Automatisert dataanalyse (ADA) på AWS er en AWS-løsning som lar deg utlede meningsfull innsikt fra data i løpet av få minutter gjennom et enkelt og intuitivt brukergrensesnitt. ADA tilbyr en AWS-native dataanalyseplattform som er klar til bruk ut av esken av dataanalytikere for en rekke brukstilfeller. Med ADA kan team innta, transformere, styre og spørre forskjellige datasett fra en rekke datakilder uten å kreve spesialisttekniske ferdigheter. ADA gir et sett med forhåndsbygde kontakter å innta data fra et bredt spekter av kilder, inkludert Amazon enkel lagringstjeneste (Amazon S3), Amazon Kinesis datastrømmer, Amazon CloudWatch, Amazon CloudTrailog Amazon DynamoDB så vel som mange andre.
ADA gir en grunnleggende plattform som kan brukes av dataanalytikere i et mangfoldig sett med brukstilfeller, inkludert IT, økonomi, markedsføring, salg og sikkerhet. ADAs ut-av-boksen CloudWatch-datakobling tillater datainntak fra CloudWatch-logger i samme AWS-konto som ADA har blitt distribuert i, eller fra en annen AWS-konto.
I dette innlegget viser vi hvordan en applikasjonsutvikler eller applikasjonstester er i stand til å bruke ADA til å utlede driftsinnsikt for applikasjoner som kjører i AWS. Vi viser også hvordan du kan bruke ADA-løsningen til å koble til ulike datakilder i AWS. Vi først implementere ADA-løsningen inn på en AWS-konto og sette opp ADA-løsningen ved å lage data produkter ved hjelp av datakoblinger. Vi bruker deretter ADA Query Workbench til å slå sammen de separate datasettene og spørre de korrelerte dataene, ved å bruke kjente Structured Query Language (SQL), for å få innsikt. Vi viser også hvordan ADA kan integreres med business intelligence (BI)-verktøy som Tableau for å visualisere dataene og bygge rapporter.
Løsningsoversikt
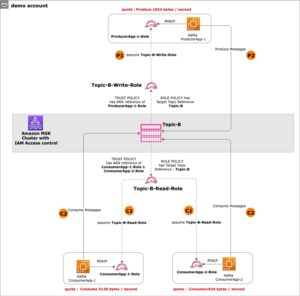
I denne delen presenterer vi løsningsarkitekturen for demoen og forklarer arbeidsflyten. For demonstrasjonsformål simuleres den skreddersydde applikasjonen ved hjelp av en AWS Lambda funksjon som sender ut pålogginger Apache-loggformat med et forhåndsinnstilt intervall ved hjelp av Amazon EventBridge. Dette standardformatet kan produseres av mange forskjellige webservere og leses av mange logganalyseprogrammer. Applikasjonsloggene (Lambda-funksjon) sendes til en CloudWatch-logggruppe. De historiske applikasjonsloggene lagres i en S3-bøtte for referanse og for spørringsformål. En oppslagstabell med en liste over HTTP-statuskoder sammen med beskrivelsene er lagret i en DynamoDB-tabell. Disse tre fungerer som kilder hvorfra data tas inn i ADA for korrelasjon, spørring og analyse. Vi implementere ADA-løsningen inn på en AWS-konto og sette opp ADA. Vi lager deretter data produkter innen ADA for CloudWatch-logggruppe, S3 bøtteog DynamoDB. Etter hvert som dataproduktene konfigureres, sørger ADA for datapipelines for å innta dataene fra kildene. Med ADA Query Workbench kan du spørre de inntatte dataene ved hjelp av vanlig SQL for applikasjonsfeilsøking eller problemdiagnose.
Følgende diagram gir en oversikt over arkitekturen og arbeidsflyten ved bruk av ADA for å få innsikt i applikasjonslogger.
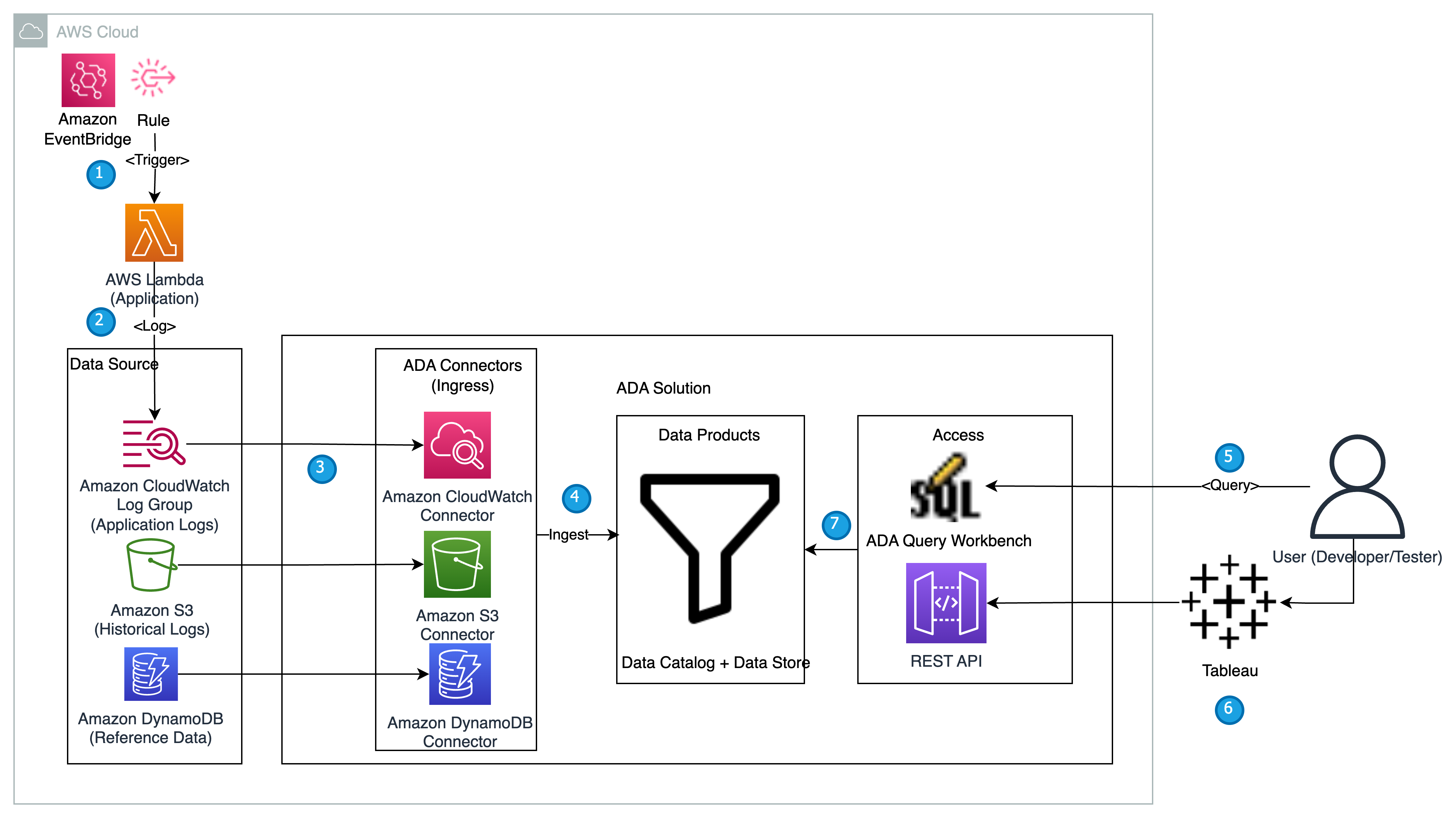
Arbeidsflyten inkluderer følgende trinn:
- En Lambda-funksjon er planlagt utløst med 2-minutters intervaller ved hjelp av EventBridge.
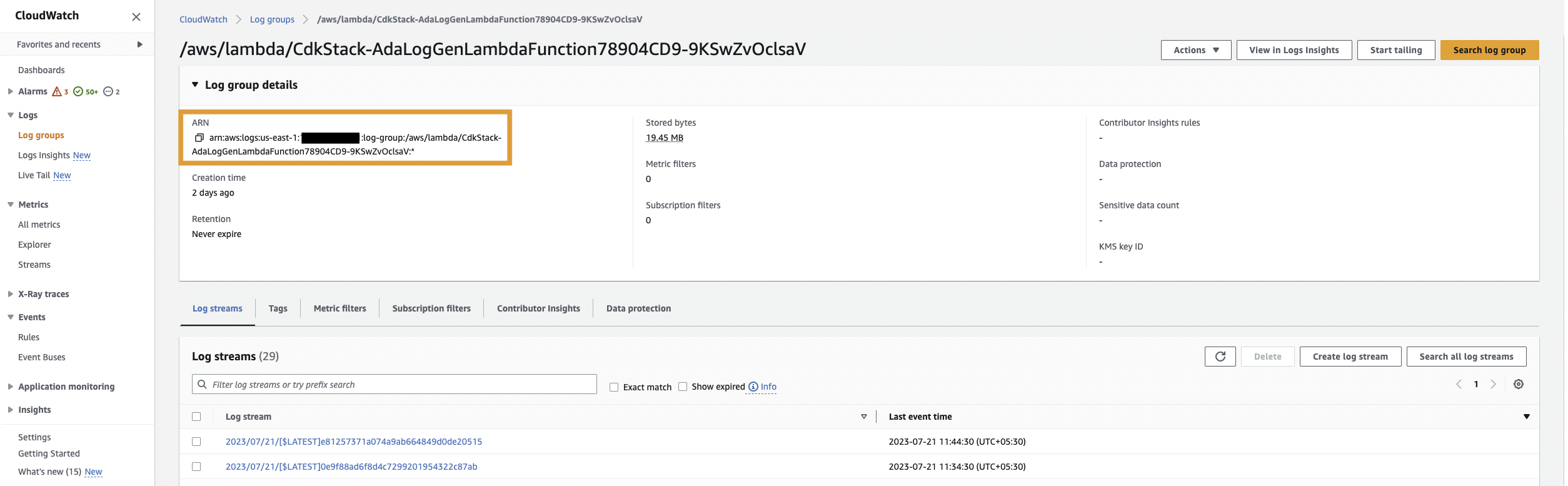
- Lambda-funksjonen sender ut logger som er lagret i en spesifisert CloudWatch-logggruppe under
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Applikasjonsloggene genereres ved hjelp av Apache Log Format-skjemaet, men lagres i CloudWatch-logggruppen i JSON-format. - Dataproduktene for CloudWatch, Amazon S3 og DynamoDB er laget i ADA. CloudWatch-dataproduktet kobles til CloudWatch-logggruppen der applikasjonsloggene (Lambda-funksjon) lagres. Amazon S3-kontakten kobles til en S3 bøttemappe der de historiske loggene er lagret. DynamoDB-koblingen kobles til en DynamoDB-tabell der statuskodene som henvises til av applikasjonen og historiske logger lagres.
- For hvert av dataproduktene distribuerer ADA datapipeline-infrastrukturen for å innta data fra kildene. Når datainntaket er fullført, kan du skrive spørringer ved hjelp av SQL via ADA Query Workbench.
- Du kan logge på ADA-portalen og komponere SQL-spørringer fra Query Workbench for å få innsikt i applikasjonsloggene. Du kan eventuelt lagre spørringen og dele spørringen med andre ADA-brukere i samme domene. ADA-spørringsfunksjonen drives av Amazonas Athena, som er en serverløs, interaktiv analysetjeneste som gir en forenklet, fleksibel måte å analysere petabyte med data på.
- Tableau er konfigurert for å få tilgang til ADA-dataproduktene via ADA-utgangsendepunkter. Deretter lager du et dashbord med to diagrammer. Det første diagrammet er et varmekart som viser utbredelsen av HTTP-feilkoder korrelert med applikasjonens API-endepunkter. Det andre diagrammet er et stolpediagram som viser de 10 beste applikasjons-API-ene med en total telling av HTTP-feilkoder fra de historiske dataene.
Forutsetninger
For dette innlegget må du fullføre følgende forutsetninger:
- Installer AWS kommandolinjegrensesnitt (AWS CLI), AWS skyutviklingssett (AWS CDK) forutsetninger, TypeScript-spesifikk forutsetningerog git.
- Distribuer ADA-løsningen i AWS-kontoen din i
us-east-1Region.- Oppgi en admin-e-postadresse mens du starter ADA AWS skyformasjon stable. Dette er nødvendig for at ADA skal sende root-brukerpassordet. Et administratortelefonnummer kreves for å motta en engangspassordmelding hvis multifaktorautentisering (MFA) er aktivert. For denne demoen er ikke MFA aktivert.
- Bygg og distribuer eksempelapplikasjonen (tilgjengelig på GitHub repo) løsning slik at følgende ressurser kan tilrettelegges på kontoen din i
us-east-1Region:- En Lambda-funksjon som simulerer loggapplikasjonen og en EventBridge-regel som påkaller applikasjonsfunksjonen med 2-minutters intervaller.
- En S3-bøtte med de relevante bøttepolicyene og en CSV-fil som inneholder de historiske applikasjonsloggene.
- En DynamoDB-tabell med oppslagsdata.
- Aktuell AWS identitets- og tilgangsadministrasjon (IAM) roller og tillatelser som kreves for tjenestene.
- Eventuelt, installer Tableau skrivebord, en tredjeparts BI-leverandør. For dette innlegget bruker vi Tableau Desktop versjon 2021.2. Det er en kostnad forbundet med å bruke en lisensiert versjon av Tableau Desktop-applikasjonen. For ytterligere detaljer, se Tableau lisensiering informasjon.
Distribuer og sett opp ADA
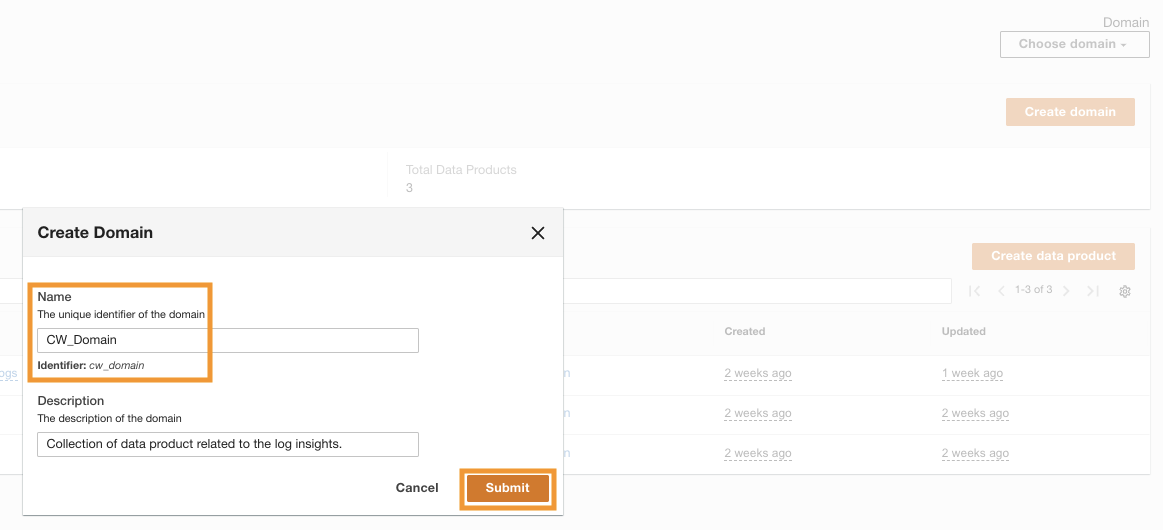
Etter at ADA er implementert, kan du Logg inn ved å bruke admin-e-postadressen som ble oppgitt under installasjonen. Deretter oppretter du en domene navngitt CW_Domain. Et domene er en brukerdefinert samling av dataprodukter. Et domene kan for eksempel være et team eller et prosjekt. Domener gir en strukturert måte for brukere å organisere dataproduktene sine og administrere tilgangstillatelser.
- Velg på ADA-konsollen Domener i navigasjonsruten.
- Velg Opprett domene.
- Skriv inn et navn (
CW_Domain) og beskrivelse, og velg deretter Send.
Sett opp eksempelapplikasjonsinfrastrukturen ved hjelp av AWS CDK
AWS CDK-løsningen som distribuerer demoapplikasjonen er vert for GitHub. Trinnene for å klone repoen og sette opp AWS CDK-prosjektet er detaljert i denne delen. Før du kjører disse kommandoene, sørg for å gjøre det konfigurere din AWS-legitimasjon. Opprett en mappe, åpne terminalen og naviger til mappen der AWS CDK-løsningen må installeres. Kjør følgende kode:
Disse trinnene utfører følgende handlinger:
- Installer bibliotekavhengighetene
- Bygg prosjektet
- Generer en gyldig CloudFormation-mal
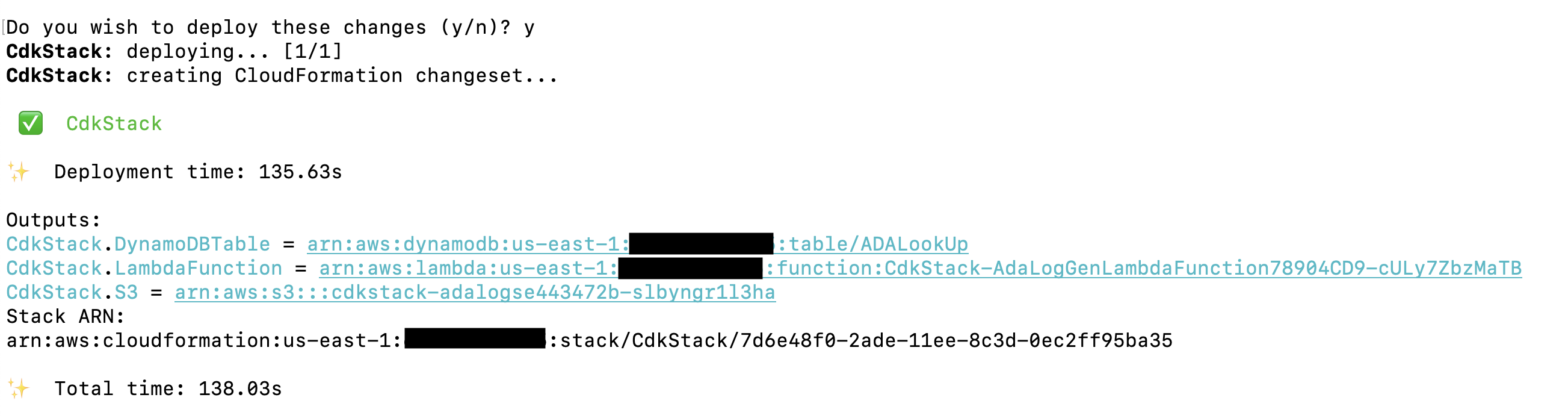
- Distribuer stabelen ved å bruke AWS CloudFormation i AWS-kontoen din
Utrullingen tar omtrent 1–2 minutter og oppretter DynamoDB-oppslagstabellen, Lambda-funksjonen og S3-bøtten som inneholder de historiske loggfilene som utdata. Kopier disse verdiene til et tekstredigeringsprogram, for eksempel Notisblokk.
Lag ADA-dataprodukter
Vi lager tre forskjellige dataprodukter for denne demoen, ett for hver datakilde du vil spørre etter for å få driftsinnsikt. Et dataprodukt er et datasett (en samling av data som en tabell eller en CSV-fil) som er vellykket importert til ADA og som kan spørres.
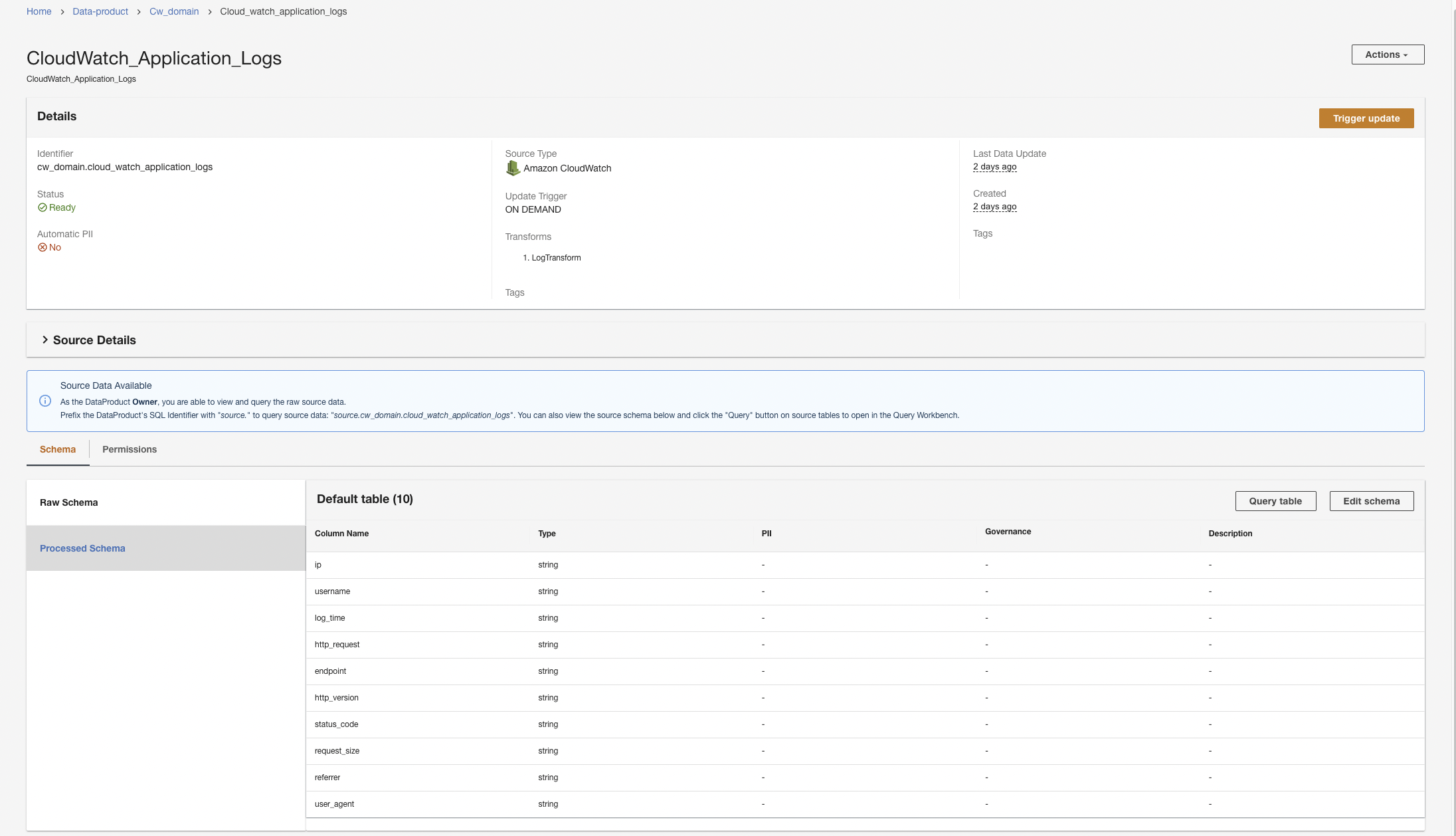
Opprett et CloudWatch-dataprodukt
Først lager vi et dataprodukt for applikasjonsloggene ved å sette opp ADA for å innta CloudWatch-logggruppen for eksempelapplikasjonen (Lambda-funksjonen). Bruke CdkStack.LambdaFunction utgang for å få Lambda-funksjonen ARN og finn den tilsvarende CloudWatch-logggruppen ARN på CloudWatch-konsollen.
Fullfør deretter følgende trinn:
- På ADA-konsollen, naviger til ADA-domenet og lag et CloudWatch-dataprodukt.
- Til Navn¸ skriv inn et navn.
- Til Kildetype, velge Amazon CloudWatch.
- Deaktiver Automatisk PII.
ADA har en funksjon som automatisk oppdager personlig identifiserbar informasjon (PII) data under import som er aktivert som standard. For denne demoen deaktiverer vi dette alternativet for dataproduktet fordi oppdagelsen av PII-data ikke er innenfor omfanget av denne demoen.
- Velg neste.
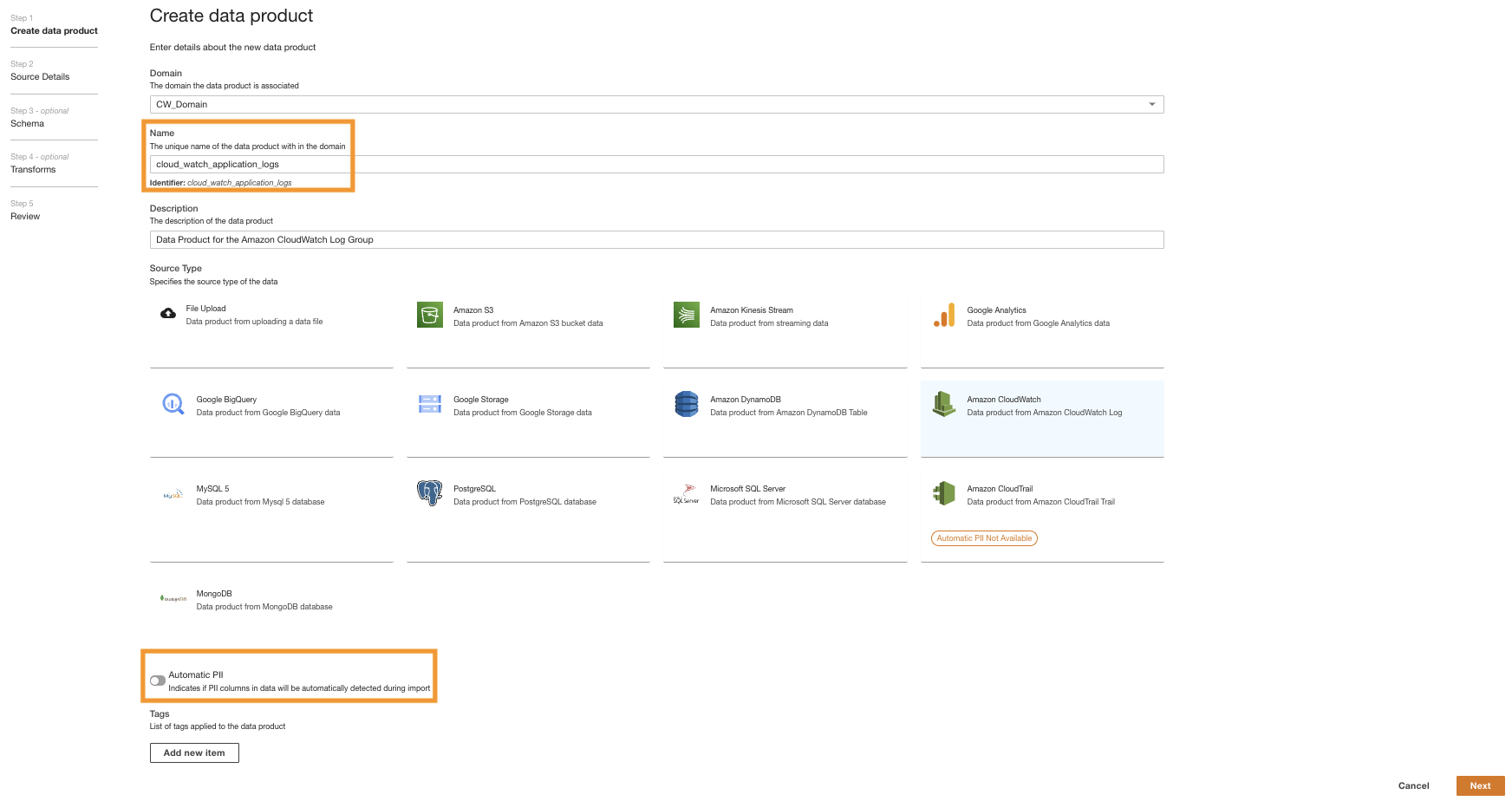
- Søk etter og velg CloudWatch-logggruppen ARN kopiert fra forrige trinn.

- Kopier logggruppen ARN.
- På dataproduktsiden skriver du inn logggruppen ARN.
- Til CloudWatch-spørring, skriv inn et søk du vil at ADA skal hente fra logggruppen.
I denne demoen spør vi @meldingsfeltet fordi vi er interessert i å få applikasjonsloggene fra logggruppen.
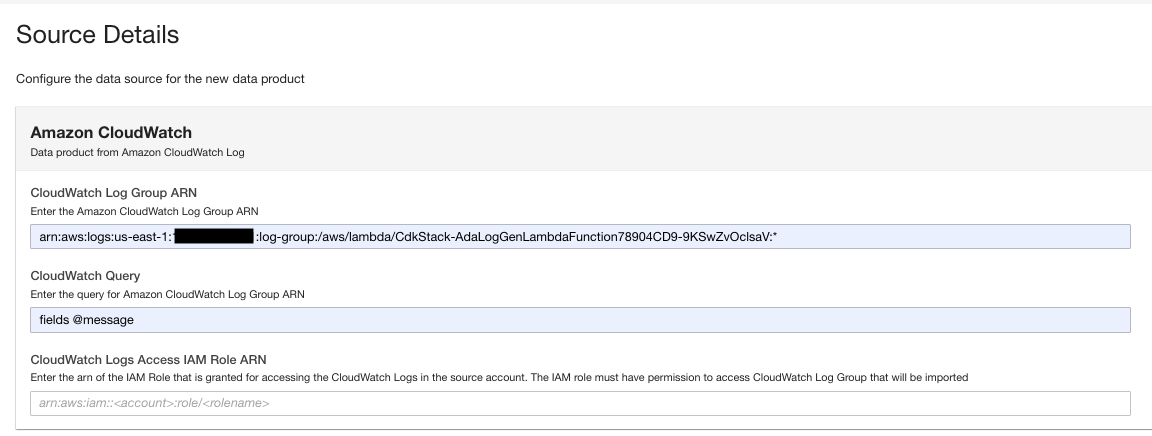
- Velg hvordan dataoppdateringene skal utløses etter første import.
ADA kan konfigureres til å ta inn data fra kilden med fleksible intervaller (opptil 15 minutter eller senere) eller på forespørsel. For demoen setter vi dataoppdateringene til å kjøre hver time.
- Velg neste.
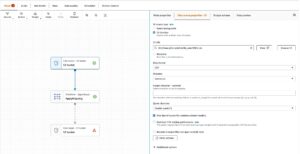
Deretter vil ADA koble seg til logggruppen og spørre etter skjemaet. Fordi loggene er i Apache-loggformat, transformerer vi loggene til separate felt slik at vi kan kjøre spørringer på de spesifikke loggfeltene. ADA gir fire standard~~POS=TRUNC transformasjoner og støtter tilpasset transformasjon gjennom et Python-skript. I denne demoen kjører vi et tilpasset Python-skript for å transformere JSON-meldingsfeltet til Apache Log Format-felt.
- Velg Transform skjema.
- Velg Lag ny transformasjon.
- Last opp
apache-log-extractor-transform.pymanus fra/asset/transform_logs/mappe. - Velg Send.
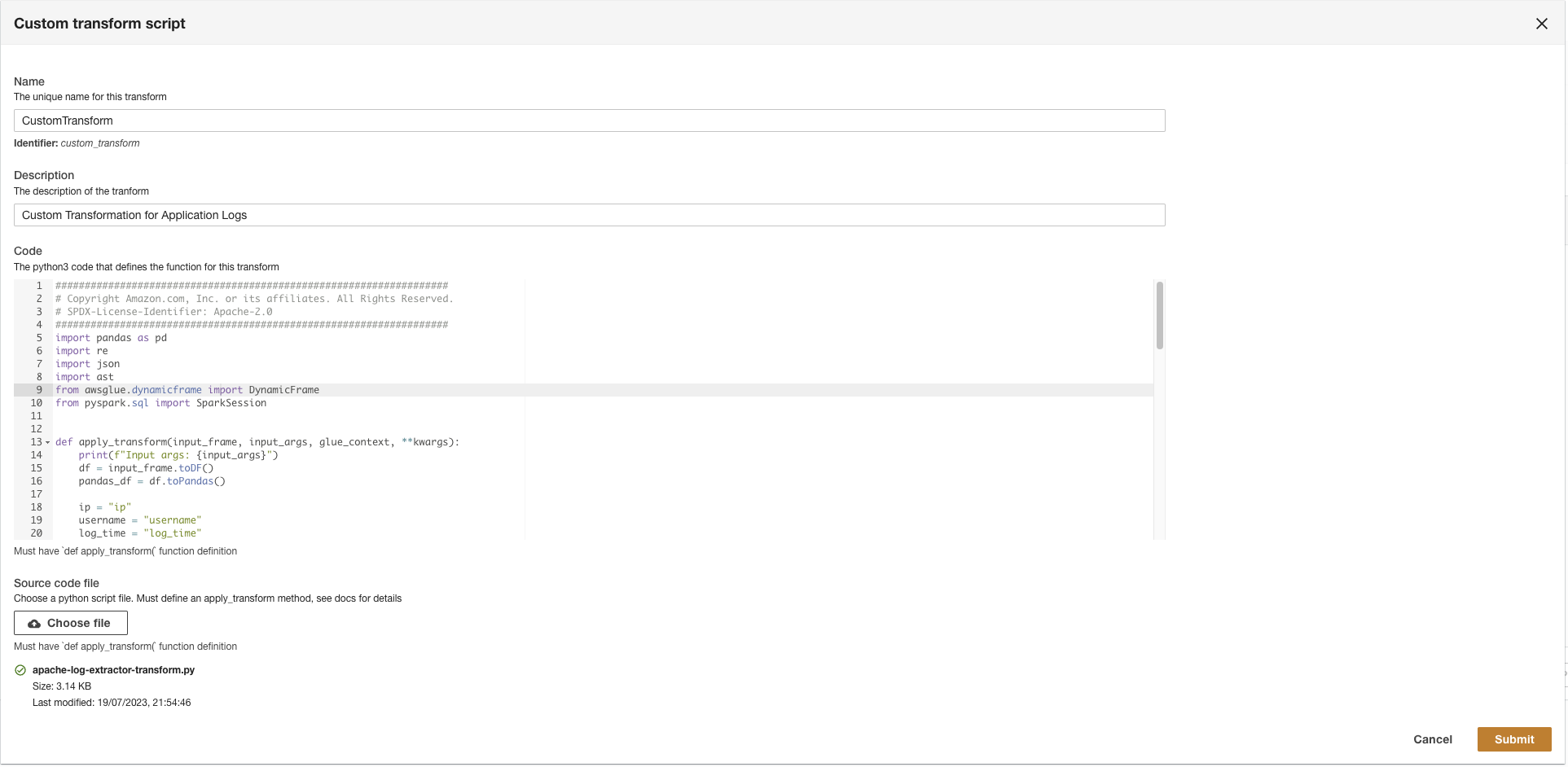
ADA vil transformere CloudWatch-loggene ved å bruke skriptet og presentere det behandlede skjemaet.
- Velg neste.
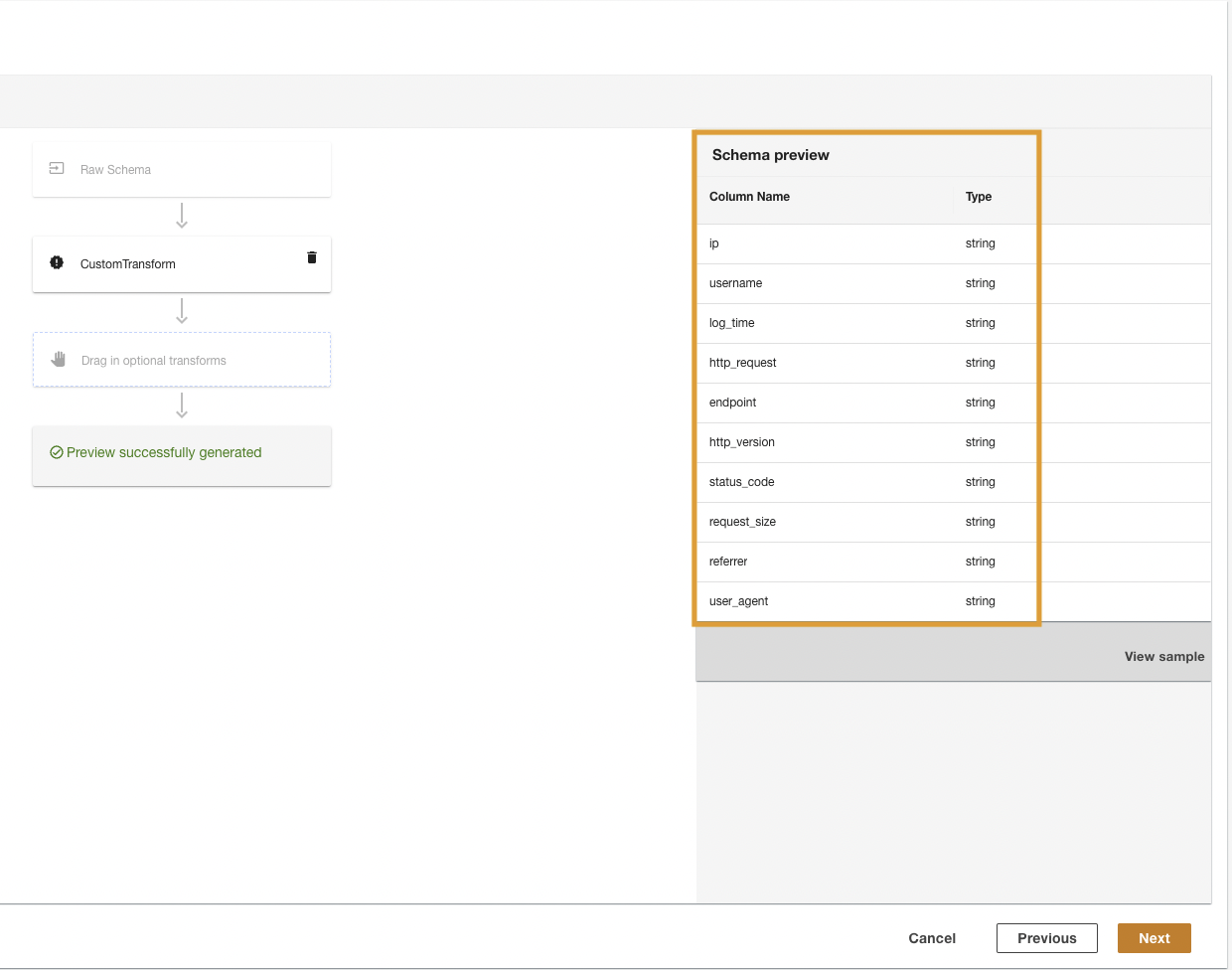
- I det siste trinnet, se gjennom trinnene og velg Send.
ADA vil starte databehandlingen, opprette datarørledningene og forberede CloudWatch-logggruppene for å bli spurt fra Query Workbench. Denne prosessen vil ta noen minutter å fullføre og vises på ADA-konsollen under Dataprodukter.
Lag et Amazon S3-dataprodukt
Vi gjentar trinnene for å legge til de historiske loggene fra Amazon S3-datakilden og slå opp referansedata fra DynamoDB-tabellen. For disse to datakildene oppretter vi ikke tilpassede transformasjoner fordi dataformatene er i CSV (for historiske logger) og nøkkelattributter (for referanseoppslagsdata).
- På ADA-konsollen oppretter du et nytt dataprodukt.
- Skriv inn et navn (
hist_logs) og velg Amazon S3.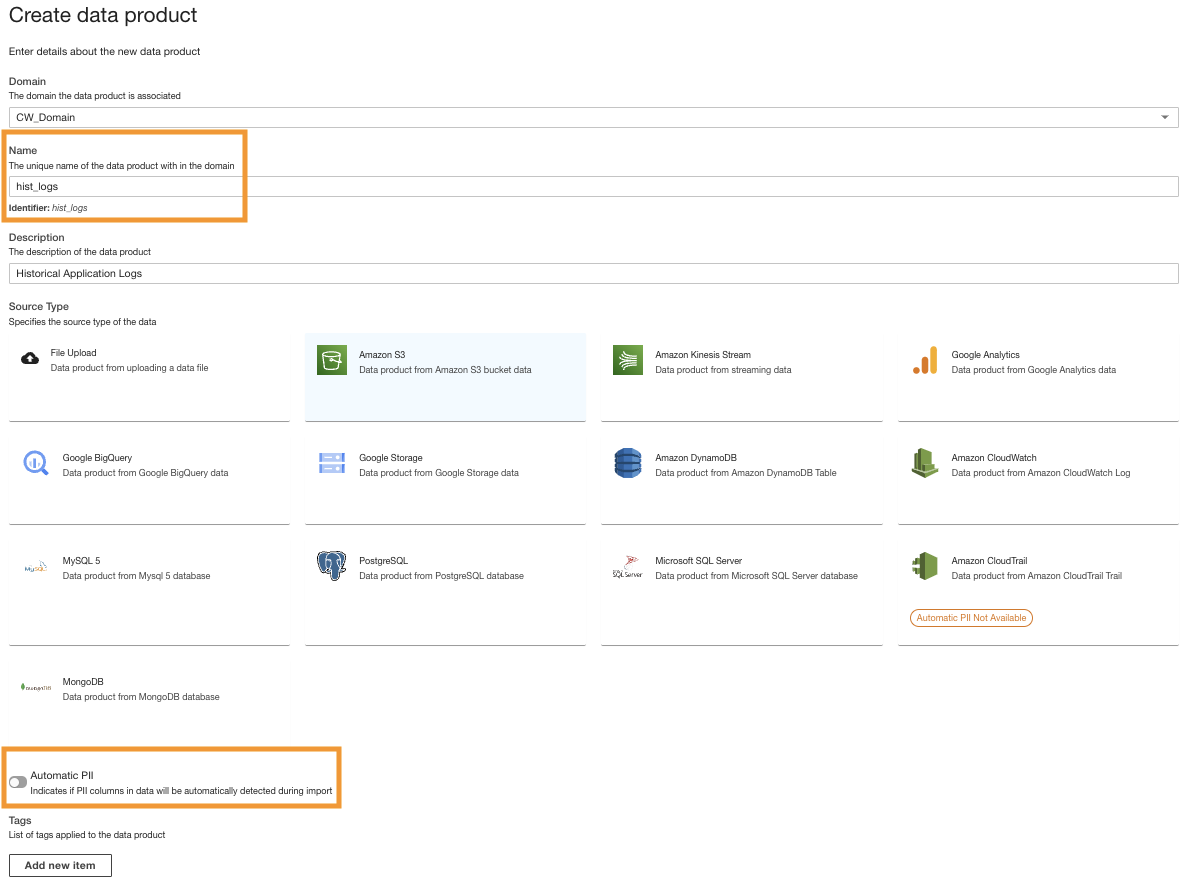
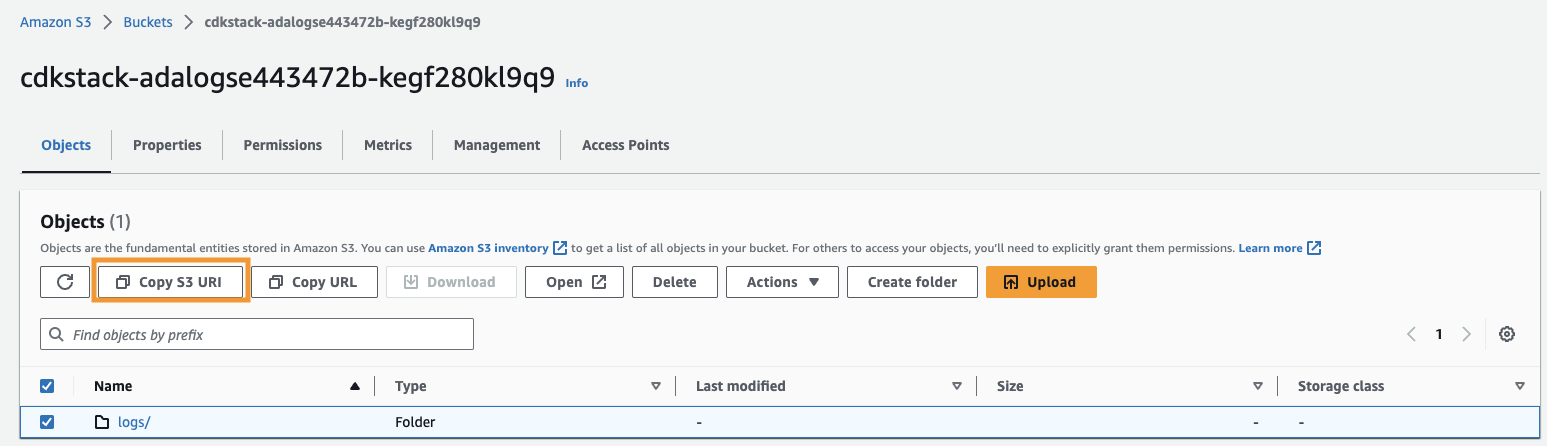
- Kopier Amazon S3 URI (teksten etter
arn:aws:s3:::) fraCdkStack.S3utdatavariabel og naviger til Amazon S3-konsollen. - Skriv inn den kopierte teksten i søkefeltet, åpne S3-bøtten, velg
/logsmappen, og velg Kopier S3 URI.
De historiske loggene er lagret i denne banen.
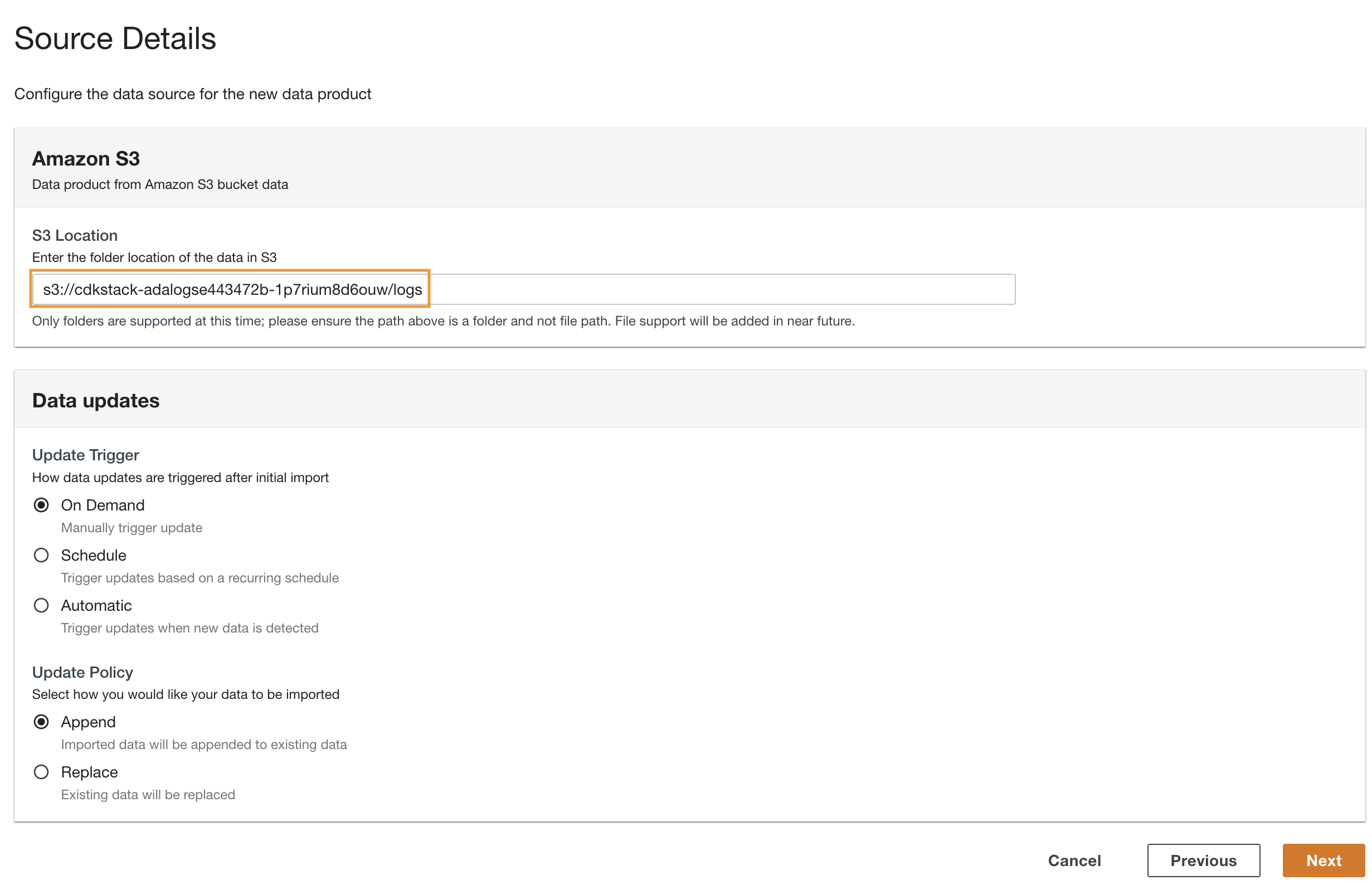
- Naviger tilbake til ADA-konsollen og skriv inn den kopierte S3 URI for S3 beliggenhet.
- Til Oppdater trigger, plukke ut På etterspørsel fordi de historiske loggene oppdateres med en uspesifisert frekvens.
- Til Oppdater policy, plukke ut Tilføy for å legge til nylig importerte data til eksisterende data.
- Velg neste.
ADA behandler skjemaet for filene i den valgte mappebanen. Fordi loggene er i CSV-format, er ADA i stand til å lese kolonnenavnene uten å kreve ytterligere transformasjoner. Imidlertid kolonnene status_code og request_size utledes som lang type av ADA. Vi ønsker å holde kolonnedatatypene konsistente blant dataproduktene, slik at vi kan slå sammen datatabellene og spørre etter dataene. Kolonnen status_code vil bli brukt til å lage sammenføyninger på tvers av datatabellene.
- Velg Transform skjema for å endre datatypene for de to kolonnene til strengdatatype.
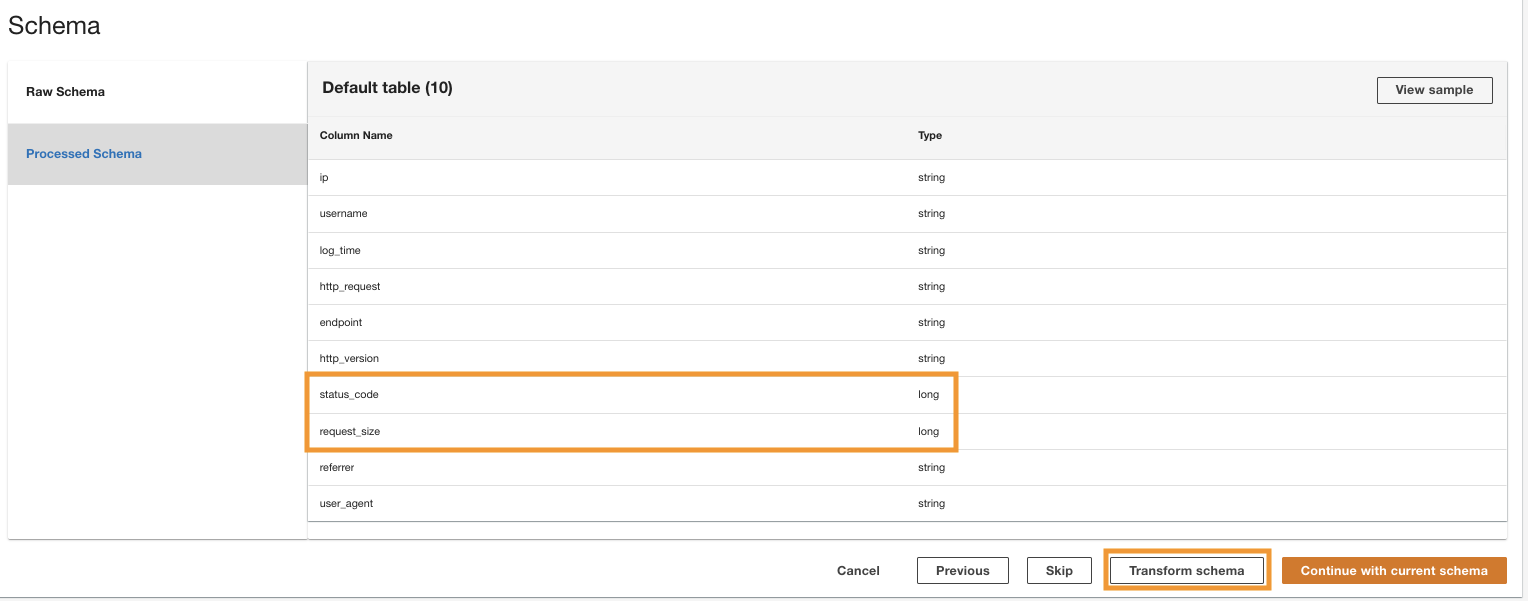
Legg merke til de uthevede kolonnenavnene i Skjema forhåndsvisning ruten før du bruker datatypetransformasjonene.
- på Forvandle plan rute, under Innebygde transformasjoner, velg Bruk kartlegging.
Dette alternativet lar deg endre datatypen fra en type til en annen.
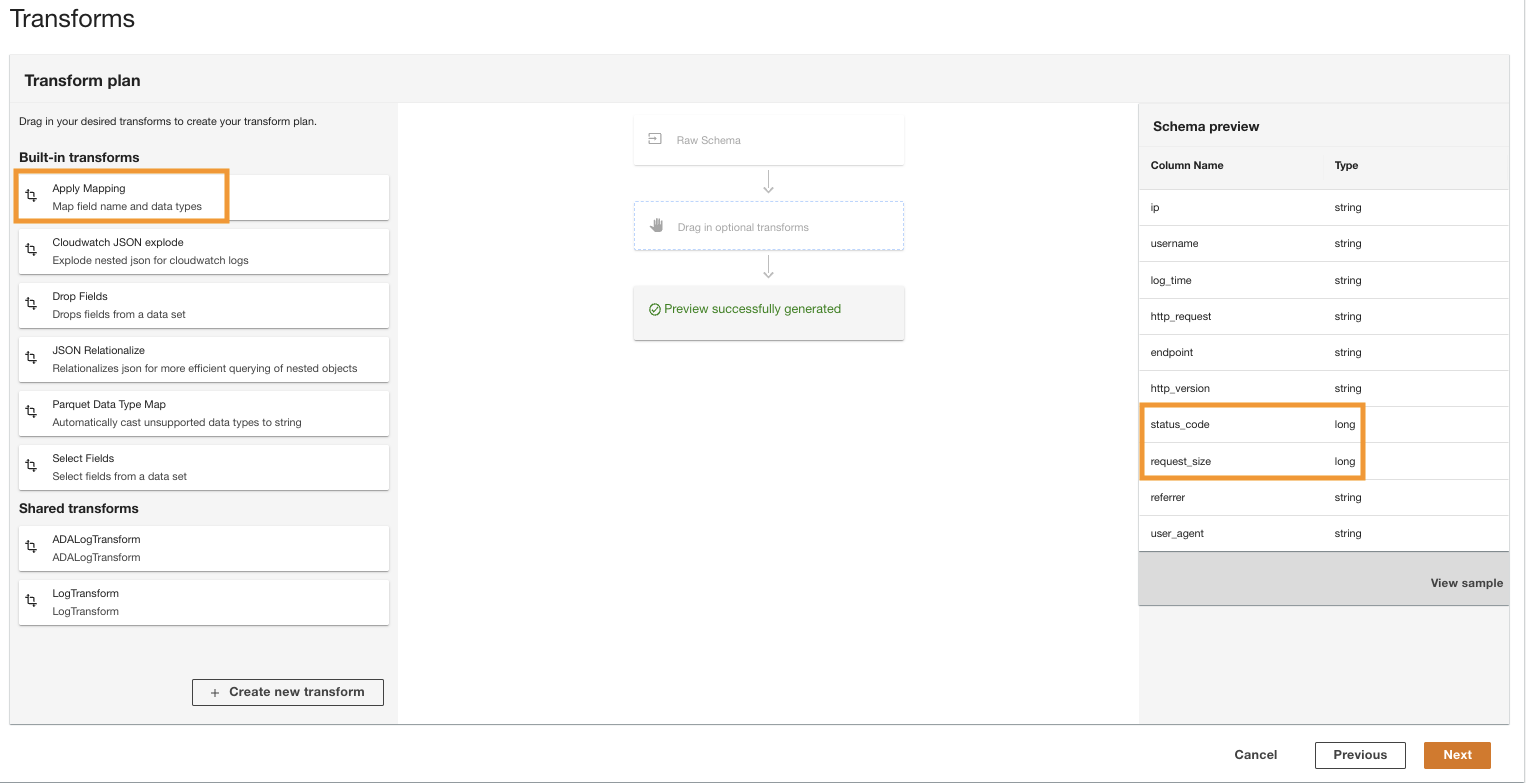
- på Bruk kartlegging seksjon, fjern markeringen Slipp andre felt.
Hvis dette alternativet ikke er deaktivert, vil bare de transformerte kolonnene bli bevart og alle andre kolonner vil bli slettet. Fordi vi ønsker å beholde alle kolonnene, deaktiverer vi dette alternativet.
- Under Feltkartlegginger¸ for Gamle navn og Nytt navn, Tast inn
status_codeog for Ny type, Tast innstring.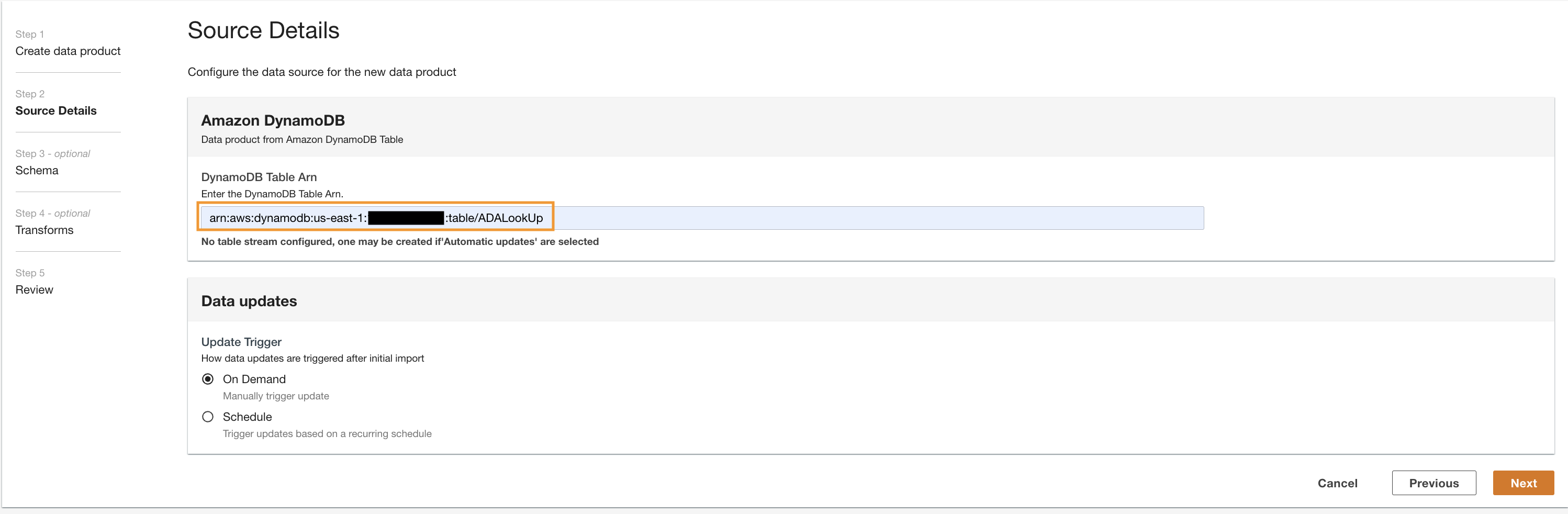
- Velg Legg til element.
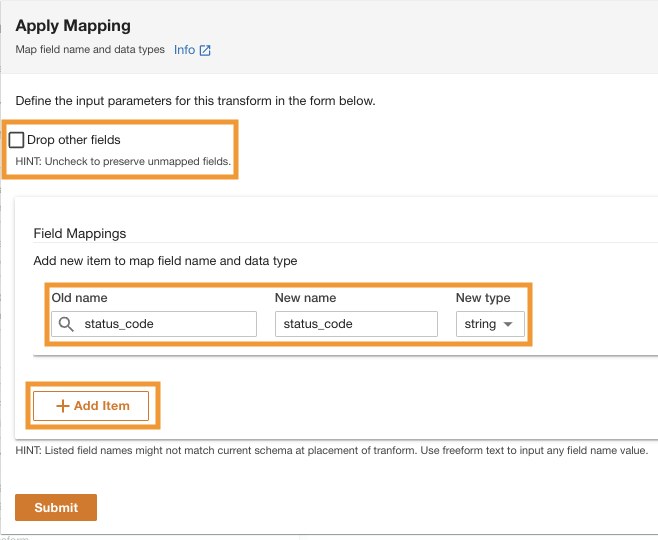
- Til Gamle navn og Nytt navn¸ skriv inn request_size og for Ny datatype, skriv inn streng.
- Velg Send.
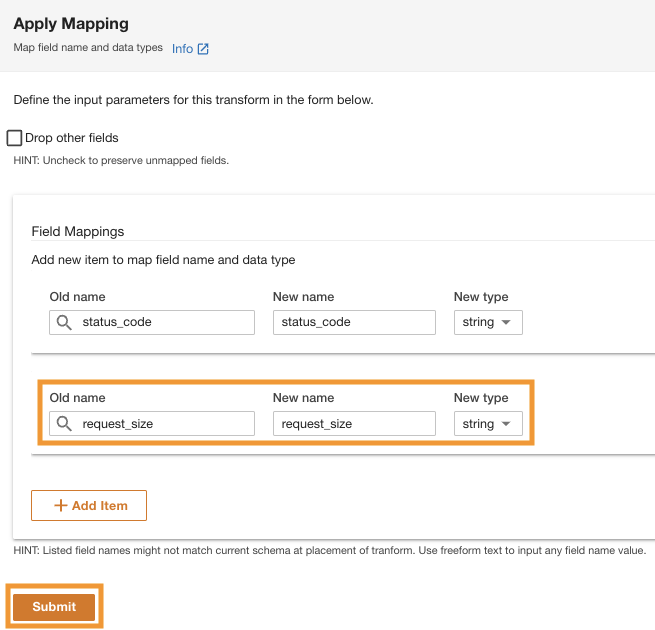
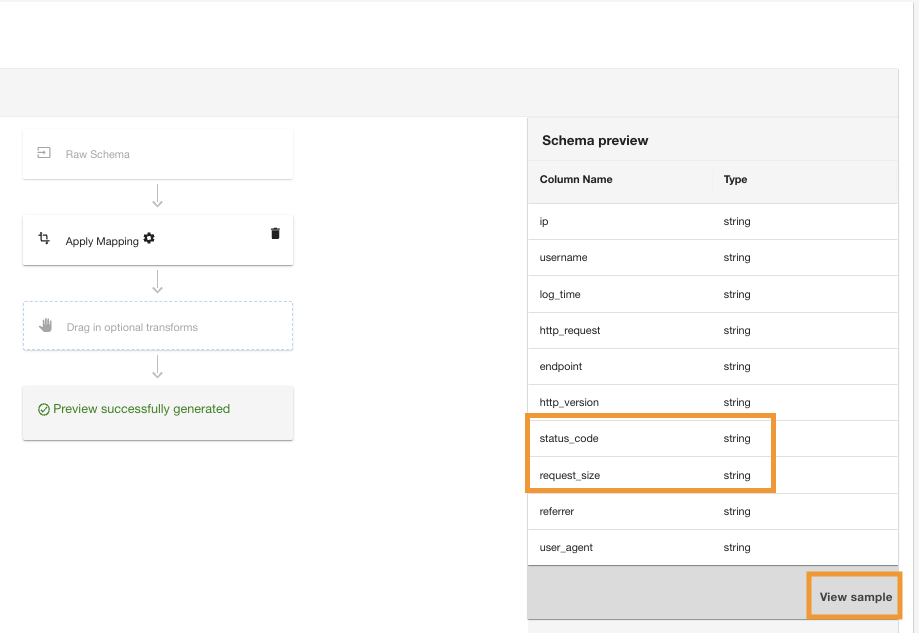
ADA vil bruke karttransformasjonen på Amazon S3-datakilden. Legg merke til kolonnetypene i Skjema forhåndsvisning ruten.
- Velg Se eksempel for å forhåndsvise dataene med transformasjonen brukt.
ADA vil vise PII-databekreftelsen for å sikre at enten bare autoriserte brukere kan se dataene eller at datasettet ikke inneholder PII-data.
- Velg Enig for å fortsette å se eksempeldataene.
Merk at skjemaet er identisk med CloudWatch-logggruppeskjemaet fordi både gjeldende applikasjons- og historiske applikasjonslogger er i Apache-loggformat.
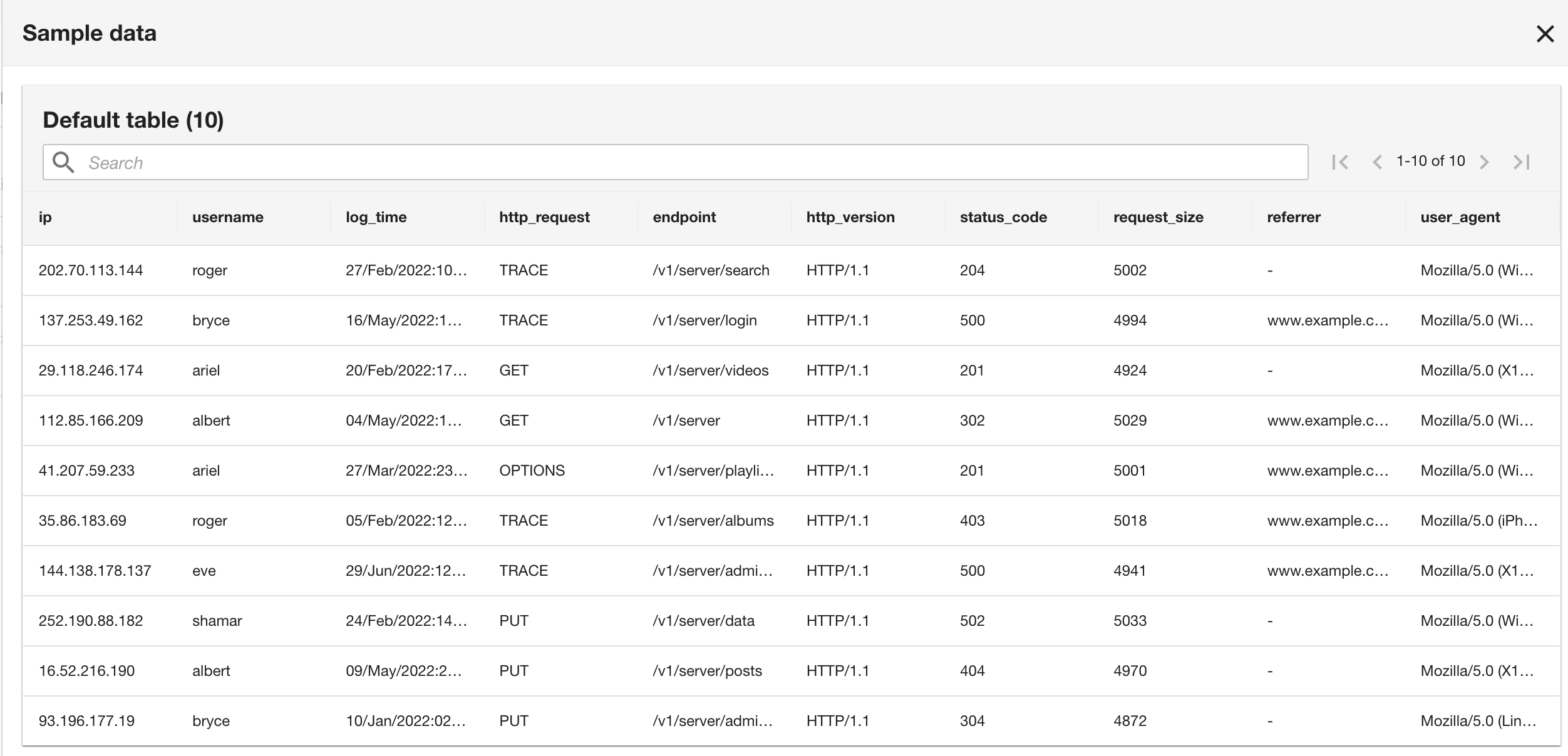
- I det siste trinnet, se gjennom konfigurasjonen og velg Send.
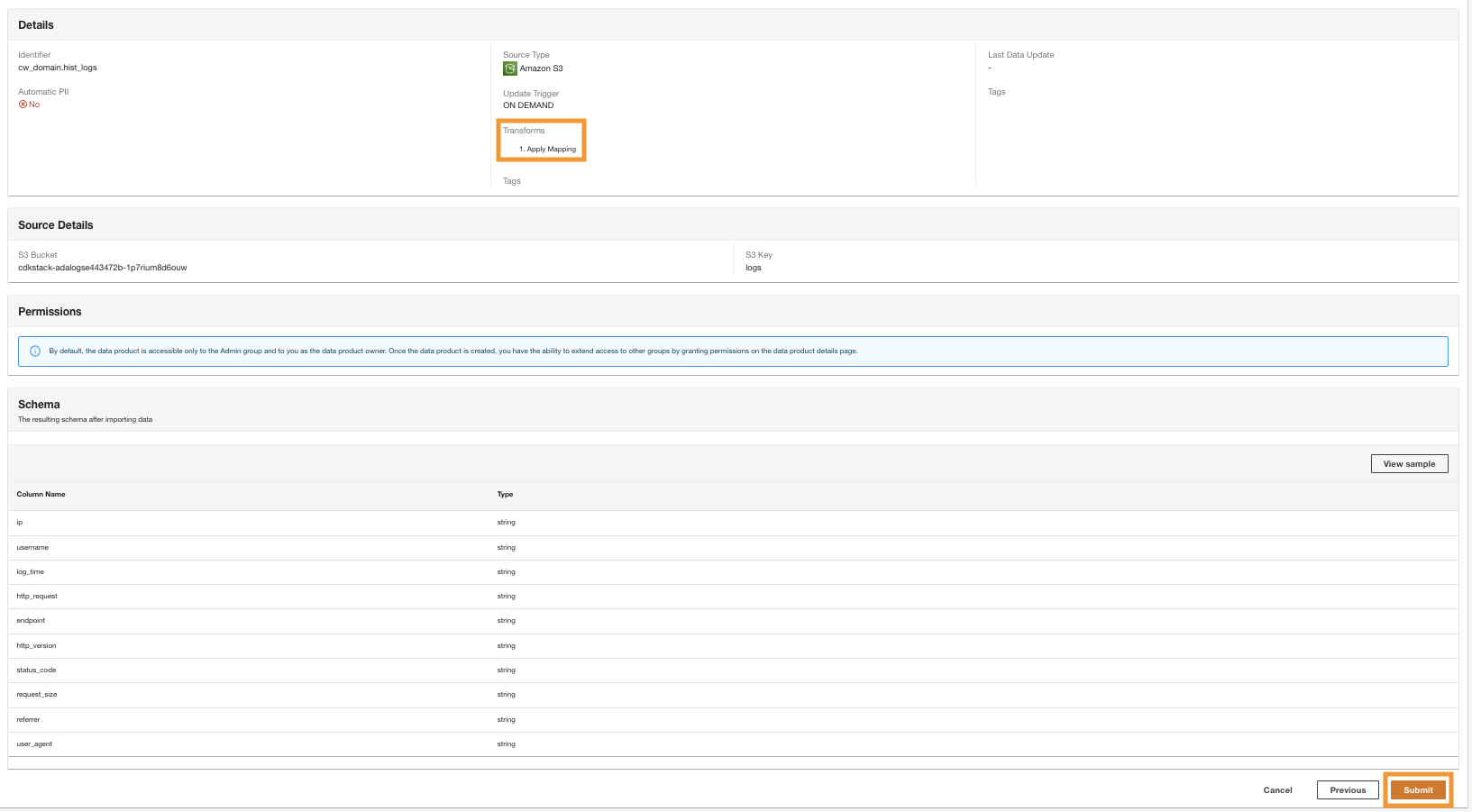
ADA begynner å behandle dataene fra Amazon S3-kilden, oppretter backend-infrastrukturen og forbereder dataproduktet. Denne prosessen tar noen minutter avhengig av størrelsen på dataene.
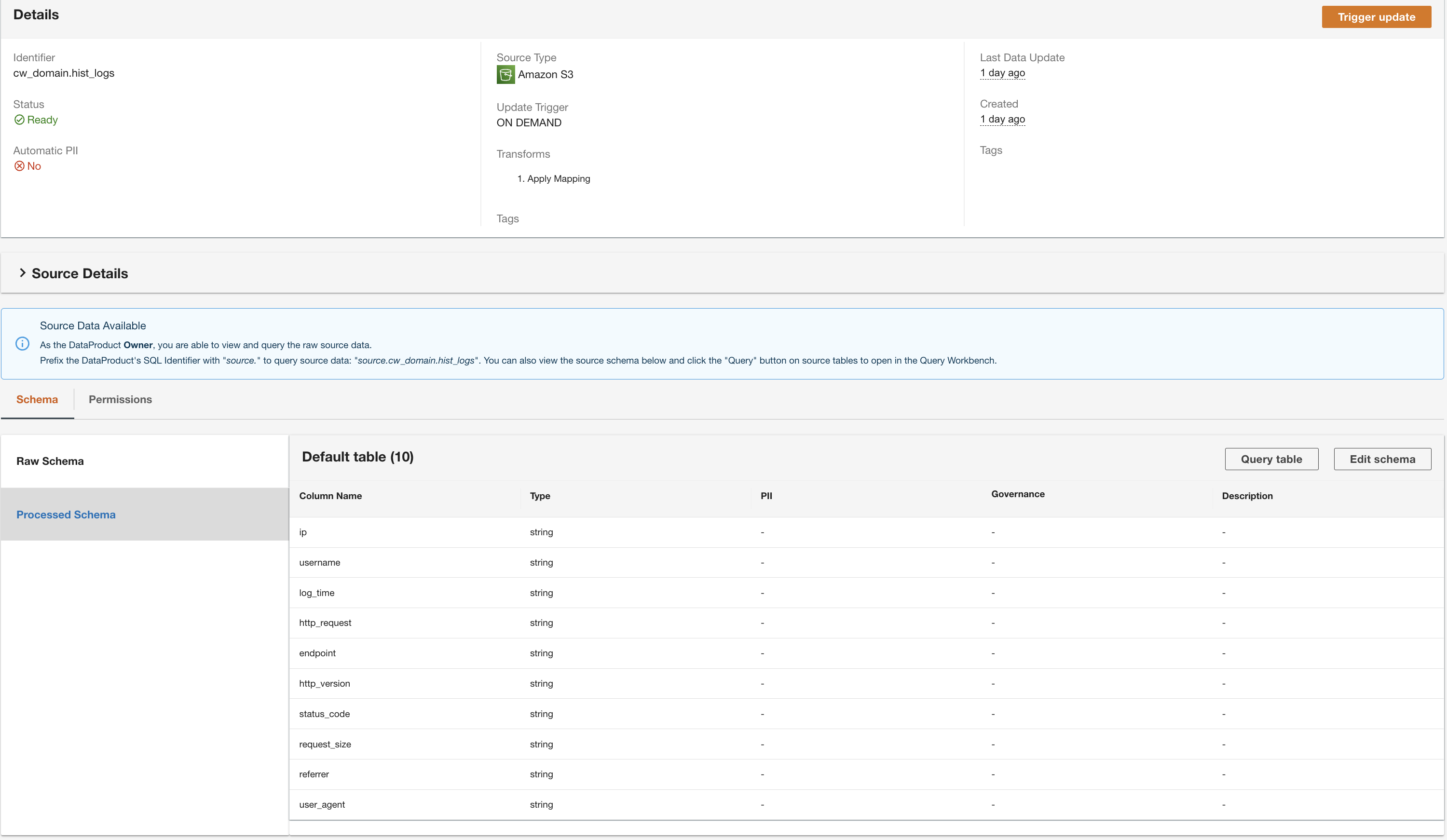
Opprett et DynamoDB-dataprodukt
Til slutt lager vi et DynamoDB-dataprodukt. Fullfør følgende trinn:
- På ADA-konsollen oppretter du et nytt dataprodukt.
- Skriv inn et navn (
lookup) og velg Amazon DynamoDB.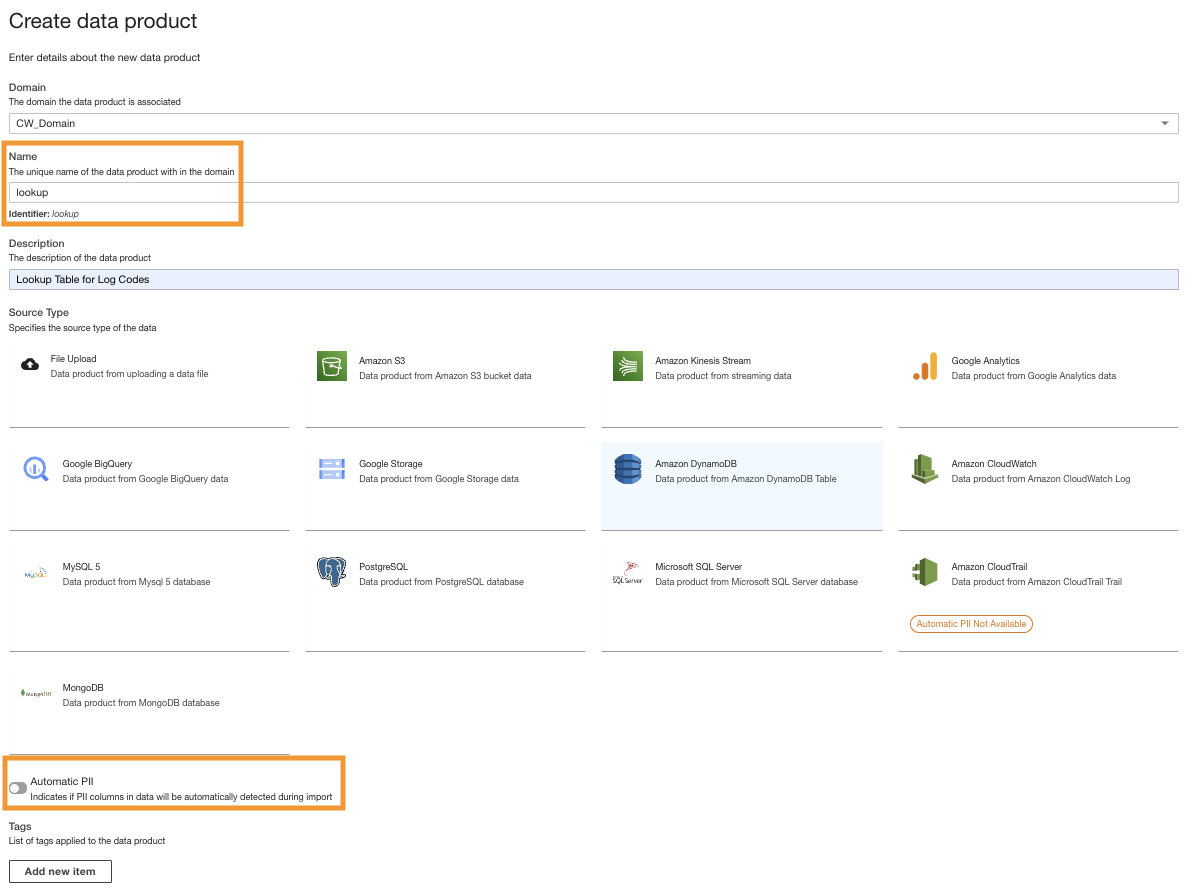
- Angi
Cdk.DynamoDBTableutgangsvariabel for DynamoDB Tabell ARN.
Denne tabellen inneholder nøkkelattributter som vil bli brukt som en oppslagstabell i denne demoen. For oppslagsdataene bruker vi HTTP-kodene og lange og korte beskrivelser av kodene. Du kan også bruke PostgreSQL, MySQL eller en CSV-filkilde som et alternativ.
- Til Oppdater trigger, plukke ut På etterspørsel.
Oppdateringene vil være på forespørsel fordi oppslaget hovedsakelig er for referanseformål under spørring, og eventuelle oppdateringer til oppslagsdataene kan oppdateres i ADA ved å bruke on-demand-utløsere.
- Velg neste.
ADA leser skjemaet fra det underliggende DynamoDB-skjemaet og presenterer kolonnenavnet og typen for valgfri transformasjon. Vi vil fortsette med standardskjemavalget fordi kolonnetypene er konsistente med typene fra CloudWatch-logggruppen og Amazon S3 CSV-datakilden. Ved å ha datatyper som er konsistente på tvers av datakildene, kan vi skrive spørringer for å hente poster ved å slå sammen tabellene ved å bruke kolonnefeltene. For eksempel kolonnen key i DynamoDB-skjemaet tilsvarer status_code i Amazon S3- og CloudWatch-dataproduktene. Vi kan skrive spørringer som kan slå sammen de tre tabellene ved å bruke kolonnenavnet key. Et eksempel er vist i neste avsnitt.
- Velg Fortsett med gjeldende skjema.
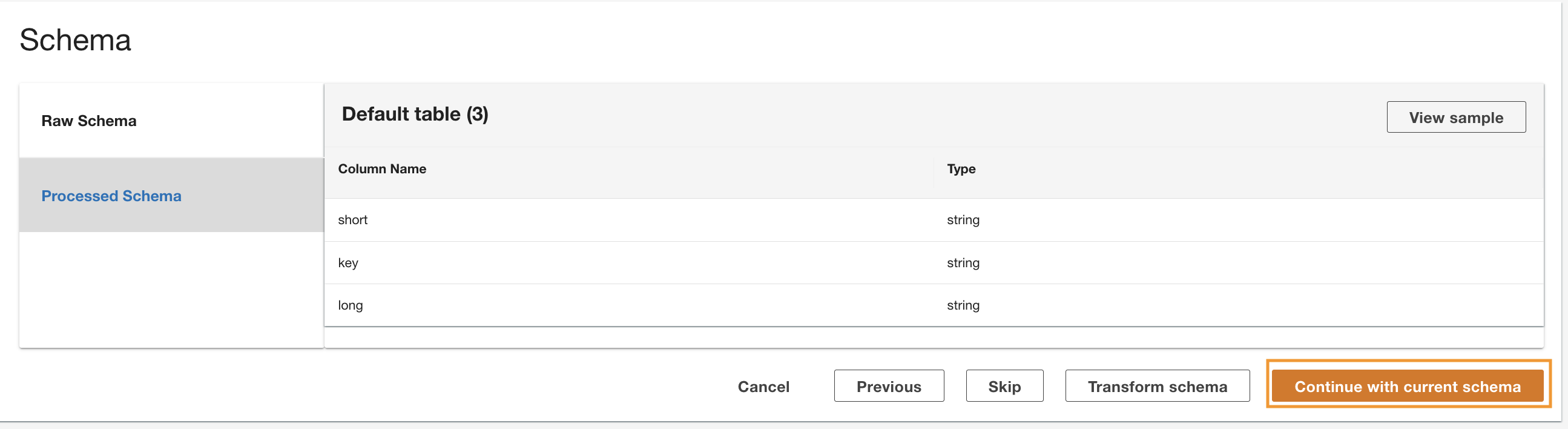
- Se gjennom konfigurasjonen og velg Send.
ADA vil behandle dataene fra DynamoDB-tabelldatakilden og forberede dataproduktet. Avhengig av størrelsen på dataene, tar denne prosessen noen minutter.
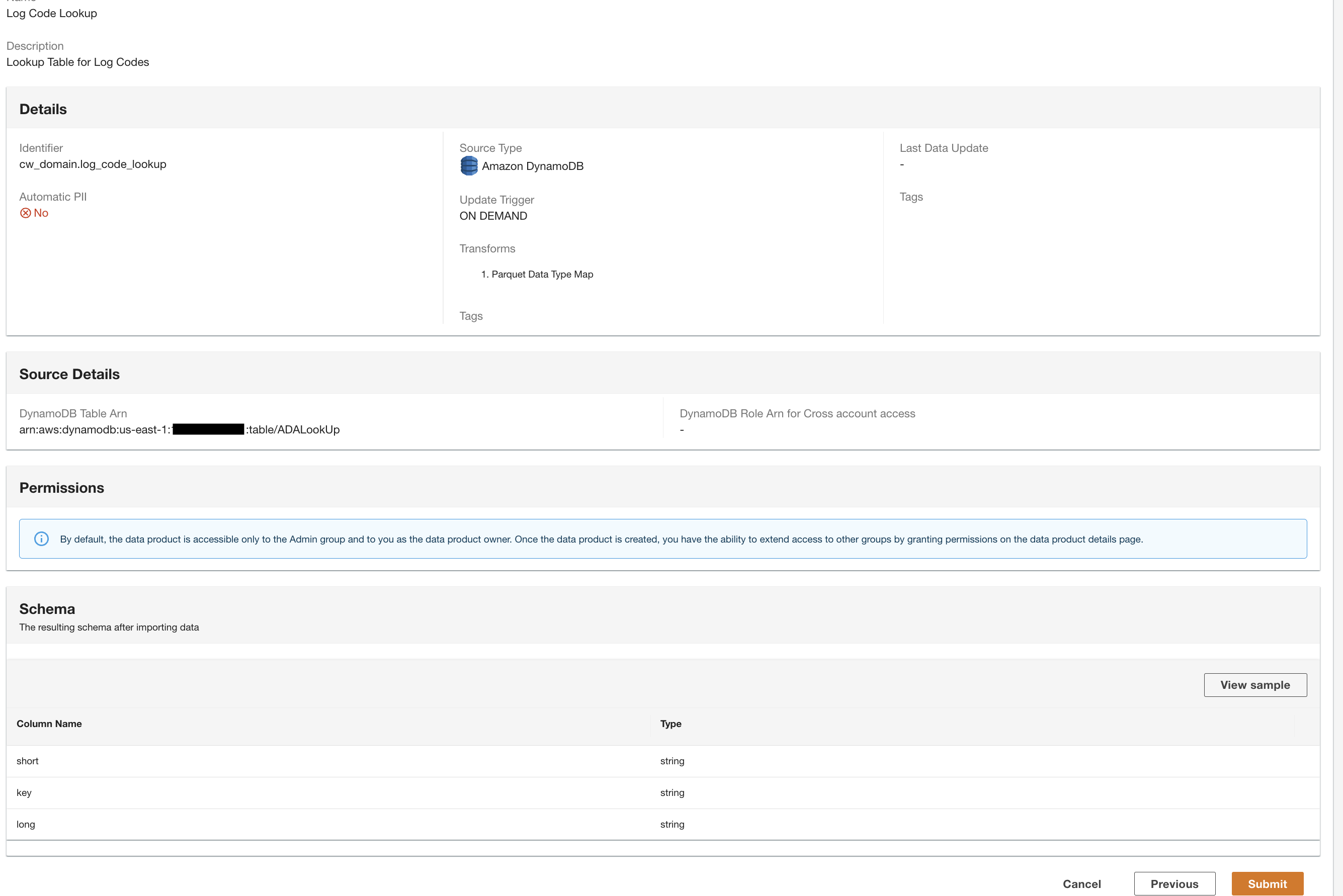
Nå har vi alle de tre dataproduktene som er behandlet av ADA og tilgjengelig for deg å kjøre spørringer.

Bruk Query Workbench til å spørre etter dataene
ADA lar deg kjøre spørringer mot dataproduktene mens du abstraherer datakilden og gjør den tilgjengelig ved hjelp av SQL (Structured Query Language). Du kan skrive spørringer og slå sammen tabellene på samme måte som du ville spørre mot tabeller i en relasjonsdatabase. Vi demonstrerer ADAs spørringsevne via to brukerscenarier. I begge scenariene kobler vi et programloggdatasett til feilkodeoppslagstabellen. I det første brukstilfellet spør vi de gjeldende applikasjonsloggene for å identifisere de 10 mest tilgjengelige applikasjonsendepunktene sammen med de tilsvarende HTTP-statuskodene:
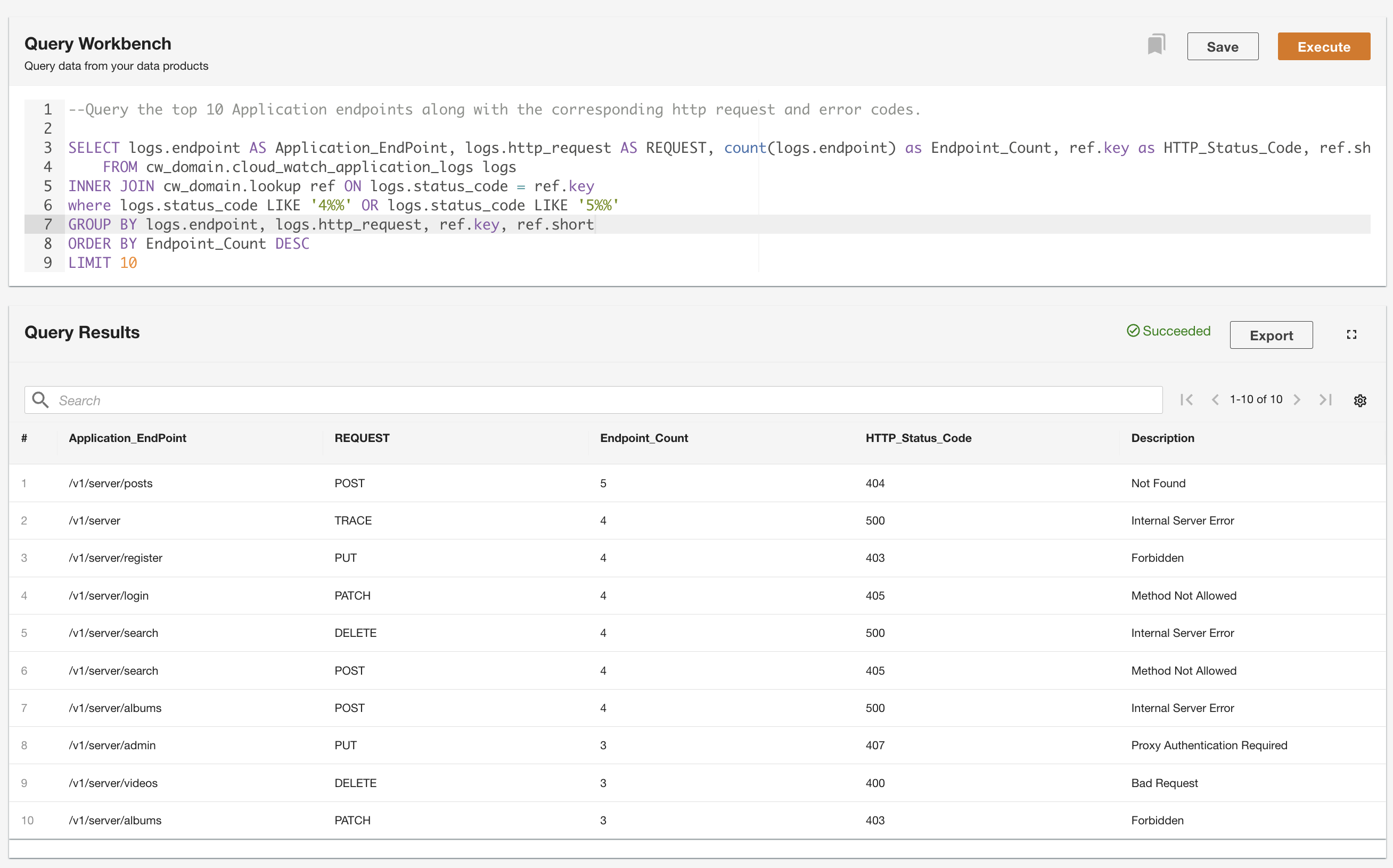
I det andre eksemplet spør vi tabellen over historiske logg for å få de 10 beste applikasjonsendepunktene med flest feil for å forstå endepunktanropsmønsteret:
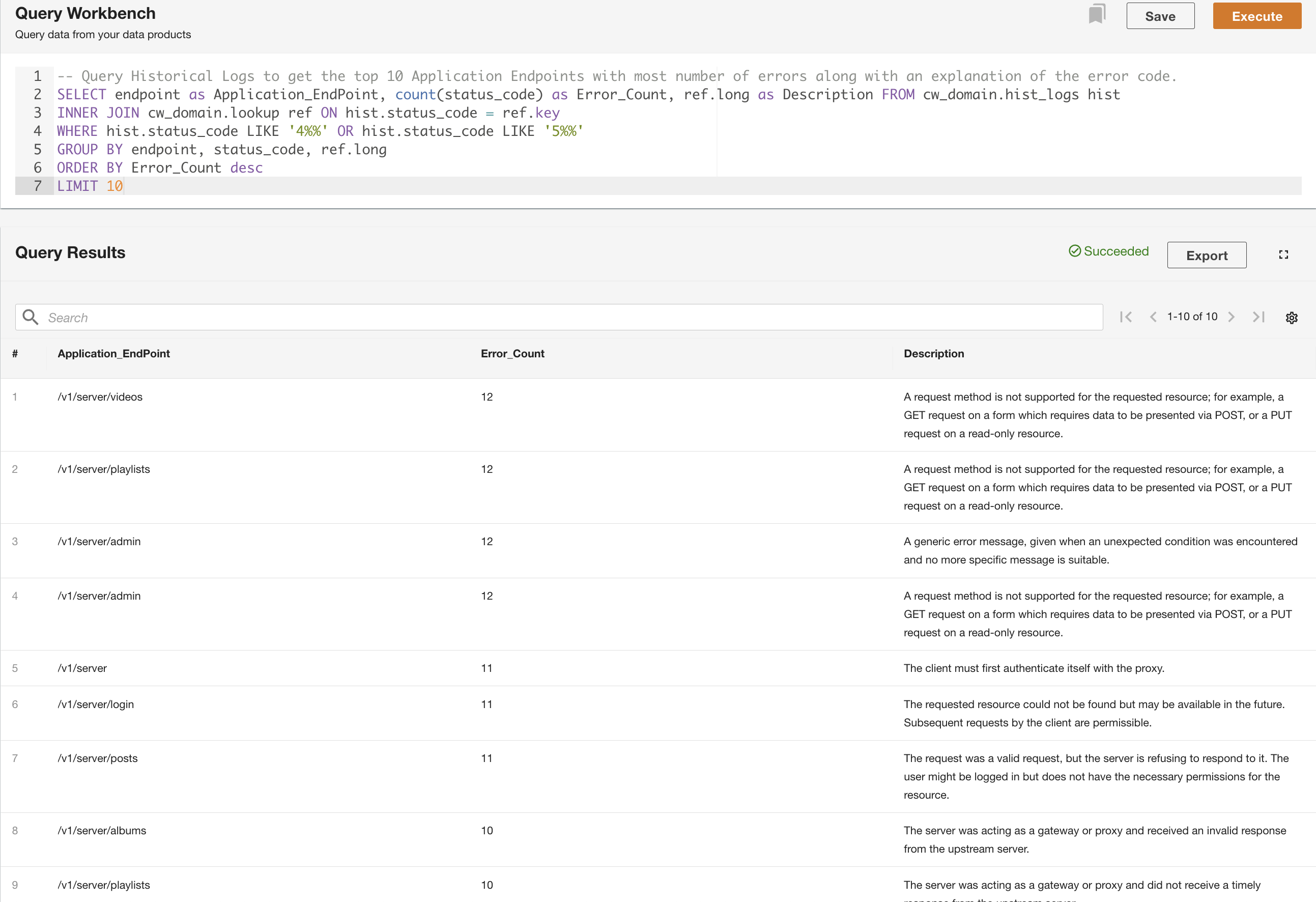
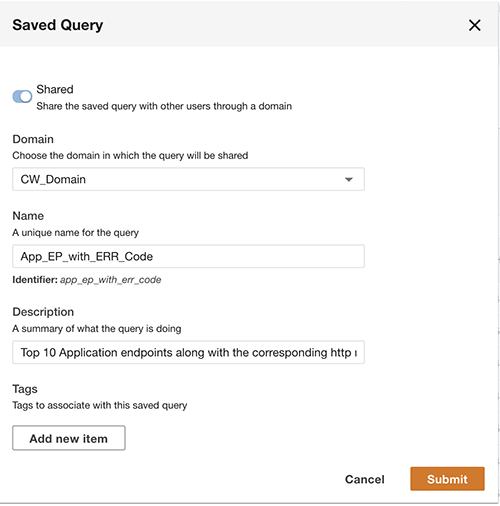
I tillegg til å spørre, kan du eventuelt lagre spørringen og dele den lagrede spørringen med andre brukere på samme domene. De delte spørringene er tilgjengelige direkte fra Query Workbench. Spørringsresultatene kan også eksporteres til CSV-format.
Visualiser ADA-dataprodukter i Tableau
ADA tilbyr muligheten til koble til tredjeparts BI-verktøy for å visualisere data og lage rapporter fra ADA-dataproduktene. I denne demoen bruker vi ADAs native integrasjon med Tableau for å visualisere dataene fra de tre dataproduktene vi konfigurerte tidligere. Bruke Tableaus Athena-kontakt og følge trinnene i Tableau-konfigurasjon, kan du konfigurere ADA som en datakilde i Tableau. Etter at en vellykket forbindelse er etablert mellom Tableau og ADA, vil Tableau fylle ut de tre dataproduktene under Tableau-katalogen cw_domain.
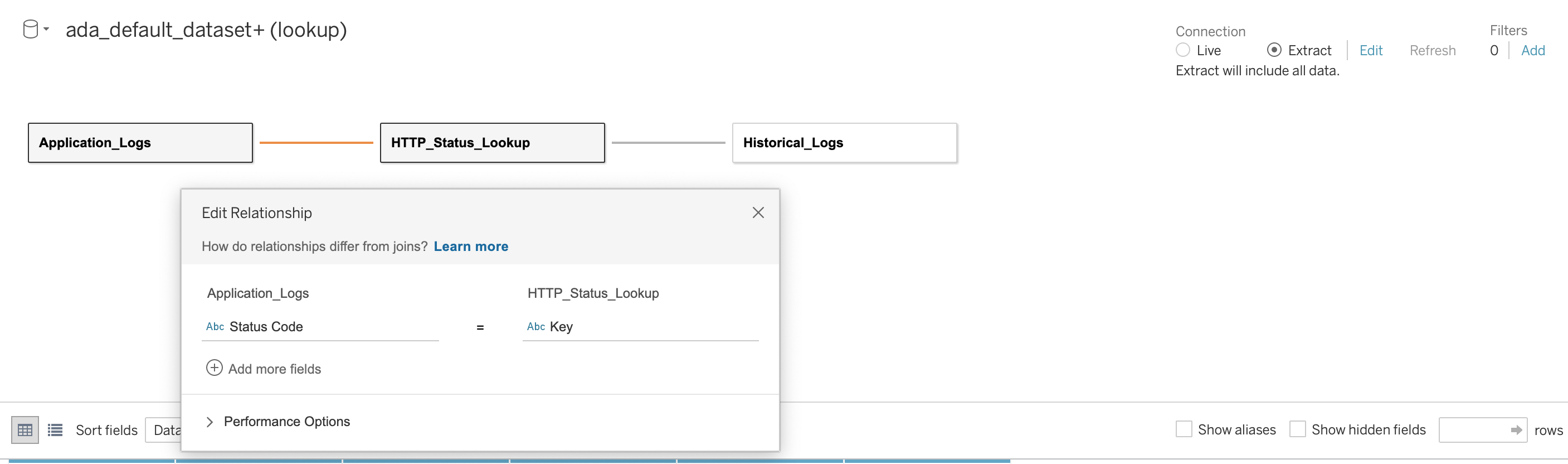
Vi etablerer deretter et forhold på tvers av de tre databasene ved å bruke HTTP-statuskoden som sammenføyningskolonnen, som vist i følgende skjermbilde. Tableau lar oss jobbe i online og offline modus med datakildene. I online-modus vil Tableau koble seg til ADA og forespørre dataproduktene live. I frakoblet modus kan vi bruke Pakk mulighet for å trekke ut dataene fra ADA og importere dataene til Tableau. I denne demoen importerer vi dataene til Tableau for å gjøre spørringen mer responsiv. Vi lagrer deretter Tableau-arbeidsboken. Vi kan inspisere dataene fra datakildene ved å velge databasen og Oppdater nå.
Med datakildekonfigurasjonene på plass i Tableau, kan vi lage tilpassede rapporter, diagrammer og visualiseringer på ADA-dataproduktene. La oss vurdere to brukstilfeller for visualiseringer.
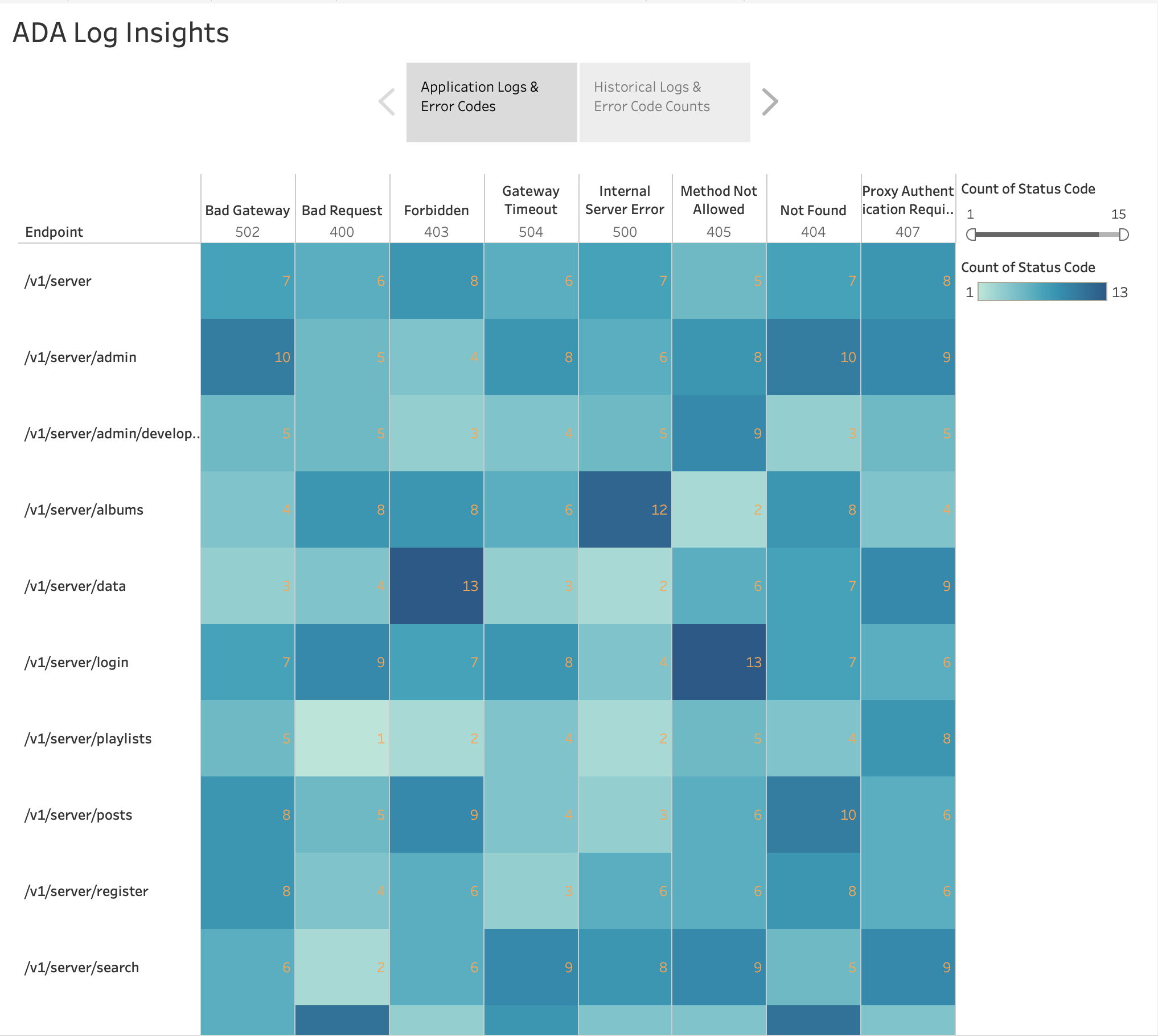
Som vist i den følgende figuren, visualiserte vi frekvensen av HTTP-feilene etter applikasjonsendepunkter ved å bruke Tableaus innebygde varmekart diagram. Vi filtrerte ut HTTP-statuskodene til kun å inkludere feilkoder i 4xx- og 5xx-området.
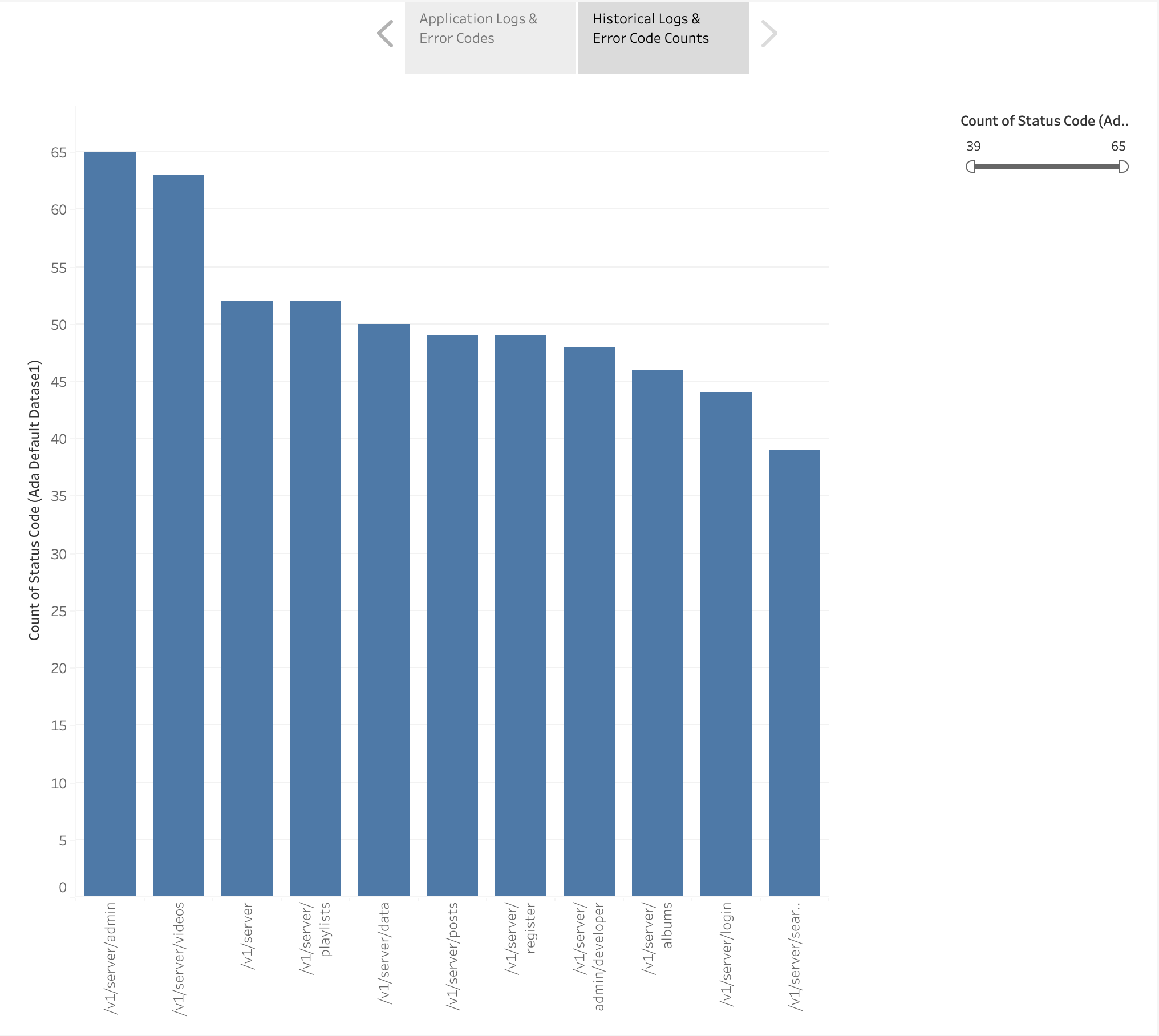
Vi har også laget et stolpediagram for å vise applikasjonens endepunkter fra de historiske loggene sortert etter antall HTTP-feilkoder. I dette diagrammet kan vi se at /v1/server/admin endepunkt har generert flest HTTP-feilstatuskoder.
Rydd opp
Å rydde opp i prøveapplikasjonsinfrastrukturen er en to-trinns prosess. Først, for å fjerne infrastrukturen klargjort for formålet med denne demoen, kjør følgende kommando i terminalen:
For følgende spørsmål, skriv inn y og AWS CDK vil slette ressursene som er distribuert for demoen:
Alternativt kan du fjerne ressursene via AWS CloudFormation-konsollen ved å navigere til CdkStack-stakken og velge Delete.
Det andre trinnet er å avinstallere ADA. For instruksjoner, se Avinstaller løsningen.
konklusjonen
I dette innlegget demonstrerte vi hvordan du bruker ADA-løsningen til å hente innsikt fra applikasjonslogger lagret på tvers av to forskjellige datakilder. Vi demonstrerte hvordan du installerer ADA på en AWS-konto og distribuerer demokomponentene ved hjelp av AWS CDK. Vi opprettet dataprodukter i ADA og konfigurerte dataproduktene med de respektive datakildene ved å bruke ADAs innebygde datakoblinger. Vi demonstrerte hvordan du kan spørre dataproduktene ved å bruke standard SQL-spørringer og generere innsikt i loggdataene. Vi koblet også Tableau Desktop-klienten, et tredjeparts BI-produkt, til ADA og demonstrerte hvordan man bygger visualiseringer mot dataproduktene.
ADA automatiserer prosessen med å innta, transformere, styre og spørre ulike datasett og forenkle livssyklusadministrasjonen av data. ADAs forhåndsbygde koblinger lar deg innta data fra forskjellige datakilder. Programvareteam med grunnleggende kunnskap om AWS-produkter og -tjenester vil kunne sette opp en operativ dataanalyseplattform i løpet av få timer og gi sikker tilgang til dataene. Dataene kan deretter enkelt og raskt søkes ved hjelp av et intuitivt og frittstående nettbrukergrensesnitt.
Prøv ADA i dag for enkelt å administrere og få innsikt fra data.
Om forfatterne
 Aparajithan Vaidyanathan er hovedarkitekt for bedriftsløsninger hos AWS. Han støtter bedriftskunder med å migrere og modernisere arbeidsmengdene deres på AWS-skyen. Han er en skyarkitekt med 23+ års erfaring med å designe og utvikle store, store og distribuerte programvaresystemer. Han spesialiserer seg på maskinlæring og dataanalyse med fokus på data- og funksjonsteknikk-domene. Han er en aspirerende maratonløper og hobbyene hans inkluderer fotturer, sykling og tilbringe tid med kona og to gutter.
Aparajithan Vaidyanathan er hovedarkitekt for bedriftsløsninger hos AWS. Han støtter bedriftskunder med å migrere og modernisere arbeidsmengdene deres på AWS-skyen. Han er en skyarkitekt med 23+ års erfaring med å designe og utvikle store, store og distribuerte programvaresystemer. Han spesialiserer seg på maskinlæring og dataanalyse med fokus på data- og funksjonsteknikk-domene. Han er en aspirerende maratonløper og hobbyene hans inkluderer fotturer, sykling og tilbringe tid med kona og to gutter.
 Rashim Rahman er en programvareutvikler basert i Sydney, Australia med 10+ års erfaring innen programvareutvikling og arkitektur. Han jobber primært med å bygge storskala åpen kildekode AWS-løsninger for vanlige kundetilfeller og forretningsproblemer. På fritiden liker han sport og tilbringe tid med venner og familie.
Rashim Rahman er en programvareutvikler basert i Sydney, Australia med 10+ års erfaring innen programvareutvikling og arkitektur. Han jobber primært med å bygge storskala åpen kildekode AWS-løsninger for vanlige kundetilfeller og forretningsproblemer. På fritiden liker han sport og tilbringe tid med venner og familie.
 Hafiz Saadullah er en hovedteknisk produktsjef hos Amazon Web Services. Hafiz fokuserer på AWS-løsninger, designet for å hjelpe kunder ved å adressere vanlige forretningsproblemer og brukstilfeller.
Hafiz Saadullah er en hovedteknisk produktsjef hos Amazon Web Services. Hafiz fokuserer på AWS-løsninger, designet for å hjelpe kunder ved å adressere vanlige forretningsproblemer og brukstilfeller.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- ChartPrime. Hev handelsspillet ditt med ChartPrime. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- evne
- I stand
- Om oss
- adgang
- aksesseres
- tilgjengelig
- Logg inn
- tvers
- handlinger
- ADA
- legge til
- tillegg
- Ytterligere
- adressering
- admin
- Etter
- mot
- Alle
- tillate
- tillater
- langs
- også
- alternativ
- Amazon
- Amazon Web Services
- blant
- an
- analyse
- analytikere
- analytics
- analysere
- og
- En annen
- noen
- Apache
- api
- APIer
- Søknad
- søknader
- anvendt
- Påfør
- påføring
- arkitektur
- ER
- AS
- håper
- At
- attributter
- Australia
- Autentisering
- autorisert
- Automatisert
- automatiserer
- automatisk
- tilgjengelig
- AWS
- AWS skyformasjon
- tilbake
- Backend
- Bar
- basert
- grunnleggende
- BE
- fordi
- vært
- før du
- skreddersydd
- mellom
- både
- Eske
- bygge
- Bygning
- innebygd
- virksomhet
- business intelligence
- men
- by
- ring
- CAN
- evne
- saken
- saker
- katalog
- CD
- endring
- Figur
- Topplisten
- Velg
- velge
- kunde
- Cloud
- kode
- koder
- samling
- Kolonne
- kolonner
- Felles
- fullføre
- komponenter
- Konfigurasjon
- konfigurert
- Koble
- tilkoblet
- tilkobling
- forbinder
- Vurder
- konsistent
- Konsoll
- inneholder
- fortsette
- korrelert
- Korrelasjon
- Tilsvarende
- tilsvarer
- Kostnad
- skape
- opprettet
- skaper
- Opprette
- Credentials
- Gjeldende
- skikk
- kunde
- Kunder
- dashbord
- dato
- Data Analytics
- databehandling
- Database
- databaser
- datasett
- Misligholde
- Etterspørsel
- Demo
- demonstrere
- demonstrert
- avhengig
- utplassere
- utplassert
- distribusjon
- Distribueres
- beskrivelse
- designet
- utforme
- desktop
- detaljert
- detaljer
- Utvikler
- utvikle
- Utvikling
- diagnose
- forskjellig
- direkte
- deaktivert
- Funnet
- Vise
- distribueres
- diverse
- ikke
- domene
- domener
- ikke
- droppet
- under
- hver enkelt
- Tidligere
- lett
- redigering
- enten
- emalje
- aktivert
- muliggjør
- Endpoint
- endepunkter
- Ingeniørarbeid
- sikre
- Enter
- Enterprise
- bedriftskunder
- Enterprise Solutions
- feil
- feil
- etablere
- etablert
- Eter (ETH)
- eksempel
- eksisterende
- erfaring
- Forklar
- forklaring
- trekke ut
- trekke ut dataene
- kjent
- familie
- Trekk
- Noen få
- felt
- Felt
- Figur
- filet
- Filer
- slutt~~POS=TRUNC
- finansiere
- Først
- fleksibel
- Fokus
- fokuserer
- etter
- Til
- format
- fire
- Frekvens
- venner
- fra
- funksjon
- Gevinst
- generere
- generert
- få
- få
- styrende
- Gruppe
- Gruppens
- Ha
- å ha
- he
- hjelpe
- Fremhevet
- vandreturer
- hans
- historisk
- Hobbyer
- vert
- TIMER
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- identiske
- identifisere
- Identitet
- if
- importere
- in
- inkludere
- inkluderer
- Inkludert
- informasjon
- Infrastruktur
- innledende
- innsikt
- installere
- installasjon
- instruksjoner
- integrert
- integrering
- Intelligens
- interaktiv
- interessert
- Interface
- inn
- intuitiv
- påkaller
- involvert
- utstedelse
- IT
- bli medlem
- sammenføyning
- tiltrer
- jpg
- JSON
- bare
- Hold
- nøkkel
- kunnskap
- Språk
- stor
- storskala
- Siste
- seinere
- lansere
- læring
- Bibliotek
- Licensed
- Livssyklus
- i likhet med
- BEGRENSE
- linje
- Liste
- leve
- logg
- logging
- Lang
- Se
- oppslag
- maskin
- maskinlæring
- gjøre
- Making
- administrer
- ledelse
- leder
- mange
- kart
- kartlegging
- Marathon
- Marketing
- Saken
- meningsfylt
- melding
- MFA
- kunne
- migrere
- minutter
- Mote
- modern
- mer
- mest
- for det meste
- Mozilla
- multifaktorautentisering
- MySQL
- navn
- oppkalt
- navn
- innfødt
- Naviger
- navigere
- Navigasjon
- Trenger
- nødvendig
- behov
- Ny
- nylig
- neste
- Antall
- of
- Tilbud
- offline
- Gammel
- on
- På etterspørsel
- ONE
- på nett
- bare
- åpen
- åpen kildekode
- operasjonell
- Alternativ
- or
- rekkefølge
- Annen
- andre
- ut
- produksjon
- oversikt
- side
- brød
- Passord
- banen
- Mønster
- utføre
- tillatelser
- personlig
- telefon
- PII
- rørledning
- Sted
- Plain
- fly
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Politikk
- Portal
- Post
- postgresql
- powered
- Forbered
- forbereder
- forutsetninger
- presentere
- gaver
- Forhåndsvisning
- forrige
- primært
- Principal
- Før
- problemer
- fortsette
- prosess
- behandlet
- Prosesser
- prosessering
- produsert
- Produkt
- Produktsjef
- Produkter
- Produkter og tjenester
- programmer
- prosjekt
- gi
- forutsatt
- leverandør
- gir
- formål
- formål
- Python
- spørsmål
- spørsmål
- raskt
- område
- Lese
- klar
- motta
- poster
- referert
- region
- forholdet
- relevant
- fjerne
- gjenta
- Rapporter
- anmode
- påkrevd
- Ressurser
- de
- responsive
- Resultater
- beholde
- anmeldelse
- riding
- roller
- root
- Regel
- Kjør
- runner
- rennende
- salg
- samme
- Spar
- Skala
- scenarier
- planlagt
- omfang
- Søk
- Sekund
- Seksjon
- sikre
- sikkerhet
- se
- valgt
- utvalg
- send
- sendt
- separat
- betjene
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- innstilling
- Del
- delt
- Kort
- vist
- Viser
- Enkelt
- forenklet
- forenkle
- Størrelse
- ferdigheter
- So
- Software
- programvareutvikling
- løsning
- Solutions
- kilde
- Kilder
- spesialist
- spesialisert
- spesifikk
- spesifisert
- utgifter
- Sports
- SQL
- stable
- stående
- Standard
- Begynn
- starter
- status
- Trinn
- Steps
- lagring
- lagret
- String
- strukturert
- vellykket
- vellykket
- slik
- Støtter
- sikker
- sydney
- Systemer
- bord
- Tableau
- Ta
- tar
- lag
- lag
- Teknisk
- tekniske ferdigheter
- terminal
- Det
- De
- Kilden
- deres
- deretter
- Der.
- Disse
- tredjeparts
- denne
- tre
- Gjennom
- tid
- til
- i dag
- verktøy
- topp
- Top 10
- Totalt
- Transform
- Transformation
- transformasjoner
- forvandlet
- transformere
- transforme
- utløst
- to
- typen
- typer
- etter
- underliggende
- forstå
- oppdatert
- oppdateringer
- upon
- URI
- us
- bruke
- bruk sak
- brukt
- Bruker
- Brukergrensesnitt
- Brukere
- ved hjelp av
- Verdier
- variabel
- variasjon
- versjon
- av
- Se
- ønsker
- Vei..
- we
- web
- webtjenester
- VI VIL
- når
- hvilken
- mens
- bred
- Bred rekkevidde
- kone
- vil
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- virker
- ville
- skrive
- år
- du
- Din
- zephyrnet