Mens OpenAI ChatGPT suger opp alt oksygenet ut av den 24-timers nyhetssyklusen, har Google i det stille avduket en ny AI-modell som kan generere videoer når det gis video-, bilde- og tekstinndata. Den nye Google Dreamix AI-videoredigereren bringer nå generert video nærmere virkeligheten.
I følge forskningen publisert på GitHub, redigerer Dreamix videoen basert på en video og en tekstmelding. Den resulterende videoen beholder sin troskap til farger, holdning, objektstørrelse og kameraposisjon, noe som resulterer i en tidsmessig konsistent video. For øyeblikket kan ikke Dreamix generere videoer fra bare en melding, men den kan ta eksisterende materiale og endre videoen ved å bruke tekstmeldinger.
Google bruker videodiffusjonsmodeller for Dreamix, en tilnærming som har blitt brukt for det meste av videobilderedigeringen vi ser i bilde-AIer som DALL-E2 eller åpen kildekode Stable Diffusion.
Tilnærmingen innebærer å kraftig redusere inngangsvideoen, legge til kunstig støy og deretter behandle den i en videodiffusjonsmodell, som deretter bruker en tekstmelding for å generere en ny video fra den som beholder noen egenskaper til den originale videoen og gjengir andre i henhold til til tekstinntastingen.
Videodiffusjonsmodellen tilbyr en lovende fremtid som kan innlede en ny æra for arbeid med videoer.

For eksempel, i videoen nedenfor, forvandler Dreamix den spisende apen (til venstre) til en dansende bjørn (til høyre) gitt beskjeden "En bjørn som danser og hopper til optimistisk musikk, beveger hele kroppen."
I et annet eksempel nedenfor bruker Dreamix et enkelt bilde som mal (som i bilde-til-video), og et objekt blir deretter animert fra det i en video via en ledetekst. Kamerabevegelser er også mulig i den nye scenen eller et påfølgende time-lapse-opptak.
I et annet eksempel gjør Dreamix orangutangen i en vannbasseng (til venstre) til en orangutang med oransje hår som bader i et vakkert bad.
"Mens diffusjonsmodeller har blitt brukt for bilderedigering, har svært få verk gjort det for videoredigering. Vi presenterer den første diffusjonsbaserte metoden som er i stand til å utføre tekstbasert bevegelse og utseenderedigering av generelle videoer."
I følge Googles forskningsartikkel bruker Dreamix en videodiffusjonsmodell for å kombinere, på inferenstidspunkt, lavoppløsnings spatiotemporal informasjon fra den originale videoen med ny, høyoppløselig informasjon som den syntetiserte for å justere med veiledende tekstmelding.»
Google sa at de tok denne tilnærmingen fordi "å oppnå høy-fidelitet til den originale videoen krever å beholde noe av den høyoppløselige informasjonen, vi legger til et foreløpig stadium for å finjustere modellen på den originale videoen, noe som øker troverdigheten betydelig."
Nedenfor er en videooversikt over hvordan Dreamix fungerer.
[Innebygd innhold]
Hvordan Dreamix videodiffusjonsmodeller fungerer
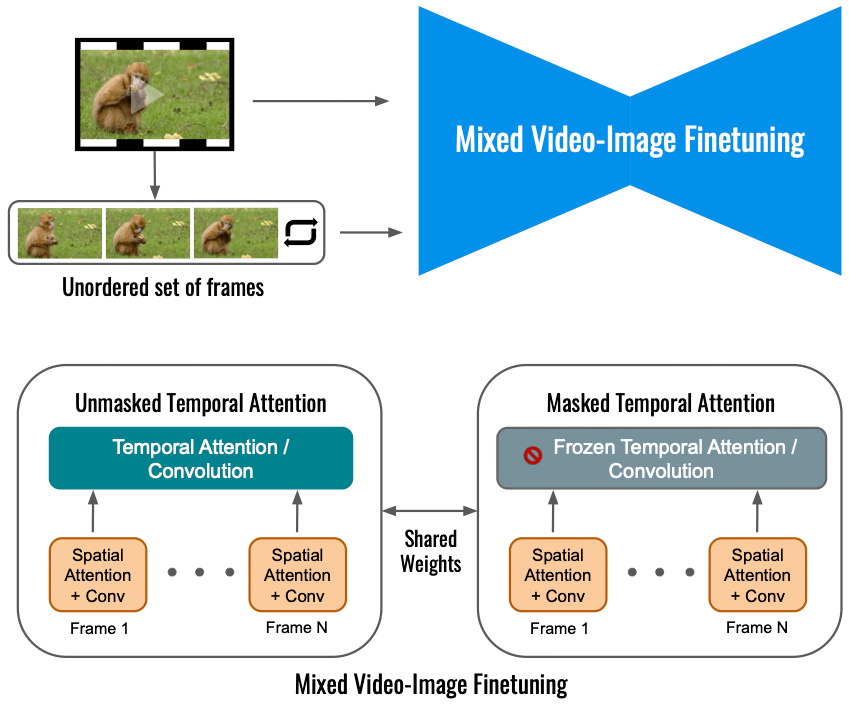
I følge Google begrenser finjustering av videodiffusjonsmodellen for Dreamix på inngangsvideoen alene omfanget av bevegelsesendring. I stedet bruker vi et blandet objektiv som i tillegg til det originale objektivet (nederst til venstre) også finjusterer på det uordnede settet med rammer. Dette gjøres ved å bruke "maskert tidsmessig oppmerksomhet", og forhindrer at den tidsmessige oppmerksomheten og konvolusjonen finjusteres (nederst til høyre). Dette gjør det mulig å legge til bevegelse til en statisk video.
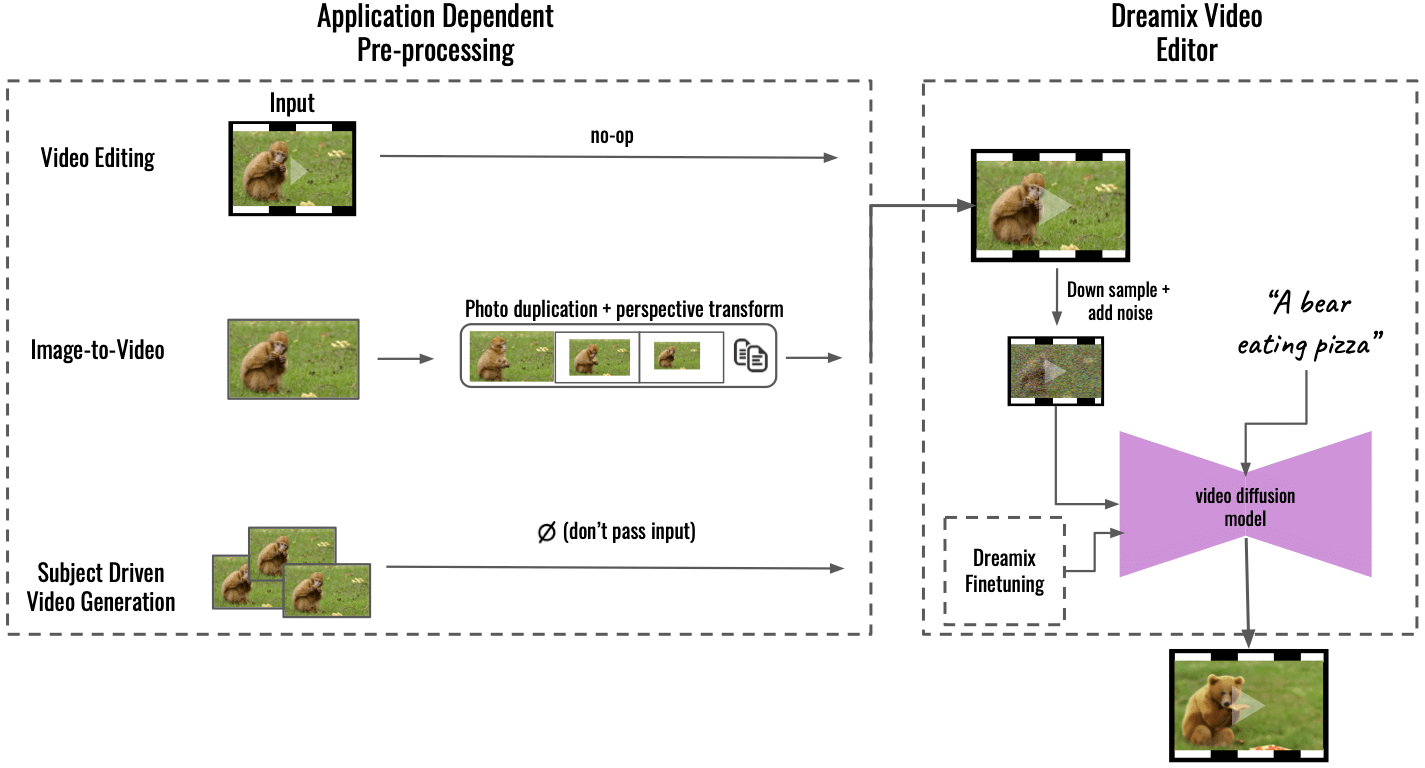
"Vår metode støtter flere applikasjoner ved applikasjonsavhengig forhåndsbehandling (til venstre), og konverterer inndatainnholdet til et enhetlig videoformat. For bilde-til-video dupliseres og transformeres inngangsbildet ved hjelp av perspektivtransformasjoner, og syntetiserer en grov video med litt kamerabevegelse. For motivdrevet videogenerering utelates input – finjustering alene tar seg av trofastheten. Denne grove videoen blir deretter redigert ved hjelp av vår generelle "Dreamix Video Editor" (til høyre): vi korrumperer først videoen ved å nedsample etterfulgt av å legge til støy. Deretter bruker vi den finjusterte tekststyrte videodiffusjonsmodellen, som oppskalerer videoen til den endelige spatiotemporale oppløsningen," skrev Dream på GitHub.
Du kan lese forskningsoppgaven nedenfor.
Google Dreamix- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- I stand
- Ifølge
- AI
- ai video
- AI-drevet
- Alle
- tillater
- alene
- og
- En annen
- søknader
- anvendt
- Påfør
- tilnærming
- kunstig
- oppmerksomhet
- basert
- Bær
- vakker
- fordi
- være
- under
- kroppen
- øke
- Bunn
- Bringer
- rom
- kan ikke
- hvilken
- endring
- ChatGPT
- nærmere
- farge
- kombinere
- konsistent
- innhold
- Opprette
- syklus
- Dans
- kringkasting
- drøm
- redaktør
- innebygd
- Era
- eksempel
- eksisterende
- Noen få
- fidelity
- slutt~~POS=TRUNC
- Først
- fulgt
- format
- fra
- framtid
- general
- generere
- generert
- generasjonen
- gif
- GitHub
- gitt
- Hår
- tungt
- høy oppløsning
- Hvordan
- Men
- HTTPS
- bilde
- bilder
- in
- informasjon
- inngang
- i stedet
- IT
- lanseringer
- grenser
- opprettholder
- materiale
- max
- metode
- blandet
- modell
- modeller
- modifisere
- øyeblikk
- mest
- bevegelse
- bevegelser
- flytting
- flere
- musikk
- Ny
- nyheter
- Bråk
- objekt
- Målet
- Tilbud
- åpen kildekode
- OpenAI
- oransje
- original
- andre
- oversikt
- Oksygen
- Papir
- utføre
- perspektiv
- plato
- Platon Data Intelligence
- PlatonData
- basseng
- mulig
- presentere
- hindre
- prosessering
- lovende
- egenskaper
- publisert
- stille
- Lese
- Reality
- innspilling
- redusere
- Krever
- forskning
- oppløsning
- resulterende
- støttemur
- Sa
- scene
- sett
- betydelig
- enkelt
- Størrelse
- So
- noen
- stabil
- Scene
- senere
- vellykket
- slik
- Støtter
- Ta
- mal
- De
- tid
- til
- transformasjoner
- forvandlet
- avduket
- bruke
- av
- video
- videoer
- Vann
- hvilken
- arbeid
- virker
- youtube
- zephyrnet











