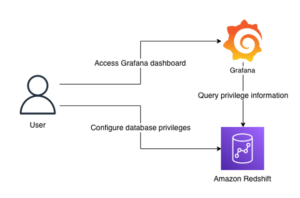
Amazonas Athena er en interaktiv spørringstjeneste som gjør det enkelt å analysere data i Amazon enkel lagringstjeneste (Amazon S3) og datakilder som ligger i AWS, lokale eller andre skysystemer som bruker SQL eller Python. Athena er bygget på Trino- og Presto-motorer med åpen kildekode, og Apache Spark-rammeverk, uten at det er nødvendig med klargjøring eller konfigurasjon. Athena er serverløs, så det er ingen infrastruktur å administrere, og du betaler kun for spørringene du kjører.
Apache isfjell er et åpent tabellformat for svært store analytiske datasett. Den administrerer store samlinger av filer som tabeller, og den støtter moderne analytiske datainnsjøoperasjoner som innsetting, oppdatering, sletting og tidsreisespørringer på rekordnivå. Athena støtter lese-, tidsreise-, skrive- og DDL-spørringer for Apache Iceberg-tabeller som bruker Apache Parquet-formatet for data og AWS Lim Data Catalog for deres metastore.
Funksjonsteknikk er en prosess med å identifisere og transformere rådata (bilder, tekstfiler, videoer og så videre), fylle ut manglende data og legge til ett eller flere meningsfulle dataelementer for å gi kontekst slik at en maskinlæringsmodell (ML) kan lære av dem. Datamerking er nødvendig for ulike brukstilfeller, inkludert prognoser, datasyn, naturlig språkbehandling og talegjenkjenning.
Kombinert med egenskapene til Athena, leverer Apache Iceberg en forenklet arbeidsflyt for dataforskere for å lage nye datafunksjoner uten å måtte kopiere eller gjenskape hele datasettet. Du kan lage funksjoner ved å bruke standard SQL på Athena uten å bruke noen annen tjeneste for funksjonsutvikling. Dataforskere kan redusere tiden brukt på å forberede og kopiere datasett, og i stedet fokusere på datafunksjonsteknikk, eksperimentering og analyse av data i stor skala.
I dette innlegget gjennomgår vi fordelene ved å bruke Athena med Apache Iceberg åpne tabellformat og hvordan det forenkler vanlige funksjonsingeniøroppgaver for dataforskere. Vi demonstrerer hvordan Athena kan konvertere en eksisterende tabell i Apache Iceberg-format, deretter legge til kolonner, slette kolonner og endre dataene i tabellen uten å gjenskape eller kopiere datasettet, og bruke disse egenskapene til å lage nye funksjoner på Apache Iceberg-tabeller.
Løsningsoversikt
Dataforskere er generelt vant til å jobbe med store datasett. Datasett lagres vanligvis i enten JSON, CSV, ORC eller Apache Parkett format, eller lignende leseoptimaliserte formater for rask leseytelse. Dataforskere lager ofte nye datafunksjoner, og fyller ut slike datafunksjoner med aggregerte og tilleggsdata. Historisk sett ble denne oppgaven oppnådd ved å lage en visning på toppen av tabellen med de underliggende dataene i Apache Parquet-format, hvor slike kolonner og data ble lagt til under kjøring eller ved å lage en ny tabell med flere kolonner. Selv om denne arbeidsflyten er godt egnet for mange brukstilfeller, er den ineffektiv for store datasett, fordi data må genereres på kjøretid eller datasett må kopieres og transformeres.
Athena har introdusert ACID (Atomicitet, Konsistens, Isolasjon, Holdbarhet) transaksjon funksjoner som legger til INSERT, UPDATE, DELETE, MERGE og tidsreiseoperasjoner bygget på Apache Iceberg-bord. Disse egenskapene gjør det mulig for dataforskere å lage nye datafunksjoner og slippe eksisterende datafunksjoner på eksisterende datasett uten å bekymre seg for å kopiere eller transformere datasettet eller abstrahere det med en visning. Dataforskere kan fokusere på funksjonsingeniørarbeid og unngå å kopiere og transformere datasettene.
Athena Iceberg UPDATE-operasjonen skriver Apache Iceberg-posisjonsslettefiler og nylig oppdaterte rader som datafiler i samme transaksjon. Du kan gjøre postkorreksjoner via en enkelt UPDATE-setning.
Med utgivelsen av Athena engine versjon 3, forbedres mulighetene for Apache Iceberg-bord med støtte for operasjoner som f.eks. OPPRETT TABELL SOM SELECT (CTAS) og MERGE-kommandoer som strømlinjeformer livssyklusadministrasjonen til dine Iceberg-data. CTAS gjør det raskt og effektivt å lage tabeller fra andre formater som Apache Paquet og SLÅ TIL betingede oppdateringer, sletter eller setter inn rader i en Iceberg-tabell. En enkelt setning kan kombinere handlinger for oppdatering, sletting og innsetting.
Forutsetninger
Sett opp en Athena-arbeidsgruppe med Athena-motor versjon 3 for å bruke CTAS- og MERGE-kommandoer med et Apache Iceberg-bord. For å oppgradere din eksisterende Athena-motor til versjon 3 i din Athena-arbeidsgruppe, følg instruksjonene i Oppgrader til Athena-motorversjon 3 for å øke søkeytelsen og få tilgang til flere analysefunksjoner eller referer til Endring av motorversjon i Athena-konsollen.
datasett
For demonstrasjon bruker vi et Apache Parquet-bord som inneholder flere millioner poster med tilfeldig distribuerte fiktive salgsdata fra de siste årene lagret i en S3-bøtte. Last ned datasettet, pakk det ut til din lokale datamaskin og last det opp til S3-bøtten. I dette innlegget lastet vi opp datasettet vårt til s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
Tabellen nedenfor viser oppsettet for tabellen customer_orders.
| Kolonnenavn | Data-type | Beskrivelse |
| ordrenøkkel | string | Ordrenummer for bestillingen |
| betjeningsnøkkel | string | Kundeidentifikasjonsnummer |
| ordre status | string | Status for bestillingen |
| totalpris | string | Totalpris på bestillingen |
| bestillingsdato | string | Dato for bestillingen |
| ordreprioritet | string | Bestillingens prioritet |
| kontorist | string | Navn på ekspeditøren som behandlet bestillingen |
| skipsprioritet | string | Prioritet på frakt |
| navn | string | Kundenavn |
| adresse | string | Kundeadresse |
| nasjonsnøkkel | string | Kundens nasjonsnøkkel |
| telefon | string | Kundens telefonnummer |
| acctbal | string | Kundekontosaldo |
| mktsegment | string | Kundemarkedssegment |
Utfør funksjonsteknikk
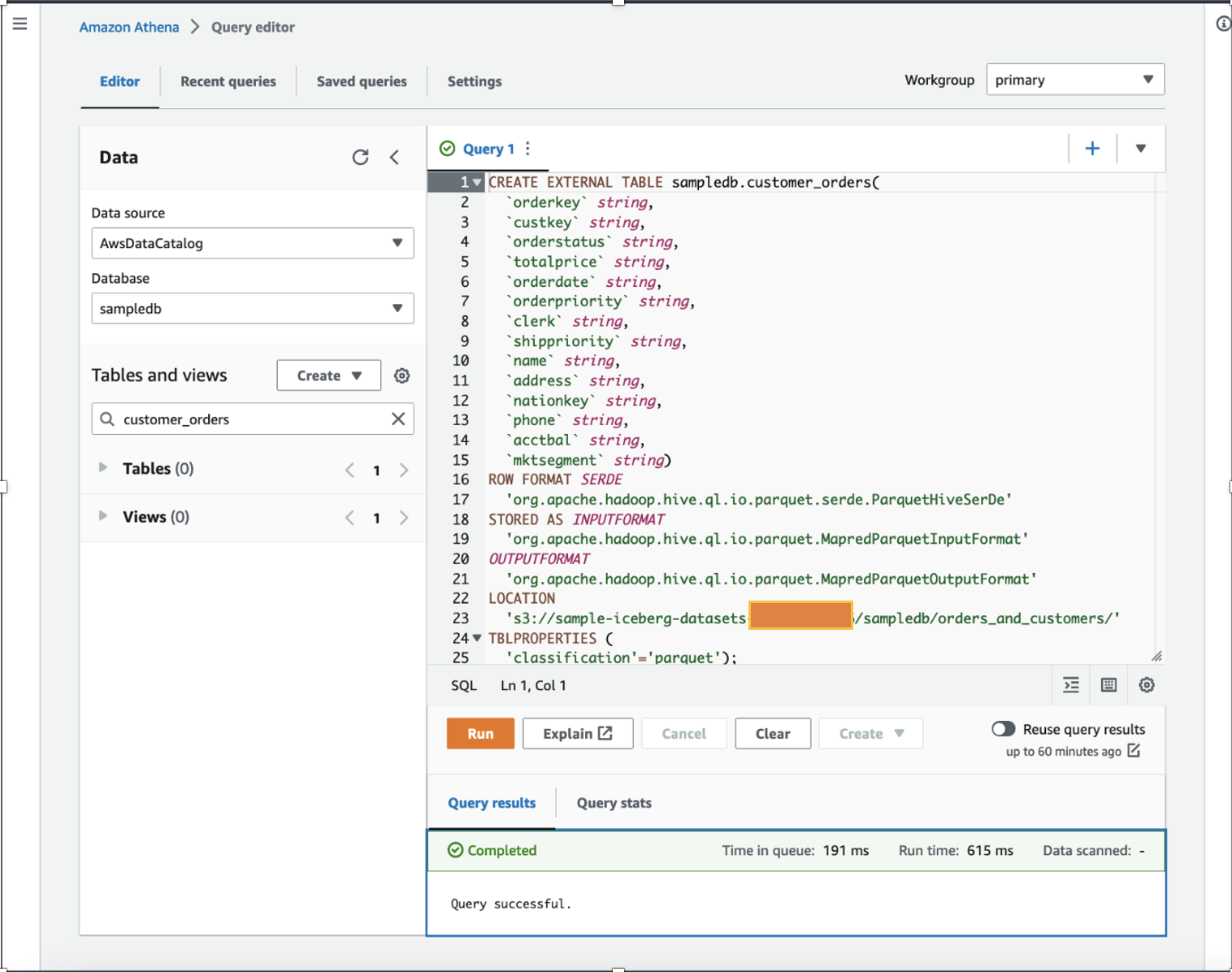
Som dataforsker ønsker vi å prestere funksjonsteknikk på kundeordredata ved å legge til beregnede ett års totale kjøp og ett års gjennomsnittlig kjøp for hver kunde i det eksisterende datasettet. For demonstrasjonsformål laget vi customer_orders bordet i sampledb database ved hjelp av Athena som vist i følgende DDL-kommando. (Du kan bruke hvilket som helst av dine eksisterende datasett og følge trinnene nevnt i dette innlegget.) The customer_orders datasettet ble generert og lagret i S3-bøtteplasseringen s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ i parkettformat. Dette bordet er ikke et Apache Iceberg-bord.
![]()
Valider dataene i tabellen ved å kjøre en spørring:
![]()
Vi ønsker å legge til nye funksjoner i denne tabellen for å få en dypere forståelse av kundesalg, noe som kan resultere i raskere modellopplæring og mer verdifull innsikt. For å legge til nye funksjoner i datasettet, konverter customer_orders Athena-bord til Apache Iceberg-bord på Athena. Utgave a CTAS spørringssetning for å lage en ny tabell med Apache Iceberg-format fra customer_orders bord. Mens du gjør det, legges en ny funksjon til for å få det totale kjøpsbeløpet det siste året (maks. år for datasettet) av hver kunde.
I følgende CTAS-spørring heter en ny kolonne one_year_sales_aggregate med standardverdien som 0.0 av datatype double legges til og table_type er satt til ICEBERG:
![]()
Utfør følgende spørring for å bekrefte dataene i Apache Iceberg-tabellen med den nye kolonnen one_year_sales_aggregate verdier som 0.0:
![]()
Vi ønsker å fylle ut verdiene for den nye funksjonen one_year_sales_aggregate i datasettet for å få det totale kjøpsbeløpet for hver kunde basert på deres kjøp det siste året (maks. år for datasettet). Utsted en MERGE-spørringssetning til Apache Iceberg-tabellen ved å bruke Athena til å fylle ut verdier for one_year_sales_aggregate funksjon:
![]()
Send følgende spørring for å validere den oppdaterte verdien for totalt forbruk av hver kunde i det siste året:
![]()
Vi bestemmer oss for å legge til en annen funksjon på et eksisterende Apache Iceberg-bord for å beregne og lagre gjennomsnittlig kjøpsbeløp i det siste året for hver kunde. Utsted en ALTER-spørringssetning for å legge til en ny kolonne i en eksisterende tabell for funksjon one_year_sales_average:
![]()
Før du fyller ut verdiene til denne nye funksjonen, kan du angi standardverdien for funksjonen one_year_sales_average til 0.0. Bruk den samme Apache Iceberg-tabellen på Athena, utsted en UPDATE-spørringserklæring for å fylle ut verdien for den nye funksjonen som 0.0:
![]()
Send følgende spørring for å bekrefte at den oppdaterte verdien for gjennomsnittlig forbruk for hver kunde i det siste året er satt til 0.0:
![]()
Nå ønsker vi å fylle ut verdiene for den nye funksjonen one_year_sales_average i datasettet for å få gjennomsnittlig kjøpsbeløp for hver kunde basert på deres kjøp det siste året (maks år for datasettet). Utsted en MERGE-spørringserklæring til den eksisterende Apache Iceberg-tabellen på Athena ved å bruke Athena-motoren for å fylle ut verdier for funksjonen one_year_sales_average:
![]()
Send følgende spørring for å bekrefte de oppdaterte verdiene for gjennomsnittlig forbruk for hver kunde:
![]()
Når ytterligere datafunksjoner er lagt til datasettet, fortsetter dataforskere vanligvis med å trene ML-modeller og gjøre slutninger ved å bruke Amazon Sagemaker eller tilsvarende verktøysett.
konklusjonen
I dette innlegget demonstrerte vi hvordan du utfører funksjonsteknikk ved å bruke Athena med Apache Iceberg. Vi demonstrerte også bruk av CTAS-spørringen for å lage en Apache Iceberg-tabell på Athena fra et eksisterende datasett i Apache Parquet-format, legge til nye funksjoner i en eksisterende Apache Iceberg-tabell på Athena ved å bruke ALTER-spørringen, og bruke UPDATE- og MERGE-spørringssetninger for å oppdatere funksjonsverdier for eksisterende kolonner.
Vi oppfordrer deg til å bruke CTAS-spørringer for å lage tabeller raskt og effektivt, og bruke MERGE-spørringssetningen til å synkronisere tabeller i ett trinn for å forenkle dataforberedelser og oppdateringsoppgaver når du transformerer funksjonene ved å bruke Athena med Apache Iceberg. Hvis du har kommentarer eller tilbakemeldinger, vennligst legg dem igjen i kommentarfeltet.
Om forfatterne
![]() Vivek Gautam er en dataarkitekt med spesialisering i datainnsjøer ved AWS Professional Services. Han jobber med bedriftskunder som bygger dataprodukter, analyseplattformer og løsninger på AWS. Når vi ikke bygger og designer moderne dataplattformer, er Vivek en matentusiast som også liker å utforske nye reisemål og gå på fotturer.
Vivek Gautam er en dataarkitekt med spesialisering i datainnsjøer ved AWS Professional Services. Han jobber med bedriftskunder som bygger dataprodukter, analyseplattformer og løsninger på AWS. Når vi ikke bygger og designer moderne dataplattformer, er Vivek en matentusiast som også liker å utforske nye reisemål og gå på fotturer.
![]() Mikhail Vaynshteyn er en løsningsarkitekt med Amazon Web Services. Mikhail jobber med kunder innen helsevesen og biovitenskap for å bygge løsninger som bidrar til å forbedre pasientenes resultater. Mikhail spesialiserer seg på dataanalysetjenester.
Mikhail Vaynshteyn er en løsningsarkitekt med Amazon Web Services. Mikhail jobber med kunder innen helsevesen og biovitenskap for å bygge løsninger som bidrar til å forbedre pasientenes resultater. Mikhail spesialiserer seg på dataanalysetjenester.
![]() Naresh Gautam er en dataanalyse- og AI/ML-leder hos AWS med 20 års erfaring, som liker å hjelpe kunder med å bygge svært tilgjengelige, høyytelseseffektive og kostnadseffektive dataanalyse- og AI/ML-løsninger for å styrke kundene med datadrevet beslutningstaking . På fritiden liker han å meditere og lage mat.
Naresh Gautam er en dataanalyse- og AI/ML-leder hos AWS med 20 års erfaring, som liker å hjelpe kunder med å bygge svært tilgjengelige, høyytelseseffektive og kostnadseffektive dataanalyse- og AI/ML-løsninger for å styrke kundene med datadrevet beslutningstaking . På fritiden liker han å meditere og lage mat.
![]() Harsha Tadiparthi er en spesialist Principal Solutions Architect, Analytics ved AWS. Han liker å løse komplekse kundeproblemer i databaser og analyser og levere vellykkede resultater. Utenom jobben elsker han å tilbringe tid med familien, se filmer og reise når det er mulig.
Harsha Tadiparthi er en spesialist Principal Solutions Architect, Analytics ved AWS. Han liker å løse komplekse kundeproblemer i databaser og analyser og levere vellykkede resultater. Utenom jobben elsker han å tilbringe tid med familien, se filmer og reise når det er mulig.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- EVM Finans. Unified Interface for desentralisert økonomi. Tilgang her.
- Quantum Media Group. IR/PR forsterket. Tilgang her.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 10
- 100
- 12
- 17
- 20
- 20 år
- 23
- 27
- 7
- a
- Om oss
- akselerere
- adgang
- oppnådd
- Logg inn
- handlinger
- legge til
- la til
- legge
- Ytterligere
- adresse
- AI / ML
- også
- Selv
- Amazon
- Amazonas Athena
- Amazon SageMaker
- Amazon Web Services
- beløp
- an
- analytisk
- Analytisk
- analytics
- analysere
- analyserer
- og
- En annen
- noen
- Apache
- Apache Spark
- ER
- AS
- At
- tilgjengelig
- gjennomsnittlig
- unngå
- AWS
- AWS profesjonelle tjenester
- basert
- BE
- fordi
- vært
- Fordeler
- bygge
- Bygning
- bygget
- by
- beregnet
- CAN
- evner
- saker
- klassifisering
- Cloud
- samlinger
- Kolonne
- kolonner
- kombinere
- kommentarer
- Felles
- komplekse
- Beregn
- datamaskin
- Datamaskin syn
- Konfigurasjon
- inneholder
- kontekst
- konvertere
- matlaging
- kopiering
- Korreksjoner
- kostnadseffektiv
- skape
- opprettet
- Opprette
- kunde
- Kunder
- dato
- Data Analytics
- Data Lake
- datavitenskap
- dataforsker
- data-drevet
- Database
- databaser
- datasett
- Dato
- bestemme
- Beslutningstaking
- dypere
- Misligholde
- levere
- leverer
- demonstrere
- demonstrert
- utforme
- destinasjoner
- distribueres
- gjør
- dobbelt
- Drop
- slitestyrke
- hver enkelt
- lett
- effektiv
- effektivt
- innsats
- enten
- elementer
- bemyndige
- muliggjøre
- oppmuntre
- Motor
- Ingeniørarbeid
- Motorer
- forbedret
- Enterprise
- bedriftskunder
- entusiast
- Hele
- Tilsvarende
- Eter (ETH)
- eksisterende
- erfaring
- utforske
- utvendig
- falsk
- familie
- FAST
- raskere
- Trekk
- Egenskaper
- tilbakemelding
- Filer
- Fokus
- følge
- etter
- mat
- Til
- format
- rammer
- Gratis
- fra
- generelt
- generert
- få
- Go
- Gruppe
- Hadoop
- Ha
- he
- helsetjenester
- hjelpe
- hjelpe
- høy ytelse
- svært
- turer
- hans
- historisk
- Hive
- Hvordan
- Hvordan
- HTML
- HTTPS
- Identifikasjon
- identifisering
- if
- bilder
- forbedre
- in
- Inkludert
- Øke
- ineffektiv
- Infrastruktur
- Setter inn
- innsikt
- i stedet
- instruksjoner
- interaktiv
- inn
- introdusert
- isolasjon
- utstedelse
- IT
- jpg
- JSON
- merking
- innsjø
- Språk
- stor
- Siste
- Layout
- leder
- LÆRE
- læring
- Permisjon
- Life
- Life Sciences
- Livssyklus
- BEGRENSE
- lokal
- plassering
- elsker
- maskin
- maskinlæring
- gjøre
- GJØR AT
- administrer
- ledelse
- forvalter
- mange
- marked
- matchet
- max
- meningsfylt
- Meditasjon
- nevnt
- Flett
- millioner
- mangler
- ML
- modell
- modeller
- Moderne
- modifisere
- mer
- Filmer
- navn
- oppkalt
- nasjon
- Naturlig
- Naturlig språk
- Natural Language Processing
- Trenger
- trenger
- Ny
- ny funksjon
- Nye funksjoner
- nylig
- Nei.
- Antall
- of
- ofte
- on
- ONE
- bare
- åpen
- åpen kildekode
- drift
- Drift
- or
- ordrer
- Annen
- vår
- utfall
- utenfor
- Past
- Betale
- utføre
- ytelse
- telefon
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- posisjon
- mulig
- Post
- forbereder
- pris
- Principal
- problemer
- prosess
- behandlet
- prosessering
- Produkter
- profesjonell
- gi
- Kjøp
- kjøp
- formål
- Python
- spørsmål
- raskt
- Raw
- rådata
- Lese
- anerkjennelse
- rekord
- poster
- redusere
- slipp
- påkrevd
- resultere
- anmeldelse
- RAD
- Kjør
- rennende
- sagemaker
- salg
- samme
- Skala
- Vitenskap
- VITENSKAPER
- Forsker
- forskere
- Seksjon
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- flere
- vist
- Viser
- lignende
- Enkelt
- forenklet
- forenkle
- enkelt
- So
- Solutions
- løse
- Kilder
- Spark
- spesialist
- spesialisert
- tale
- Talegjenkjenning
- bruke
- brukt
- SQL
- Standard
- Uttalelse
- uttalelser
- Trinn
- Steps
- lagring
- oppbevare
- lagret
- effektivisere
- String
- vellykket
- slik
- støtte
- Støtter
- Systemer
- bord
- Oppgave
- oppgaver
- Det
- De
- Sammenslåingen
- deres
- Dem
- deretter
- Der.
- Disse
- denne
- tid
- tidsreiser
- til
- topp
- Totalt
- Tog
- Kurs
- Transaksjonen
- transaksjonell
- forvandlet
- transformere
- reiser
- typen
- underliggende
- forståelse
- Oppdater
- oppdatert
- oppdateringer
- oppgradering
- lastet opp
- bruke
- ved hjelp av
- vanligvis
- VALIDERE
- Verdifull
- verdi
- Verdier
- ulike
- verifisere
- versjon
- veldig
- av
- videoer
- Se
- syn
- ønsker
- var
- Se
- we
- web
- webtjenester
- var
- når
- når som helst
- hvilken
- mens
- HVEM
- med
- uten
- Arbeid
- arbeidsflyt
- arbeidsgruppe
- arbeid
- virker
- ville
- skrive
- år
- år
- du
- Din
- zephyrnet
- Zip