Introduksjon
Innenfor akademisk forskning kan reisen fra rådata til innsiktsfulle konklusjoner være skremmende hvis du er nybegynner eller nybegynner. Men med riktig tilnærming og verktøy er det en utrolig givende opplevelse å transformere data til meningsfull kunnskap. I denne veiledningen vil vi lede deg gjennom en typisk arbeidsflyt for akademisk dataanalyse, ved å bruke et praktisk eksempel fra en nylig studie om effektiviteten til ulike dietter for vekttap.

Innholdsfortegnelse
Læringsmål
Vi bruker en avansert AI-dataverktøy - Julius, for å utføre analysen. Vårt mål er å avmystifisere den akademiske forskningsanalyseprosessen, og vise hvordan data, når de er nøye og riktig analysert, kan belyse fascinerende trender og gi svar på kritiske forskningsspørsmål.
Navigere i arbeidsflyten for akademisk data med Julius
I akademisk forskning er måten vi håndterer data på nøkkelen til å avdekke ny innsikt. Denne delen av guiden vår leder deg gjennom standardtrinnene for å analysere forskningsdata. Fra å starte med et klart spørsmål til å dele de endelige resultatene, er hvert trinn avgjørende.
Vi skal vise hvordan forskere ved å følge denne klare veien kan gjøre rådata om til pålitelige og verdifulle funn. Deretter vil vi lede deg gjennom hvert trinn i et eksempel på en case-studie, og viser deg hvordan du kan spare tid og samtidig sikre resultater av høyere kvalitet ved å bruke Julius gjennom hele prosessen.
1. Spørsmålsformulering
Begynn med å tydelig definere forskningsspørsmålet eller hypotesen. Dette veileder hele analysen og bestemmer metodene du skal bruke.
2. Datainnsamling
Samle de nødvendige dataene, og sørg for at de stemmer overens med forskningsspørsmålet ditt. Dette kan innebære å samle inn nye data eller bruke eksisterende datasett. Dataene bør inkludere variabler som er relevante for studien din.
3. Datarensing og forbehandling
Forbered datasettet for analyse. Dette trinnet innebærer å sikre datakonsistens (som standardiserte måleenheter), håndtere manglende verdier og identifisere eventuelle feil eller uteliggere i dataene dine.
4. Utforskende dataanalyse (EDA)
Gjennomfør en første undersøkelse av dataene. Dette inkluderer å analysere fordelingen av variabler, identifisere mønstre eller uteliggere og forstå egenskapene til datasettet ditt.
5. Metodevalg
- Bestemme analyseteknikker: Velg passende statistiske metoder eller modeller basert på dine data og forskningsspørsmål. Dette kan innebære å sammenligne grupper, identifisere relasjoner eller forutsi utfall.
- Betraktninger for metodevalg: Utvalget påvirkes av typen data (f.eks. kategorisk eller kontinuerlig), antall grupper som sammenlignes, og arten av relasjonene du undersøker.
6. Statistisk analyse
- Operasjonaliserende variabler: Om nødvendig, lag nye variabler som bedre representerer konseptene du studerer.
- Utføre statistiske tester: Bruk de valgte statistiske metodene for å analysere dataene dine. Dette kan innebære tester som t-tester, ANOVA, regresjonsanalyse, etc.
- Regnskap for kovariater: I mer komplekse analyser, inkludere andre relevante variabler for å kontrollere for deres potensielle effekter.
7. Tolkning
Tolk resultatene nøye i sammenheng med forskningsspørsmålet ditt. Dette innebærer å forstå hva de statistiske funnene betyr i praksis og vurdere eventuelle begrensninger.
8. rapportering
Sett sammen funnene, metodikken og tolkningene dine til en omfattende rapport eller akademisk oppgave. Dette bør være klart, konsist og godt strukturert for å effektivt kommunisere forskningen din.
Case Study Introduksjon
I denne casestudien undersøker vi hvordan ulike dietter påvirker vekttap. Vi har data inkludert alder, kjønn, startvekt, dietttype og vekt etter seks uker. Målet vårt er å finne ut hvilke dietter som er mest effektive for vekttap, ved å bruke ekte data fra ekte mennesker.
Spørsmålsformulering
I enhver forskning, som vår studie om dietter og vekttap, begynner alt med et godt spørsmål. Det er som et veikart for forskningen din, som veileder deg om hva du skal fokusere på.
Med diettdataene våre spurte vi for eksempel, Fører en bestemt diett til betydelig vekttap på seks uker?
Dette spørsmålet er enkelt og forteller oss nøyaktig hva vi trenger å se etter i dataene våre, som inkluderer detaljer som hver persons dietttype, vekt før og etter seks uker, alder og kjønn. Et tydelig spørsmål som dette sørger for at vi holder oss på sporet og ser på de riktige tingene i dataene våre for å finne svarene vi trenger.
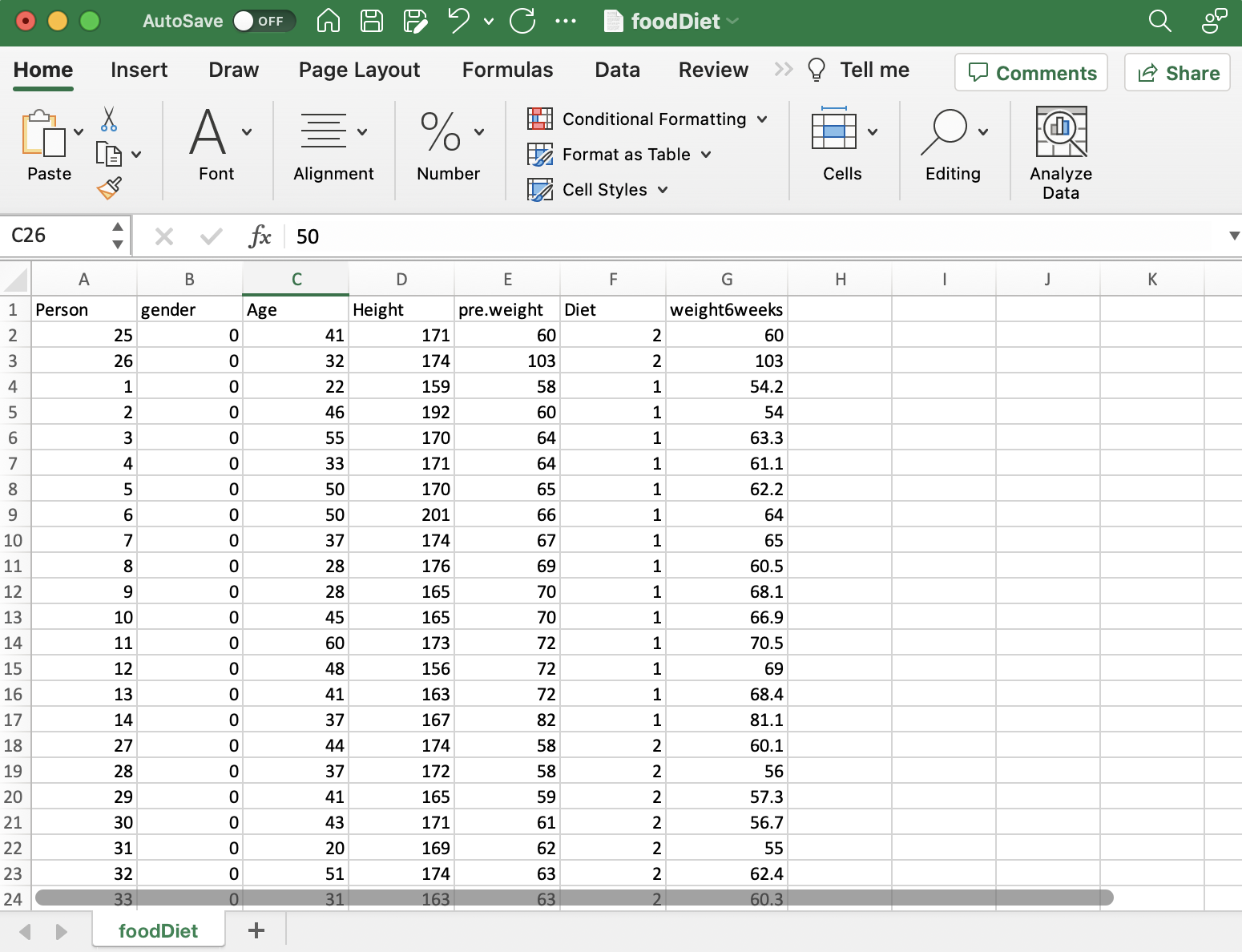
Datainnsamling
I forskning er innsamling av riktig data nøkkelen. For vår studie om dietter og vekttap, samlet vi informasjon om hver persons dietttype, vekt før og etter dietten, alder og kjønn. Det er viktig å sørge for at dataene passer til forskningsspørsmålet ditt. I noen tilfeller må du kanskje samle inn ny informasjon, men her brukte vi eksisterende data som allerede hadde alle detaljene vi trengte. Å få gode data er det første store skrittet for å finne ut hva du vil vite.
Datarensing og forbehandling
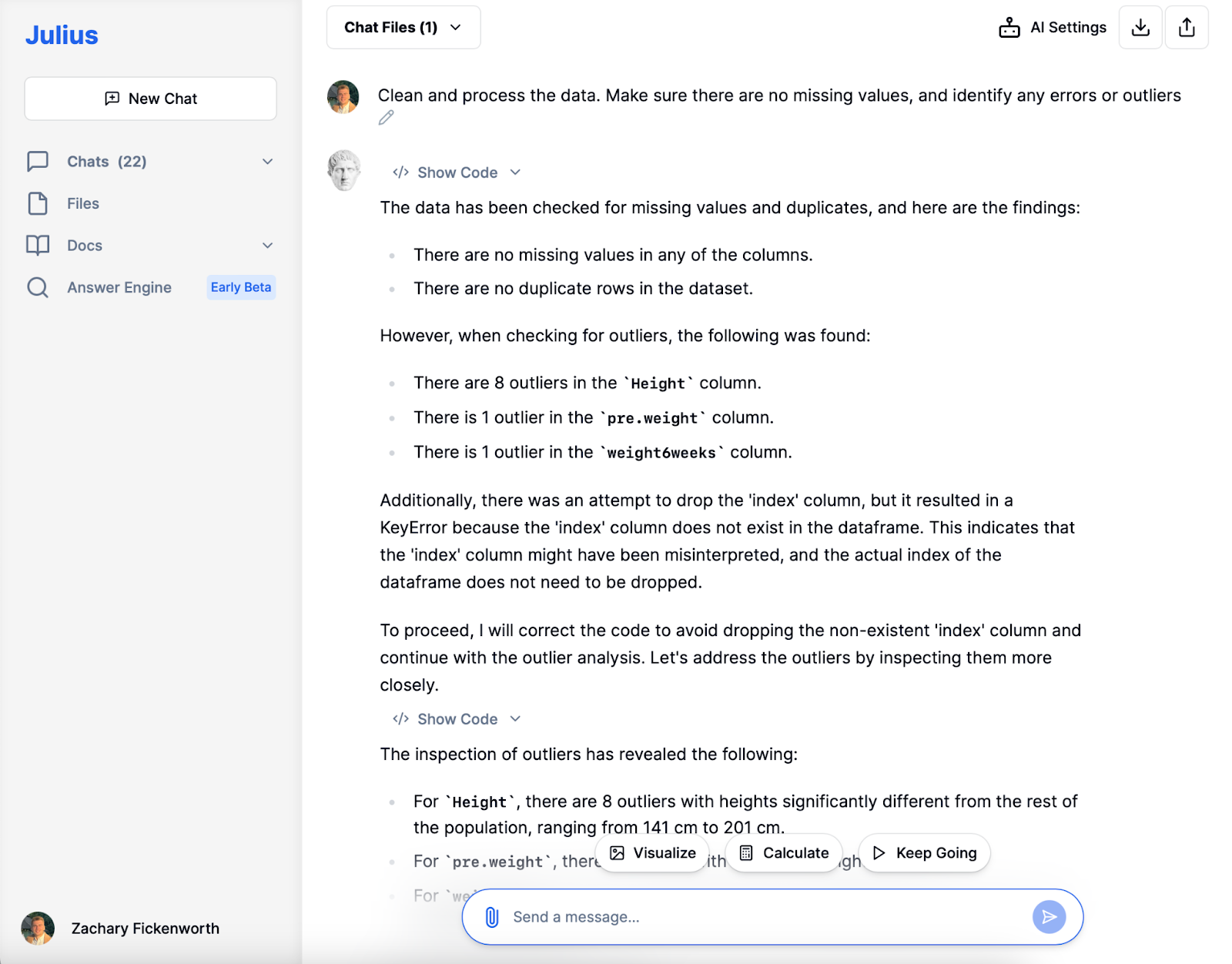
I vår diettstudie var datarensing med Julius sentralt. Etter å ha lastet inn dataene, identifiserte Julius manglende verdier og duplikater, noe som sørget for klarhet i datasettet. Mens vi bevarte høydeavvik for mangfold, valgte vi å ekskludere et individ med en eksepsjonelt høy vekt før diett (103 kg) for å opprettholde analyseintegritet, og sikre datasettberedskap for påfølgende stadier.
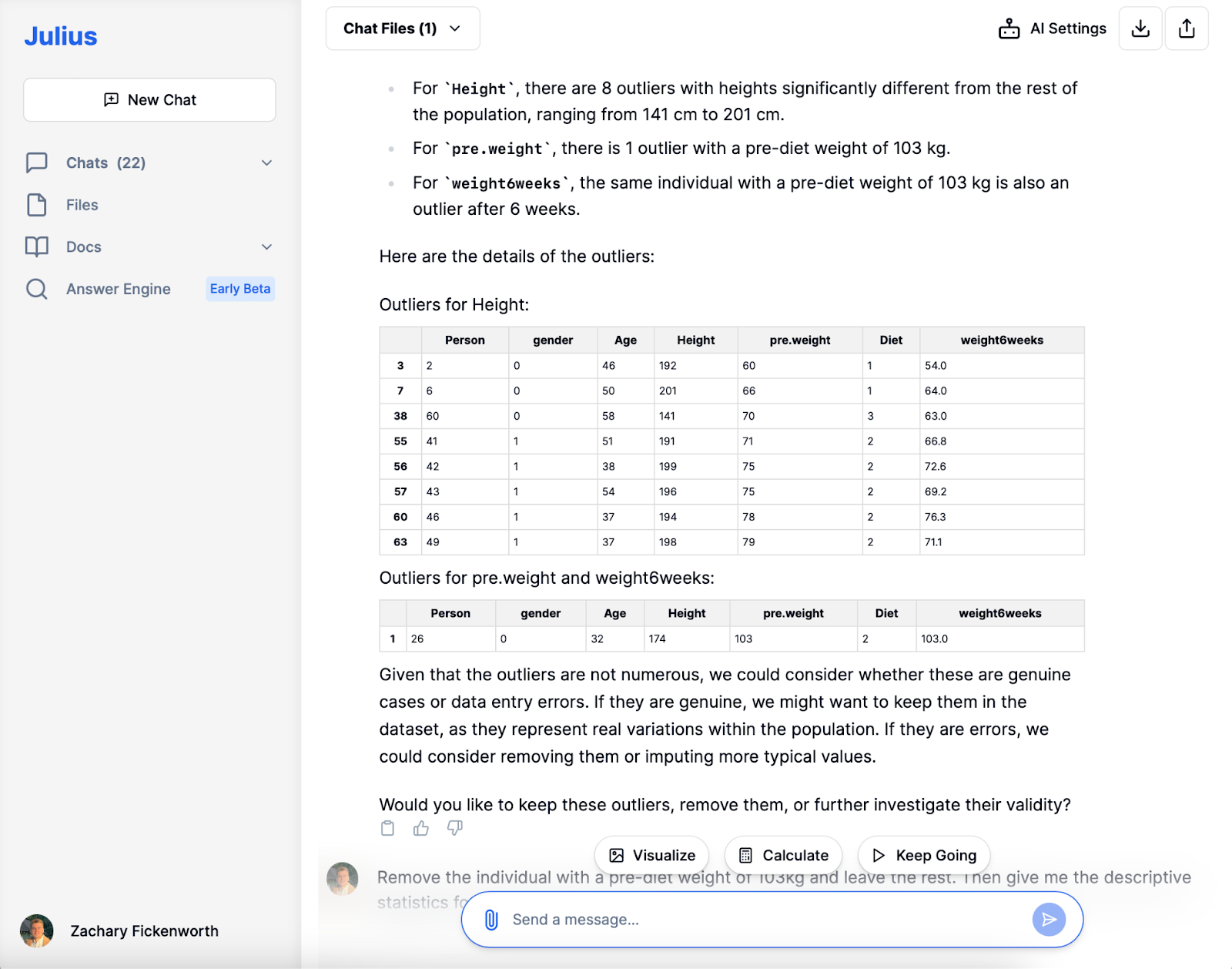
Utforskende dataanalyse (EDA)
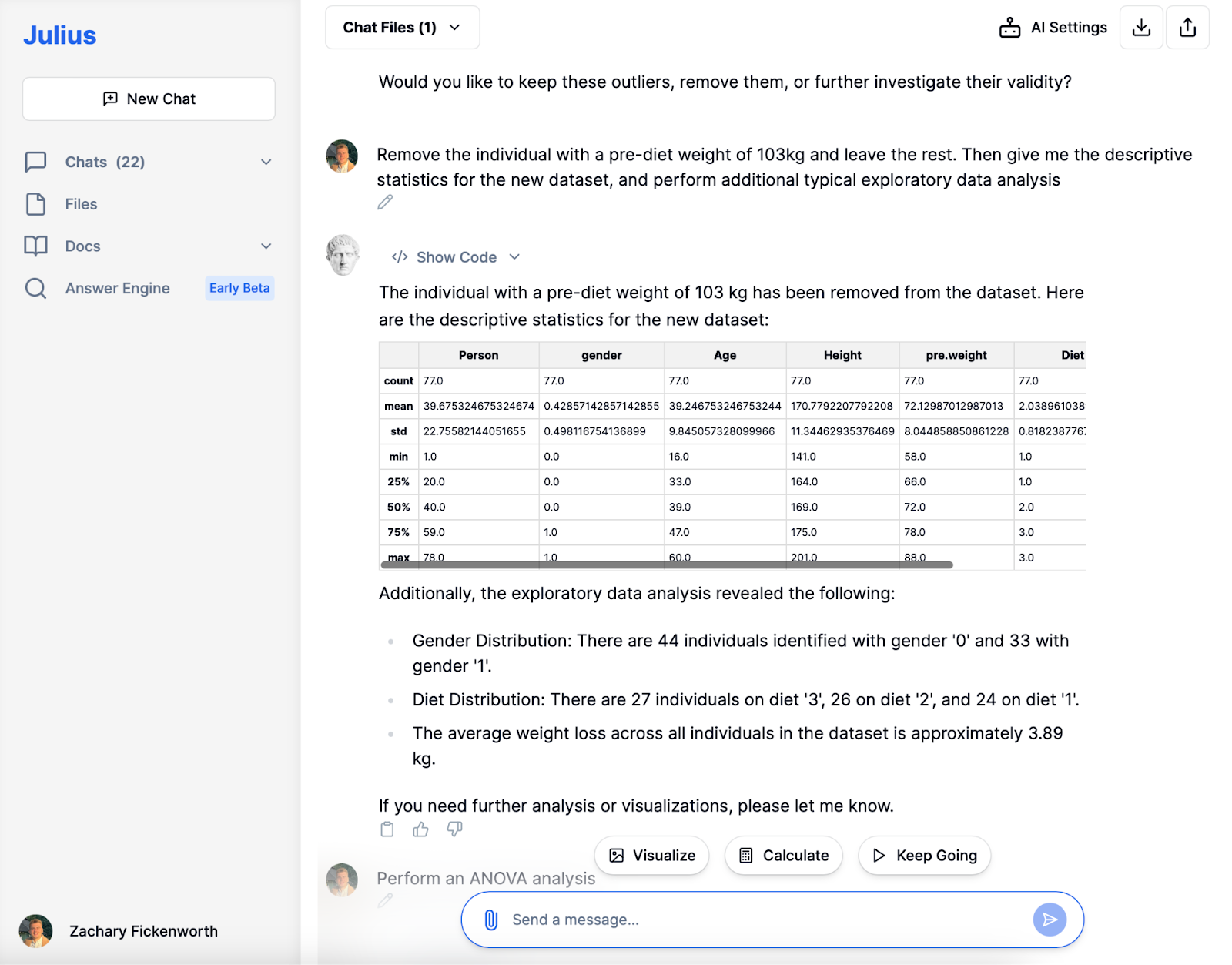
Etter fjerning av uteliggeren med en uvanlig høy vekt før diett, fordypet vi oss i den utforskende dataanalysefasen (EDA). Julius leverte raskt fersk beskrivende statistikk, og ga en klarere oversikt over våre 77 deltakere. Å oppdage en gjennomsnittlig vekt før diett på omtrent 72 kg og et gjennomsnittlig vekttap på rundt 3.89 kg ga verdifull innsikt.
Utover grunnleggende statistikk, la Julius til rette for en undersøkelse av kjønn og dietttypefordeling. Studien avdekket en balansert kjønnsfordeling og en jevn fordeling på ulike dietttyper. Denne EDA oppsummerer ikke bare data; den avslører mønstre og trender, avgjørende for dypere analyser. For eksempel setter forståelsen av gjennomsnittlig vekttap scenen for å bestemme den mest effektive dietten. Denne AI-drevne fasen etablerer grunnlaget for påfølgende detaljert analyse.
Metodevalg
I vår diettstudie var valg av de riktige statistiske metodene et avgjørende skritt. Vårt hovedmål var å sammenligne vekttap på tvers av ulike dietter, noe som direkte informerte vårt valg av analyseteknikker. Gitt at vi hadde mer enn to grupper (de forskjellige dietttypene) å sammenligne, var en variasjonsanalyse (ANOVA) det ideelle valget. ANOVA er kraftig i situasjoner som vår, hvor vi trenger å forstå om det er signifikante forskjeller i en kontinuerlig variabel (vekttap) på tvers av flere uavhengige grupper (dietttypene).
Men mens ANOVA forteller oss om det er forskjeller, spesifiserer den ikke hvor disse forskjellene ligger. For å finne ut hvilke spesifikke dietter som var mest effektive, trengte vi en mer målrettet tilnærming. Det var her Pairwise sammenligninger kom inn. Etter å ha funnet signifikante resultater med ANOVA, brukte vi Pairwise sammenligninger for å undersøke vekttapsforskjellene mellom hvert par av dietttyper.
Denne to-trinns tilnærmingen – som starter med ANOVA for å oppdage eventuelle generelle forskjeller, etterfulgt av parvise sammenligninger for å detaljere disse forskjellene – var strategisk. Det ga en omfattende forståelse av hvordan hver diett presterte i forhold til de andre, og sikret en grundig og nyansert analyse av diettdataene våre.
Statistisk analyse
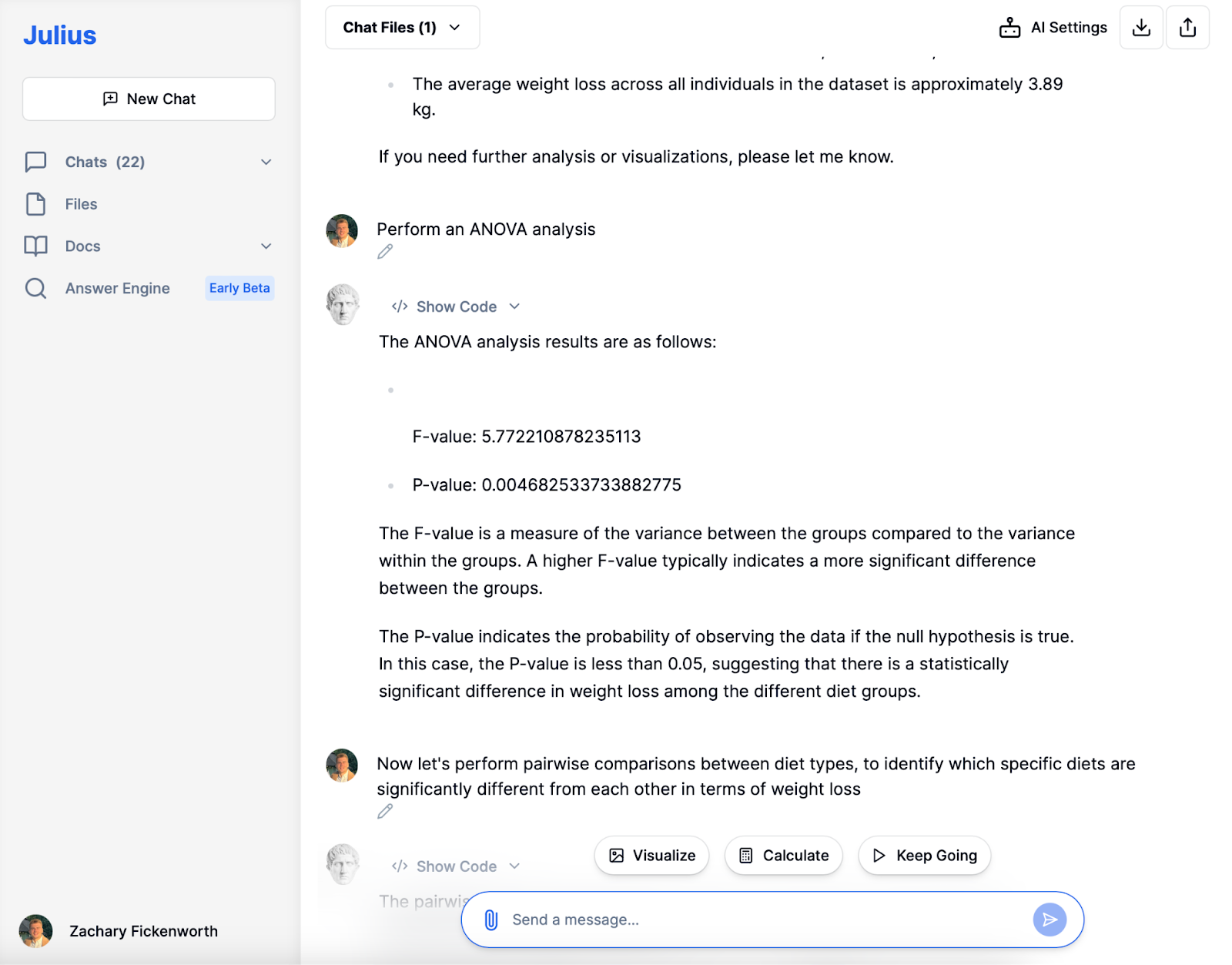
ANOVA
I hjertet av vår statistiske utforskning gjennomførte vi en ANOVA analyse for å forstå om vekttapsforskjellene mellom de ulike dietttypene var statistisk signifikante. Resultatene var ganske avslørende. Med en F-verdi på 5.772 antydet analysen en merkbar variasjon mellom diettgruppene sammenlignet med variansen innen hver gruppe. Denne F-verdien, som er høyere, indikerte signifikante forskjeller i vekttap på tvers av diettene.
Mer avgjørende var at P-verdien, på 0.00468, skilte seg ut. Denne verdien, som ligger godt under den konvensjonelle terskelen på 0.05, antydet sterkt at forskjellene vi observerte i vekttap blant diettgruppene ikke bare var tilfeldig. I statistiske termer betydde dette at vi kunne forkaste nullhypotesen – som ville anta ingen forskjell i vekttap på tvers av diettene – og konkludere med at typen diett faktisk hadde en betydelig innvirkning på vekttap. Dette ANOVA-resultatet var en kritisk milepæl, som førte til at vi undersøkte ytterligere nøyaktig hvilke dietter som skilte seg fra hverandre.
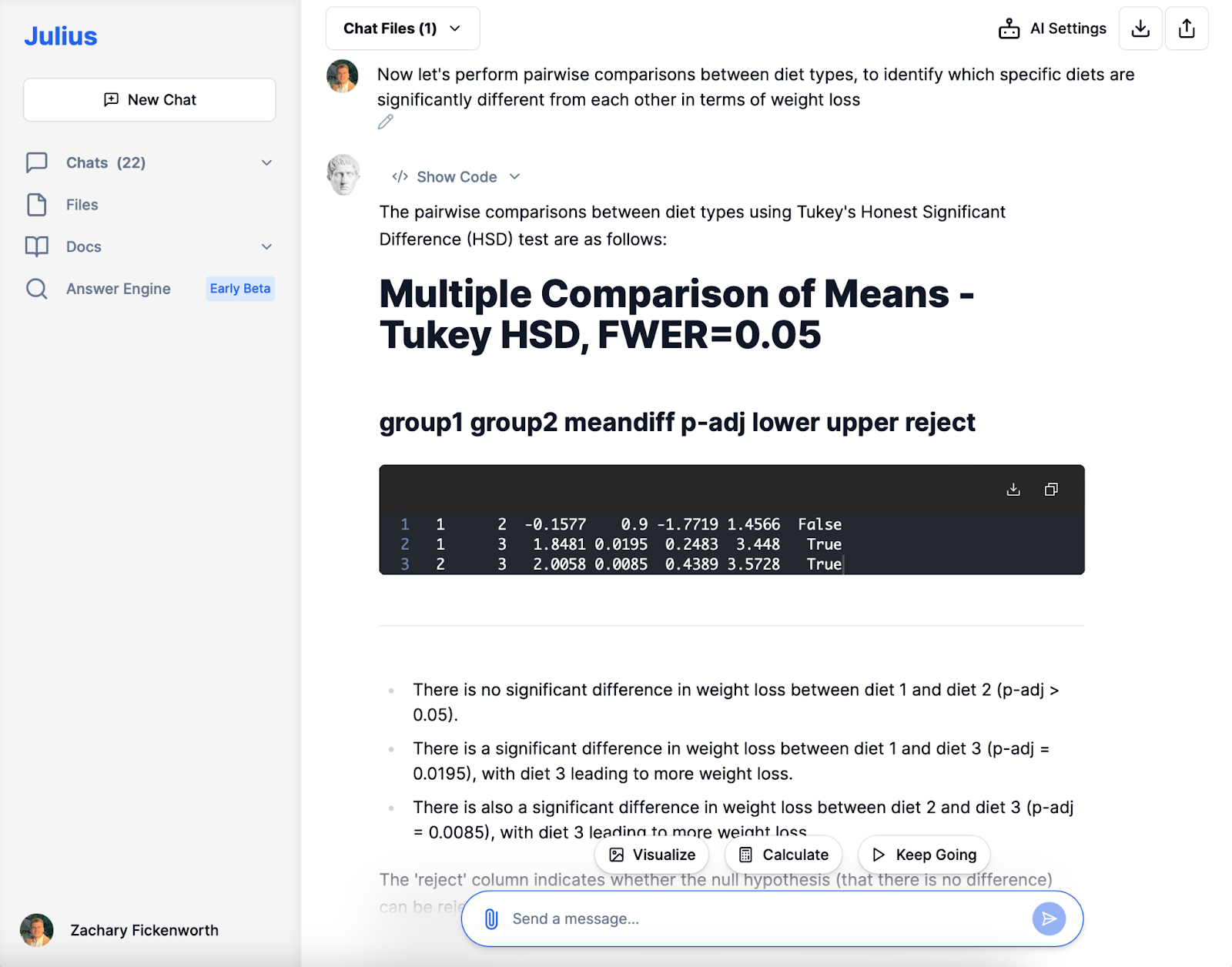
Parvis
I den følgende analysefasen med Julius gjennomførte vi parvise sammenligninger mellom dietttyper for å identifisere spesifikke forskjeller i vekttap. Tukey HSD-testen indikerte ingen signifikant forskjell mellom diett 1 og diett 2. Den avslørte imidlertid at diett 3 resulterte i betydelig større vekttap sammenlignet med både diett 1 og diett 2, støttet av statistisk signifikante p-verdier. Denne konsise, men likevel innsiktsfulle analysen av Julius spilte en sentral rolle i å forstå den relative effektiviteten til hver diett.
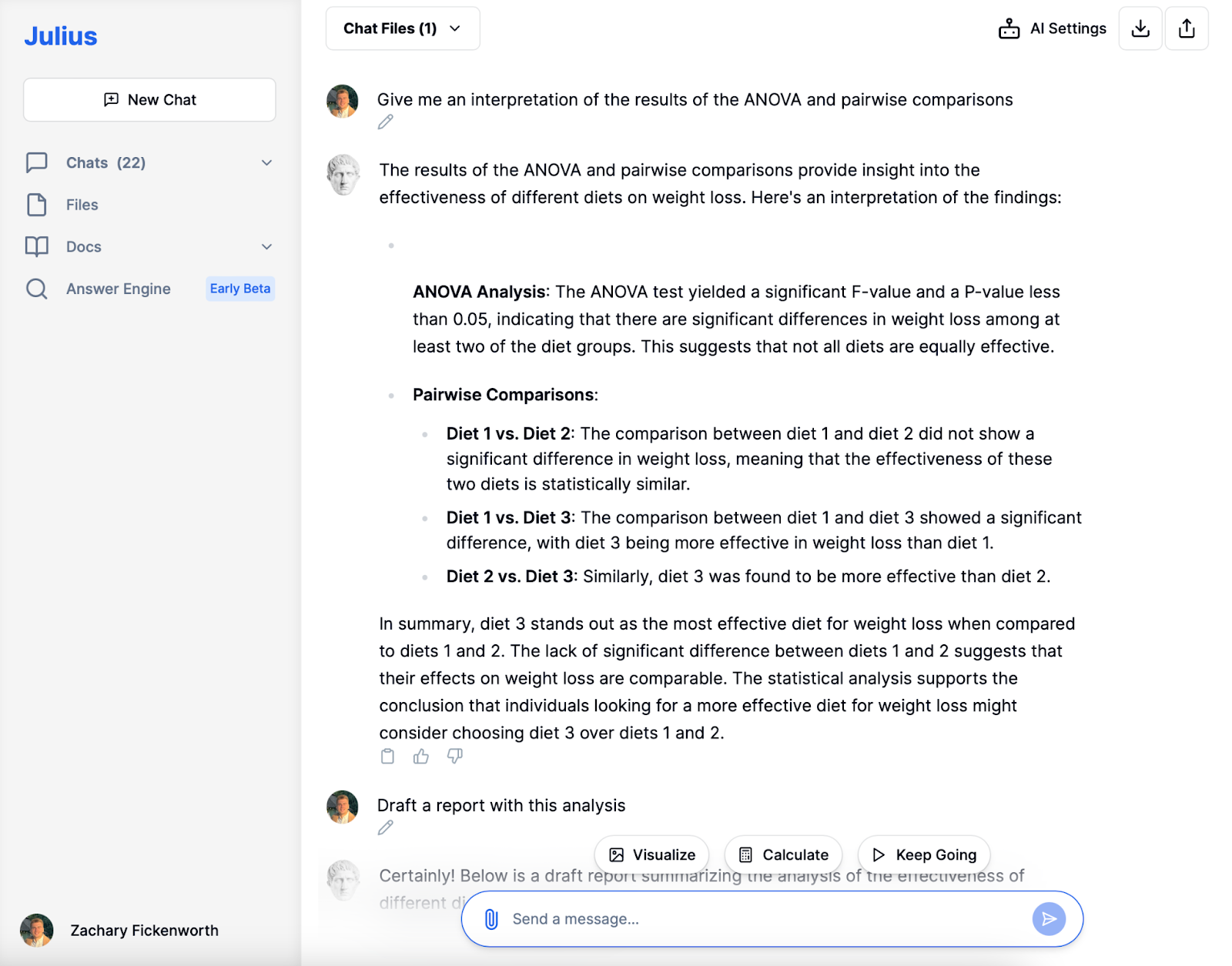
Tolkning
I vår studie om dietteffektivitet spilte Julius en nøkkelrolle i å tolke og forklare resultatene av ANOVA og parvise sammenligninger. Slik hjalp det oss å forstå funnene:
ANOVA tolkning
Den analyserte først ANOVA-resultatene, som viste en signifikant F-verdi og en P-verdi mindre enn 0.05. Dette indikerte at det var meningsfulle forskjeller i vekttap mellom de ulike diettgruppene. Det hjalp oss å forstå at dette betydde at ikke alle diettene i studien var like effektive for å fremme vekttap.
Tolkning av parvise sammenligninger
- Diett 1 vs. diett 2: Den sammenlignet disse to diettene og fant ingen signifikant forskjell i vekttap. Denne tolkningen betydde at disse to diettene statistisk sett var like effektive.
- Diett 1 vs. diett 3 og diett 2 vs. diett 3: I begge disse sammenligningene bekreftet jeg at diett 3 var betydelig mer effektiv for å fremme vekttap enn enten diett 1 eller diett 2.
Julius sin tolkning var avgjørende for å trekke konkrete konklusjoner fra vår analyse. Den presiserte at mens diett 1 og 2 var like i sin effektivitet, var diett 3 det fremtredende alternativet for vekttap. Denne tolkningen ga oss ikke bare et klart resultat av studien, men demonstrerte også de praktiske implikasjonene av funnene våre. Med denne informasjonen kan vi trygt foreslå at Diet 3 kan være det bedre valget for personer som søker effektive vekttapløsninger.
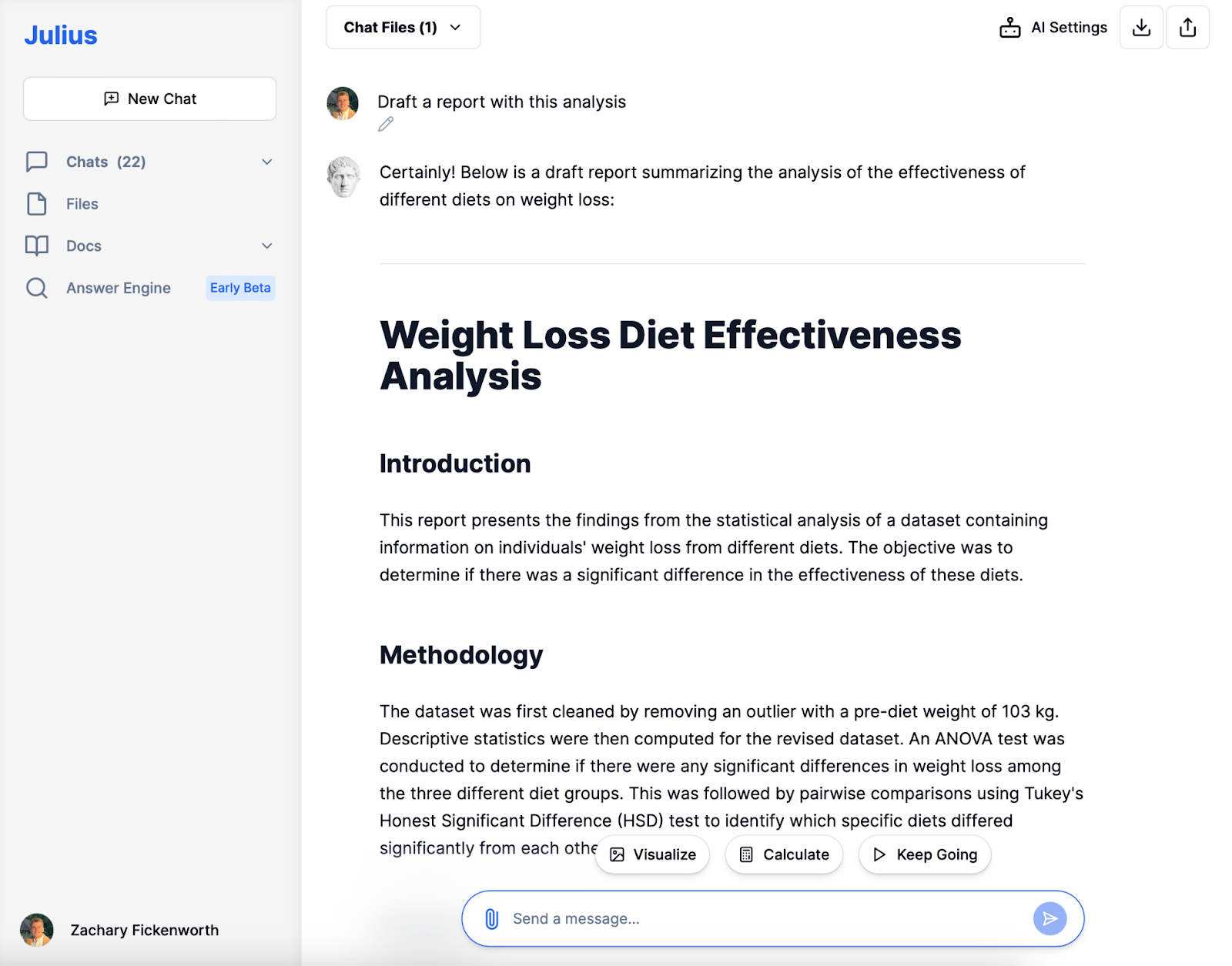
Rapportering
I sluttfasen av kostholdsstudien vår ville vi lage en rapport som pent oppsummerer hele forskningsprosessen og funnene våre. Denne rapporten, ledet av analysen gjort med Julius, vil inkludere:
- Introduksjon: En kort forklaring på studiens mål, som er å evaluere effektiviteten til ulike dietter på vekttap.
- metodikk: En kortfattet beskrivelse av hvordan vi renset dataene, de statistiske metodene som ble brukt (ANOVA og Tukeys HSD), og hvorfor de ble valgt.
- Funn og tolkning: En tydelig presentasjon av resultatene, inkludert de betydelige forskjellene som er funnet mellom diettene, spesielt fremhever Diet 3s effektivitet.
- Konklusjon: Å trekke endelige konklusjoner fra dataene og foreslå praktiske implikasjoner eller anbefalinger basert på funnene våre.
- Referanser: Siterer verktøyene og statistiske metodene, som Julius, som støttet analysen vår.
Denne rapporten vil tjene som en klar, strukturert og omfattende oversikt over forskningen vår, og gjøre den tilgjengelig og informativ for leserne.
konklusjonen
Vi har kommet til slutten av reisen vår innen akademisk forskning, og forvandler et datasett om dietter til meningsfull innsikt. Denne prosessen, fra det første spørsmålet til den endelige rapporten, viser hvordan de riktige verktøyene og metodene kan gjøre dataanalyse tilgjengelig, selv for nybegynnere.
Ved hjelp av Julius, vårt avanserte AI-verktøy, har vi sett hvordan strukturerte trinn i dataanalyse kan avsløre viktige trender og svare på viktige spørsmål. Vår studie om dietter og vekttap er bare ett eksempel på hvordan data, når de analyseres nøye, ikke bare forteller en historie, men også gir klare, handlingsrettede konklusjoner. Vi håper denne veiledningen har kastet lys over dataanalyseprosessen, noe som gjør den mindre skremmende og mer spennende for alle som er interessert i å avdekke historiene som er skjult i dataene deres.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2024/01/guide-to-academic-data-analysis-with-julius-ai/
- : har
- :er
- :ikke
- :hvor
- 1
- 72
- 77
- a
- akademisk
- akademisk forskning
- tilgjengelig
- tvers
- avansert
- Etter
- alder
- AI
- AI-drevet
- sikte
- Justerer
- Alle
- allerede
- også
- blant
- an
- analyser
- analyse
- analysere
- analysert
- analyserer
- og
- besvare
- svar
- noen
- noen
- tilnærming
- tilnærmet
- hensiktsmessig
- ca
- ER
- AREA
- rundt
- AS
- anta
- At
- gjennomsnittlig
- Balansert
- basert
- grunnleggende
- BE
- før du
- Nybegynner
- nybegynnere
- være
- under
- Bedre
- mellom
- Stor
- både
- men
- by
- kom
- CAN
- nøye
- saken
- case study
- saker
- sjanse
- egenskaper
- valg
- valgt ut
- avklart
- klarhet
- Rengjøring
- fjerne
- tydeligere
- klart
- samle
- Samle
- samling
- Kom
- kommunisere
- sammenligne
- sammenlignet
- sammenligne
- sammenligninger
- komplekse
- omfattende
- konsepter
- konsis
- konkluderer
- betong
- gjennomført
- selvsikkert
- vurderer
- kontekst
- kontinuerlig
- kontroll
- konvensjonell
- kunne
- skape
- kritisk
- avgjørende
- avgjørende
- dato
- dataanalyse
- datasett
- dypere
- definere
- demonstrert
- avmystifisere
- beskrivelse
- detalj
- detaljert
- detaljer
- oppdage
- bestemmes
- bestemme
- gJORDE
- Kosthold
- forskjell
- forskjeller
- forskjellig
- direkte
- oppdage
- distribusjon
- Mangfold
- ikke
- gjort
- tegning
- duplikater
- e
- hver enkelt
- Effektiv
- effektivt
- effektivitet
- effekter
- enten
- slutt
- sikrer
- Hele
- like
- feil
- spesielt
- etablerer
- etc
- Eter (ETH)
- evaluere
- Selv
- alt
- nøyaktig
- undersøkelse
- undersøke
- undersøke
- eksempel
- used
- spennende
- eksisterende
- erfaring
- forklare
- forklaring
- leting
- Utforskende dataanalyse
- tilrettelagt
- fascinerende
- slutt~~POS=TRUNC
- Finn
- finne
- funn
- Først
- passer inn
- Fokus
- fulgt
- etter
- Til
- formuleringen
- funnet
- fersk
- fra
- videre
- samlet
- ga
- Kjønn
- få
- gitt
- mål
- god
- større
- grunnarbeid
- Gruppe
- Gruppens
- veilede
- guidet
- Guider
- førings
- HAD
- håndtere
- Håndtering
- Ha
- Hjerte
- høyde
- hjulpet
- her.
- skjult
- Høy
- høyere
- utheving
- håp
- Hvordan
- Hvordan
- Men
- HTTPS
- i
- ideell
- identifisert
- identifisere
- identifisering
- if
- belyse
- umåtelig
- Påvirkning
- implikasjoner
- viktig
- in
- inkludere
- inkluderer
- Inkludert
- uavhengig
- indikert
- indikativ
- individuelt
- individer
- påvirket
- informasjon
- informative
- informert
- innledende
- innsiktsfull
- innsikt
- integritet
- interessert
- tolkning
- inn
- undersøke
- involvere
- innebærer
- IT
- DET ER
- reise
- Julius
- bare
- bare én
- nøkkel
- Vet
- kunnskap
- føre
- ledende
- mindre
- løgn
- lett
- i likhet med
- begrensninger
- lasting
- Se
- tap
- Hoved
- vedlikeholde
- gjøre
- GJØR AT
- Making
- max bredde
- Kan..
- bety
- meningsfylt
- ment
- måling
- bare
- metode
- metodikk
- metoder
- kunne
- milepæl
- mangler
- modeller
- mer
- mest
- Natur
- nødvendig
- Trenger
- nødvendig
- Ny
- Nei.
- bemerkelsesverdig
- nybegynner
- nyansert
- Antall
- Målet
- observerte
- of
- tilby
- on
- ONE
- bare
- Alternativ
- or
- Annen
- andre
- vår
- ut
- Utfallet
- utfall
- uteligger
- samlet
- par
- Papir
- del
- deltakere
- banen
- mønstre
- Ansatte
- utføre
- utført
- fase
- sentral
- plato
- Platon Data Intelligence
- PlatonData
- spilt
- potensiell
- kraftig
- Praktisk
- forutsi
- presentasjon
- bevarer
- prosess
- fremme
- riktig
- gi
- forutsatt
- gir
- kvalitet
- spørsmål
- spørsmål
- ganske
- Raw
- rådata
- lesere
- Beredskap
- ekte
- nylig
- anbefalinger
- rekord
- regresjon
- forhold
- Relasjoner
- slektning
- relevant
- fjerning
- rapporterer
- representere
- forskning
- forskere
- resultere
- resulterte
- Resultater
- avsløre
- Avslørt
- avslørende
- givende
- ikke sant
- veikart
- Rolle
- Spar
- søker
- sett
- velge
- utvalg
- betjene
- sett
- flere
- deling
- skur
- bør
- Vis
- viste
- viser
- Viser
- signifikant
- betydelig
- lignende
- på samme måte
- situasjoner
- SIX
- Solutions
- noen
- spesifikk
- splittet
- Scene
- stadier
- Standard
- standardisert
- standout
- Start
- statistisk
- statistisk
- statistikk
- opphold
- Trinn
- Steps
- sto
- Stories
- Story
- rett fram
- Strategisk
- sterk
- strukturert
- Studer
- Studerer
- senere
- foreslår
- Støttes
- sikker
- SVG
- raskt
- målrettet
- teknikker
- forteller
- vilkår
- test
- tester
- enn
- Det
- De
- Området
- deres
- deretter
- Der.
- Disse
- de
- ting
- denne
- terskel
- Gjennom
- hele
- tid
- til
- verktøy
- verktøy
- spor
- transformere
- Trender
- troverdig
- SVING
- Turning
- to
- typen
- typer
- typisk
- forstå
- forståelse
- lomper
- avduket
- avduker
- us
- bruke
- brukt
- ved hjelp av
- Verdifull
- verdi
- Verdier
- variabel
- ulike
- Se
- vs
- gå
- vandringer
- ønsker
- var
- Vei..
- we
- uker
- vekt
- VI VIL
- var
- Hva
- når
- om
- hvilken
- mens
- hvorfor
- vil
- med
- innenfor
- arbeidsflyt
- ville
- ennå
- du
- Din
- Zach
- zephyrnet