
Bilde fra forfatter | Bing Image Creator
Dolly 2.0 er en åpen kildekode, instruksjonsfølt, stor språkmodell (LLM) som ble finjustert på et menneskegenerert datasett. Den kan brukes til både forskning og kommersielle formål.
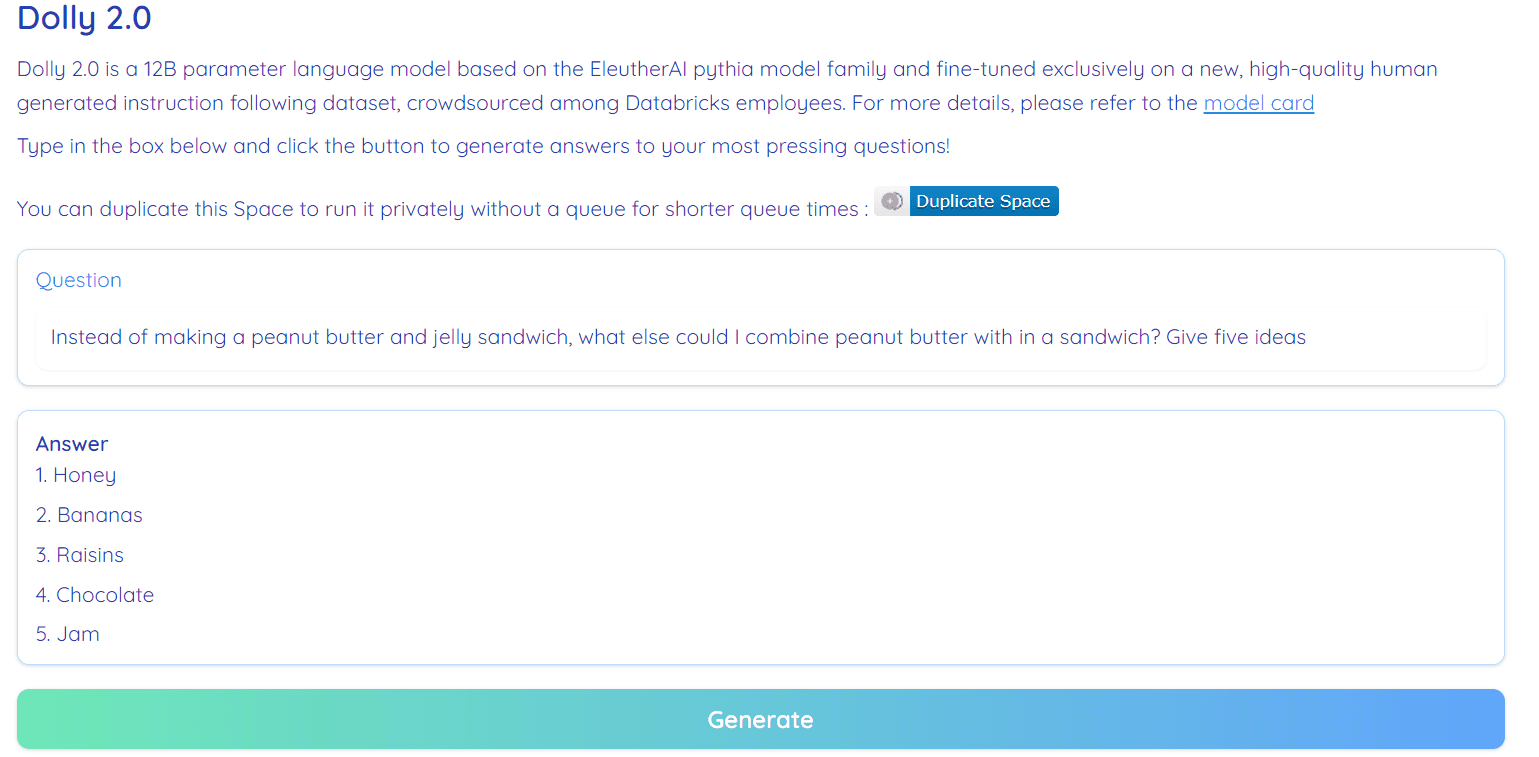
Bilde fra Hugging Face Space av RamAnanth1
Tidligere ga Databricks-teamet ut Dolly 1.0, LLM, som viser ChatGPT-lignende instruksjoner etter evne og koster mindre enn $30 å trene. Den brukte Stanford Alpaca-teamdatasettet, som var under en begrenset lisens (kun forskning).
Dolly 2.0 har løst dette problemet ved å finjustere 12B-parameterspråkmodellen (Pythia) på en menneskeskapt instruksjon av høy kvalitet i følgende datasett, som ble merket av en Datbricks-ansatt. Både modell og datasett er tilgjengelig for kommersiell bruk.
Dolly 1.0 ble trent på et Stanford Alpaca-datasett, som ble opprettet ved hjelp av OpenAI API. Datasettet inneholder utdata fra ChatGPT og hindrer noen i å bruke det til å konkurrere med OpenAI. Kort sagt, du kan ikke bygge en kommersiell chatbot eller språkapplikasjon basert på dette datasettet.
De fleste av de nyeste modellene utgitt de siste ukene led av de samme problemene, modeller som Alpaca, Koala, GPT4Allog Vicuna. For å komme oss rundt må vi lage nye høykvalitets datasett som kan brukes til kommersiell bruk, og det er det Databricks-teamet har gjort med databricks-dolly-15k datasettet.
Det nye datasettet inneholder 15,000 XNUMX høykvalitets menneskemerkede spørsmål/svar-par som kan brukes til å designe instruksjonsjustering av store språkmodeller. De databricks-dolly-15k datasettet følger med Creative Commons Attribution-ShareAlike 3.0 Unported-lisens, som lar hvem som helst bruke den, endre den og lage en kommersiell applikasjon på den.
Hvordan opprettet de databricks-dolly-15k datasettet?
OpenAI-forskningen papir oppgir at den originale InstructGPT-modellen ble trent på 13,000 13 forespørsler og svar. Ved å bruke denne informasjonen begynte Databricks-teamet å jobbe med det, og det viser seg at å generere 5,000 XNUMX spørsmål og svar var en vanskelig oppgave. De kan ikke bruke syntetiske data eller AI-generative data, og de må generere originale svar på hvert spørsmål. Det er her de har bestemt seg for å bruke XNUMX ansatte i Databricks til å lage menneskeskapte data.
Databricks har satt opp en konkurranse, der de 20 beste merkerne vil få en stor pris. I denne konkurransen deltok 5,000 Databricks-ansatte som var svært interessert i LLM-er
Dolly-v2-12b er ikke en toppmoderne modell. Den presterer dårligere enn dolly-v1-6b i noen evalueringsbenchmarks. Det kan skyldes sammensetningen og størrelsen på de underliggende finjusteringsdatasettene. Dolly-modellfamilien er under aktiv utvikling, så du vil kanskje se en oppdatert versjon med bedre ytelse i fremtiden.
Kort fortalt har dolly-v2-12b-modellen prestert bedre enn EleutherAI/gpt-neox-20b og EleutherAI/pythia-6.9b.

Bilde fra Gratis Dolly
Dolly 2.0 er 100 % åpen kildekode. Den kommer med treningskode, datasett, modellvekter og inferensrørledning. Alle komponentene er egnet for kommersiell bruk. Du kan prøve ut modellen på Hugging Face Spaces Dolly V2 av RamAnanth1.
Bilde fra Klemme ansiktet
Ressurs:
Dolly 2.0-demo: Dolly V2 av RamAnanth1
Abid Ali Awan (@1abidaliawan) er en sertifisert dataforsker som elsker å bygge maskinlæringsmodeller. For tiden fokuserer han på innholdsskaping og skriver tekniske blogger om maskinlæring og datavitenskapsteknologier. Abid har en mastergrad i teknologiledelse og en bachelorgrad i telekommunikasjonsteknikk. Hans visjon er å bygge et AI-produkt ved å bruke et grafisk nevralt nettverk for studenter som sliter med psykiske lidelser.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- : har
- :er
- :ikke
- $OPP
- 000
- 1
- 20
- a
- evne
- aktiv
- AI
- Alle
- tillater
- alternativ
- an
- og
- svar
- noen
- api
- Søknad
- ER
- rundt
- forfatter
- tilgjengelig
- award
- basert
- BE
- benchmarks
- Berkeley
- Bedre
- Stor
- Bing
- blogger
- både
- bygge
- Bygning
- by
- CAN
- kan ikke
- Sertifisert
- chatbot
- ChatGPT
- kode
- kommersiell
- Commons
- konkurrere
- komponenter
- inneholder
- innhold
- innholdsskaping
- konkurranse
- Kostnader
- skape
- opprettet
- skaperverket
- I dag
- dato
- datavitenskap
- dataforsker
- Databaser
- datasett
- besluttet
- Grad
- Demo
- utforming
- Utvikling
- gJORDE
- vanskelig
- Dolly
- Ansatt
- ansatte
- Ingeniørarbeid
- evaluering
- Hver
- utstillinger
- Face
- familie
- Noen få
- fokusering
- etter
- Til
- fra
- framtid
- generere
- genererer
- generative
- få
- graf
- Graf Neural Network
- Ha
- he
- høykvalitets
- holder
- HTML
- HTTPS
- sykdom
- bilde
- in
- informasjon
- interessert
- utstedelse
- saker
- IT
- jpg
- KDnuggets
- Språk
- stor
- Siste
- siste
- læring
- Tillatelse
- i likhet med
- maskin
- maskinlæring
- ledelse
- Master
- mental
- Mentalt syk
- kunne
- modell
- modeller
- modifisere
- Trenger
- nettverk
- neural
- nevrale nettverket
- Ny
- of
- on
- bare
- åpen
- åpen kildekode
- OpenAI
- or
- original
- produksjon
- par
- parameter
- deltok
- ytelse
- rørledning
- plato
- Platon Data Intelligence
- PlatonData
- Produkt
- profesjonell
- formål
- spørsmål
- spørsmål
- utgitt
- forskning
- løst
- begrenset
- s
- samme
- Vitenskap
- Forsker
- sett
- Kort
- Størrelse
- So
- noen
- kilde
- Rom
- mellomrom
- stanford
- startet
- state-of-the-art
- Stater
- Sliter
- Studenter
- egnet
- syntetisk
- syntetiske data
- Oppgave
- lag
- Teknisk
- Technologies
- Teknologi
- telekommunikasjon
- enn
- Det
- De
- Fremtiden
- de
- denne
- til
- topp
- Tog
- trent
- Kurs
- etter
- underliggende
- oppdatert
- bruke
- brukt
- ved hjelp av
- versjon
- syn
- var
- we
- uker
- var
- Hva
- hvilken
- HVEM
- med
- Arbeid
- ville
- skriving
- du
- zephyrnet










