Afbeelding gegenereerd met DALL-E
In een tijd waarin data-analytische verwerking het cruciale verschil is tussen een succesvol bedrijf en niet, hebben we een toolset nodig die aan de behoeften kan voldoen. De vooruitgang van de technologie heeft bijgedragen aan de vooruitgang van al deze datatools die we nodig hebben, namelijk DuckDB en MotherDuck.
DuckDB is een open-source, in-process SQL Online Analytical Processing (OLAP) databasebeheersysteem. Het databasesysteem is ontworpen voor het snel verwerken van gegevensanalysevragen, ongeacht de gegevensgrootte. Het systeem implementeert in-memory processing en OLAP-systemen die ons gegevensanalyseproces effectief verbeteren.
DuckDB is perfect voor het opslaan en verwerken van gegevens in tabelvorm waarbij gegevensanalyse nodig is (samenvoegen van tabellen, gegevensaggregatie, enz.) en wanneer onze workflow gewoonlijk aanzienlijke wijzigingen in de tabel met zich meebrengt. Aan de andere kant is DuckDB niet geschikt voor grote gegevensactiviteiten en meerdere gelijktijdige processen in één database.
Moeder Eend is een beheerde DuckDB-in-the-cloud-service. Het is gratis te gebruiken en open-source terwijl het wordt onderhouden door de DuckDB-gemeenschap. Het is een service die is gebouwd door samen te werken met DuckDB Lab om een cloudserviceplatform te creëren dat het publiek kan gebruiken.
Met een combinatie van DuckDB en Motherduck kunnen we een analyse-engine creëren die in elk scenario direct bruikbaar is. Hoe doen we dat? Laten we erop ingaan.
We zouden de native MotherDuck-gebruikersinterface gebruiken om u een voorbeeld te geven van hoe de service werkt en waarom DuckDB een krachtig hulpmiddel is voor gegevensanalyse. Registreer u op de website en verkrijg het MotherDuck-account als u dat nog niet heeft gedaan.
Zodra u zich succesvol heeft geregistreerd voor het MotherDuck-account, worden we naar de MotherDuck-gebruikersinterface geleid. Probeer vertrouwd te raken met de gebruikersinterface en u zult zich realiseren dat de gebruikersinterface vergelijkbaar is met de Jupyter Notebook als u er ooit een gebruikt.
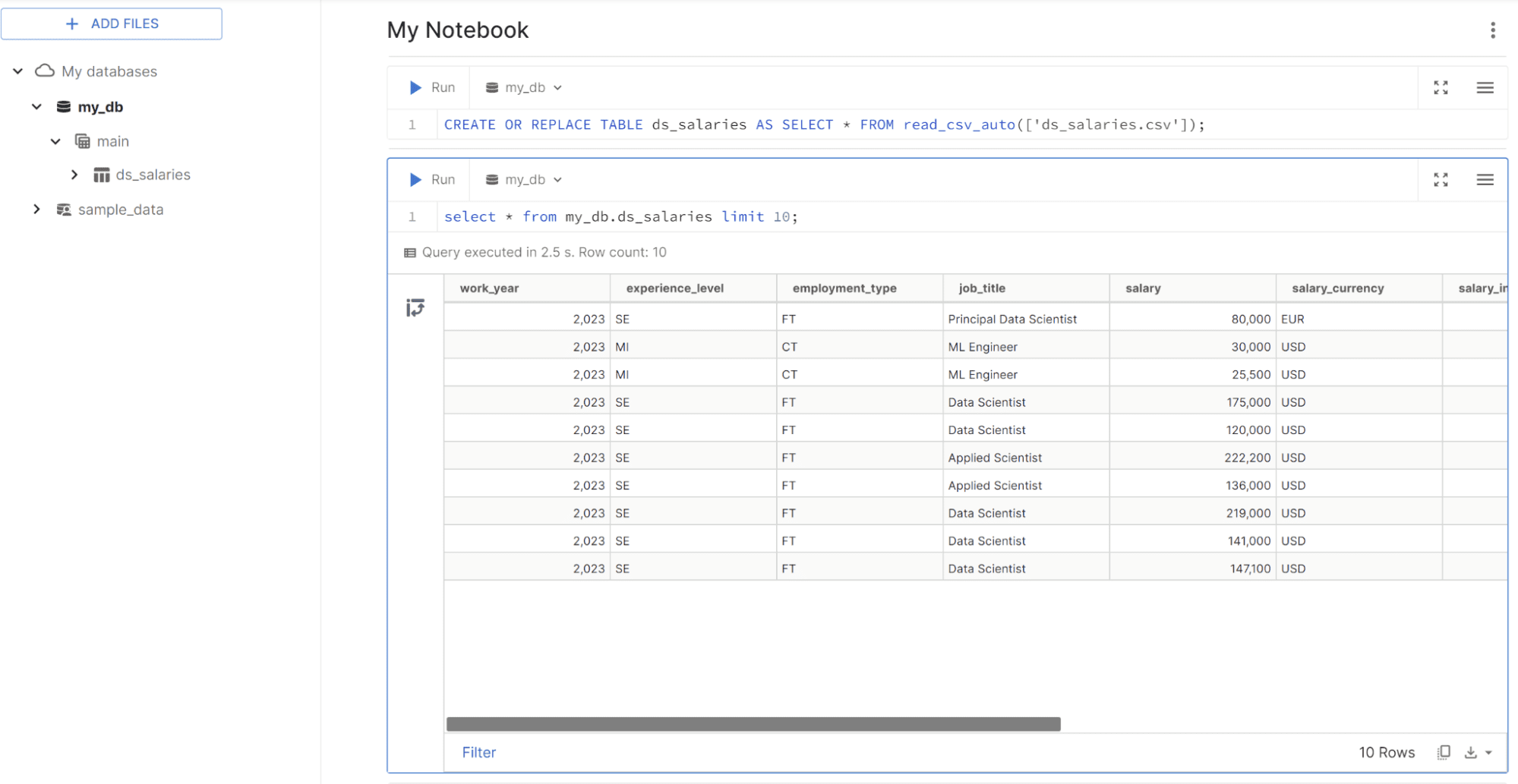
We zullen experimenteren met de DBduck-kracht in de MotherDuck-gebruikersinterface met de DS-salarisgegevens van Kaggle. Upload de gegevens met behulp van de knop Bestanden toevoegen en er wordt een nieuwe cel weergegeven met de uit te voeren query. De query zou er als volgt uit moeten zien.
CREATE OR REPLACE TABLE ds_salaries AS SELECT * FROM read_csv_auto(['ds_salaries.csv']);
Nadat u de tabel heeft gemaakt, probeert u de gegevens op te vragen met de volgende code.
select * from my_db.ds_salaries limit 10;
Zoals je ziet lijkt MotherDuck op het uitvoeren van data-analyse in Notebook, maar dan met SQL-query's. Laten we de query uitproberen om gegevensanalyse uit te voeren in MotherDuck.
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
U kunt de query in de cel uitvoeren; het tabelresultaat wordt op dezelfde manier weergegeven als de onderstaande afbeelding.
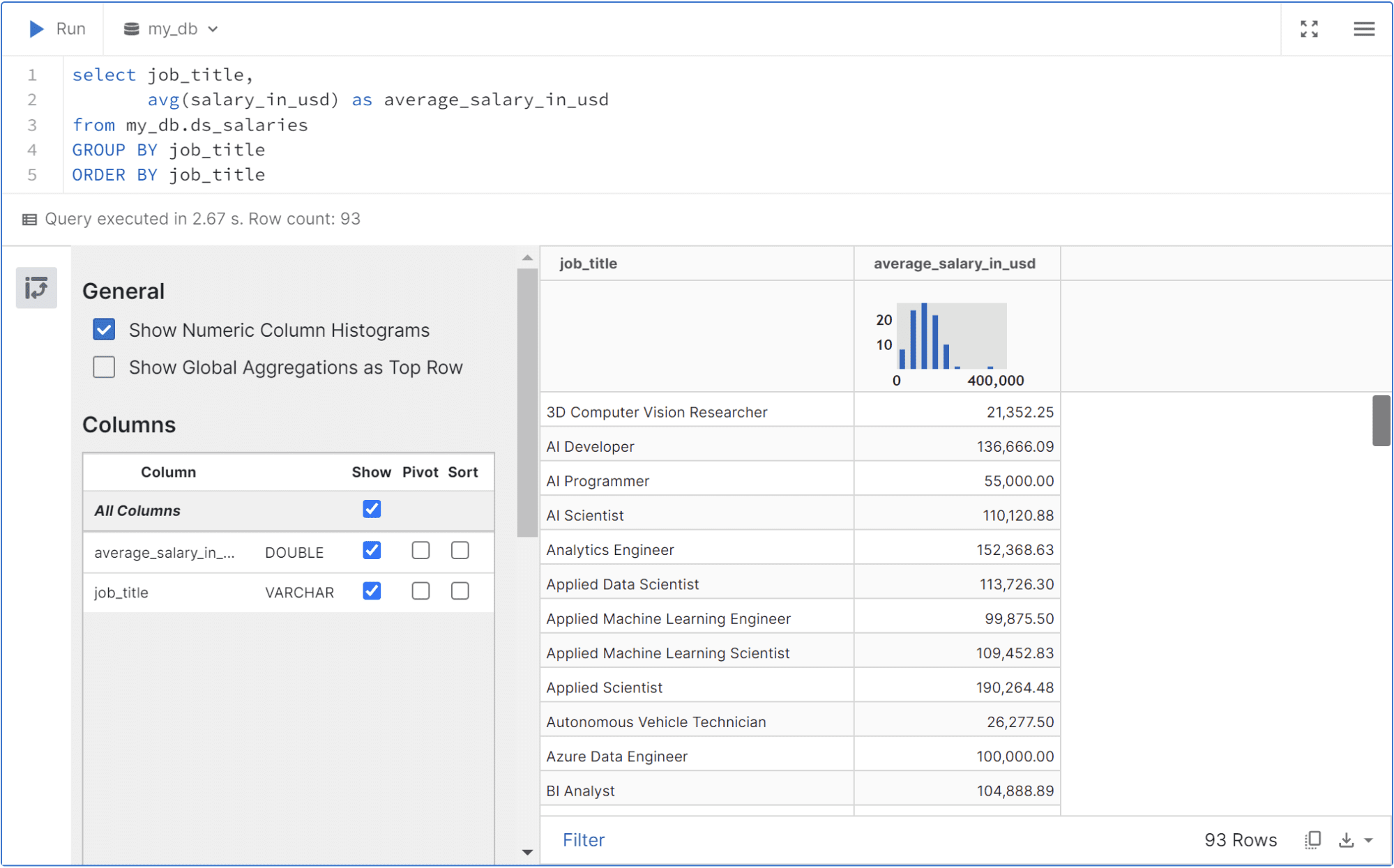
U kunt de gegevens filteren, de tabel draaien of het resultaat downloaden met de selectieknop die beschikbaar is in de gebruikersinterface.
Met MotherDuck heeft de gebruiker ook toegang tot de database via Python op uw notebook. We moeten het DuckDB-pakket installeren met behulp van de volgende code.
pip install duckdb==v0.9.2
De huidige versie die MotherDuck ondersteunt is DuckDB 0.9.2; daarom hebben we die versie geïnstalleerd.
Wanneer de installatie succesvol is, moeten we de DuckDB verbinden met de Motherduck. Er zijn een paar manieren om de verbinding te verifiëren, maar we zouden het servicetoken gebruiken. Dit token kun je verkrijgen in je MotherDuck-instellingen.
import duckdb
token = "insert token here"
# initiate the MotherDuck connection
con = duckdb.connect(f'md:?motherduck_token={token}')
Als we geen databasenaam hadden ingesteld, zou MotherDuck toegang krijgen via de standaarddatabase, namelijk my_db. Laten we vervolgens dezelfde query gebruiken die we eerder in Notebook hebben gedaan.
q = """
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
"""
con.sql(q).show()
U zult de uitvoer zien die vergelijkbaar is met de onderstaande tabel.
┌─────────────────────────────────────┬───────────────────────┐
│ job_title │ average_salary_in_usd │
│ varchar │ double │
├─────────────────────────────────────┼───────────────────────┤
│ 3D Computer Vision Researcher │ 21352.25 │
│ AI Developer │ 136666.0909090909 │
│ AI Programmer │ 55000.0 │
│ AI Scientist │ 110120.875 │
│ Analytics Engineer │ 152368.63106796116 │
│ Applied Data Scientist │ 113726.3 │
│ Applied Machine Learning Engineer │ 99875.5 │
│ Applied Machine Learning Scientist │ 109452.83333333333 │
│ Applied Scientist │ 190264.4827586207 │
│ Autonomous Vehicle Technician │ 26277.5 │
│ · │ · │
│ · │ · │
│ · │ · │
│ Principal Data Engineer │ 192500.0 │
│ Principal Data Scientist │ 198171.125 │
│ Principal Machine Learning Engineer │ 190000.0 │
│ Product Data Analyst │ 56497.2 │
│ Product Data Scientist │ 8000.0 │
│ Research Engineer │ 163108.37837837837 │
│ Research Scientist │ 161214.19512195123 │
│ Software Data Engineer │ 62510.0 │
│ Staff Data Analyst │ 15000.0 │
│ Staff Data Scientist │ 105000.0 │
├─────────────────────────────────────┴───────────────────────┤
│ 93 rows (20 shown) 2 columns │
└─────────────────────────────────────────────────────────────┘
Met de bovenstaande query kunt u de volgende code gebruiken om ze in het Pandas DataFrame te verwerken.
import pandas as pd
df = con.sql(q).fetchdf()
Ten slotte kunt u met de volgende query nog een gegevensset in de database laden.
con.sql("CREATE TABLE mytable AS SELECT * FROM '~/filepath.csv'")
Bij de bovenstaande zoekopdracht wordt ervan uitgegaan dat uw gegevens een CSV-bestand zijn. Andere opties zijn onder meer S3 of de lokale DuckDB naar de MotherDuck-database.
DuckDB is een open-source databasesysteem dat speciaal is ontwikkeld voor data-analyse. Het systeem is ontworpen om de gegevensverwerking snel en efficiënt af te handelen. MotherDuck is een open-source beheerde cloudgebaseerde service voor DuckDB.
Door DuckDB en MotherDuck te combineren, kunnen we van onze laptops een persoonlijke analyse-engine maken door onze gegevens in de cloud te hebben en deze snel te verwerken met DuckDB.
Cornellius Yudha Wijaya is een data science assistent-manager en dataschrijver. Terwijl hij fulltime bij Allianz Indonesia werkt, deelt hij graag Python- en Data-tips via sociale media en schrijvende media.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/turn-your-laptop-into-a-personal-analytics-engine-with-duckdb-and-motherduck?utm_source=rss&utm_medium=rss&utm_campaign=turn-your-laptop-into-a-personal-analytics-engine-with-duckdb-and-motherduck
- : heeft
- :is
- :niet
- :waar
- 10
- 125
- 15000
- 20
- 25
- 3d
- 7
- 8
- 8000
- 9
- a
- boven
- toegang
- Account
- verwerven
- verworven
- activiteit
- toevoegen
- bevorderen
- vordering
- aggregatie
- AI
- Alles
- Allianz
- toestaat
- al
- ook
- an
- analyse
- analist
- analytisch
- Analytisch
- analytics
- en
- Nog een
- elke
- toegepast
- ZIJN
- AS
- Assistent
- gaat uit van
- At
- waarmerken
- autonoom
- autonoom voertuig
- Beschikbaar
- BE
- onder
- tussen
- bebouwd
- bedrijfsdeskundigen
- maar
- by
- CAN
- cel
- Wijzigingen
- Cloud
- code
- columns
- combinatie van
- combineren
- gemeenschap
- computer
- Computer visie
- gelijktijdig
- Verbinden
- versterken
- kon
- en je merk te creëren
- kritisch
- Actueel
- gegevens
- gegevensanalyse
- data-analist
- gegevens Analytics
- data engineer
- gegevensverwerking
- data science
- data scientist
- Database
- Standaard
- ontworpen
- ontwikkelde
- Ontwikkelaar
- DEED
- verschil
- do
- doen
- verdubbelen
- Download
- effectief
- efficiënt
- Motor
- ingenieur
- etc
- Ether (ETH)
- OOIT
- Alle
- voorbeeld
- uitvoeren
- experiment
- vertrouwd raken
- weinig
- Dien in
- Bestanden
- filter
- volgend
- Voor
- Gratis
- oppompen van
- gegenereerde
- krijgen
- Geven
- Groep
- hand
- handvat
- Behandeling
- met
- he
- geholpen
- hier
- Hoe
- HTTPS
- if
- beeld
- gereedschap
- verbeteren
- in
- omvatten
- Indonesië
- beginnen
- installeren
- installatie
- in
- gaat
- waarbij
- IT
- mee
- Jupyter Notebook
- KDnuggets
- laboratorium
- laptop
- laptops
- leren
- als
- LIMIT
- laden
- lokaal
- Kijk
- ziet eruit als
- houdt
- machine
- machine learning
- beheerd
- management
- beheersysteem
- manager
- Media
- veel
- meervoudig
- naam
- namelijk
- inheemse
- Noodzaak
- behoeften
- New
- volgende
- notitieboekje
- of
- on
- EEN
- online.
- open source
- Opties
- or
- bestellen
- Overige
- onze
- uit
- uitgang
- pakket
- panda's
- partnering
- persoonlijk
- Spil
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- dan
- energie
- krachtige
- mooi
- die eerder
- Principal
- processen
- verwerking
- Product
- Programmeur
- publiek
- Python
- queries
- snel
- gemakkelijk
- realiseren
- achteloos
- registreren
- vervangen
- onderzoek
- onderzoeker
- resultaat
- salaris
- dezelfde
- scenario
- Wetenschap
- Wetenschapper
- zien
- kiezen
- selectie
- service
- reeks
- settings
- Delen
- moet
- getoond
- aanzienlijke
- gelijk
- evenzo
- Maat
- Social
- social media
- Software
- specifiek
- SQL
- stack
- Medewerkers
- geslaagd
- Met goed gevolg
- geschikt
- ondersteuning
- steunen
- snel
- system
- Systems
- tafel
- ingenomen
- Technologie
- dat
- De
- Ze
- Er.
- Deze
- dit
- niet de tijd of
- tips
- naar
- teken
- tools
- tools
- proberen
- BEURT
- ui
- .
- Gebruiker
- gebruik
- doorgaans
- voertuig
- versie
- via
- visie
- was
- manieren
- we
- Website
- wanneer
- welke
- en
- Waarom
- wil
- Met
- workflow
- werkzaam
- Bedrijven
- zou
- schrijver
- het schrijven van
- u
- Your
- jezelf
- zephyrnet