Velkommen til datatiden. Selve volumet av data som fanges opp daglig, fortsetter å vokse, og krever plattformer og løsninger for å utvikle seg. Tjenester som f.eks Amazon enkel lagringstjeneste (Amazon S3) tilbyr en skalerbar løsning som tilpasser seg, men fortsatt er kostnadseffektiv for voksende datasett. De Amazon Sustainability Data Initiative (ASDI) bruker egenskapene til Amazon S3 for å tilby en gratis løsning for deg å lagre og dele klimavitenskapelige arbeidsmengder over hele verden. Amazons Open Data Sponsorship Program lar organisasjoner være vert for gratis på AWS.
I løpet av det siste tiåret har vi sett en økning i rammeverk for datavitenskap som kommer til utførelse, sammen med masseadopsjon av datavitenskapssamfunnet. Et slikt rammeverk er CBE, som er kraftig for sin evne til å sørge for en orkestrering av arbeiderberegningsnoder, og dermed akselerere kompleks analyse på store datasett.
I dette innlegget viser vi deg hvordan du implementerer en tilpasset AWS skyutviklingssett (AWS CDK) løsning som utvider Dasks funksjonalitet til å fungere interregionalt på tvers av Amazons globale nettverk. AWS CDK-løsningen distribuerer et nettverk av Dask-arbeidere på tvers av to AWS-regioner, og kobles til en klientregion. For mer informasjon, se Veiledning for distribuert databehandling med Cross Regional Dask på AWS og GitHub repo for åpen kildekode.
Etter distribusjon vil brukeren ha tilgang til en Jupyter-notisbok, der de kan samhandle med to datasett fra ASDI på AWS: Coupled Model Intercomparison Project 6 (CMIP6) og ECMWF ERA5 reanalyse. CMIP6 fokuserer på den sjette fasen av globalt koplet hav-atmosfære generell sirkulasjonsmodellensemble; ERA5 er den femte generasjonen av ECMWF atmosfæriske reanalyser av det globale klimaet, og den første reanalysen produsert som en operativ tjeneste.
Denne løsningen ble inspirert av arbeid med en nøkkelkunde fra AWS, The UK Met Office. The Met Office ble grunnlagt i 1854 og er den nasjonale meteorologiske tjenesten for Storbritannia. De gir vær- og klimaspådommer for å hjelpe deg med å ta bedre beslutninger for å holde deg trygg og trives. Et samarbeid mellom Met Office og EUMETSAT, detaljert i Datanær beregning på en Dask-klynge distribuert mellom datasentre, fremhever det økende behovet for å utvikle en bærekraftig, effektiv og skalerbar datavitenskapelig løsning. Denne løsningen oppnår dette ved å bringe databehandling nærmere dataene, i stedet for å tvinge dataene til å komme nærmere dataressursene, noe som øker kostnadene, ventetiden og energien.
Løsningsoversikt
Hver dag produserer UK Met Office opptil 300 TB vær- og klimadata, hvorav en del publiseres til ASDI. Disse datasettene er distribuert over hele verden og vert for offentlig bruk. Met Office ønsker å gjøre det mulig for forbrukere å få mest mulig ut av dataene sine for å hjelpe til med å informere kritiske beslutninger om å håndtere problemer som bedre forberedelse for klimaendringer-induserte skogbranner og flom, og redusere matusikkerhet gjennom bedre avlingsavlingsanalyse.
Tradisjonelle løsninger som brukes i dag, spesielt med klimadata, er tidkrevende og uholdbare, og replikerer datasett på tvers av regioner. Unødvendig dataoverføring på petabyte-skalaen er kostbar, treg og bruker energi.
Vi estimerte at hvis denne praksisen ble tatt i bruk av Met Office-brukerne, kunne tilsvarende 40 hjems daglige strømforbruk spares hver dag, og de kunne også redusere overføringen av data mellom regioner.
Følgende diagram illustrerer løsningsarkitekturen.
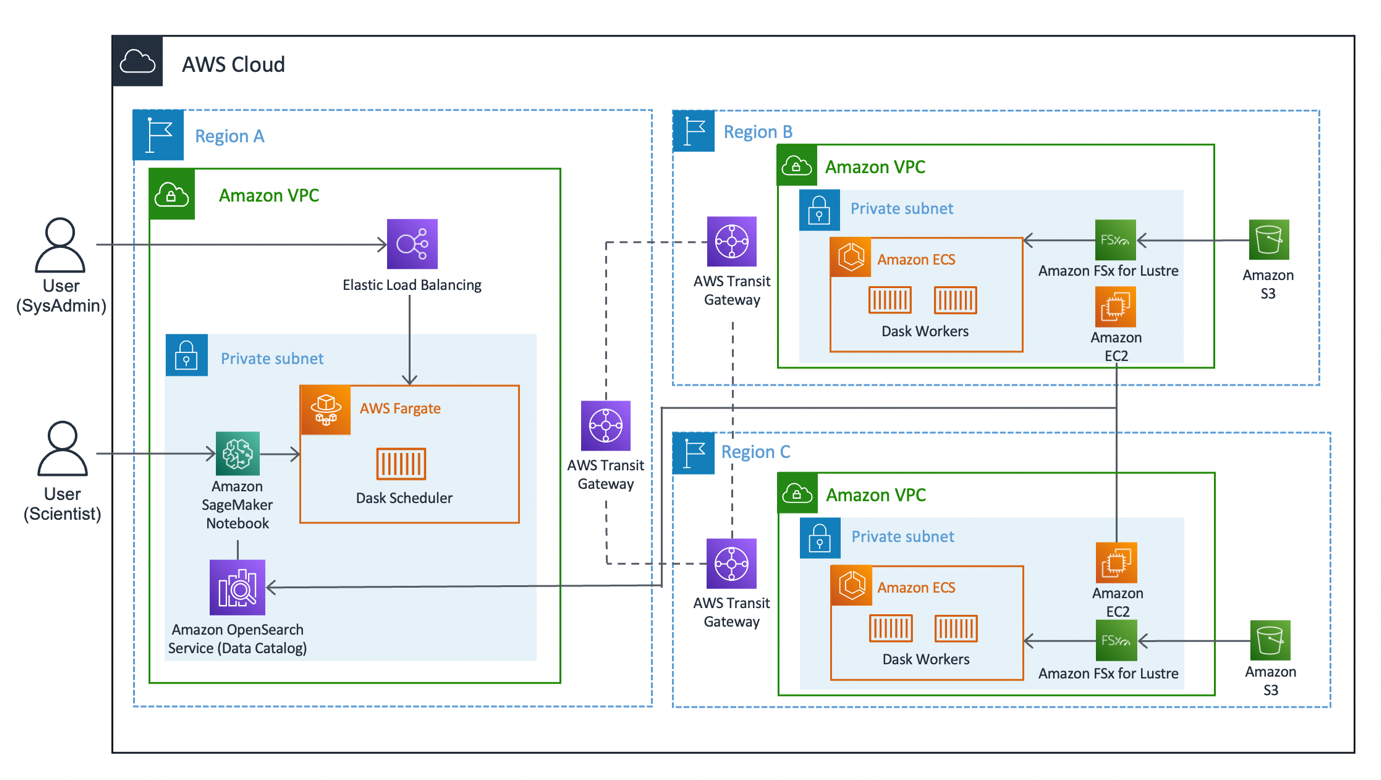
Løsningen kan deles inn i tre hovedsegmenter: klient, arbeidere og nettverk. La oss dykke ned i hver og se hvordan de kommer sammen.
kunde
Klienten representerer kilderegionen der dataforskere kobler til. Denne regionen (Region A i diagrammet) inneholder en Amazon SageMaker notatbok, En Amazon OpenSearch-tjeneste domene, og en Dask planlegger som nøkkelkomponenter. Systemadministratorer har tilgang til det innebygde Dask-dashbordet som vises via en Elastisk belastningsbalanser.
Dataforskere har tilgang til Jupyter-notisboken som ligger på SageMaker. Den bærbare datamaskinen kan koble til og kjøre arbeidsbelastninger på Dask-planleggeren. OpenSearch Service-domenet lagrer metadata på datasettene som er koblet til regionene. Brukere av bærbare PC-er kan spørre denne tjenesten for å hente detaljer, for eksempel riktig Region of Dask-arbeidere uten å måtte vite dataens regionale plassering på forhånd.
Worker
Hver av arbeiderregionene (region B og C i diagrammet) består av en Amazon Elastic Container Service (Amazon ECS) klynge av Dask arbeidere, En Amazon FSx for Luster filsystem og et frittstående Amazon Elastic Compute Cloud (Amazon EC2) forekomst. FSx for Luster lar Dask-arbeidere få tilgang til og behandle Amazon S3-data fra et høyytelses filsystem ved å koble filsystemene dine til S3-bøtter. Den gir forsinkelser på under millisekunder, opptil hundrevis av GBs/s med gjennomstrømning og millioner av IOPS. En nøkkelfunksjon ved Luster er at bare filsystemets metadata synkroniseres. Luster styrer balansen mellom filer som skal lastes inn og holdes varme, basert på etterspørsel.
Arbeiderklynger skaleres basert på CPU-bruk, sørger for flere arbeidere i lengre perioder med etterspørsel, og nedskaleres etter hvert som ressursene blir ledige.
Hver natt klokken 0:00 UTC ber en datasynkroniseringsjobb Luster-filsystemet om å synkronisere på nytt med den vedlagte S3-bøtten, og trekker en oppdatert metadatakatalog over bøtten. Deretter skyver den frittstående EC2-forekomsten disse oppdateringene inn i OpenSearch Service i henhold til den regionens indeks. OpenSearch-tjenesten gir den nødvendige informasjonen til klienten om hvilken gruppe av arbeidere som skal tilkalles for et bestemt datasett.
Network
Nettverk utgjør kjernen i denne løsningen, ved å bruke Amazons interne ryggradsnettverk. Ved bruk av AWS Transit Gateway, vi er i stand til å koble hver av regionene til hverandre uten å måtte krysse det offentlige internett. Hver av arbeiderne er i stand til å koble seg dynamisk inn i Dask-planleggeren, slik at dataforskere kan kjøre interregionale spørringer gjennom Dask.
Forutsetninger
AWS CDK-pakken bruker TypeScript-programmeringsspråket. Følg trinnene i Komme i gang for AWS CDK for å sette opp ditt lokale miljø og starte opp utviklingskontoen din (du må starte opp alle regioner spesifisert i GitHub repo).
For en vellykket distribusjon trenger du Docker installert og kjører på din lokale maskin.
Distribuer AWS CDK-pakken
Det er enkelt å distribuere en AWS CDK-pakke. Etter at du har installert forutsetningene og oppstartet kontoen din, kan du fortsette med å laste ned kodebasen.
- Last ned GitHub repository:
- Installer nodemoduler:
- Distribuer AWS CDK:
Det kan ta over en og en halv time å distribuere stakken.
Kodegjennomgang
I denne delen inspiserer vi noen av nøkkelfunksjonene til kodebasen. Hvis du vil inspisere hele kodebasen, kan du se GitHub repository.
Konfigurer og tilpass stabelen din
I filen bin/variabler.ts, finner du to variable erklæringer: én for klienten og én for arbeidere. Klienterklæringen er en ordbok med referanse til et område og et CIDR-område. Tilpassing av disse variablene vil endre både region- og CIDR-området for hvor klientressurser skal distribueres.
Arbeidsvariabelen kopierer den samme funksjonaliteten; Det er imidlertid en liste over ordbøker for å legge til eller trekke fra datasett brukeren ønsker å inkludere. I tillegg inneholder hver ordbok de lagte feltene til dataset og lustreFileSystemPath. Datasett brukes til å spesifisere koblende S3 URI for Luster å koble til. De lustreFileSystemPath variabel brukes som en tilordning for hvordan brukeren vil at datasettet skal kartlegges lokalt på arbeiderfilsystemet. Se følgende kode:
Publiser planleggerens IP dynamisk
En utfordring som lå i dette prosjektets tverrregionale karakter var å opprettholde en dynamisk forbindelse mellom Dask-arbeiderne og planleggeren. Hvordan kunne vi publisere en IP-adresse, som er i stand til å endre, på tvers av AWS-regioner? Vi var i stand til å oppnå dette gjennom bruk av AWS Cloud Map og assosiere-vpc-med-hosted-zone. Tjenestens sammendrag som lar AWS administrere dette DNS-navneområdet privat. Se følgende kode:
Jupyter bærbare brukergrensesnitt
Jupyter-notisboken som er vert på SageMaker, gir forskere et ferdig miljø for distribusjon for enkelt å koble til og eksperimentere med de innlastede datasettene. Vi brukte a livssyklus-konfigurasjonsskript for å klargjøre den bærbare datamaskinen med et forhåndskonfigurert utviklermiljø og eksempelkodebase. Se følgende kode:
Dask arbeider noder
Når det gjelder Dask-arbeiderne, er det gitt større tilpasningsmuligheter, mer spesifikt på instanstype, tråder per beholder og skaleringsalarmer. Som standard monterer arbeiderne på forekomsttypen m5d.4xlarge til Luster-filsystemet ved lansering, og underdeler arbeiderne og trådene dynamisk til porter. Alt dette kan tilpasses valgfritt. Se følgende kode:
Ytelse
For å vurdere ytelsen bruker vi en prøveberegning og plotting av lufttemperatur ved 2 meter basert på forskjellen mellom CMIP6-prediksjon for en måned og ERA5 gjennomsnittlig lufttemperatur i 10 år. Vi setter en benchmark for to arbeidere i hver region og vurderer forskjellen i tidsreduksjon etter hvert som flere arbeidere ble lagt til. I teorien, ettersom løsningen skalerer, bør det være en produktiv materialforskjell i å redusere den totale tiden.
Tabellen nedenfor oppsummerer datasettdetaljene våre.
| datasett | Variabler | Diskstørrelse | Xarray-datasettstørrelse | Region |
| ERA5 | 2011–2020 (120 netcdf-filer) | 53.5GB | 364.1 GB | us-øst-1 |
| CMIP6 | 1.13GB | 0.11 GB | us-vest-2 |
Følgende tabell viser resultatene som er samlet inn, og viser tiden (i sekunder) for hver beregning og prediksjon i tre trinn i beregning av CMIP6-prediksjon, ERA5 og forskjell.
| . | . | Antall arbeidere | |||
| Beregn | Region | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2 (CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
us-vest-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
us-øst-1 | 1512 | 711 | 427 | 202 |
Forskjell (propogated pool) |
us-west-2 og us-east-1 | 1527 | 906 | 469 | 251 |
Følgende graf visualiserer ytelsen og skalaen.
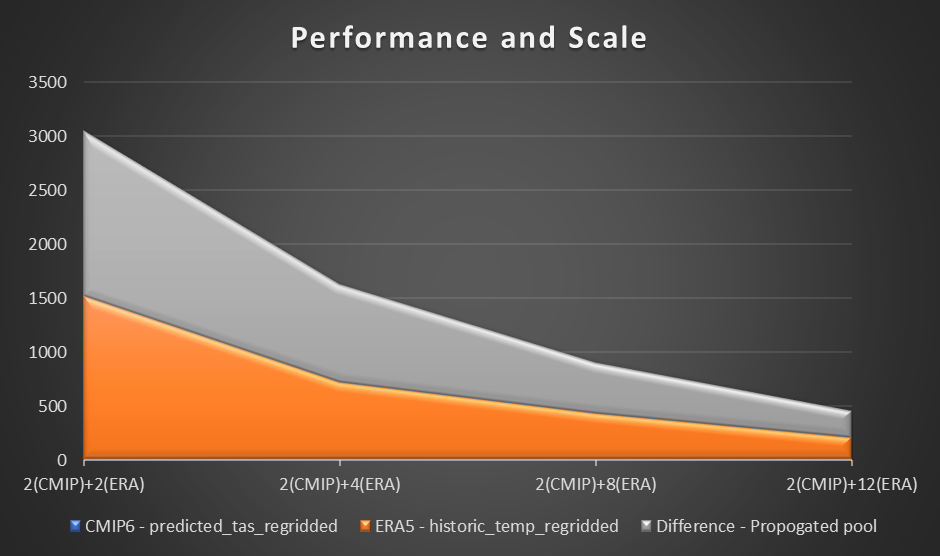
Fra eksperimentet vårt observerte vi en lineær forbedring av beregningen for ERA5-datasettet etter hvert som antall arbeidere økte. Etter hvert som antallet arbeidere økte, ble beregningstidene til tider halvert.
Jupyter notisbok
Som en del av lanseringen av løsningen distribuerer vi en forhåndskonfigurert Jupyter-notebook for å hjelpe til med å teste den tverrregionale Dask-løsningen. Notatboken demonstrerer den fjernede bekymringen ved å måtte vite den regionale plasseringen til datasett, i stedet spørre en katalog gjennom en serie Jupyter-notatbøker som kjører i bakgrunnen.
For å komme i gang, følg instruksjonene i denne delen.
Koden for notatbøkene finner du i lib/SagemakerCode med den primære notatboken ux_notebook.ipynb. Denne notatboken bruker andre notatbøker, og utløser hjelpeskript. ux_notebook er designet for å være inngangspunktet for forskere, uten behov for å gå andre steder.
For å komme i gang, åpne denne notatboken i SageMaker etter at du har distribuert AWS CDK. AWS CDK oppretter en notatbokforekomst med alle filene i depotet lastet og sikkerhetskopiert til en AWS CodeCommit oppbevaringssted.
For å kjøre programmet, åpne og kjør den første cellen i ux_notebook. Denne cellen kjører get_variables notatbok i bakgrunnen, som ber deg om inndata for dataene du vil velge. Vi tar med et eksempel; Vær imidlertid oppmerksom på at spørsmål kun vises etter at det forrige alternativet er valgt. Dette er tilsiktet for å begrense rullegardinvalgene og er valgfritt konfigurerbart ved å redigere get_variables notisbok.
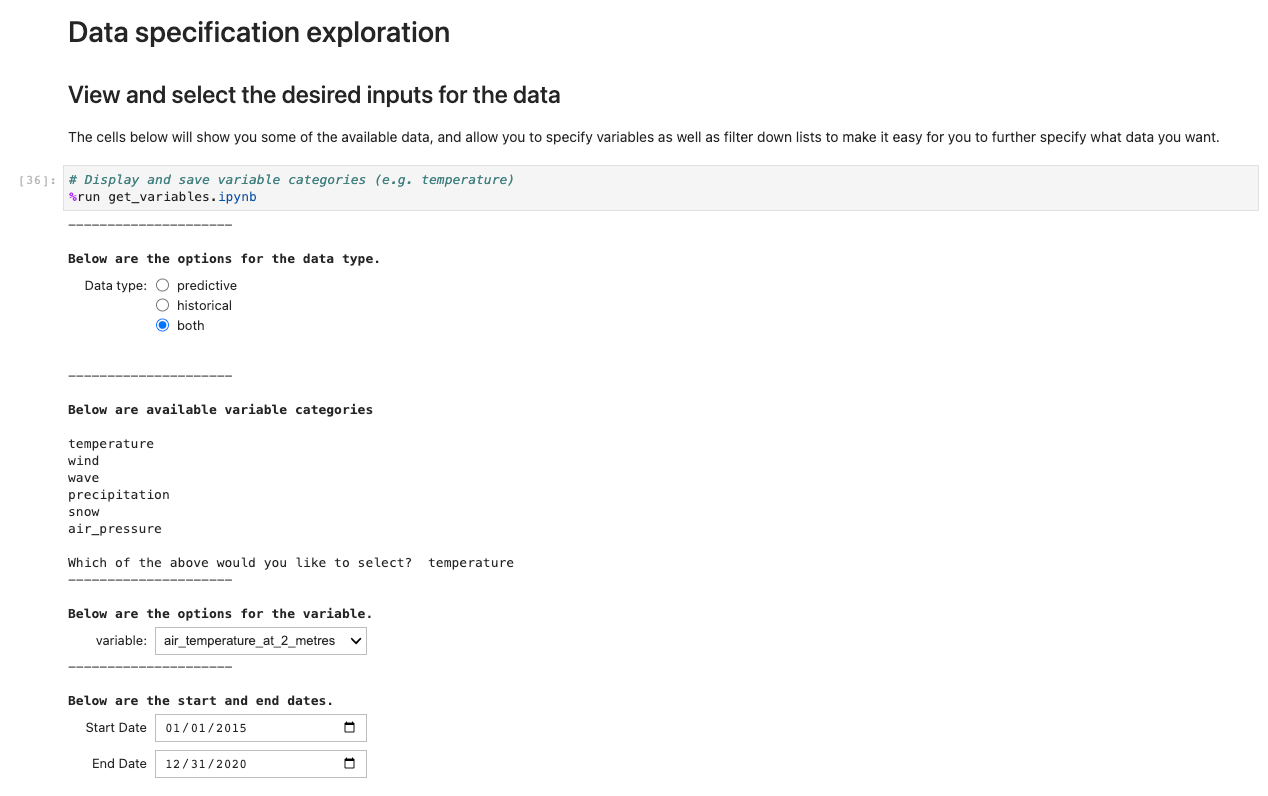
Den foregående koden lagrer variabler globalt slik at andre bærbare datamaskiner kan hente og laste inn valgene du har. For demonstrasjon bør neste celle gi ut lagrede variabler fra før.
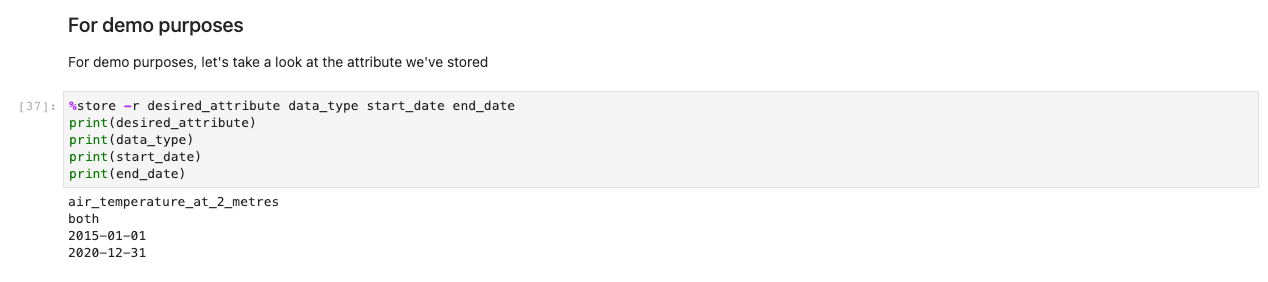
Deretter vises en melding om ytterligere dataspesifikasjoner. Denne cellen avgrenser dataene du er ute etter ved å presentere ID-ene til tabeller i menneskelig lesbart format. Brukere velger som om det var et skjema, men titlene tilordnes tabeller i bakgrunnen som hjelper systemet med å hente de riktige datasettene.
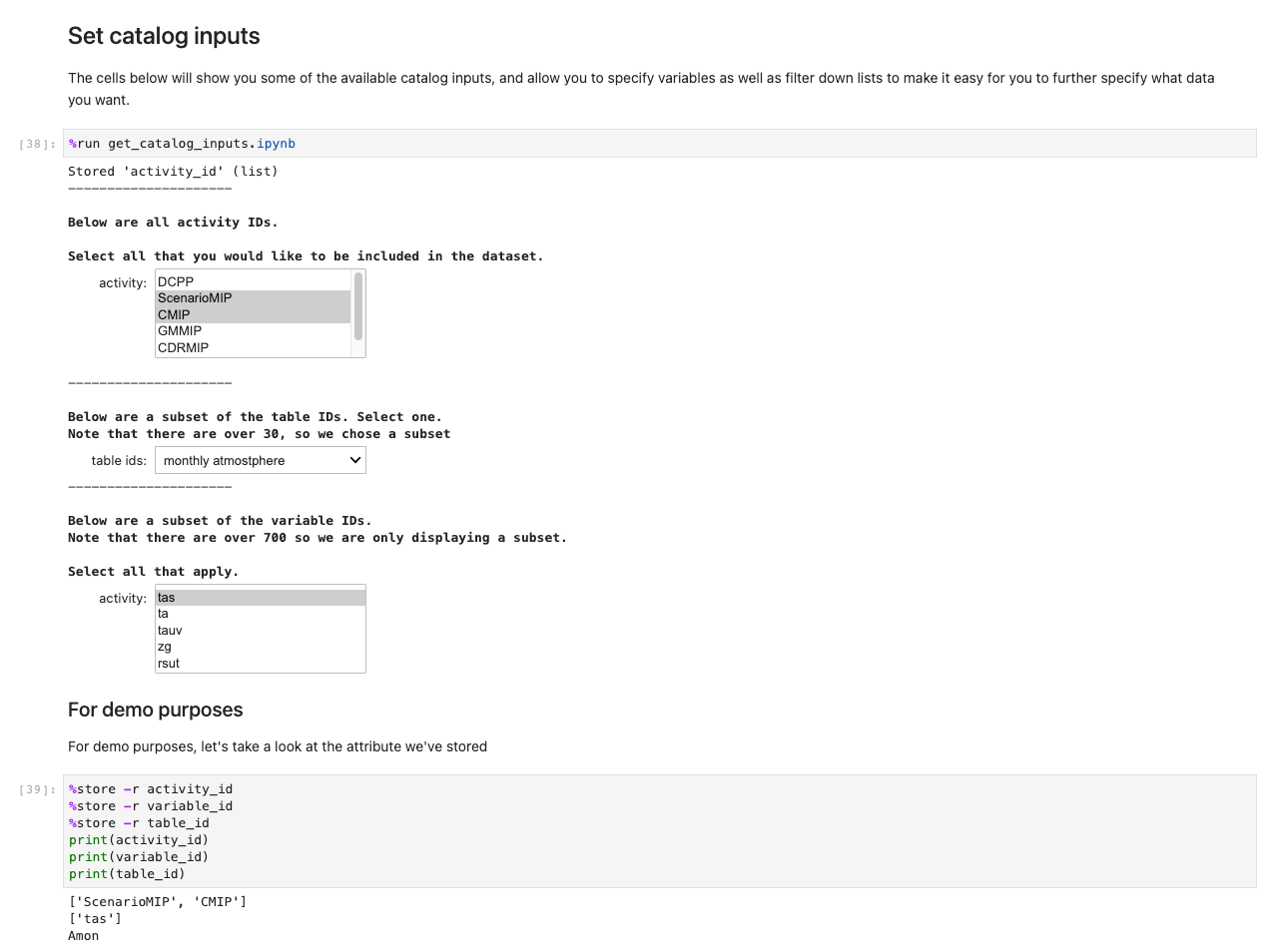
Etter at du har lagret alle valgene og utvalgscellene, laster du dataene inn i regionene ved å kjøre cellen i Få dataene sett seksjon. %%capture-kommandoen vil undertrykke unødvendige utdata fra get_data notisbok. Merk at du kan fjerne dette for å inspisere utdata fra de andre notatbøkene. Data hentes deretter i backend.
Mens andre bærbare datamaskiner kjøres i bakgrunnen, er det eneste berøringspunktet for brukeren ux_notebook. Dette er for å abstrahere den kjedelige prosessen med å importere data til et format alle brukere er i stand til å følge med letthet.
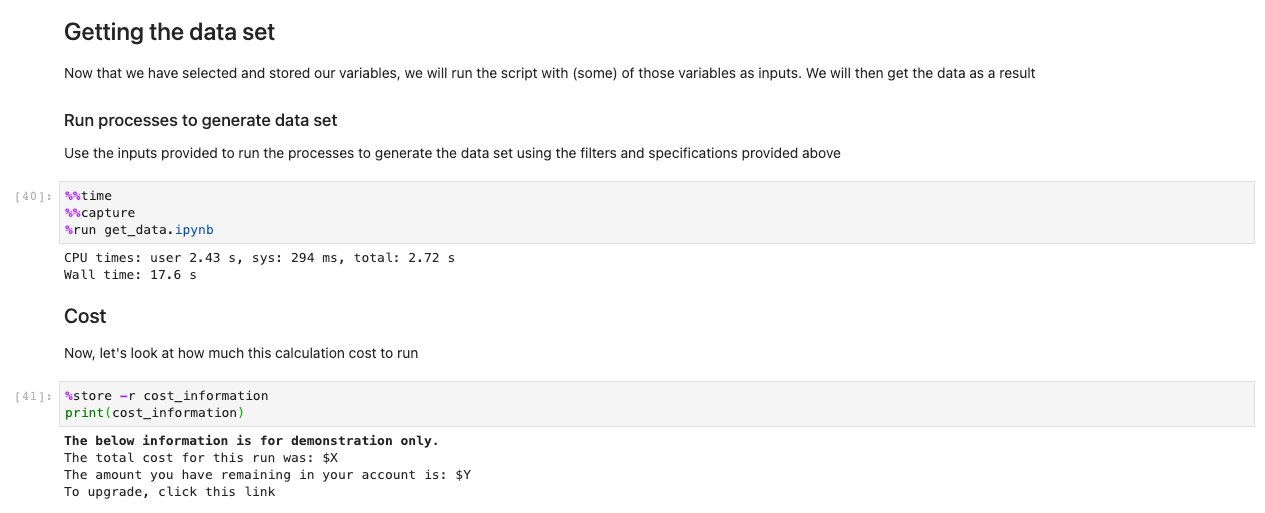
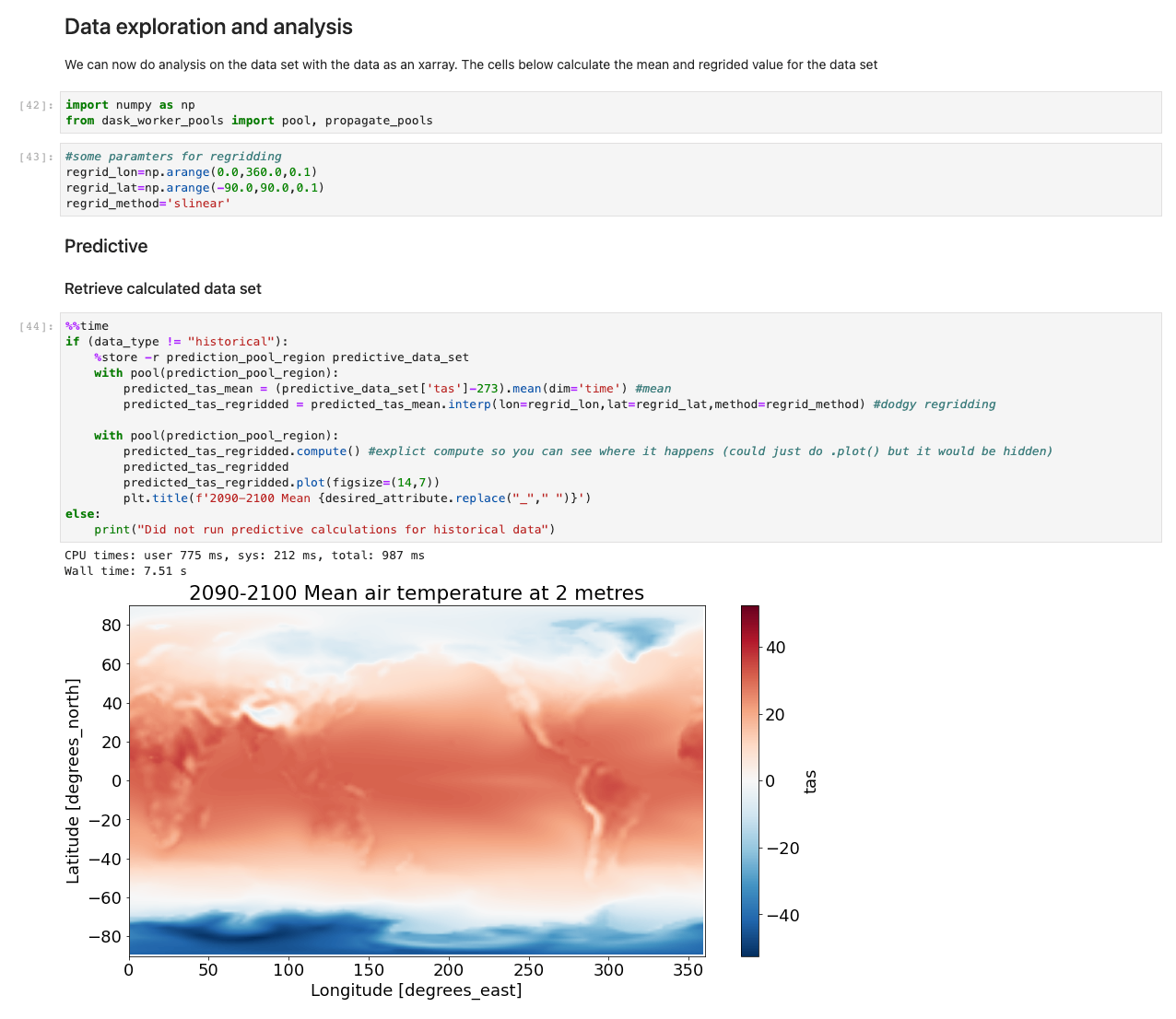
Når dataene nå er lastet inn, kan vi begynne å samhandle med dem. De følgende cellene er eksempler på beregninger du kan kjøre på værdata. Ved hjelp av røntgenbilder, vi importerer, beregner og plotter deretter disse datasettene.
Eksemplet vårt illustrerer et plott av prediktiv data som henter data, kjører beregningen og plotter resultatene på under 7.5 sekunder – størrelsesordener raskere enn en typisk tilnærming.
Under panseret
Notatbøkene get_catalog_input og get_variables bruke biblioteket ipywidgets for å vise widgets som rullegardinmenyene og multiboksvalg. Disse alternativene lagres globalt ved å bruke %%store-kommandoen slik at de kan nås fra ux_notebook. Ett av alternativene spør deg om du vil ha historiske data, prediktive data eller begge deler. Denne variabelen sendes til get_data notatbok for å bestemme hvilke påfølgende notatbøker som skal kjøres.
De get_data notatboken henter først det delte OpenSearch Service-domenet som er lagret til AWS Systems Manager Parameter Store. Dette domenet lar notatboken vår kjøre en spørring om å samle informasjon som vil indikere hvor de valgte datasettene er lagret regionalt. Med disse datasettene lokalisert regionalt, vil den bærbare datamaskinen gjøre et tilkoblingsforsøk til Dask-planleggeren, og overføre informasjonen som er samlet inn fra OpenSearch Service. Dask-planleggeren vil på sin side kunne kalle på arbeidere i de riktige regionene.
Hvordan tilpasse og fortsette utviklingen
Disse notatbøkene er ment å være et eksempel på hvordan du kan lage en måte for brukere å bruke og samhandle med dataene. Notatboken i dette innlegget fungerer som en illustrasjon for hva som er mulig, og vi inviterer deg til å fortsette å bygge videre på løsningen for å forbedre brukerengasjementet ytterligere. Kjernedelen av denne løsningen er backend-teknologien, men uten en eller annen mekanisme for å samhandle med den backend, vil brukerne ikke realisere det fulle potensialet til løsningen.
Slett ressursene for å unngå fremtidige kostnader. La oss ødelegge vår utplasserte løsning med følgende kommando:
konklusjonen
Dette innlegget viser utvidelsen av Dask inter-regionalt på AWS, og en mulig integrasjon med offentlige datasett på AWS. Løsningen ble bygget som et generisk mønster, og ytterligere datasett kan lastes inn for å akselerere høye I/O-analyser på komplekse data.
Data transformerer hvert felt og hver virksomhet. Men med data som vokser raskere enn de fleste bedrifter kan holde styr på, er det utfordrende å samle inn data og få verdi ut av disse dataene. En moderne datastrategi kan hjelpe deg med å skape bedre forretningsresultater med data. AWS tilbyr det mest komplette settet med tjenester for ende-til-ende-datareisen for å hjelpe deg med å låse opp verdi fra dataene dine og gjøre dem om til innsikt.
For å lære mer om de ulike måtene å bruke dataene dine på skyen, besøk AWS Big Data-blogg. Vi inviterer deg videre til å kommentere med dine tanker om dette innlegget, og om dette er en løsning du har tenkt å prøve ut.
Om forfatterne
 Patrick O'Connor er en WWSO Prototyping Engineer basert i London. Han er en kreativ problemløser som kan tilpasses på tvers av et bredt spekter av teknologier, som IoT, serverløs teknologi, 3D romlig teknologi og ML/AI, sammen med en nådeløs nysgjerrighet på hvordan teknologi kan fortsette å utvikle hverdagslige tilnærminger.
Patrick O'Connor er en WWSO Prototyping Engineer basert i London. Han er en kreativ problemløser som kan tilpasses på tvers av et bredt spekter av teknologier, som IoT, serverløs teknologi, 3D romlig teknologi og ML/AI, sammen med en nådeløs nysgjerrighet på hvordan teknologi kan fortsette å utvikle hverdagslige tilnærminger.
 Chakra Nagarajan er en Principal Machine Learning Prototyping SA med 21 års erfaring innen maskinlæring, big data og høyytelses databehandling. I sin nåværende rolle hjelper han kunder med å løse komplekse forretningsproblemer i den virkelige verden ved å bygge prototyper med ende-til-ende AI/ML-løsninger i sky- og kantenheter. Hans ML-spesialisering inkluderer datasyn, naturlig språkbehandling, tidsserieprognoser og personalisering.
Chakra Nagarajan er en Principal Machine Learning Prototyping SA med 21 års erfaring innen maskinlæring, big data og høyytelses databehandling. I sin nåværende rolle hjelper han kunder med å løse komplekse forretningsproblemer i den virkelige verden ved å bygge prototyper med ende-til-ende AI/ML-løsninger i sky- og kantenheter. Hans ML-spesialisering inkluderer datasyn, naturlig språkbehandling, tidsserieprognoser og personalisering.
 Val Cohen er en senior WWSO Prototyping Engineer basert i London. Val er en problemløser av natur, og liker å skrive kode for å automatisere prosesser, bygge kundebesatte verktøy og lage infrastruktur for ulike applikasjoner for hennes globale kundebase. Val har erfaring på tvers av et bredt spekter av teknologier, som front-end webutvikling, backend-arbeid og AI/ML.
Val Cohen er en senior WWSO Prototyping Engineer basert i London. Val er en problemløser av natur, og liker å skrive kode for å automatisere prosesser, bygge kundebesatte verktøy og lage infrastruktur for ulike applikasjoner for hennes globale kundebase. Val har erfaring på tvers av et bredt spekter av teknologier, som front-end webutvikling, backend-arbeid og AI/ML.
 Niall Robinson er leder for produktfutures ved UK Met Office. Han og teamet hans utforsker nye måter Met Office kan gi verdi gjennom produktinnovasjon og strategiske partnerskap. Han har hatt en variert karriere, ledet et tverrfaglig informatikk-FoU-team, akademisk forskning innen datavitenskap og feltforsker sammen med ekspertise på klimamodeller.
Niall Robinson er leder for produktfutures ved UK Met Office. Han og teamet hans utforsker nye måter Met Office kan gi verdi gjennom produktinnovasjon og strategiske partnerskap. Han har hatt en variert karriere, ledet et tverrfaglig informatikk-FoU-team, akademisk forskning innen datavitenskap og feltforsker sammen med ekspertise på klimamodeller.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- : har
- :er
- :hvor
- $OPP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- evne
- I stand
- Om oss
- ovenfor
- ABSTRACT
- sammendrag
- akademisk
- akademisk forskning
- akselerere
- akselerer
- adgang
- aksesseres
- imøtekomme
- utrette
- Logg inn
- oppnår
- tvers
- tilpasser
- la til
- legge
- Ytterligere
- I tillegg
- adresse
- adressering
- Legger
- administratorer
- vedtatt
- Adopsjon
- Etter
- AI / ML
- AIR
- Alle
- tillate
- tillater
- langs
- også
- Amazon
- Amazon EC2
- an
- analyse
- og
- noen
- vises
- Søknad
- søknader
- tilnærming
- tilnærminger
- hensiktsmessig
- arkitektur
- ER
- AS
- At
- Atmosfære
- atmosfærisk
- automatisere
- unngå
- AWS
- AWS-kunde
- Backbone
- Backed
- Backend
- bakgrunn
- Balansere
- basen
- basert
- BE
- bli
- vært
- før du
- være
- under
- benchmark
- Bedre
- mellom
- Stor
- Store data
- Bootstrap
- både
- Bringe
- Brutt
- bygge
- Bygning
- bygget
- innebygd
- virksomhet
- men
- by
- beregne
- ring
- som heter
- ringer
- Samtaler
- CAN
- evner
- stand
- Karriere
- katalog
- CD
- Celler
- utfordre
- utfordrende
- endring
- endring
- kostnad
- avgifter
- valg
- Sirkulasjon
- kunde
- Klima
- nærmere
- Cloud
- Cluster
- CO
- kode
- kodebase
- samarbeid
- Samle
- Kom
- kommer
- kommer
- kommentere
- samfunnet
- Selskaper
- fullføre
- komplekse
- komponenter
- Omfattet
- beregningen
- Beregn
- datamaskin
- Datamaskin syn
- databehandling
- Konfigurasjon
- Koble
- tilkoblet
- Tilkobling
- tilkobling
- Forbrukere
- forbruk
- Container
- inneholder
- fortsette
- fortsetter
- kopier
- Kjerne
- korrigere
- Kostnad
- kostnadseffektiv
- kunne
- kombinert
- prosessor
- skape
- skaper
- Kreativ
- kritisk
- avling
- Kryss
- nysgjerrighet
- Gjeldende
- skikk
- kunde
- Kunder
- tilpasses
- tilpasse
- daglig
- dashbord
- dato
- datavitenskap
- datastrategi
- datasett
- dag
- tiår
- avgjørelser
- Misligholde
- Etterspørsel
- demonstrerer
- utplassere
- utplassert
- distribusjon
- Distribueres
- designet
- ødelegge
- detaljert
- detaljer
- Bestem
- utvikle
- Utvikler
- Utvikling
- Enheter
- forskjell
- deaktivert
- Funnet
- Vise
- distribueres
- distribuert databehandling
- dns
- Docker
- domene
- ned
- dynamisk
- dynamisk
- hver enkelt
- lette
- lett
- Edge
- redigering
- effektiv
- andre steder
- muliggjøre
- ende til ende
- energi
- engasjement
- ingeniør
- entry
- Miljø
- Tilsvarende
- Era
- anslått
- Eter (ETH)
- Hver
- hver dag
- hverdagen
- utvikle seg
- eksempel
- eksempler
- erfaring
- eksperiment
- ekspertise
- utforske
- eksportere
- utsatt
- forlengelse
- raskere
- Trekk
- Egenskaper
- felt
- Felt
- filet
- Filer
- Finn
- Først
- fokuserer
- følge
- etter
- mat
- Til
- skjema
- format
- skjemaer
- funnet
- Stiftet
- Rammeverk
- rammer
- Gratis
- fra
- frukting
- fullt
- funksjonalitet
- videre
- framtid
- Futures
- general
- generasjonen
- få
- få
- gå
- Global
- globalt nettverk
- Globalt
- globus
- skal
- graf
- større
- Grid
- Grow
- Økende
- HAD
- Halvparten
- halvert
- Ha
- he
- hode
- hjelpe
- hjelper
- her
- Høy
- høy ytelse
- striper
- hans
- historisk
- vert
- vert
- time
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- lesbar
- Hundrevis
- Idle
- ids
- if
- illustrerer
- importere
- importere
- forbedre
- forbedring
- in
- inkludere
- inkluderer
- økt
- indeks
- indikerer
- informere
- informasjon
- Infrastruktur
- iboende
- Innovasjon
- inngang
- usikkerhet
- innsikt
- inspirert
- installere
- f.eks
- i stedet
- instruksjoner
- integrering
- Tilsiktet
- samhandle
- samhandler
- Interface
- intern
- Internet
- inn
- invitere
- IOT
- IP
- IP-adresse
- saker
- IT
- DET ER
- Jobb
- reise
- jpg
- Jupyter Notebook
- Hold
- nøkkel
- Vet
- Språk
- stor
- Siste
- Ventetid
- lansere
- ledende
- LÆRE
- læring
- Bibliotek
- Livssyklus
- i likhet med
- linking
- Liste
- laste
- lokal
- lokalt
- ligger
- plassering
- London
- maskin
- maskinlæring
- større
- gjøre
- administrer
- leder
- forvalter
- kart
- kartlegging
- Mass
- Masseadopsjon
- materiale
- Kan..
- bety
- mekanisme
- metadata
- millioner
- ML
- modell
- Moderne
- Moduler
- Måned
- månedlig
- månedlige data
- mer
- mest
- MONTER
- tverrfaglig
- navn
- nasjonal
- Naturlig
- Naturlig språk
- Natural Language Processing
- Natur
- nødvendig
- Trenger
- trenger
- nettverk
- Ny
- neste
- natt
- node
- noder
- bærbare
- notatbøker
- nå
- Antall
- tall
- of
- tilby
- Office
- on
- ONE
- bare
- åpen
- åpne data
- åpen kildekode
- åpen kildekode
- operasjonell
- Alternativ
- alternativer
- or
- orkestre
- organisasjoner
- Annen
- vår
- ut
- utfall
- produksjon
- enn
- samlet
- pakke
- parameter
- del
- Spesielt
- spesielt
- partnerskap
- bestått
- Passerer
- Mønster
- ytelse
- perioder
- Tilpassing
- petabyte
- fase
- fly
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Point
- basseng
- porter
- mulig
- Post
- potensiell
- makt
- kraftig
- praksis
- prediksjon
- Spådommer
- forutsetninger
- forrige
- primære
- Principal
- privat
- Problem
- problemer
- prosess
- Prosesser
- prosessering
- produsert
- Produkt
- Produktinnovasjon
- produktiv
- program
- Programmering
- prosjekt
- prototyper
- prototyping
- gi
- forutsatt
- gir
- forsyning
- offentlig
- publisere
- publisert
- Trekker
- spørsmål
- spørsmål
- FoU
- område
- heller
- ferdige
- virkelige verden
- realisere
- redusere
- redusere
- reduksjon
- region
- regional
- regioner
- nådeløse
- forblir
- fjerne
- fjernet
- Repository
- representerer
- forskning
- Ressurser
- de
- Resultater
- Rolle
- Kjør
- rennende
- SA
- trygge
- sagemaker
- samme
- Spar
- skalerbar
- Skala
- vekter
- skalering
- Vitenskap
- Forsker
- forskere
- skript
- sekunder
- Seksjon
- se
- sett
- segmenter
- valgt
- utvalg
- senior
- Serien
- server~~POS=TRUNC
- serverer
- tjeneste
- Tjenester
- sett
- Del
- delt
- bør
- Vis
- utstillingsvindu
- Viser
- Enkelt
- ganske enkelt
- sjette
- langsom
- So
- løsning
- Solutions
- LØSE
- noen
- kilde
- romlig
- spesielt
- spesifikasjoner
- spesifisert
- sponsoravtale
- stable
- stadier
- stående
- Begynn
- startet
- opphold
- Steps
- lagring
- oppbevare
- lagret
- butikker
- rett fram
- Strategisk
- strategiske partnerskap
- Strategi
- senere
- I ettertid
- vellykket
- slik
- overflaten
- bølge
- Bærekraft
- bærekraftig
- system
- Systemer
- bord
- Ta
- lag
- tech
- Technologies
- Teknologi
- test
- enn
- Det
- De
- informasjonen
- Kilden
- Storbritannia
- verden
- deres
- deretter
- Der.
- derved
- Disse
- de
- denne
- De
- tre
- Thrive
- Gjennom
- gjennomstrømning
- tid
- Tidsserier
- ganger
- titler
- til
- i dag
- sammen
- verktøy
- spor
- Sporing
- overføre
- transformere
- transitt
- utløsende
- SVING
- to
- typen
- Loggfila
- typisk
- Uk
- etter
- låse opp
- uholdbar
- up-to-date
- oppdateringer
- upon
- URI
- bruk
- bruke
- brukt
- Bruker
- Brukere
- ved hjelp av
- UTC
- utnytte
- VAL
- verdi
- variasjon
- ulike
- av
- syn
- Besøk
- volum
- ønsker
- ønsker
- varm
- var
- Vei..
- måter
- we
- Vær
- web
- Webutvikling
- var
- om
- hvilken
- bred
- Bred rekkevidde
- vil
- ønsker
- med
- uten
- Arbeid
- arbeidstaker
- arbeidere
- verden
- bekymring
- ville
- skriving
- år
- ennå
- Utbytte
- du
- Din
- zephyrnet