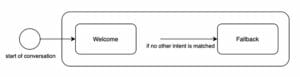
Figur 1: Representasjon av Text2SQL-flyten
Ettersom verdenen vår blir mer global og dynamisk, er bedrifter mer og mer avhengige av data for å ta informerte, objektive og rettidige beslutninger. Men per nå er det ofte et privilegium for en håndfull dataforskere og analytikere å slippe løs det fulle potensialet til organisasjonsdata. De fleste ansatte mestrer ikke det konvensjonelle datavitenskapelige verktøysettet (SQL, Python, R osv.). For å få tilgang til de ønskede dataene går de via et ekstra lag der analytikere eller BI-team «oversetter» prosaen til forretningsspørsmål til dataspråket. Potensialet for friksjon og ineffektivitet på denne reisen er stort - for eksempel kan dataene leveres med forsinkelser eller til og med når spørsmålet allerede er foreldet. Informasjon kan gå tapt underveis når kravene ikke er nøyaktig oversatt til analytiske spørringer. Dessuten krever det å generere innsikt av høy kvalitet en iterativ tilnærming som frarådes med hvert ekstra trinn i loopen. På den andre siden skaper disse ad-hoc-interaksjonene forstyrrelser for dyre datatalenter og distraherer dem fra mer strategisk dataarbeid, som beskrevet i disse "bekjennelsene" til en dataforsker:
Da jeg var på Square og teamet var mindre, hadde vi en fryktet "analytics-vakt"-rotasjon. Den ble strengt rotert på en ukentlig basis, og hvis det var din dukker opp visste du at du ville få veldig lite "ekte" arbeid gjort den uken og bruke mesteparten av tiden din på å stille ad hoc-spørsmål fra de forskjellige produkt- og driftsteamene på selskap (SQL monkeying, kalte vi det). Det var grusom konkurranse om lederroller i analyseteamet, og jeg tror dette var helt og holdent et resultat av at ledere ble unntatt fra denne rotasjonen – ingen statuspremie kunne konkurrere med gulroten av å ikke gjøre vaktarbeid.[1]
Faktisk, ville det ikke vært kult å snakke direkte med dataene dine i stedet for å måtte gå gjennom flere runder med interaksjon med datapersonalet ditt? Denne visjonen er omfavnet av samtalegrensesnitt som lar mennesker samhandle med data ved hjelp av språk, vår mest intuitive og universelle kommunikasjonskanal. Etter å ha analysert et spørsmål, koder en algoritme det til en strukturert logisk form i det valgte spørringsspråket, for eksempel SQL. Dermed kan ikke-tekniske brukere chatte med dataene sine og raskt få tak i spesifikk, relevant og tidsriktig informasjon, uten å ta omveien via et BI-team. I denne artikkelen vil vi vurdere de ulike implementeringsaspektene ved Text2SQL og fokusere på moderne tilnærminger med bruk av store språkmodeller (LLM), som oppnår best ytelse per nå (jf. [2]; for en undersøkelse over alternative tilnærminger utover LLM-er, henvises leserne til [3]). Artikkelen er strukturert i henhold til følgende "mentale modell" av hovedelementene du bør vurdere når du planlegger og bygger en AI-funksjon:

La oss starte med slutten i tankene og oppsummere verdien – hvorfor du vil bygge en Text2SQL-funksjon inn i data- eller analyseproduktet ditt. De tre hovedfordelene er:
- Forretningsbrukere kan få tilgang til organisasjonsdata på en direkte og rettidig måte.
- Dette lindrer datavitere og analytikere fra byrden av ad-hoc-forespørsler fra bedriftsbrukere og lar dem fokusere på avanserte datautfordringer.
- Dette gjør at virksomhet å utnytte dataene sine på en mer flytende og strategisk måte, og til slutt gjøre dem til et solid grunnlag for beslutningstaking.
Nå, hva er produktscenarioene der du kan vurdere Text2SQL? De tre hovedinnstillingene er:
- Du tilbyr en skalerbar data/BI-produkt og ønsker å gjøre det mulig for flere brukere å få tilgang til dataene deres på en ikke-teknisk måte, og dermed øke både bruken og brukerbasen. Som et eksempel har ServiceNow integrerte dataspørringer i et større samtaletilbudog Atlan har nylig annonsert datautforskning på naturlig språk.
- Du ønsker å bygge noe i data/AI-området for å demokratisere datatilgang i selskaper, i så fall kan du potensielt vurdere en MVP med Text2SQL i kjernen. Tilbydere liker AI2SQL og Text2sql.ai gjør allerede en inngang i dette rommet.
- Du jobber med en tilpasset BI-system og ønsker å maksimere og demokratisere bruken i den enkelte bedrift.
Som vi vil se i de følgende delene, krever Text2SQL et ikke-trivielt oppsett på forhånd. For å estimere avkastningen, vurder arten av beslutningene som skal støttes, så vel som på tilgjengelige data. Text2SQL kan være en absolutt seier i dynamiske miljøer hvor data endres raskt og brukes aktivt og hyppig i beslutningsprosesser, som for eksempel investeringer, markedsføring, produksjon og energiindustrien. I disse miljøene er tradisjonelle verktøy for kunnskapshåndtering for statiske, og mer flytende måter å få tilgang til data og informasjon på hjelper bedrifter med å generere et konkurransefortrinn. Når det gjelder dataene, gir Text2SQL den største verdien med en database som er:
- Stor og voksende, slik at Text2SQL kan utfolde sin verdi over tid ettersom mer og mer av dataene utnyttes.
- Høy kvalitet, slik at Text2SQL-algoritmen ikke trenger å håndtere overdreven støy (inkonsekvenser, tomme verdier etc.) i dataene. Generelt har data som genereres automatisk av applikasjoner høyere kvalitet og konsistens enn data som er opprettet og vedlikeholdt av mennesker.
- Semantisk moden i motsetning til rå, slik at mennesker kan spørre etter data basert på sentrale konsepter, relasjoner og beregninger som finnes i deres mentale modell. Merk at semantisk modenhet kan oppnås ved et ekstra transformasjonstrinn som tilpasser rådata til en konseptuell struktur (jf. avsnittet "Berike forespørselen med databaseinformasjon").
I det følgende vil vi dykke dypt ned i dataene, algoritmen, brukeropplevelsen, samt de relevante ikke-funksjonelle kravene til en Text2SQL-funksjon. Artikkelen er skrevet for produktledere, UX-designere og de dataviterne og ingeniørene som er i begynnelsen av deres Text2SQL-reise. For disse menneskene gir den ikke bare en veiledning for å komme i gang, men også et felles kunnskapsgrunnlag for diskusjoner rundt grensesnittet mellom produkt, teknologi og virksomhet, inkludert de relaterte avveiningene. Hvis du allerede er mer avansert i implementeringen, gir referansene på slutten en rekke dypdykk å utforske.
Hvis dette inngående pedagogiske innholdet er nyttig for deg, kan du abonner på vår adresseliste for AI-forskning å bli varslet når vi slipper nytt materiale.
1. Data
Enhver maskinlæring starter med data, så vi starter med å klargjøre strukturen til input- og måldataene som brukes under trening og prediksjon. Gjennom hele artikkelen vil vi bruke Text2SQL-flyten fra figur 1 som vår løpende representasjon, og fremheve de aktuelle komponentene og relasjonene i gult.

1.1 Format og struktur på dataene
Vanligvis består et rå Text2SQL input-out-par av et naturlig språkspørsmål og den tilsvarende SQL-spørringen, for eksempel:
Spørsmål: "List opp navn og antall følgere for hver bruker."
SQL-spørring:
velg navn, følgere fra brukerprofiler
I treningsdatarommet er tilordningen mellom spørsmål og SQL-spørringer mange-til-mange:
- En SQL-spørring kan tilordnes mange forskjellige spørsmål i naturlig språk; for eksempel kan søkesemantikken ovenfor uttrykkes ved: "vis meg navn og antall følgere per bruker","hvor mange følgere er det for hver bruker?" etc.
- SQL-syntaks er svært allsidig, og nesten alle spørsmål kan representeres i SQL på flere måter. Det enkleste eksemplet er forskjellige rekkefølger av WHERE-klausuler. På en mer avansert måte vil alle som har utført SQL-spørringsoptimalisering vite at mange veier fører til det samme resultatet, og semantisk ekvivalente spørringer kan ha en helt annen syntaks.
Den manuelle innsamlingen av treningsdata for Text2SQL er spesielt kjedelig. Det krever ikke bare SQL-mestring fra kommentatorens side, men også mer tid per eksempel enn mer generelle språklige oppgaver som sentimentanalyse og tekstklassifisering. For å sikre en tilstrekkelig mengde treningseksempler, kan dataforsterkning brukes - for eksempel kan LLM-er brukes til å generere parafraser for det samme spørsmålet. [3] gir en mer fullstendig undersøkelse av Text2SQL-dataforsterkningsteknikker.
1.2 Berike forespørselen med databaseinformasjon
Text2SQL er en algoritme i grensesnittet mellom ustrukturerte og strukturerte data. For optimal ytelse må begge typer data være tilstede under trening og prediksjon. Spesifikt må algoritmen kjenne til den spørrede databasen og være i stand til å formulere spørringen på en slik måte at den kan kjøres mot databasen. Denne kunnskapen kan omfatte:
- Kolonner og tabeller i databasen
- Relasjoner mellom tabeller (fremmednøkler)
- Databaseinnhold
Det er to alternativer for å inkorporere databasekunnskap: på den ene siden kan treningsdataene begrenses til eksempler skrevet for den spesifikke databasen, i så fall læres skjemaet direkte fra SQL-spørringen og dens tilordning til spørsmålet. Denne enkeltdatabaseinnstillingen lar deg optimere algoritmen for en individuell database og/eller bedrift. Det dreper imidlertid alle ambisjoner om skalerbarhet, siden modellen må finjusteres for hver enkelt kunde eller database. Alternativt, i en multi-database-innstilling, kan databaseskjemaet leveres som en del av input, slik at algoritmen kan "generalisere" til nye, usynlige databaseskjemaer. Selv om du absolutt må gå for denne tilnærmingen hvis du vil bruke Text2SQL på mange forskjellige databaser, husk at det krever betydelig ingeniørarbeid. For enhver rimelig forretningsdatabase, inkludert den fullstendige informasjonen i ledeteksten, vil det være ekstremt ineffektivt og mest sannsynlig umulig på grunn av begrensninger i promptlengde. Derfor bør funksjonen som er ansvarlig for rask formulering være smart nok til å velge et undersett av databaseinformasjon som er mest "nyttig" for et gitt spørsmål, og til å gjøre dette for potensielt usynlige databaser.
Til slutt spiller databasestruktur en avgjørende rolle. I de scenariene der du har nok kontroll over databasen, kan du gjøre modellens liv enklere ved å la den lære av en intuitiv struktur. Som en tommelfingerregel, jo mer databasen din gjenspeiler hvordan bedriftsbrukere snakker om virksomheten, jo bedre og raskere kan modellen din lære av den. Vurder derfor å bruke ytterligere transformasjoner på dataene, for eksempel å sette sammen normaliserte eller på annen måte spredte data til brede tabeller eller et datahvelv, navngi tabeller og kolonner på en eksplisitt og entydig måte osv. All forretningskunnskap som du kan kode på forhånd vil redusere byrden av sannsynlighetslæring på modellen din og hjelpe deg med å oppnå bedre resultater.
2. algoritme

Text2SQL er en type semantisk analysering — kartlegging av tekster til logiske representasjoner. Dermed må algoritmen ikke bare "lære" naturlig språk, men også målrepresentasjonen - i vårt tilfelle SQL. Spesifikt må den tilegne seg og følgende kunnskapsbiter:
- SQL-syntaks og semantikk
- Databasestruktur
- Naturlig språkforståelse (NLU)
- Kartlegging mellom naturlig språk og SQL-spørringer (syntaktisk, leksikalsk og semantisk)
2.1 Løse språklig variasjon i input
Ved inngangen ligger hovedutfordringen til Text2SQL i språkets fleksibilitet: som beskrevet i avsnittet Format og struktur på dataene, kan det samme spørsmålet omskrives på mange forskjellige måter. I tillegg, i den virkelige samtalekonteksten, må vi håndtere en rekke problemer som stave- og grammatikkfeil, ufullstendige og tvetydige inndata, flerspråklige inndata osv.

LLM-er som GPT-modellene, T5 og CodeX kommer nærmere og nærmere å løse denne utfordringen. Ved å lære av enorme mengder mangfoldig tekst lærer de å håndtere et stort antall språklige mønstre og uregelmessigheter. Til slutt blir de i stand til å generalisere over spørsmål som er semantisk like til tross for at de har forskjellige overflateformer. LLM-er kan brukes rett ut av esken (nullskudd) eller etter finjustering. Den førstnevnte, selv om den er praktisk, fører til lavere nøyaktighet. Sistnevnte krever mer dyktighet og arbeid, men kan øke nøyaktigheten betydelig.
Når det gjelder nøyaktighet, som forventet, er de beste modellene de nyeste modellene i GPT-familien, inkludert CodeX-modellene. I april 2023 førte GPT-4 til en dramatisk nøyaktighetsøkning på mer enn 5 % i forhold til forrige toppmoderne og oppnådde en nøyaktighet på 85.3 % (på den metriske «utførelse med verdier»).[4] I open source-leiren var de første forsøkene på å løse Text2SQL-puslespillet fokusert på auto-kodingsmodeller som BERT, som utmerker seg med NLU-oppgaver.[5, 6, 7] Men midt i hypen rundt generativ AI, fokuserer nyere tilnærminger på autoregressive modeller som T5-modellen. T5 er forhåndstrent ved bruk av fleroppgavelæring og tilpasser seg dermed enkelt til nye språklige oppgaver, inkl. forskjellige varianter av semantisk parsing. Imidlertid har autoregressive modeller en iboende feil når det kommer til semantiske analyseringsoppgaver: de har et ubegrenset utdataområde og ingen semantiske rekkverk som vil begrense produksjonen deres, noe som betyr at de kan bli utrolig kreative i oppførselen. Selv om dette er fantastiske ting for å generere innhold i fri form, er det en plage for oppgaver som Text2SQL der vi forventer en begrenset, godt strukturert målutgang.
2.2 Søkevalidering og forbedring
For å begrense LLM-utdata, kan vi introdusere ytterligere mekanismer for å validere og forbedre spørringen. Dette kan implementeres som et ekstra valideringstrinn, som foreslått i PICARD-systemet.[8] PICARD bruker en SQL-parser som kan bekrefte om en delvis SQL-spørring kan føre til en gyldig SQL-spørring etter fullføring. Ved hvert generasjonstrinn av LLM blir tokens som vil ugyldiggjøre spørringen avvist, og de gyldige tokenene med høyest sannsynlighet beholdes. Denne tilnærmingen er deterministisk og sikrer 100 % SQL-gyldighet så lenge parseren observerer korrekte SQL-regler. Den kobler også spørringsvalideringen fra generasjonen, og tillater dermed å opprettholde begge komponentene uavhengig av hverandre og å oppgradere og modifisere LLM.
En annen tilnærming er å inkorporere struktur- og SQL-kunnskap direkte i LLM. For eksempel bruker Graphix [9] grafbevisste lag for å injisere strukturert SQL-kunnskap i T5-modellen. På grunn av den sannsynlige karakteren til denne tilnærmingen, fordreier den systemet mot korrekte forespørsler, men gir ingen garanti for suksess.
Endelig kan LLM brukes som en flertrinnsagent som autonomt kan sjekke og forbedre spørringen.[10] Ved å bruke flere trinn i en tankekjede, kan agenten få i oppgave å reflektere over riktigheten av sine egne spørringer og forbedre eventuelle feil. Hvis den validerte spørringen fortsatt ikke kan utføres, kan SQL-unntakssporingen sendes til agenten som en ekstra tilbakemelding for forbedring.
Utover disse automatiserte metodene som skjer i backend, er det også mulig å involvere brukeren under spørringskontrollprosessen. Vi vil beskrive dette mer detaljert i avsnittet om brukeropplevelse.
2.3 Evaluering
For å evaluere vår Text2SQL-algoritme, må vi generere et test(validerings-) datasett, kjøre algoritmen vår på den og bruke relevante evalueringsmålinger på resultatet. Et naivt datasett delt inn i opplærings-, utviklings- og valideringsdata vil være basert på spørsmål-spørringspar og føre til suboptimale resultater. Valideringsspørsmål kan bli avslørt for modellen under trening og føre til et altfor optimistisk syn på dens generaliseringsferdigheter. EN spørringsbasert splittelse, der datasettet er delt på en slik måte at ingen spørring vises både under trening og under validering, gir mer sannferdige resultater.
Når det gjelder evalueringsmålinger, er det vi bryr oss om i Text2SQL ikke å generere spørringer som er helt identiske med gullstandarden. Dette "nøyaktig strengmatch" metoden er for streng og vil generere mange falske negativer, siden forskjellige SQL-spørringer kan føre til det samme returnerte datasettet. I stedet ønsker vi å oppnå høye semantisk nøyaktighet og evaluer om de forutsagte og "gullstandard"-spørringene alltid vil returnere de samme datasettene. Det er tre evalueringsberegninger som tilnærmer dette målet:
- Nøyaktig innstilt matchnøyaktighet: de genererte SQL-spørringene og mål-SQL-spørringene deles inn i deres bestanddeler, og de resulterende settene sammenlignes for identitet.[11] Manglen her er at den kun tar hensyn til rekkefølgevariasjoner i SQL-spørringen, men ikke for mer uttalte syntaktiske forskjeller mellom semantisk ekvivalente spørringer.
- Utførelsesnøyaktighet: datasettene som er et resultat av de genererte og mål-SQL-spørringene sammenlignes for identitet. Med hell kan spørringer med forskjellig semantikk fortsatt bestå denne testen på en spesifikk databaseforekomst. For eksempel, hvis vi antar en database der alle brukere er over 30 år, vil følgende to spørringer gi identiske resultater til tross for at de har forskjellig semantikk:
velg * fra bruker
velg * fra bruker der alder > 30 år - Test-suite nøyaktighet: test-suite nøyaktighet er en mer avansert og mindre ettergivende versjon av utførelsesnøyaktighet. For hver spørring genereres et sett ("testsuite") med databaser som er svært differensierte med hensyn til variablene, betingelsene og verdiene i spørringen. Deretter testes utførelsesnøyaktigheten på hver av disse databasene. Selv om det krever ekstra innsats for å konstruere testsuitegenerasjonen, reduserer denne beregningen også risikoen for falske positiver i evalueringen betydelig..[12]
3. Brukeropplevelse

Den nåværende state-of-the-art av Text2SQL tillater ikke en fullstendig sømløs integrasjon i produksjonssystemer – i stedet er det nødvendig å aktivt administrere forventningene og oppførselen til brukeren, som alltid bør være klar over at hun samhandler med et AI-system.
3.1 Feilhåndtering
Text2SQL kan mislykkes i to moduser, som må fanges opp på forskjellige måter:
- SQL-feil: den genererte spørringen er ikke gyldig - enten er SQL-en ugyldig, eller den kan ikke kjøres mot den spesifikke databasen på grunn av leksikalske eller semantiske feil. I dette tilfellet kan ingen resultater returneres til brukeren.
- Semantiske feil: den genererte spørringen er gyldig, men den reflekterer ikke semantikken til spørsmålet, og fører dermed til et feil returnert datasett.
Den andre modusen er spesielt vanskelig siden risikoen for "stille feil" - feil som ikke blir oppdaget av brukeren - er høy. Den prototypiske brukeren vil verken ha tid eller tekniske ferdigheter til å verifisere riktigheten av spørringen og/eller de resulterende dataene. Når data brukes til beslutningstaking i den virkelige verden, kan denne typen feil ha ødeleggende konsekvenser. For å unngå dette er det avgjørende å utdanne brukere og etablere rekkverk på forretningsnivå som begrenser den potensielle innvirkningen, for eksempel ytterligere datasjekker for beslutninger med større innvirkning. På den annen side kan vi også bruke brukergrensesnittet til å administrere menneske-maskin-interaksjonen og hjelpe brukeren med å oppdage og forbedre problematiske forespørsler.
3.2 Menneske-maskin interaksjon
Brukere kan bli involvert i AI-systemet ditt med forskjellige grader av intensitet. Mer interaksjon per forespørsel kan føre til bedre resultater, men det bremser også flyten av brukeropplevelsen. I tillegg til den potensielle negative effekten av feilsøkende søk og resultater, bør du også vurdere hvor motiverte brukerne dine vil være til å gi tilbakemeldinger frem og tilbake for å få mer nøyaktige resultater og også bidra til å forbedre produktet på lang sikt.
Den enkleste og minst engasjerende måten er å jobbe med selvtillitsscore. Mens den naive beregningen av tillit som et gjennomsnitt av sannsynlighetene for de genererte tokenene er for forenklet, kan mer avanserte metoder som verbalisert tilbakemelding brukes. [13] Tilliten kan vises i grensesnittet og fremheves med et eksplisitt varsel i tilfelle den er farlig lav. På denne måten lander ansvaret for en hensiktsmessig oppfølging i den «virkelige verden» – det være seg en avvisning, aksept eller en ekstra sjekk av dataene – på skuldrene til brukeren din. Selv om dette er en sikker innsats for deg som leverandør, kan overføring av dette arbeidet til brukeren også redusere verdien av produktet ditt.
En annen mulighet er å engasjere brukeren i en avklaringsdialog ved lavkonfidensi, tvetydige eller på annen måte mistenkelige spørsmål. Systemet ditt kan for eksempel foreslå ortografiske eller grammatiske rettelser til inndataene og be om å disambiguere spesifikke ord eller grammatiske strukturer. Det kan også tillate brukeren å proaktivt be om rettelser i spørringen:[14]
BRUKER: Vis meg Johns oppgaver i denne sprinten.
ASSISTENT: Vil du se oppgavene John har laget, eller de han jobber med?
BRUKER: oppgaver John skapte
ASSISTENT: Ok, her er oppgave-ID-ene:

BRUKER: Takk, jeg vil også gjerne se mer informasjon om oppgavene. Sorter også etter hastegrad.
ASSISTENT: Jada, her er oppgavene sammen med korte beskrivelser, oppdragstakere og frister, sortert etter frist.

Til slutt, for å lette forståelsen av spørsmål for brukeren, kan systemet ditt også gi en eksplisitt tekstlig omformulering av spørringen og be brukeren enten bekrefte eller korrigere den.[15]
4. Ikke-funksjonelle krav
I denne delen diskuterer vi de spesifikke ikke-funksjonelle kravene for Text2SQL samt avveiningene mellom dem. Vi vil fokusere på de seks kravene som synes viktigst for oppgaven: nøyaktighet, skalerbarhet, hastighet, forklarbarhet, personvern og tilpasningsevne over tid.
4.1 Nøyaktighet
For Text2SQL er kravene til nøyaktighet høye. For det første brukes Text2SQL vanligvis i en samtaleinnstilling der spådommer lages én etter én. Derfor hjelper ikke "Loven om store tall" som vanligvis hjelper til med å balansere feilen i batchforutsigelser. For det andre er syntaktisk og leksikalsk gyldighet en "vanskelig" betingelse: modellen må generere en velformet SQL-spørring, potensielt med kompleks syntaks og semantikk, ellers kan ikke forespørselen utføres mot databasen. Og hvis dette går bra og spørringen kan utføres, kan den fortsatt inneholde semantiske feil og føre til feil returnert datasett (jf. avsnitt 3.1 Feilhåndtering).
4.2 Skalerbarhet
De viktigste skalerbarhetshensynene er om du vil bruke Text2SQL på én eller flere databaser – og i sistnevnte tilfelle, om settet med databaser er kjent og lukket. Hvis ja, vil du ha en lettere tid siden du kan inkludere informasjonen om disse databasene under trening. Imidlertid, i et scenario med et skalerbart produkt - det være seg en frittstående Text2SQL-applikasjon eller en integrasjon i et eksisterende dataprodukt - må algoritmen din takle ethvert nytt databaseskjema på farten. Dette scenariet gir deg heller ikke muligheten til å transformere databasestrukturen for å gjøre den mer intuitiv for læring (lenke!). Alt dette fører til en tung avveining med nøyaktighet, noe som også kan forklare hvorfor nåværende Text2SQL-leverandører som tilbyr ad-hoc-spørring av nye databaser ennå ikke har oppnådd en betydelig markedspenetrasjon.
4.3 Speed
Siden Text2SQL-forespørsler typisk vil bli behandlet online i en samtale, er hastighetsaspektet viktig for brukertilfredsheten. På den positive siden er brukere ofte klar over det faktum at dataforespørsler kan ta en viss tid og vise den nødvendige tålmodigheten. Denne velviljen kan imidlertid undergraves av chat-innstillingen, der brukere ubevisst forventer menneskelignende samtalehastighet. Brute-force-optimaliseringsmetoder som å redusere størrelsen på modellen kan ha en uakseptabel innvirkning på nøyaktigheten, så vurder inferensoptimalisering for å tilfredsstille denne forventningen.
4.4 Forklarlighet og åpenhet
I det ideelle tilfellet kan brukeren følge med på hvordan spørringen ble generert fra teksten, se kartleggingen mellom spesifikke ord eller uttrykk i spørsmålet og SQL-spørringen etc. Dette gjør det mulig å verifisere spørringen og gjøre eventuelle justeringer ved interaksjon med systemet . Dessuten kan systemet også gi en eksplisitt tekstlig omformulering av spørringen og be brukeren enten bekrefte eller korrigere den.
4.5 Personvern
Text2SQL-funksjonen kan isoleres fra kjøring av spørringer, slik at den returnerte databaseinformasjonen kan holdes usynlig. Det kritiske spørsmålet er imidlertid hvor mye informasjon om databasen som er inkludert i ledeteksten. De tre alternativene (ved å redusere personvernnivået) er:
- Ingen informasjon
- Databaseskjema
- Databaseinnhold
Personvernet avvikles med nøyaktighet - jo mindre begrenset du er med å inkludere nyttig informasjon i forespørselen, jo bedre blir resultatene.
4.6 Tilpasningsevne over tid
For å bruke Text2SQL på en varig måte, må du tilpasse deg datadrift, dvs. den endrede distribusjonen av dataene som modellen brukes på. La oss for eksempel anta at dataene som brukes til innledende finjustering gjenspeiler den enkle spørreatferden til brukere når de begynner å bruke BI-systemet. Etter hvert som tiden går, blir informasjonsbehovene til brukerne mer sofistikerte og krever mer komplekse spørsmål, som overvelder din naive modell. Dessuten kan målene eller strategien til en bedriftsendring også drive og rette informasjonsbehovet mot andre områder av databasen. Til slutt, en Text2SQL-spesifikk utfordring er databasedrift. Etter hvert som firmadatabasen utvides, kommer nye, usynlige kolonner og tabeller inn i ledeteksten. Mens Text2SQL-algoritmer som er designet for multi-databaseapplikasjoner kan håndtere dette problemet godt, kan det påvirke nøyaktigheten til en enkeltdatabasemodell betydelig. Alle disse problemene løses best med et finjusterende datasett som gjenspeiler den nåværende, virkelige atferden til brukere. Derfor er det avgjørende å logge brukerspørsmål og resultater, samt eventuelle tilhørende tilbakemeldinger som kan samles inn fra bruk. I tillegg kan semantiske klyngealgoritmer, for eksempel ved bruk av innebygging eller emnemodellering, brukes for å oppdage underliggende langsiktige endringer i brukeratferd og bruke disse som en ekstra kilde til informasjon for å perfeksjonere ditt finjusteringsdatasett
konklusjonen
La oss oppsummere hovedpunktene i artikkelen:
- Text2SQL gjør det mulig å implementere intuitiv og demokratisk datatilgang i en virksomhet, og dermed maksimere verdien av tilgjengelige data.
- Text2SQL-data består av spørsmål ved inngangen, og SQL-spørringer ved utgangen. Kartleggingen mellom spørsmål og SQL-spørringer er mange-til-mange.
- Det er viktig å oppgi informasjon om databasen som en del av forespørselen. I tillegg kan databasestrukturen optimaliseres for å gjøre det lettere for algoritmen å lære og forstå den.
- Når det gjelder input, er hovedutfordringen den språklige variabiliteten til naturlige språkspørsmål, som kan tilnærmes ved hjelp av LLM-er som ble forhåndsopplært på en lang rekke forskjellige tekststiler
- Utdataene fra Text2SQL skal være en gyldig SQL-spørring. Denne begrensningen kan inkorporeres ved å "injisere" SQL-kunnskap i algoritmen; alternativt, ved å bruke en iterativ tilnærming, kan spørringen kontrolleres og forbedres i flere trinn.
- På grunn av den potensielt høye effekten av "stille feil" som returnerer feil data for beslutningstaking, er feilhåndtering en primær bekymring i brukergrensesnittet.
- På en "utvidet" måte kan brukere være aktivt involvert i iterativ validering og forbedring av SQL-spørringer. Selv om dette gjør applikasjonen mindre flytende, reduserer den også feilfrekvensen, lar brukerne utforske data på en mer fleksibel måte og skaper verdifulle signaler for videre læring.
- De viktigste ikke-funksjonelle kravene å vurdere er nøyaktighet, skalerbarhet, hastighet, forklarbarhet, personvern og tilpasningsevne over tid. De viktigste avveiningene består mellom nøyaktighet på den ene siden, og skalerbarhet, hastighet og personvern på den andre siden.
Referanser
[1] Ken Van Haren. 2023. Erstatter en SQL-analytiker med 26 rekursive GPT-meldinger
[2] Nitarshan Rajkumar et al. 2022. Evaluering av tekst-til-SQL-funksjonene til store språkmodeller
[3] Naihao Deng et al. 2023. Nylige fremskritt i tekst-til-SQL: En undersøkelse av hva vi har og hva vi forventer
[4] Mohammadreza Pourreza et al. 2023. DIN-SQL: Dekomponert In-Context læring av tekst-til-SQL med selvkorreksjon
[5] Victor Zhong et al. 2021. Jordet tilpasning for nullskuddsutførbar semantisk parsing
[6] Xi Victoria Lin et al. 2020. Slå bro mellom tekst- og tabelldata for tekst-til-SQL-semantisk parsing på tvers av domener
[7] Tong Guo et al. 2019. Innholdsforbedret BERT-basert tekst-til-SQL-generering
[8] Torsten Scholak et al. 2021. PICARD: Parsing trinnvis for begrenset autoregressiv dekoding fra språkmodeller
[9] Jinyang Li et al. 2023. Graphix-T5: Blanding av ferdigtrente transformatorer med grafbevisste lag for tekst-til-SQL-parsing
[10] Langkjede. 2023. LLM og SQL
[11] Tao Yu et al. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
[12] Ruiqi Zhong et al. 2020. Semantisk evaluering for tekst-til-SQL med destillerte testsuiter
[13] Katherine Tian et al. 2023. Bare be om kalibrering: Strategier for å fremkalle kalibrerte selvtillitspoeng fra språkmodeller finjustert med menneskelig tilbakemelding
[14] Braden Hancock et al. 2019. Lær av dialog etter distribusjon: Mat deg selv, Chatbot!
[15] Ahmed Elgohary et al. 2020. Snakk med parseren din: Interaktiv tekst-til-SQL med tilbakemelding på naturlig språk
[16] Janna Lipenkova. 2022. Snakk med meg! Text2SQL-samtaler med bedriftens data, snakk på New York Natural Language Processing meetup.
Alle bildene er av forfatteren.
Denne artikkelen ble opprinnelig publisert på Mot datavitenskap og publisert på nytt til TOPBOTS med tillatelse fra forfatteren.
Liker du denne artikkelen? Registrer deg for flere AI-forskningsoppdateringer.
Vi gir beskjed når vi gir ut flere sammendragsartikler som denne.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://www.topbots.com/conversational-ai-for-data-analysis/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 11
- 12
- 13
- 14
- 15%
- 16
- 2018
- 2019
- 2020
- 2021
- 2022
- 2023
- 26
- 30
- 7
- 8
- 9
- a
- I stand
- Om oss
- ovenfor
- Absolute
- absolutt
- godkjennelse
- adgang
- Tilgang til data
- Ifølge
- kontoer
- nøyaktighet
- nøyaktig
- nøyaktig
- Oppnå
- oppnådd
- erverve
- aktivt
- tilpasse
- tilpasning
- tilpasser
- Ytterligere
- I tillegg
- justeringer
- avansert
- fremskritt
- Fordel
- Etter
- mot
- alder
- alderen
- Agent
- AI
- ai forskning
- AL
- Varsle
- algoritme
- algoritmer
- Alle
- tillate
- tillate
- tillater
- langs
- allerede
- også
- alternativ
- alltid
- utrolig
- ambisjoner
- blant
- an
- analyse
- analytiker
- analytikere
- Analytisk
- analytics
- og
- En annen
- noen
- Søknad
- søknader
- anvendt
- Påfør
- påføring
- tilnærming
- tilnærminger
- hensiktsmessig
- tilnærmet
- April
- ER
- områder
- rundt
- Artikkel
- artikler
- AS
- aspektet
- aspekter
- assosiert
- At
- forsøk
- forfatter
- Automatisert
- automatisk
- autonomt
- tilgjengelig
- gjennomsnittlig
- unngå
- klar
- Backend
- Balansere
- basen
- basert
- basis
- BE
- bli
- Begynnelsen
- være
- Fordeler
- foruten
- BEST
- Bet
- Bedre
- mellom
- Beyond
- skjevheter
- Biggest
- både
- bygge
- Bygning
- byrde
- virksomhet
- bedrifter
- men
- by
- som heter
- Camp
- CAN
- Kan få
- kan ikke
- evner
- hvilken
- saken
- fanget
- sentral
- viss
- utfordre
- utfordringer
- endring
- Endringer
- endring
- Kanal
- sjekk
- sjekket
- kontroll
- Sjekker
- valg
- klassifisering
- stengt
- nærmere
- gruppering
- samling
- kolonner
- kommer
- kommer
- Felles
- Kommunikasjon
- Selskaper
- Selskapet
- Selskapets
- sammenlignet
- konkurranse
- konkurranse
- fullføre
- helt
- ferdigstillelse
- komplekse
- komponenter
- konsepter
- konseptuelle
- Bekymring
- tilstand
- forhold
- selvtillit
- Bekrefte
- Konsekvenser
- Vurder
- betydelig
- betraktninger
- ansett
- består
- innhold
- kontekst
- kontroll
- Praktisk
- konvensjonell
- Samtale
- conversational
- samtale AI
- Samtalegrensesnitt
- samtaler
- Kul
- korrigere
- Korreksjoner
- Tilsvarende
- kunne
- skape
- opprettet
- skaper
- Opprette
- Kreativ
- kritisk
- avgjørende
- Gjeldende
- I dag
- kunde
- dato
- data tilgang
- dataanalyse
- datavitenskap
- dataforsker
- Database
- databaser
- datasett
- avtale
- avgjørelse
- Beslutningstaking
- avgjørelser
- Dekoding
- dyp
- dypdykk
- forsinkelser
- levert
- demokratisk
- avhengig
- distribusjon
- beskrive
- beskrevet
- designet
- designere
- ønsket
- Til tross for
- detalj
- ødeleggende
- Utvikling
- Dialog
- forskjeller
- forskjellig
- differensiert
- direkte
- direkte
- motet
- diskutere
- diskusjoner
- fordelt
- vises
- Avbrudd
- distribusjon
- diverse
- do
- gjør
- ikke
- gjør
- gjort
- ikke
- ned
- dramatisk
- to
- under
- dynamisk
- e
- E&T
- hver enkelt
- lette
- enklere
- enkleste
- lett
- Edge
- utdanne
- pedagogisk
- innsats
- enten
- elementer
- omfavnet
- ansatte
- muliggjøre
- omfatte
- slutt
- energi
- engasjere
- engasjerende
- ingeniør
- Ingeniørarbeid
- Ingeniører
- forbedret
- nok
- berikende
- sikre
- sikrer
- fullstendig
- inngang
- miljøer
- Tilsvarende
- feil
- feil
- anslag
- etc
- Eter (ETH)
- evaluere
- evaluering
- Selv
- Hver
- alle
- eksempel
- eksempler
- Excel
- unntak
- henrettet
- gjennomføring
- Fritatt
- eksisterer
- eksisterende
- forvente
- forventning
- forventninger
- forventet
- dyrt
- erfaring
- Forklar
- Forklarbarhet
- utforske
- uttrykte
- uttrykkene
- ekstra
- ekstremt
- Faktisk
- FAIL
- Failure
- falsk
- familie
- Mote
- raskere
- Trekk
- tilbakemelding
- Figur
- Endelig
- Først
- feil
- feil
- fleksibilitet
- fleksibel
- flyten
- væske
- flyt
- Fokus
- fokusert
- følge
- følgere
- etter
- Til
- utenlandske
- skjema
- format
- Tidligere
- skjemaer
- formuleringen
- ofte
- friksjon
- fra
- fullt
- funksjon
- videre
- general
- generere
- generert
- genererer
- generasjonen
- generative
- Generativ AI
- få
- få
- Gi
- gitt
- Global
- Go
- mål
- Mål
- Går
- Gull
- Gold Standard
- god
- Goodwill
- Grammatikk
- Ground
- Økende
- garantere
- veilede
- HAD
- hånd
- håndfull
- håndtere
- hender
- skje
- Ha
- å ha
- he
- tung
- hjelpe
- hjelper
- her.
- Høy
- høykvalitets
- høyere
- Uthev
- Fremhevet
- svært
- Hvordan
- Men
- HTML
- HTTPS
- stort
- menneskelig
- Mennesker
- Hype
- i
- ideell
- identiske
- Identitet
- ids
- if
- bilder
- Påvirkning
- iverksette
- gjennomføring
- implementert
- viktig
- umulig
- forbedre
- forbedret
- forbedring
- bedre
- in
- dyptgående
- inkludere
- inkludert
- Inkludert
- innlemme
- Incorporated
- innlemme
- Øke
- uavhengig av hverandre
- individuelt
- industri
- ineffektiv
- informasjon
- informert
- innledende
- injisere
- inngang
- innganger
- innsikt
- f.eks
- i stedet
- integrering
- samhandle
- samhandler
- interaksjon
- interaksjoner
- interaktiv
- Interface
- grensesnitt
- inn
- egenverdi
- introdusere
- intuitiv
- investere
- involvere
- involvert
- isolert
- utstedelse
- saker
- IT
- DET ER
- John
- reise
- Hold
- holdt
- nøkkel
- nøkler
- Dreper
- Type
- Vet
- kunnskap
- Knowledge Management
- kjent
- lander
- Språk
- stor
- storskala
- større
- siste
- lag
- lag
- føre
- ledende
- Fører
- LÆRE
- lært
- læring
- minst
- Led
- Lengde
- mindre
- utleie
- Nivå
- Leverage
- li
- ligger
- Life
- i likhet med
- BEGRENSE
- begrensninger
- lin
- lite
- logg
- logisk
- Lang
- langsiktig
- ser
- tapte
- Lav
- lavere
- flaks
- maskin
- maskinlæring
- laget
- Hoved
- vedlikeholde
- større
- gjøre
- GJØR AT
- Making
- administrer
- ledelse
- leder
- Ledere
- håndbok
- produksjon
- mange
- kartlegging
- merket
- marked
- Marketing
- Master
- mestring
- Match
- materiale
- modenhet
- max bredde
- maksimering
- me
- midler
- mekanismer
- Meetup
- mental
- metode
- metoder
- metrisk
- Metrics
- kunne
- tankene
- feil
- Blanding
- Mote
- modell
- modellering
- modeller
- Moderne
- moduser
- modifisere
- mer
- mest
- motivert
- mye
- flere
- navn
- navn
- navngiving
- Naturlig
- Naturlig språk
- Natural Language Processing
- Natur
- nødvendig
- Trenger
- behov
- negativ
- negativer
- Ingen
- Ny
- New York
- NLU
- Nei.
- Bråk
- ikke-teknisk
- eller
- nå
- Antall
- tall
- Målet
- Observerer
- foreldet
- of
- off
- tilby
- tilby
- ofte
- on
- ONE
- på nett
- bare
- åpen kildekode
- Drift
- Opportunity
- motsetning
- optimal
- optimalisere
- Optimalisert
- Optimistisk
- alternativer
- or
- rekkefølge
- opprinnelig
- Annen
- ellers
- vår
- produksjon
- enn
- egen
- par
- par
- del
- spesielt
- passere
- bestått
- passerer
- Tålmodighet
- mønstre
- penetration
- perfeksjonere
- ytelse
- tillatelse
- planlegging
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- vær så snill
- poeng
- positiv
- mulighet
- mulig
- potensiell
- potensielt
- spådd
- prediksjon
- Spådommer
- presentere
- forrige
- primære
- privatliv
- privilegium
- premie
- sannsynligvis
- prosess
- behandlet
- prosessering
- Produkt
- Produksjon
- uttales
- foreslått
- gi
- forutsatt
- tilbydere
- gir
- publisert
- puslespillet
- Python
- kvalitet
- kvantitet
- spørsmål
- spørsmål
- spørsmål
- raskt
- område
- priser
- Raw
- rådata
- lesere
- ekte
- virkelige verden
- rimelig
- oppsummering
- nylig
- rekursiv
- redusere
- reduserer
- redusere
- referanser
- referert
- reflektere
- Gjenspeiler
- i slekt
- relasjoner
- Relasjoner
- slipp
- relevant
- representasjon
- representert
- anmode
- forespørsler
- krever
- påkrevd
- Krav
- Krever
- forskning
- respekt
- ansvar
- ansvarlig
- begrenset
- resultere
- resulterende
- Resultater
- retur
- Avslørt
- Risiko
- Rival
- veier
- ROI
- Rolle
- roller
- runder
- Regel
- regler
- Kjør
- rennende
- trygge
- samme
- tilfredshet
- skalerbarhet
- skalerbar
- scenario
- scenarier
- Vitenskap
- Forsker
- forskere
- score
- sømløs
- Sekund
- Seksjon
- seksjoner
- se
- synes
- semantikk
- sentiment
- ServiceNow
- sett
- sett
- innstilling
- innstillinger
- oppsett
- hun
- Kort
- bør
- Vis
- side
- undertegne
- signaler
- signifikant
- betydelig
- lignende
- Enkelt
- siden
- enkelt
- SIX
- Størrelse
- ferdighet
- ferdigheter
- bremser
- mindre
- Smart
- So
- solid
- løse
- noe
- sofistikert
- kilde
- Rom
- spesifikk
- spesielt
- fart
- bruke
- splittet
- Sprint
- SQL
- kvadrat
- Staff
- stående
- Standard
- Begynn
- startet
- starter
- state-of-the-art
- status
- Trinn
- Steps
- Still
- Strategisk
- strategier
- Strategi
- streng
- String
- strukturell
- struktur
- strukturert
- suksess
- slik
- tilstrekkelig
- foreslår
- SAMMENDRAG
- Støttes
- overflaten
- Survey /Inspeksjonsfartøy
- mistenkelig
- syntaks
- system
- Systemer
- Ta
- Talent
- Snakk
- Target
- Oppgave
- oppgaver
- lag
- lag
- Teknisk
- teknikker
- Teknologi
- begrep
- vilkår
- test
- testet
- Tekstklassifisering
- enn
- Det
- De
- Codex
- informasjonen
- deres
- Dem
- deretter
- Der.
- Disse
- de
- tror
- denne
- De
- tre
- Gjennom
- hele
- tid
- til
- tokens
- også
- verktøykasse
- verktøy
- TOPPBOTS
- Tema
- mot
- handler
- tradisjonelle
- Kurs
- Overføre
- Transform
- Transformation
- transformasjoner
- transformers
- SVING
- Turning
- to
- typen
- typer
- typisk
- underliggende
- forstå
- forståelse
- Universell
- oppdateringer
- oppgradering
- hastverk
- bruk
- bruke
- brukt
- nyttig informasjon
- Bruker
- Brukererfaring
- Brukergrensesnitt
- Brukere
- bruker
- ved hjelp av
- ux
- ux-designere
- validert
- validere
- validering
- Verdifull
- verdi
- Verdier
- variasjon
- ulike
- Vault
- leverandør
- verifisere
- allsidig
- versjon
- veldig
- av
- Victoria
- Se
- syn
- ønsker
- var
- Vei..
- måter
- we
- uke
- ukentlig
- VI VIL
- var
- Hva
- når
- om
- hvilken
- mens
- HVEM
- hvorfor
- bred
- vil
- vinne
- med
- uten
- ord
- Arbeid
- arbeid
- verden
- ville
- skrevet
- Feil
- xi
- gul
- ja
- ennå
- york
- du
- Din
- deg selv
- youtube
- zephyrnet
- Zhong