15 Python -utdrag for å optimalisere datavitenskapsledningen
Raske Python-løsninger for å hjelpe datavitenskapen din til å syklus.
By Lucas Soares, Maskinlæringsingeniør ved K1 Digital

Photo by Carlos muza on Unsplash
Hvorfor utdrag er viktige for datavitenskap
I min daglige rutine må jeg håndtere mye av de samme situasjonene fra å laste inn csv-filer til å visualisere data. Så, for å hjelpe til med å strømlinjeforme prosessen min, skapte jeg en vane med å lagre kodebiter som er nyttige i forskjellige situasjoner fra lasting av csv-filer til visualisering av data.
I dette innlegget vil jeg dele 15 kodebiter for å hjelpe med ulike aspekter av dataanalysepipeline
1. Laster flere filer med glob- og listeforståelse
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]2. Hente unike verdier fra en kolonnetabell
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'], dtype=object)3. Vis panda-datarammer side ved side
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])): # source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side html_str='' for df,title in zip(args, chain(titles,cycle(['</br>'])) ): html_str+='<th style="text-align:center"><td style="vertical-align:top">' html_str+="<br>" html_str+=f'<h2>{title}</h2>' html_str+=df.to_html().replace('table','table style="display:inline"') html_str+='</td></th>' display_html(html_str,raw=True)
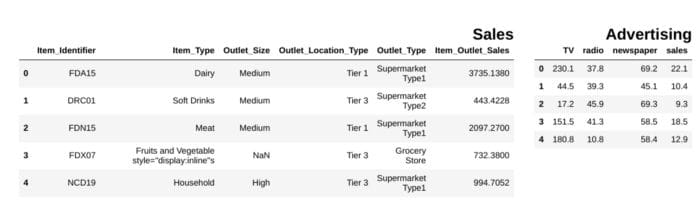
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
bilde av forfatteren
4. Fjern alle NaN i pandas dataramme
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. Vis antall NaN-oppføringer i DataFrame-kolonner
def findNaNCols(df): for col in df: print(f"Column: {col}") num_NaNs = df[col].isnull().sum() print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 26. Transformering av kolonner med .apply og lambda-funksjoner
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df

7. Transformere 2 DataFrame-kolonner til en ordbok
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}8. Plotte rutenett av fordelinger med betingelser på kolonner
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
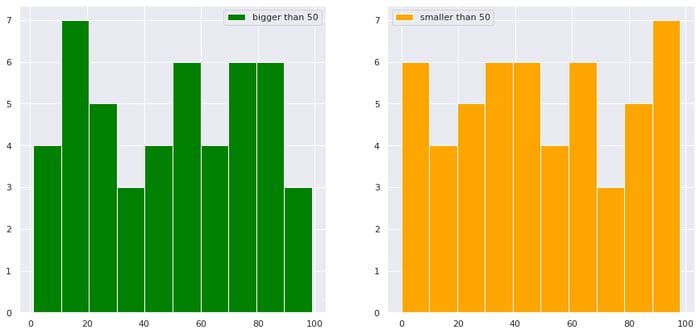
import pandas as pd df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
bilde av forfatteren
9. Kjøre t-tester for verdier av forskjellige kolonner i pandaer
from scipy.stats import ttest_rel data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)10. Slå sammen datarammer på en gitt kolonne
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. Normalisering av verdier i en pandasøyle med sklearn
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))12. Slippe NaNs i en spesifikk kolonne i pandaer
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)13. Velge delsett av en dataramme med betingelser og or uttalelse
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

14. Grunnleggende kakediagram
import matplotlib.pyplot as plt df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()

15. Endre en prosentstreng til en numerisk verdi ved å bruke .apply()
def change_to_numerical(x): try: x = int(x.strip("%")[:2]) except: x = int(x.strip("%")[:1]) return x df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

konklusjonen
Jeg synes kodebiter er veldig verdifulle, omskriving av kode kan være bortkastet tid, så det kan være til stor hjelp å ha et komplett verktøysett med alle de enkle løsningene du trenger for å strømlinjeforme dataanalyseprosessen.
Hvis du likte dette innlegget, ta kontakt med meg på Twitter, Linkedin og følg meg videre Medium. Takk og se deg neste gang! 🙂
Mer innhold på vanlig engelsk.io
Bio: Lucas Soares er en AI-ingeniør som jobber med dyplæringsapplikasjoner for et bredt spekter av problemer.
original. Ompostet med tillatelse.
Relatert:
| Topphistorier siste 30 dager | |||||
|---|---|---|---|---|---|
|
|
||||
Kilde: https://www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
- '
- "
- &
- 100
- 7
- Annonsering
- AI
- Alle
- analyse
- Søknad
- søknader
- auto
- AWS
- kode
- Kolonne
- Felles
- innhold
- dato
- dataanalyse
- datavitenskap
- avtale
- dyp læring
- Regissør
- ingeniør
- Egenskaper
- Først
- følge
- GPU
- flott
- Grønn
- Grid
- Hvordan
- Hvordan
- HTTPS
- Intervju
- etiketter
- LÆRE
- læring
- Liste
- maskinlæring
- medium
- ML
- neural
- åpen
- åpen kildekode
- Python
- område
- grunner
- regresjon
- rennende
- salg
- Vitenskap
- forskere
- Del
- Enkelt
- So
- Solutions
- kvadrat
- stats
- Stories
- TD
- Testing
- tid
- topp
- transformere
- verdi
- X