Afbeelding door auteur
Wanneer u aan de slag gaat met machine learning, is logistische regressie een van de eerste algoritmen die u aan uw gereedschapskist toevoegt. Het is een eenvoudig en robuust algoritme dat vaak wordt gebruikt voor binaire classificatietaken.
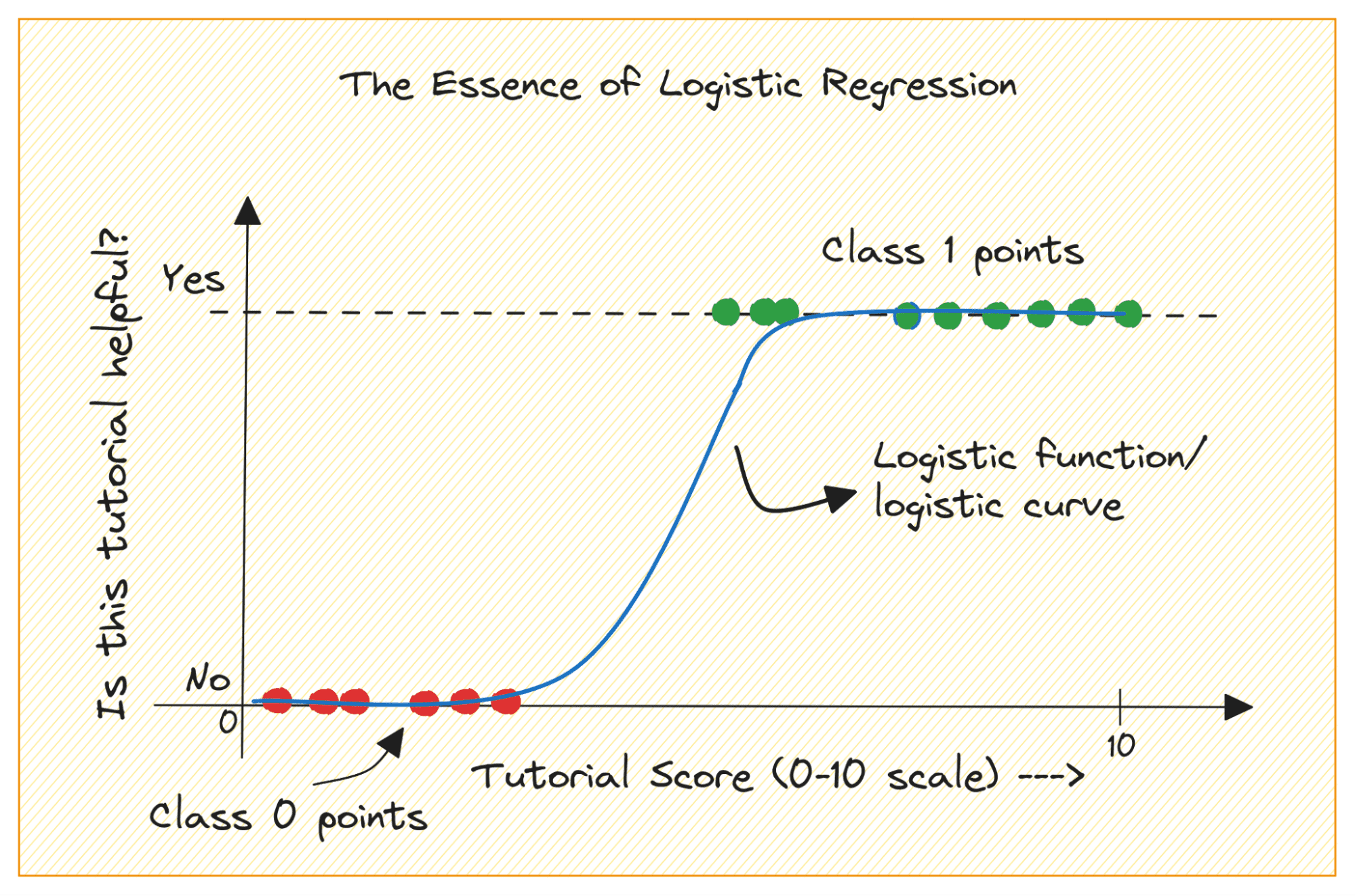
Beschouw een binair classificatieprobleem met klassen 0 en 1. Logistische regressie past een logistieke of sigmoïde functie toe aan de invoergegevens en voorspelt de waarschijnlijkheid dat een querydatapunt tot klasse 1 behoort. Interessant, ja?
In deze tutorial leren we vanaf het begin over logistieke regressie:
- De logistieke (of sigmoïde) functie
- Hoe we van lineaire naar logistieke regressie gaan
- Hoe logistische regressie werkt
Ten slotte zullen we een eenvoudig logistisch regressiemodel bouwen classificeren RADAR-retouren uit de ionosfeer.
Voordat we meer leren over logistische regressie, gaan we eerst bekijken hoe de logistieke functie werkt. De logistieke (of sigmoïdefunctie) wordt gegeven door:

Wanneer u de sigmoïdfunctie plot, ziet deze er als volgt uit:
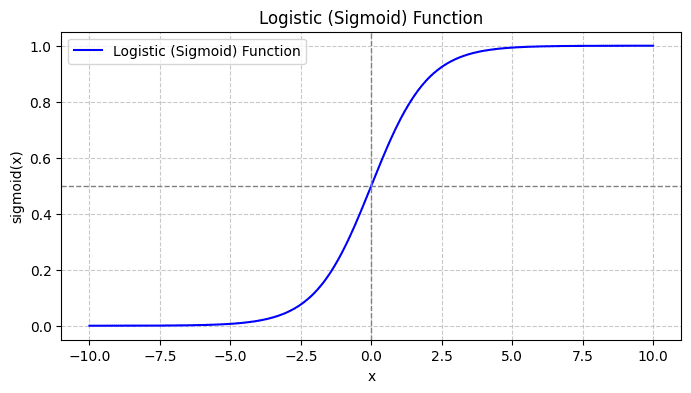
Uit de plot zien we dat:
- Wanneer x = 0, neemt σ(x) de waarde 0.5 aan.
- Wanneer x +∞ nadert, benadert σ(x) 1.
- Wanneer x -∞ nadert, nadert σ(x) 0.
Dus voor alle reële invoergegevens drukt de sigmoïdefunctie ze samen om waarden in het bereik [0, 1] aan te nemen.
Laten we eerst bespreken waarom we lineaire regressie niet kunnen gebruiken voor een binair classificatieprobleem.
Bij een binair classificatieprobleem is de uitvoer een categorisch label (0 of 1). Omdat lineaire regressie outputs met een continue waarde voorspelt die kleiner dan 0 of groter dan 1 kunnen zijn, heeft dit geen zin voor het onderhavige probleem.
Bovendien past een rechte lijn mogelijk niet optimaal als de uitvoerlabels tot een van de twee categorieën behoren.
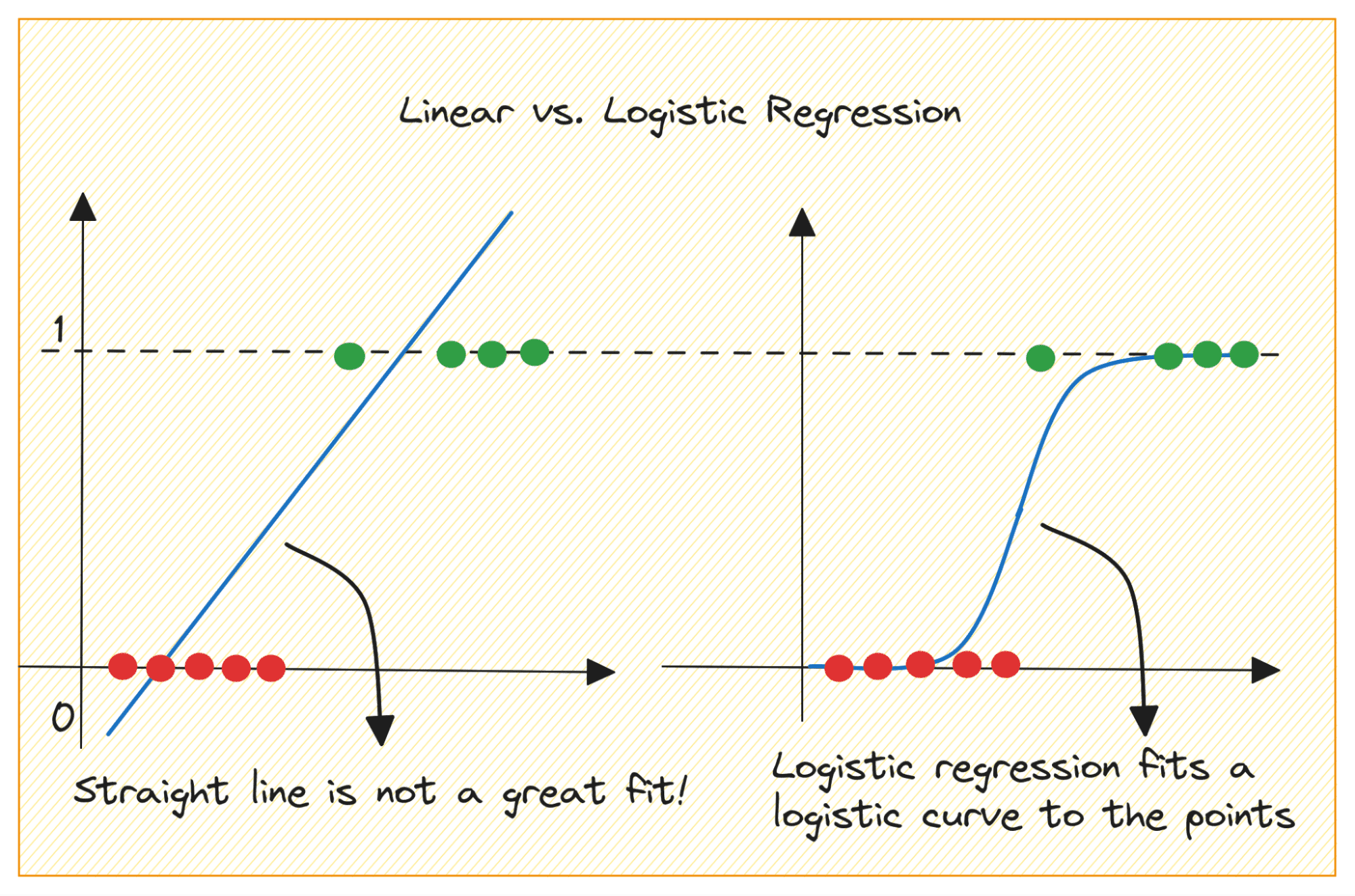
Afbeelding door auteur
Dus hoe gaan we van lineaire naar logistische regressie? Bij lineaire regressie wordt de voorspelde output gegeven door:
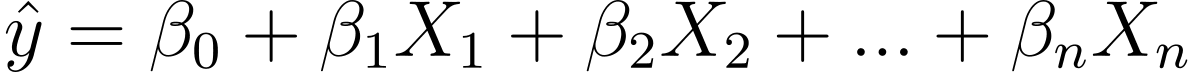
Waar de βs de coëfficiënten zijn en X_is de voorspellers (of kenmerken).
Laten we, zonder verlies van algemeenheid, aannemen dat X_0 = 1:

We kunnen dus een beknoptere uitdrukking gebruiken:
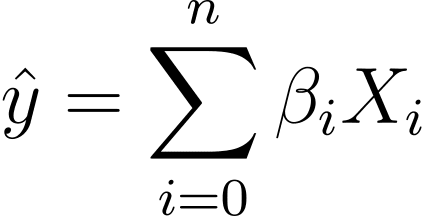
Bij logistische regressie hebben we de voorspelde waarschijnlijkheid p_i nodig in het [0,1] interval. We weten dat de logistieke functie invoergegevens comprimeert, zodat deze waarden aannemen in het [0,1]-interval.
Dus als we deze uitdrukking in de logistieke functie pluggen, hebben we de voorspelde waarschijnlijkheid als:
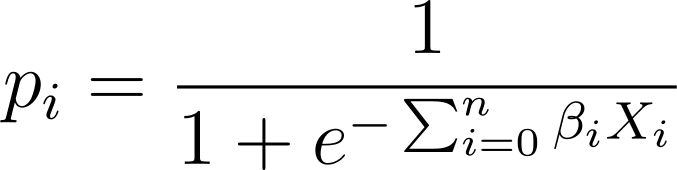
Dus hoe vinden we de best passende logistieke curve voor de gegeven dataset? Laten we, om dit te beantwoorden, de schatting van de maximale waarschijnlijkheid begrijpen.
Maximale waarschijnlijkheidsschatting (MLE) wordt gebruikt om de parameters van het logistieke regressiemodel te schatten door de waarschijnlijkheidsfunctie te maximaliseren. Laten we het proces van MLE in logistieke regressie uitsplitsen en hoe de kostenfunctie wordt geformuleerd voor optimalisatie met behulp van gradiëntafdaling.
Maximale waarschijnlijkheidsschatting uitsplitsen
Zoals besproken modelleren we de waarschijnlijkheid dat een binaire uitkomst optreedt als een functie van een of meer voorspellende variabelen (of kenmerken):
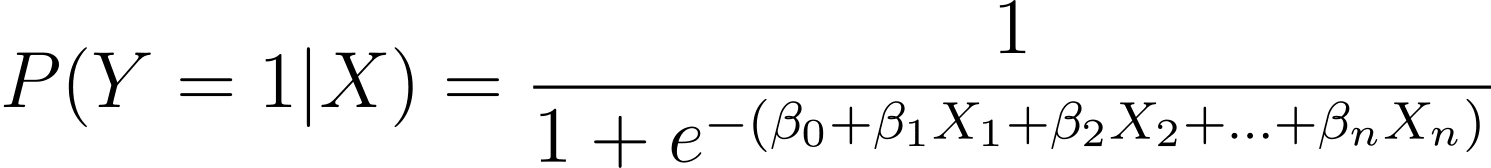
Hier zijn de β's de modelparameters of coëfficiënten. X_1, X_2,…, X_n zijn de voorspellende variabelen.
MLE heeft tot doel de waarden van β te vinden die de waarschijnlijkheid van de waargenomen gegevens maximaliseren. De waarschijnlijkheidsfunctie, aangeduid als L(β), vertegenwoordigt de waarschijnlijkheid van het waarnemen van de gegeven uitkomsten voor de gegeven voorspellende waarden onder het logistische regressiemodel.
Het formuleren van de log-waarschijnlijkheidsfunctie
Om het optimalisatieproces te vereenvoudigen, is het gebruikelijk om met de log-likelihood-functie te werken. Omdat het producten van waarschijnlijkheden omzet in sommen van logwaarschijnlijkheden.
De logwaarschijnlijkheidsfunctie voor logistische regressie wordt gegeven door:
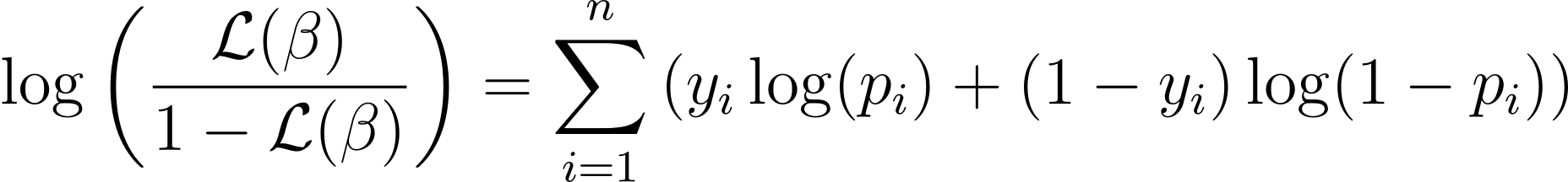
Nu we de essentie van log-waarschijnlijkheid kennen, gaan we verder met het formuleren van de kostenfunctie voor logistische regressie en vervolgens gradiëntdaling om de beste modelparameters te vinden
Kostenfunctie voor logistieke regressie
Om het logistische regressiemodel te optimaliseren, moeten we de logwaarschijnlijkheid maximaliseren. We kunnen dus de negatieve logwaarschijnlijkheid gebruiken als kostenfunctie om tijdens de training te minimaliseren. De negatieve logwaarschijnlijkheid, vaak het logistieke verlies genoemd, wordt gedefinieerd als:
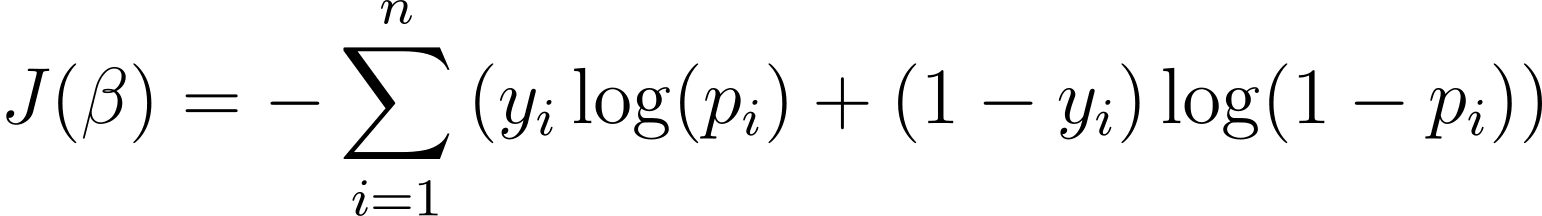
Het doel van het leeralgoritme is daarom om de waarden te vinden van ? die deze kostenfunctie minimaliseren. Gradiëntdaling is een veelgebruikt optimalisatiealgoritme om het minimum van deze kostenfunctie te vinden.
Gradiëntdaling in logistieke regressie
Verloop afdaling is een iteratief optimalisatiealgoritme dat de modelparameters β bijwerkt in de tegenovergestelde richting van de gradiënt van de kostenfunctie ten opzichte van β. De updateregel bij stap t+1 voor logistische regressie met behulp van gradiëntdaling is als volgt:
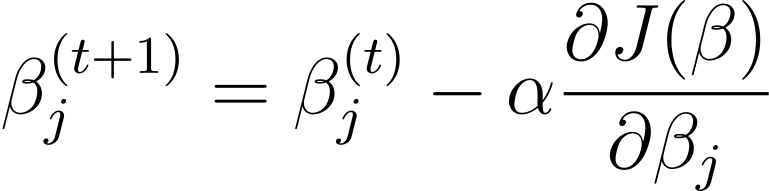
Waarbij α de leersnelheid is.
De partiële afgeleiden kunnen worden berekend met behulp van de kettingregel. Gradiëntafdaling werkt de parameters iteratief bij (tot aan convergentie), met als doel het logistieke verlies te minimaliseren. Terwijl het convergeert, vindt het de optimale waarden van β die de waarschijnlijkheid van de waargenomen gegevens maximaliseren.
Nu u weet hoe logistische regressie werkt, gaan we een voorspellend model bouwen met behulp van de scikit-learn-bibliotheek.
We gebruiken de ionosfeer-dataset uit de UCI machine learning-repository voor deze tutorial. De dataset omvat 34 numerieke kenmerken. De uitvoer is binair, 'goed' of 'slecht' (aangegeven met 'g' of 'b'). Het uitvoerlabel 'goed' verwijst naar RADAR-resultaten die enige structuur in de ionosfeer hebben gedetecteerd.
Stap 1 – Het laden van de dataset
Download eerst de dataset en lees deze in een pandas-dataframe:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Stap 2 – De dataset verkennen
Laten we eens kijken naar de eerste paar rijen van het dataframe:
# Display the first few rows of the DataFrame
df.head()
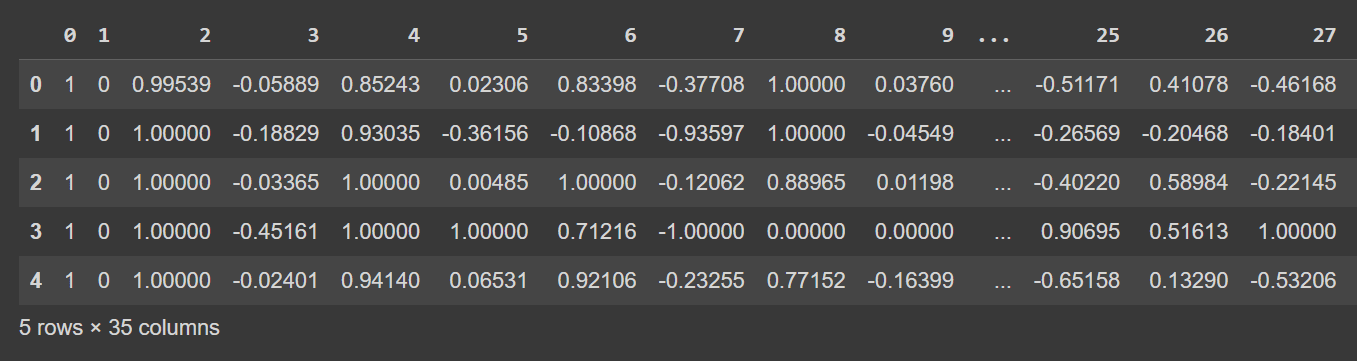
Afgekapte uitvoer van df.head()
Laten we wat informatie krijgen over de dataset: het aantal niet-null-waarden en de gegevenstypen van elk van de kolommen:
# Get information about the dataset
print(df.info())
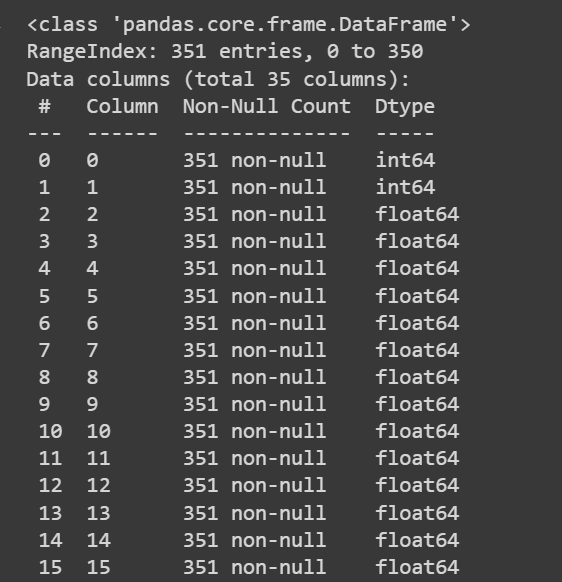 Afgekapte uitvoer van df.info()
Afgekapte uitvoer van df.info()
Omdat we over alle numerieke kenmerken beschikken, kunnen we ook enkele beschrijvende statistieken verkrijgen met behulp van de describe() methode op het dataframe:
# Get descriptive statistics of the dataset
print(df.describe())
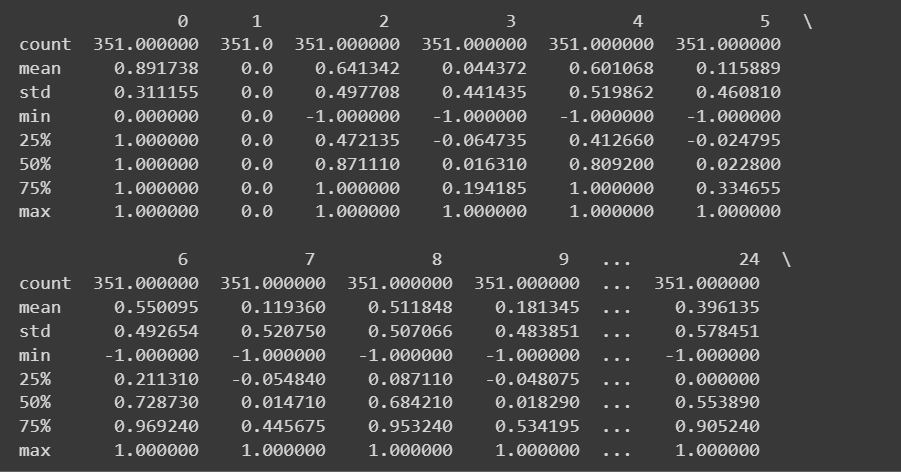
Afgeknotte uitvoer van df.describe()
De kolomnamen zijn momenteel 0 tot en met 34, inclusief het label. Omdat de dataset geen beschrijvende namen voor de kolommen biedt, verwijst deze er alleen naar attribuut_1 tot attribuut_34. Als u wilt, kunt u de kolommen van het dataframe hernoemen zoals weergegeven:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Opmerking: deze stap is puur optioneel. U kunt desgewenst doorgaan met de standaardkolomnamen.
# Display the first few rows of the DataFrame
df.head()
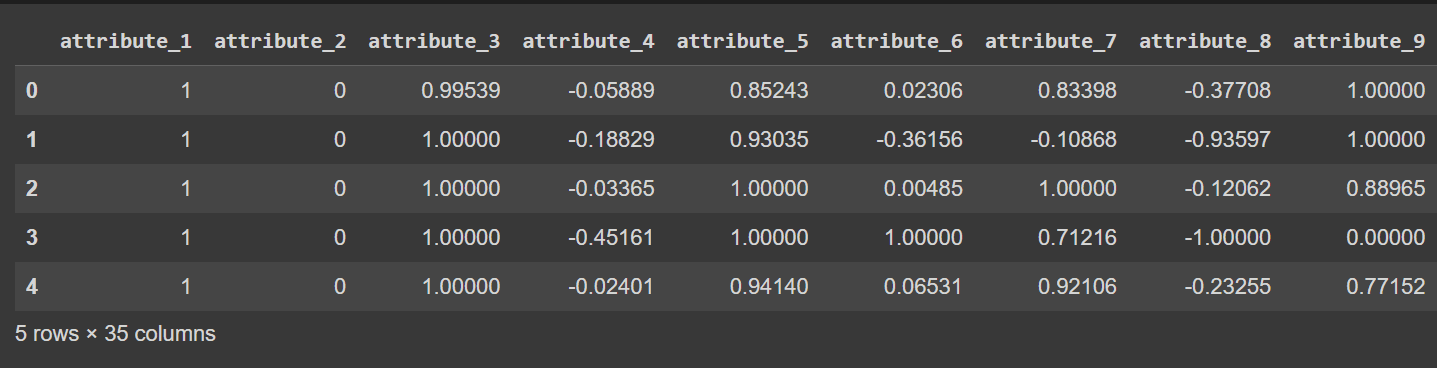
Afgekapte uitvoer van df.head() [na hernoemen van kolommen]
Stap 3 – De naam van klassenlabels wijzigen en de klassenverdeling visualiseren
Omdat de uitvoerklasselabels 'g' en 'b' zijn, moeten we ze respectievelijk toewijzen aan 1 en 0 . Je kunt het doen met behulp van map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Laten we ook de verdeling van de klassenlabels visualiseren:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
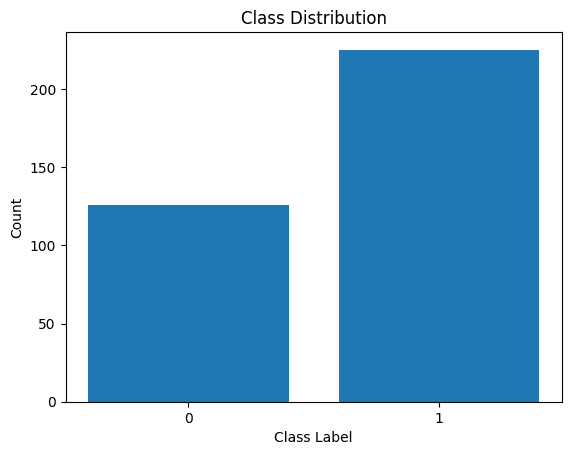
Distributie van klassenlabels
We zien dat er sprake is van een onevenwicht in de verdeling. Er zijn meer records die tot klasse 1 behoren dan tot klasse 0. We zullen deze onbalans in de klasse aanpakken bij het bouwen van het logistische regressiemodel.
Stap 5 – De dataset voorbewerken
Laten we de functies en uitvoerlabels als volgt verzamelen:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Nadat we de dataset hebben opgesplitst in de trein- en testsets, moeten we de dataset voorbewerken.
Als er veel numerieke kenmerken zijn, elk op een potentieel andere schaal, moeten we de numerieke kenmerken voorbewerken. Een gebruikelijke methode is om ze zo te transformeren dat ze een verdeling volgen zonder gemiddelde en eenheidsvariantie.
De StandardScaler van de voorverwerkingsmodule van scikit-learn helpt ons dit te bereiken.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Stap 6 – Een logistiek regressiemodel bouwen
Nu kunnen we een logistische regressieclassificator instantiëren. De LogisticRegression klasse maakt deel uit van de lineaire_modelmodule van scikit-learn.
Merk op dat we de class_weight parameter op 'gebalanceerd'. Dit zal ons helpen rekening te houden met de onevenwichtigheid in de klassen. Door aan elke klasse gewichten toe te kennen, omgekeerd evenredig aan het aantal records in de klassen.
Nadat we de klasse hebben geïnstantieerd, kunnen we het model aanpassen aan de trainingsdataset:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Stap 7 – Evaluatie van het logistieke regressiemodel
U kunt de predict() methode om de voorspellingen van het model te verkrijgen.
Naast de nauwkeurigheidsscore kunnen we ook een classificatierapport krijgen met statistieken zoals precisie, herinnering en F1-score.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
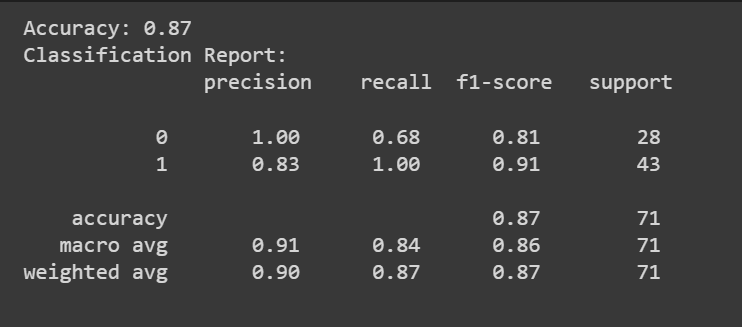
Gefeliciteerd, u heeft uw eerste logistische regressiemodel gecodeerd!
In deze tutorial leerden we gedetailleerd over logistieke regressie: van theorie en wiskunde tot het coderen van een logistieke regressieclassificator.
Probeer als volgende stap een logistisch regressiemodel te bouwen voor een geschikte dataset naar keuze.
De Ionosphere-gegevensset is gelicentieerd onder a Creative Commons Naamsvermelding 4.0 Internationaal (CC BY 4.0) licentie:
Sigillito,V., Wing,S., Hutton,L., en Baker,K.. (1989). Ionosfeer. UCI Machine Learning-opslagplaats. https://doi.org/10.24432/C5W01B.
Bala Priya C is een ontwikkelaar en technisch schrijver uit India. Ze werkt graag op het snijvlak van wiskunde, programmeren, datawetenschap en contentcreatie. Haar interessegebieden en expertise omvatten DevOps, data science en natuurlijke taalverwerking. Ze houdt van lezen, schrijven, coderen en koffie drinken! Momenteel werkt ze aan het leren en delen van haar kennis met de gemeenschap van ontwikkelaars door het schrijven van zelfstudies, handleidingen, opiniestukken en meer.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :is
- :niet
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Over
- Account
- nauwkeurigheid
- Bereiken
- toevoegen
- toevoeging
- Na
- wil
- algoritme
- algoritmen
- Alles
- ook
- an
- en
- beantwoorden
- benaderingen
- ZIJN
- gebieden
- AS
- ervan uitgaan
- At
- schrijven
- b
- bakker
- Evenwichtig
- bars
- BE
- omdat
- behorende
- BEST
- Breken
- bouw
- Gebouw
- by
- Bellen
- CAN
- kan niet
- categorieën
- keten
- keuze
- klasse
- klassen
- classificatie
- gecodeerde
- codering
- verzamelen
- Kolom
- columns
- Gemeen
- algemeen
- Volk
- gemeenschap
- omvat
- beknopt
- content
- content creatie
- converteren
- Kosten
- aan het bedekken
- en je merk te creëren
- het aanmaken
- Op dit moment
- curve
- gegevens
- data punten
- data science
- gegevensset
- Standaard
- gedefinieerd
- Derivaten
- detail
- gedetecteerd
- Ontwikkelaar
- DevOps
- anders
- richting
- bespreken
- besproken
- Display
- distributie
- do
- doet
- beneden
- Download
- gedurende
- elk
- essentie
- schatting
- evalueren
- expertise
- Verkennen
- uitdrukking
- Voordelen
- weinig
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- het vinden van
- vondsten
- Voornaam*
- geschikt
- volgen
- volgt
- Voor
- FRAME
- oppompen van
- functie
- krijgen
- het krijgen van
- gegeven
- Go
- doel
- Kopen Google Reviews
- meer
- Ground
- Guides
- hand
- handvat
- Hebben
- hulp
- helpt
- haar
- Hoe
- HTTPS
- ICS
- if
- onbalans
- importeren
- in
- omvatten
- index
- Indië
- Index
- informatie
- invoer
- ingangen
- belang
- interessant
- kruispunt
- in
- IT
- voor slechts
- KDnuggets
- blijven
- kennis
- label
- labels
- taal
- LEARN
- geleerd
- leren
- minder
- laten
- Bibliotheek
- Vergunning
- Erkend
- als
- waarschijnlijkheid
- sympathieën
- Lijn
- het laden
- inloggen
- Kijk
- ziet eruit als
- uit
- machine
- machine learning
- maken
- veel
- kaart
- wiskunde
- matplotlib
- Maximaliseren
- maximaliseren
- maximaal
- Mei..
- gemiddelde
- methode
- Metriek
- verkleinen
- minimum
- model
- modellen
- module
- meer
- beweging
- namen
- Naturel
- Natuurlijke taal
- Natural Language Processing
- Noodzaak
- negatief
- volgende
- aantal
- opgemerkt
- of
- vaak
- on
- EEN
- Advies
- tegenover
- optimale
- optimalisatie
- Optimaliseer
- or
- Resultaat
- resultaten
- uitgang
- uitgangen
- panda's
- parameter
- parameters
- deel
- stukken
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- punten
- mogelijk
- precisie
- voorspeld
- Voorspellingen
- voorspellend
- predictor
- voorspelt
- de voorkeur geven
- waarschijnlijkheid
- probleem
- gaan
- verwerking
- Producten
- Programming
- zorgen voor
- puur
- Python
- radar
- reeks
- tarief
- Lees
- lezing
- vast
- archief
- verwezen
- verwijst
- regressie
- verslag
- bewaarplaats
- vertegenwoordigt
- te vragen
- culturele wortels
- respectievelijk
- Retourneren
- beoordelen
- robuust
- Regel
- s
- Wetenschap
- scikit-leren
- partituur
- zien
- zin
- reeks
- Sets
- delen
- ze
- getoond
- Eenvoudig
- vereenvoudigen
- So
- sommige
- spleet
- gestart
- statistiek
- Stap voor
- recht
- structuur
- Hierop volgend
- dergelijk
- geschikt
- sommen
- Nemen
- neemt
- doelwit
- taken
- Technisch
- proef
- Testen
- neem contact
- dat
- De
- Ze
- theorie
- Er.
- daarom
- ze
- dit
- Door
- naar
- Toolbox
- Trainen
- getraind
- Trainingen
- Transformeren
- transformaties
- proberen
- zelfstudie
- tutorials
- twee
- types
- voor
- begrijpen
- eenheid
- bijwerken
- updates
- URL
- us
- Amerikaanse rekening
- .
- gebruikt
- gebruik
- waarde
- Values
- visualiseren
- we
- wanneer
- welke
- Waarom
- Wikipedia
- wil
- Vleugel
- Met
- Mijn werk
- werkzaam
- Bedrijven
- zou
- schrijver
- het schrijven van
- X
- ja
- u
- Your
- zephyrnet
- nul