Finne lignende kolonner i en data innsjø har viktige applikasjoner innen datarensing og merknader, skjematilpasning, dataoppdagelse og analyser på tvers av flere datakilder. Manglende evne til nøyaktig å finne og analysere data fra ulike kilder representerer en potensiell effektivitetsdreper for alle fra dataforskere, medisinske forskere, akademikere til finans- og regjeringsanalytikere.
Konvensjonelle løsninger involverer leksikalsk nøkkelordsøk eller samsvar med regulære uttrykk, som er utsatt for datakvalitetsproblemer som fraværende kolonnenavn eller forskjellige kolonnenavnekonvensjoner på tvers av forskjellige datasett (f.eks. zip_code, zcode, postalcode).
I dette innlegget demonstrerer vi en løsning for å søke etter lignende kolonner basert på kolonnenavn, kolonneinnhold eller begge deler. Løsningen bruker omtrentlige algoritmer for nærmeste naboer tilgjengelig i Amazon OpenSearch-tjeneste for å søke etter semantisk lignende kolonner. For å lette søket lager vi funksjonsrepresentasjoner (innbygginger) for individuelle kolonner i datasjøen ved å bruke forhåndstrente transformatormodeller fra setningstransformatorbibliotek in Amazon SageMaker. Til slutt, for å samhandle med og visualisere resultater fra løsningen vår, bygger vi en interaktiv Strømbelyst nettapplikasjon som kjører på AWS Fargate.
Vi inkluderer en kodeopplæring for deg å distribuere ressursene for å kjøre løsningen på eksempeldata eller dine egne data.
Løsningsoversikt
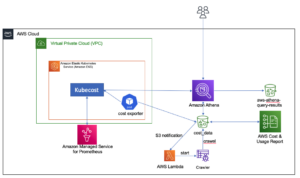
Følgende arkitekturdiagram illustrerer to-trinns arbeidsflyt for å finne semantisk lignende kolonner. Den første etappen går en AWS trinnfunksjoner arbeidsflyt som oppretter innbygginger fra tabellkolonner og bygger søkeindeksen for OpenSearch Service. Den andre fasen, eller den elektroniske slutningsfasen, kjører en Streamlit-applikasjon gjennom Fargate. Nettapplikasjonen samler inn søkespørsmål og henter fra OpenSearch Service-indeksen de omtrentlige k-mest-lignende kolonnene til spørringen.

Figur 1. Løsningsarkitektur
Den automatiserte arbeidsflyten fortsetter i følgende trinn:
- Brukeren laster opp tabelldatasett til en Amazon enkel lagringstjeneste (Amazon S3) bøtte, som påkaller en AWS Lambda funksjon som starter arbeidsflyten for trinnfunksjoner.
- Arbeidsflyten begynner med en AWS Lim jobb som konverterer CSV-filene til Apache Parkett dataformat.
- En SageMaker Processing-jobb oppretter innbygginger for hver kolonne ved å bruke forhåndsopplærte modeller eller tilpassede innbyggingsmodeller for kolonner. SageMaker Processing-jobben lagrer kolonneinnbyggingene for hver tabell i Amazon S3.
- En Lambda-funksjon oppretter OpenSearch Service-domenet og -klyngen for å indeksere kolonneinnbyggingene produsert i forrige trinn.
- Til slutt er en interaktiv Streamlit-nettapplikasjon distribuert med Fargate. Nettapplikasjonen gir brukeren et grensesnitt for å legge inn spørringer for å søke i OpenSearch Service-domenet etter lignende kolonner.
Du kan laste ned kodeveiledningen fra GitHub for å prøve denne løsningen på eksempeldata eller dine egne data. Instruksjoner om hvordan du distribuerer de nødvendige ressursene for denne opplæringen er tilgjengelig på Github.
Forutsetninger
For å implementere denne løsningen trenger du følgende:
- An AWS-konto.
- Grunnleggende kjennskap til AWS-tjenester som f.eks AWS skyutviklingssett (AWS CDK), Lambda, OpenSearch Service og SageMaker Processing.
- Et tabelldatasett for å lage søkeindeksen. Du kan ta med egne tabelldata eller laste ned prøvedatasettene på GitHub.
Bygg en søkeindeks
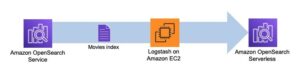
Det første trinnet bygger kolonnesøkemotorindeksen. Følgende figur illustrerer arbeidsflyten for trinnfunksjoner som kjører dette stadiet.

Figur 2 – Arbeidsflyt for trinnfunksjoner – flere innbyggingsmodeller
datasett
I dette innlegget bygger vi en søkeindeks som inkluderer over 400 kolonner fra over 25 tabelldatasett. Datasettene stammer fra følgende offentlige kilder:
For den fullstendige listen over tabellene som er inkludert i indeksen, se kodeveiledningen på GitHub.
Du kan ta med ditt eget tabelldatasett for å utvide eksempeldataene eller bygge din egen søkeindeks. Vi inkluderer to Lambda-funksjoner som starter Step Functions-arbeidsflyten for å bygge søkeindeksen for henholdsvis individuelle CSV-filer eller en gruppe CSV-filer.
Gjør om CSV til parkett
Rå CSV-filer konverteres til parkettdataformat med AWS Glue. Parkett er et kolonneorientert filformat foretrukket i big data-analyse som gir effektiv komprimering og koding. I våre eksperimenter tilbød Parquet-dataformatet betydelig reduksjon i lagringsstørrelse sammenlignet med rå CSV-filer. Vi brukte også Parkett som et vanlig dataformat for å konvertere andre dataformater (for eksempel JSON og NDJSON) fordi det støtter avanserte nestede datastrukturer.
Opprett kolonneinnbygginger i tabellform
For å trekke ut innebygginger for individuelle tabellkolonner i eksempeltabelldatasettene i dette innlegget, bruker vi følgende forhåndsopplærte modeller fra sentence-transformers bibliotek. For flere modeller, se Fortrente modeller.
SageMaker Processing-jobben kjører create_embeddings.py(kode) for en enkelt modell. For å trekke ut embeddings fra flere modeller, kjører arbeidsflyten parallelle SageMaker Processing-jobber som vist i arbeidsflyten Step Functions. Vi bruker modellen til å lage to sett med innebygging:
- column_name_embeddings – Innebygging av kolonnenavn (overskrifter)
- column_content_embeddings – Gjennomsnittlig innebygging av alle radene i kolonnen
For mer informasjon om kolonneinnbyggingsprosessen, se kodeveiledningen på GitHub.
Et alternativ til SageMaker Processing-trinnet er å lage en SageMaker batch-transformasjon for å få innbygging av kolonner på store datasett. Dette vil kreve å distribuere modellen til et SageMaker-endepunkt. For mer informasjon, se Bruk Batch Transform.
Indeks innebygginger med OpenSearch Service
I det siste trinnet av dette stadiet legger en Lambda-funksjon til kolonneinnbyggingene til en OpenSearch-tjeneste omtrentlig k-Nearest-Neighbor (kNN) søkeindeks. Hver modell er tildelt sin egen søkeindeks. For mer informasjon om de omtrentlige kNN-søkeindeksparametrene, se k-NN.
Online slutning og semantisk søk med en nettapp
Den andre fasen av arbeidsflyten kjører en Strømbelyst nettapplikasjon der du kan gi inndata og søke etter semantisk lignende kolonner indeksert i OpenSearch Service. Applikasjonslaget bruker en Lastbalanse for applikasjon, Fargate og Lambda. Applikasjonsinfrastrukturen distribueres automatisk som en del av løsningen.
Applikasjonen lar deg gi inndata og søke etter semantisk lignende kolonnenavn, kolonneinnhold eller begge deler. I tillegg kan du velge innebyggingsmodell og antall nærmeste naboer som skal returneres fra søket. Applikasjonen mottar input, bygger inn input med den angitte modellen og bruker kNN-søk i OpenSearch Service for å søke i indekserte kolonneinnbygginger og finne de kolonnene som ligner mest på den gitte inngangen. Søkeresultatene som vises inkluderer tabellnavn, kolonnenavn og likhetspoeng for de identifiserte kolonnene, samt plasseringen av dataene i Amazon S3 for videre utforskning.
Følgende figur viser et eksempel på nettapplikasjonen. I dette eksemplet søkte vi etter kolonner i datasjøen vår som har lignende Column Names (type nyttelast) Til district (nyttelast). Applikasjonen som brukes all-MiniLM-L6-v2 som den innbyggingsmodell og kom tilbake 10 (k) nærmeste naboer fra vår OpenSearch Service-indeks.
Søknaden kom tilbake transit_district, city, boroughog location som de fire mest like kolonnene basert på dataene som er indeksert i OpenSearch Service. Dette eksemplet demonstrerer søkemetodens evne til å identifisere semantisk like kolonner på tvers av datasett.

Figur 3: Brukergrensesnitt for nettapplikasjoner
Rydd opp
For å slette ressursene som er opprettet av AWS CDK i denne opplæringen, kjør følgende kommando:
cdk destroy --allkonklusjonen
I dette innlegget presenterte vi en ende-til-ende arbeidsflyt for å bygge en semantisk søkemotor for tabellkolonner.
Kom i gang i dag med dine egne data med vår kodeveiledning tilgjengelig på GitHub. Hvis du vil ha hjelp til å fremskynde bruken av ML i produktene og prosessene dine, vennligst kontakt Amazon Machine Learning Solutions Lab.
Om forfatterne
![]() Kachi Odoemene er en Applied Scientist ved AWS AI. Han bygger AI/ML-løsninger for å løse forretningsproblemer for AWS-kunder.
Kachi Odoemene er en Applied Scientist ved AWS AI. Han bygger AI/ML-løsninger for å løse forretningsproblemer for AWS-kunder.
![]() Taylor McNally er en Deep Learning Architect ved Amazon Machine Learning Solutions Lab. Han hjelper kunder fra ulike bransjer med å bygge løsninger som utnytter AI/ML på AWS. Han nyter en god kopp kaffe, friluftsliv og tid med familien sin og den energiske hunden.
Taylor McNally er en Deep Learning Architect ved Amazon Machine Learning Solutions Lab. Han hjelper kunder fra ulike bransjer med å bygge løsninger som utnytter AI/ML på AWS. Han nyter en god kopp kaffe, friluftsliv og tid med familien sin og den energiske hunden.
![]() Austin Welch er en dataforsker i Amazon ML Solutions Lab. Han utvikler tilpassede dyplæringsmodeller for å hjelpe AWS-kunder i offentlig sektor med å akselerere AI og skyadopsjon. På fritiden liker han å lese, reise og jiu-jitsu.
Austin Welch er en dataforsker i Amazon ML Solutions Lab. Han utvikler tilpassede dyplæringsmodeller for å hjelpe AWS-kunder i offentlig sektor med å akselerere AI og skyadopsjon. På fritiden liker han å lese, reise og jiu-jitsu.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- evne
- Om oss
- fraværende
- akselerere
- akselerer
- nøyaktig
- tvers
- Ytterligere
- I tillegg
- Legger
- Adopsjon
- avansert
- AI
- AI / ML
- Alle
- tillater
- alternativ
- Amazon
- Amazon maskinlæring
- Amazon ML Solutions Lab
- analytikere
- analytics
- analysere
- og
- Apache
- Søknad
- søknader
- anvendt
- tilnærming
- arkitektur
- tildelt
- Automatisert
- automatisk
- tilgjengelig
- gjennomsnittlig
- AWS
- AWS Lim
- basert
- fordi
- Stor
- Store data
- bringe
- bygge
- Bygning
- bygger
- virksomhet
- Rengjøring
- Cloud
- skyadopsjon
- Cluster
- kode
- Kaffe
- innsamler
- Kolonne
- kolonner
- Felles
- sammenlignet
- kontakt
- innhold
- konvensjoner
- konvertere
- konvertert
- skape
- opprettet
- skaper
- kopp
- skikk
- Kunder
- dato
- Data Analytics
- Data Lake
- datakvalitet
- dataforsker
- datasett
- dyp
- dyp læring
- demonstrere
- demonstrerer
- utplassere
- utplassert
- utplasserings
- ødelegge
- Utvikling
- utvikler
- forskjellig
- Funnet
- uensartede
- diverse
- Hund
- domene
- nedlasting
- hver enkelt
- effektivitet
- effektiv
- ende til ende
- Endpoint
- Motor
- Eter (ETH)
- alle
- eksempel
- leting
- trekke ut
- legge til rette
- Familiær
- familie
- Egenskaper
- Figur
- filet
- Filer
- slutt~~POS=TRUNC
- Endelig
- finansiell
- Finn
- finne
- Først
- etter
- format
- fra
- fullt
- funksjon
- funksjoner
- videre
- få
- gitt
- god
- Regjeringen
- overskrifter
- hjelpe
- hjelper
- Hvordan
- Hvordan
- HTML
- HTTPS
- identifisert
- identifisere
- iverksette
- viktig
- in
- manglende evne
- inkludere
- inkludert
- indeks
- individuelt
- bransjer
- informasjon
- Infrastruktur
- initiere
- Starter
- inngang
- instruksjoner
- samhandle
- interaktiv
- Interface
- påkaller
- involvere
- saker
- IT
- Jobb
- Jobb
- JSON
- lab
- innsjø
- stor
- lag
- læring
- utnytte
- Bibliotek
- Liste
- laste
- steder
- maskin
- maskinlæring
- matchende
- medisinsk
- ML
- modell
- modeller
- mer
- mest
- flere
- navn
- navn
- navngiving
- Trenger
- naboer
- Antall
- tilbudt
- på nett
- Annen
- utendørs
- egen
- Parallel
- parametere
- del
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- Post
- potensiell
- trekkes
- presentert
- forrige
- problemer
- fortsetter
- prosess
- Prosesser
- prosessering
- produsert
- Produkter
- gi
- gir
- offentlig
- kvalitet
- Raw
- Lesning
- mottar
- regelmessig
- representerer
- krever
- påkrevd
- forskere
- Ressurser
- henholdsvis
- Resultater
- retur
- Kjør
- rennende
- sagemaker
- Forsker
- forskere
- Søk
- søkemotor
- søker
- Sekund
- sektor
- tjeneste
- Tjenester
- sett
- vist
- Viser
- signifikant
- lignende
- Enkelt
- enkelt
- Størrelse
- løsning
- Solutions
- LØSE
- Kilder
- spesifisert
- Scene
- startet
- Trinn
- Steps
- lagring
- slik
- Støtter
- utsatt
- bord
- De
- deres
- Gjennom
- tid
- til
- i dag
- Transform
- transformers
- Traveling
- tutorial
- bruke
- Bruker
- Brukergrensesnitt
- ulike
- web
- Webapplikasjon
- hvilken
- arbeidsflyt
- ville
- Din
- zephyrnet