In het huidige informatietijdperk vormen de enorme hoeveelheden gegevens in talloze documenten zowel een uitdaging als een kans voor bedrijven. Traditionele documentverwerkingsmethoden schieten vaak tekort wat betreft efficiëntie en nauwkeurigheid, waardoor er ruimte overblijft voor innovatie, kostenefficiëntie en optimalisaties. Documentverwerking heeft aanzienlijke vooruitgang geboekt met de komst van Intelligent Document Processing (IDP). Met IDP kunnen bedrijven ongestructureerde gegevens uit verschillende documenttypen omzetten in gestructureerde, bruikbare inzichten, waardoor de efficiëntie aanzienlijk wordt verbeterd en handmatige inspanningen worden verminderd. Het potentieel houdt hier echter niet op. Door generatieve kunstmatige intelligentie (AI) in het proces te integreren, kunnen we de mogelijkheden van ontheemden verder verbeteren. Generatieve AI introduceert niet alleen verbeterde mogelijkheden bij documentverwerking, maar introduceert ook een dynamisch aanpassingsvermogen aan veranderende gegevenspatronen. Dit bericht neemt je mee door de synergie van IDP en generatieve AI en onthult hoe ze de volgende grens in documentverwerking vertegenwoordigen.
We bespreken IDP in detail in onze serie Intelligente documentverwerking met AWS AI-services (Deel 1 en Deel 2). In dit bericht bespreken we hoe u een nieuwe of bestaande IDP-architectuur kunt uitbreiden met grote taalmodellen (LLM's). Meer specifiek bespreken we hoe we kunnen integreren Amazon T-extract Met LangChain als documentlader en Amazonebodem om gegevens uit documenten te extraheren en generatieve AI-mogelijkheden te gebruiken binnen de verschillende ontheemdingsfasen.
Amazon Textract is een machine learning (ML)-service die automatisch tekst, handschrift en gegevens uit gescande documenten extraheert. Amazon Bedrock is een volledig beheerde service die een keuze biedt uit goed presterende funderingsmodellen (FM's) via eenvoudig te gebruiken API's.
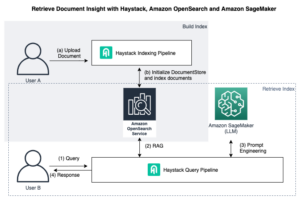
Het volgende diagram is een referentiearchitectuur op hoog niveau waarin wordt uitgelegd hoe u een IDP-workflow verder kunt verbeteren met basismodellen. U kunt LLM's gebruiken in één of alle fasen van IDP, afhankelijk van de use case en het gewenste resultaat.
In de volgende secties duiken we diep in hoe Amazon Textract is geïntegreerd in generatieve AI-workflows met behulp van LangChain om documenten voor elk van deze specifieke taken te verwerken. De hier verstrekte codeblokken zijn kortheidshalve ingekort. Raadpleeg onze GitHub-repository voor gedetailleerde Python-notebooks en een stapsgewijze uitleg.
Tekstextractie uit documenten is een cruciaal aspect als het gaat om het verwerken van documenten met LLM's. U kunt Amazon Textract gebruiken om ongestructureerde onbewerkte tekst uit documenten te extraheren en de originele semi-gestructureerde of gestructureerde objecten zoals sleutel-waardeparen en tabellen in het document te behouden. Documentpakketten zoals zorg- en verzekeringsclaims of hypotheken bestaan uit complexe formulieren die veel informatie bevatten in gestructureerde, semi-gestructureerde en ongestructureerde formaten. Documentextractie is hier een belangrijke stap omdat LLM's profiteren van de rijke inhoud om nauwkeurigere en relevantere antwoorden te genereren, die anders de kwaliteit van de output van de LLM's zouden kunnen beïnvloeden.
LangChain is een krachtig open-sourceframework voor integratie met LLM's. LLM's zijn over het algemeen veelzijdig, maar kunnen moeite hebben met domeinspecifieke taken waarbij een diepere context en genuanceerde antwoorden nodig zijn. LangChain stelt ontwikkelaars in dergelijke scenario's in staat agenten te bouwen die complexe taken in kleinere subtaken kunnen opsplitsen. De subtaken kunnen vervolgens context en geheugen in LLM's introduceren door LLM-prompts met elkaar te verbinden en aan elkaar te koppelen.
LangChain-aanbiedingen documentladers waarmee gegevens uit documenten kunnen worden geladen en getransformeerd. U kunt ze gebruiken om documenten te structureren in voorkeursformaten die door LLM's kunnen worden verwerkt. De AmazonTextractPDFLoader is een documentlader van het type serviceloader die een snelle manier biedt om documentverwerking te automatiseren door Amazon Textract te gebruiken in combinatie met LangChain. Voor meer details over AmazonTextractPDFLoader, verwijs naar de LangChain documentatie. Om de Amazon Textract-documentlader te gebruiken, begint u met het importeren vanuit de LangChain-bibliotheek:
from langchain.document_loaders import AmazonTextractPDFLoaderhttps_loader = AmazonTextractPDFLoader("https://sample-website.com/sample-doc.pdf")
https_document = https_loader.load() s3_loader = AmazonTextractPDFLoader("s3://sample-bucket/sample-doc.pdf")
s3_document = s3_loader.load()Je kunt ook documenten opslaan in Amazon S3 en ernaar verwijzen met behulp van het s3:// URL-patroon, zoals uitgelegd in Toegang krijgen tot een bucket met S3://en geef dit S3-pad door aan de Amazon Textract PDF-lader:
import boto3
textract_client = boto3.client('textract', region_name='us-east-2') file_path = "s3://amazon-textract-public-content/langchain/layout-parser-paper.pdf"
loader = AmazonTextractPDFLoader(file_path, client=textract_client)
documents = loader.load()Een document met meerdere pagina's bevat meerdere pagina's met tekst, die vervolgens toegankelijk zijn via het documentobject, dat een lijst met pagina's is. De volgende code loopt door de pagina's in het documentobject en drukt de documenttekst af, die beschikbaar is via het page_content attribuut:
print(len(documents)) for document in documents: print(document.page_content)Amazon Comprehend en LLM's kunnen effectief worden gebruikt voor documentclassificatie. Amazon Comprehend is een dienst voor natuurlijke taalverwerking (NLP) die ML gebruikt om inzichten uit tekst te halen. Amazon Comprehend ondersteunt ook aangepaste classificatiemodeltraining met lay-outbewustzijn voor documenten zoals PDF's, Word en afbeeldingsformaten. Voor meer informatie over het gebruik van de Amazon Comprehend-documentclassificator raadpleegt u Amazon Comprehend-documentclassificatie voegt lay-outondersteuning toe voor hogere nauwkeurigheid.
In combinatie met LLM's wordt documentclassificatie een krachtige aanpak voor het beheren van grote hoeveelheden documenten. LLM's zijn nuttig bij de classificatie van documenten omdat ze de tekst, patronen en contextuele elementen in het document kunnen analyseren met behulp van natuurlijk taalbegrip. U kunt ze ook verfijnen voor specifieke documentklassen. Wanneer een nieuw documenttype dat in de IDP-pijplijn is geïntroduceerd, classificatie nodig heeft, kan de LLM tekst verwerken en het document categoriseren op basis van een reeks klassen. Het volgende is een voorbeeldcode die de LangChain-documentlader, mogelijk gemaakt door Amazon Textract, gebruikt om de tekst uit het document te extraheren en deze te gebruiken voor het classificeren van het document. Wij gebruiken de Antropische Claude v2 model via Amazon Bedrock om de classificatie uit te voeren.
In het volgende voorbeeld extraheren we eerst tekst uit een ontslagrapport van een patiënt en gebruiken we een LLM om deze te classificeren op basis van een lijst met drie verschillende documenttypen:DISCHARGE_SUMMARY, RECEIPT en PRESCRIPTION. De volgende schermafbeelding toont ons rapport.
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.llms import Bedrock
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain loader = AmazonTextractPDFLoader("./samples/document.png")
document = loader.load() template = """ Given a list of classes, classify the document into one of these classes. Skip any preamble text and just give the class name. <classes>DISCHARGE_SUMMARY, RECEIPT, PRESCRIPTION</classes>
<document>{doc_text}<document>
<classification>""" prompt = PromptTemplate(template=template, input_variables=["doc_text"])
bedrock_llm = Bedrock(client=bedrock, model_id="anthropic.claude-v2") llm_chain = LLMChain(prompt=prompt, llm=bedrock_llm)
class_name = llm_chain.run(document[0].page_content) print(f"The provided document is = {class_name}")
Samenvatten houdt in dat een bepaalde tekst of document wordt gecomprimeerd tot een kortere versie, terwijl de belangrijkste informatie behouden blijft. Deze techniek is nuttig voor het efficiënt ophalen van informatie, waardoor gebruikers snel de belangrijkste punten van een document kunnen begrijpen zonder de volledige inhoud te lezen. Hoewel Amazon Textract niet rechtstreeks tekstsamenvattingen uitvoert, biedt het de fundamentele mogelijkheden om de volledige tekst uit documenten te extraheren. Deze geëxtraheerde tekst dient als invoer voor ons LLM-model voor het uitvoeren van tekstsamenvattingstaken.
Met behulp van hetzelfde monsterontladingsrapport gebruiken we AmazonTextractPDFLoader om tekst uit dit document te extraheren. Net als voorheen gebruiken we het Claude v2-model via Amazon Bedrock en initialiseren we het met een prompt die de instructies bevat over wat we met de tekst moeten doen (in dit geval een samenvatting). Ten slotte voeren we de LLM-keten uit door de geëxtraheerde tekst uit de documentlader door te geven. Hierdoor wordt een gevolgtrekkingsactie uitgevoerd op de LLM met de prompt die bestaat uit de instructies om samen te vatten, en de tekst van het document gemarkeerd met Document. Zie de volgende code:
De code genereert de samenvatting van een samenvattend rapport over ontslag van een patiënt:
In het voorgaande voorbeeld werd een document van één pagina gebruikt om samenvattingen uit te voeren. U zult echter waarschijnlijk te maken krijgen met documenten die meerdere pagina's bevatten die moeten worden samengevat. Een gebruikelijke manier om samenvattingen op meerdere pagina's uit te voeren, is door eerst samenvattingen van kleinere stukken tekst te genereren en vervolgens de kleinere samenvattingen te combineren om een definitieve samenvatting van het document te krijgen. Houd er rekening mee dat deze methode meerdere aanroepen naar de LLM vereist. De logica hiervoor kan eenvoudig worden bedacht; LangChain biedt echter een ingebouwde samenvattingsketen die grote teksten (van documenten met meerdere pagina's) kan samenvatten. De samenvatting kan gebeuren via map_reduce of stuff opties, die beschikbaar zijn als opties om de meerdere oproepen naar de LLM te beheren. In het volgende voorbeeld gebruiken we map_reduce om een document met meerdere pagina's samen te vatten. De volgende afbeelding illustreert onze workflow.
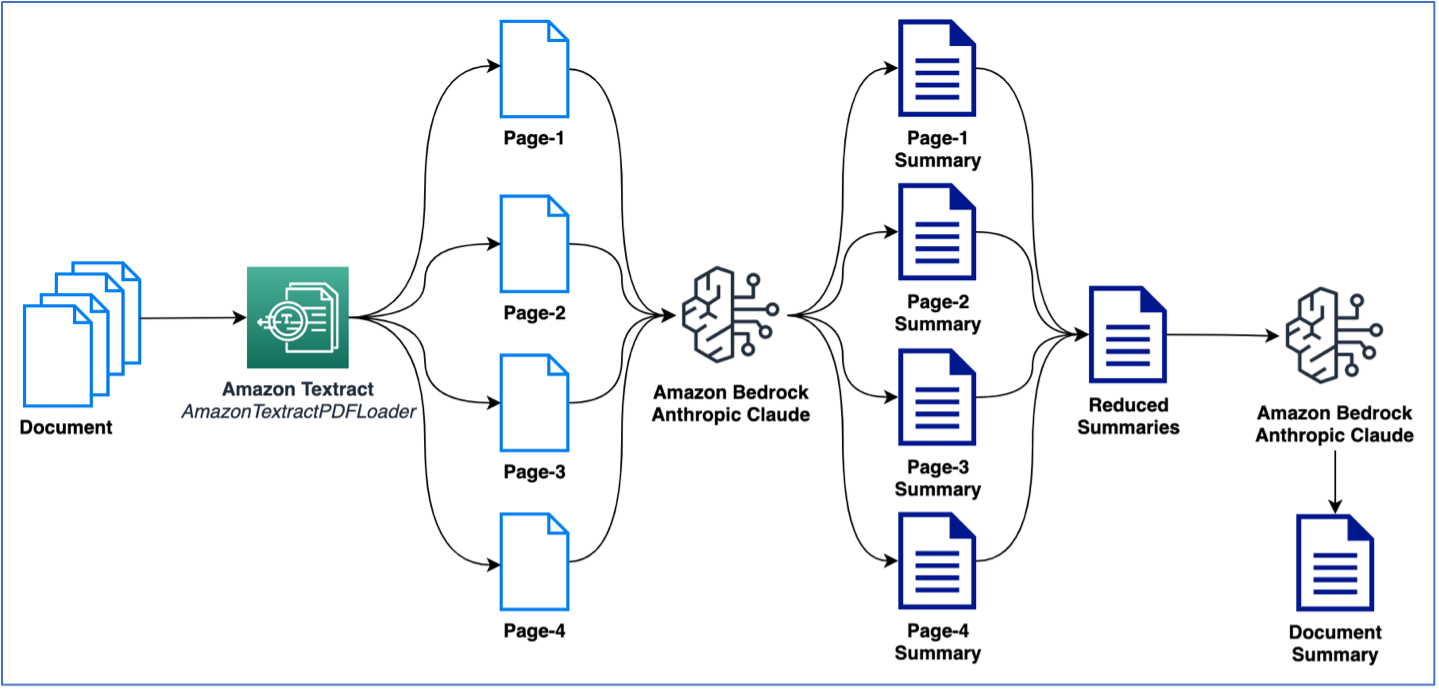
Laten we eerst beginnen met het extraheren van het document en het totale aantal tokens per pagina en het totale aantal pagina's bekijken:
Vervolgens gebruiken we de ingebouwde LangChain load_summarize_chain om het hele document samen te vatten:
from langchain.chains.summarize import load_summarize_chain summary_chain = load_summarize_chain(llm=bedrock_llm, chain_type='map_reduce')
output = summary_chain.run(document)
print(output.strip())Standaardisatie en vragen en antwoorden
In deze sectie bespreken we standaardisatie- en vraag- en antwoordtaken.
normalisering
Uitvoerstandaardisatie is een tekstgeneratietaak waarbij LLM's worden gebruikt om een consistente opmaak van de uitvoertekst te bieden. Deze taak is met name handig voor de automatisering van de extractie van sleutelentiteiten, waarbij de uitvoer moet worden afgestemd op de gewenste indelingen. We kunnen bijvoorbeeld de best practices van snelle engineering volgen om een LLM te verfijnen om datums op te maken in de notatie MM/DD/JJJJ, wat compatibel kan zijn met een database DATE-kolom. Het volgende codeblok toont een voorbeeld van hoe dit wordt gedaan met behulp van een LLM en prompt engineering. We standaardiseren niet alleen het uitvoerformaat voor de datumwaarden, we vragen het model ook om de uiteindelijke uitvoer in een JSON-formaat te genereren, zodat deze gemakkelijk kan worden gebruikt in onze downstream-applicaties. We gebruiken LangChain-expressietaal (LCEL) om twee acties aan elkaar te koppelen. De eerste actie vraagt de LLM om een uitvoer in JSON-indeling te genereren van alleen de datums uit het document. De tweede actie neemt de JSON-uitvoer en standaardiseert het datumformaat. Merk op dat deze tweestapsactie ook in één stap kan worden uitgevoerd met de juiste snelle engineering, zoals we zullen zien bij normalisatie en sjablonen.
De uitvoer van het voorgaande codevoorbeeld is een JSON-structuur met de datums 07/09/2020 en 08/09/2020, die de indeling DD/MM/JJJJ hebben en respectievelijk de opname- en ontslagdatum van de patiënt uit het ziekenhuis zijn. naar het samenvattend ontslagverslag.
Vraag en antwoord met Retrieval Augmented Generation
Het is bekend dat LLM's feitelijke informatie bewaren, vaak hun wereldkennis of wereldbeeld genoemd. Wanneer ze worden verfijnd, kunnen ze state-of-the-art resultaten opleveren. Er zijn echter beperkingen aan hoe effectief een LLM toegang kan krijgen tot deze kennis en deze kan manipuleren. Als gevolg hiervan zijn de prestaties van taken die sterk afhankelijk zijn van specifieke kennis mogelijk niet optimaal voor bepaalde gebruiksscenario's. In vraag- en antwoordscenario's is het bijvoorbeeld essentieel dat het model zich strikt houdt aan de context die in het document wordt gegeven, zonder uitsluitend te vertrouwen op zijn wereldkennis. Als u hiervan afwijkt, kan dit leiden tot verkeerde voorstellingen, onnauwkeurigheden of zelfs onjuiste antwoorden. De meest gebruikte methode om dit probleem aan te pakken staat bekend als Ophalen Augmented Generation (VOD). Deze aanpak combineert de sterke punten van zowel ophaalmodellen als taalmodellen, waardoor de nauwkeurigheid en kwaliteit van de gegenereerde antwoorden worden verbeterd.
LLM's kunnen ook tokenbeperkingen opleggen vanwege hun geheugenbeperkingen en de beperkingen van de hardware waarop ze draaien. Om dit probleem aan te pakken, worden technieken zoals chunking gebruikt om grote documenten in kleinere delen te verdelen die binnen de tokenlimieten van LLM's passen. Aan de andere kant worden inbeddingen in NLP voornamelijk gebruikt om de semantische betekenis van woorden en hun relaties met andere woorden in een hoogdimensionale ruimte vast te leggen. Deze inbedding transformeert woorden in vectoren, waardoor modellen tekstuele gegevens efficiënt kunnen verwerken en begrijpen. Door de semantische nuances tussen woorden en zinsdelen te begrijpen, kunnen LLM's met inbedding coherente en contextueel relevante resultaten genereren. Let op de volgende sleutelbegrippen:
- gerammel – Dit proces splitst grote hoeveelheden tekst uit documenten op in kleinere, betekenisvolle stukjes tekst.
- inbeddingen – Dit zijn vast-dimensionale vectortransformaties van elk deel dat de semantische informatie uit de delen behoudt. Deze insluitingen worden vervolgens in een vectordatabase geladen.
- Vector-database – Dit is een database met woordinbedding of vectoren die de context van woorden vertegenwoordigen. Het fungeert als een kennisbron die NLP-taken ondersteunt bij documentverwerkingspijplijnen. Het voordeel van de vectordatabase is dat tijdens het genereren van tekst alleen de noodzakelijke context aan de LLM's kan worden verstrekt, zoals we in de volgende sectie uitleggen.
RAG gebruikt de kracht van insluitingen om relevante documentsegmenten te begrijpen en op te halen tijdens de ophaalfase. Door dit te doen kan RAG werken binnen de tokenbeperkingen van LLM's, waardoor wordt gegarandeerd dat de meest relevante informatie wordt geselecteerd voor generatie, wat resulteert in nauwkeurigere en contextueel relevante resultaten.
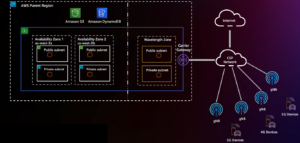
Het volgende diagram illustreert de integratie van deze technieken om de input voor LLM's te creëren, hun contextueel begrip te vergroten en relevantere in-contextreacties mogelijk te maken. Eén benadering omvat het zoeken naar overeenkomsten, waarbij gebruik wordt gemaakt van zowel een vectordatabase als chunking. De vectordatabase slaat insluitingen op die semantische informatie vertegenwoordigen, en chunking verdeelt tekst in beheersbare secties. Met behulp van deze context uit het zoeken naar overeenkomsten kunnen LLM's taken uitvoeren zoals het beantwoorden van vragen en domeinspecifieke bewerkingen zoals classificatie en verrijking.

Voor dit bericht gebruiken we een op RAG gebaseerde aanpak om in-context Q&A met documenten uit te voeren. In het volgende codevoorbeeld extraheren we tekst uit een document en splitsen het document vervolgens in kleinere stukjes tekst. Chunking is vereist omdat we mogelijk grote documenten van meerdere pagina's hebben en onze LLM's mogelijk tokenlimieten hebben. Deze chunks worden vervolgens in de vectordatabase geladen voor het uitvoeren van overeenkomstenonderzoek in de volgende stappen. In het volgende voorbeeld gebruiken we het Amazon Titan Embed Text v1-model, dat de vectorinsluitingen van de documentfragmenten uitvoert:
De code creëert een relevante context voor de LLM met behulp van de stukjes tekst die worden geretourneerd door de zoekactie naar overeenkomsten uit de vectordatabase. Voor dit voorbeeld gebruiken we een open source FAISS vectorwinkel als een voorbeeldvectordatabase om vectorinsluitingen van elk stuk tekst op te slaan. Vervolgens definiëren we de vectordatabase als a LangChain-retriever, die wordt doorgegeven aan de RetrievalQA ketting. Hiermee wordt intern een overeenkomstzoekopdracht uitgevoerd in de vectordatabase, die de bovenste n (waarbij n=3 in ons voorbeeld) stukken tekst retourneert die relevant zijn voor de vraag. Ten slotte wordt de LLM-keten uitgevoerd met de relevante context (een groep relevante stukjes tekst) en de vraag die de LLM moet beantwoorden. Voor een stapsgewijze code-uitleg van Q&A met RAG raadpleegt u het Python-notebook op GitHub.
Als alternatief voor FAISS kunt u ook gebruiken Amazon OpenSearch Service vectordatabasemogelijkheden, Amazon Relational Database Service (Amazon RDS) voor PostgreSQL met de vector extensie als vectordatabases of open-source Chroma Database.
Vraag en antwoord met gegevens in tabelvorm
Tabelgegevens in documenten kunnen voor LLM's een uitdaging zijn om te verwerken vanwege de structurele complexiteit ervan. Amazon Textract kan worden uitgebreid met LLM's omdat het het mogelijk maakt tabellen uit documenten te extraheren in een genest formaat van elementen zoals pagina, tabel en cellen. Het uitvoeren van vragen en antwoorden met gegevens in tabelvorm is een proces dat uit meerdere stappen bestaat en kan worden bereikt via zelf opvragen. Hieronder volgt een overzicht van de stappen:
- Extraheer tabellen uit documenten met Amazon Textract. Met Amazon Textract kan de tabelstructuur (rijen, kolommen, kopteksten) uit een document worden geëxtraheerd.
- Sla de tabelgegevens op in een vectordatabase, samen met metagegevens, zoals de headernamen en de beschrijving van elke header.
- Gebruik de prompt om een gestructureerde query samen te stellen, met behulp van een LLM, om de gegevens uit de tabel af te leiden.
- Gebruik de query om de relevante tabelgegevens uit de vectordatabase te extraheren.
Op een bankafschrift zou de LLM bijvoorbeeld, gegeven de vraag 'Wat zijn de transacties met meer dan $ 1000 aan stortingen', de volgende stappen uitvoeren:
- Maak een query, zoals
“Query: transactions” , “filter: greater than (Deposit$)”. - Converteer de query naar een gestructureerde query.
- Pas de gestructureerde query toe op de vectordatabase waarin onze tabelgegevens zijn opgeslagen.
Voor een stapsgewijze voorbeeldcode-walkthrough van Q&A met tabel raadpleegt u het Python-notebook in GitHub.
Sjablonen en normalisaties
In deze sectie bekijken we hoe u prompt-engineeringtechnieken en het ingebouwde mechanisme van LangChain kunt gebruiken om uitvoer te genereren met extracties uit een document in een gespecificeerd schema. We voeren ook enige standaardisatie uit op de geëxtraheerde gegevens, met behulp van de eerder besproken technieken. We beginnen met het definiëren van een sjabloon voor onze gewenste uitvoer. Dit zal als schema dienen en de details samenvatten over elke entiteit die we uit de tekst van het document willen halen.
Merk op dat we voor elk van de entiteiten de beschrijving gebruiken om uit te leggen wat die entiteit is om de LLM te helpen bij het extraheren van de waarde uit de tekst van het document. In de volgende voorbeeldcode gebruiken we deze sjabloon om onze prompt voor de LLM samen te stellen met de tekst die uit het document is geëxtraheerd met behulp van AmazonTextractPDFLoader en voer vervolgens gevolgtrekkingen uit met het model:
Zoals u kunt zien, de {keys} een deel van de prompt zijn de sleutels van onze sjabloon, en de {details} zijn de sleutels samen met hun beschrijving. In dit geval vragen we het model niet expliciet om de indeling van de uitvoer, behalve dat we in de instructie opgeven om de uitvoer in JSON-indeling te genereren. Dit werkt voor het grootste deel; Omdat de uitvoer van LLM's echter niet-deterministische tekstgeneratie is, willen we het formaat expliciet specificeren als onderdeel van de instructie in de prompt. Om dit op te lossen kunnen we LangChain's gebruiken gestructureerde uitvoerparser module om te profiteren van de geautomatiseerde prompt-engineering die helpt bij het converteren van onze sjabloon naar een formaatinstructieprompt. We gebruiken de eerder gedefinieerde sjabloon om de formaatinstructieprompt als volgt te genereren:
Vervolgens gebruiken we deze variabele binnen onze oorspronkelijke prompt als een instructie voor de LLM, zodat deze de uitvoer in het gewenste schema extraheert en formatteert door een kleine wijziging aan onze prompt aan te brengen:
Tot nu toe hebben we de gegevens alleen in een gewenst schema uit het document gehaald. We moeten echter nog steeds enige standaardisatie uitvoeren. We willen bijvoorbeeld dat de opnamedatum en de ontslagdatum van de patiënt worden geëxtraheerd in de notatie DD/MM/JJJJ. In dit geval vergroten we de description van de sleutel met de formatteringsinstructie:
Raadpleeg het Python-notebook in GitHub voor een volledige stapsgewijze uitleg en uitleg.
Spellingcontroles en correcties
LLM's hebben opmerkelijke vaardigheden getoond in het begrijpen en genereren van mensachtige tekst. Een van de minder besproken maar enorm nuttige toepassingen van LLM's is hun potentieel bij grammaticale controles en zinscorrectie in documenten. In tegenstelling tot traditionele grammaticacontroles die vertrouwen op een reeks vooraf gedefinieerde regels, gebruiken LLM's patronen die ze hebben geïdentificeerd uit grote hoeveelheden tekstgegevens om te bepalen wat correcte of vloeiende taal is. Dit betekent dat ze nuances, context en subtiliteiten kunnen detecteren die op regels gebaseerde systemen mogelijk over het hoofd zien.
Stel je de tekst voor die uit een samenvatting van het ontslag van een patiënt is gehaald en luidt: 'Patiënt Jon Doe, die werd opgenomen met een ernstige longontsteking, heeft aanzienlijke verbetering laten zien en kan veilig worden ontslagen. Volgende week staan er vervolgonderzoeken gepland.” Een traditionele spellingcontrole kan 'admittd', 'longontsteking', 'verbetering' en 'nex' als fouten herkennen. De context van deze fouten kan echter leiden tot verdere fouten of algemene suggesties. Een LLM, uitgerust met een uitgebreide training, zou kunnen suggereren: “Patiënt John Doe, die werd opgenomen met een ernstige longontsteking, heeft aanzienlijke verbetering laten zien en kan veilig worden ontslagen. Volgende week staan de vervolgonderzoeken gepland.”
Het volgende is een slecht handgeschreven voorbeelddocument met dezelfde tekst als eerder uitgelegd.

We extraheren het document met een Amazon Textract-documentlader en instrueren vervolgens de LLM, via prompt engineering, om de geëxtraheerde tekst te corrigeren om eventuele spel- en/of grammaticafouten te corrigeren:
De uitvoer van de voorgaande code toont de originele tekst die is geëxtraheerd door de documentlader, gevolgd door de gecorrigeerde tekst die is gegenereerd door de LLM:
Houd er rekening mee dat, hoe krachtig LLM's ook zijn, het van essentieel belang is om hun suggesties als precies dat te zien: suggesties. Hoewel ze de fijne kneepjes van de taal indrukwekkend goed weergeven, zijn ze niet onfeilbaar. Sommige suggesties kunnen de bedoelde betekenis of toon van de originele tekst veranderen. Daarom is het van cruciaal belang dat menselijke beoordelaars door LLM gegenereerde correcties als leidraad gebruiken en niet als absoluut gegeven. De samenwerking van menselijke intuïtie met LLM-mogelijkheden belooft een toekomst waarin onze schriftelijke communicatie niet alleen foutloos is, maar ook rijker en genuanceerder.
Conclusie
Generatieve AI verandert de manier waarop u documenten met IDP kunt verwerken om inzichten te verkrijgen. Bij de post Verbetering van de intelligente documentverwerking van AWS met generatieve AIbespraken we de verschillende fasen van de pijplijn en hoe AWS-klant Ricoh zijn IDP-pijplijn uitbreidt met LLM's. In dit bericht hebben we verschillende mechanismen besproken om de IDP-workflow met LLM's uit te breiden via Amazon Bedrock, Amazon Textract en het populaire LangChain-framework. U kunt vandaag nog aan de slag met de nieuwe Amazon Textract-documentlader met LangChain met behulp van de voorbeeldnotitieboekjes die beschikbaar zijn in onze GitHub-repository. Voor meer informatie over het werken met generatieve AI op AWS, zie Aankondiging van nieuwe tools voor bouwen met generatieve AI op AWS.
Over de auteurs
 Sonali Sahu leidt intelligente documentverwerking met het AI/ML-serviceteam in AWS. Ze is auteur, opinieleider en gepassioneerd technoloog. Haar belangrijkste aandachtsgebied is AI en ML, en ze spreekt regelmatig op AI- en ML-conferenties en -bijeenkomsten over de hele wereld. Ze heeft zowel brede als diepgaande ervaring in technologie en de technologie-industrie, met branche-expertise in de gezondheidszorg, de financiële sector en verzekeringen.
Sonali Sahu leidt intelligente documentverwerking met het AI/ML-serviceteam in AWS. Ze is auteur, opinieleider en gepassioneerd technoloog. Haar belangrijkste aandachtsgebied is AI en ML, en ze spreekt regelmatig op AI- en ML-conferenties en -bijeenkomsten over de hele wereld. Ze heeft zowel brede als diepgaande ervaring in technologie en de technologie-industrie, met branche-expertise in de gezondheidszorg, de financiële sector en verzekeringen.
 Anjan Biswas is een Senior AI Services Solutions Architect met een focus op AI/ML en Data Analytics. Anjan maakt deel uit van het wereldwijde AI-serviceteam en werkt samen met klanten om hen te helpen bij het begrijpen en ontwikkelen van oplossingen voor zakelijke problemen met AI en ML. Anjan heeft meer dan 14 jaar ervaring in het werken met wereldwijde supply chain-, productie- en retailorganisaties en helpt klanten actief om aan de slag te gaan en op te schalen met AWS AI-services.
Anjan Biswas is een Senior AI Services Solutions Architect met een focus op AI/ML en Data Analytics. Anjan maakt deel uit van het wereldwijde AI-serviceteam en werkt samen met klanten om hen te helpen bij het begrijpen en ontwikkelen van oplossingen voor zakelijke problemen met AI en ML. Anjan heeft meer dan 14 jaar ervaring in het werken met wereldwijde supply chain-, productie- en retailorganisaties en helpt klanten actief om aan de slag te gaan en op te schalen met AWS AI-services.
 Chinmayee Rane is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Ze heeft een passie voor toegepaste wiskunde en machine learning. Ze richt zich op het ontwerpen van intelligente documentverwerking en generatieve AI-oplossingen voor AWS-klanten. Buiten haar werk houdt ze van salsa- en bachatadansen.
Chinmayee Rane is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Ze heeft een passie voor toegepaste wiskunde en machine learning. Ze richt zich op het ontwerpen van intelligente documentverwerking en generatieve AI-oplossingen voor AWS-klanten. Buiten haar werk houdt ze van salsa- en bachatadansen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/intelligent-document-processing-with-amazon-textract-amazon-bedrock-and-langchain/
- : heeft
- :is
- :niet
- :waar
- .volgende
- $1000
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 15%
- 16
- 22
- 23
- 33
- 35%
- 7
- 9
- a
- capaciteiten
- Over
- absoluut
- toegang
- geraadpleegde
- Volgens
- nauwkeurigheid
- accuraat
- bereikt
- over
- Actie
- acties
- actief
- activiteit
- Handelingen
- Ad
- adres
- Voegt
- aanhangen
- toegeven
- toegegeven
- vooruitgang
- Voordeel
- komst
- leeftijd
- agenten
- AI
- AI-diensten
- AI / ML
- uitgelijnd
- Alles
- Het toestaan
- toestaat
- langs
- ook
- alternatief
- Hoewel
- Amazone
- Amazon begrijpt het
- Amazon RDS
- Amazon T-extract
- Amazon Web Services
- hoeveelheden
- an
- analytics
- analyseren
- en
- beantwoorden
- antropisch
- antibiotica
- elke
- APIs
- toepassingen
- toegepast
- benoemingen
- nadering
- architectuur
- ZIJN
- GEBIED
- rond
- Kunst
- kunstmatig
- kunstmatige intelligentie
- Kunstmatige intelligentie (AI)
- AS
- verschijning
- helpen
- Assistent
- At
- vergroten
- aangevuld
- auteur
- automatiseren
- geautomatiseerde
- webmaster.
- Automatisering
- Beschikbaar
- bewustzijn
- AWS
- AWS-klant
- Bank
- BE
- omdat
- wordt
- geweest
- vaardigheden
- heilzaam
- voordeel
- BEST
- 'best practices'
- tussen
- Blok
- Blokken
- zowel
- breedte
- Breken
- breaks
- bouw
- Gebouw
- ingebouwd
- bedrijfsdeskundigen
- ondernemingen
- maar
- by
- oproepen
- CAN
- Kan krijgen
- mogelijkheden
- vangen
- geval
- gevallen
- Cellen
- zeker
- keten
- ketens
- uitdagen
- uitdagend
- verandering
- Wijzigingen
- veranderende
- Controles
- keuze
- vorderingen
- klasse
- klassen
- classificatie
- classificeren
- code
- SAMENHANGEND
- samenwerking
- Kolom
- columns
- combinatie van
- combineren
- komt
- Gemeen
- algemeen
- Communicatie
- verenigbaar
- compleet
- complex
- ingewikkeldheid
- begrijpen
- beknopt
- conferenties
- Wij verbinden
- consequent
- bestaat uit
- beperkingen
- bouwen
- bevatten
- bevatte
- bevat
- content
- verband
- contextual
- converteren
- Kern
- te corrigeren
- gecorrigeerd
- Correcties
- kon
- ambachtelijke
- bewerkte
- creëert
- cruciaal
- gewoonte
- klant
- Klanten
- Dansen
- gegevens
- gegevens Analytics
- Database
- databanken
- Datum
- Data
- transactie
- deep
- diepere
- bepalen
- gedefinieerd
- het definiëren van
- gedemonstreerd
- Afhankelijk
- deposito's
- diepte
- beschreven
- beschrijving
- ontwerpen
- gewenste
- detail
- gedetailleerd
- gegevens
- opsporen
- Bepalen
- ontwikkelen
- ontwikkelaars
- Dieet
- anders
- direct
- bespreken
- besproken
- duiken
- verdelen
- verdeelt
- do
- dokter
- document
- documentatie
- documenten
- DOE
- Nee
- doen
- don
- gedaan
- Dont
- beneden
- dramatisch
- twee
- gedurende
- dynamisch
- e
- elk
- Vroeger
- gemakkelijk
- gemakkelijk te gebruiken
- effectief
- doeltreffendheid
- doeltreffend
- efficiënt
- inspanningen
- beide
- geeft je de mogelijkheid
- insluiten
- loondienst
- machtigt
- in staat stellen
- maakt
- waardoor
- einde
- Engineering
- verhogen
- verbeterde
- verbeteren
- verzekeren
- zorgen
- Geheel
- entiteiten
- entiteit
- uitgerust
- fouten
- essentieel
- Ether (ETH)
- Zelfs
- voorbeeld
- Behalve
- uitzondering
- bestaand
- ervaring
- expertise
- Verklaren
- uitgelegd
- Verklaart
- uitleg
- uitdrukkelijk
- uitdrukking
- verlengen
- uitbreiding
- uitgebreid
- extract
- extractie
- extracten
- Feitelijk
- Vallen
- vals
- ver
- 피로
- Velden
- Figuur
- finale
- Tot slot
- financieel
- Financiële sector
- Voornaam*
- geschikt
- Focus
- richt
- volgen
- gevolgd
- volgend
- volgt
- Voor
- formaat
- formulieren
- gevonden
- Foundation
- Achtergrond
- Gratis
- vaak
- oppompen van
- Grens
- vol
- geheel
- verder
- toekomst
- Algemeen
- voortbrengen
- gegenereerde
- genereert
- het genereren van
- generatie
- generatief
- generatieve AI
- krijgen
- Geven
- gegeven
- Globaal
- Grammatica
- grijpen
- meer
- Groep
- gids
- hand
- handvat
- gebeuren
- Happening
- Hardware
- Hebben
- headers
- gezondheidszorg
- hard
- hulp
- nuttig
- het helpen van
- helpt
- haar
- hier
- high-level
- goed presterende
- hoger
- houdt
- Ziekenhuis
- Hoe
- How To
- Echter
- HTML
- HTTPS
- menselijk
- i
- ID
- geïdentificeerd
- if
- illustreert
- beeld
- onmetelijk
- Impact
- importeren
- belangrijk
- importeren
- opgelegde
- verbetering
- in
- Inclusief
- index
- -industrie
- informatie
- Informatie leeftijd
- Innovatie
- invoer
- inzichten
- instantie
- instructies
- verzekering
- integreren
- geïntegreerde
- Integreren
- integratie
- Intelligentie
- Intelligent
- Intelligente documentverwerking
- bestemde
- inwendig
- in
- fijne kneepjes
- voorstellen
- geïntroduceerd
- Introduceert
- intuïtie
- gaat
- IT
- HAAR
- Jackson
- John
- JOHN DOE
- jon
- jpg
- json
- voor slechts
- sleutel
- toetsen
- blijven
- kennis
- bekend
- taal
- Groot
- Layout
- leiden
- leider
- leidend
- leren
- verlaten
- Bibliotheek
- als
- Waarschijnlijk
- beperkingen
- grenzen
- Lijst
- laden
- lader
- logica
- Kijk
- lot
- machine
- machine learning
- maken
- beheer
- beheerd
- beheren
- handboek
- productie
- gemarkeerd
- wiskunde
- Mei..
- me
- betekenis
- zinvolle
- middel
- mechanisme
- mechanismen
- Meetups
- Geheugen
- meta
- Metadata
- methode
- methoden
- macht
- denken
- missen
- fouten
- ML
- model
- modellen
- module
- meer
- Hypotheken
- meest
- meervoudig
- naam
- namen
- Naturel
- Natuurlijke taal
- Natural Language Processing
- Natuurlijk taalbegrip
- noodzakelijk
- Noodzaak
- nodig
- behoeften
- New
- volgende
- volgende week
- nlp
- nota
- notitieboekje
- laptops
- nu
- shading
- aantal
- object
- objecten
- of
- Aanbod
- vaak
- on
- EEN
- Slechts
- open source
- Operations
- kansen
- optimale
- Opties
- or
- organisaties
- origineel
- Overige
- anders-
- onze
- uit
- Resultaat
- uitgang
- uitgangen
- buiten
- over
- overzicht
- Paketten
- pagina
- paginas
- Pijn
- gepaarde
- paren
- deel
- vooral
- passeren
- voorbij
- Voorbijgaand
- hartstochtelijk
- pad
- patiënt
- Patronen
- patronen
- voor
- uitvoeren
- prestatie
- uitgevoerd
- uitvoerend
- presteert
- fase
- phd
- zinnen
- pijpleiding
- plan
- Plato
- Plato gegevensintelligentie
- PlatoData
- dan
- longontsteking
- punten
- Populair
- mogelijk
- Post
- potentieel
- energie
- aangedreven
- krachtige
- praktijken
- Precies
- precisie
- bij voorkeur
- presenteren
- die eerder
- in de eerste plaats
- prints
- probleem
- problemen
- verwerkt
- verwerking
- produceren
- Beloften
- gepast
- zorgen voor
- mits
- leverancier
- biedt
- Python
- Q & A
- kwaliteit
- vraag
- Quick
- snel
- Rauw
- lezing
- herkennen
- vermindering
- verwijzen
- referentie
- verwezen
- Relaties
- relevante
- vertrouwen
- te vertrouwen
- opmerkelijk
- verslag
- vertegenwoordigen
- vertegenwoordigen
- nodig
- vereist
- respectievelijk
- reacties
- beperkingen
- resultaat
- verkregen
- Resultaten
- <HR>Retail
- behouden
- behoudende
- Retourneren
- Rijk
- Kamer
- reglement
- lopen
- loopt
- s
- veilig
- dezelfde
- ervaren
- Scale
- scenario's
- gepland
- Ontdek
- Tweede
- sectie
- secties
- sector
- zien
- segmenten
- gekozen
- senior
- zin
- -Series
- dienen
- bedient
- service
- Diensten
- reeks
- streng
- ze
- Bermuda's
- moet
- getoond
- Shows
- aanzienlijke
- single
- Klein
- kleinere
- snipper
- So
- uitsluitend
- Oplossingen
- OPLOSSEN
- sommige
- bron
- Tussenruimte
- spreekt
- specialist
- specifiek
- specifiek
- gespecificeerd
- spelling
- spleet
- stadia
- normalisering
- begin
- gestart
- state-of-the-art
- Statement
- Stap voor
- Stappen
- Still
- shop
- opgeslagen
- winkels
- sterke punten
- Draad
- structureel
- structuur
- gestructureerde
- volgend
- Hierop volgend
- dergelijk
- stel
- samenvatten
- OVERZICHT
- leveren
- toeleveringsketen
- ondersteuning
- steunen
- synergie
- Systems
- T
- tafel
- Nemen
- neemt
- Taak
- taken
- team
- techniek
- technieken
- technoloog
- Technologie
- sjabloon
- termen
- tekst
- tekst generatie
- tekstueel
- neem contact
- dat
- De
- de wereld
- hun
- Ze
- harte
- Er.
- daarom
- Deze
- ze
- dit
- gedachte
- drie
- Door
- Titan
- naar
- vandaag
- vandaag
- samen
- teken
- tokens
- TONE
- tools
- top
- Totaal
- traditioneel
- Trainingen
- Transacties
- Transformeren
- transformaties
- waar
- proberen
- twee
- type dan:
- types
- begrijpen
- begrip
- anders
- onthulling
- URL
- .
- use case
- gebruikt
- gebruikers
- toepassingen
- gebruik
- gebruikt
- Gebruik makend
- v1
- waarde
- Values
- variabele
- divers
- groot
- veelzijdig
- versie
- via
- Bekijk
- volumes
- walkthrough
- willen
- was
- Manier..
- we
- web
- webservices
- week
- GOED
- Wat
- wanneer
- welke
- en
- WIE
- wil
- Met
- binnen
- zonder
- getuige
- Woord
- woorden
- Mijn werk
- workflow
- workflows
- werkzaam
- Bedrijven
- wereld
- zou
- geschreven
- X
- jaar
- u
- zephyrnet