Organisaties over de hele wereld – zowel profit als non-profit – kijken naar het gebruik van data-analyse om de bedrijfsprestaties te verbeteren. Bevindingen uit een McKinsey-enquête geven aan dat datagestuurde organisaties 23 keer meer kans hebben om klanten te werven, zes keer zoveel kans om klanten te behouden en 19 keer meer winstgevend te zijn [1]. Onderzoek door MIT ontdekte dat digitaal volwassen bedrijven 26% winstgevender zijn dan hun sectorgenoten [2]. Maar veel bedrijven hebben, ondanks dat ze rijk zijn aan data, moeite met het implementeren van data-analyse vanwege de tegenstrijdige prioriteiten tussen bedrijfsbehoeften, beschikbare mogelijkheden en middelen. Onderzoek door Gartner ontdekte dat meer dan 85% van de data- en analyseprojecten mislukken [3] en gezamenlijk verslag van IBM en Carnegie Melon laat zien dat 90% van de data in een organisatie nooit succesvol wordt gebruikt voor welk strategisch doel dan ook [4].
Tegen deze achtergrond introduceren we het concept ‘data analytics fabric (DAF)’, als een ecosysteem of een structuur die data-analyse in staat stelt effectief te functioneren op basis van (a) zakelijke behoeften of doelstellingen, (b) beschikbare capaciteiten zoals mensen/vaardigheden , processen, cultuur, technologieën, inzichten, besluitvormingscompetenties en meer, en (c) middelen (dat wil zeggen componenten die een bedrijf nodig heeft om het bedrijf te runnen).
Ons primaire doel van het introduceren van het data-analyseweefsel is het beantwoorden van deze fundamentele vraag: “Wat is er nodig om effectief een beslissingsbevorderend systeem te bouwen op basis van data Science algoritmen om bedrijfsprestaties te meten en te verbeteren?” Het data-analyseweefsel en de vijf belangrijkste manifestaties ervan worden hieronder getoond en besproken.
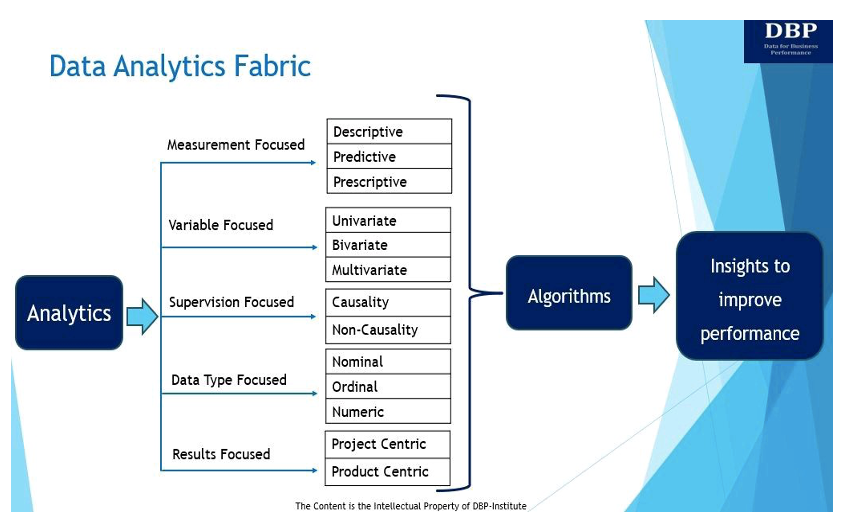
1. Meetgericht
In de kern gaat analytics over het gebruik van data om inzichten te verkrijgen, de bedrijfsprestaties te meten en te verbeteren [5]. Er zijn drie hoofdtypen analyses om de bedrijfsprestaties te meten en te verbeteren:
- Beschrijvende analyses stelt de vraag: “Wat is er gebeurd?” Beschrijvende analyses worden gebruikt om historische gegevens te analyseren om patronen, trends en relaties te identificeren met behulp van verkennende, associatieve en inferentiële gegevensanalysetechnieken. Verkennende data-analysetechnieken analyseren en vatten datasets samen. Associatieve beschrijvende analyse verklaart de relatie tussen variabelen. Inferentiële beschrijvende data-analyse wordt gebruikt om trends over een grotere populatie af te leiden of te concluderen op basis van de steekproefdataset.
- Voorspellende analyse kijkt naar het beantwoorden van de vraag: “Wat zal er gebeuren?” Kortom, voorspellende analyses zijn het proces waarbij gegevens worden gebruikt om toekomstige trends en gebeurtenissen te voorspellen. Voorspellende analyses kunnen handmatig worden uitgevoerd (algemeen bekend als door analisten aangestuurde voorspellende analyses) of met behulp van algoritmen voor machine learning (ook bekend als datagestuurde voorspellende analyses). Hoe dan ook, de historische gegevens worden gebruikt om toekomstige voorspellingen te doen.
- Prescriptieve analyses helpt bij het beantwoorden van de vraag: “Hoe kunnen we dit laten gebeuren?” Kortom, prescriptieve analyses bevelen de beste handelwijze aan om verder te komen met behulp van optimalisatie- en simulatietechnieken. Doorgaans gaan voorspellende analyse en prescriptieve analyse samen omdat voorspellende analyse helpt bij het vinden van potentiële uitkomsten, terwijl prescriptieve analyse naar die uitkomsten kijkt en meer opties vindt.
2. Variabel gericht
Gegevens kunnen ook worden geanalyseerd op basis van het aantal beschikbare variabelen. In dit opzicht kunnen de data-analysetechnieken, op basis van het aantal variabelen, univariate, bivariate of multivariate zijn.
- Univariate analyse: Univariate analyse omvat het analyseren van het patroon dat aanwezig is in een enkele variabele, met behulp van metingen van centraliteit (gemiddelde, mediaan, modus, enzovoort) en variatie (standaarddeviatie, standaardfout, variantie, enzovoort).
- Bivariate analyse: Er zijn twee variabelen waarbij de analyse verband houdt met de oorzaak en de relatie tussen de twee variabelen. Deze twee variabelen kunnen afhankelijk of onafhankelijk van elkaar zijn. De correlatietechniek is de meest gebruikte bivariate analysetechniek.
- Multivariate analyse: Deze techniek wordt gebruikt voor het analyseren van meer dan twee variabelen. In een multivariate omgeving opereren we doorgaans in de arena van voorspellende analyses en de meeste bekende machine learning (ML)-algoritmen, zoals lineaire regressie, logistische regressie, regressiebomen, ondersteunende vectormachines en neurale netwerken, worden doorgaans toegepast op een multivariate omgeving. instelling.
3. Toezichtgericht
Het derde type data-analysestructuur houdt zich bezig met het trainen van de invoergegevens of onafhankelijke variabele gegevens die zijn gelabeld voor een bepaalde output (dwz de afhankelijke variabele). Kortom, de onafhankelijke variabele is degene die de onderzoeker controleert. De afhankelijke variabele is de variabele die verandert als reactie op de onafhankelijke variabele. De op toezicht gerichte DAF zou uit twee typen kunnen bestaan.
- causaliteit: Gelabelde gegevens, zowel automatisch als handmatig gegenereerd, zijn essentieel voor begeleid leren. Met gelabelde gegevens kan men een afhankelijke variabele duidelijk definiëren, en dan is het een kwestie van het voorspellende analyse-algoritme om een AI/ML-tool te bouwen die een relatie zou opbouwen tussen het label (afhankelijke variabele) en de reeks onafhankelijke variabelen. Omdat we een duidelijke afbakening hebben tussen het idee van een afhankelijke variabele en een reeks onafhankelijke variabelen, staan we onszelf toe de term ‘causaliteit’ te introduceren om de relatie het beste uit te leggen.
- Niet-causaliteit: Wanneer we ‘supervisiegericht’ als onze dimensie aangeven, bedoelen we ook de ‘afwezigheid van toezicht’, en dat brengt de niet-causale modellen ter discussie. De niet-causale modellen verdienen vermelding omdat ze geen gelabelde gegevens vereisen. De basistechniek hier is clustering, en de meest populaire methoden zijn k-Means en Hiërarchische Clustering.
4. Gegevenstypegericht
Deze dimensie of manifestatie van het data-analyseweefsel richt zich op de drie verschillende soorten datavariabelen die verband houden met zowel de onafhankelijke als de afhankelijke variabelen die worden gebruikt in de data-analysetechnieken voor het afleiden van inzichten.
- Nominale gegevens wordt gebruikt voor het labelen of categoriseren van gegevens. Er is geen numerieke waarde bij betrokken en daarom zijn er geen statistische berekeningen mogelijk met nominale gegevens. Voorbeelden van nominale gegevens zijn geslacht, productbeschrijving, klantadres en dergelijke.
- Ordinale of gerangschikte gegevens is de volgorde van de waarden, maar de verschillen tussen de waarden zijn niet echt bekend. Veel voorkomende voorbeelden hiervan zijn het rangschikken van bedrijven op basis van marktkapitalisatie, betalingsvoorwaarden van leveranciers, klanttevredenheidsscores, leveringsprioriteit, enzovoort.
- Numerieke gegevens behoeft geen introductie en is numeriek van waarde. Deze variabelen zijn de meest fundamentele gegevenstypen die kunnen worden gebruikt om alle soorten algoritmen te modelleren.
5. Resultaatgericht
Dit type data-analysestructuur kijkt naar de manieren waarop bedrijfswaarde kan worden geleverd uit de inzichten die uit analyses voortkomen. Er zijn twee manieren waarop bedrijfswaarde kan worden aangestuurd door analytics, en dat is via producten of projecten. Hoewel producten mogelijk extra gevolgen moeten hebben op het gebied van gebruikerservaring en software-engineering, zal de modelleringsoefening voor het afleiden van het model vergelijkbaar zijn in zowel het project als het product.
- A data-analyseproduct is een herbruikbare data-asset om aan de langetermijnbehoeften van het bedrijf te voldoen. Het verzamelt data uit relevante databronnen, waarborgt de datakwaliteit, verwerkt deze en maakt deze toegankelijk voor iedereen die deze nodig heeft. Producten zijn doorgaans ontworpen voor persona's en hebben meerdere levenscyclusfasen of iteraties waarin productwaarde wordt gerealiseerd.
- A data-analyseproject is ontworpen om tegemoet te komen aan een specifieke of unieke zakelijke behoefte en heeft een gedefinieerde of beperkte gebruikersbasis of doel. Kortom, een project is een tijdelijke onderneming die bedoeld is om de oplossing binnen een bepaalde reikwijdte, binnen het budget en op tijd op te leveren.
De wereldeconomie zal de komende jaren dramatisch transformeren, omdat organisaties steeds meer data en analyses zullen gebruiken om inzichten te verkrijgen en beslissingen te nemen om de bedrijfsprestaties te meten en te verbeteren. McKinsey ontdekte dat bedrijven die inzichtgestuurd zijn, een stijging van de EBITDA (winst vóór rente, belastingen, afschrijvingen en amortisatie) tot wel 25% rapporteren [5]. Veel organisaties zijn echter niet succesvol in het inzetten van data en analyses om de bedrijfsresultaten te verbeteren. Maar er bestaat niet één standaardmanier of -aanpak om data-analyses te leveren. De inzet of implementatie van oplossingen voor data-analyse is afhankelijk van bedrijfsdoelstellingen, mogelijkheden en middelen. De DAF en de vijf hier besproken verschijningsvormen kunnen ervoor zorgen dat analyses effectief kunnen worden ingezet op basis van zakelijke behoeften, beschikbare mogelijkheden en middelen.
Referenties
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-than-hun-peers/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-zegt-bijna-de helft-van-de-cio's-van plan-om-kunstmatige-intelligentie in te zetten
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, “Analytics Best Practices”, Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- : heeft
- :is
- :niet
- $UP
- 1
- 19
- 23
- a
- Over
- beschikbaar
- verwerven
- Actie
- Extra
- adres
- AI / ML
- algoritme
- algoritmen
- Alles
- toelaten
- toestaat
- ook
- amortisatie
- an
- analyse
- analytics
- analyseren
- geanalyseerd
- het analyseren van
- en
- beantwoorden
- elke
- iedereen
- toegepast
- nadering
- ZIJN
- arena
- rond
- AS
- aanwinst
- At
- webmaster.
- Beschikbaar
- b
- achtergrond
- baseren
- gebaseerde
- basis-
- Eigenlijk
- BE
- omdat
- geweest
- vaardigheden
- wezen
- onder
- BEST
- tussen
- zowel
- Brengt
- begroting
- bouw
- bedrijfsdeskundigen
- zakelijke prestaties
- maar
- by
- CAN
- mogelijkheden
- kapitalisatie
- categoriseren
- Veroorzaken
- Centrality
- Wijzigingen
- duidelijk
- clustering
- verzamelt
- COM
- komst
- Gemeen
- algemeen
- Bedrijven
- componenten
- concept
- concludeert
- uitgevoerd
- Tegenstrijdig
- controles
- Kern
- Correlatie
- kon
- cursus
- Culture
- klant
- Klanttevredenheid
- Klanten
- gegevens
- gegevensanalyse
- gegevens Analytics
- data kwaliteit
- gegevensset
- gegevenssets
- Gegevensgestuurde
- DATAVERSITEIT
- Deals
- Besluitvorming
- beslissingen
- bepalen
- gedefinieerd
- leveren
- geleverd
- levering
- afhankelijk
- afhankelijk
- ingezet
- inzet
- waardevermindering
- Afgeleid
- beschrijving
- verdienen
- ontworpen
- Niettegenstaande
- afwijking
- verschillen
- anders
- digitaal
- Afmeting
- besproken
- discussie
- onderscheiden
- do
- doet
- gedaan
- dramatisch
- gedreven
- twee
- e
- elk
- Verdiensten
- EBITDA
- economie
- ecosysteem
- effectief
- beide
- in staat stellen
- maakt
- toekomst
- Engineering
- waarborgt
- fout
- essentieel
- EVENTS
- voorbeelden
- Oefening
- ervaring
- Verklaren
- Verklaart
- Verkennende gegevensanalyse
- stof
- feit
- FAIL
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- bevindingen
- vondsten
- bedrijven
- vijf
- richt
- Voor
- Forbes
- Voorspelling
- Naar voren
- gevonden
- oppompen van
- functie
- fundamenteel
- toekomst
- Gartner
- Geslacht
- gegenereerde
- Go
- doel
- gebeuren
- gebeurd
- Hebben
- helpt
- Vandaar
- hier
- historisch
- Echter
- HTTPS
- i
- IBM
- identificeren
- uitvoeren
- uitvoering
- verbeteren
- verbeterd
- het verbeteren van
- in
- Verhoogt
- in toenemende mate
- onafhankelijk
- aangeven
- invoer
- inzichten
- bestemde
- belang
- voorstellen
- de invoering
- Introductie
- betrekken
- gaat
- IT
- iteraties
- HAAR
- sleutel
- bekend
- label
- etikettering
- groter
- leren
- leveraging
- levenscyclus van uw product
- als
- Waarschijnlijk
- langdurig
- op zoek
- LOOKS
- machine
- machine learning
- Machines
- Hoofd
- maken
- MERKEN
- handmatig
- veel
- Markt
- Marktkapitalisatie
- Materie
- volwassen
- max-width
- Mei..
- McKinsey
- gemiddelde
- maatregel
- maatregelen
- noemen
- methoden
- MIT
- ML
- Mode
- model
- modellering
- modellen
- meer
- meest
- Meest populair
- bewegend
- meervoudig
- Noodzaak
- behoeften
- netwerken
- Neural
- neurale netwerken
- nooit
- geen
- Non-profit
- notie
- aantal
- doelstellingen
- of
- on
- EEN
- besturen
- optimalisatie
- Opties
- or
- bestellen
- organisatie
- organisaties
- Overige
- onze
- onszelf
- resultaten
- uitgang
- over
- bijzonder
- Patronen
- patronen
- betaling
- prestatie
- Plato
- Plato gegevensintelligentie
- PlatoData
- Populair
- bevolking
- mogelijk
- potentieel
- Voorspellingen
- voorspellend
- Voorspellende analyse
- Predictive Analytics
- presenteren
- primair
- prioriteit
- processen
- Product
- Producten
- Profit
- winstgevend
- project
- projecten
- doel
- kwaliteit
- vraag
- gevolgen
- gerangschikt
- Ranking
- realiseerde
- werkelijk
- beveelt
- Beschouwen
- regressie
- verwant
- verwantschap
- Relaties
- relevante
- verslag
- vereisen
- nodig
- Resources
- antwoord
- behouden
- herbruikbare
- tevredenheid
- omvang
- scores
- dienen
- reeks
- Sets
- het instellen van
- getoond
- Shows
- gelijk
- simulatie
- single
- ZES
- So
- Software
- software engineering
- oplossing
- Oplossingen
- bron
- bronnen
- stadia
- standaard
- statistisch
- strategisch
- structuur
- geslaagd
- Met goed gevolg
- dergelijk
- samenvatten
- leren onder toezicht
- toezicht
- ondersteuning
- system
- Belastingen
- technieken
- Technologies
- tijdelijk
- termijn
- termen
- neem contact
- dat
- De
- de wereld
- hun
- harte
- Er.
- Deze
- ze
- Derde
- dit
- die
- drie
- Door
- niet de tijd of
- keer
- naar
- samen
- tools
- Trainingen
- Transformeren
- Bomen
- Trends
- twee
- type dan:
- types
- typisch
- unieke
- .
- gebruikt
- Gebruiker
- Gebruikerservaring
- gebruik
- waarde
- Values
- variabele
- verkoper
- Manier..
- manieren
- we
- bekend
- wanneer
- of
- welke
- en
- WIE
- wil
- Met
- binnen
- wereld
- s werelds
- zou
- jaar
- zephyrnet











