In het huidige digitale tijdperk vormen data de kern van het succes van elke organisatie. Een van de meest gebruikte formaten voor het uitwisselen van gegevens is XML. Het analyseren van XML-bestanden is om verschillende redenen cruciaal. Ten eerste worden XML-bestanden in veel sectoren gebruikt, waaronder de financiële sector, de gezondheidszorg en de overheid. Het analyseren van XML-bestanden kan organisaties helpen inzicht te krijgen in hun gegevens, waardoor ze betere beslissingen kunnen nemen en hun activiteiten kunnen verbeteren. Het analyseren van XML-bestanden kan ook helpen bij de data-integratie, omdat veel applicaties en systemen XML als standaard dataformaat gebruiken. Door XML-bestanden te analyseren kunnen organisaties eenvoudig gegevens uit verschillende bronnen integreren en consistentie binnen hun systemen garanderen. XML-bestanden bevatten echter semi-gestructureerde, sterk geneste gegevens, waardoor het moeilijk is om toegang te krijgen tot informatie en deze te analyseren, vooral als het bestand groot is en veel gegevens bevat. complex, sterk genest schema.
XML-bestanden zijn zeer geschikt voor toepassingen, maar zijn mogelijk niet optimaal voor analyse-engines. Om de queryprestaties te verbeteren en gemakkelijke toegang mogelijk te maken in downstream analyse-engines zoals Amazone Athene, is het van cruciaal belang om XML-bestanden voor te verwerken in een kolomindeling zoals Parquet. Deze transformatie zorgt voor verbeterde efficiëntie en bruikbaarheid in analyseworkflows. In dit bericht laten we zien hoe u XML-gegevens kunt verwerken met behulp van AWS lijm en Athene.
Overzicht oplossingen
We onderzoeken twee verschillende technieken die uw workflow voor de verwerking van XML-bestanden kunnen stroomlijnen:
- Techniek 1: Gebruik een AWS Glue-crawler en de visuele editor van AWS Glue – U kunt de AWS Glue-gebruikersinterface gebruiken in combinatie met een crawler om de tabelstructuur voor uw XML-bestanden te definiëren. Deze aanpak biedt een gebruiksvriendelijke interface en is met name geschikt voor personen die de voorkeur geven aan een grafische benadering voor het beheren van hun gegevens.
- Techniek 2: Gebruik AWS Glue DynamicFrames met afgeleide en vaste schema's – De crawler heeft een beperking als het gaat om het verwerken van een enkele rij in XML-bestanden die groter zijn dan 1 MB. Om deze beperking te omzeilen, gebruiken we een AWS Glue-notebook om AWS Glue te maken
DynamicFrames, waarbij zowel afgeleide als vaste schema's worden gebruikt. Deze methode garandeert een efficiënte verwerking van XML-bestanden met rijen groter dan 1 MB.
In beide benaderingen is ons uiteindelijke doel het converteren van XML-bestanden naar het Apache Parquet-formaat, waardoor ze direct beschikbaar zijn voor bevraging met Athena. Met deze technieken kunt u de verwerkingssnelheid en toegankelijkheid van uw XML-gegevens verbeteren, waardoor u gemakkelijk waardevolle inzichten kunt verkrijgen.
Voorwaarden
Voordat u met deze zelfstudie begint, moet u aan de volgende vereisten voldoen (deze zijn van toepassing op beide technieken):
- Download de XML-bestanden techniek1.xml en techniek2.xml.
- Upload de bestanden naar een Amazon eenvoudige opslagservice (Amazon S3) bak. Je kunt ze uploaden naar dezelfde S3-bucket in verschillende mappen of naar verschillende S3-buckets.
- Maak een AWS Identiteits- en toegangsbeheer (IAM)-rol voor uw ETL-taak of notebook zoals aangegeven in IAM-machtigingen instellen voor AWS Glue Studio.
- Voeg een inline-beleid toe aan uw rol met de al: PassRole actie:
- Voeg een machtigingsbeleid toe aan de rol met toegang tot uw S3-bucket.
Nu we klaar zijn met de vereisten, gaan we verder met het implementeren van de eerste techniek.
Techniek 1: Gebruik een AWS Glue-crawler en de visuele editor
Het volgende diagram illustreert de eenvoudige architectuur die u kunt gebruiken om de oplossing te implementeren.
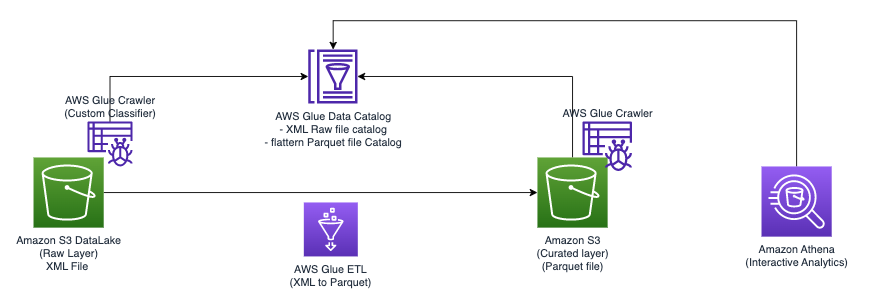
Om XML-bestanden die zijn opgeslagen in Amazon S3 te analyseren met AWS Glue en Athena, voltooien we de volgende stappen op hoog niveau:
- Maak een AWS Glue-crawler om XML-metagegevens te extraheren en een tabel te maken in de AWS Glue-gegevenscatalogus.
- Verwerk en transformeer XML-gegevens naar een formaat (zoals Parquet) dat geschikt is voor Athena met behulp van een AWS Glue-taak voor extraheren, transformeren en laden (ETL).
- Stel een AWS Glue-taak in en voer deze uit via de AWS Glue-console of de AWS-opdrachtregelinterface (AWS CLI).
- Gebruik de verwerkte gegevens (in Parquet-indeling) met Athena-tabellen, waardoor SQL-query's mogelijk zijn.
- Gebruik de gebruiksvriendelijke interface in Athena om de XML-gegevens te analyseren met SQL-query's op uw gegevens die zijn opgeslagen in Amazon S3.
Deze architectuur is een schaalbare, kosteneffectieve oplossing voor het analyseren van XML-gegevens op Amazon S3 met behulp van AWS Glue en Athena. U kunt grote datasets analyseren zonder complex infrastructuurbeheer.
We gebruiken de AWS Glue-crawler om metadata van XML-bestanden te extraheren. U kunt de standaard AWS Glue-classifier kiezen voor algemene XML-classificatie. Het detecteert automatisch de XML-gegevensstructuur en het schema, wat handig is voor veelgebruikte formaten.
We gebruiken in deze oplossing ook een aangepaste XML-classifier. Het is ontworpen voor specifieke XML-schema's of -formaten, waardoor nauwkeurige extractie van metagegevens mogelijk is. Dit is ideaal voor niet-standaard XML-formaten of wanneer u gedetailleerde controle over de classificatie nodig heeft. Een aangepaste classificatie zorgt ervoor dat alleen de noodzakelijke metagegevens worden geëxtraheerd, waardoor de verwerkings- en analysetaken verderop in de keten worden vereenvoudigd. Deze aanpak optimaliseert het gebruik van uw XML-bestanden.
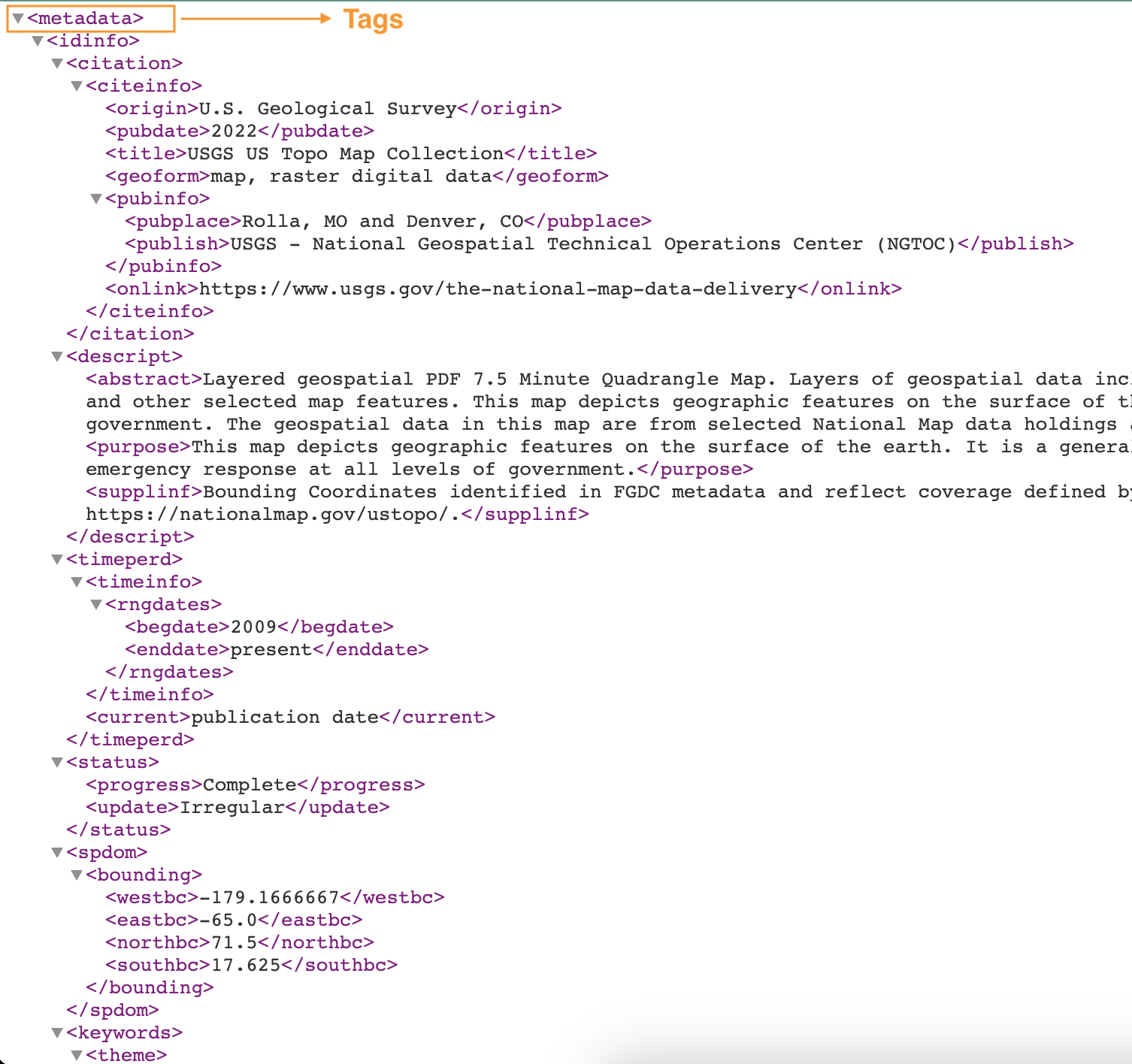
De volgende schermafbeelding toont een voorbeeld van een XML-bestand met tags.
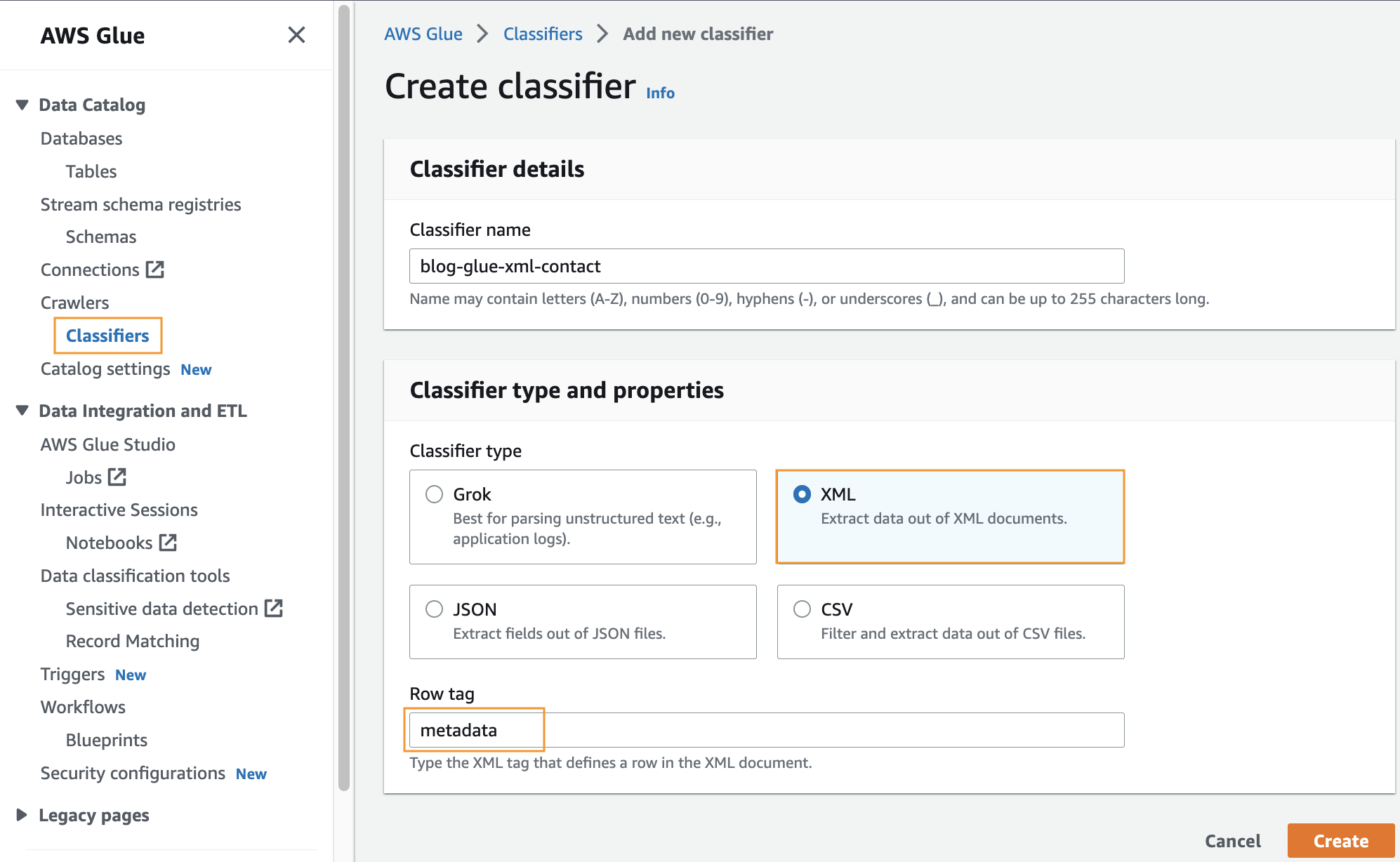
Maak een aangepaste classificatie
In deze stap maakt u een aangepaste AWS Glue-classifier om metadata uit een XML-bestand te extraheren. Voer de volgende stappen uit:
- Op de AWS Glue-console, onder crawlers in het navigatievenster, kies Classifiers.
- Kies Classificatie toevoegen.
- kies XML als het classificatietype.
- Voer een naam in voor de classificatie, bijvoorbeeld
blog-glue-xml-contact. - Voor RijtagVoer de naam in van de roottag die de metagegevens bevat (bijvoorbeeld
metadata). - Kies creëren.
Maak een AWS Glue Crawler om het XML-bestand te crawlen
In deze sectie maken we een Glue Crawler om de metagegevens uit het XML-bestand te extraheren met behulp van de klantclassificatie die in de vorige stap is gemaakt.
Maak een database
- Ga naar uw AWS Lijm console, kiezen databases in het navigatievenster.
- Klik op Database toevoegen.
- Geef een naam op, bijvoorbeeld
blog_glue_xml - Kies creëren Database
Maak een crawler
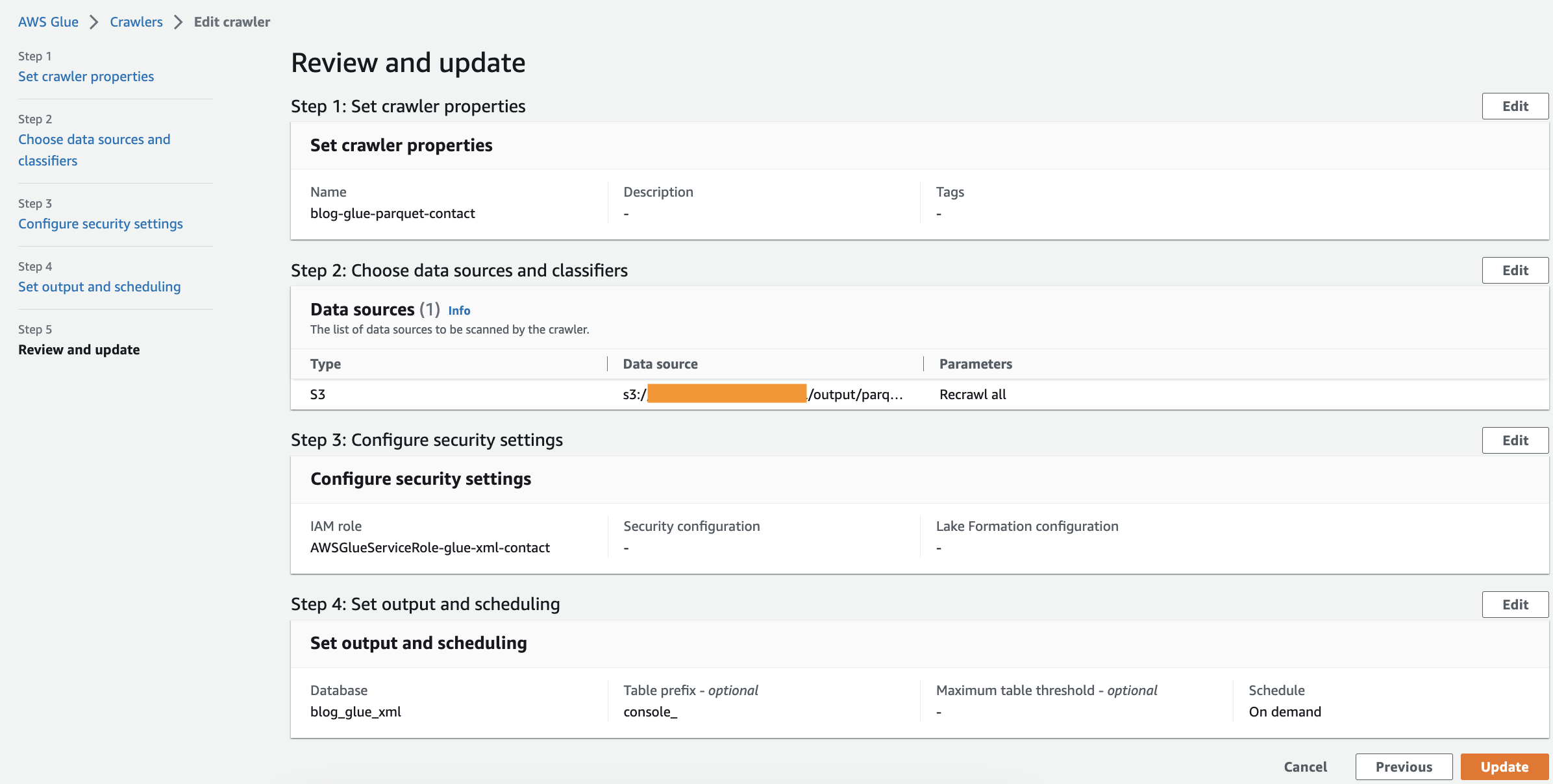
Voer de volgende stappen uit om uw eerste crawler te maken:
- Kies op de AWS Glue-console: crawlers in het navigatievenster.
- Kies Creëren van crawler.
- Op de Crawlereigenschappen instellen pagina, geef een naam op voor de nieuwe crawler (zoals
blog-glue-parquet), kies dan Volgende. - Op de Kies gegevensbronnen en classificaties 4040 hand404040 details hand4040 hand 3 details hand40 hand40 hand details details details details hand 3 Nog niet voor Configuratie van gegevensbron.
- Kies Voeg een datastore toe.
- Voor S3-pad, blader naar
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Zorg ervoor dat u de XML-map kiest in plaats van het bestand in de map.
- Laat de rest van de opties standaard staan en kies Voeg een S3-gegevensbron toe.
- Uitvouwen Aangepaste classificaties – optioneel, kies blog-glue-xml-contact en kies vervolgens Volgende en behoud de rest van de opties als standaard.
- Kies uw IAM-rol of kies Nieuwe IAM-rol maken, voeg het achtervoegsel toe
glue-xml-contact(bijvoorbeeld,AWSGlueServiceNotebookRoleBlog), en kies Volgende. - Op de Uitvoer en planning instellen pagina, onder Uitgangsconfiguratie, kiezen
blog_glue_xmlFor Doeldatabase. - Enter
console_als het voorvoegsel toegevoegd aan tabellen (optioneel) en onder Crawler-schema, laat de frequentie ingesteld staan Op aanvraag. - Kies Volgende.
- Bekijk alle parameters en kies Creëren van crawler.
Voer de crawler uit
Nadat u de crawler heeft gemaakt, voert u de volgende stappen uit om deze uit te voeren:
- Kies op de AWS Glue-console: crawlers in het navigatievenster.
- Open de crawler die u hebt gemaakt en kies lopen.
Het duurt 1 à 2 minuten om de crawler te voltooien.
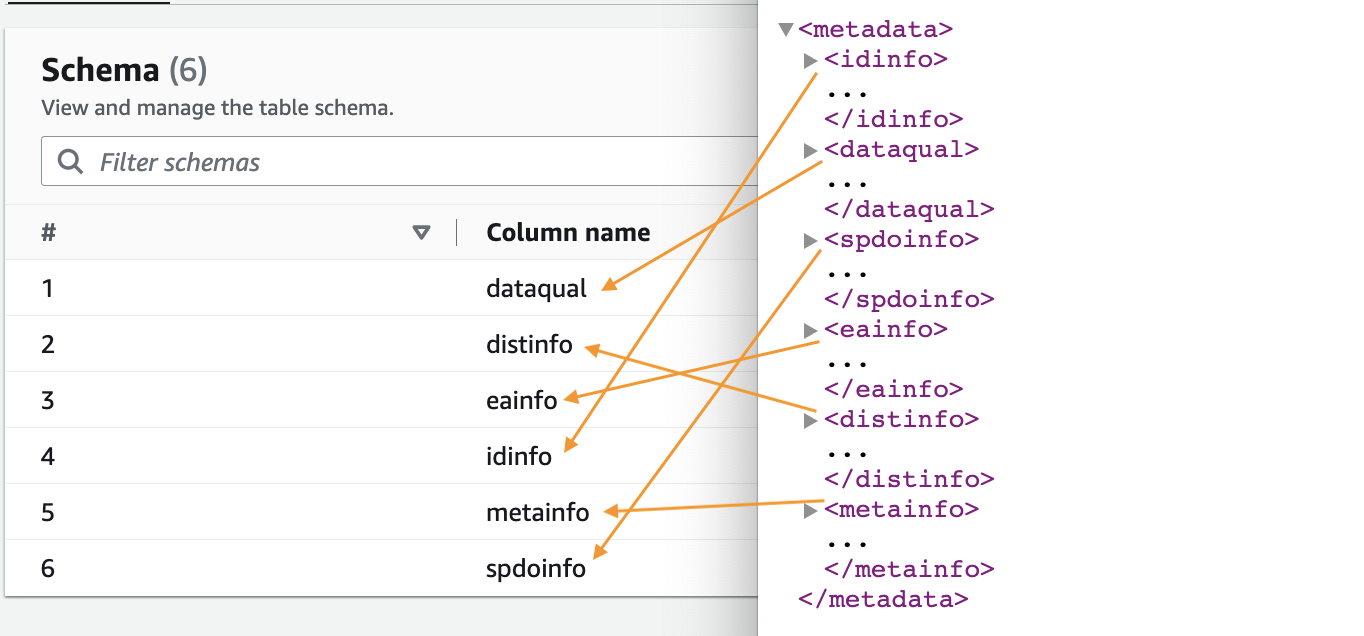
- Wanneer de crawler is voltooid, kiest u: databases in het navigatievenster.
- Kies de database die u in de krat heeft opgenomen en kies de tabelnaam om het schema te zien dat door de crawler wordt geëxtraheerd.
Maak een AWS Glue-taak om de XML naar Parquet-indeling te converteren
In deze stap maakt u een AWS Glue Studio-taak om het XML-bestand naar een Parquet-bestand te converteren. Voer de volgende stappen uit:
- Kies op de AWS Glue-console: Vacatures in het navigatievenster.
- Onder Baan creërenselecteer Visueel met een leeg canvas.
- Kies creëren.
- Hernoem de taak naar
blog_glue_xml_job.
Nu hebt u een lege visuele taakeditor van AWS Glue Studio. Bovenaan de editor bevinden zich de tabbladen voor verschillende weergaven.
- Kies de Script tabblad om een lege shell van het AWS Glue ETL-script te zien.
Naarmate we nieuwe stappen toevoegen in de visuele editor, wordt het script automatisch bijgewerkt.
- Kies de Details van de baan tabblad om alle taakconfiguraties te bekijken.
- Voor IAM-rol, kiezen
AWSGlueServiceNotebookRoleBlog. - Voor Lijm versie, kiezen Lijm 4.0 – Ondersteuning Spark 3.3, Scala 2, Python 3.
- Zet de Gevraagd aantal werknemers om 2.
- Zet de Aantal nieuwe pogingen om 0.
- Kies de Visual tabblad om terug te gaan naar de visuele editor.
- Op de bron vervolgkeuzemenu, kies AWS-lijmgegevenscatalogus.
- Op de Gegevensbroneigenschappen – Gegevenscatalogus tabblad, geef de volgende informatie op:
- Voor Database, kiezen
blog_glue_xml. - Voor tafel, kies de tabel die begint met de naam console_ die de crawler heeft gemaakt (bijvoorbeeld
console_geologicalsurvey).
- Voor Database, kiezen
- Op de Knooppunt eigenschappen tabblad, geef de volgende informatie op:
- Veranderen Naam naar
geologicalsurveygegevensset. - Kies Actie en de transformatie Schema wijzigen (toewijzing toepassen).
- Kies Knooppunt eigenschappen en wijzig de naam van de transformatie van Schema wijzigen (toewijzing toepassen) in
ApplyMapping. - Op de doelwit menu, kies S3.
- Veranderen Naam naar
- Op de Eigenschappen gegevensbron - S3 tabblad, geef de volgende informatie op:
- Voor Formaatselecteer Parket.
- Voor Compressietypeselecteer Ongecomprimeerd.
- Voor S3-brontypeselecteer S3 locatie.
- Voor S3-URL, ga naar binnen
s3://${BUCKET_NAME}/output/parquet/. - Kies Knooppunteigenschappen en verander de naam in
Output.
- Kies Bespaar om de baan te redden.
- Kies lopen om de baan uit te voeren.
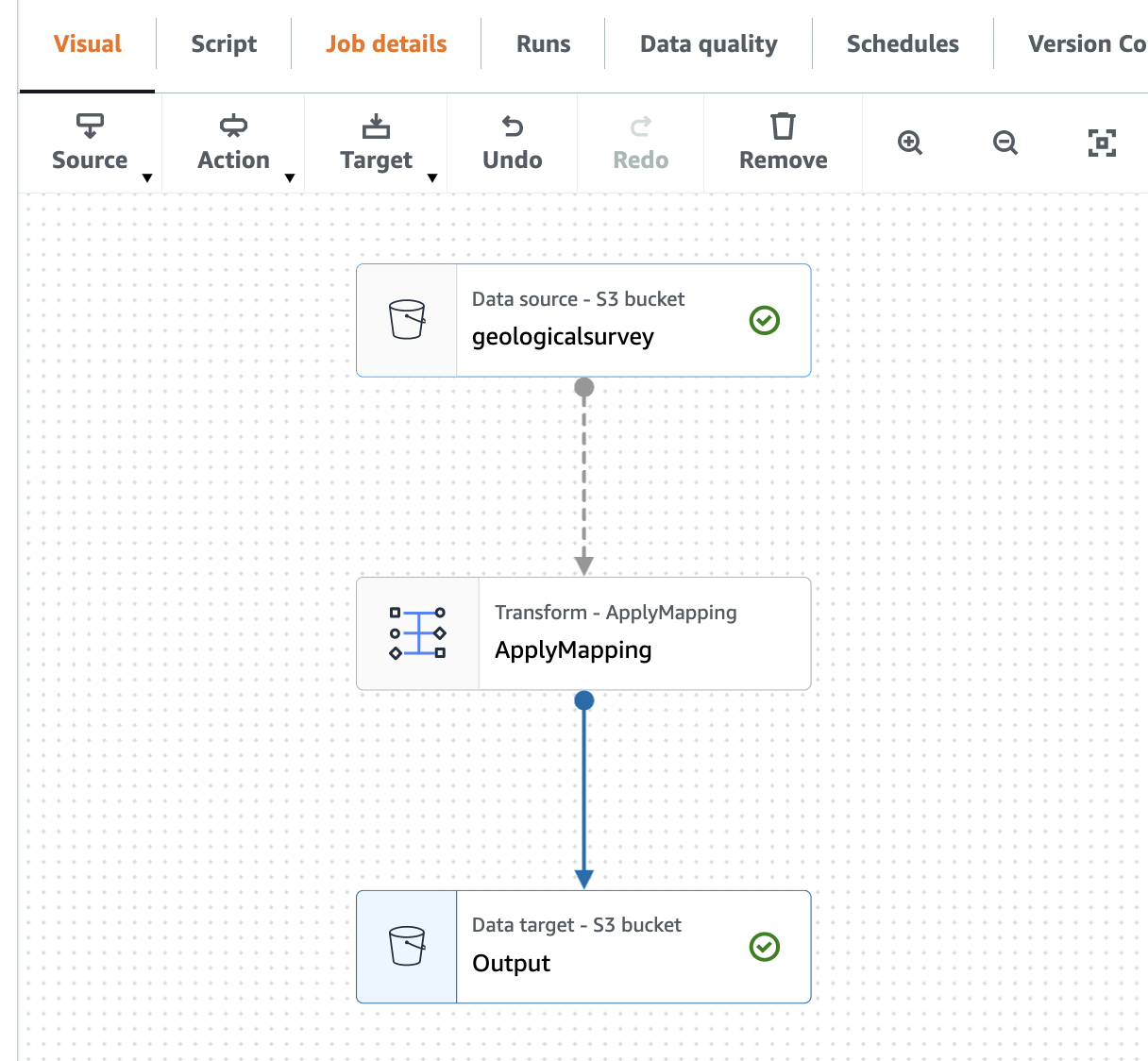
De volgende schermafbeelding toont de taak in de visuele editor.
Maak een AWS Gue Crawler om het Parquet-bestand te crawlen
In deze stap maakt u een AWS Glue-crawler om metagegevens te extraheren uit het Parquet-bestand dat u hebt gemaakt met behulp van een AWS Glue Studio-taak. Deze keer gebruikt u de standaardclassificator. Voer de volgende stappen uit:
- Kies op de AWS Glue-console: crawlers in het navigatievenster.
- Kies Creëren van crawler.
- Op de Crawlereigenschappen instellen pagina, geef een naam op voor de nieuwe crawler, zoals blog-glue-parket-contact, en kies vervolgens Volgende.
- Op de Kies gegevensbronnen en classificaties 4040 hand404040 details hand4040 hand 3 details hand40 hand40 hand details details details details hand 3 Nog niet For Configuratie van gegevensbron.
- Kies Voeg een datastore toe.
- Voor S3-pad, blader naar
s3://${BUCKET_NAME}/output/parquet/.
Zorg ervoor dat u de parquet map in plaats van het bestand in de map.
- Kies uw IAM-rol die is aangemaakt tijdens de vereistensectie of kies Nieuwe IAM-rol maken (bijvoorbeeld,
AWSGlueServiceNotebookRoleBlog), en kies Volgende. - Op de Uitvoer en planning instellen pagina, onder Uitgangsconfiguratie, kiezen
blog_glue_xmlFor Database. - Enter
parquet_als het voorvoegsel toegevoegd aan tabellen (optioneel) en onder Crawler-schema, laat de frequentie ingesteld staan Op aanvraag. - Kies Volgende.
- Bekijk alle parameters en kies Creëren van crawler.
Nu kunt u de crawler uitvoeren. Dit duurt 1 à 2 minuten.

U kunt een voorbeeld bekijken van het nieuw gemaakte schema voor het Parquet-bestand in de AWS Glue Data Catalog, dat vergelijkbaar is met het schema van het XML-bestand.
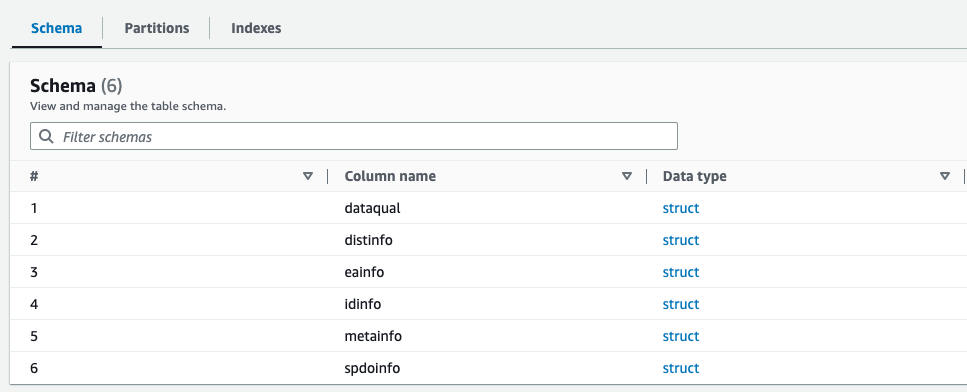
Wij beschikken nu over gegevens die geschikt zijn voor gebruik met Athena. In de volgende sectie voeren we dataquery's uit met Athena.
Voer een query uit op het Parquet-bestand met Athena
Athena biedt geen ondersteuning voor het opvragen van de XML-bestandsformaat, daarom hebt u het XML-bestand geconverteerd naar Parquet voor efficiëntere gegevensquery's en -gebruik puntnotatie om complexe typen en geneste structuren op te vragen.
De volgende voorbeeldcode gebruikt puntnotatie om geneste gegevens op te vragen:
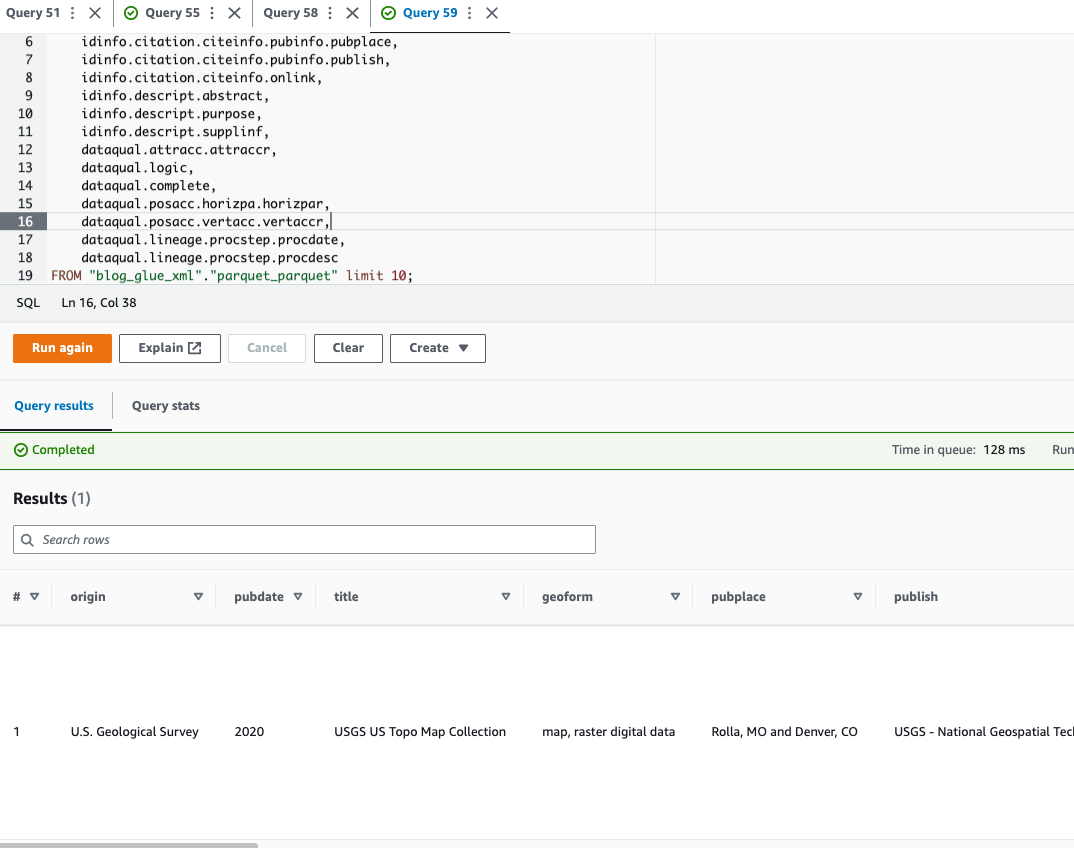
Nu we techniek 1 hebben voltooid, gaan we verder met techniek 2.
Techniek 2: Gebruik AWS Glue DynamicFrames met afgeleide en vaste schema's
In de vorige sectie hebben we het proces besproken van het verwerken van een klein XML-bestand met behulp van een AWS Glue-crawler om een tabel te genereren, een AWS Glue-taak om het bestand naar Parquet-indeling te converteren, en Athena om toegang te krijgen tot de Parquet-gegevens. De crawler stuit echter op beperkingen als het gaat om het verwerken van XML-bestanden die groter zijn dan 1 MB groot. In deze sectie verdiepen we ons in het onderwerp van batchverwerking van grotere XML-bestanden, waardoor extra parsering nodig is om individuele gebeurtenissen te extraheren en analyses uit te voeren met Athena.
Onze aanpak bestaat uit het lezen van de XML-bestanden via AWS Glue Dynamische Frames, waarbij gebruik wordt gemaakt van zowel afgeleide als vaste schema's. Vervolgens extraheren we de afzonderlijke gebeurtenissen in Parquet-indeling met behulp van de relationaliseren transformatie, waardoor we ze naadloos kunnen opvragen en analyseren met Athena.
Om deze oplossing te implementeren, voltooit u de volgende stappen op hoog niveau:
- Maak een AWS Glue-notebook om het XML-bestand te lezen en analyseren.
- Te gebruiken
DynamicFramesMetInferSchemaom het XML-bestand te lezen. - Gebruik de relationalize-functie om arrays te ontnesten.
- Converteer de gegevens naar de Parquet-indeling.
- Query's uitvoeren op de Parquet-gegevens met Athena.
- Herhaal de voorgaande stappen, maar geef deze keer een schema door
DynamicFramesin plaats van gebruikenInferSchema.
Het XML-bestand met populatiegegevens van elektrische voertuigen heeft een response tag op het rootniveau. Deze tag bevat een array van row tags, die erin zijn genest. De rijtag is een array die een reeks andere rijtags bevat, die informatie geven over een voertuig, inclusief het merk, het model en andere relevante details. De volgende schermafbeelding toont een voorbeeld.

Maak een AWS-lijmnotitieboekje
Voer de volgende stappen uit om een AWS Glue-notebook te maken:
- Open de AWS Lijm Studio console, kies Vacatures in het navigatievenster.
- kies Jupyter Notebook En kies creëren.
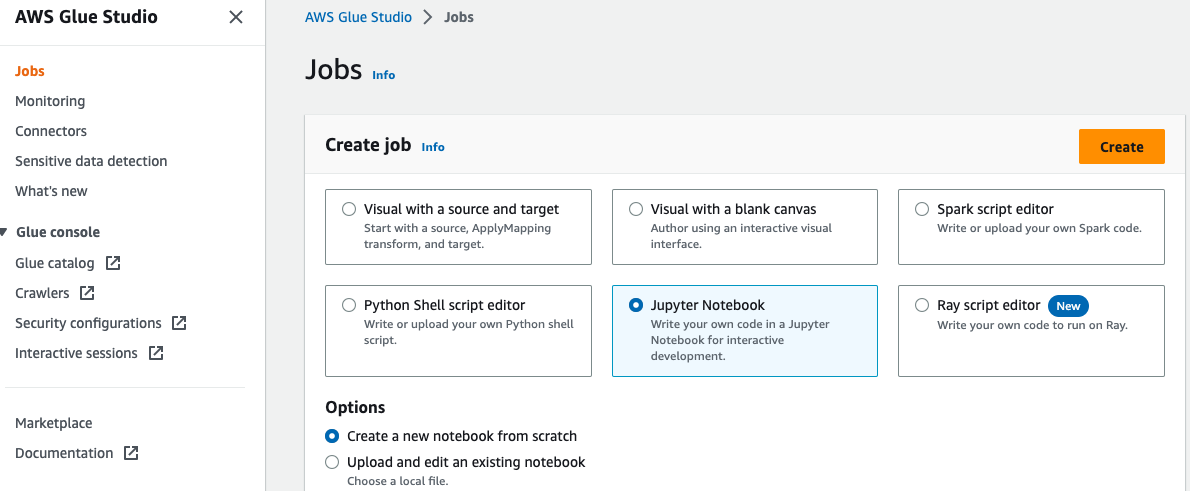
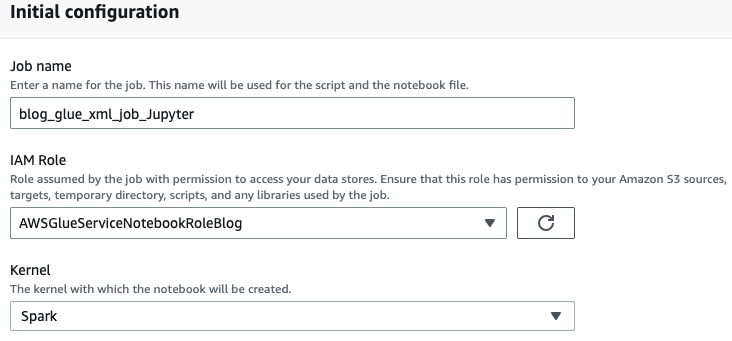
- Voer een naam in voor uw AWS Glue-taak, zoals
blog_glue_xml_job_Jupyter. - Kies de rol die u in de vereisten hebt gemaakt (
AWSGlueServiceNotebookRoleBlog).
De AWS Glue-notebook wordt geleverd met een reeds bestaand voorbeeld dat laat zien hoe u een database kunt bevragen en de uitvoer naar Amazon S3 kunt schrijven.
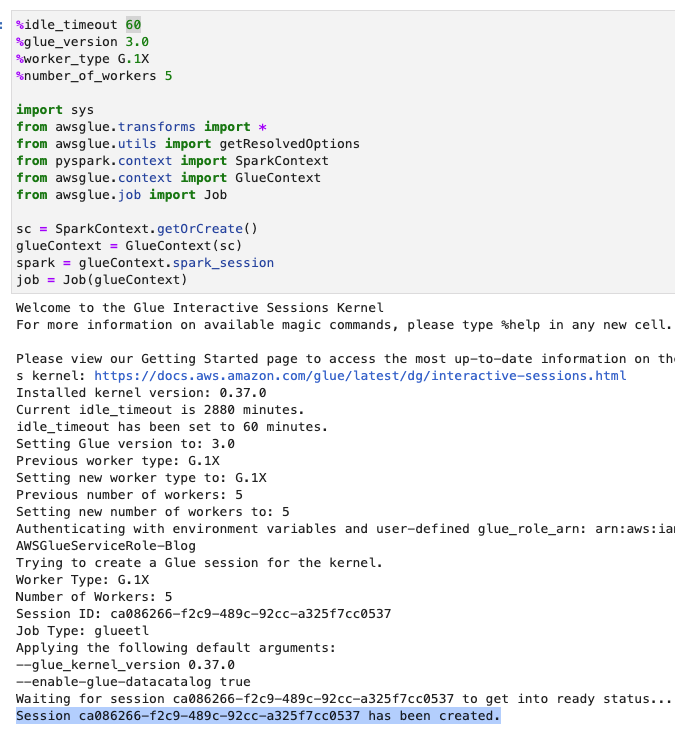
- Pas de time-out (in minuten) aan zoals weergegeven in de volgende schermafbeelding en voer de cel uit om de interactieve AWS Glue-sessie te creëren.
Maak basisvariabelen
Nadat u de interactieve sessie hebt gemaakt, maakt u aan het einde van het notitieblok een nieuwe cel met de volgende variabelen (geef uw eigen bucketnaam op):
Lees het XML-bestand dat het schema afleidt
Als u geen schema doorgeeft aan de DynamicFrame, zal het het schema van de bestanden afleiden. Om de gegevens te lezen met behulp van een dynamisch frame, kunt u de volgende opdracht gebruiken:
Druk het DynamicFrame-schema af
Print het schema met de volgende code:
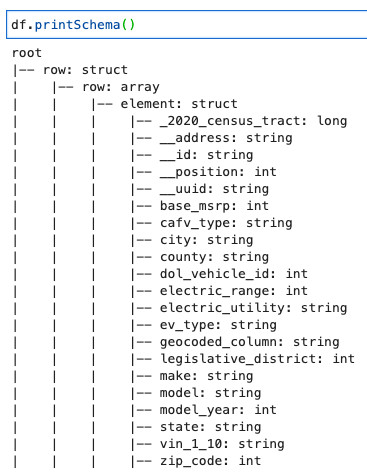
Het schema toont een geneste structuur met a row array die meerdere elementen bevat. Om deze structuur in lijnen te ontbinden, kunt u de AWS Glue gebruiken relationaliseren transformatie:
We zijn alleen geïnteresseerd in de informatie in de rijarray en we kunnen het schema bekijken met behulp van de volgende opdracht:
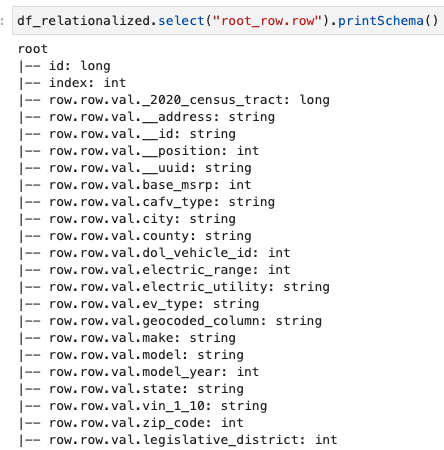
De kolomnamen bevatten row.row, die overeenkomen met de arraystructuur en arraykolom in de gegevensset. We hernoemen de kolommen in dit bericht niet; voor instructies om dit te doen, zie Automatiseer het dynamisch in kaart brengen en hernoemen van kolomnamen in gegevensbestanden met AWS Glue: Deel 1. Vervolgens kunt u de gegevens naar Parquet-indeling converteren en de AWS Glue-tabel maken met behulp van de volgende opdracht:
AWS lijm DynamicFrame biedt functies die u in uw ETL-script kunt gebruiken om een schema in de gegevenscatalogus te maken en bij te werken. Wij gebruiken de updateBehavior parameter om de tabel rechtstreeks in de gegevenscatalogus te maken. Met deze aanpak hoeven we geen AWS Glue-crawler uit te voeren nadat de AWS Glue-taak is voltooid.

Lees het XML-bestand door een schema in te stellen
Een alternatieve manier om het bestand te lezen is door een schema vooraf te definiëren. Om dit te doen, voert u de volgende stappen uit:
- Importeer de AWS Glue-gegevenstypen:
- Maak een schema voor het XML-bestand:
- Geef het schema door bij het lezen van het XML-bestand:
- Ontnes de dataset zoals voorheen:
- Converteer de dataset naar Parquet en maak de AWS Glue-tabel:
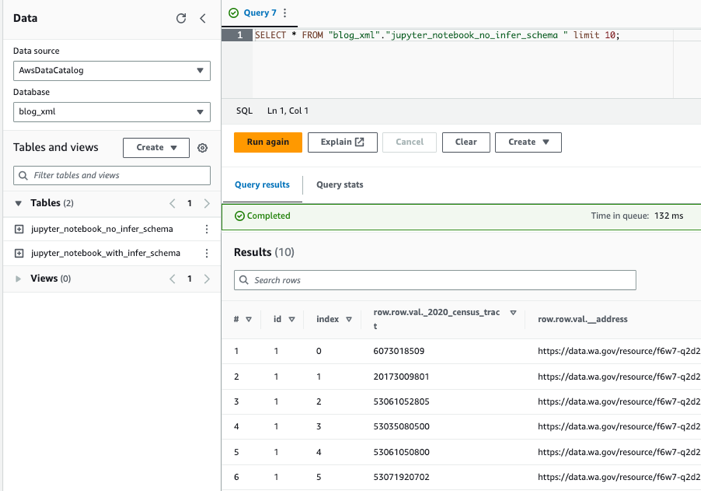
Query's uitvoeren op de tabellen met behulp van Athena
Nu we beide tabellen hebben gemaakt, kunnen we de tabellen opvragen met Athena. We kunnen bijvoorbeeld de volgende query gebruiken:
Clean Up
In dit bericht hebben we een IAM-rol, een AWS Glue Jupyter-notebook en twee tabellen in de AWS Glue Data Catalog gemaakt. We hebben ook enkele bestanden geüpload naar een S3-bucket. Voer de volgende stappen uit om deze objecten op te ruimen:
- Verwijder op de IAM-console de rol die u heeft gemaakt.
- Verwijder op de AWS Glue Studio-console de aangepaste classificatie, crawler, ETL-taken en Jupyter-notebook.
- Navigeer naar de AWS Glue Data Catalog en verwijder de tabellen die u hebt gemaakt.
- Navigeer op de Amazon S3-console naar de bucket die u hebt gemaakt en verwijder de genoemde mappen
temp,infer_schemaenno_infer_schema.
Key Takeaways
In AWS Glue is er een functie genaamd InferSchema in AWS-lijm DynamicFrames. Het berekent automatisch de structuur van een dataframe op basis van de gegevens die het bevat. Het definiëren van een schema betekent daarentegen expliciet aangeven hoe de structuur van het dataframe eruit moet zien voordat de gegevens worden geladen.
Omdat XML een op tekst gebaseerd formaat is, beperkt het de gegevenstypen van de kolommen niet. Dit kan problemen veroorzaken met de functie InferSchema. Bij de eerste uitvoering resulteert een bestand met kolom A met de waarde 2 bijvoorbeeld in een Parquet-bestand met kolom A als geheel getal. Bij de tweede run heeft een nieuw bestand kolom A met de waarde C, wat leidt tot een Parquet-bestand met kolom A als tekenreeks. Nu staan er twee bestanden op S3, elk met een kolom A met verschillende gegevenstypen, wat stroomafwaarts problemen kan veroorzaken.
Hetzelfde gebeurt met complexe gegevenstypen zoals geneste structuren of arrays. Als een bestand bijvoorbeeld één tag-invoer heeft genaamd transaction, wordt het afgeleid als een struct. Maar als een ander bestand dezelfde tag heeft, wordt dit afgeleid als een array
Ondanks deze problemen met het gegevenstype, InferSchema is handig als u het schema niet kent of als het handmatig definiëren van een schema onpraktisch is. Het is echter niet ideaal voor grote of voortdurend veranderende datasets. Het definiëren van een schema is nauwkeuriger, vooral bij complexe gegevenstypen, maar kent zijn eigen problemen, zoals handmatige inspanning en de inflexibiliteit ten aanzien van gegevenswijzigingen.
InferSchema heeft beperkingen, zoals onjuiste gevolgtrekking van gegevenstypen en problemen met het verwerken van nulwaarden. Het definiëren van een schema kent ook beperkingen, zoals handmatige inspanningen en mogelijke fouten.
De keuze tussen het afleiden en definiëren van een schema hangt af van de behoeften van het project. InferSchema is ideaal voor het snel verkennen van kleine datasets, terwijl het definiëren van een schema beter is voor grotere, complexe datasets die nauwkeurigheid en consistentie vereisen. Houd rekening met de afwegingen en beperkingen van elke methode om te kiezen wat het beste bij uw project past.
Conclusie
In dit bericht hebben we twee technieken onderzocht voor het beheren van XML-gegevens met AWS Glue, elk afgestemd op de specifieke behoeften en uitdagingen die u kunt tegenkomen.
Techniek 1 biedt een gebruiksvriendelijk pad voor degenen die de voorkeur geven aan een grafische interface. U kunt een AWS Glue-crawler en de visuele editor gebruiken om moeiteloos de tabelstructuur voor uw XML-bestanden te definiëren. Deze aanpak vereenvoudigt het gegevensbeheerproces en is vooral aantrekkelijk voor mensen die op zoek zijn naar een eenvoudige manier om met hun gegevens om te gaan.
We erkennen echter dat de crawler zijn beperkingen heeft, vooral als het gaat om XML-bestanden met rijen die groter zijn dan 1 MB. Dit is waar techniek 2 te hulp schiet. Door gebruik te maken van AWS Glue DynamicFrames Met zowel afgeleide als vaste schema's, en met behulp van een AWS Glue-notebook, kunt u op efficiënte wijze XML-bestanden van elke grootte verwerken. Deze methode biedt een robuuste oplossing die een naadloze verwerking garandeert, zelfs voor XML-bestanden met rijen die de beperking van 1 MB overschrijden.
Terwijl u door de wereld van gegevensbeheer navigeert, kunt u met deze technieken in uw toolkit weloverwogen beslissingen nemen op basis van de specifieke vereisten van uw project. Of u nu de voorkeur geeft aan de eenvoud van techniek 1 of aan de schaalbaarheid van techniek 2, AWS Glue biedt de flexibiliteit die u nodig heeft om effectief met XML-gegevens om te gaan.
Over de auteurs
 Navnit Shuklafungeert als AWS Specialist Solution Architect met een focus op Analytics. Hij beschikt over een groot enthousiasme om klanten te helpen bij het ontdekken van waardevolle inzichten uit hun data. Door zijn expertise bouwt hij innovatieve oplossingen die bedrijven in staat stellen tot weloverwogen, datagestuurde keuzes te komen. Navnit Shukla is met name de ervaren auteur van het boek getiteld “Data Wrangling on AWS.
Navnit Shuklafungeert als AWS Specialist Solution Architect met een focus op Analytics. Hij beschikt over een groot enthousiasme om klanten te helpen bij het ontdekken van waardevolle inzichten uit hun data. Door zijn expertise bouwt hij innovatieve oplossingen die bedrijven in staat stellen tot weloverwogen, datagestuurde keuzes te komen. Navnit Shukla is met name de ervaren auteur van het boek getiteld “Data Wrangling on AWS.
 Patrick Müller werkt als Senior Data Lab Architect bij AWS. Zijn belangrijkste verantwoordelijkheid is het helpen van klanten bij het omzetten van hun ideeën in een productieklaar dataproduct. In zijn vrije tijd houdt Patrick van voetballen, films kijken en reizen.
Patrick Müller werkt als Senior Data Lab Architect bij AWS. Zijn belangrijkste verantwoordelijkheid is het helpen van klanten bij het omzetten van hun ideeën in een productieklaar dataproduct. In zijn vrije tijd houdt Patrick van voetballen, films kijken en reizen.
 Amogh Gaikwad is een Senior Solutions Developer bij Amazon Web Services. Hij helpt wereldwijde klanten bij het bouwen en implementeren van AI/ML-oplossingen op AWS. Zijn werk is voornamelijk gericht op computervisie en natuurlijke taalverwerking en het helpen van klanten bij het optimaliseren van hun AI/ML-workloads voor duurzaamheid. Amogh heeft zijn master Computerwetenschappen behaald, gespecialiseerd in Machine Learning.
Amogh Gaikwad is een Senior Solutions Developer bij Amazon Web Services. Hij helpt wereldwijde klanten bij het bouwen en implementeren van AI/ML-oplossingen op AWS. Zijn werk is voornamelijk gericht op computervisie en natuurlijke taalverwerking en het helpen van klanten bij het optimaliseren van hun AI/ML-workloads voor duurzaamheid. Amogh heeft zijn master Computerwetenschappen behaald, gespecialiseerd in Machine Learning.
 Sheela Sonone is een Senior Resident Architect bij AWS. Ze helpt AWS-klanten bij het maken van weloverwogen keuzes en afwegingen over het versnellen van hun data-, analyse- en AI/ML-workloads en -implementaties. In haar vrije tijd brengt ze graag tijd door met haar gezin, meestal op de tennisbanen.
Sheela Sonone is een Senior Resident Architect bij AWS. Ze helpt AWS-klanten bij het maken van weloverwogen keuzes en afwegingen over het versnellen van hun data-, analyse- en AI/ML-workloads en -implementaties. In haar vrije tijd brengt ze graag tijd door met haar gezin, meestal op de tennisbanen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Over
- SAMENVATTING
- versnellen
- toegang
- de toegankelijkheid
- volbracht
- nauwkeurigheid
- over
- Actie
- toevoegen
- toegevoegd
- Extra
- adres
- Na
- leeftijd
- AI / ML
- Alles
- toelaten
- Het toestaan
- toestaat
- ook
- alternatief
- Amazone
- Amazone Athene
- Amazon Web Services
- an
- analyse
- analytics
- analyseren
- het analyseren van
- en
- Nog een
- elke
- apache
- aantrekkelijk
- toepassingen
- Solliciteer
- nadering
- benaderingen
- architectuur
- ZIJN
- reeks
- AS
- helpen
- bijstaan
- At
- auteur
- webmaster.
- Beschikbaar
- AWS
- AWS lijm
- terug
- gebaseerde
- basis-
- BE
- omdat
- vaardigheden
- beginnen
- wezen
- BEST
- Betere
- tussen
- blanco
- boek
- zowel
- bouw
- ondernemingen
- maar
- by
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- CAN
- catalogus
- Veroorzaken
- cel
- uitdagingen
- verandering
- Wijzigingen
- veranderende
- keuzes
- Kies
- Plaats
- classificatie
- klanten
- code
- Kolom
- columns
- COM
- komt
- Gemeen
- algemeen
- compleet
- Voltooid
- complex
- computer
- Computer Science
- Computer visie
- voorwaarde
- Gedrag
- samenwerking
- Overwegen
- troosten
- permanent
- beperkingen
- bouwen
- bevatten
- bevatte
- bevat
- contrast
- onder controle te houden
- converteren
- geconverteerd
- kostenefficient
- kosteneffectieve oplossing
- provincie
- Rechtbanken
- bedekt
- crawler
- en je merk te creëren
- aangemaakt
- Wij creëren
- cruciaal
- gewoonte
- klant
- Klanten
- gegevens
- gegevens integratie
- gegevensbeheer
- Gegevensgestuurde
- Database
- datasets
- omgang
- beslissingen
- Standaard
- bepalen
- het definiëren van
- delven
- demonstreert
- afhankelijk
- implementeren
- ontworpen
- gedetailleerd
- gegevens
- Ontwikkelaar
- anders
- moeilijk
- digitaal
- digitale tijdperk
- direct
- het ontdekken van
- onderscheiden
- do
- Nee
- gedaan
- Dont
- DOT
- gedurende
- dynamisch
- elk
- gemak
- gemakkelijk
- En het is heel gemakkelijk
- editor
- effect
- effectief
- doeltreffendheid
- doeltreffend
- efficiënt
- inspanning
- moeiteloos
- Elektrisch
- elektrisch voertuig
- geeft je de mogelijkheid
- gebruik
- machtigen
- machtigt
- leeg
- in staat stellen
- waardoor
- ontmoeting
- einde
- Motoren
- verhogen
- verzekeren
- waarborgt
- Enter
- enthousiasme
- toegang
- fouten
- vooral
- Ether (ETH)
- Zelfs
- EVENTS
- Alle
- voorbeeld
- overtreffen
- uitwisselen
- expertise
- exploratie
- Verken
- Nagegaan
- extract
- extractie
- familie
- Kenmerk
- Voordelen
- Figuren
- Dien in
- Bestanden
- financiën
- Voornaam*
- vast
- Flexibiliteit
- Focus
- gericht
- volgend
- Voor
- formaat
- FRAME
- Gratis
- Frequentie
- oppompen van
- functie
- Krijgen
- voor algemeen gebruik
- voortbrengen
- Globaal
- Go
- doel
- Overheid
- groot
- handvat
- Behandeling
- gebeurt
- Benutten
- Hebben
- met
- he
- gezondheidszorg
- Hart
- hulp
- het helpen van
- helpt
- haar
- high-level
- zeer
- zijn
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- IAM
- ideaal
- ideeën
- Identiteit
- if
- illustreert
- uitvoeren
- implementaties
- uitvoering
- importeren
- verbeteren
- verbeterd
- in
- Inclusief
- individueel
- individuen
- industrieën
- informatie
- op de hoogte
- Infrastructuur
- innovatieve
- binnen
- inzichten
- verkrijgen in plaats daarvan
- instructies
- integreren
- integratie
- interactieve
- geïnteresseerd
- Interface
- in
- gaat
- problemen
- IT
- HAAR
- Jobomschrijving:
- Vacatures
- jpg
- json
- Jupyter Notebook
- Houden
- blijven
- laboratorium
- taal
- Groot
- groter
- leidend
- LEARN
- leren
- Niveau
- als
- LIMIT
- beperking
- beperkingen
- Lijn
- lijnen
- laden
- het laden
- logica
- op zoek
- machine
- machine learning
- Hoofd
- voornamelijk
- maken
- maken
- management
- beheren
- handboek
- handmatig
- veel
- in kaart brengen
- master's
- Mei..
- middel
- Menu
- Metadata
- methode
- minuten
- model
- meer
- efficiënter
- meest
- beweging
- Films
- meervoudig
- naam
- Genoemd
- namen
- Naturel
- Natuurlijke taal
- Natural Language Processing
- OP DEZE WEBSITE VIND JE
- Navigatie
- noodzakelijk
- Noodzaak
- behoeften
- New
- onlangs
- volgende
- in het bijzonder
- notitieboekje
- nu
- aantal
- objecten
- of
- Aanbod
- on
- EEN
- Slechts
- Operations
- optimale
- Optimaliseer
- Optimaliseert
- Opties
- or
- bestellen
- organisaties
- Oorsprong
- Overige
- onze
- uit
- uitgang
- over
- Overwinnen
- het te bezitten.
- pagina
- brood
- parameter
- parameters
- deel
- vooral
- passeren
- pad
- patrick
- uitvoeren
- prestatie
- permissies
- kiezen
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- beleidsmaatregelen
- bevolking
- bezitten
- Post
- potentieel
- nauwkeurig
- de voorkeur geven
- vereisten
- Voorbeschouwing
- vorig
- problemen
- verwerkt
- verwerking
- Product
- project
- projecten
- vastgoed
- zorgen voor
- biedt
- publiceren
- doel
- Python
- queries
- Quick
- liever
- Lees
- gemakkelijk
- lezing
- redenen
- ontvangen
- herkennen
- verwijzen
- relevante
- Voorwaarden
- redden
- hulpbron
- antwoord
- verantwoordelijkheid
- REST
- beperken
- beperking
- Resultaten
- robuust
- Rol
- wortel
- RIJ
- lopen
- dezelfde
- Bespaar
- Scala
- Schaalbaarheid
- schaalbare
- Wetenschap
- script
- naadloos
- naadloos
- Tweede
- sectie
- zien
- senior
- Diensten
- Sessie
- reeks
- het instellen van
- verscheidene
- ze
- Shell
- moet
- tonen
- getoond
- Shows
- gelijk
- Eenvoudig
- eenvoud
- vereenvoudigen
- single
- Maat
- Klein
- So
- Voetbal
- oplossing
- Oplossingen
- sommige
- bron
- bronnen
- Vonk
- specialist
- gespecialiseerd
- specifiek
- specifiek
- snelheid
- Uitgaven
- SQL
- standaard
- starts
- Land
- Statement
- vermelding
- Stap voor
- Stappen
- mediaopslag
- opgeslagen
- eenvoudig
- gestroomlijnd
- Draad
- sterke
- structuur
- structuren
- studio
- succes
- dergelijk
- geschikt
- ondersteuning
- zeker
- Duurzaamheid
- Systems
- tafel
- TAG
- op maat gemaakt
- Nemen
- neemt
- taken
- technieken
- tennis
- neem contact
- dat
- De
- de informatie
- de wereld
- hun
- Ze
- harte
- Er.
- Deze
- ze
- dit
- die
- Door
- niet de tijd of
- Titel
- getiteld
- naar
- vandaag
- toolkit
- top
- onderwerp
- Transformeren
- Transformatie
- Reizend
- Draai
- zelfstudie
- twee
- type dan:
- types
- ultieme
- voor
- bijwerken
- bijgewerkt
- geüpload
- us
- bruikbaarheid
- .
- gebruikt
- Gebruiker
- User Interface
- gebruiksvriendelijke
- toepassingen
- gebruik
- doorgaans
- Gebruik makend
- waardevol
- waarde
- Values
- voertuig
- versie
- via
- Bekijk
- .
- visie
- kijken
- Manier..
- we
- web
- webservices
- Wat
- wanneer
- terwijl
- of
- welke
- WIE
- Waarom
- wil
- Met
- binnen
- zonder
- Mijn werk
- workflow
- workflows
- Bedrijven
- wereld
- schrijven
- XML
- u
- Your
- zephyrnet