
Bilde av rawpixel.com on Freepik
Uansett hvilken virksomhet du er i, er det viktigere enn noen gang å vite hvordan du analyserer data i den datadrevne æraen. Dataanalyse vil gjøre det mulig for bedrifter å holde seg konkurransedyktige og gi muligheten til å ta bedre beslutninger.
Viktigheten av dataanalyse driver hver enkelt til å vite hvordan man utfører dataanalyse. Noen ganger tar det imidlertid for mye tid å utføre dataanalyse. Det er derfor vi kunne stole på ChatGPT for å lage en fullstendig rapport fra datafilen vår.
Denne artikkelen vil utforske fem enkle trinn for å lage komplette analytiske rapporter fra CSV-filen din. Disse fem trinnene inkluderer:
Trinn 1: Importere CSV-filen
Trinn 2: Datasammendrag og forhåndsbehandling
Trinn 3: Dataanalyse
Trinn 4: Datavisualisering
Trinn 5: Rapportgenerering
Som en forutsetning forutsetter denne artikkelen at leseren har abonnert på ChatGPT Plus. Med det i tankene, la oss komme i gang.
Det første trinnet er å forberede CSV-filen du vil analysere og lage en rapport. Denne filen kan komme fra hvilken som helst pålitelig kilde, men denne artikkelen vil bruke Telecom Churn-datasettet fra kaggle.
Sørg for at dataene er strukturert, organisert og har en klar overskrift. Hvis du har et bestemt mål du vil analysere, så ikke glem å inkludere disse dataene i filen. I vårt eksempel ville vi prøve å utføre en analyse for churn-kolonnen.
Med dataene klare, fest dem til ChatGPT og la modellen gjøre jobben sin.
Det neste trinnet er å hente datasammendraget fra CSV-filen vår og forhåndsbehandle dem. Skriv inn følgende spørsmål mens du laster opp dataene.
Provide the data summary to this file and perform appropriate data processing for the dataset.Spørsmålet ovenfor gir følgende resultater:
Her er sammendraget av datasettet ditt:
Antall rader: 3333
Antall kolonner: 11
Kolonnenavn:
Churn
AccountWeeks
Kontrakt fornyelse
Data plan
Databruk
CustServCalls
DayMins
Daganrop
Monthly Charge
OverageFee
RoamMins
Datatyper:
Heltall: Churn, AccountWeeks, ContractRenewal, DataPlan, CustServCalls, DayCalls
Flytende: DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins
Manglende verdier: Det mangler ingen verdier i noen av kolonnene.
ChatGPT kunne tydelig lese dataene godt og var i stand til å gi det gitte datasettet. Det neste resultatet er dataforbehandlingen fra ChatGPT.
Siden det ikke mangler verdier i datasettet, vil hovedfokuset for datarensing og forbehandling være på:
- Sjekker for avvik eller uregelmessigheter i dataene.
- Normalisering eller standardisering av data om nødvendig, spesielt for kolonner med kontinuerlige numeriske verdier.
- Konvertering av kategoriske data til et format som er egnet for analyse, om nødvendig.
La oss fortsette med disse trinnene.
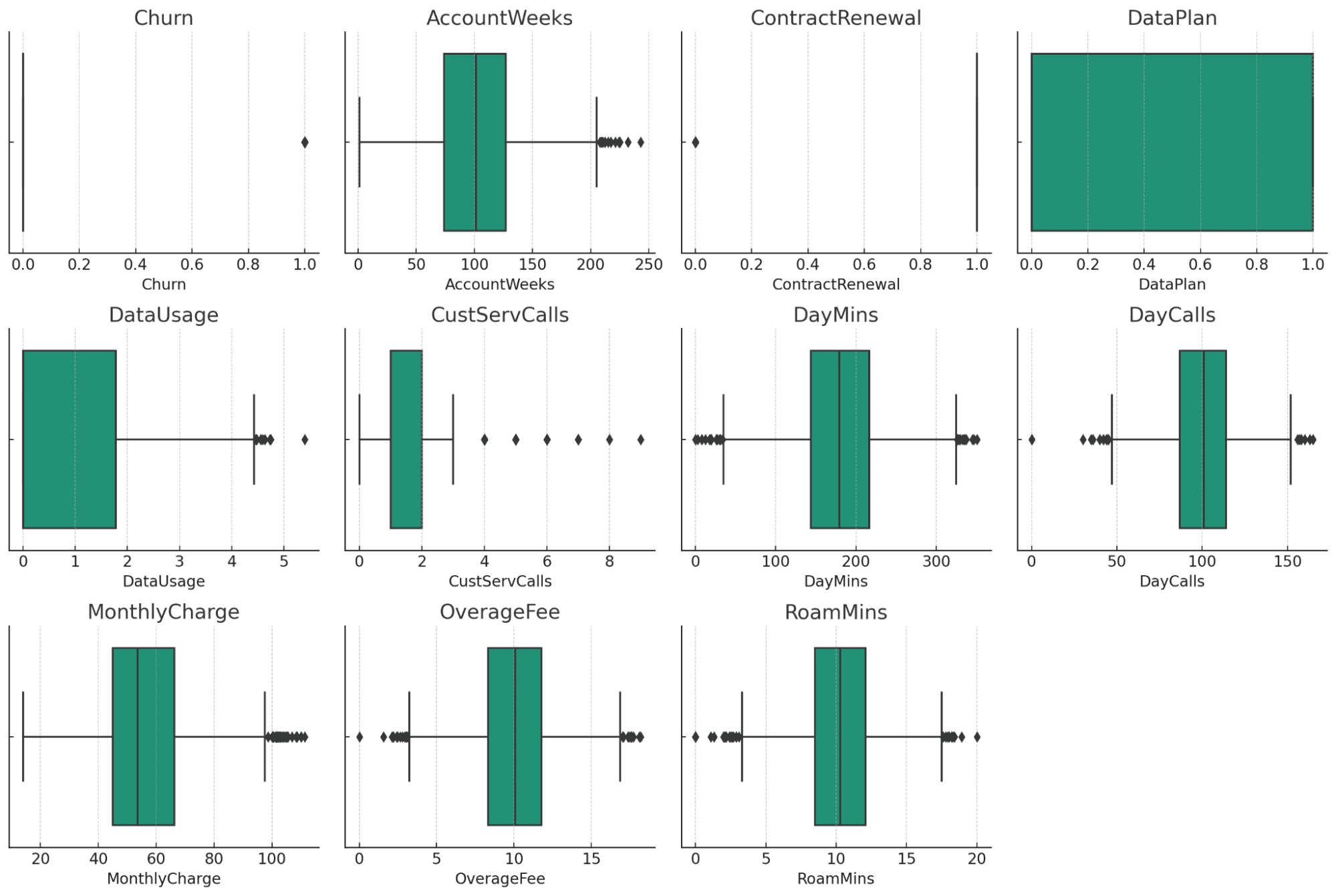
Boksplottene gir en visuell oversikt over potensielle uteliggere i hver numeriske kolonne i datasettet ditt. Her er noen observasjoner:
- AccountWeeks, CustServCalls, DayCalls: Disse kolonnene viser en ganske normal fordeling med noen få uteliggere.
- DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins: Disse kolonnene viser også noen uteliggere, men de ser ut til å være innenfor et rimelig område, tatt i betraktning dataenes natur.
- Churn, ContractRenewal, DataPlan: Disse kolonnene er kategoriske/binære data, og viser ikke tradisjonelle uteliggere.
Gitt denne informasjonen, kan de neste trinnene i datarensing og forbehandling omfatte:
- Håndtering av avvikere: Vi kan bestemme om vi skal fjerne, begrense eller på annen måte håndtere avvik basert på dine spesifikke analytiske behov og domenekunnskap.
- Datatransformasjon: Om nødvendig kan vi normalisere eller standardisere kolonner som DayMins, MonthlyCharge, etc., spesielt hvis du planlegger å bruke algoritmer som er sensitive for dataskalaen.
- Kategorisk datakoding: Konverter kategoriske data til et format som er egnet for analyse, hvis en slik transformasjon er nødvendig.
Du kan la ChatGPT utføre ytterligere trinn for datarensing og forhåndsbehandling eller la den være som den er. For dette eksemplet vil vi fortsette til de neste trinnene.
Deretter ville vi utføre dataanalyse med ChatGPT. Dataanalysen er avhengig av hva du ønsker å oppnå. I vårt tilfelle ønsker vi å utføre dataanalyse fra Churn POV.
Vi bruker følgende ledetekst for å utføre dataanalysen med ChatGPT for tilfellet ovenfor.
Please perform the data analysis based on the data above with respect to the churn data.
Dataanalysen kan sees i følgende resultat.
For å utføre dataanalyse med hensyn til churn-dataene, vil vi fokusere på å forstå hvordan ulike faktorer relaterer seg til kundechurn. Churn, som er en binær variabel (0 for ingen churn, 1 for churn), analyseres vanligvis gjennom klassifiseringsmetoder og ved å undersøke sammenhenger med andre variabler. Her er planen:
- Korrelasjonsanalyse: Til å begynne med skal vi se på hvordan hver numerisk funksjon korrelerer med churn. Dette gir oss en innledende forståelse av hvilke faktorer som kan være nærmere relatert til churn.
- Statistiske tester: For kategoriske variabler som ContractRenewal og DataPlan kan vi bruke statistiske tester for å se om det er signifikante forskjeller i churn-rater på tvers av ulike kategorier.
- Visuell analyse: Vi lager noen visualiseringer for å utforske disse forholdene ytterligere. Dette inkluderer å sammenligne churn-rater på tvers av ulike grupper og plotte nøkkelvariabler mot churn.
- Sammendragsstatistikk: Vi gir sammendragsstatistikk for ulike grupper basert på churn-status for å se om det er merkbare forskjeller i gjennomsnitt eller fordeling.
La oss starte med korrelasjonsanalysen og deretter gå videre til de neste trinnene.
Korrelasjonsanalyse med Churn
Korrelasjonen mellom forskjellige variabler med churn er som følger (fra sterkeste negative til sterkeste positive korrelasjon):
Negativ korrelasjon:
- Kontraktfornyelse: Sterkeste negative korrelasjon. Indikerer at kunder som ikke fornyer kontraktene sine, har større sannsynlighet for å churn.
- DataPlan: Kunder uten dataplan er litt mer sannsynlige å avbryte.
- Databruk: Høyere databruk reduserer sannsynligheten for churn litt.
Positiv korrelasjon:
- AccountWeeks, DayCalls: Svært svak positiv korrelasjon, noe som tyder på minimal innvirkning på churn.
- RoamMins: En liten økning i churn-sannsynlighet med økte roaming-minutter.
- MonthlyCharge: Noe høyere churn rater med økte månedlige avgifter.
- OverageFee: Høyere overageavgifter er moderat korrelert med økt churn.
- DayMins: Høyere daglige minutter er moderat korrelert med økt churn.
- CustServCalls: Sterk positiv korrelasjon. Flere kundeservicesamtaler er forbundet med høyere churn rater.
Basert på disse korrelasjonene ser det ut til at faktorer som kontraktsfornyelse, kundeserviceoppringninger, daglige minutter og overskuddsgebyrer er nærmere knyttet til avgang. Vi kan utforske disse faktorene ytterligere gjennom visuell analyse og statistiske tester, spesielt for kategoriske variabler som ContractRenewal og DataPlan.
Visuell analyse
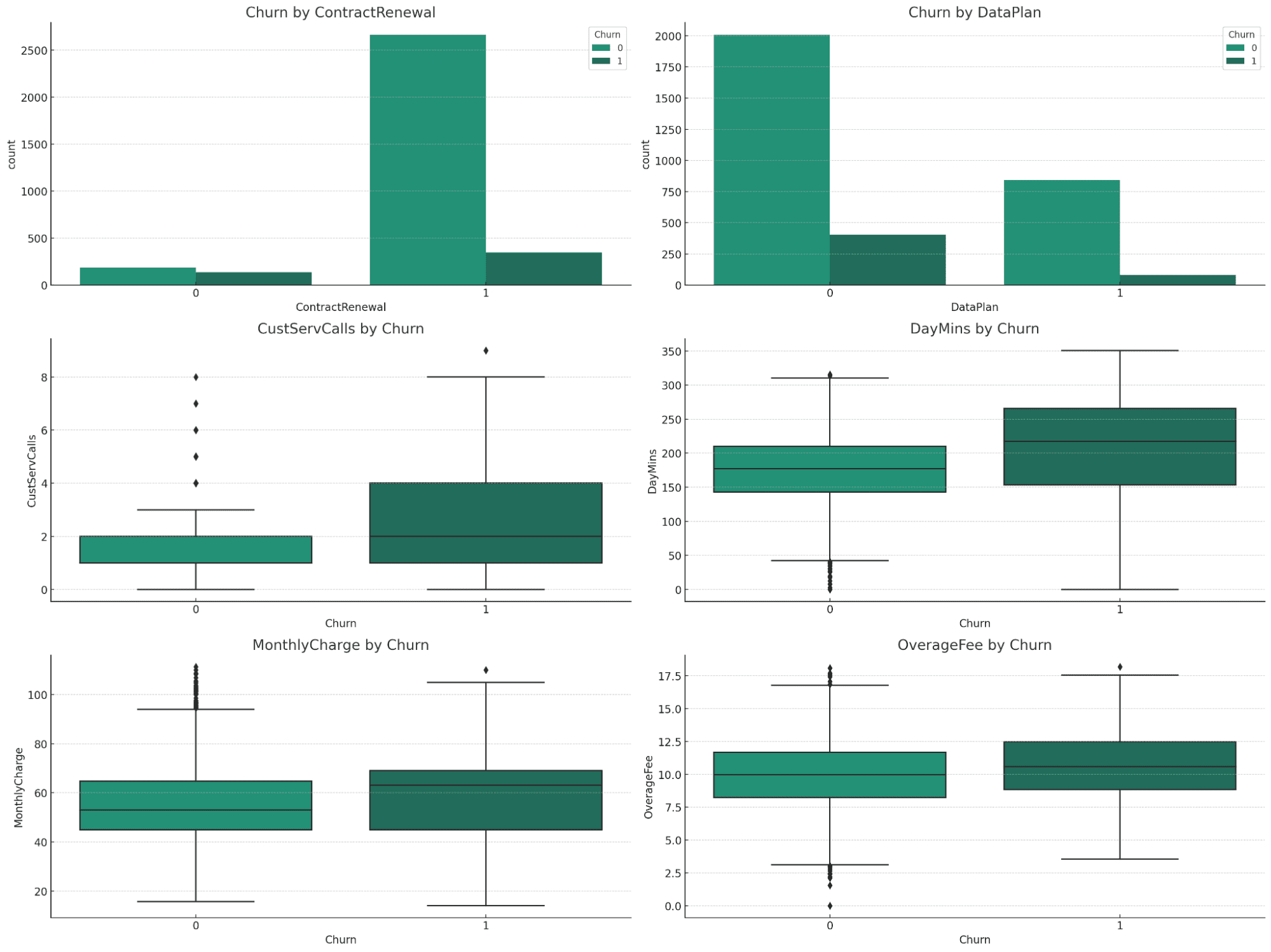
Visualiseringene gir verdifull innsikt i forholdet mellom ulike variabler og churn:
Churn ved ContractRenewal og DataPlan:
- Kontraktfornyelse: En betydelig forskjell i churn rater er tydelig. Kunder som ikke fornyet kontraktene sine viser en høyere avgang.
- DataPlan: Det er en merkbar forskjell i churn rater basert på om kunder har en dataplan eller ikke, med de uten dataplan som viser høyere churn.
Numeriske variabler (CustServCalls, DayMins, MonthlyCharge, OverageFee) etter Churn:
- CustServCalls: Kunder med høyere antall kundeserviceanrop har en tendens til å churne mer.
- DayMins: Høyere daglige minutter er assosiert med større sannsynlighet for churn.
- MonthlyCharge: Høyere månedlige kostnader korrelerer med en økt churn rate.
- OverageFee: Høyere overageavgifter er også forbundet med økt churn.
Konklusjoner fra analysen
- Kontraktsfornyelsesstatus og tilstedeværelsen av en dataplan er viktige faktorer i kundefragang.
- Høyt bruk (i form av dagminutter) og høye gebyrer (månedlige avgifter og overskuddsgebyrer) er forbundet med høyere churn rater.
- Et høyere antall kundeserviceanrop er en sterk indikator på potensiell avgang.
Neste trinn
Basert på denne innsikten kan målrettede strategier utvikles for å redusere avgang, for eksempel å forbedre kundeservice, revidere prisstrategier eller tilby insentiver for kontraktsfornyelse og abonnement på dataplaner.
Med en enkelt melding kan vi se hvor godt ChatGPT kan gi oss den komplette dataanalysen og komme med innsikt fra dataene. Du kan justere analysemålene og starte derfra.
Datavisualiseringen er en støttende aktivitet for å forbedre dataanalysen og den generelle rapporten. Ved å ha visualiseringen kan vi få en mer omfattende rapport for å forstå dataene våre.
Ved å bruke følgende ledetekst kan vi utføre datavisualiseringen med ChatGPT.
Please perform data visualization from the data analysis to explain the data better.For å forbedre forståelsen av dataanalyseresultatene, vil jeg lage en serie visualiseringer som tydelig viser nøkkelfunnene knyttet til kundefragang. Disse visualiseringene vil inkludere:
- Søyleplott for kategoriske variabler:
- Sammenligning av churn rater for kunder med og uten kontraktsfornyelse.
- Sammenligning av churn rater for kunder med og uten dataplan.
- Boksplott for numeriske nøkkelvariabler:
- Kundeservicesamtaler vs Churn.
- Daglige minutter vs Churn.
- Månedlige avgifter vs Churn.
- Overskuddsgebyr vs Churn.
- Varmekart over korrelasjon:
For å visualisere korrelasjonen av alle variabler med churn.
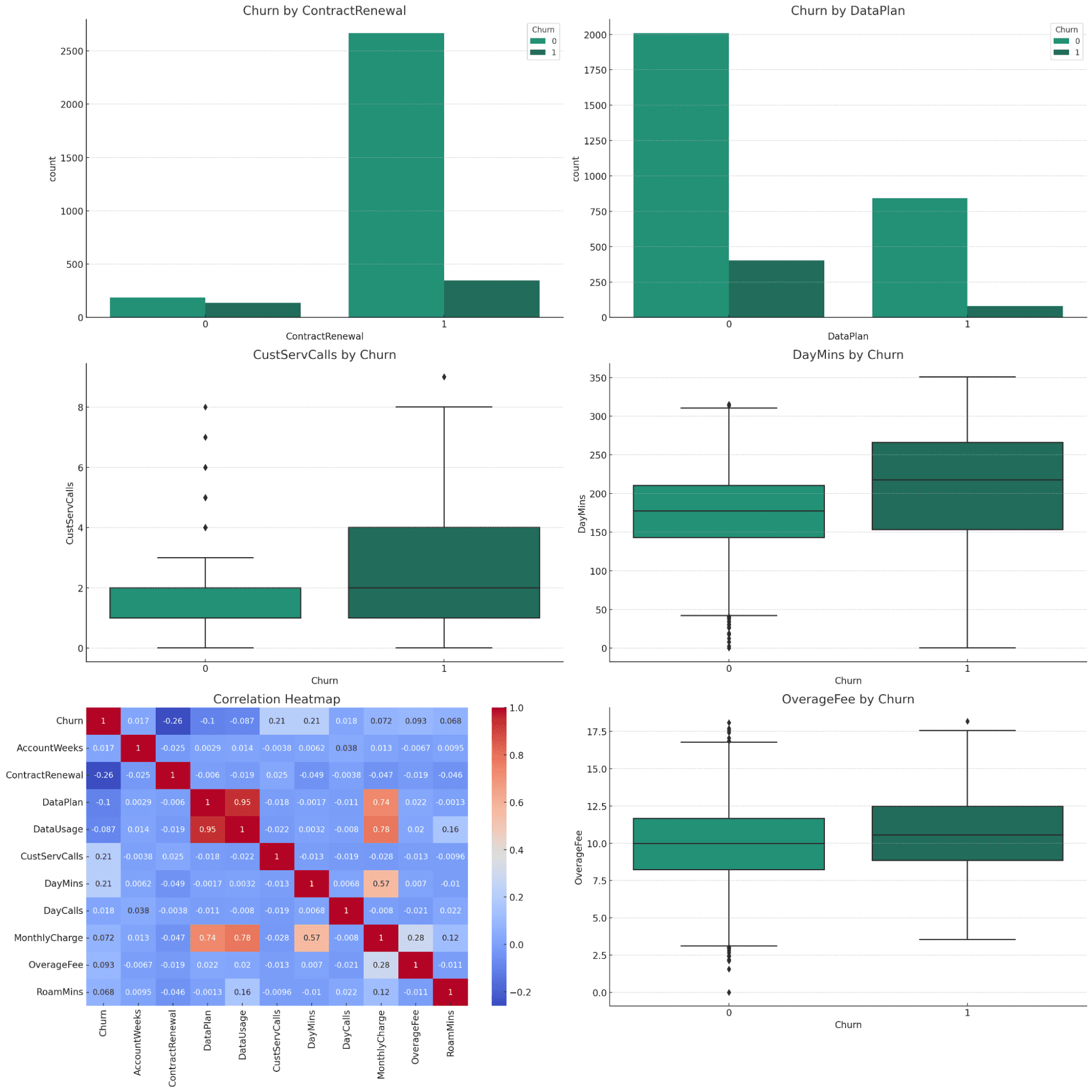
Visualiseringen vil vise alle de viktige plottene som innkapsler hele datasettet. Vi kan be om mer detaljerte beskrivelser for hver tomt, som du kan prøve uavhengig.
Det siste trinnet er å generere rapporten basert på de foregående trinnene. Dessverre kan det hende at ChatGPT ikke fanger opp all beskrivelsen og innsikten fra dataanalysen, men vi kan fortsatt ha den enkle versjonen av rapporten.
Bruk følgende ledetekst for å generere en PDF-rapport basert på forrige analyse.
Please provide me with the pdf report from the first step to the last step.Du vil få PDF-lenkeresultatet med din tidligere analyse dekket. Prøv å gjenta trinnene hvis du føler at resultatet er utilstrekkelig eller hvis det er ting du vil endre.
Dataanalyse er en aktivitet som alle bør kjenne til, siden det er en av de mest nødvendige ferdighetene i den nåværende epoken. Men å lære om å utføre dataanalyse kan ta lang tid. Med ChatGPT kan vi minimere all den aktivitetstiden.
I denne artikkelen har vi diskutert hvordan du genererer en komplett analytisk rapport fra CSV-filer i 5 trinn. ChatGPT gir brukere ende-til-ende dataanalyseaktivitet, fra å importere filen til å produsere rapporten.
Cornellius Yudha Wijaya er assistentleder for datavitenskap og dataskribent. Mens han jobber på heltid i Allianz Indonesia, elsker han å dele Python- og Data-tips via sosiale medier og skrivemedier.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps?utm_source=rss&utm_medium=rss&utm_campaign=from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps
- : har
- :er
- :ikke
- $OPP
- 1
- 7
- a
- evne
- I stand
- Om oss
- ovenfor
- Oppnå
- tvers
- aktivitet
- Ytterligere
- mot
- mål
- algoritmer
- Alle
- Allianz
- også
- an
- analyse
- Analytisk
- analysere
- analysert
- og
- noen
- hensiktsmessig
- ER
- Artikkel
- AS
- spør
- Assistent
- assosiert
- antar
- At
- feste
- Bar
- basert
- BE
- være
- Bedre
- mellom
- Eske
- virksomhet
- bedrifter
- men
- by
- Samtaler
- CAN
- lokk
- fangst
- saken
- kategorier
- viss
- endring
- avgifter
- ChatGPT
- kontroll
- klassifisering
- Rengjøring
- fjerne
- klart
- tett
- Kolonne
- kolonner
- Kom
- sammenligne
- konkurranse
- fullføre
- omfattende
- Gjennomføre
- vurderer
- fortsette
- kontinuerlig
- kontrakt
- kontrakter
- konvertere
- konvertering
- korrelert
- Korrelasjon
- korrelasjoner
- kunne
- dekket
- skape
- Gjeldende
- kunde
- Kundeservice
- Kunder
- daglig
- dato
- dataanalyse
- databehandling
- datavitenskap
- datavisualisering
- data-drevet
- dag
- bestemme
- avgjørelser
- avtar
- avhengig
- beskrivelse
- detaljert
- utviklet
- gJORDE
- forskjell
- forskjeller
- forskjellig
- diskutert
- distribusjon
- Distribusjoner
- do
- domene
- Don
- ikke
- stasjoner
- hver enkelt
- muliggjøre
- koding
- ende til ende
- forbedre
- Era
- spesielt
- etc
- NOEN GANG
- Hver
- alle
- tydelig
- undersøke
- eksempel
- henrette
- Forklar
- utforske
- faktorer
- ganske
- Trekk
- føler
- avgifter
- Noen få
- filet
- Filer
- funn
- Først
- fem
- Fokus
- etter
- følger
- Til
- format
- fra
- videre
- generere
- få
- Gi
- gitt
- gir
- større
- Gruppens
- håndtere
- Håndtering
- Ha
- å ha
- he
- her.
- Høy
- høyere
- Hvordan
- Hvordan
- Men
- HTTPS
- i
- if
- Påvirkning
- betydning
- viktig
- importere
- forbedre
- bedre
- in
- Incentiver
- inkludere
- inkluderer
- Øke
- økt
- uavhengig av hverandre
- indikerer
- Indikator
- individuelt
- Indonesia
- informasjon
- innledende
- inngang
- innsikt
- innsikt
- inn
- IT
- jpg
- KDnuggets
- nøkkel
- Vet
- Knowing
- kunnskap
- Siste
- læring
- la
- i likhet med
- sannsynligheten
- Sannsynlig
- LINK
- ll
- Lang
- lang tid
- Se
- elsker
- Hoved
- gjøre
- leder
- Saken
- me
- midler
- Media
- metoder
- kunne
- tankene
- minimal
- minimere
- minutter
- mangler
- modell
- månedlig
- mer
- mest
- flytte
- mye
- navn
- Natur
- nødvendig
- nødvendig
- behov
- negativ
- neste
- Nei.
- normal
- Antall
- tall
- observasjoner
- of
- tilby
- tilby
- on
- ONE
- or
- Organisert
- Annen
- ellers
- vår
- samlet
- oversikt
- utføre
- utfører
- fly
- plato
- Platon Data Intelligence
- PlatonData
- i tillegg til
- positiv
- potensiell
- Forbered
- tilstedeværelse
- forrige
- prising
- fortsette
- prosessering
- produserende
- gi
- gir
- Python
- område
- Sats
- priser
- Lese
- Reader
- klar
- rimelig
- redusere
- i slekt
- forholdet
- Relasjoner
- avhengige
- fjerne
- rapporterer
- Rapporter
- påkrevd
- respekt
- resultere
- Resultater
- s
- Skala
- Vitenskap
- se
- synes
- synes
- sett
- sensitive
- Serien
- tjeneste
- Del
- bør
- Vis
- viser
- signifikant
- Enkelt
- enkelt
- ferdigheter
- selskap
- sosiale medier
- noen
- noen ganger
- kilde
- spesifikk
- standardisere
- Begynn
- startet
- statistisk
- statistikk
- status
- opphold
- Trinn
- Steps
- Still
- strategier
- sterk
- sterkeste
- strukturert
- abonnementer
- slik
- egnet
- SAMMENDRAG
- støttende
- T
- Ta
- tar
- Target
- målrettet
- telekom
- vilkår
- tester
- enn
- Det
- De
- deres
- Dem
- deretter
- Der.
- Disse
- de
- ting
- denne
- De
- Gjennom
- tid
- tips
- til
- også
- tradisjonelle
- Transformation
- troverdig
- prøve
- tweak
- typisk
- forstå
- forståelse
- dessverre
- us
- bruk
- bruke
- Brukere
- Verdifull
- Verdier
- variabel
- versjon
- veldig
- av
- visuell
- visualisering
- visualisere
- vs
- ønsker
- var
- we
- VI VIL
- Hva
- om
- hvilken
- mens
- HVEM
- hele
- hvorfor
- vil
- med
- innenfor
- uten
- Arbeid
- arbeid
- ville
- forfatter
- skriving
- du
- Din
- zephyrnet









