Dette er et gjesteinnlegg av AK Roy fra Qualcomm AI.
Amazon Elastic Compute Cloud (Amazon EC2) DL2q-forekomster, drevet av Qualcomm AI 100 Standard-akseleratorer, kan brukes til kostnadseffektivt distribusjon av deep learning (DL) arbeidsbelastninger i skyen. De kan også brukes til å utvikle og validere ytelsen og nøyaktigheten til DL-arbeidsbelastninger som vil bli distribuert på Qualcomm-enheter. DL2q-forekomster er de første forekomstene som bringer Qualcomms kunstige intelligente (AI)-teknologi til skyen.
Med åtte Qualcomm AI 100 Standard-akseleratorer og 128 GiB totalt akseleratorminne, kan kunder også bruke DL2q-forekomster til å kjøre populære generative AI-applikasjoner, som innholdsgenerering, tekstoppsummering og virtuelle assistenter, samt klassiske AI-applikasjoner for naturlig språkbehandling og datasyn. I tillegg har Qualcomm AI 100-akseleratorer den samme AI-teknologien som brukes på smarttelefoner, autonom kjøring, personlige datamaskiner og utvidede reality-headset, slik at DL2q-forekomster kan brukes til å utvikle og validere disse AI-arbeidsbelastningene før distribusjon.
Nye DL2q-forekomsthøydepunkter
Hver DL2q-forekomst inneholder åtte Qualcomm Cloud AI100-akseleratorer, med en samlet ytelse på over 2.8 PetaOps av Int8-inferensytelse og 1.4 PetaFlops av FP16-slutningsytelse. Forekomsten har totalt 112 AI-kjerner, akseleratorminnekapasitet på 128 GB og minnebåndbredde på 1.1 TB per sekund.
Hver DL2q-forekomst har 96 vCPUer, en systemminnekapasitet på 768 GB og støtter en nettverksbåndbredde på 100 Gbps samt Amazon Elastic Block Store (Amazon EBS) lagring på 19 Gbps.
| Forekomstnavn | vCPUer | Cloud AI100 akseleratorer | Akseleratorminne | Akseleratorminne BW (aggregert) | Forekomstminne | Forekomst av nettverk | Lagringsbåndbredde (Amazon EBS). |
| DL2q.24xlarge | 96 | 8 | 128 GB | 1.088 TB / s | 768 GB | 100 Gbps | 19 Gbps |
Qualcomm Cloud AI100 akseleratorinnovasjon
Cloud AI100-akseleratoren system-på-brikke (SoC) er en spesialbygd, skalerbar flerkjernearkitektur, som støtter et bredt spekter av bruksområder for dyp læring som strekker seg fra datasenteret til kanten. SoC bruker skalar-, vektor- og tensordatakjerner med en bransjeledende SRAM-kapasitet på 126 MB. Kjernene er sammenkoblet med et nettverk-på-brikke (NoC) mesh med høy båndbredde og lav latens.
AI100-akseleratoren støtter et bredt og omfattende utvalg av modeller og bruksområder. Tabellen nedenfor fremhever rekkevidden til modellstøtten.
| Modellkategori | Rekke modeller | Eksempler |
| NLP | 157 | BERT, BART, FasterTransformer, T5, Z-kode MOE |
| Generativ AI – NLP | 40 | LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen |
| Generativ AI – bilde | 3 | Stabil diffusjon v1.5 og v2.1, OpenAI CLIP |
| CV – Bildeklassifisering | 45 | ViT, ResNet, ResNext, MobileNet, EfficientNet |
| CV – Objektdeteksjon | 23 | YOLO v2, v3, v4, v5 og v7, SSD-ResNet, RetinaNet |
| CV – Annet | 15 | LPRNet, superoppløsning/SRGAN, ByteTrack |
| Bilnettverk* | 53 | Persepsjon og LIDAR-, fotgjenger-, kjørefelt- og trafikklysdeteksjon |
| Total | > 300 â € < | â € < |
* De fleste bilnettverk er sammensatte nettverk som består av en fusjon av individuelle nettverk.
Den store SRAM-en på DL2q-akseleratoren muliggjør effektiv implementering av avanserte ytelsesteknikker som MX6 mikro-eksponentpresisjon for lagring av vekter og MX9 mikro-eksponentpresisjon for akselerator-til-akselerator-kommunikasjon. Mikro-eksponentteknologien er beskrevet i følgende Open Compute Project (OCP) bransjekunngjøring: AMD, Arm, Intel, Meta, Microsoft, NVIDIA og Qualcomm standardiserer neste generasjons smale presisjonsdataformater for AI » Open Compute Project.
Forekomstbrukeren kan bruke følgende strategi for å maksimere ytelsen per kostnad:
- Lagre vekter ved hjelp av MX6 mikro-eksponentpresisjon i DDR-minnet på akseleratoren. Bruk av MX6-presisjon maksimerer utnyttelsen av den tilgjengelige minnekapasiteten og minnebåndbredden for å levere klassens beste gjennomstrømning og ventetid.
- Beregn i FP16 for å levere den nødvendige nøyaktigheten til brukstilfeller, mens du bruker den overlegne SRAM-en på brikken og ekstra TOP-er på kortet, for å implementere høyytelses MX6 til FP16-kjerner med lav latens.
- Bruk en optimalisert batchstrategi og en høyere batchstørrelse ved å bruke den store SRAM-en på brikken som er tilgjengelig for å maksimere gjenbruken av vekter, samtidig som aktiveringene på brikken beholdes maksimalt.
DL2q AI Stack og verktøykjede
DL2q-forekomsten er ledsaget av Qualcomm AI Stack som gir en konsistent utvikleropplevelse på tvers av Qualcomm AI i skyen og andre Qualcomm-produkter. Den samme Qualcomm AI stack and base AI-teknologien kjører på DL2q-forekomster og Qualcomm edge-enheter, og gir kundene en konsistent utvikleropplevelse, med en enhetlig API på tvers av deres sky-, bil-, personlige datamaskin-, utvidede virkelighets- og smarttelefonutviklingsmiljøer.
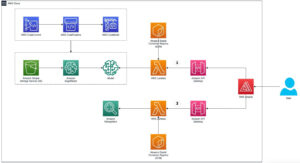
Verktøykjeden gjør det mulig for instansbrukeren å raskt ombord på en tidligere opplært modell, kompilere og optimalisere modellen for instansfunksjonene, og deretter distribuere de kompilerte modellene for brukstilfeller for produksjonsslutninger i tre trinn vist i følgende figur.

For å lære mer om hvordan du justerer ytelsen til en modell, se Cloud AI 100 Key Performance Parameters Dokumentasjon.
Kom i gang med DL2q-forekomster
I dette eksemplet kompilerer og distribuerer du en forhåndsopplært BERT modell fra Klemme ansiktet på en EC2 DL2q-forekomst ved hjelp av en forhåndsbygd tilgjengelig DL2q AMI, i fire trinn.
Du kan bruke enten en forhåndsbygd Qualcomm DLAMI på forekomsten eller start med en Amazon Linux2 AMI og bygg din egen DL2q AMI med Cloud AI 100 Platform og Apps SDK tilgjengelig i denne Amazon Simple Storage Service (Amazon S3) bøtte: s3://ec2-linux-qualcomm-ai100-sdks/latest/.
Trinnene som følger bruker den forhåndsbygde DL2q AMI, Qualcomm Base AL2 DLAMI.
Bruk SSH for å få tilgang til DL2q-forekomsten din med Qualcomm Base AL2 DLAMI AMI og følg trinn 1 til 4.
Trinn 1. Sett opp miljøet og installer nødvendige pakker
- Installer Python 3.8.
- Sett opp det virtuelle Python 3.8-miljøet.
- Aktiver det virtuelle Python 3.8-miljøet.
- Installer de nødvendige pakkene, vist i krav.txt-dokument tilgjengelig på Qualcomm offentlige Github-nettsted.
- Importer de nødvendige bibliotekene.
Trinn 2. Importer modellen
- Importer og tokeniser modellen.
- Definer en prøveinngang og trekk ut
inputIdsogattentionMask. - Konverter modellen til ONNX, som deretter kan sendes til kompilatoren.
- Du vil kjøre modellen i FP16-presisjon. Så du må sjekke om modellen inneholder konstanter utenfor FP16-området. Send modellen til
fix_onnx_fp16funksjon for å generere den nye ONNX-filen med de nødvendige rettelsene.
Trinn 3. Kompiler modellen
De qaic-exec kommandolinjegrensesnitt (CLI) kompilatorverktøy brukes til å kompilere modellen. Inndata til denne kompilatoren er ONNX-filen generert i trinn 2. Kompilatoren produserer en binær fil (kalt QPCFor Qualcomm-programbeholder) i banen definert av -aic-binary-dir argument.
I kompileringskommandoen nedenfor bruker du fire AI-beregningskjerner og en batchstørrelse på én for å kompilere modellen.
QPC genereres i bert-base-cased/generatedModels/bert-base-cased_fix_outofrange_fp16_qpc mappe.
Trinn 4. Kjør modellen
Sett opp en økt for å kjøre slutningen på en Cloud AI100 Qualcomm-akselerator i DL2q-forekomsten.
Qualcomm qaic Python-biblioteket er et sett med APIer som gir støtte for å kjøre slutninger på Cloud AI100-akseleratoren.
- Bruk Session API-kallet til å opprette en sesjonsforekomst. Session API-kallet er inngangspunktet for å bruke qaic Python-biblioteket.
- Omstrukturer dataene fra utgangsbuffer med
output_shapeogoutput_type. - Dekode utgangen som produseres.
Her er utdataene for inngangssetningen "Hunden [MASK] på matten."
Det er det. Med bare noen få trinn kompilerte og kjørte du en PyTorch-modell på en Amazon EC2 DL2q-forekomst. For å lære mer om onboarding og kompilering av modeller på DL2q-forekomsten, se Cloud AI100 opplæringsdokumentasjon.
For å lære mer om hvilke DL-modellarkitekturer som passer godt for AWS DL2q-forekomster og gjeldende modellstøttematrise, se Qualcomm Cloud AI100 dokumentasjon.
Tilgjengelig nå
Du kan lansere DL2q-forekomster i dag i AWS-regionene i USA vest (Oregon) og Europa (Frankfurt) som På etterspørsel, RESERVERTog Spotforekomster, eller som en del av en Spareplan. Som vanlig med Amazon EC2 betaler du kun for det du bruker. For mer informasjon, se Amazon EC2-priser.
DL2q-forekomster kan distribueres ved hjelp av AWS Deep Learning AMI (DLAMI), og containerbilder er tilgjengelige gjennom administrerte tjenester som Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS)og AWS ParallelCluster.
For å lære mer, besøk Amazon EC2 DL2q-forekomst side, og send tilbakemelding til AWS re: Post for EC2 eller gjennom dine vanlige AWS -støttekontakter.
Om forfatterne
 AK Roy er direktør for produktadministrasjon hos Qualcomm, for Cloud and Datacenter AI-produkter og -løsninger. Han har over 20 års erfaring innen produktstrategi og utvikling, med det nåværende fokuset på klassens beste ytelse og ytelse/$ ende-til-ende-løsninger for AI-slutning i skyen, for det brede spekteret av brukstilfeller, inkludert GenAI, LLMs, Auto og Hybrid AI.
AK Roy er direktør for produktadministrasjon hos Qualcomm, for Cloud and Datacenter AI-produkter og -løsninger. Han har over 20 års erfaring innen produktstrategi og utvikling, med det nåværende fokuset på klassens beste ytelse og ytelse/$ ende-til-ende-løsninger for AI-slutning i skyen, for det brede spekteret av brukstilfeller, inkludert GenAI, LLMs, Auto og Hybrid AI.
 Jianying Lang er en Principal Solutions Architect ved AWS Worldwide Specialist Organization (WWSO). Hun har over 15 års arbeidserfaring innen HPC og AI-feltet. Hos AWS fokuserer hun på å hjelpe kunder med å distribuere, optimalisere og skalere AI/ML-arbeidsmengdene deres på akselererte databehandlingsinstanser. Hun brenner for å kombinere teknikkene innen HPC og AI-felt. Jianying har en doktorgrad i beregningsfysikk fra University of Colorado i Boulder.
Jianying Lang er en Principal Solutions Architect ved AWS Worldwide Specialist Organization (WWSO). Hun har over 15 års arbeidserfaring innen HPC og AI-feltet. Hos AWS fokuserer hun på å hjelpe kunder med å distribuere, optimalisere og skalere AI/ML-arbeidsmengdene deres på akselererte databehandlingsinstanser. Hun brenner for å kombinere teknikkene innen HPC og AI-felt. Jianying har en doktorgrad i beregningsfysikk fra University of Colorado i Boulder.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/amazon-ec2-dl2q-instance-for-cost-efficient-high-performance-ai-inference-is-now-generally-available/
- : har
- :er
- $OPP
- 1
- 1 TB
- 10
- 100
- 11
- 12
- 13
- 15 år
- 15%
- 17
- 19
- 20
- 20 år
- 22
- 23
- 46
- 7
- 75
- 8
- 84
- a
- Om oss
- ovenfor
- akselerert
- akselerator
- akseleratorer
- adgang
- ledsaget
- nøyaktighet
- tvers
- aktiveringer
- I tillegg
- avansert
- aggregat
- AI
- AI / ML
- Alle
- også
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- og
- Kunngjøring
- noen
- api
- APIer
- søknader
- apps
- arkitektur
- ER
- argument
- ARM
- kunstig
- AS
- assistenter
- At
- auto
- automotive
- autonom
- tilgjengelig
- AWS
- AKSER
- Båndbredde
- basen
- batching
- BE
- før du
- under
- Beyond
- BIN
- Blokker
- Bloom
- bringe
- bred
- buffer
- bygge
- by
- ring
- som heter
- CAN
- evner
- Kapasitet
- kort
- saken
- sjekk
- Classic
- Cloud
- Colorado
- kombinere
- Kommunikasjon
- kompilert
- omfattende
- beregnings
- Beregn
- datamaskin
- Datamaskin syn
- datamaskiner
- databehandling
- konsistent
- Består
- kontakter
- Container
- inneholder
- innhold
- skape
- Gjeldende
- Kunder
- dato
- Datacenter
- dyp
- dyp læring
- definert
- Grad
- leverer
- leverer
- utplassere
- utplassert
- distribusjon
- beskrevet
- utvikle
- Utvikler
- Utvikling
- enhet
- Enheter
- kringkasting
- Regissør
- dokumentasjon
- Hund
- kjøring
- dynamisk
- ebs
- Edge
- effektiv
- enten
- anvender
- muliggjør
- ende til ende
- entry
- Miljø
- miljøer
- Eter (ETH)
- Europa
- eksempel
- erfaring
- utvidet virkelighet
- trekke ut
- falsk
- Trekk
- tilbakemelding
- Noen få
- felt
- Felt
- Figur
- filet
- Først
- passer
- reparasjoner
- Fokus
- fokuserer
- følge
- etter
- Til
- funnet
- fire
- Frankfurt
- fra
- funksjon
- fusjon
- generelt
- generere
- generert
- generasjonen
- generative
- Generativ AI
- GitHub
- gitt
- god
- Gjest
- gjest innlegg
- he
- hodetelefoner
- hjelpe
- her.
- høy ytelse
- høyere
- striper
- holder
- hpc
- HTML
- HTTPS
- Hybrid
- i
- iDX
- if
- bilde
- bilder
- iverksette
- gjennomføring
- importere
- in
- Inkludert
- inkorporerer
- individuelt
- industri
- bransjeledende
- informasjon
- inngang
- installere
- f.eks
- forekomster
- Intel
- Intelligent
- sammenhengende
- Interface
- IT
- jpg
- bare
- nøkkel
- Kubernetes
- Lane
- Språk
- stor
- Ventetid
- lansere
- LÆRE
- læring
- bibliotekene
- Bibliotek
- håndtere
- lett
- linje
- laster
- fikk til
- ledelse
- maske
- Matrix
- max
- Maksimer
- Maksimerer
- maksimal
- Minne
- mesh
- Meta
- Microsoft
- minutter
- modell
- modeller
- modifisert
- mer
- mest
- navn
- Naturlig
- Naturlig språk
- Natural Language Processing
- nødvendig
- Trenger
- nettverk
- nettverk
- nettverk
- Ny
- neste generasjon
- nå
- følelsesløs
- Nvidia
- objekt
- of
- on
- Ombord
- onboarding
- ONE
- bare
- åpen
- OpenAI
- Optimalisere
- optimalisert
- or
- Oregon
- organisasjon
- OS
- Annen
- ut
- produksjon
- utganger
- enn
- egen
- pakker
- side
- del
- passere
- bestått
- lidenskapelig
- banen
- Betale
- for
- ytelse
- personlig
- Personlige datamaskiner
- phd
- Fysikk
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Point
- Populær
- mulig
- Post
- powered
- Precision
- tidligere
- Principal
- prosessering
- produsert
- produserer
- Produkt
- produktledelse
- Produksjon
- Produkter
- program
- prosjekt
- gir
- gi
- offentlig
- Python
- pytorch
- Qualcomm
- raskt
- område
- RE
- Lesning
- Reality
- regioner
- påkrevd
- Krav
- støttemur
- retur
- gjenbruk
- roy
- Kjør
- rennende
- går
- samme
- Spar
- besparende
- skalerbar
- Skala
- SDK
- Sekund
- se
- send
- dømme
- Sequence
- tjeneste
- Tjenester
- Session
- sett
- hun
- vist
- Enkelt
- forenkle
- nettstedet
- Størrelse
- smarttelefon
- smartphones
- So
- Solutions
- Spenning
- spesialist
- stable
- Standard
- Begynn
- startet
- Trinn
- Steps
- lagring
- oppbevare
- Strategi
- I ettertid
- slik
- overlegen
- støtte
- Støtte
- Støtter
- system
- bord
- teknikker
- Teknologi
- tekst
- Det
- De
- deres
- deretter
- Disse
- de
- denne
- tre
- Gjennom
- gjennomstrømning
- thru
- til
- i dag
- symbolisere
- verktøy
- Topper
- lommelykt
- Totalt
- trafikk
- trent
- transformers
- sant
- tutorial
- enhetlig
- universitet
- us
- bruke
- bruk sak
- bruk-tilfeller
- brukt
- Bruker
- ved hjelp av
- vanlig
- v1
- VAL
- VALIDERE
- verdi
- virtuelle
- syn
- Besøk
- we
- web
- webtjenester
- VI VIL
- Vest
- Hva
- hvilken
- mens
- bred
- Bred rekkevidde
- vil
- med
- ord
- arbeid
- verdensomspennende
- år
- du
- Din
- zephyrnet