Å forbedre hvordan brukere oppdager nytt innhold er avgjørende for å øke brukerengasjement og -tilfredshet på medieplattformer. Nøkkelordsøk alene har utfordringer med å fange semantikk og brukerintensjon, noe som fører til resultater som mangler relevant kontekst; for eksempel finne datekveld eller filmer med juletema. Dette kan føre til lavere oppbevaringsrater hvis brukere ikke kan finne innholdet de vil ha pålitelig. Imidlertid med store språkmodeller (LLMs), er det en mulighet til å løse disse semantiske utfordringene og brukerintensjonsutfordringene. Ved å kombinere embeddinger som fanger semantikk med en teknikk som kalles Retrieval Augmented Generation (RAG), kan du generere mer relevante svar basert på hentet kontekst fra dine egne datakilder.
I dette innlegget viser vi deg hvordan du sikkert oppretter en filmchatbot ved å implementere RAG med dine egne data ved å bruke Kunnskapsbaser forum Amazonas grunnfjell. Vi bruker IMDb og Box Office Mojo-datasettet til å simulere en katalog for medie- og underholdningskunder og vise frem hvordan du kan bygge din egen RAG-løsning i bare et par trinn.
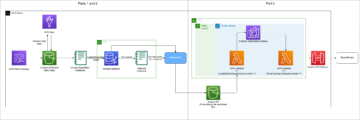
Løsningsoversikt
De IMDb og Box Office Mojo Movies/TV/OTT lisensierbar datapakke gir et bredt spekter av underholdningsmetadata, inkludert over 1.6 milliard brukervurderinger; kreditter for mer enn 13 millioner rollebesetnings- og besetningsmedlemmer; 10 millioner film-, TV- og underholdningstitler; og globale billettkontorrapporteringsdata fra mer enn 60 land. Mange AWS medie- og underholdningskunder lisensierer IMDb-data gjennom AWS datautveksling for å forbedre innholdsoppdagelsen og øke kundeengasjement og -oppbevaring.
Introduksjon til kunnskapsbaser for Amazons grunnfjell
For å utstyre en LLM med oppdatert proprietær informasjon, bruker organisasjoner RAG, en teknikk som innebærer å hente data fra selskapets datakilder og berike ledeteksten med disse dataene for å levere mer relevante og nøyaktige svar. Kunnskapsbaser for Amazon Bedrock muliggjør en fullstendig administrert RAG-funksjon som lar deg tilpasse LLM-svar med kontekstuelle og relevante bedriftsdata. Kunnskapsbaser automatiserer ende-til-ende RAG-arbeidsflyten, inkludert inntak, henting, umiddelbar utvidelse og siteringer, og eliminerer behovet for deg å skrive tilpasset kode for å integrere datakilder og administrere spørringer. Kunnskapsbaser for Amazon Bedrock muliggjør også samtaler med flere svinger slik at LLM kan svare på komplekse brukerspørsmål med riktig svar.
Vi bruker følgende tjenester som en del av denne løsningen:
Vi går gjennom følgende trinn på høyt nivå:
- Forbehandle IMDb-dataene for å lage dokumenter fra hver filmpost og laste opp dataene til en Amazon enkel lagringstjeneste (Amazon S3) bøtte.
- Lag en kunnskapsbase.
- Synkroniser kunnskapsbasen din med datakilden din.
- Bruk kunnskapsbasen til å svare på semantiske spørsmål om filmkatalogen.
Forutsetninger
IMDb-dataene som brukes i dette innlegget krever en kommersielt innholdslisens og betalt abonnement på IMDb og Box Office Mojo Movies/TV/OTT-lisenspakken på AWS Data Exchange. For å spørre om en lisens og få tilgang til eksempeldata, besøk developer.imdb.com. For å få tilgang til datasettet, se Kraftanbefaling og søk ved hjelp av en IMDb-kunnskapsgraf – Del 1 og følg Få tilgang til IMDb-dataene seksjon.
Forbehandle IMDb-dataene
Før vi oppretter en kunnskapsbase, må vi forhåndsbehandle IMDb-datasettet til tekstfiler og laste dem opp til en S3-bøtte. I dette innlegget simulerer vi en kundekatalog ved å bruke IMDb-datasettet. Vi tar 10,000 XNUMX populære filmer fra IMDb-datasettet for katalogen og bygger datasettet.
Bruk følgende bærbare for å lage datasettet med tilleggsinformasjon som skuespillere, regissører og produsenter. Vi bruker følgende kode for å lage en enkelt fil for en film med all informasjon som er lagret i filen i en ustrukturert tekst som kan forstås av LLM-er:
Etter at du har dataene i .txt-format, kan du laste opp dataene til Amazon S3 ved å bruke følgende kommando:
Opprett IMDb Knowledge Base
Fullfør følgende trinn for å lage din kunnskapsbase:
- På Amazon Bedrock-konsollen velger du Kunnskapsbase i navigasjonsruten.
- Velg Lag kunnskapsbase.
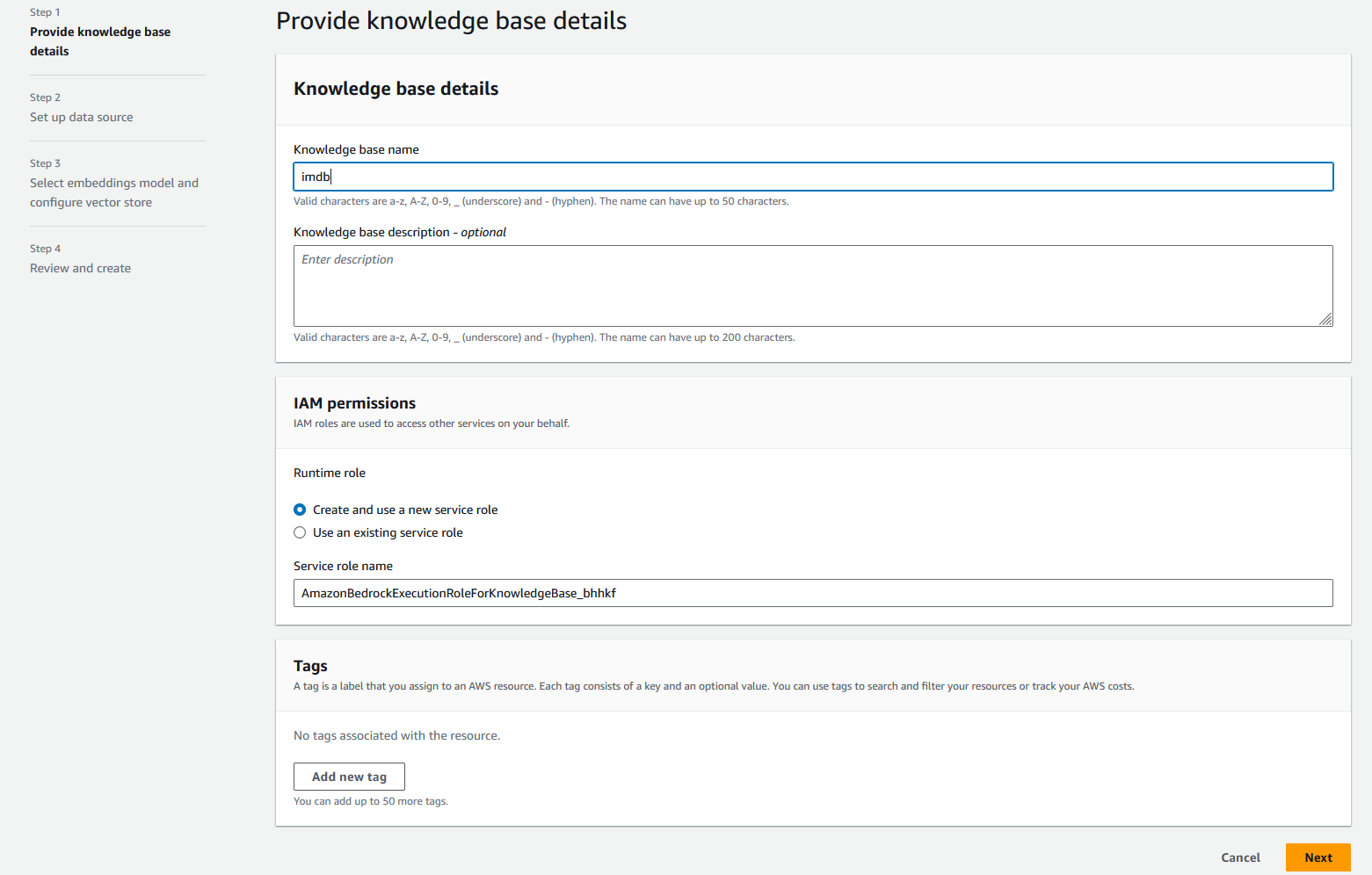
- Til Navn på kunnskapsbase, Tast inn
imdb. - Til Kunnskapsbasebeskrivelse, skriv inn en valgfri beskrivelse, for eksempel Kunnskapsbase for inntak og lagring av imdb-data.
- Til IAM-tillatelser, plukke ut Opprett og bruk en ny tjenesterolle, og skriv deretter inn et navn for din nye tjenesterolle.
- Velg neste.
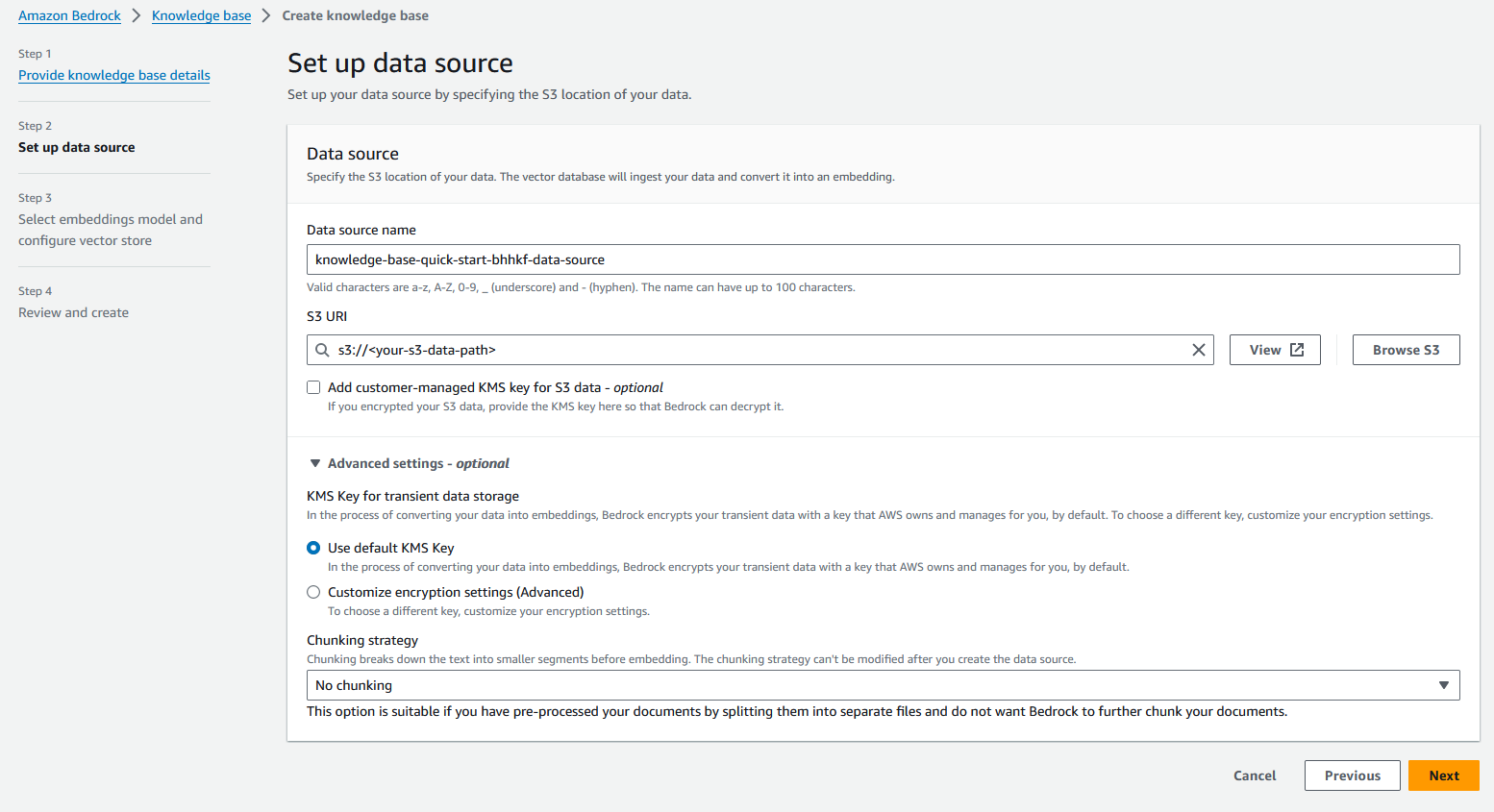
- Til Navn på datakilde, Tast inn
imdb-s3. - Til S3 URI, skriv inn S3-URI-en du lastet opp dataene til.
- på Avanserte innstillinger – valgfritt seksjon, for Chunking strategi, velg Ingen klumping.
- Velg neste.
Kunnskapsbaser lar deg dele opp dokumentene dine i mindre segmenter for å gjøre det enkelt for deg å behandle store dokumenter. I vårt tilfelle har vi allerede delt dataene inn i et dokument i mindre størrelse (ett per film).
- på Vektordatabase seksjon, velg Lag raskt en ny vektorbutikk.
Amazon Bedrock vil automatisk opprette en fullstendig administrert OpenSearch Serverless vektorsøkesamling og konfigurere innstillingene for å bygge inn datakildene dine ved å bruke den valgte Titan Embedding G1 – Tekstinnbyggingsmodellen.
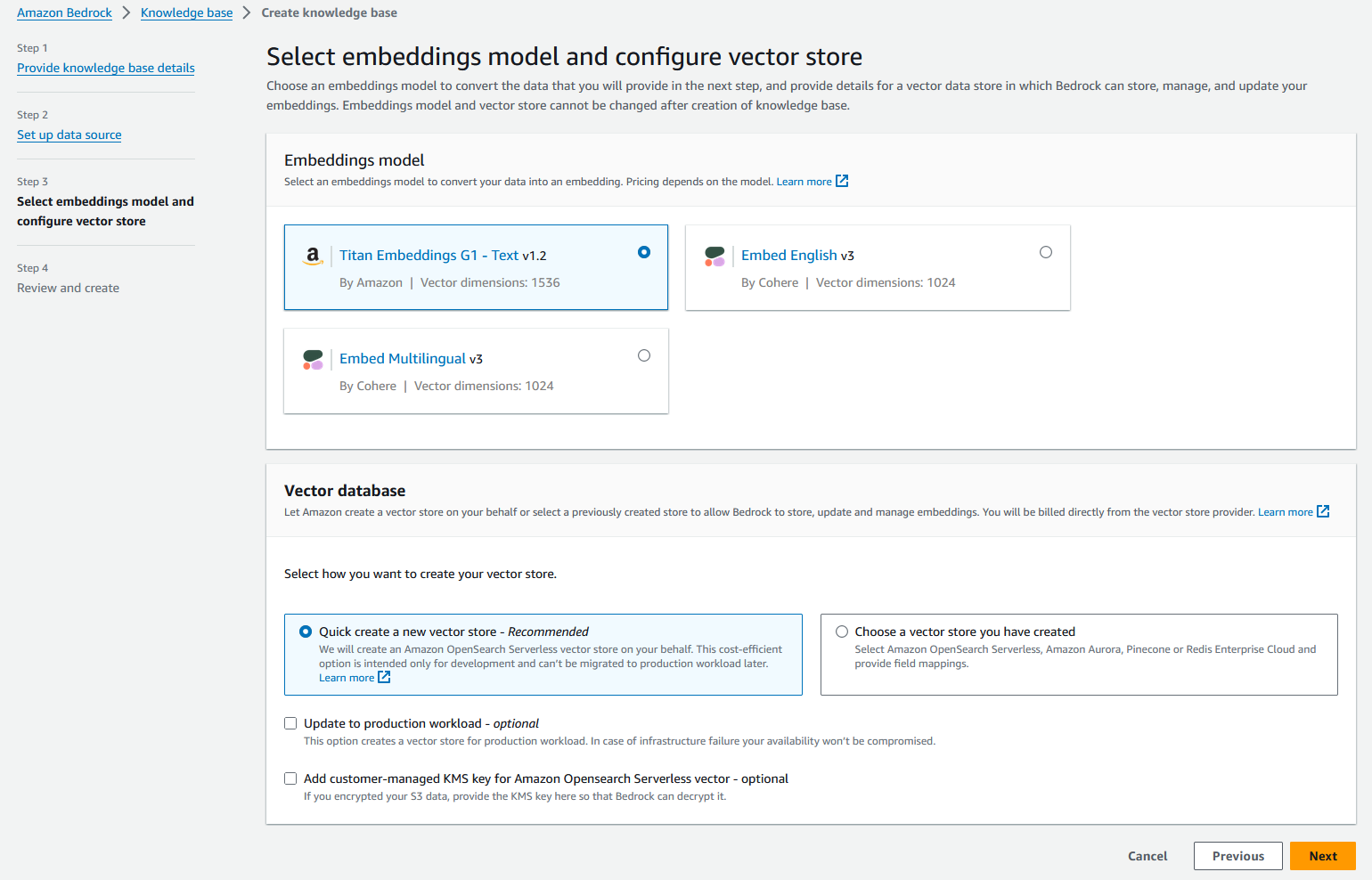
- Velg neste.
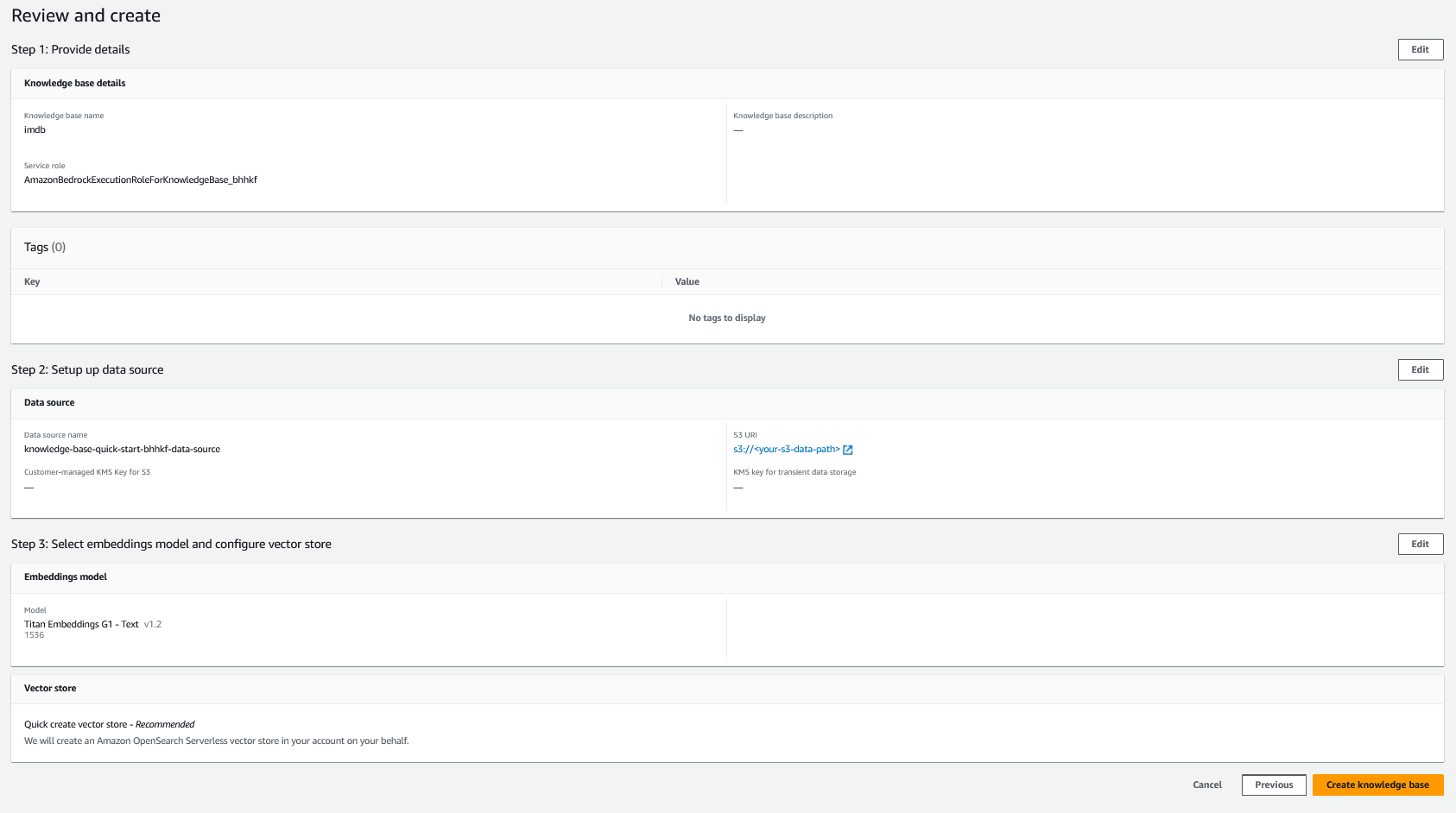
- Gå gjennom innstillingene og velg Lag kunnskapsbase.
Synkroniser dataene dine med kunnskapsbasen
Nå som du har opprettet kunnskapsbasen din, kan du synkronisere kunnskapsbasen med dataene dine.
- På Amazon Bedrock-konsollen kan du navigere til kunnskapsbasen din.
- på Datakilde delen velger Synkroniser.

Etter at datakilden er synkronisert, er du klar til å spørre etter dataene.
Forbedre søk ved hjelp av semantiske resultater
Fullfør følgende trinn for å teste løsningen og forbedre søket ditt ved hjelp av semantiske resultater:
- På Amazon Bedrock-konsollen kan du navigere til kunnskapsbasen din.
- Velg din kunnskapsbase og velg Test kunnskapsbase.
- Velg Velg modell, og velg Antropiske Claude v2.1.
- Velg Påfør.
Nå er du klar til å spørre etter dataene.
Vi kan stille noen semantiske spørsmål, for eksempel «Anbefal meg noen filmer med juletema».
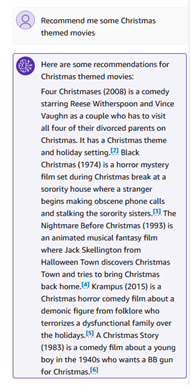
Kunnskapsbasens svar inneholder sitater som du kan utforske for korrekthet og fakta.
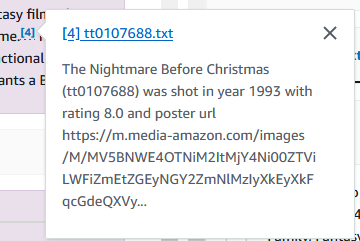
Du kan også se nærmere på all informasjon du trenger fra disse filmene. I følgende eksempel spør vi "hvem regisserte mareritt før jul?"

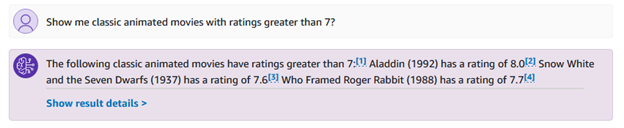
Du kan også stille mer spesifikke spørsmål knyttet til sjangere og rangeringer, for eksempel "vis meg klassiske animasjonsfilmer med rangeringer over 7?"
Utvid kunnskapsbasen din med agenter
Agenter for Amazon Bedrock hjelpe deg med å automatisere komplekse oppgaver. Agenter kan bryte ned brukerspørringen i mindre oppgaver og kalle opp tilpassede APIer eller kunnskapsbaser for å supplere informasjon for kjørende handlinger. Med Agents for Amazon Bedrock kan utviklere integrere intelligente agenter i appene sine, akselerere leveringen av AI-drevne applikasjoner og spare uker med utviklingstid. Med agenter kan du utvide kunnskapsbasen din ved å legge til mer funksjonalitet som anbefalinger fra Amazon Tilpasse for brukerspesifikke anbefalinger eller utførelse av handlinger som filtrering av filmer basert på brukerbehov.
konklusjonen
I dette innlegget viste vi hvordan du bygger en samtalefilmchatbot ved hjelp av Amazon Bedrock i noen få trinn for å svare på semantiske søk og samtaleopplevelser basert på dine egne data og IMDb og Box Office Mojo Movies/TV/OTT-lisensierte datasett. I neste innlegg går vi gjennom prosessen med å legge til mer funksjonalitet til løsningen din ved å bruke Agents for Amazon Bedrock. For å komme i gang med kunnskapsbaser på Amazon Bedrock, se Kunnskapsbaser for Amazon Bedrock.
Om forfatterne
 Gaurav Rele er senior dataforsker ved Generative AI Innovation Center, hvor han jobber med AWS-kunder på tvers av ulike vertikaler for å akselerere deres bruk av generative AI og AWS Cloud-tjenester for å løse forretningsutfordringene deres.
Gaurav Rele er senior dataforsker ved Generative AI Innovation Center, hvor han jobber med AWS-kunder på tvers av ulike vertikaler for å akselerere deres bruk av generative AI og AWS Cloud-tjenester for å løse forretningsutfordringene deres.
 Divya Bhargavi er en Senior Applied Scientist Lead ved Generative AI Innovation Center, hvor hun løser forretningsproblemer med høy verdi for AWS-kunder ved å bruke generative AI-metoder. Hun jobber med bilde/videoforståelse og gjenfinning, kunnskapsgrafforsterkede store språkmodeller og personlig tilpassede annonseringsbruk.
Divya Bhargavi er en Senior Applied Scientist Lead ved Generative AI Innovation Center, hvor hun løser forretningsproblemer med høy verdi for AWS-kunder ved å bruke generative AI-metoder. Hun jobber med bilde/videoforståelse og gjenfinning, kunnskapsgrafforsterkede store språkmodeller og personlig tilpassede annonseringsbruk.
 Suren Gunturu er en dataforsker som jobber i Generative AI Innovation Center, hvor han jobber med ulike AWS-kunder for å løse forretningsproblemer med høy verdi. Han spesialiserer seg på å bygge ML-rørledninger ved å bruke store språkmodeller, primært gjennom Amazon Bedrock og andre AWS Cloud-tjenester.
Suren Gunturu er en dataforsker som jobber i Generative AI Innovation Center, hvor han jobber med ulike AWS-kunder for å løse forretningsproblemer med høy verdi. Han spesialiserer seg på å bygge ML-rørledninger ved å bruke store språkmodeller, primært gjennom Amazon Bedrock og andre AWS Cloud-tjenester.
 Vidya Sagar Ravipati er Science Manager ved Generative AI Innovation Center, hvor han utnytter sin enorme erfaring innen distribuerte systemer i stor skala og lidenskapen hans for maskinlæring for å hjelpe AWS-kunder på tvers av ulike industrivertikaler med å akselerere deres AI og skyadopsjon.
Vidya Sagar Ravipati er Science Manager ved Generative AI Innovation Center, hvor han utnytter sin enorme erfaring innen distribuerte systemer i stor skala og lidenskapen hans for maskinlæring for å hjelpe AWS-kunder på tvers av ulike industrivertikaler med å akselerere deres AI og skyadopsjon.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/
- : har
- :er
- :hvor
- $ 10 millioner
- 000
- 1
- 10
- 100
- 11
- 118
- 12
- 13
- 360
- 385
- 60
- 7
- a
- Om oss
- akselerere
- akselerer
- adgang
- nøyaktig
- tvers
- handlinger
- aktører
- legge
- Ytterligere
- Adopsjon
- Annonsering
- agenter
- AI
- AI-drevet
- Alle
- tillater
- alene
- allerede
- også
- Amazon
- Amazon Web Services
- an
- og
- besvare
- svar
- noen
- APIer
- søknader
- anvendt
- apps
- ER
- AS
- spør
- At
- øke
- augmented
- automatisere
- automatisk
- AWS
- basen
- basert
- BE
- før du
- Milliarder
- Eske
- box office
- Break
- bygge
- Bygning
- virksomhet
- by
- ring
- som heter
- CAN
- evne
- fangst
- fange
- saken
- saker
- katalog
- sentrum
- utfordringer
- chatbot
- Velg
- valgt ut
- jul
- Classic
- Cloud
- skyadopsjon
- skytjenester
- kode
- samling
- kombinere
- kommersiell
- Selskapet
- komplekse
- Konsoll
- inneholde
- innhold
- kontekst
- kontekstuelle
- conversational
- samtaler
- korrigere
- land
- Par
- skape
- opprettet
- studiepoeng
- mannskap
- kritisk
- skikk
- kunde
- Kundedeltakelse
- Kunder
- tilpasse
- dato
- Datautveksling
- dataforsker
- Dato
- leverer
- levering
- beskrivelse
- detaljer
- utviklere
- Utvikling
- forskjellig
- regissert
- Regissør
- Styremedlemmer
- oppdage
- Funnet
- distribueres
- distribuerte systemer
- dokument
- dokumenter
- ned
- stasjonen
- eliminere
- embedding
- muliggjøre
- ende til ende
- engasjement
- berikende
- Enter
- Entertainment
- Eter (ETH)
- Hver
- eksempel
- utveksling
- erfaring
- Erfaringer
- utforske
- Noen få
- filet
- Filer
- filtrering
- Finn
- finne
- følge
- etter
- Til
- format
- fra
- fullt
- funksjonalitet
- g1
- generere
- generasjonen
- generative
- Generativ AI
- sjangere
- få
- Global
- Go
- graf
- større
- Ha
- he
- hjelpe
- høyt nivå
- hans
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- if
- implementere
- forbedre
- in
- Inkludert
- Øke
- industri
- info
- informasjon
- Innovasjon
- spørre
- integrere
- Intelligent
- hensikt
- inn
- innebærer
- IT
- jpg
- bare
- kunnskap
- maling
- Språk
- stor
- storskala
- føre
- ledende
- læring
- utnytter
- Tillatelse
- Licensed
- Lisensiering
- i likhet med
- llm
- lokal
- plassering
- lavere
- maskin
- maskinlæring
- gjøre
- administrer
- fikk til
- leder
- mange
- me
- Media
- medlemmer
- metadata
- metoder
- millioner
- ML
- modell
- modeller
- mojo
- mer
- film
- Filmer
- navn
- navn
- Naviger
- Navigasjon
- Trenger
- behov
- Ny
- neste
- natt
- of
- Office
- on
- ONE
- Opportunity
- or
- organisasjoner
- Annen
- vår
- enn
- egen
- pakke
- side
- betalt
- brød
- del
- lidenskap
- banen
- for
- utfører
- Personlig
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- plott
- Populær
- Post
- plakat
- primært
- problemer
- prosess
- produsent
- Produsentene
- proprietær
- gir
- spørsmål
- spørring
- spørsmål
- fille
- område
- priser
- vurdering
- rangeringer
- klar
- anbefaler
- Anbefaling
- anbefalinger
- rekord
- referere
- i slekt
- relevant
- Rapportering
- Krever
- svar
- svar
- Resultater
- oppbevaring
- gjenfinning
- retur
- Rolle
- RAD
- rennende
- tilfredshet
- besparende
- Vitenskap
- Forsker
- Søk
- Seksjon
- sikkert
- segmenter
- velg
- semantisk
- semantikk
- senior
- server~~POS=TRUNC
- tjeneste
- Tjenester
- innstillinger
- hun
- shot
- Vis
- presentere
- viste
- Enkelt
- simulere
- enkelt
- Størrelse
- mindre
- So
- løsning
- LØSE
- løser
- noen
- kilde
- Kilder
- spesialisert
- spesifikk
- startet
- Steps
- lagring
- oppbevare
- lagret
- rett fram
- abonnement
- slik
- supplere
- synk.
- Systemer
- Ta
- oppgaver
- teknikk
- test
- tekst
- enn
- Det
- De
- informasjonen
- deres
- Dem
- themed
- deretter
- Der.
- Disse
- de
- denne
- Gjennom
- tid
- titan
- titler
- til
- tv
- forståelse
- forstås
- ustrukturert
- up-to-date
- lastet opp
- URI
- URL
- bruke
- brukt
- Bruker
- Brukere
- ved hjelp av
- ulike
- enorme
- vertikaler
- Besøk
- W
- gå
- ønsker
- var
- we
- web
- webtjenester
- uker
- bred
- Bred rekkevidde
- vil
- med
- arbeidsflyt
- arbeid
- virker
- skrive
- X
- år
- du
- Din
- zephyrnet