Als u een bedrijfsanalist bent, is het begrijpen van klantgedrag waarschijnlijk een van de belangrijkste dingen waar u om geeft. Inzicht in de redenen en mechanismen achter aankoopbeslissingen van klanten kan de omzetgroei vergemakkelijken. Het verlies van klanten (gewoonlijk aangeduid als klantverloop) brengt altijd een risico met zich mee. Inzicht krijgen in waarom klanten weggaan, kan net zo cruciaal zijn voor het behoud van winst en omzet.
Hoewel machine learning (ML) waardevolle inzichten kan opleveren, waren ML-experts nodig om voorspellingsmodellen voor klantverloop te bouwen tot de introductie van Amazon SageMaker-canvas.
SageMaker Canvas is een beheerde service met weinig/geen code waarmee u ML-modellen kunt maken die veel bedrijfsproblemen kunnen oplossen zonder ook maar één regel code te schrijven. Het stelt u ook in staat de modellen te evalueren met behulp van geavanceerde statistieken alsof u een datawetenschapper bent.
In dit bericht laten we zien hoe een bedrijfsanalist een classificatieverloopmodel dat is gemaakt met SageMaker Canvas kan evalueren en begrijpen met behulp van de Geavanceerde statistieken tabblad. We leggen de statistieken uit en laten technieken zien om met gegevens om te gaan om betere modelprestaties te verkrijgen.
Voorwaarden
Als je alle of een deel van de taken die in dit bericht worden beschreven wilt implementeren, heb je een AWS-account nodig met toegang tot SageMaker Canvas. Verwijzen naar Voorspel klantverloop met machine learning zonder code met Amazon SageMaker Canvas om de basisprincipes van SageMaker Canvas, het churn-model en de dataset te behandelen.
Inleiding tot de evaluatie van modelprestaties
Als algemene richtlijn geldt dat wanneer u de prestaties van een model moet evalueren, u probeert te meten hoe goed het model iets zal voorspellen wanneer het nieuwe gegevens ziet. Deze voorspelling wordt genoemd gevolgtrekking. U begint met het trainen van het model met behulp van bestaande gegevens en vraagt het model vervolgens de uitkomst te voorspellen op basis van gegevens die het nog niet heeft gezien. Hoe nauwkeurig het model deze uitkomst voorspelt, is waar u naar kijkt om de prestaties van het model te begrijpen.
Als het model de nieuwe gegevens niet heeft gezien, hoe kan iemand dan weten of de voorspelling goed of slecht is? Het idee is om daadwerkelijk historische gegevens te gebruiken waarvan de resultaten al bekend zijn, en deze waarden te vergelijken met de voorspelde waarden van het model. Dit wordt mogelijk gemaakt door een deel van de historische trainingsgegevens opzij te zetten, zodat deze kunnen worden vergeleken met wat het model voorspelt voor die waarden.
In het voorbeeld van klantenverloop (wat een categorisch classificatieprobleem is) begint u met een historische dataset die klanten beschrijft met veel attributen (één in elke record). Een van de kenmerken, genaamd Churn, kan Waar of Onwaar zijn en beschrijft of de klant de service heeft verlaten of niet. Om de nauwkeurigheid van het model te evalueren, splitsen we deze dataset en trainen we het model met behulp van één deel (de trainingsdataset), en vragen we het model om de uitkomst te voorspellen (de klant classificeren als Churn of niet) met het andere deel (de testdataset). Vervolgens vergelijken we de voorspelling van het model met de grondwaarheid in de testdataset.
Geavanceerde statistieken interpreteren
In deze sectie bespreken we de geavanceerde statistieken in SageMaker Canvas die u kunnen helpen de modelprestaties te begrijpen.
Verwarring matrix
SageMaker Canvas maakt gebruik van verwarringsmatrices om u te helpen visualiseren wanneer een model correct voorspellingen genereert. In een verwarringsmatrix worden uw resultaten gerangschikt om de voorspelde waarden te vergelijken met de werkelijke historische (bekende) waarden. In het volgende voorbeeld wordt uitgelegd hoe een verwarringsmatrix werkt voor een voorspellingsmodel met twee categorieën dat positieve en negatieve labels voorspelt:
- Echt positief – Het model voorspelde correct positief terwijl het echte label positief was
- Echt negatief – Het model voorspelde correct negatief terwijl het echte label negatief was
- Vals positief – Het model voorspelde ten onrechte positief terwijl het echte label negatief was
- Fout negatief – Het model voorspelde ten onrechte negatief terwijl het echte label positief was
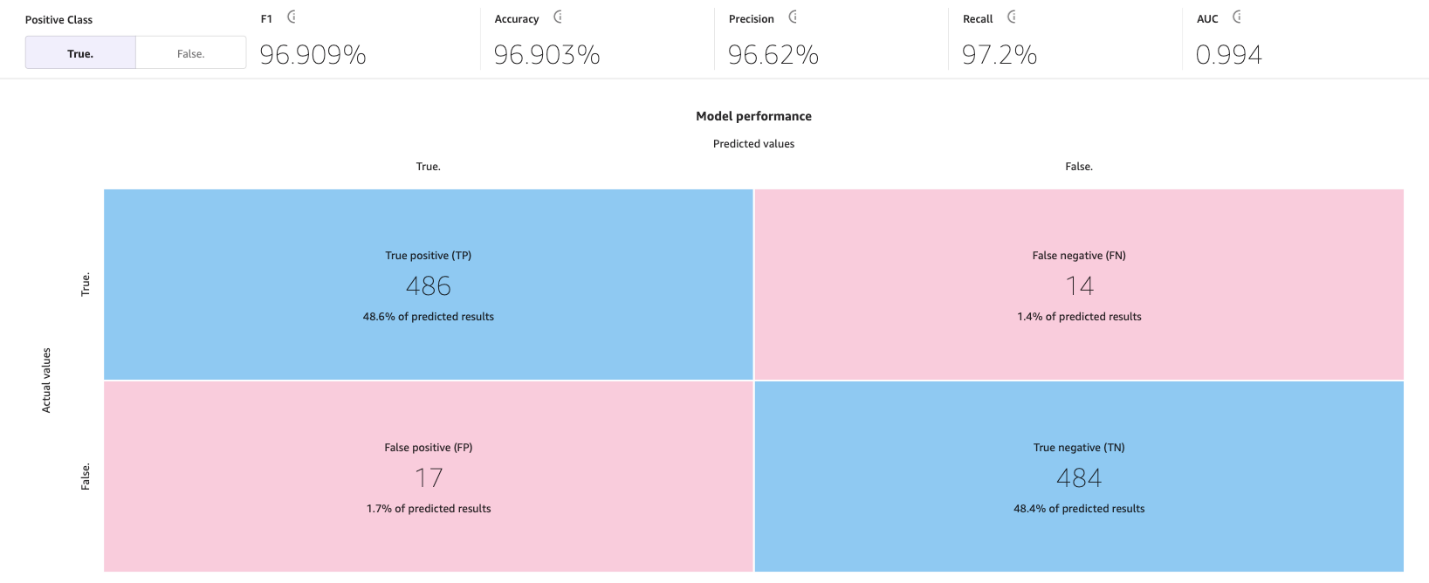
De volgende afbeelding is een voorbeeld van een verwarringsmatrix voor twee categorieën. In ons churn-model komen de werkelijke waarden uit de testdataset en komen de voorspelde waarden uit het vragen van ons model.
Nauwkeurigheid
Nauwkeurigheid is het percentage correcte voorspellingen uit alle rijen of voorbeelden van de testset. Het zijn de echte monsters die als True zijn voorspeld, plus de valse monsters die correct als False zijn voorspeld, gedeeld door het totale aantal monsters in de dataset.
Het is een van de belangrijkste statistieken om te begrijpen, omdat het u vertelt in welk percentage het model correct heeft voorspeld, maar het kan in sommige gevallen misleidend zijn. Bijvoorbeeld:
- Klasse onbalans – Wanneer de klassen in uw dataset niet gelijkmatig verdeeld zijn (u heeft een onevenredig groot aantal steekproeven uit de ene klasse en heel weinig uit de andere), kan de nauwkeurigheid misleidend zijn. In dergelijke gevallen kan zelfs een model dat eenvoudigweg de meerderheidsklasse voor elke instantie voorspelt, een hoge nauwkeurigheid bereiken.
- Kostengevoelige classificatie – In sommige toepassingen kunnen de kosten van verkeerde classificatie voor verschillende klassen verschillend zijn. Als we bijvoorbeeld voorspellen of een medicijn een aandoening kan verergeren, kan een vals-negatief (bijvoorbeeld voorspellen dat het medicijn misschien niet verergert terwijl dit in werkelijkheid wel het geval is) duurder zijn dan een vals-positief (bijvoorbeeld voorspellen dat het medicijn de aandoening kan verergeren). terwijl dat in werkelijkheid niet het geval is).
Precisie, terugroepactie en F1-score
Precisie is de fractie echte positieven (TP) van alle voorspelde positieven (TP + FP). Het meet het percentage positieve voorspellingen dat daadwerkelijk correct is.
Recall is de fractie echte positieven (TP) van alle daadwerkelijke positieven (TP + FN). Het meet het aandeel positieve gevallen dat door het model correct als positief werd voorspeld.
De F1-score combineert precisie en herinnering om één enkele score te bieden die de balans daartussen in evenwicht brengt. Het wordt gedefinieerd als het harmonische gemiddelde van precisie en herinnering:
F1-score = 2 * (precisie * terugroepen) / (precisie + terugroepen)
De F1-score varieert van 0-1, waarbij een hogere score betere prestaties aangeeft. Een perfecte F1-score van 1 geeft aan dat het model zowel perfecte precisie als perfecte herinnering heeft bereikt, en een score van 0 geeft aan dat de voorspellingen van het model volkomen verkeerd zijn.
De F1-score biedt een evenwichtige evaluatie van de prestaties van het model. Het houdt rekening met precisie en herinnering, en biedt een meer informatieve evaluatiemetriek die het vermogen van het model weerspiegelt om positieve gevallen correct te classificeren en valse positieven en valse negatieven te vermijden.
Bij medische diagnoses, fraudedetectie en sentimentanalyse is F1 bijvoorbeeld bijzonder relevant. Bij medische diagnoses is het nauwkeurig identificeren van de aanwezigheid van een specifieke ziekte of aandoening van cruciaal belang, en vals-negatieven of vals-positieven kunnen aanzienlijke gevolgen hebben. De F1-score houdt rekening met zowel precisie (het vermogen om positieve gevallen correct te identificeren) als herinnering (het vermogen om alle positieve gevallen te vinden), wat een evenwichtige evaluatie oplevert van de prestaties van het model bij het detecteren van de ziekte. Op soortgelijke wijze kan bij de detectie van fraude, waar het aantal daadwerkelijke fraudegevallen relatief laag is in vergelijking met niet-frauduleuze gevallen (onevenwichtige klassen), de nauwkeurigheid alleen al misleidend zijn vanwege het grote aantal echte negatieven. De F1-score biedt een uitgebreide maatstaf voor het vermogen van het model om zowel frauduleuze als niet-frauduleuze gevallen op te sporen, waarbij rekening wordt gehouden met zowel precisie als herinnering. En als bij sentimentanalyse de dataset onevenwichtig is, weerspiegelt de nauwkeurigheid mogelijk niet nauwkeurig de prestaties van het model bij het classificeren van instanties van de positieve sentimentklasse.
AUC (oppervlakte onder de curve)
De AUC-metriek evalueert het vermogen van een binair classificatiemodel om bij alle classificatiedrempels onderscheid te maken tussen positieve en negatieve klassen. A drempel is een waarde die door het model wordt gebruikt om een beslissing te nemen tussen de twee mogelijke klassen, waarbij de waarschijnlijkheid dat een steekproef deel uitmaakt van een klasse wordt omgezet in een binaire beslissing. Om de AUC te berekenen, worden het werkelijk positieve percentage (TPR) en het fout-positieve percentage (FPR) uitgezet over verschillende drempelinstellingen. De TPR meet het aandeel echte positieven van alle werkelijke positieven, terwijl de FPR het aandeel valse positieven meet van alle werkelijke negatieven. De resulterende curve, de ROC-curve (Receiver Operating Characteristic) genoemd, biedt een visuele weergave van de TPR en FPR bij verschillende drempelinstellingen. De AUC-waarde, die varieert van 0–1, vertegenwoordigt het gebied onder de ROC-curve. Hogere AUC-waarden duiden op betere prestaties, waarbij een perfecte classificator een AUC van 1 behaalt.
De volgende grafiek toont de ROC-curve, met TPR als de Y-as en FPR als de X-as. Hoe dichter de curve bij de linkerbovenhoek van de grafiek komt, hoe beter het model de gegevens in categorieën indeelt.

Laten we ter verduidelijking een voorbeeld bekijken. Laten we eens nadenken over een fraudedetectiemodel. Meestal worden deze modellen getraind op basis van onevenwichtige datasets. Dit is te wijten aan het feit dat doorgaans bijna alle transacties in de dataset niet-frauduleus zijn, waarbij slechts enkele als fraude bestempeld worden. In dit geval is het mogelijk dat de nauwkeurigheid alleen niet voldoende de prestaties van het model weergeeft, omdat het waarschijnlijk sterk wordt beïnvloed door de overvloed aan niet-frauduleuze gevallen, wat leidt tot misleidend hoge nauwkeurigheidsscores.
In dit geval zou de AUC een betere maatstaf zijn om de prestaties van modellen te beoordelen, omdat deze een alomvattende beoordeling biedt van het vermogen van een model om onderscheid te maken tussen frauduleuze en niet-frauduleuze transacties. Het biedt een meer genuanceerde evaluatie, waarbij rekening wordt gehouden met de wisselwerking tussen het werkelijk positieve percentage en het fout-positieve percentage bij verschillende classificatiedrempels.
Net als de F1-score is deze vooral handig als de dataset onevenwichtig is. Het meet de afweging tussen TPR en FPR en laat zien hoe goed het model onderscheid kan maken tussen de twee klassen, ongeacht hun verdeling. Dit betekent dat zelfs als de ene klasse aanzienlijk kleiner is dan de andere, de ROC-curve de prestaties van het model op een evenwichtige manier beoordeelt door beide klassen gelijkwaardig te beschouwen.
Extra belangrijke onderwerpen
Geavanceerde statistieken zijn niet de enige belangrijke hulpmiddelen die voor u beschikbaar zijn voor het evalueren en verbeteren van de prestaties van ML-modellen. Gegevensvoorbereiding, feature-engineering en feature-impactanalyse zijn technieken die essentieel zijn voor het bouwen van modellen. Deze activiteiten spelen een cruciale rol bij het extraheren van betekenisvolle inzichten uit onbewerkte gegevens en het verbeteren van de modelprestaties, wat leidt tot robuustere en inzichtelijkere resultaten.
Gegevensvoorbereiding en feature-engineering
Feature-engineering is het proces van het selecteren, transformeren en creëren van nieuwe variabelen (functies) uit onbewerkte gegevens, en speelt een sleutelrol bij het verbeteren van de prestaties van een ML-model. Het selecteren van de meest relevante variabelen of kenmerken uit de beschikbare gegevens impliceert het verwijderen van irrelevante of overbodige kenmerken die niet bijdragen aan de voorspellende kracht van het model. Het transformeren van gegevensfuncties naar een geschikt formaat omvat schalen, normaliseren en omgaan met ontbrekende waarden. En ten slotte gebeurt het creëren van nieuwe features op basis van de bestaande data door middel van wiskundige transformaties, het combineren of interacteren van verschillende features, of het creëren van nieuwe features op basis van domeinspecifieke kennis.
Analyse van het belang van functies
SageMaker Canvas genereert een functiebelanganalyse waarin de impact wordt uitgelegd die elke kolom in uw dataset op het model heeft. Wanneer u voorspellingen genereert, kunt u de kolomimpact zien, waarmee wordt aangegeven welke kolommen de meeste impact hebben op elke voorspelling. Dit geeft u inzicht in welke functies het verdienen om deel uit te maken van uw uiteindelijke model en welke moeten worden weggegooid. Kolomimpact is een percentagescore die aangeeft hoeveel gewicht een kolom heeft bij het maken van voorspellingen ten opzichte van de andere kolommen. Bij een kolomimpact van 25% weegt Canvas de voorspelling als 25% voor de kolom en 75% voor de overige kolommen.
Benaderingen om de nauwkeurigheid van modellen te verbeteren
Hoewel er meerdere methoden zijn om de nauwkeurigheid van modellen te verbeteren, volgen datawetenschappers en ML-professionals meestal een van de twee benaderingen die in deze sectie worden besproken, waarbij ze gebruik maken van de eerder beschreven tools en statistieken.
Modelgerichte aanpak
Bij deze aanpak blijven de gegevens altijd hetzelfde en worden ze gebruikt om het model iteratief te verbeteren om tot de gewenste resultaten te komen. Hulpmiddelen die bij deze aanpak worden gebruikt, zijn onder meer:
- Meerdere relevante ML-algoritmen proberen
- Afstemming en optimalisatie van algoritmen en hyperparameters
- Verschillende modelensemblemethoden
- Met behulp van vooraf getrainde modellen (SageMaker biedt verschillende ingebouwde of vooraf getrainde modellen om ML-beoefenaars te helpen)
- AutoML, wat SageMaker Canvas achter de schermen doet (met behulp van Amazon SageMaker-stuurautomaat), dat al het bovenstaande omvat
Datacentrische aanpak
Bij deze aanpak ligt de nadruk op datavoorbereiding, het verbeteren van de datakwaliteit en het iteratief aanpassen van de data om de prestaties te verbeteren:
- Statistieken verkennen van de dataset die wordt gebruikt om het model te trainen, ook bekend als verkennende data-analyse (EDA)
- Verbetering van de gegevenskwaliteit (gegevensopschoning, imputatie van ontbrekende waarden, detectie en beheer van uitschieters)
- Functies selecteren
- Functie-engineering
- Gegevensvergroting
Modelprestaties verbeteren met Canvas
We beginnen met de datacentrische benadering. We gebruiken de modelpreview-functionaliteit om een initiële EDA uit te voeren. Dit biedt ons een basislijn die we kunnen gebruiken om data-augmentatie uit te voeren, een nieuwe basislijn te genereren en uiteindelijk het beste model te krijgen met een modelgerichte aanpak met behulp van de standaard bouwfunctionaliteit.
We maken gebruik van de synthetische dataset van een mobiele telefoonmaatschappij. Deze voorbeelddataset bevat 5,000 records, waarbij elke record 21 attributen gebruikt om het klantprofiel te beschrijven. Verwijzen naar Voorspel klantverloop met machine learning zonder code met Amazon SageMaker Canvas voor een volledige beschrijving.
Modelvoorbeeld in een datacentrische benadering
Als eerste stap openen we de dataset, selecteren we de kolom die we willen voorspellen als Churn? en genereren we een voorbeeldmodel door te kiezen Voorbeeldmodel.

De Voorbeeldmodel deelvenster toont de voortgang totdat het voorbeeldmodel gereed is.

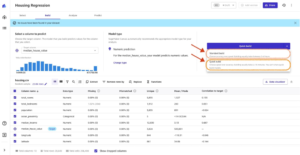
Wanneer het model klaar is, genereert SageMaker Canvas een analyse van het belang van de functies.

Als het voltooid is, toont het deelvenster ten slotte een lijst met kolommen met de impact ervan op het model. Deze zijn handig om te begrijpen hoe relevant de functies zijn voor onze voorspellingen. Kolomimpact is een percentagescore die aangeeft hoeveel gewicht een kolom heeft bij het maken van voorspellingen ten opzichte van de andere kolommen. In het volgende voorbeeld weegt SageMaker Canvas voor de kolom Nachtoproepen de voorspelling als 4.04% voor de kolom en 95.9% voor de andere kolommen. Hoe hoger de waarde, hoe groter de impact.
Zoals we kunnen zien, heeft het preview-model een nauwkeurigheid van 95.6%. Laten we proberen de modelprestaties te verbeteren met behulp van een datacentrische benadering. We voeren gegevensvoorbereiding uit en gebruiken feature-engineeringtechnieken om de prestaties te verbeteren.
Zoals u in de volgende schermafbeelding kunt zien, kunnen we zien dat de kolommen Telefoon en Staat veel minder invloed hebben op onze voorspelling. Daarom zullen we deze informatie gebruiken als input voor onze volgende fase, datavoorbereiding.

SageMaker Canvas biedt ML-gegevenstransformaties waarmee u uw gegevens kunt opschonen, transformeren en voorbereiden voor modelbouw. U kunt deze transformaties zonder enige code op uw datasets gebruiken en ze worden toegevoegd aan het modelrecept, dat een registratie is van de gegevensvoorbereiding die op uw gegevens is uitgevoerd voordat het model wordt gebouwd.
Houd er rekening mee dat alle gegevenstransformaties die u gebruikt alleen de invoergegevens wijzigen bij het bouwen van een model en niet uw gegevensset of originele gegevensbron wijzigen.
De volgende transformaties zijn beschikbaar in SageMaker Canvas zodat u uw gegevens kunt voorbereiden voor het bouwen:
- Datum/tijd-extractie
- Kolommen neerzetten
- Rijen filteren
- Functies en operatoren
- Rijen beheren
- Hernoem kolommen
- Rijen verwijderen
- Waarden vervangen
- Resample tijdreeksgegevens
Laten we beginnen met het schrappen van de kolommen die we hebben gevonden en die weinig impact hebben op onze voorspelling.
In deze dataset is het telefoonnummer bijvoorbeeld slechts het equivalent van een rekeningnummer. Het is nutteloos of zelfs schadelijk bij het voorspellen van de waarschijnlijkheid van klantverloop bij andere accounts. Op dezelfde manier heeft de toestand van de klant niet veel invloed op ons model. Laten we de kolommen Telefoon en Staat verwijderen door die functies eronder uit te schakelen Kolomnaam.

Laten we nu wat extra gegevenstransformatie en feature-engineering uitvoeren.
We merkten bijvoorbeeld in onze eerdere analyse dat het bedrag dat aan klanten in rekening wordt gebracht een directe impact heeft op het klantverloop. Laten we daarom een nieuwe kolom maken die de totale kosten voor onze klanten berekent door Kosten, Minuten en Gesprekken voor Dag, Avond, Nacht en Internationaal te combineren. Hiervoor gebruiken we de aangepaste formules in SageMaker Canvas.

Laten we beginnen met kiezen Functies, dan voegen we aan het formuletekstvak de volgende tekst toe:
(Dagoproepen*Dagkosten*Dagminuten)+(Eva-oproepen*Eva-kosten*Eve-minuten)+(Nachtoproepen*Nachtkosten*Nachtminuten)+(Intl gesprekken*Intl kosten*Intl minuten)
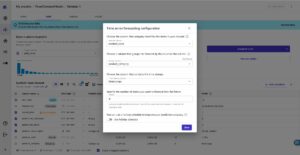
Geef de nieuwe kolom een naam (bijvoorbeeld Totale kosten) en kies Toevoegen nadat het voorbeeld is gegenereerd. Het modelrecept zou er nu uit moeten zien zoals weergegeven in de volgende schermafbeelding.

Wanneer deze gegevensvoorbereiding is voltooid, trainen we een nieuw preview-model om te zien of het model is verbeterd. Kiezen Voorbeeldmodel nogmaals, en het deelvenster rechtsonder toont de voortgang.

Wanneer de training is voltooid, wordt de voorspelde nauwkeurigheid opnieuw berekend en wordt er ook een nieuwe kolomimpactanalyse gemaakt.

En ten slotte, wanneer het hele proces voltooid is, kunnen we hetzelfde venster zien dat we eerder zagen, maar met de nieuwe nauwkeurigheid van het voorbeeldmodel. U kunt merken dat de modelnauwkeurigheid met 0.4% is toegenomen (van 95.6% naar 96%).

De cijfers in de voorgaande afbeeldingen kunnen afwijken van die van u, omdat ML enige stochasticiteit introduceert in het proces van het trainen van modellen, wat kan leiden tot verschillende resultaten in verschillende builds.
Modelgerichte benadering om het model te creëren
Canvas biedt twee opties om uw modellen te bouwen:
- Standaard gebouwd – Bouwt het beste model vanuit een geoptimaliseerd proces waarbij snelheid wordt ingeruild voor betere nauwkeurigheid. Het maakt gebruik van Auto-ML, dat verschillende ML-taken automatiseert, waaronder modelselectie, het uitproberen van verschillende algoritmen die relevant zijn voor uw ML-gebruiksscenario, het afstemmen van hyperparameters en het maken van rapporten over de uitlegbaarheid van modellen.
- Snel gebouwd – Bouwt een eenvoudig model in een fractie van de tijd vergeleken met een standaardmodel, maar nauwkeurigheid wordt ingeruild voor snelheid. Snel model is handig bij iteratie om sneller inzicht te krijgen in de impact van gegevenswijzigingen op de nauwkeurigheid van uw model.
Laten we doorgaan met het gebruik van een standaardbouwaanpak.
Standaard gebouwd
Zoals we eerder zagen, bouwt de standaardconstructie het beste model op vanuit een geoptimaliseerd proces om de nauwkeurigheid te maximaliseren.

Het bouwproces voor ons churnmodel duurt ongeveer 45 minuten. Gedurende deze tijd test Canvas honderden kandidaat-pijplijnen en selecteert het beste model. In de volgende schermafbeelding kunnen we de verwachte bouwtijd en voortgang zien.
Met het standaard bouwproces heeft ons ML-model onze modelnauwkeurigheid verbeterd tot 96.903%, wat een aanzienlijke verbetering is.

Ontdek geavanceerde statistieken
Laten we het model verkennen met behulp van de Geavanceerde statistieken tabblad. Op de Scoren tabblad, kies Geavanceerde statistieken.

Op deze pagina wordt de volgende verwarringsmatrix weergegeven samen met de geavanceerde statistieken: F1-score, nauwkeurigheid, precisie, herinnering, F1-score en AUC.

Voorspellingen genereren
Nu de statistieken er goed uitzien, kunnen we een interactieve voorspelling uitvoeren op de Voorspellen tabblad, hetzij in een batch of in een enkele (real-time) voorspelling.
We hebben twee opties:
- Gebruik dit model om batch- of afzonderlijke voorspellingen uit te voeren
- Stuur het model naar Amazon Sagemaker Studio om te delen met datawetenschappers
Opruimen
Om te voorkomen dat u in de toekomst loopt sessiekosten, log uit bij SageMaker Canvas.

Conclusie
SageMaker Canvas biedt krachtige tools waarmee u modellen kunt bouwen en beoordelen, waardoor de prestaties ervan worden verbeterd zonder dat u codering of gespecialiseerde datawetenschap en ML-expertise nodig hebt. Zoals we in het voorbeeld hebben gezien door het creëren van een klantverloopmodel, kunnen bedrijfsanalisten, door deze tools te combineren met zowel een datacentrische als een modelcentrische benadering met behulp van geavanceerde statistieken, voorspellingsmodellen creëren en evalueren. Met een visuele interface kunt u ook zelf nauwkeurige ML-voorspellingen genereren. We raden u aan de referenties door te nemen en te zien hoeveel van deze concepten van toepassing kunnen zijn op andere soorten ML-problemen.
Referenties
Over de auteurs
 Marcos is een AWS Sr. Machine Learning Solutions Architect gevestigd in Florida, VS. In die rol is hij verantwoordelijk voor het begeleiden en assisteren van Amerikaanse startup-organisaties bij hun strategie richting de cloud, waarbij hij advies geeft over hoe risicovolle problemen kunnen worden aangepakt en hun machine learning-workloads kunnen worden geoptimaliseerd. Hij heeft meer dan 25 jaar ervaring met technologie, waaronder de ontwikkeling van cloudoplossingen, machine learning, softwareontwikkeling en datacenterinfrastructuur.
Marcos is een AWS Sr. Machine Learning Solutions Architect gevestigd in Florida, VS. In die rol is hij verantwoordelijk voor het begeleiden en assisteren van Amerikaanse startup-organisaties bij hun strategie richting de cloud, waarbij hij advies geeft over hoe risicovolle problemen kunnen worden aangepakt en hun machine learning-workloads kunnen worden geoptimaliseerd. Hij heeft meer dan 25 jaar ervaring met technologie, waaronder de ontwikkeling van cloudoplossingen, machine learning, softwareontwikkeling en datacenterinfrastructuur.
 Indrajit is een AWS Enterprise Sr. Solutions Architect. In zijn rol helpt hij klanten hun bedrijfsresultaten te bereiken door middel van cloudadoptie. Hij ontwerpt moderne applicatie-architecturen op basis van microservices, serverless, API's en gebeurtenisgestuurde patronen. Hij werkt samen met klanten om hun data-analyse en machine learning-doelen te realiseren door de adoptie van DataOps- en MLOps-praktijken en -oplossingen. Indrajit spreekt regelmatig op openbare AWS-evenementen zoals topconferenties en ASEAN-workshops, heeft verschillende AWS-blogposts gepubliceerd en klantgerichte technische workshops ontwikkeld gericht op data en machine learning op AWS.
Indrajit is een AWS Enterprise Sr. Solutions Architect. In zijn rol helpt hij klanten hun bedrijfsresultaten te bereiken door middel van cloudadoptie. Hij ontwerpt moderne applicatie-architecturen op basis van microservices, serverless, API's en gebeurtenisgestuurde patronen. Hij werkt samen met klanten om hun data-analyse en machine learning-doelen te realiseren door de adoptie van DataOps- en MLOps-praktijken en -oplossingen. Indrajit spreekt regelmatig op openbare AWS-evenementen zoals topconferenties en ASEAN-workshops, heeft verschillende AWS-blogposts gepubliceerd en klantgerichte technische workshops ontwikkeld gericht op data en machine learning op AWS.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/is-your-model-good-a-deep-dive-into-amazon-sagemaker-canvas-advanced-metrics/
- : heeft
- :is
- :niet
- :waar
- 000
- 1
- 100
- 1239
- 25
- 420
- a
- vermogen
- Over
- overvloed
- toegang
- Account
- nauwkeurigheid
- accuraat
- nauwkeurig
- Bereiken
- bereikt
- het bereiken van
- over
- activiteiten
- daadwerkelijk
- werkelijk
- toevoegen
- toegevoegd
- Extra
- adres
- voldoende
- Adoptie
- vergevorderd
- Na
- weer
- tegen
- algoritmen
- Alles
- toestaat
- alleen
- al
- ook
- altijd
- Amazone
- Amazon Sage Maker
- Amazon SageMaker-canvas
- Amazon Web Services
- bedragen
- an
- analyse
- analist
- analisten
- analytics
- en
- elke
- APIs
- Aanvraag
- toepassingen
- Solliciteer
- nadering
- benaderingen
- ZIJN
- GEBIED
- rond
- geregeld
- AS
- Asean
- schatten
- beoordeling
- bijstaan
- At
- attributen
- automaten
- Beschikbaar
- vermijd
- AWS
- As
- slecht
- saldi
- gebaseerde
- Baseline
- De Basis
- BE
- omdat
- geweest
- vaardigheden
- beginnen
- achter
- Achter de schermen
- wezen
- BEST
- Betere
- tussen
- Blog
- Blog Posts
- zowel
- bouw
- Gebouw
- bouwt
- bedrijfsdeskundigen
- maar
- by
- berekenen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- oproepen
- CAN
- kandidaat
- canvas
- vangen
- verzorging
- geval
- gevallen
- categorieën
- Centreren
- Wijzigingen
- karakteristiek
- lading
- opgeladen
- lasten
- Kies
- het kiezen van
- klasse
- klassen
- classificatie
- classificeren
- Schoonmaak
- dichterbij
- Cloud
- cloud adoptie
- code
- codering
- Kolom
- columns
- combines
- combineren
- hoe
- algemeen
- vergelijken
- vergeleken
- compleet
- compleet
- uitgebreid
- concepten
- voorwaarde
- verwarring
- Gevolgen
- aangezien
- beschouwt
- bevatte
- bevat
- voortzetten
- bijdragen
- het omzetten van
- Hoek
- te corrigeren
- Kosten
- kostbaar
- deksel
- en je merk te creëren
- aangemaakt
- Wij creëren
- het aanmaken
- cruciaal
- curve
- gewoonte
- klant
- Klant gedrag
- Klanten
- gegevens
- gegevensanalyse
- gegevens Analytics
- Data Center
- Data voorbereiding
- data kwaliteit
- data science
- data scientist
- datasets
- dag
- transactie
- beslissing
- beslissingen
- deep
- diepe duik
- gedefinieerd
- beschrijven
- beschreven
- beschrijving
- verdienen
- ontwerpen
- gewenste
- Opsporing
- ontwikkelde
- Ontwikkeling
- diagnose
- verschillen
- anders
- onderscheiden
- directe
- bespreken
- besproken
- Ziekte
- onderscheiden
- verdeeld
- distributie
- Verdeeld
- do
- doet
- Nee
- gedaan
- dropping
- drug
- twee
- gedurende
- elk
- Vroeger
- beide
- gemachtigd
- in staat stellen
- ingeschakeld
- maakt
- omvat
- aanmoedigen
- Engineering
- verbeteren
- Enterprise
- even
- Gelijkwaardig
- vooral
- essentieel
- Ether (ETH)
- schatten
- evalueren
- evaluatie
- vooravond
- Zelfs
- gelijkmatig
- EVENTS
- Alle
- voorbeeld
- uitgewisseld
- bestaand
- verwacht
- ervaring
- expertise
- deskundigen
- Verklaren
- Uitlegbaarheid
- Verklaart
- Verkennende gegevensanalyse
- Verken
- f1
- vergemakkelijken
- feit
- vals
- Kenmerk
- Voordelen
- weinig
- finale
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- Florida
- Focus
- gericht
- volgen
- volgend
- Voor
- formaat
- formule
- gevonden
- fractie
- bedrog
- fraude detectie
- frauduleus
- oppompen van
- vol
- functionaliteit
- toekomst
- met het verkrijgen van
- Algemeen
- voortbrengen
- gegenereerde
- genereert
- het genereren van
- het krijgen van
- Geven
- Go
- Doelen
- goed
- Ground
- leiding
- Behandeling
- Hebben
- he
- hard
- hulp
- helpt
- Hoge
- hoog risico
- hoger
- zijn
- historisch
- Hoe
- How To
- Echter
- HTML
- HTTPS
- Honderden
- Hyperparameter afstemmen
- idee
- identificeert
- identificeren
- het identificeren van
- if
- beeld
- afbeeldingen
- Impact
- uitvoeren
- belang
- belangrijk
- verbeteren
- verbeterd
- verbetering
- het verbeteren van
- in
- Anders
- omvatten
- omvat
- Inclusief
- onjuist
- meer
- aangeven
- geeft aan
- wat aangeeft
- beïnvloed
- informatie
- leerzaam
- Infrastructuur
- eerste
- invoer
- inzichtelijke
- inzichten
- instantie
- interactie
- interactieve
- Interface
- in
- Introduceert
- Introductie
- problemen
- IT
- HAAR
- jpg
- voor slechts
- sleutel
- blijven
- kennis
- bekend
- label
- labels
- leiden
- leidend
- leren
- Verlof
- links
- minder
- als
- waarschijnlijkheid
- Lijn
- Lijst
- Elke kleine stap levert grote resultaten op!
- inloggen
- Kijk
- uit
- Laag
- te verlagen
- machine
- machine learning
- Meerderheid
- maken
- maken
- beheerd
- management
- manier
- veel
- wiskundig
- Matrix
- Maximaliseren
- Mei..
- gemiddelde
- zinvolle
- middel
- maatregel
- maatregelen
- mechanismen
- medisch
- Maak kennis met
- methoden
- metriek
- Metriek
- microservices
- macht
- minuten
- misleidend
- vermist
- ML
- MLops
- Mobile
- mobiele telefoon
- model
- modellen
- Modern
- wijzigen
- meer
- meest
- veel
- meervoudig
- naam
- Noodzaak
- nodig
- negatief
- negatieven
- New
- Nieuwe mogelijkheden
- volgende
- nacht
- Merk op..
- nu
- aantal
- nummers
- waarnemen
- verkrijgen
- of
- Aanbod
- on
- EEN
- degenen
- Slechts
- open
- werkzaam
- Optimaliseer
- geoptimaliseerde
- Opties
- or
- organisaties
- origineel
- Overige
- Overig
- onze
- uit
- Resultaat
- resultaten
- over
- het te bezitten.
- pagina
- brood
- deel
- vooral
- patronen
- percentage
- uitvoeren
- prestatie
- uitgevoerd
- fase
- phone
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- speelt
- plus
- vormt
- positief
- mogelijk
- Post
- Berichten
- energie
- krachtige
- praktijken
- precisie
- voorspellen
- voorspeld
- het voorspellen van
- voorspelling
- Voorspellingen
- voorspelt
- voorbereiding
- Voorbereiden
- aanwezigheid
- Voorbeschouwing
- vorig
- waarschijnlijkheid
- waarschijnlijk
- probleem
- problemen
- Profiel
- winst
- Voortgang
- proportie
- zorgen voor
- biedt
- het verstrekken van
- publiek
- gepubliceerde
- inkomsten
- kwaliteit
- Quick
- snel
- tarief
- Rauw
- ruwe data
- klaar
- real-time
- realiseren
- redenen
- recept
- record
- archief
- referenties
- verwezen
- reflecteren
- weerspiegelt
- achteloos
- regelmatig
- relatie
- relatief
- relevante
- stoffelijk overschot
- verwijderen
- het verwijderen van
- Rapporten
- vertegenwoordiging
- vertegenwoordigt
- verantwoordelijk
- verkregen
- Resultaten
- inkomsten
- Omzetgroei
- rechts
- Risico
- robuust
- Rol
- lopen
- sagemaker
- dezelfde
- Voorbeeldgegevensset
- zagen
- scaling
- Scenes
- Wetenschap
- Wetenschapper
- wetenschappers
- partituur
- scores
- sectie
- zien
- gezien
- ziet
- selecteren
- selectie
- sentiment
- -Series
- Serverless
- service
- Diensten
- reeks
- het instellen van
- settings
- verscheidene
- Delen
- moet
- tonen
- getoond
- Shows
- aanzienlijke
- aanzienlijk
- evenzo
- Eenvoudig
- eenvoudigweg
- single
- kleinere
- So
- Software
- software development
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- iets
- bron
- spreekt
- gespecialiseerde
- specifiek
- snelheid
- spleet
- standaard
- begin
- startup
- Land
- statistiek
- Stap voor
- Strategie
- dergelijk
- geschikt
- Toppen
- neemt
- het nemen
- taken
- Technisch
- technieken
- Technologie
- telecommunicatie
- vertellen
- proef
- testen
- neem contact
- dat
- De
- De omgeving
- The Basics
- hun
- Ze
- harte
- Er.
- daarom
- Deze
- ze
- spullen
- denken
- dit
- die
- drempel
- Door
- niet de tijd of
- Tijdreeksen
- naar
- tools
- top
- Totaal
- in de richting van
- tp
- TPR
- Trainen
- getraind
- Trainingen
- Transacties
- Transformeren
- Transformatie
- transformaties
- transformeren
- transformaties
- waar
- waarheid
- proberen
- twee
- types
- voor
- begrijpen
- begrip
- tot
- us
- .
- use case
- gebruikt
- toepassingen
- gebruik
- doorgaans
- waardevol
- waarde
- Values
- divers
- zeer
- was
- we
- web
- webservices
- weegt
- gewicht
- GOED
- waren
- Wat
- wanneer
- welke
- en
- geheel
- Waarom
- wil
- Met
- zonder
- Bedrijven
- Workshops
- zou
- het schrijven van
- Verkeerd
- X
- jaar
- u
- Your
- zephyrnet