundersøkelser ved hjelp av luftbårne sensorer, som radar. Fordelen med å bruke radarsensorer er at bølgene kan trenge inn under isoverflaten. Disse dataene representerer imidlertid et øyeblikksbilde i tid, og er knyttet til geospatiale koordinater. Operasjon IceBridge ga petabyte med offentlig tilgjengelige rådata, og manuell analyse var en stor utfordring. For eksempel viser følgende figur et radarbildesegment som ble samlet inn på Grønland i 2012. Den horisontale retningen er flysporet, og den vertikale retningen er snødybden. Enhetene per bildepiksel vises på bildet.

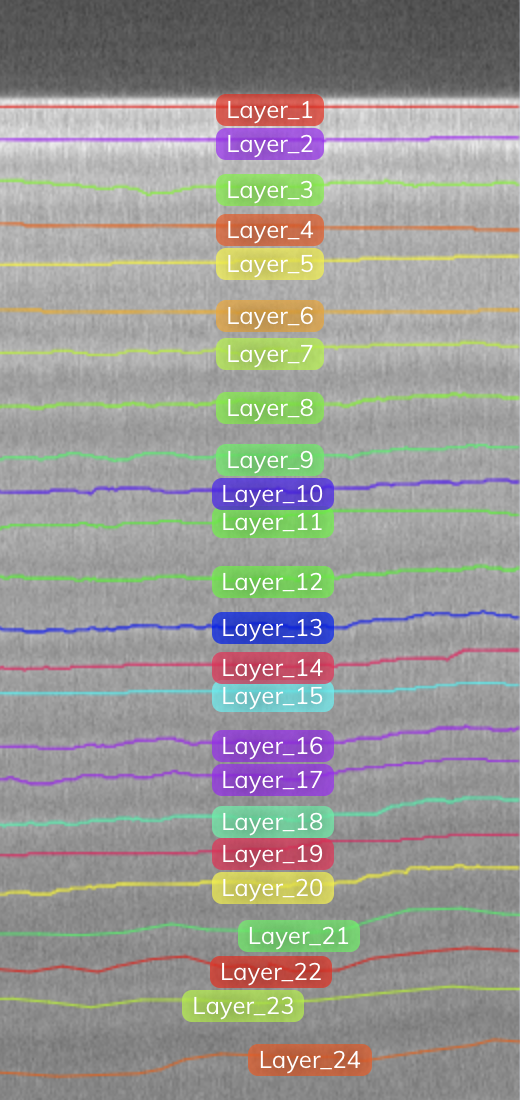
Følgende figur viser det samme bildet med lagkommentarene som ble tegnet manuelt. Den aller første grenselinjen (merket som Layer-1) er snøoverflaten; hvert påfølgende lag under den representerer den årlige opphopningen av snø i tidligere år. Målet vårt er å oppdage lagene og til slutt beregne tykkelsen på lagene, men dette var bare for ett segment av bare én ramme! Vi ønsket å kunne skalere og kartlegge islagene over hele Grønland!

I hovedsak ønsker vi at modellene våre skal kunne forutsi alle lagene, som vist i følgende figur (som inkluderer originalbildet og et kommentert bilde av alle lagene). Dette er et eksempel på et bilde med veldig stramme og falmede lag. Det er imidlertid andre problemer å passe på, for eksempel støy og gjenstander, som diskusjonen ligger utenfor rammen av dette innlegget.
 |
 |
Oppsummert, i deres IEEE 2019 og JOG 2020 papir, registrerte forskerne følgende observasjoner fra deres eksperimenter om effektiviteten av å bruke dyp læring for radarbildemerking:
- De fleste av de velkjente dyplæringstilnærmingene fungerer veldig bra på normale bilder, men ble ikke funnet å gi akseptable resultater i nærvær av støy. Det faktum at dyplæringsmodeller ikke er robuste med hensyn til støy er diskutert i ulike arbeider.
- Overføringslæringsmetoder fungerer ikke bra for radarbilder, mens trening fra bunnen av gir langt bedre resultater.
- Trening fra bunnen av krever kommenterte data levert av domeneekspertene. Generering av gode syntetiske data kan være en løsning for mangel på annoterte data.
Basert på disse observasjonene innså vi at vi måtte ta hensyn til visse hensyn:
- Datasettet vårt under eksperimentering ville være av lav størrelse (omtrent 5,000 bilder). Vi trengte imidlertid å fremtidssikre arkitekturen for å skalere etter behov.
- Vi trengte å veve inn vår eksisterende halvautomatiske løsning for lagsporing (ved å bruke modellen nevnt i IEEE-papiret).
- Tilnærmingen bør bruke et delvis kommentert datasett vi hadde (vi har ikke tid eller ressurser til å kommentere datasettet fullt ut).
- Vi trengte evnen til å distribuere et aktivt læringsrammeverk slik at modellen kan utvikles ved å bruke tilbakemeldinger fra menneskelige anmeldere. Den aktive læringstilnærmingen ville finne en mellomting som lar domeneforskere endre modellspådommer.
Sluttmålet var selvfølgelig å maksimere modellnøyaktigheten i lagprediksjoner.
Skalerbar ML med SageMaker
SageMaker er en fullt administrert ML-tjeneste. SageMaker tilbyr et integrert Jupyter-miljø for forfatterskap og eksperimentering, og et nettbasert visuelt grensesnitt kalt SageMaker Studio, hvor du kan utføre alle ML-utviklingstrinn med full tilgang, kontroll og synlighet. SageMaker sørger for og administrerer infrastrukturen som kreves for opplæring og hosting. SageMaker tilbyr også vanlige ML-algoritmer som er optimalisert for å kjøre effektivt mot ekstremt store data i et distribuert miljø. Med innebygd støtte for ta med-din-egen-algoritmer og rammeverk, tilbyr SageMaker fleksible distribuerte opplæringsalternativer som tilpasser seg tilpassede arbeidsflyter. Opplæring og hosting faktureres etter minutter med bruk, uten minimumsavgifter og ingen forhåndsforpliktelser.
Vi fant SageMaker godt egnet for kravene våre på grunn av dens evne til å skalere, dens fleksibilitet til å støtte våre tilpassede ML-algoritmer, det faktum at vi kunne komme raskt i gang på grunn av brukervennlighet, og enda viktigere muligheten til å sette opp aktiv læring ved hjelp av Amazon A2I. For å fortsette eksperimenter med vår semantiske segmenteringsmodell ved bruk av SageMaker, designet vi følgende arkitektur.

Last ned og forhåndsbehandle bilder
Vi bruker offentlig tilgjengelige data. For å trene modellen vår brukte vi radardata tilgjengelig på Nasjonalt snø- og isdatasenter. Delvise merknader av islagene er tilgjengelige for bruk. Imidlertid er ikke alle lag til stede i merknaden, noe som kan skjeve resultatene. Som et første trinn lastet vi ned det rå datasettet til en Amazon enkel lagringstjeneste (Amazon S3) bøtte. Vi sørget for en SageMaker Jupyter notatbok, som vi hentet bildene med og konverterte dem til RecordIO format, som optimerer lagring og muliggjør strømming av data i pipe-modus for raskere trening. RecordIO-filene blir deretter lastet opp tilbake til Amazon S3 som tog- og testdatasett.
Tren flerskala-lagsporingsmodellen på SageMaker
Vi opprettet en Python-fil som et inngangspunkt som inneholdt koden for vår flerskala-lagsporingsalgoritme. Vi brukte SageMaker MXNet estimator som en innpakning for vårt CNN, og vi brukte SageMaker Python SDK for å initialisere estimatoren, konfigurere hyperparametrene og kjøre treningen. Vi utførte hyperparameteroptimalisering med SageMaker automatisk modell tuner for å finne de optimale innstillingene som ga oss de beste resultatene.
Host modellen på SageMaker og kjør spådommer
Når modellopplæringen var fullført, ble artefaktene automatisk sendt til en S3-bøtte av SageMaker. Før vi kunne kjøre bulkprediksjon av merknader for bildene våre, ønsket vi i det eksperimentelle stadiet å sette opp et sanntidsendepunkt, kjøre tester på prediksjonskvalitet og muliggjøre aktiv læring. For å sette opp sanntidsslutning, vi først laget modellpakken, deretter opprettet en endepunktkonfigurasjon som spesifiserte forekomsttypen vi ønsket for hosting, sammen med detaljer om hvorvidt vi ønsket å kjøre flere versjoner samtidig. Vi valgte ikke dette alternativet da vi var i det eksperimentelle stadiet, men for flere detaljer, se Distribuer en modell i Amazon SageMaker. Til slutt, vi opprettet endepunktet. For å kjøre spådommer brukte vi et forhåndsbehandlet testdatasett med bilder som vi sendte til det vertsbaserte endepunktet. Modellen returnerte JSON-kommentarene for laggrensene fra inngangsbildet vårt, og vi vedvarte merknadskoordinatene og bildet i en S3-bøtte.
Å bringe modellen vår til SageMaker var selvfølgelig det første trinnet, men dette ga oss grunnlaget vi trengte for raskt å innovere og akselerere eksperimenteringen vår. I neste avsnitt viser vi deg hvordan vi brukte Amazon A2I med SageMaker for å lage en fullt funksjonell arbeidsflyt for aktiv læring.
Sett opp en aktiv læringsarbeidsflyt med Amazon A2I
Amazon A2I gjør det enkelt å legge til menneskelig vurdering i ML-arbeidsflyten din. Amazon A2I har innebygde arbeidsflyter for menneskelig gjennomgang for vanlige ML-brukstilfeller, for eksempel innholdsmoderering og tekstutvinning fra dokumenter. Du kan også lage dine egne arbeidsflyter for ML-modeller bygget på SageMaker eller andre verktøy. Med Amazon A2I kan du tillate menneskelige anmeldere å trå til når en modell ikke er i stand til å lage en høysikkerhetsprediksjon eller revidere sine spådommer fortløpende. Amazon A2I tilbyr forhåndsbygde maler for å lage oppgave-UI-sider for gjennomgang av lyd, bilder, tekst og video, og du kan tilpasse malene for dine behov. For vårt bruk laget vi en tilpasset væskemal ved hjelp av en crowd-polyline element. Dette muliggjorde implementering av aktiv læring fordi menneskelige anmeldere (våre forskere) nå kunne samhandle med et oppgavegrensesnitt (en nettside) for å fullføre følgende trinn:
- Evaluer det originale delvis kommenterte inngangsbildet.
- Sammenlign de forutsagte merknadene fra modellen med det originale delvis kommenterte inngangsbildet.
- Bruk det interaktive oppgavegrensesnittet til å oppdatere eller endre de forutsagte merknadene og bildet, og sende inn for omskolering.
Først veileder vi deg gjennom hvordan du setter opp en menneskelig anmeldelse med Amazon A2I. Deretter viser vi deg hvordan du aktiverer omskolering og fullfører den aktive læringsarbeidsflyten.
Opprett en arbeidsoppgavemal
Sørg først for alt Amazon A2I-forutsetninger er møtt. Dette inkluderer å sette opp S3-bøtter for input og output, AWS identitets- og tilgangsadministrasjon (IAM) roller, og en arbeidsstyrke for arbeidsflytene for menneskelig gjennomgang.
Deretter oppretter vi oppgavegrensesnittet ved å bruke en arbeidsoppgavemal i SageMaker. Arbeidsoppgavemalen er en HTML-fil som gjør at brukergrensesnittet kan skreddersys for å passe brukssaken for menneskelig vurdering. For å komme i gang inkluderer SageMaker et bredt utvalg av HTML-komponenter for å bygge et tilpasset brukergrensesnitt. For denne brukssaken trenger vi at anmelderen kan oppdatere linjesegmenter på brukergrensesnittet som tilsvarer snølag i et bilde. Vi valgte å bruke crowd-form og crowd-polyline-elementene. Mengdeformelementet gir grunnleggende kontroller for brukergrensesnittet, for eksempel å sende inn resultater. Crowd-polyline-elementet lar brukeren samhandle med linjesegmenter på brukergrensesnittet, som brukes til å passe linjer på de enkelte snølagene.
Nå som vi har identifisert UI-komponentene som skal brukes, må vi inkludere modelldataene som skal samhandles med via UI. Crowd-polyline-komponenten inkluderer felt for å fylle ut startverdien, etiketter og kildebilde. Disse feltene brukes til å fylle ut snølagsdata så vel som bildet av snølagene. Etter at arbeidsgrensesnittet er gjengitt, kan anmelderen redigere og legge til flere linjesegmenter. For å hjelpe anmelderen inkluderte vi også den originale modellens utdata og merkede inngangsbilder sammen med crowd-polyline-editoren.
Følgende skjermbilde viser oppgavegrensesnittet når det er aktivert.

Følgende er en kodebit av malen:
Lag arbeidsflyten for menneskelig gjennomgang
Når oppgavemalen er fullført, går vi videre til å lage arbeidsflyten for menneskelig gjennomgang. Dette spesifiserer følgende:
- Arbeidsstyrken som oppgaver sendes til
- Oppgavemalen opprettet i forrige trinn
- Resultatet utdataplassering
Vi kan lage arbeidsflyten via API eller Amazon A2I-konsollen. Se Lag en menneskelig gjennomgang arbeidsflyt for mer informasjon.
Start menneskelige gjennomgangsløkker
På dette tidspunktet har vi laget vår oppgavemal og arbeidsflyt for menneskelig gjennomgang, som definerer hvordan vi vil at vårt gjennomgangsgrensesnitt skal se ut og fungere. Å starte menneskelige gjennomgangsløkker er det siste trinnet i Amazon A2I-prosessen. For hvert sett med merkede data og bilder oppretter vi en menneskelig gjennomgangsløkke for å skape miljøet for våre ansattes anmeldere. Se Opprett og start en menneskelig sløyfe for en tilpasset oppgavetype for mer informasjon.
De enkelte anmelderne oppretter en konto og logger inn for å utføre eventuelle vurderinger som er opprettet. Deretter velger de fra en liste over oppgaver som er tildelt dem, som vist på følgende skjermbilde.

Etter å ha valgt en oppgave, ser de oppgavegrensesnittet som ble bygget med de tilpassede HTML-komponentene. Til slutt sender brukeren inn sine oppdateringer etter å ha tilpasset polylinjene til snølagene.

Aktiver omskolering
Følgende diagram viser den oppdaterte arkitekturen med aktiv læring implementert.

Nå som den menneskelige gjennomgangssløyfen er på plass for å endre merknader, må vi sende resultatene tilbake til prosessen for å implementere automatisert omskolering etter at en kritisk masse bilder har blitt korrigert av anmelderne. Når vi fullfører dette trinnet, er arkitekturen vår fullt aktivert for aktiv læring. I vårt tilfelle bestemte vi oss for at omskolering skulle utløses etter hver 100 bildekorrigering. Bildene med de korrigerte merknadene lagt over lagres i en S3-bøtte, og vi lagrer også merknadskoordinatene sammen med deres tilsvarende S3-bildeprefiks i en Amazon DynamoDB tabell for enkel gjenfinning og indeksering.
Konklusjon og neste steg
I dette innlegget gikk vi gjennom hvordan vi brukte SageMaker og Amazon A2I for å sette opp en aktiv lærings-ML-arbeidsflyt for å forbedre annoteringsnøyaktigheten til sporing av arktisk islag. Dette er en pågående eksperimentering for oss, og vi planlegger å publisere et følgeinnlegg for å dele resultatene i form av et svært nøyaktig annotert datasett av polare islag. Vi er alltid på utkikk etter samarbeidspartnere, så hvis dette høres interessant ut, søk oss på i-HARP.org eller gi oss tilbakemelding i kommentarfeltet.
Om forfatterne
 Prem Ranga spesialiserer seg på ML og AI hos AWS med en lidenskap for å hjelpe kunder med å løse NLP, CV og dyplæringsproblemer. Prem bygde de Alexa-kontrollerte ølstasjonene i Houston og andre steder. Prem er en Packt-forfatter. Du kan lese om denne og andre publikasjoner på https://www.linkedin.com/in/premkr/
Prem Ranga spesialiserer seg på ML og AI hos AWS med en lidenskap for å hjelpe kunder med å løse NLP, CV og dyplæringsproblemer. Prem bygde de Alexa-kontrollerte ølstasjonene i Houston og andre steder. Prem er en Packt-forfatter. Du kan lese om denne og andre publikasjoner på https://www.linkedin.com/in/premkr/
 Dr. Masoud Yari er forskningsprofessor ved iHARP Data Science Institute og Bina lab ved College of Engineering and Information Technology, University of Maryland, Baltimore County, MD. Hans forskningsinteresser inkluderer maskinlæring, datasyn, fjernmåling, matematisk modellering og dynamiske systemer. Han brenner for å oppdage handlingskraftig innsikt i data og lede tverrfaglige forskningsteam og prosjekter for å løse miljø- og humanitære problemer.
Dr. Masoud Yari er forskningsprofessor ved iHARP Data Science Institute og Bina lab ved College of Engineering and Information Technology, University of Maryland, Baltimore County, MD. Hans forskningsinteresser inkluderer maskinlæring, datasyn, fjernmåling, matematisk modellering og dynamiske systemer. Han brenner for å oppdage handlingskraftig innsikt i data og lede tverrfaglige forskningsteam og prosjekter for å løse miljø- og humanitære problemer.
 Brett Seib er en AWS Enterprise Solutions Architect basert i Austin, TX. Han brenner for å innovere og løse forretningsutfordringer med kunder. Brett har flere års erfaring i IoT- og Data Analytics-bransjene og hjelper kunder med å innovere med data.
Brett Seib er en AWS Enterprise Solutions Architect basert i Austin, TX. Han brenner for å innovere og løse forretningsutfordringer med kunder. Brett har flere års erfaring i IoT- og Data Analytics-bransjene og hjelper kunder med å innovere med data.
 Morgan Dutton er en AWS Technical Program Manager med Amazon Augmented AI og Mechanical Turk-teamet basert i Seattle, WA. Hun jobber med kunder i akademisk og offentlig sektor for å akselerere deres bruk av human-in-the-loop ML-tjenester. Morgan er spesielt interessert i å samarbeide med akademiske kunder for å støtte adopsjon av ML-teknologier av forskere, studenter og lærere.
Morgan Dutton er en AWS Technical Program Manager med Amazon Augmented AI og Mechanical Turk-teamet basert i Seattle, WA. Hun jobber med kunder i akademisk og offentlig sektor for å akselerere deres bruk av human-in-the-loop ML-tjenester. Morgan er spesielt interessert i å samarbeide med akademiske kunder for å støtte adopsjon av ML-teknologier av forskere, studenter og lærere.
 Maryam Rahnemoonfar, Ph.D., er PI og direktør for NSF datavitenskapsinstitutt-iHARP, direktør for Computer Vision and Remote Sensing Laboratory (Bina lab), og førsteamanuensis i AI og datavitenskap ved College of Engineering and Information Technology, UMBC. Hennes forskningsinteresser inkluderer Deep Learning, Computer Vision, Data Science, AI for Social Good, Remote Sensing og Document Image Analysis. Forskningsprosjektene hennes har blitt finansiert av flere priser, inkludert NSF HDR institute Award, NSF BIGDATA award, Amazon Academic Research Award, Amazon Machine Learning Award, Microsoft og IBM.
Maryam Rahnemoonfar, Ph.D., er PI og direktør for NSF datavitenskapsinstitutt-iHARP, direktør for Computer Vision and Remote Sensing Laboratory (Bina lab), og førsteamanuensis i AI og datavitenskap ved College of Engineering and Information Technology, UMBC. Hennes forskningsinteresser inkluderer Deep Learning, Computer Vision, Data Science, AI for Social Good, Remote Sensing og Document Image Analysis. Forskningsprosjektene hennes har blitt finansiert av flere priser, inkludert NSF HDR institute Award, NSF BIGDATA award, Amazon Academic Research Award, Amazon Machine Learning Award, Microsoft og IBM.
- '
- &
- 000
- 100
- 11
- 2019
- 2020
- 98
- adgang
- Logg inn
- aktiv
- Aktiviteter
- Ytterligere
- Adopsjon
- Fordel
- AI
- Alexa
- algoritme
- algoritmer
- Alle
- tillate
- Amazon
- Amazon maskinlæring
- Amazon SageMaker
- blant
- analyse
- analytics
- Apache
- api
- arkitektur
- Arctic
- Artikkel
- lyd
- revisjon
- austin
- Automatisert
- tilgjengelighet
- AWS
- Baltimore
- øl
- BEST
- Store data
- bigdata
- BRO
- bygge
- Bygning
- virksomhet
- cambridge
- saker
- utfordre
- endring
- Klima forandringer
- Cloud
- cloud computing
- CNN
- kode
- samarbeid
- Høyskole
- Colorado
- kommentarer
- Felles
- komponent
- Datamaskin syn
- databehandling
- Konferanse
- innhold
- innholdsmoderasjon
- fortsette
- fortsetter
- Korreksjoner
- fylke
- Opprette
- Kunder
- dato
- dataanalyse
- Data Analytics
- datavitenskap
- dyp læring
- Etterspørsel
- Gjenkjenning
- Utvikling
- Regissør
- dokumenter
- Edge
- redaktør
- Effektiv
- Endpoint
- Ingeniørarbeid
- Enterprise
- Enterprise Solutions
- Miljø
- miljømessige
- hendelser
- erfaring
- eksperter
- utdrag
- avgifter
- Felt
- Figur
- Endelig
- Først
- passer
- fleksibilitet
- flytur
- skjema
- format
- Fundament
- Rammeverk
- funksjon
- finansierte
- framtid
- Global
- god
- Hosting
- Hvordan
- Hvordan
- HTTPS
- stort
- menneske i løkka
- Humanitær
- IAM
- IBM
- ICE
- identifisere
- Identitet
- IEEE
- bilde
- bildeanalyse
- Inkludert
- Øke
- bransjer
- informasjon
- informasjonsteknologi
- Infrastruktur
- innsikt
- interaktiv
- IOT
- IT
- Jupyter Notebook
- Kansas
- kunnskap
- merking
- etiketter
- arbeidskraft
- stor
- føre
- Ledelse
- ledende
- LÆRE
- læring
- LÅNE
- Nivå
- Begrenset
- linje
- Flytende
- Liste
- lokal
- maskinlæring
- Making
- kart
- Maryland
- Microsoft
- ML
- ML-algoritmer
- modell
- modellering
- flytte
- Nasa
- nett
- neural
- nlp
- Bråk
- Tilbud
- Alternativ
- alternativer
- Annen
- Papir
- Mønster
- Ansatte
- rør
- pixel
- planet
- prediksjon
- Spådommer
- presentere
- program
- prosjekter
- bevis
- offentlig
- offentlig sektor
- publikasjoner
- publisere
- Python
- kvalitet
- radar
- område
- Raw
- rådata
- sanntids
- poster
- Relasjoner
- Krav
- forskning
- Ressurser
- REST
- Resultater
- omskolering
- anmeldelse
- Anmeldelser
- Kjør
- rennende
- sagemaker
- skalerbarhet
- Skala
- Vitenskap
- forskere
- SEA
- Havnivå
- Seattle
- sensorer
- Tjenester
- sett
- innstilling
- Del
- Enkelt
- Størrelse
- Snapshot
- snø
- So
- selskap
- Sosialt bra
- Solutions
- LØSE
- Rom
- spesialisert
- fart
- Scene
- Begynn
- startet
- lagring
- oppbevare
- streaming
- Studer
- superdatamaskiner
- støtte
- Støttes
- overflaten
- syntetiske data
- Systemer
- Teknisk
- teknikker
- Technologies
- Teknologi
- test
- tester
- tid
- topp
- temaer
- spor
- Sporing
- Kurs
- Trender
- ui
- avdekke
- forent
- forente nasjoner
- universitet
- University of Maryland
- Oppdater
- oppdateringer
- us
- verdi
- Hastighet
- video
- synlighet
- syn
- Se
- Vann
- bølger
- Weave
- Nettsted
- Arbeid
- arbeidsflyt
- arbeidsstyrke
- virker
- år


