
Bilde av forfatter
Mens vi analyserer dataene, er tingen i tankene våre å finne skjulte mønstre og trekke ut meningsfull innsikt. La oss gå inn i den nye kategorien ML-basert læring, dvs. uovervåket læring, der en av de kraftige algoritmene for å løse klyngeoppgavene er K-Means klyngealgoritmen som revolusjonerer dataforståelsen.
K-Means har blitt en nyttig algoritme i applikasjoner for maskinlæring og datautvinning. I denne artikkelen vil vi dykke dypt inn i funksjonene til K-Means, implementeringen ved hjelp av Python, og utforske prinsippene, applikasjonene osv. Så la oss starte reisen for å låse opp de hemmelige mønstrene og utnytte potensialet til K-Means klyngealgoritme.
K-Means-algoritmen brukes til å løse klyngeproblemene som tilhører læringsklassen uten tilsyn. Ved hjelp av denne algoritmen kan vi gruppere antall observasjoner i K-klynger.
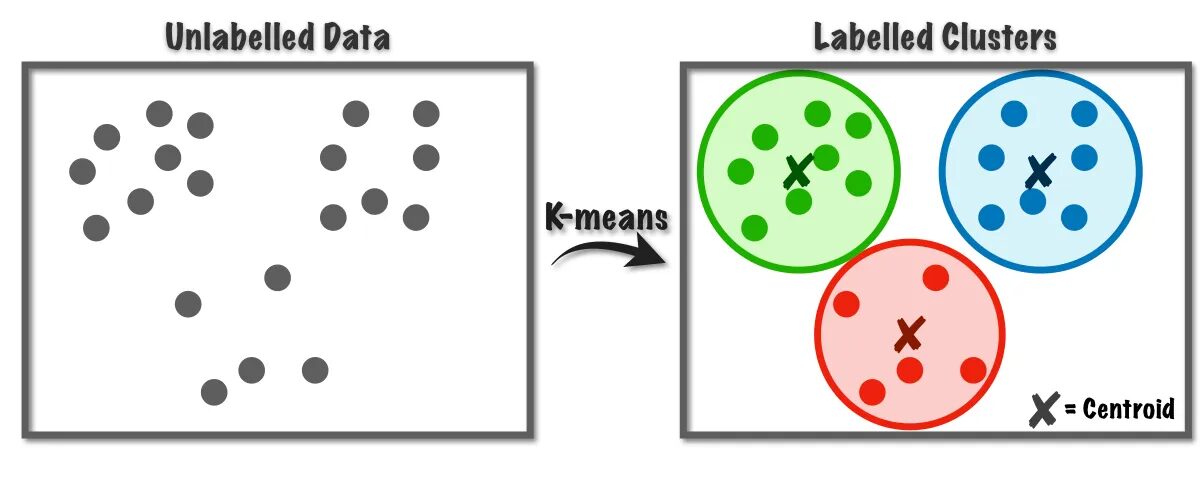
Fig.1 K-Means-algoritmen fungerer | Bilde fra Mot datavitenskap
Denne algoritmen bruker internt vektorkvantisering, der vi kan tilordne hver observasjon i datasettet til klyngen med minimumsavstanden, som er prototypen til klyngealgoritmen. Denne klyngealgoritmen brukes ofte i datautvinning og maskinlæring for datapartisjonering i K-klynger basert på likhetsmålinger. Derfor, i denne algoritmen, må vi minimere summen av kvadraters avstand mellom observasjonene og deres tilsvarende tyngdepunkt, noe som til slutt resulterer i distinkte og homogene klynger.
Anvendelser av K-betyr Clustering
Her er noen av standardapplikasjonene til denne algoritmen. K-means-algoritmen er en ofte brukt teknikk i industrielle brukstilfeller for å løse grupperelaterte problemer.
- Kundesegmentering: K-means clustering kan segmentere ulike kunder basert på deres interesser. Det kan brukes til bank, telekom, e-handel, sport, reklame, salg, etc.
- Dokumentklynger: I denne teknikken vil vi klubbe lignende dokumenter fra et sett med dokumenter, noe som resulterer i lignende dokumenter i samme klynger.
- Anbefalingsmotorer: Noen ganger kan K-betyr clustering brukes til å lage anbefalingssystemer. For eksempel vil du anbefale sanger til vennene dine. Du kan se på sangene den personen liker, og deretter bruke clustering for å finne lignende sanger og anbefale de mest like.
Det er mange flere applikasjoner som jeg er sikker på at du allerede har tenkt på, som du sannsynligvis deler i kommentarfeltet under denne artikkelen.
I denne delen vil vi begynne å implementere K-Means-algoritmen på et av datasettene ved hjelp av Python, hovedsakelig brukt i Data Science-prosjekter.
1. Importer nødvendige biblioteker og avhengigheter
Først, la oss importere python-bibliotekene vi bruker for å implementere K-means-algoritmen, inkludert NumPy, Pandas, Seaborn, Marplotlib, etc.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. Last inn og analyser datasettet
I dette trinnet vil vi laste studentdatasettet ved å lagre det i Pandas-datarammen. For å laste ned datasettet kan du se lenken her..
Den komplette rørledningen for problemet er vist nedenfor:

Fig. 2 Prosjekt Pipeline | Bilde av forfatter
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. Spredningsplott for datasettet
Nå kommer trinnet med modellering er å visualisere dataene, så vi bruker matplotlib til å tegne spredningsplottet for å sjekke hvordan klyngealgoritmen fungerer og lage forskjellige klynger.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
Utgang:
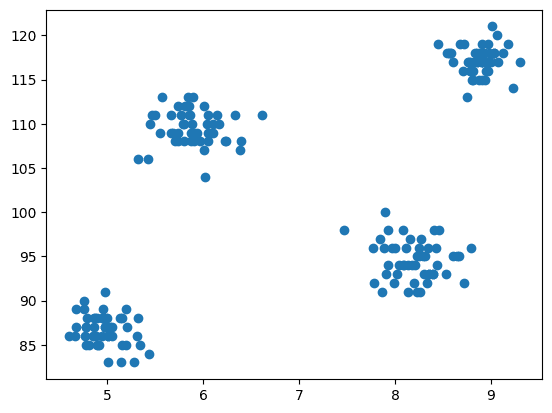
Fig.3 Spredningsplott | Bilde av forfatter
4. Importer K-Means fra Cluster Class of Scikit-learn
Nå, ettersom vi må implementere K-Means-klynger, importerer vi først klyngeklassen, og så har vi KMeans som modulen til den klassen.
from sklearn.cluster import KMeans5. Finne den optimale verdien av K ved hjelp av albuemetoden
I dette trinnet vil vi finne den optimale verdien av K, en av hyperparametrene, mens vi implementerer algoritmen. K-verdien angir hvor mange klynger vi må opprette for datasettet vårt. Å finne denne verdien intuitivt er ikke mulig, så for å finne den optimale verdien, skal vi lage et plott mellom WCSS(innen-klynge-sum-av-kvadrater) og forskjellige K-verdier, og vi må velge den K, som gir oss minimumsverdien av WCSS.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
La oss nå plotte albueplottet for å finne den optimale verdien av K.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
Utgang:
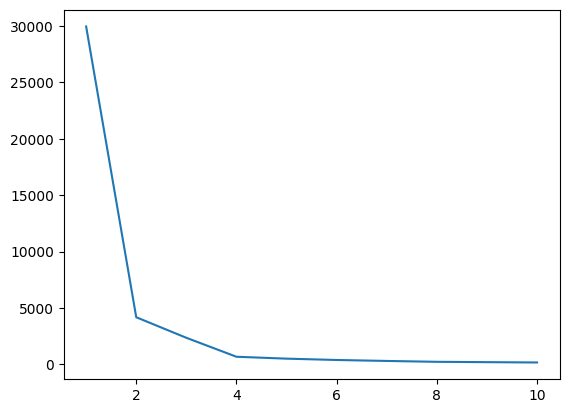
Fig.4 Albueplott | Bilde av forfatter
Fra albueplottet ovenfor kan vi se ved K=4; det er et fall i verdien til WCSS, noe som betyr at hvis vi bruker den optimale verdien som 4, vil i så fall clustering gi deg en god ytelse.
6. Tilpass K-Means-algoritmen med den optimale verdien av K
Vi er ferdige med å finne den optimale verdien av K. La oss nå gjøre modelleringen der vi skal lage en X-matrise som lagrer hele datasettet med alle funksjonene. Det er ikke nødvendig å skille mål- og trekkvektoren her, siden det er et problem uten tilsyn. Etter det vil vi lage et objekt av KMeans-klassen med en valgt K-verdi og deretter tilpasse det til datasettet som er gitt. Til slutt skriver vi ut y_means, som indikerer midlene til forskjellige klynger som er dannet.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. Sjekk klyngetilordningen for hver kategori
La oss sjekke hvilke alle punktene i datasettet som tilhører hvilken klynge.
X[y_means == 3,1]
Til nå, for tyngdepunktinitialisering, har vi brukt K-Means++-strategien, nå, la oss initialisere de tilfeldige centroidene i stedet for K-Means++ og sammenligne resultatene ved å følge den samme prosessen.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
Sjekk hvor mange verdier som samsvarer.
sum(y_means == y_means_new)8. Visualisere klyngene
For å visualisere hver klynge, plotter vi dem på aksene og tildeler forskjellige farger som vi enkelt kan se 4 klynger dannet gjennom.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
Utgang:
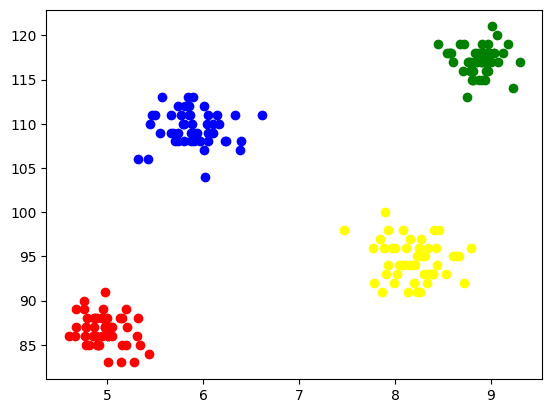
Fig. 5 Visualisering av dannede klynger | Bilde av forfatter
9. K-Means på 3D-data
Siden forrige datasett har 2 kolonner, har vi et 2D-problem. Nå vil vi bruke det samme settet med trinn for et 3D-problem og prøve å analysere kodereproduserbarheten for n-dimensjonale data.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
Utgang:
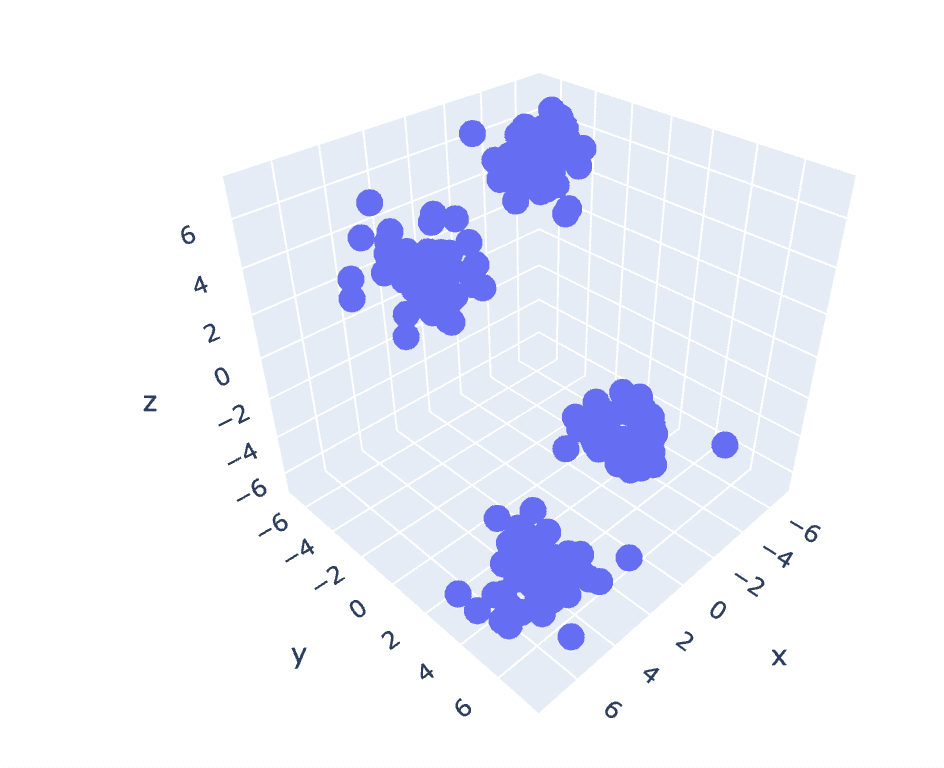
Fig. 6 Spredningsplott for 3D-datasett | Bilde av forfatter
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
Utgang:

Fig.7 Albueplott | Bilde av forfatter
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
Utgang:
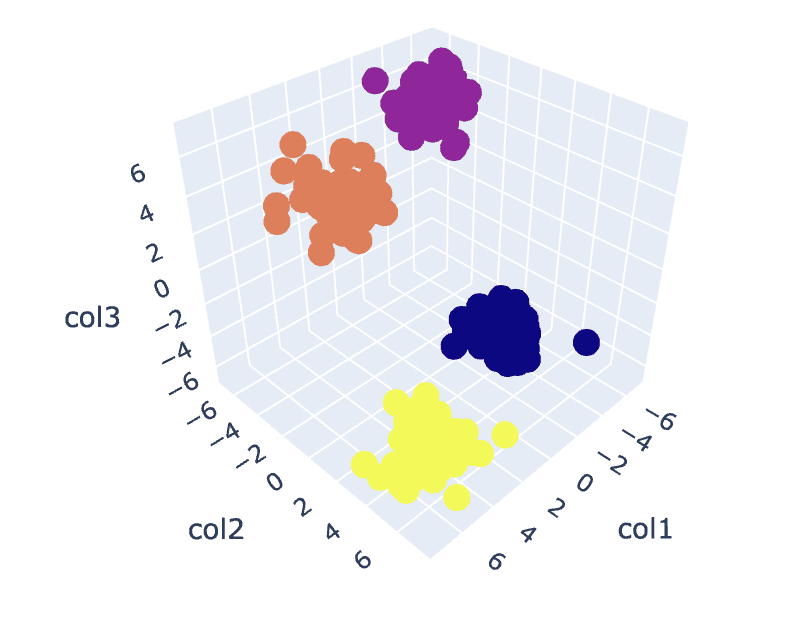
Fig.8. Klynger visualisering | Bilde av forfatter
Du finner hele koden her – Colab notatbok
Dette fullfører vår diskusjon. Vi har diskutert K-Means-arbeid, implementering og applikasjoner. Avslutningsvis er implementering av klyngeoppgavene en mye brukt algoritme fra klassen for uovervåket læring som gir en enkel og intuitiv tilnærming til å gruppere observasjonene til et datasett. Hovedstyrken til denne algoritmen er å dele opp observasjonene i flere sett basert på de valgte likhetsmålingene ved hjelp av brukeren som implementerer algoritmen.
Basert på valget av sentroider i det første trinnet, oppfører algoritmen vår seg annerledes og konvergerer til lokale eller globale optima. Derfor er det avgjørende å velge antall klynger for å implementere algoritmen, forhåndsbehandle dataene, håndtere uteliggere osv. for å oppnå gode resultater. Men hvis vi observerer den andre siden av denne algoritmen bak begrensningene, er K-Means en nyttig teknikk for utforskende dataanalyse og mønstergjenkjenning på ulike felt.
Ariske Garg er en B.Tech. Elektroingeniørstudent, går for tiden siste året av undergraden. Hans interesse ligger innen webutvikling og maskinlæring. Han har fulgt denne interessen og er ivrig etter å jobbe mer i disse retningene.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- : har
- :er
- :ikke
- :hvor
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- ovenfor
- Annonsering
- Etter
- algoritme
- algoritmer
- Alle
- allerede
- am
- an
- analysere
- analyse
- analysere
- analyserer
- og
- søknader
- anvendt
- tilnærming
- ER
- Array
- Artikkel
- AS
- At
- AKSER
- b
- Banking
- basert
- BE
- bli
- bak
- under
- mellom
- Blå
- Bygning
- men
- by
- CAN
- saken
- saker
- Kategori
- sjekk
- Velg
- klasse
- klubb
- Cluster
- gruppering
- kode
- kolonner
- kommer
- kommentarer
- vanligvis
- sammenligne
- fullføre
- Fullfører
- konklusjon
- Tilsvarende
- skape
- avgjørende
- I dag
- kunde
- Kunder
- dato
- dataanalyse
- data mining
- datavitenskap
- datasett
- dyp
- dypdykk
- Utvikling
- forskjellig
- Dypp
- retninger
- diskutert
- diskusjon
- avstand
- distinkt
- do
- dokument
- dokumenter
- gjort
- nedlasting
- tegne
- e
- e-handel
- hver enkelt
- ivrig
- lett
- elektroteknikk
- Ingeniørarbeid
- Motorer
- Enter
- etc
- etter hvert
- eksempel
- Utforskende dataanalyse
- Utforske
- ekspress
- trekke ut
- Trekk
- Egenskaper
- felt
- Felt
- Fiken
- slutt~~POS=TRUNC
- Endelig
- Finn
- finne
- Først
- passer
- etter
- Til
- dannet
- venner
- fra
- Gi
- gir
- Global
- skal
- god
- Grønn
- Gruppe
- Håndtering
- seletøy
- Ha
- å ha
- he
- hjelpe
- nyttig
- her.
- skjult
- hans
- Hvordan
- HTTPS
- i
- if
- bilde
- iverksette
- gjennomføring
- implementere
- importere
- in
- Inkludert
- indikerer
- industriell
- treghet
- innsikt
- i stedet
- interesse
- interesser
- internt
- inn
- intuitiv
- IT
- DET ER
- reise
- jpg
- KDnuggets
- Etiketten
- læring
- bibliotekene
- ligger
- begrensninger
- LINK
- Liste
- laste
- lokal
- Se
- maskin
- maskinlæring
- Hoved
- hovedsakelig
- gjøre
- mange
- Match
- matplotlib
- meningsfylt
- midler
- Metrics
- tankene
- minimum
- Gruvedrift
- modell
- modellering
- moduler
- mer
- mest
- flere
- må
- nødvendig
- Trenger
- Ny
- Nei.
- nå
- Antall
- følelsesløs
- objekt
- observere
- få
- of
- on
- ONE
- seg
- optimal
- or
- Annen
- vår
- pandaer
- passere
- Mønster
- mønstre
- ytelse
- person
- rørledning
- plato
- Platon Data Intelligence
- PlatonData
- poeng
- mulig
- potensiell
- kraftig
- forrige
- prinsipper
- Skrive ut
- sannsynligvis
- Problem
- problemer
- prosess
- prosjekt
- prosjekter
- prototype
- forutsatt
- gir
- Python
- tilfeldig
- anerkjennelse
- anbefaler
- Anbefaling
- Rød
- forskning
- resulterende
- Resultater
- revolusjonerer
- s
- salg
- samme
- Vitenskap
- sjøfødt
- Secret
- Seksjon
- se
- segmentet
- segmentering
- valgt
- velge
- utvalg
- separat
- sett
- sett
- Form
- Del
- vist
- side
- betyr
- lignende
- Enkelt
- So
- LØSE
- løse
- noen
- Sports
- firkanter
- Standard
- Begynn
- Trinn
- Steps
- oppbevare
- butikker
- Strategi
- styrke
- Student
- sikker
- syntetisk
- Systemer
- Target
- oppgaver
- tech
- telekom
- Det
- De
- deres
- Dem
- deretter
- Der.
- derfor
- Disse
- ting
- denne
- trodde
- Gjennom
- til
- prøve
- forståelse
- sluppet løs
- låse opp
- uovervåket læring
- us
- bruke
- brukt
- Bruker
- bruker
- ved hjelp av
- bruke
- verdi
- Verdier
- ulike
- visualisering
- vs
- ønsker
- we
- web
- Webutvikling
- hvilken
- mens
- HVEM
- allment
- vil
- med
- Arbeid
- arbeid
- hjemkomsten
- virker
- X
- år
- gul
- du
- Din
- zephyrnet








