Amazon RedShift er et fullstendig administrert og petabyte-skala skydatavarehus som brukes av titusenvis av kunder til å behandle exabyte med data hver dag for å drive analysearbeidsmengden deres. Du kan strukturere dataene dine, måle forretningsprosesser og få verdifull innsikt raskt kan gjøres ved å bruke en dimensjonsmodell. Amazon Redshift har innebygde funksjoner for å akselerere prosessen med modellering, orkestrering og rapportering fra en dimensjonsmodell.
I dette innlegget diskuterer vi hvordan du implementerer en dimensjonsmodell, nærmere bestemt Kimball-metodikk. Vi diskuterer implementeringsdimensjoner og fakta innen Amazon Redshift. Vi viser hvordan man utfører uttrekk, transformasjon og last (ELT), en integrasjonsprosess fokusert på å få rådata fra en datainnsjø inn i et iscenesettelseslag for å utføre modelleringen. Totalt sett vil innlegget gi deg en klar forståelse av hvordan du bruker dimensjonsmodellering i Amazon Redshift.
Løsningsoversikt
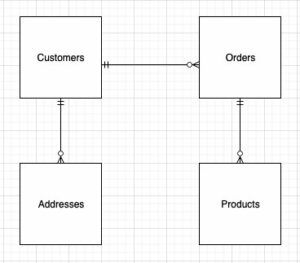
Følgende diagram illustrerer løsningsarkitekturen.

I de følgende avsnittene diskuterer og demonstrerer vi først nøkkelaspektene ved den dimensjonale modellen. Etter det lager vi en datamart ved hjelp av Amazon Redshift med en dimensjonal datamodell inkludert dimensjons- og faktatabeller. Data lastes og iscenesettes ved hjelp av KOPI kommandoen lastes dataene i dimensjonene ved hjelp av SLÅ SAMMEN uttalelse, og fakta vil bli koblet til dimensjonene der innsikt er hentet fra. Vi planlegger lasting av dimensjoner og fakta ved å bruke Amazon Redshift Query Editor V2. Til slutt bruker vi Amazon QuickSight for å få innsikt i de modellerte dataene i form av et QuickSight-dashbord.
For denne løsningen bruker vi et eksempeldatasett (normalisert) levert av Amazon Redshift for billettsalg til arrangementer. For dette innlegget har vi begrenset datasettet for enkelhets- og demonstrasjonsformål. Følgende tabeller viser eksempler på data for billettsalg og spillesteder.


Ifølge Kimball dimensjonsmodelleringsmetodikk, er det fire nøkkeltrinn i utformingen av en dimensjonsmodell:
- Identifiser forretningsprosessen.
- Deklarer kornet av dataene dine.
- Identifiser og implementer dimensjonene.
- Identifiser og implementer fakta.
I tillegg legger vi til et femte trinn for demonstrasjonsformål, som er å rapportere og analysere forretningshendelser.
Forutsetninger
For dette gjennomgangen bør du ha følgende forutsetninger:
Identifiser forretningsprosessen
Enkelt sagt, identifisering av forretningsprosessen er å identifisere en målbar hendelse som genererer data i en organisasjon. Vanligvis har selskaper et slags operasjonelt kildesystem som genererer dataene deres i sitt råformat. Dette er et godt utgangspunkt for å identifisere ulike kilder for en forretningsprosess.
Forretningsprosessen fortsettes deretter som en datamart i form av dimensjoner og fakta. Når vi ser på vårt eksempeldatasett nevnt tidligere, kan vi tydelig se at forretningsprosessen er salget for en gitt hendelse.
En vanlig feil som gjøres er å bruke avdelinger i et selskap som forretningsprosess. Dataene (forretningsprosessen) må integreres på tvers av ulike avdelinger, i dette tilfellet kan markedsføring få tilgang til salgsdataene. Det er avgjørende å identifisere den riktige forretningsprosessen – å ta feil av dette trinnet kan påvirke hele datamarkedet (det kan føre til at kornet dupliseres og feile beregninger i sluttrapportene).
Deklarer kornet av dataene dine
Å erklære kornet er handlingen med å identifisere en post i datakilden din. Kornet brukes i faktatabellen for å nøyaktig måle dataene og gjøre deg i stand til å rulle opp videre. I vårt eksempel kan dette være en ordrelinje i salgsprosessen.
I vårt brukstilfelle kan et salg identifiseres unikt ved å se på transaksjonstidspunktet da salget fant sted; dette vil være det mest atomære nivået.

Identifiser og implementer dimensjonene
Dimensjonstabellen din beskriver faktatabellen og dens attributter. Når du identifiserer den beskrivende konteksten til forretningsprosessen din, lagrer du teksten i en separat tabell, med tanke på faktatabellen. Når du kobler dimensjonstabellen til faktatabellen, skal det kun være en enkelt rad knyttet til faktatabellen. I vårt eksempel bruker vi følgende tabell for å deles inn i en dimensjonstabell; disse feltene beskriver fakta vi skal måle.
Når du designer strukturen til den dimensjonale modellen (skjemaet), kan du enten lage en stjerne or snøfnugg skjema. Strukturen bør være nært tilpasset forretningsprosessen; derfor passer et stjerneskjema best for vårt eksempel. Følgende figur viser vårt Entity Relationship Diagram (ERD).

I de følgende delene beskriver vi trinnene for å implementere dimensjonene.
Iscenesetter kildedataene
Før vi kan opprette og laste inn dimensjonstabellen, trenger vi kildedata. Derfor iscenesetter vi kildedataene til en iscenesettelse eller midlertidig tabell. Dette blir ofte referert til som iscenesettelseslag, som er råkopien av kildedataene. For å gjøre dette i Amazon Redshift bruker vi COPY kommando for å laste inn dataene fra den offentlige S3-bøtten dimensjonal-modellering-i-amazon-rødforskyvning som ligger på us-east-1 Region. Merk at COPY-kommandoen bruker en AWS identitets- og tilgangsadministrasjon (IAM) rolle med tilgang til Amazon S3. Rollen må være knyttet til klyngen. Fullfør følgende trinn for å iscenesette kildedataene:
- Opprett
venuekildetabell:
- Last inn lokaledata:
- Opprett
saleskildetabell:
- Last inn salgskildedata:
- Opprett
calendartabell:
- Last inn kalenderdata:
Lag dimensjonstabellen
Utformingen av dimensjonstabellen kan avhenge av forretningsbehovet ditt – må du for eksempel spore endringer i dataene over tid? Det er syv forskjellige dimensjonstyper. For vårt eksempel bruker vi typen 1 fordi vi ikke trenger å spore historiske endringer. For mer om type 2, se Forenkle datainnlasting i Type 2 sakte skiftende dimensjoner i Amazon Redshift. Dimensjonstabellen vil bli denormalisert med en primærnøkkel, surrogatnøkkel og noen få felt som er lagt til for å indikere endringer i tabellen. Se følgende kode:
Noen få merknader om hvordan du oppretter dimensjonstabellen:
- Feltnavnene omdannes til bedriftsvennlige navn
- Vår primære nøkkel er
VenueID, som vi bruker til å identifisere et sted hvor salget fant sted - To ekstra rader vil bli lagt til, som indikerer når en post ble satt inn og oppdatert (for å spore endringer)
- Vi bruker en AUTO distribusjonsstil å gi Amazon Redshift ansvaret for å velge og justere distribusjonsstilen
En annen viktig faktor å vurdere i dimensjonsmodellering er bruken av surrogatnøkler. Surrogatnøkler er kunstige nøkler som brukes i dimensjonsmodellering for å identifisere hver post unikt i en dimensjonstabell. De genereres vanligvis som et sekvensielt heltall, og de har ingen betydning i forretningsdomenet. De tilbyr flere fordeler, som å sikre unikhet og forbedre ytelsen i sammenføyninger, fordi de vanligvis er mindre enn naturlige nøkler og som surrogatnøkler endres de ikke over tid. Dette gjør at vi kan være konsekvente og lettere koble sammen fakta og dimensjoner.
I Amazon Redshift opprettes surrogatnøkler vanligvis ved å bruke IDENTITY-nøkkelordet. For eksempel oppretter den foregående CREATE-setningen en dimensjonstabell med en VenueSkey surrogatnøkkel. De VenueSkey kolonnen fylles automatisk ut med unike verdier når nye rader legges til i tabellen. Denne kolonnen kan deretter brukes til å slå sammen spillestedsbordet til FactSaleTransactions tabellen.
Noen tips for å designe surrogatnøkler:
- Bruk en liten datatype med fast bredde for surrogatnøkkelen. Dette vil forbedre ytelsen og redusere lagringsplass.
- Bruk nøkkelordet IDENTITY, eller generer surrogatnøkkelen ved å bruke en sekvensiell eller GUID-verdi. Dette vil sikre at surrogatnøkkelen er unik og ikke kan endres.
Last ned dimtabellen med MERGE
Det er mange måter å laste inn dimmet bord på. Visse faktorer må vurderes – for eksempel ytelse, datavolum og kanskje SLA-lastetider. Med SLÅ SAMMEN uttalelse, utfører vi en upsert uten å måtte spesifisere flere innsettings- og oppdateringskommandoer. Du kan sette opp SLÅ SAMMEN uttalelse i en Lagret prosedyre å fylle ut dataene. Du planlegger deretter at den lagrede prosedyren skal kjøres programmatisk via spørringseditoren, som vi viser senere i innlegget. Følgende kode oppretter en lagret prosedyre kalt SalesMart.DimVenueLoad:
Noen få merknader om dimensjonslasting:
- Når en post settes inn for første gang, vil den innsatte datoen og den oppdaterte datoen fylles ut. Når noen verdier endres, oppdateres dataene og den oppdaterte datoen gjenspeiler datoen da den ble endret. Den innsatte datoen gjenstår.
- Fordi dataene vil bli brukt av forretningsbrukere, må vi erstatte NULL-verdier, hvis noen, med mer forretningsmessige verdier.
Identifiser og implementer fakta
Nå som vi har erklært at kornet vårt er et salg som fant sted på et bestemt tidspunkt, vil faktatabellen vår lagre numeriske fakta for forretningsprosessen vår.
Vi har identifisert følgende numeriske fakta å måle:
- Antall solgte billetter per salg
- Provisjon for salget
Implementering av faktum
Det finnes tre typer faktatabeller (transaksjonsfaktatabell, periodisk faktatabell for øyeblikksbilder og faktatabell for akkumulering av øyeblikksbilde). Hver serverer et annet syn på forretningsprosessen. For vårt eksempel bruker vi en transaksjonsfaktatabell. Fullfør følgende trinn:
- Lag faktatabellen
En innsatt dato med en standardverdi legges til, som indikerer om og når en post ble lastet. Du kan bruke dette når du laster faktatabellen på nytt for å fjerne de allerede innlastede dataene for å unngå duplikater.
Lasting av faktatabellen består av en enkel innsettingssetning som forener de tilknyttede dimensjonene dine. Vi blir med fra DimVenue tabellen som ble opprettet, som beskriver våre fakta. Det er beste praksis, men valgfritt å ha kalenderdato dimensjoner, som lar sluttbrukeren navigere i faktatabellen. Data kan enten lastes inn når det er et nytt salg, eller daglig; det er her den innsatte datoen eller lastedatoen kommer godt med.
Vi laster faktatabellen ved hjelp av en lagret prosedyre og bruker en datoparameter.
- Opprett den lagrede prosedyren med følgende kode. For å beholde den samme dataintegriteten som vi brukte i dimensjonsbelastningen, erstatter vi NULL-verdier, hvis noen, med mer forretningsmessige verdier:
- Last inn dataene ved å ringe fremgangsmåten med følgende kommando:
Planlegg datainnlastingen
Vi kan nå automatisere modelleringsprosessen ved å planlegge de lagrede prosedyrene i Amazon Redshift Query Editor V2. Fullfør følgende trinn:
- Vi kaller først dimensjonsbelastningen, og etter at dimensjonsbelastningen har kjørt vellykket, begynner faktabelastningen:
Hvis dimensjonsbelastningen svikter, vil ikke faktalasten kjøre. Dette sikrer konsistens i dataene fordi vi ikke ønsker å laste faktatabellen med utdaterte dimensjoner.
- For å planlegge belastningen, velg Planlegg i Query Editor V2.

- Vi planlegger at spørringen skal kjøres hver dag kl. 5.
- Eventuelt kan du legge til feilmeldinger ved å aktivere Amazon enkel varslingstjeneste (Amazon SNS) varsler.

Rapporter og analyser dataene i Amazon Quicksight
QuickSight er en business intelligence-tjeneste som gjør det enkelt å levere innsikt. Som en fullstendig administrert tjeneste lar QuickSight deg enkelt lage og publisere interaktive dashboards som deretter kan nås fra hvilken som helst enhet og bygges inn i applikasjonene, portalene og nettstedene dine.
Vi bruker vår datamart til å visuelt presentere fakta i form av et dashbord. For å komme i gang og sette opp QuickSight, se Opprette et datasett ved hjelp av en database som ikke er autooppdaget.
Etter at du har opprettet datakilden din i QuickSight, slår vi sammen de modellerte dataene (datamart) basert på vår surrogatnøkkel skey. Vi bruker dette datasettet for å visualisere datamarkedet.

Sluttdashbordet vårt vil inneholde datamarkedets innsikt og svare på kritiske forretningsspørsmål, for eksempel total provisjon per spillested og datoer med høyest salg. Følgende skjermbilde viser sluttproduktet til datamarkedet.

Rydd opp
For å unngå fremtidige kostnader, slett eventuelle ressurser du opprettet som en del av dette innlegget.
konklusjonen
Vi har nå implementert en datamart med vår DimVenue, DimCalendarog FactSaleTransactions tabeller. Vårt lager er ikke komplett; ettersom vi kan utvide datamarkedet med mer fakta og implementere flere mars, og ettersom forretningsprosessen og kravene vokser over tid, vil datavarehuset også vokse. I dette innlegget ga vi et ende-til-ende syn på forståelse og implementering av dimensjonsmodellering i Amazon Redshift.
Kom i gang med din Amazon RedShift dimensjonsmodell i dag.
Om forfatterne
 Bernard Verster er en erfaren skyingeniør med mange års eksponering i å lage skalerbare og effektive datamodeller, definere dataintegrasjonsstrategier og sikre datastyring og sikkerhet. Han brenner for å bruke data til å generere innsikt, samtidig som han er i tråd med forretningskrav og mål.
Bernard Verster er en erfaren skyingeniør med mange års eksponering i å lage skalerbare og effektive datamodeller, definere dataintegrasjonsstrategier og sikre datastyring og sikkerhet. Han brenner for å bruke data til å generere innsikt, samtidig som han er i tråd med forretningskrav og mål.
 Abhishek Pan er en WWSO-spesialist i SA-Analytics som jobber med kunder i offentlig sektor fra AWS India. Han engasjerer seg med kunder for å definere datadrevet strategi, gi dypdykksøkter om analytiske brukstilfeller og designe skalerbare og effektive analytiske applikasjoner. Han har 12 års erfaring og brenner for databaser, analyser og AI/ML. Han er en ivrig reisende og prøver å fange verden gjennom kameralinsen.
Abhishek Pan er en WWSO-spesialist i SA-Analytics som jobber med kunder i offentlig sektor fra AWS India. Han engasjerer seg med kunder for å definere datadrevet strategi, gi dypdykksøkter om analytiske brukstilfeller og designe skalerbare og effektive analytiske applikasjoner. Han har 12 års erfaring og brenner for databaser, analyser og AI/ML. Han er en ivrig reisende og prøver å fange verden gjennom kameralinsen.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Om oss
- akselerere
- adgang
- aksesseres
- nøyaktig
- tvers
- Handling
- legge til
- la til
- Ytterligere
- Etter
- AI / ML
- justere
- justering
- tillate
- tillater
- allerede
- am
- Amazon
- Amazon Web Services
- an
- analyse
- Analytisk
- analytics
- analysere
- og
- besvare
- noen
- søknader
- anvendt
- hensiktsmessig
- arkitektur
- ER
- kunstig
- AS
- aspekter
- assosiert
- At
- attributter
- auto
- automatisere
- automatisk
- unngå
- AWS
- b
- basert
- BE
- fordi
- begynne
- Fordeler
- BEST
- innebygd
- virksomhet
- business intelligence
- Forretningsprosess
- forretningsprosesser
- men
- by
- Kalender
- ring
- som heter
- ringer
- rom
- CAN
- fangst
- saken
- saker
- Årsak
- viss
- endring
- endret
- Endringer
- endring
- karakter
- avgifter
- Velg
- fjerne
- klart
- tett
- Cloud
- kode
- Kolonne
- kommer
- kommisjon
- Felles
- Selskaper
- Selskapet
- fullføre
- Vurder
- konsistent
- består
- kontekst
- korrigere
- kunne
- skape
- opprettet
- skaper
- Opprette
- skaperverket
- kritisk
- Kunder
- daglig
- dashbord
- oversikter
- dato
- dataintegrasjon
- Data Lake
- datalager
- data-drevet
- Datadrevet strategi
- Database
- databaser
- Dato
- datoer
- dato tid
- dag
- dyp
- dypdykk
- Misligholde
- definere
- leverer
- demonstrere
- avdelinger
- Avledet
- beskrive
- utforming
- utforme
- detalj
- enhet
- forskjellig
- Dimensjon
- dimensjoner
- diskutere
- distinkt
- distribusjon
- do
- domene
- gjort
- ikke
- ned
- stasjonen
- duplikater
- hver enkelt
- Tidligere
- lett
- lett
- redaktør
- effektiv
- enten
- innebygd
- muliggjøre
- muliggjør
- slutt
- ende til ende
- engasjerer
- ingeniør
- sikre
- sikrer
- sikrer
- Hele
- enhet
- Eter (ETH)
- Event
- hendelser
- Hver
- hver dag
- eksempel
- eksempler
- Expand
- erfaring
- erfaren
- Eksponering
- trekke ut
- Faktisk
- faktor
- faktorer
- fakta
- mislykkes
- Failure
- Egenskaper
- Noen få
- felt
- Felt
- femte
- Figur
- filtrere
- slutt~~POS=TRUNC
- Først
- første gang
- passer
- fokuserte
- etter
- Til
- skjema
- format
- fire
- fra
- fullt
- videre
- framtid
- Gevinst
- generere
- generert
- genererer
- få
- få
- Gi
- gitt
- god
- styresett
- Grow
- praktisk
- Ha
- he
- høyest
- hans
- historisk
- ferie
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- IAM
- identifisert
- identifisere
- identifisering
- Identitet
- if
- illustrerer
- Påvirkning
- iverksette
- implementert
- implementere
- viktig
- forbedre
- bedre
- in
- Inkludert
- india
- indikerer
- indikerer
- info
- innsikt
- integrert
- integrering
- integritet
- Intelligens
- interaktiv
- inn
- IT
- DET ER
- bli medlem
- ble med
- sammenføyning
- tiltrer
- jpg
- Hold
- holde
- nøkkel
- nøkler
- innsjø
- Språk
- seinere
- siste
- lag
- venstre
- Lens
- Lar
- Nivå
- linje
- laste
- lasting
- laster
- ligger
- ser
- laget
- GJØR AT
- fikk til
- Marketing
- matchet
- betyr
- måle
- nevnt
- Flett
- Metrics
- tankene
- feil
- modell
- modellering
- modellering
- modeller
- Måned
- mer
- mest
- flere
- navn
- Naturlig
- Naviger
- Trenger
- trenger
- behov
- Ny
- Merknader
- varsling
- varslinger
- nå
- mange
- mål
- of
- tilby
- ofte
- on
- bare
- operasjonell
- or
- organisasjon
- vår
- enn
- samlet
- parameter
- del
- lidenskapelig
- for
- utføre
- ytelse
- kanskje
- periodisk
- Sted
- plato
- Platon Data Intelligence
- PlatonData
- Point
- befolket
- Post
- makt
- praksis
- forutsetninger
- presentere
- primære
- prosedyren
- prosedyrer
- prosess
- Prosesser
- Produkt
- gi
- forutsatt
- gir
- offentlig
- publisere
- formål
- spørsmål
- raskt
- heve
- Raw
- rådata
- rekord
- poster
- redusere
- referert
- Gjenspeiler
- region
- forholdet
- forblir
- fjerne
- erstatte
- rapporterer
- Rapportering
- Rapporter
- Krav
- Ressurser
- ansvar
- Rolle
- Rull
- RAD
- Kjør
- går
- salg
- salg
- samme
- Eksempel på datasett
- skalerbar
- planlegge
- planlegging
- seksjoner
- sektor
- sikkerhet
- se
- separat
- serverer
- tjeneste
- Tjenester
- sesjoner
- sett
- flere
- bør
- Vis
- Viser
- Enkelt
- enkelhet
- enkelt
- Sakte
- liten
- mindre
- Snapshot
- So
- solgt
- løsning
- noen
- kilde
- Kilder
- Rom
- spesialist
- spesifikk
- spesielt
- Scene
- iscenesettelse
- Stjerne
- startet
- Start
- Uttalelse
- Trinn
- Steps
- lagring
- oppbevare
- lagret
- strategier
- Strategi
- struktur
- vellykket
- vellykket
- slik
- system
- bord
- midlertidig
- titus
- vilkår
- enn
- Det
- De
- Kilden
- verden
- deres
- deretter
- Der.
- derfor
- Disse
- de
- denne
- tusener
- Gjennom
- billett
- billettsalg
- billetter
- tid
- ganger
- tidsstempel
- tips
- til
- i dag
- sammen
- tok
- Totalt
- spor
- Transaksjonen
- Transform
- forvandlet
- reisende
- typen
- typer
- typisk
- forståelse
- unik
- unikt
- unikhet
- ukjent
- Oppdater
- oppdatert
- us
- bruk
- bruke
- bruk sak
- brukt
- Brukere
- bruker
- ved hjelp av
- vanligvis
- Verdifull
- verdi
- Verdier
- ulike
- Venue
- arenaer
- av
- Se
- volum
- walkthrough
- ønsker
- Warehouse
- var
- måter
- we
- web
- webtjenester
- nettsteder
- uke
- når
- hvilken
- mens
- vil
- med
- innenfor
- uten
- arbeid
- verden
- Feil
- år
- år
- du
- Din
- zephyrnet