Introduksjon
Confluence er et samarbeidsverktøy utviklet av Atlassian, designet for å hjelpe team med å samarbeide og dele kunnskap effektivt. I det moderne arbeidsområdet er evnen til å jobbe digitalt uvurderlig. Confluence forenkler dette ved å tilby en plattform der team kan opprette, dele og samarbeide om prosjekter på ett sted. Utover bare samarbeid, skiller Confluence seg ut med funksjoner som sanntidsredigering, integrasjon med andre Atlassian-produkter og et brukervennlig grensesnitt, noe som gjør det til et foretrukket valg for mange organisasjoner.
Veiledning om bruk av Confluence innebygde søkefunksjon
I Confluence er søk etter informasjon eller spesifikke elementer en enkel, men begrenset funksjon. Slik kan du få mest mulig ut av Confluences søkefunksjoner:
1. Grunnleggende søk:
Slik starter du et grunnleggende søk:
- Klikk på forstørrelsesglassikonet i overskriften eller bruk snarveien
Shift + /å fokusere på søkefeltet. - Skriv inn søket ditt i søkefeltet som vises øverst på siden. Mens du skriver, vil Confluence gi direkte søkeresultater, og gi forslag basert på innholdet som er tilgjengelig på nettstedet ditt.
2. Avansert søk:
For mer raffinerte resultater, er det avanserte søk hvor du bør gå:
- Klikk på forstørrelsesglassikonet og deretter på "Avansert søk" ved siden av søkefeltet eller bruk snarveien
Shift + /etterfulgt ava. - Her kan du filtrere søket ditt basert på ulike kriterier som typen innhold (sider, blogger, vedlegg, etc.), mellomrom, bidragsytere og datoperioder blant annet.
3. Bruke søkesyntaks:
Confluence støtter en rekke søkesyntakser for å begrense søket ditt:
- Anførselstegn: Bruk anførselstegn for å søke etter en eksakt setning. For eksempel "møtenotater".
- Jokertegn: Bruk stjernen
*som et jokertegn for å representere et hvilket som helst antall tegn i et ord. - Boolske operatører: Bruk
AND,ORogNOTå kombinere eller ekskludere termer. - Nærhetssøk: Bruk tilden
~etterfulgt av et tall for å søke etter ord innenfor en viss avstand fra hverandre. For eksempel «årsrapport»~10. - Feltsøking: Søk innenfor spesifikke felt ved å bruke syntaks som
title:,text:,creator:ogmodifier:blant andre.
4. Søke etter vedlegg:
Når det gjelder å lete etter spesifikke vedlegg:
- naviger til
Search > Advanced Search. - Velg "Vedlegg" i delen "Av type".
- Bruk søkesyntaksen
/.*<attachment type>.*/. For eksempel, for å søke etter PNG-filer, ville du bruke/.*png.*/.
5. Databasesøk (for server- og datasenterdistribusjoner):
For de med tilgang til Confluence-databasen, kan spesifikke SQL-spørringer brukes til å søke etter bestemte vedleggstyper. For å finne alle PNG-vedlegg kan du for eksempel bruke følgende SQL-spørring:
select c.TITLE as Attachment_Name, s.spacename,
c2.TITLE as Page_Title, 'http://<confluence_base_url>/pages/viewpageattachments.action?pageId='||c.PAGEID as Location
from CONTENT c
join CONTENT c2 ON c.PAGEID = c2.CONTENTID
join SPACES s on c2.SPACEID = s.SPACEID
where c.CONTENTTYPE = 'ATTACHMENT' and c.title like '%.png%';
SQL-spørringene kan justeres basert på vedleggstypen du søker etter.
6. Søk etter vedleggsmappe (spesifikke plattformer):
På visse plattformer kan Unix-søkesyntaks brukes direkte i vedleggsmappen til Confluence for å finne bestemte filtyper:
find /<confluence_home>/attachments -type f | xargs file | grep PNG
Dette vil søke etter og liste alle PNG-filer i vedleggsmappen til Confluence-forekomsten.
Hver av disse metodene gir et annet nivå av granularitet og kontroll over søket ditt, og sikrer at du finner akkurat det du trenger i Confluence.
Du kan gå dypere inn i Confluence innebygde søk ved å lese disse artiklene –
Mangler ved den innebygde søkefunksjonen Confluence
Den iboende kompleksiteten i å søke Confluence stammer først og fremst fra dens manglende evne til å bruke den kontekstuelle essensen av søkespørringer, i motsetning til søkemotorer som Google. Her er en oversikt over utfordringene:
- Gjentakelse i søk: Begrensede forekomster av identiske søk i søkehistorikken hindrer ofte nøyaktigheten av søkeresultater, på grunn av minimale kontekstuelle data tilgjengelig fra tidligere søk. Dette blir spesielt problematisk når brukere søker etter oppdatert eller nylig informasjon, som kan være begravet under utdaterte eller mindre relevante resultater.
- Semantisk forståelse: Plattformens manglende kapasitet til å skjelne synonymer eller ignorere stoppord fører ofte til mindre relevante innholdsforslag. For eksempel kan det være vanskelig å skille mellom "IT" som et akronym for informasjonsteknologi og "det" som et pronomen. I tillegg kan denne mangelen på semantisk forståelse føre til forvirring når vanlig bransjesjargong eller akronymer brukes i søk.
- Eksakt matchdilemma: Mens du prøver å eliminere stoppord, forstyrrer Confluence noen ganger søket etter nøyaktig samsvar, noe som gjør oppgaven enda mer utfordrende. Dette kan potensielt føre til at brukere ikke finner det eksakte dokumentet eller informasjonen de søker etter, og dermed hindre produktiviteten.
- One-size-fits-all-dilemma: Mangfoldet i organisasjonsstrukturer, intern informasjon og brukerhensikter nødvendiggjør et mer personlig tilpasset søkesystem. En rudimentær Machine Learning (ML)-tilnærming kan potensielt forbedre søkeopplevelsen ved å utnytte brukerinteraksjonsdata for å avgrense søkerelevansen over tid. Når vi diskuterer ML, kan algoritmer som samarbeidsfiltrering eller dyp læring utforskes for å gjøre Confluences søk mer intuitivt og brukersentrisk.
Enkelt sagt, hvis Alice slår opp et emne (la oss si X) i dag og finner et dokument (doc3) nyttig, så når Bob søker etter det samme emnet (X) i morgen, bør doc3 vises høyere i søkeresultatene fordi det var nyttig for Alice. For å få dette til, må systemet holde styr på hvilke dokumenter folk finner nyttige. Denne sporingen må imidlertid gjøres på en måte som respekterer personvernet, slik at bare personer som skal se visse dokumenter kan se dem. Denne prosessen kan også bruke opp mye datamaskinressurser som minne og lagring, noe som kan være en bekymring. Noen organisasjoner har kanskje ikke de ekstra ressursene eller personalet til å administrere dette, så de foretrekker et enklere system som kanskje ikke blir bedre over tid, men som er enkelt å vedlikeholde og ikke gir dem ekstra hodepine som å gå tom for minne.
Søk Confluence med Nanonets Confluence Bot
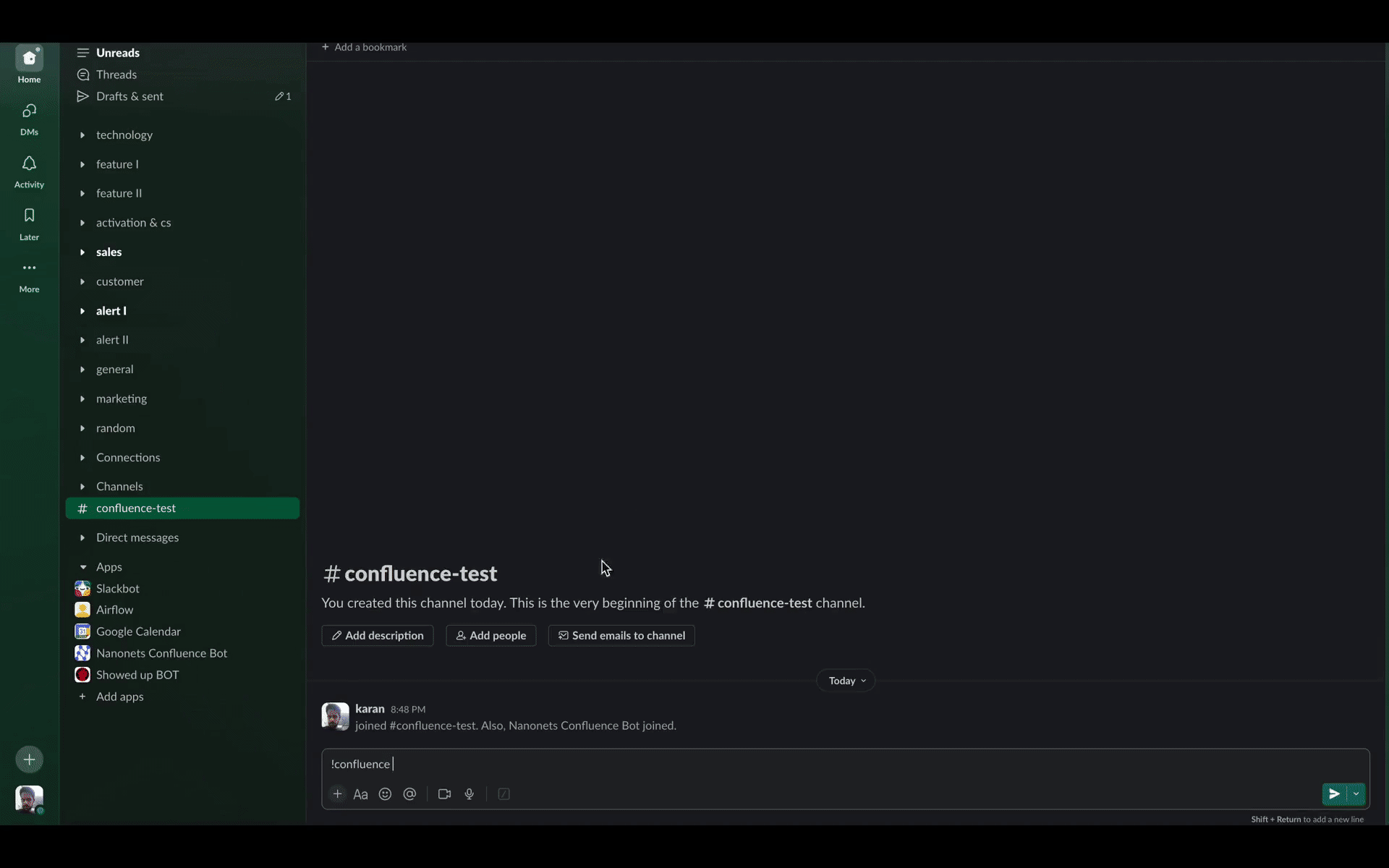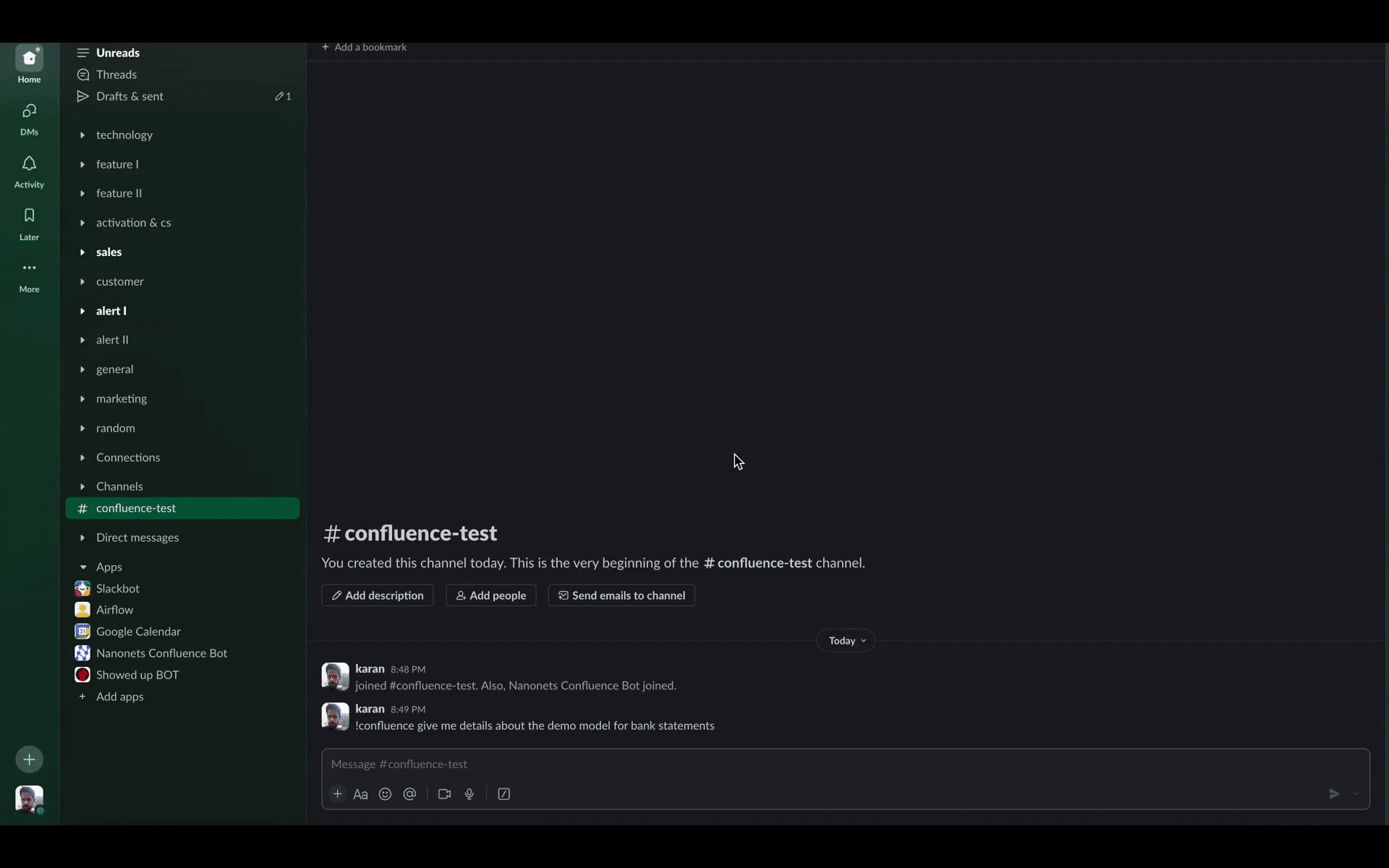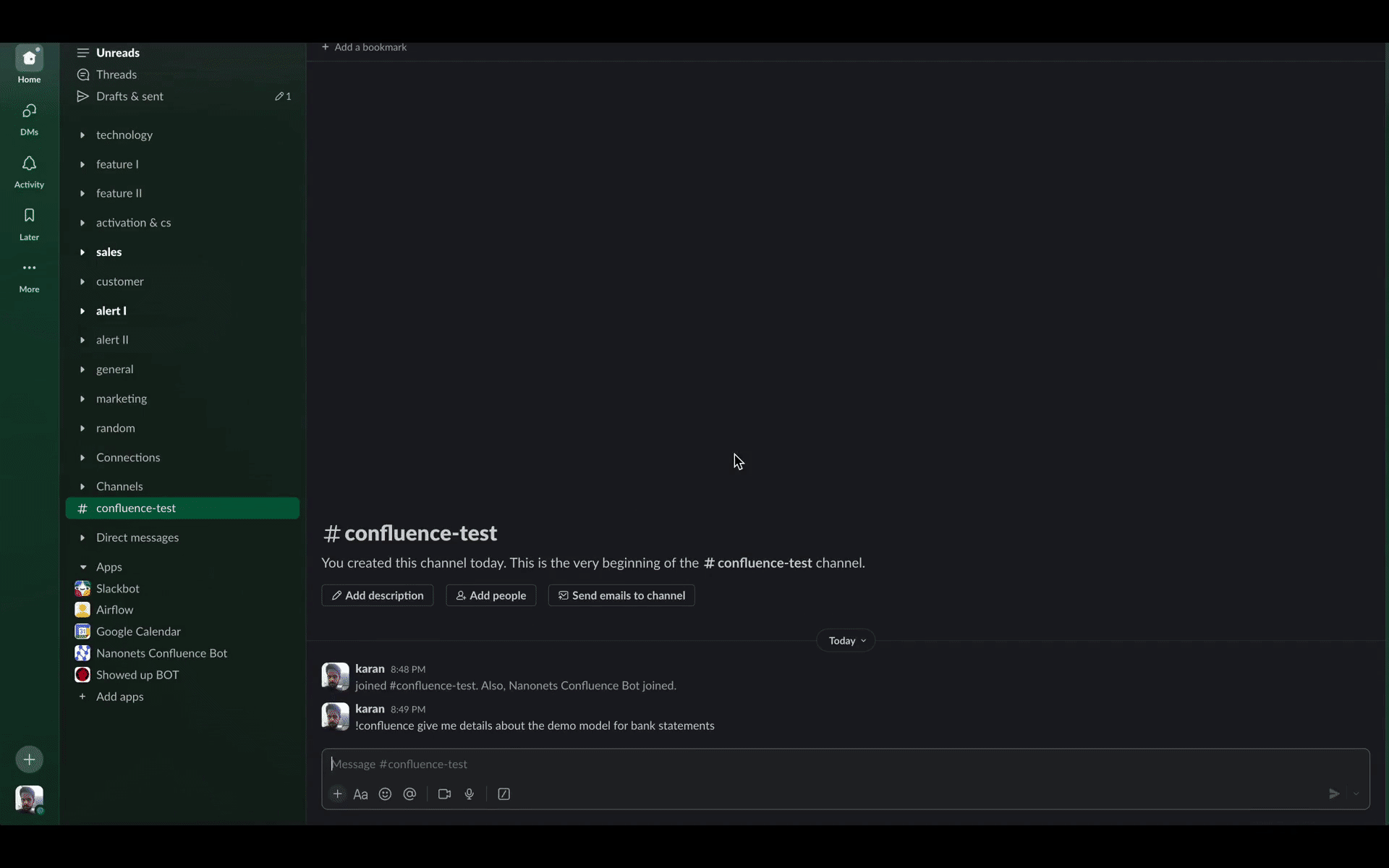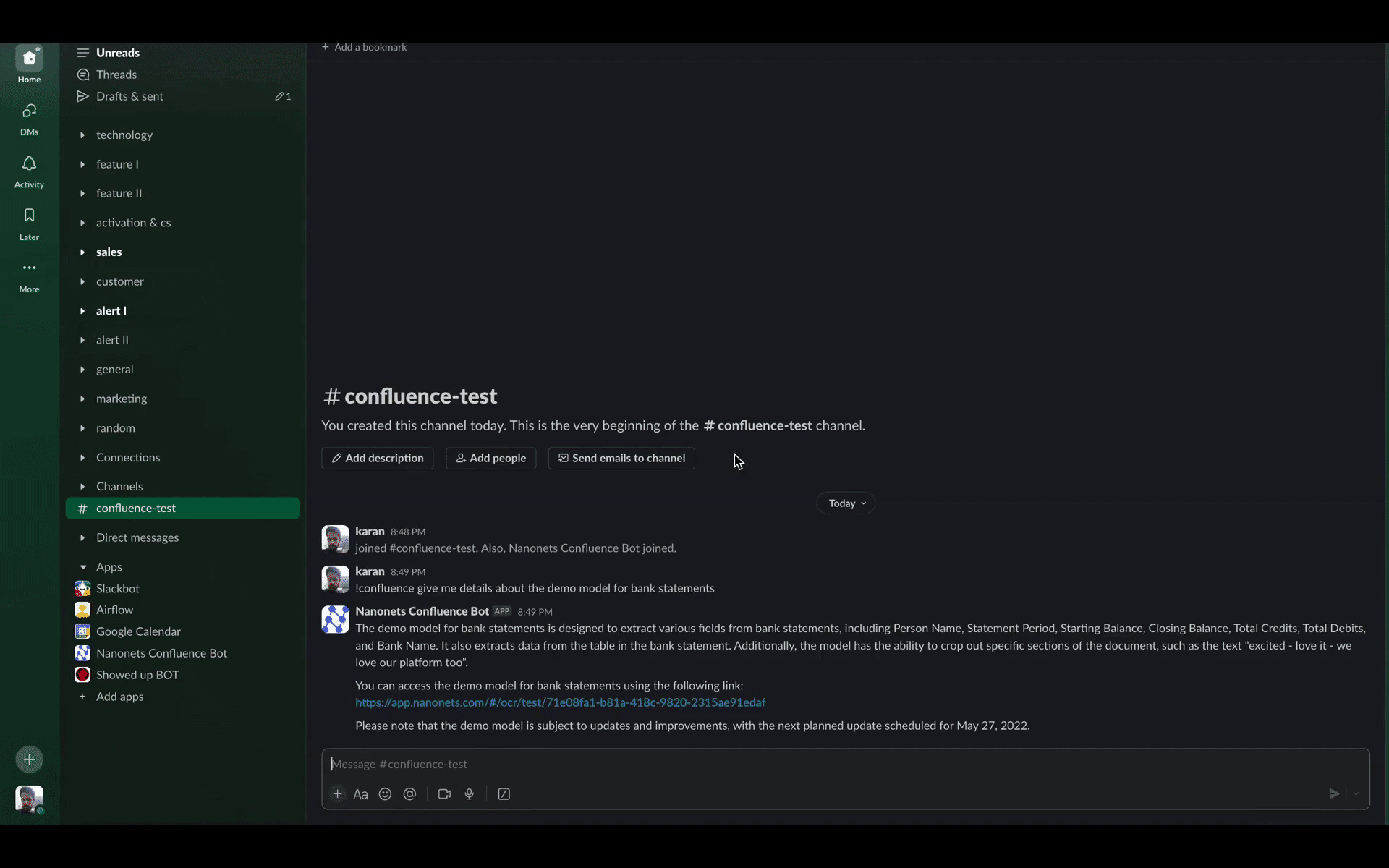
Nanonets introduserer en transformativ løsning på de nevnte utfordringene i Confluences søkefunksjoner. Å bruke vår egendefinerte LLM-baserte chatbot som assistent kan bygge bro over gapene og forbedre brukersøkeopplevelsen. Dette er hvordan:
- Kontekstuell forståelse: I motsetning til tradisjonelle søkemetoder, forstår chatboten vår konteksten til søk. For eksempel vil et søk etter "Java" få opp resultater relatert til programmeringsspråket, ikke øya eller kaffen. LLM-teknologien (Language Model) bak chatboten vår er spesielt skreddersydd for å forstå nyansene og konteksten bedre, og dermed gi mer nøyaktige og relevante søkeresultater.
- Lær av brukerinteraksjon: Vår chatbot kan lære av hvordan brukere samhandler med søkemotoren. Hvis et dokument ofte åpnes via et bestemt søk, vil det bli rangert høyere for lignende fremtidige søk, som et dokument som blir mer populært når det søkes etter «Agil metodikk». Over tid kan denne læringen utvikles for å forutse brukerbehov bedre, noe som gjør søkeprosessen mye mer intuitiv.
- Semantiske forhold: Den LLM-baserte chatboten kan gjenkjenne synonymer og relaterte termer, og forbedre søkeforslagene. For eksempel vil et søk etter «feilsporing» også vise dokumenter relatert til «problemsporing» og «feilsporing».
- Brukerforeslått innhold: Brukere kan foreslå innhold for spesifikke søk, og forbedre søkedatabasen over tid. Dette gjør dokumenter lettere å finne, som å gjøre et dokument mer synlig for spørsmål om «Scrum-praksis».
- Administrasjon av tilgangsrettigheter: Vi sikrer at kun autoriserte brukere har tilgang til visse dokumenter under et søk. For eksempel, hvis to prosjekter har konfidensielle dokumenter, vil et søk kun vise dokumenter fra søkerens eget prosjekt, og holde andre prosjekts dokumenter konfidensielle.
- Ressursoptimalisering: Våre løsninger fungerer effektivt og sparer både tid og kostnader, noe som er avgjørende for organisasjoner som ønsker å effektivisere driften og redusere driftsutgiftene.
Slack Integration for Nanonets Confluence Bot
Vår chatbot kommer med en klar til bruk Slack-integrasjon. Når chatboten din er klar, kan du ganske enkelt autentisere Slack-arbeidsområdet ditt og utføre et par klikk for å konfigurere integrasjonen. Når du er ferdig, vil du kunne stille spørsmål og til og med ha detaljerte samtaler om samløpsområdene dine med boten direkte fra Slack-appen din, uten å måtte bytte mellom apper. Denne integrasjonen fremmer et enhetlig digitalt arbeidsområde, som muliggjør strømlinjeformet kommunikasjon og samarbeid, og dermed øke produktiviteten og brukertilfredsheten.
Ta en titt på demoen nedenfor.
konklusjonen
Confluence av Atlassian forenkler digitalt teamarbeid, men har en grunnleggende søkefunksjon. Nanonets Confluence Bot forbedrer dette betydelig ved å forstå kontekst og lære av brukerinteraksjoner, noe som gjør søk mer intuitive. Den opprettholder også dokumenttilgangssikkerhet, og sikrer at bare autoriserte brukere har tilgang til viss informasjon. Dessuten fremmer Slack-integrasjonen et enhetlig digitalt arbeidsområde, noe som øker produktiviteten og brukertilfredsheten. Gjennom disse forbedringene forbedrer Nanonets Confluence Bot søkeopplevelsen i Confluence, og bidrar til et mer effektivt samarbeidsmiljø for deg og teamene dine.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://nanonets.com/blog/search-in-confluence/
- : har
- :er
- :ikke
- :hvor
- $OPP
- a
- evne
- I stand
- Om oss
- adgang
- aksesseres
- nøyaktighet
- nøyaktig
- Akronymer
- Handling
- Ytterligere
- I tillegg
- justert
- avansert
- smidig
- algoritmer
- alice
- Alle
- tillate
- også
- blant
- an
- og
- årlig
- forutse
- noen
- app
- vises
- tilnærming
- apps
- ER
- artikler
- AS
- spør
- Assistent
- At
- Atlassian
- forsøker
- godkjenne
- autorisert
- tilgjengelig
- Bar
- basert
- grunnleggende
- BE
- fordi
- blir
- bli
- bak
- under
- Bedre
- mellom
- Beyond
- blogger
- bob
- Bot
- både
- Breakdown
- BRO
- bringe
- Bug
- men
- by
- CAN
- evner
- Kapasitet
- sentrum
- viss
- utfordringer
- utfordrende
- tegn
- chatbot
- chatbots
- valg
- Kaffe
- samarbeide
- samarbeid
- samarbeids
- kombinere
- kommer
- Felles
- Kommunikasjon
- kompleksitet
- datamaskin
- Bekymring
- konklusjon
- sammenløp
- forvirring
- innhold
- kontekst
- kontekstuelle
- medvirkende
- bidragsytere
- kontroll
- samtaler
- Kostnad
- kunne
- Par
- skape
- kriterier
- avgjørende
- skikk
- dato
- Datasenter
- Database
- Dato
- dyp
- dyp læring
- dypere
- dybden
- Demo
- distribusjoner
- designet
- detaljert
- utviklet
- forskjellig
- digitalt
- digitalt
- direkte
- skjelne
- diskutere
- avstand
- Mangfold
- dokument
- dokumenter
- ikke
- gjort
- ned
- under
- hver enkelt
- enklere
- lett
- redigering
- Effektiv
- effektivt
- eliminere
- innebygd
- ansette
- Motor
- Motorer
- forbedre
- styrke
- sikre
- sikrer
- Miljø
- feil
- spesielt
- essens
- etc
- Eter (ETH)
- Selv
- utvikle seg
- nøyaktig
- eksempel
- utgifter
- erfaring
- utforsket
- ekstra
- forenkler
- Trekk
- Egenskaper
- felt
- Felt
- filet
- Filer
- filtrere
- filtrering
- Finn
- finne
- funn
- Fokus
- fulgt
- etter
- Til
- fra
- funksjonalitet
- framtid
- hull
- gif
- Gi
- glass
- skje
- Ha
- å ha
- hode
- hodepine
- hjelpe
- nyttig
- her.
- høyere
- historie
- Hvordan
- Men
- http
- HTTPS
- ICON
- identiske
- if
- ignorere
- forbedre
- forbedringer
- forbedrer
- bedre
- in
- manglende evne
- industri
- informasjon
- informasjonsteknologi
- iboende
- initiere
- f.eks
- integrering
- samhandle
- interaksjon
- interaksjoner
- Interface
- intern
- inn
- Introduserer
- Introduksjon
- intuitiv
- uvurderlig
- Øya
- utstedelse
- IT
- varer
- DET ER
- sjargong
- Java
- bli medlem
- Hold
- holde
- kunnskap
- maling
- Språk
- føre
- Fører
- LÆRE
- læring
- mindre
- la
- Nivå
- utnytte
- i likhet med
- Begrenset
- Liste
- leve
- plassering
- Se
- ser
- UTSEENDE
- Lot
- maskin
- maskinlæring
- vedlikeholde
- opprettholder
- gjøre
- GJØR AT
- Making
- administrer
- ledelse
- mange
- Match
- Kan..
- møte
- Minne
- bare
- metodikk
- metoder
- kunne
- minimal
- ML
- modell
- Moderne
- mer
- Videre
- mest
- mye
- Trenger
- behov
- neste
- Merknader
- skyggelegging
- Antall
- of
- tilby
- ofte
- on
- gang
- ONE
- bare
- betjene
- operasjonell
- Drift
- operatører
- optimalisering
- or
- organisasjons
- organisasjoner
- Annen
- andre
- vår
- ut
- enn
- egen
- side
- sider
- Spesielt
- spesielt
- Past
- Ansatte
- utføre
- Personlig
- Sted
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Populær
- potensielt
- praksis
- trekker
- trekkes
- presentere
- primært
- privatliv
- prosess
- produktivitet
- Produkter
- Programmering
- prosjekt
- prosjekter
- fremmer
- gi
- gir
- gi
- spørsmål
- spørsmål
- område
- rangert
- RE
- Lesning
- klar
- sanntids
- nylig
- gjenkjenne
- redusere
- avgrense
- raffinert
- i slekt
- Relasjoner
- relevant
- rapporterer
- representere
- Ressurser
- henseender
- Resultater
- rettigheter
- rennende
- s
- samme
- tilfredshet
- besparende
- sier
- Søk
- søkemotor
- Søkemotorer
- søk
- søker
- Seksjon
- sikkerhet
- se
- server
- Del
- bør
- Vis
- betydelig
- lignende
- Enkelt
- ganske enkelt
- nettstedet
- slakk
- So
- løsning
- Solutions
- noen
- noen ganger
- mellomrom
- spesifikk
- SQL
- Staff
- står
- stammer
- Stopp
- lagring
- rett fram
- effektivisere
- strømlinjeformet
- strukturer
- foreslår
- Støtter
- ment
- Bytte om
- syntaks
- system
- skreddersydd
- Oppgave
- lag
- teamarbeid
- Teknologi
- vilkår
- Det
- De
- Dem
- deretter
- derved
- Disse
- de
- denne
- De
- Gjennom
- Dermed
- tid
- Tittel
- til
- i dag
- sammen
- i morgen
- verktøy
- topp
- Tema
- spor
- Sporing
- tradisjonelle
- transformative
- tutorial
- to
- typen
- typer
- etter
- forstå
- forståelse
- forstår
- enhetlig
- unix
- I motsetning til
- oppdatert
- bruke
- brukt
- Bruker
- brukersentrisk
- brukervennlig
- Brukere
- ved hjelp av
- bruke
- benyttes
- ulike
- av
- Vimeo
- synlig
- var
- Vei..
- we
- Hva
- når
- hvilken
- mens
- HVEM
- vil
- med
- innenfor
- uten
- ord
- ord
- Arbeid
- arbeide sammen
- X
- du
- Din
- zephyrnet