I dagens datadrevne forretningsmiljø står organisasjoner overfor utfordringen med å effektivt forberede og transformere store mengder data for analyse- og datavitenskapsformål. Bedrifter må bygge datavarehus og datainnsjøer basert på driftsdata. Dette er drevet av behovet for å sentralisere og integrere data som kommer fra ulike kilder.
Samtidig stammer driftsdata ofte fra applikasjoner støttet av eldre datalagre. Modernisering av applikasjoner krever en mikrotjenestearkitektur, som igjen nødvendiggjør konsolidering av data fra flere kilder for å konstruere et operativt datalager. Uten modernisering kan eldre applikasjoner pådra seg økende vedlikeholdskostnader. Modernisering av applikasjoner innebærer å endre den underliggende databasemotoren til en moderne dokumentbasert database som MongoDB.
Disse to oppgavene (bygge datainnsjøer eller datavarehus og applikasjonsmodernisering) involverer databevegelse, som bruker en prosess for uttrekk, transformasjon og lasting (ETL). ETL-jobben er en nøkkelfunksjonalitet for å ha en godt strukturert prosess for å lykkes.
AWS Lim er en serverløs dataintegrasjonstjeneste som gjør det enkelt å oppdage, forberede, flytte og integrere data fra flere kilder for analyse, maskinlæring (ML) og applikasjonsutvikling. MongoDB Atlas er en integrert pakke med skydatabaser og datatjenester som kombinerer transaksjonsbehandling, relevansbasert søk, sanntidsanalyse og mobil-til-sky-datasynkronisering i en elegant og integrert arkitektur.
Ved å bruke AWS Glue med MongoDB Atlas kan organisasjoner strømlinjeforme ETL-prosessene sine. Med sin fullt administrerte, skalerbare og sikre databaseløsning gir MongoDB Atlas et fleksibelt og pålitelig miljø for lagring og administrasjon av driftsdata. Sammen er AWS Glue ETL og MongoDB Atlas en kraftig løsning for organisasjoner som ønsker å optimalisere hvordan de bygger datainnsjøer og datavarehus, og for å modernisere applikasjonene sine, for å forbedre forretningsytelsen, redusere kostnadene og drive vekst og suksess.
I dette innlegget viser vi hvordan du overfører data fra Amazon enkel lagringstjeneste (Amazon S3)-bøtter til MongoDB Atlas ved hjelp av AWS Glue ETL, og hvordan trekke ut data fra MongoDB Atlas til en Amazon S3-basert datainnsjø.
Løsningsoversikt
I dette innlegget utforsker vi følgende brukstilfeller:
- Trekker ut data fra MongoDB – MongoDB er en populær database som brukes av tusenvis av kunder til å lagre applikasjonsdata i stor skala. Bedriftskunder kan sentralisere og integrere data som kommer fra flere datalagre ved å bygge datainnsjøer og datavarehus. Denne prosessen innebærer å trekke ut data fra de operative datalagrene. Når dataene er på ett sted, kan kundene raskt bruke dem til forretningsinformasjonsbehov eller for ML.
- Innføring av data i MongoDB – MongoDB fungerer også som en ikke-SQL-database for å lagre applikasjonsdata og bygge driftsdatalagre. Modernisering av applikasjoner innebærer ofte migrering av driftslageret til MongoDB. Kunder må trekke ut eksisterende data fra relasjonsdatabaser eller fra flate filer. Mobil- og nettapper krever ofte at dataingeniører bygger datapipelines for å lage en enkelt visning av data i Atlas mens de inntar data fra flere siled kilder. Under denne migreringen må de koble seg sammen med forskjellige databaser for å lage dokumenter. Denne komplekse sammenføyningsoperasjonen ville trenge betydelig engangsberegningskraft. Utviklere må også bygge dette raskt for å migrere dataene.
AWS Glue kommer til nytte i disse tilfellene med betal-som-du-gå-modellen og dens evne til å kjøre komplekse transformasjoner på tvers av enorme datasett. Utviklere kan bruke AWS Glue Studio for å effektivt lage slike datapipelines.
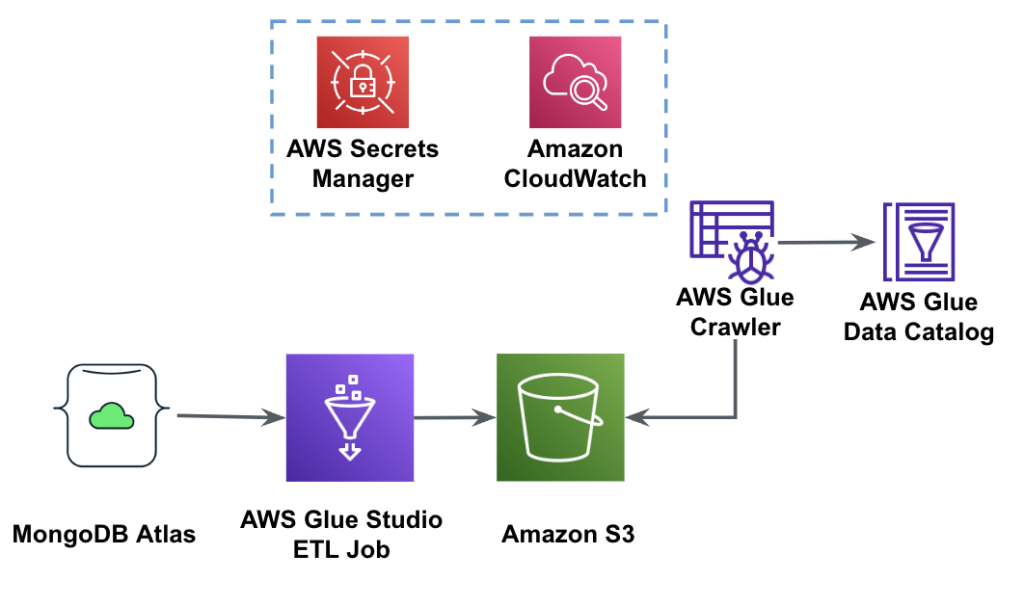
Følgende diagram viser arbeidsflyten for datautvinning fra MongoDB Atlas til en S3-bøtte ved hjelp av AWS Glue Studio.
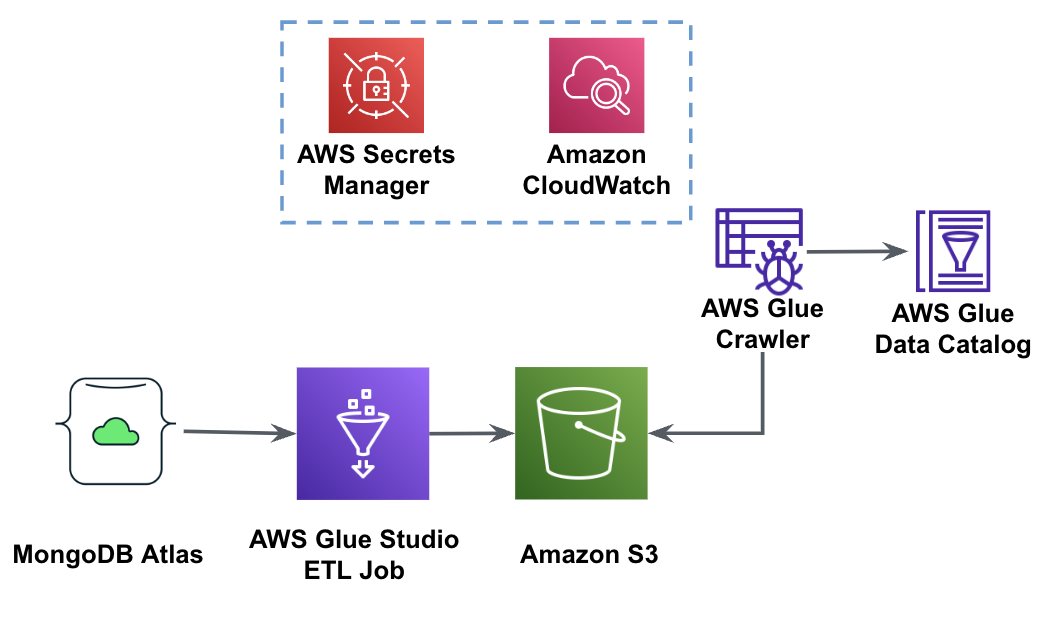
For å implementere denne arkitekturen trenger du en MongoDB Atlas-klynge, en S3-bøtte og en AWS identitets- og tilgangsadministrasjon (IAM) rolle for AWS Glue. For å konfigurere disse ressursene, se de nødvendige trinnene i det følgende GitHub repo.
Følgende figur viser arbeidsflyten for datainnlasting fra en S3-bøtte til MongoDB Atlas ved bruk av AWS Glue.
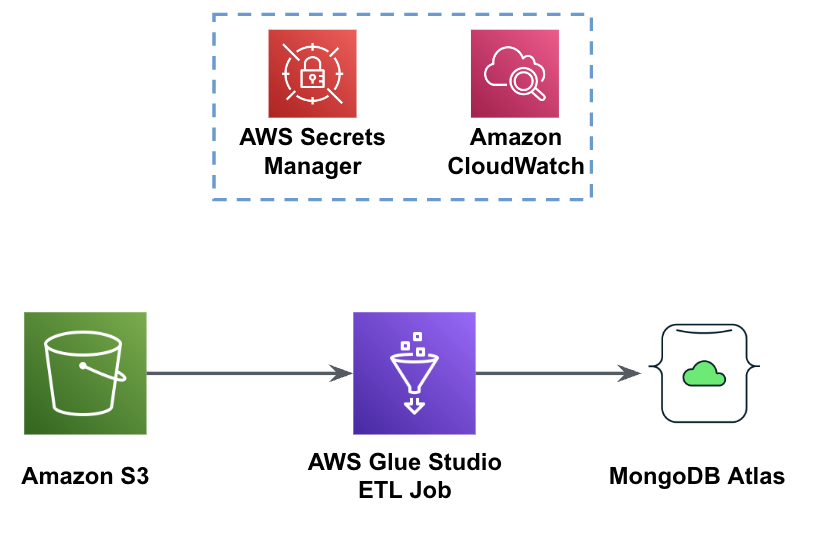
De samme forutsetningene er nødvendige her: en S3-bøtte, IAM-rolle og en MongoDB Atlas-klynge.
Last inn data fra Amazon S3 til MongoDB Atlas ved hjelp av AWS Glue
De følgende trinnene beskriver hvordan du laster data fra S3-bøtten til MongoDB Atlas ved hjelp av en AWS-limjobb. Utvinningsprosessen fra MongoDB Atlas til Amazon S3 er veldig lik, med unntak av skriptet som brukes. Vi nevner forskjellene mellom de to prosessene.
- Opprett en gratis klynge i MongoDB Atlas.
- Last opp eksempel JSON-fil til din S3-bøtte.
- Opprett en ny AWS Glue Studio-jobb med Spark script editor alternativet.

- Avhengig av om du vil laste eller trekke ut data fra MongoDB Atlas-klyngen, skriv inn last script or trekke ut skript i AWS Glue Studio manusredigering.
Følgende skjermbilde viser en kodebit for å laste data inn i MongoDB Atlas-klyngen.

Koden bruker AWS Secrets Manager for å hente MongoDB Atlas-klyngenavnet, brukernavnet og passordet. Deretter skaper det en DynamicFrame for S3-bøtten og filnavnet som ble sendt til skriptet som parametere. Koden henter database- og samlingsnavnene fra jobbparameterkonfigurasjonen. Til slutt skriver koden DynamicFrame til MongoDB Atlas-klyngen ved å bruke de hentede parameterne.
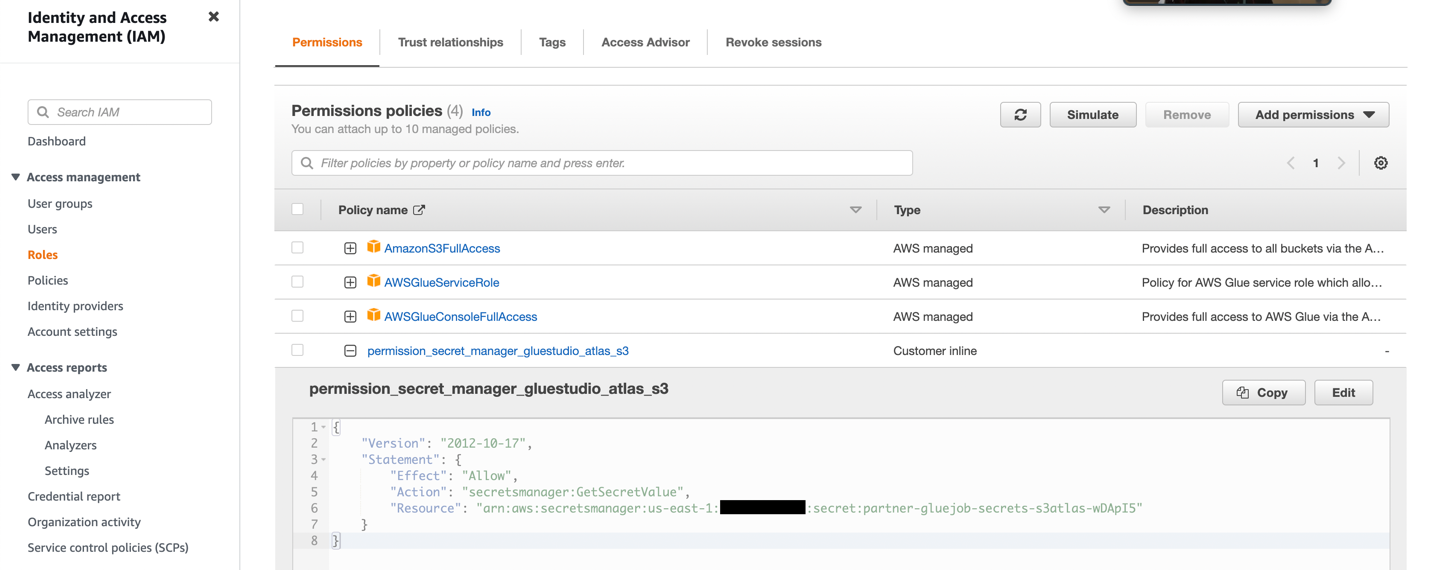
- Opprett en IAM-rolle med tillatelsene som vist i følgende skjermbilde.
For mer informasjon, se Konfigurer en IAM-rolle for ETL-jobben din.
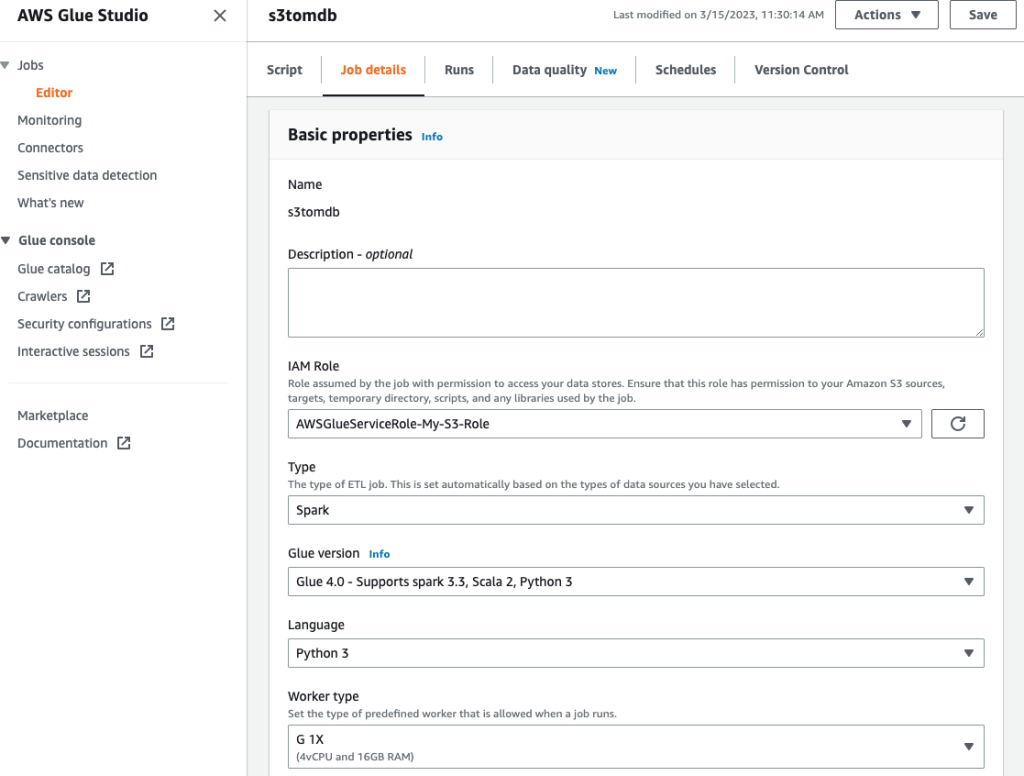
- Gi jobben et navn og oppgi IAM-rollen som ble opprettet i forrige trinn på Jobbdetaljer fanen.
- Du kan la resten av parameterne være standard, som vist i de følgende skjermbildene.
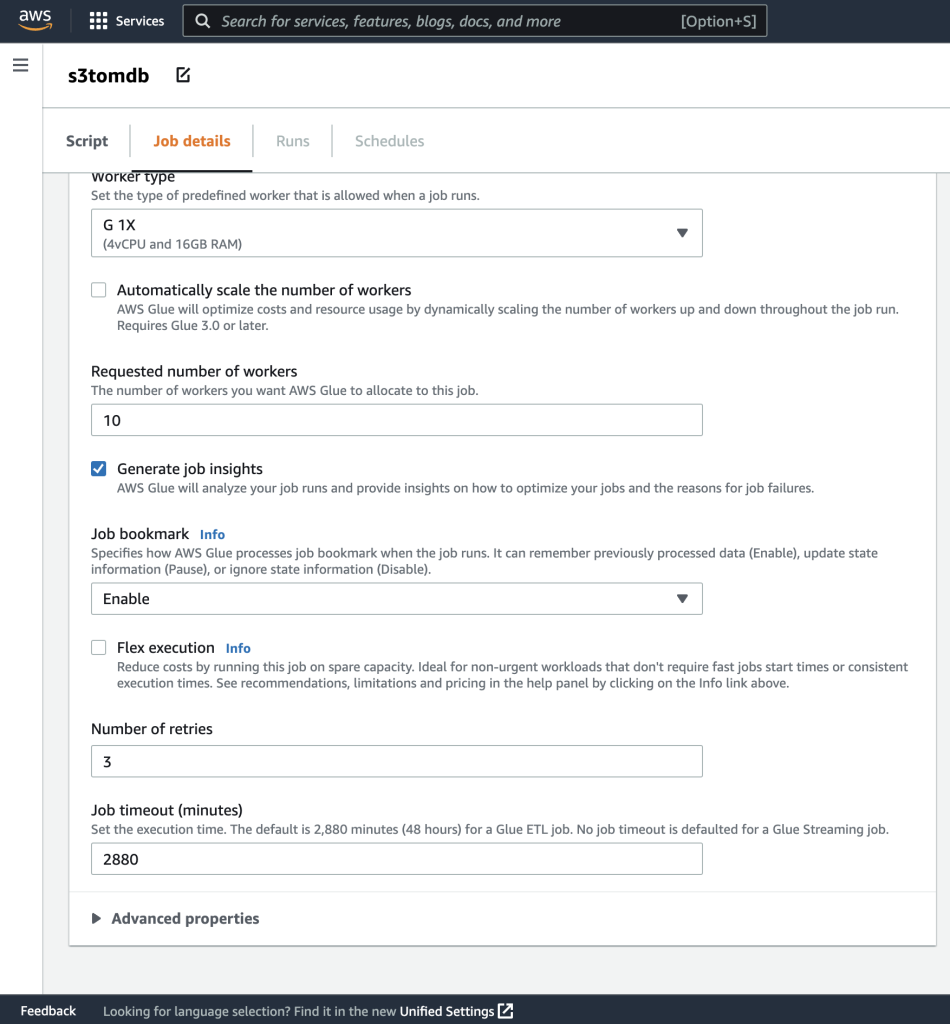
- Deretter definerer du jobbparametrene som skriptet bruker og oppgir standardverdiene.
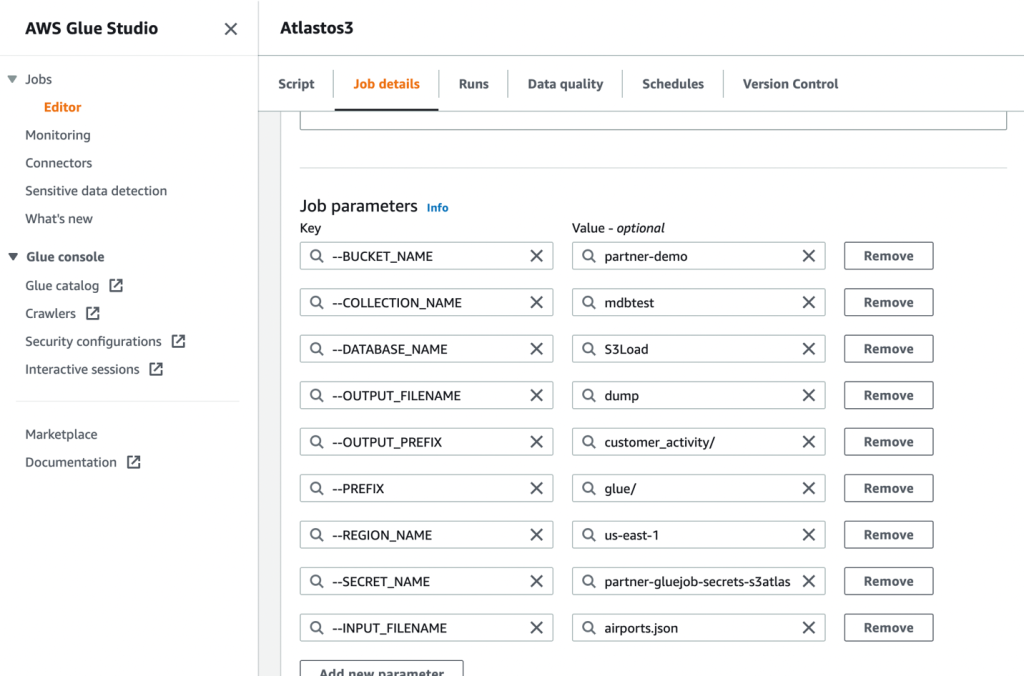
- Lagre jobben og kjør den.
- For å bekrefte en vellykket kjøring, observer innholdet i MongoDB Atlas-databasesamlingen hvis du laster dataene, eller S3-bøtten hvis du utførte et uttrekk.



Følgende skjermbilde viser resultatene av en vellykket datainnlasting fra en Amazon S3-bøtte inn i MongoDB Atlas-klyngen. Dataene er nå tilgjengelige for spørringer i MongoDB Atlas UI.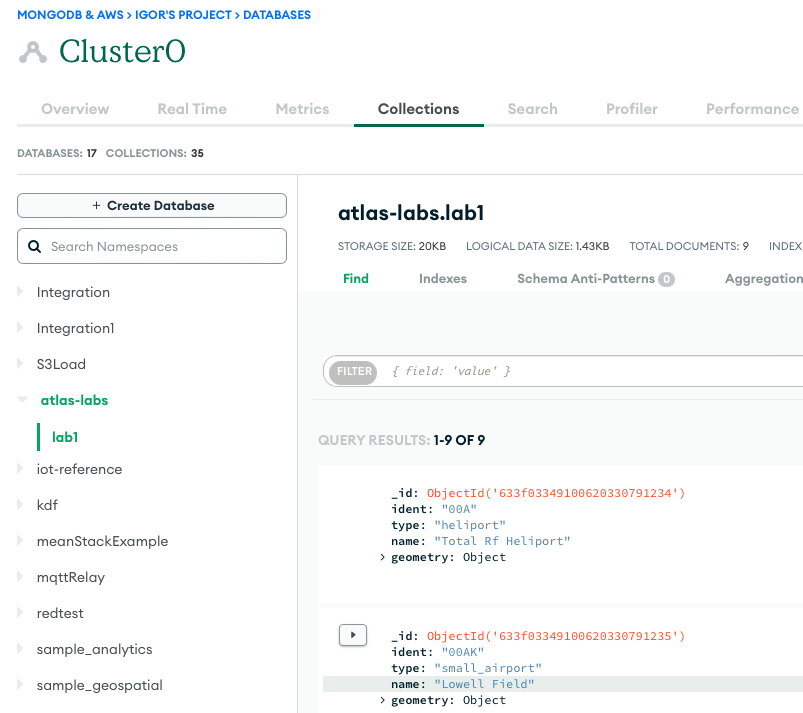
- For å feilsøke løpene dine, se gjennom Amazon CloudWatch logger ved å bruke lenken på jobbens Kjør fanen.
Følgende skjermbilde viser at jobben gikk vellykket, med tilleggsdetaljer som koblinger til CloudWatch-loggene.

konklusjonen
I dette innlegget beskrev vi hvordan du trekker ut og inntar data til MongoDB Atlas ved å bruke AWS Glue.
Med AWS Glue ETL-jobber kan vi nå overføre dataene fra MongoDB Atlas til AWS Glue-kompatible kilder, og omvendt. Du kan også utvide løsningen til å bygge analyser ved hjelp av AWS AI- og ML-tjenester.
For å lære mer, se GitHub repository for trinnvise instruksjoner og eksempelkode. Du kan anskaffe MongoDB Atlas på AWS Marketplace.
Om forfatterne

Igor Alekseev er Senior Partner Solution Architect hos AWS i data- og analysedomene. I sin rolle jobber Igor med strategiske partnere som hjelper dem med å bygge komplekse, AWS-optimaliserte arkitekturer. Før han begynte i AWS, implementerte han som Data/Solution Architect mange prosjekter i Big Data-domenet, inkludert flere datainnsjøer i Hadoop-økosystemet. Som dataingeniør var han involvert i å bruke AI/ML til svindeldeteksjon og kontorautomatisering.
 Babu Srinivasan er Senior Partner Solutions Architect hos MongoDB. I sin nåværende rolle jobber han med AWS for å bygge de tekniske integrasjonene og referansearkitekturene for AWS- og MongoDB-løsningene. Han har mer enn to tiår med erfaring innen database- og skyteknologier. Han brenner for å tilby tekniske løsninger til kunder som arbeider med flere globale systemintegratorer (GSI) på tvers av flere geografier.
Babu Srinivasan er Senior Partner Solutions Architect hos MongoDB. I sin nåværende rolle jobber han med AWS for å bygge de tekniske integrasjonene og referansearkitekturene for AWS- og MongoDB-løsningene. Han har mer enn to tiår med erfaring innen database- og skyteknologier. Han brenner for å tilby tekniske løsninger til kunder som arbeider med flere globale systemintegratorer (GSI) på tvers av flere geografier.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- : har
- :er
- 100
- 11
- a
- evne
- Om oss
- adgang
- tvers
- Ytterligere
- AI
- AI / ML
- også
- Amazon
- beløp
- an
- analytics
- og
- Søknad
- Applikasjonutvikling
- søknader
- påføring
- apps
- arkitektur
- ER
- AS
- At
- atlas
- Automatisering
- tilgjengelig
- AWS
- AWS Lim
- AWS Marketplace
- Backed
- basert
- være
- mellom
- Stor
- Store data
- bygge
- Bygning
- virksomhet
- business intelligence
- forretningsytelse
- bedrifter
- by
- ring
- CAN
- saker
- utfordre
- endring
- Cloud
- Cluster
- kode
- samling
- skurtreskerne
- kommer
- kommer
- komplekse
- Beregn
- Konfigurasjon
- Bekrefte
- konsolidering
- konstruere
- innhold
- fortsatte
- Kostnader
- skape
- opprettet
- skaper
- skaperverket
- Gjeldende
- Kunder
- dato
- dataingeniør
- dataintegrasjon
- Data Lake
- datavitenskap
- datavarehus
- data-drevet
- Database
- databaser
- datasett
- tiår
- Misligholde
- demonstrere
- beskrive
- beskrevet
- detaljer
- Gjenkjenning
- utviklere
- Utvikling
- forskjeller
- forskjellig
- oppdage
- uensartede
- dokumenter
- domene
- stasjonen
- drevet
- under
- økosystem
- redaktør
- effektivt
- Motor
- ingeniør
- Ingeniører
- Enter
- Enterprise
- bedriftskunder
- Miljø
- Eter (ETH)
- unntak
- eksisterende
- erfaring
- utforske
- utvide
- trekke ut
- utdrag
- Face
- Figur
- filet
- Filer
- Endelig
- flate
- fleksibel
- etter
- Til
- svindel
- svindeloppdagelse
- Gratis
- fra
- fullt
- funksjonalitet
- geografier
- Global
- Vekst
- Hadoop
- praktisk
- å ha
- he
- hjelpe
- her.
- hans
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- stort
- IAM
- Identitet
- if
- iverksette
- implementert
- forbedre
- in
- Inkludert
- økende
- inngang
- instruksjoner
- integrere
- integrert
- integrering
- integrasjoner
- Intelligens
- inn
- involvere
- involvert
- IT
- DET ER
- Jobb
- Jobb
- bli medlem
- sammenføyning
- JSON
- nøkkel
- innsjø
- stor
- LÆRE
- læring
- Permisjon
- Legacy
- i likhet med
- LINK
- lenker
- laste
- lasting
- ser
- maskin
- maskinlæring
- vedlikehold
- GJØR AT
- fikk til
- administrerende
- mange
- markedsplass
- Kan..
- migrere
- migrasjon
- ML
- Mobil
- modell
- Moderne
- modernisering
- modern
- MongoDB
- mer
- flytte
- bevegelse
- flere
- navn
- navn
- Trenger
- nødvendig
- behov
- Ny
- nå
- observere
- of
- Office
- ofte
- on
- ONE
- drift
- operasjonell
- Optimalisere
- Alternativ
- or
- rekkefølge
- organisasjoner
- ut
- parametere
- partner
- partnere
- bestått
- lidenskapelig
- Passord
- ytelse
- utfører
- tillatelser
- Sted
- plato
- Platon Data Intelligence
- PlatonData
- Populær
- Post
- makt
- kraftig
- Forbered
- forbereder
- forutsetninger
- forrige
- Før
- prosess
- Prosesser
- prosessering
- prosjekter
- gir
- gi
- formål
- spørsmål
- raskt
- sanntids
- redusere
- pålitelig
- krever
- Krever
- Ressurser
- REST
- Resultater
- anmeldelse
- Rolle
- Kjør
- samme
- skalerbar
- Skala
- Vitenskap
- skjermbilder
- Søk
- sikre
- senior
- server~~POS=TRUNC
- serverer
- tjeneste
- Tjenester
- flere
- vist
- Viser
- signifikant
- lignende
- Enkelt
- enkelt
- løsning
- Solutions
- Kilder
- Trinn
- Steps
- lagring
- oppbevare
- butikker
- rett fram
- Strategisk
- strategiske partnere
- effektivisere
- studio
- lykkes
- suksess
- vellykket
- vellykket
- slik
- suite
- levere
- synkronisering
- system
- oppgaver
- Teknisk
- Technologies
- enn
- Det
- De
- deres
- Dem
- deretter
- Disse
- de
- denne
- tusener
- tid
- til
- dagens
- sammen
- transaksjonell
- overføre
- Transform
- transformasjoner
- transformere
- SVING
- to
- ui
- underliggende
- bruke
- brukt
- Bruker
- ved hjelp av
- Verdier
- veldig
- Se
- ønsker
- var
- we
- web
- var
- når
- om
- hvilken
- mens
- vil
- med
- uten
- arbeidsflyt
- arbeid
- ville
- du
- Din
- zephyrnet