Amazon OpenSearch-service onlangs geïntroduceerd Multi-AZ met stand-by, een implementatieoptie die is ontworpen om bedrijven te voorzien van verbeterde beschikbaarheid en consistente prestaties voor kritieke werklasten. Met deze functie kunnen beheerde clusters een beschikbaarheid van 99.99% bereiken, terwijl ze veerkrachtig blijven tegen zonale infrastructuurstoringen.
In dit bericht onderzoeken we hoe zoeken en indexeren werkt met Multi-AZ met Standby en duiken we in de onderliggende mechanismen die bijdragen aan de betrouwbaarheid, eenvoud en fouttolerantie ervan.
Achtergrond
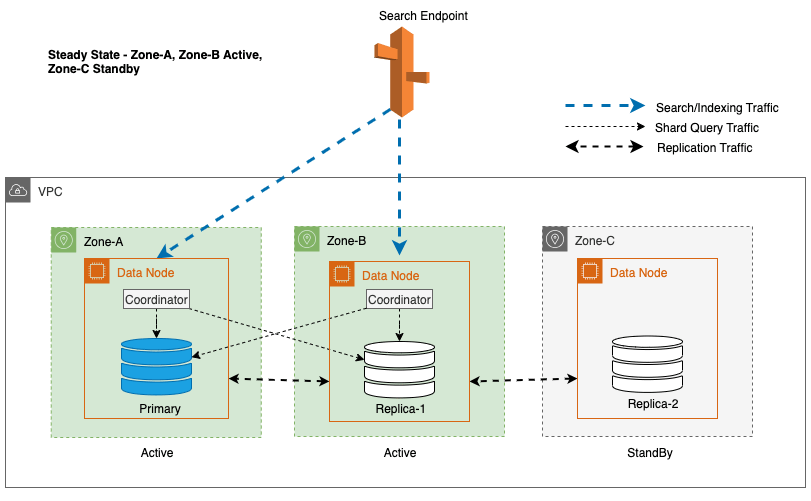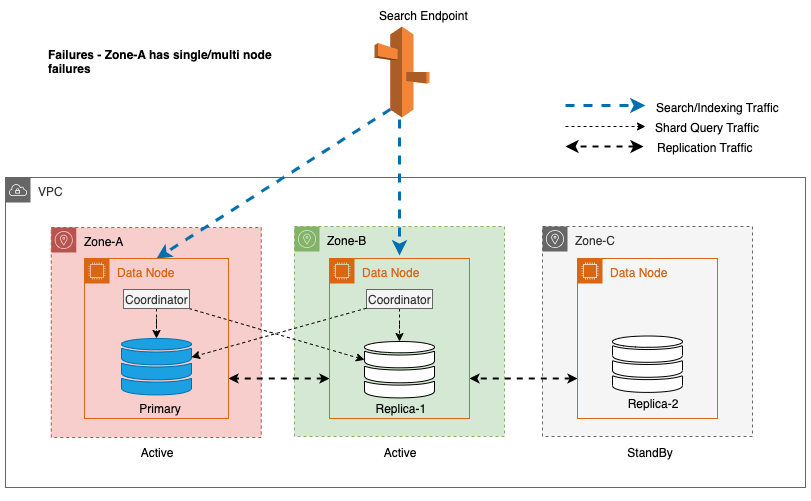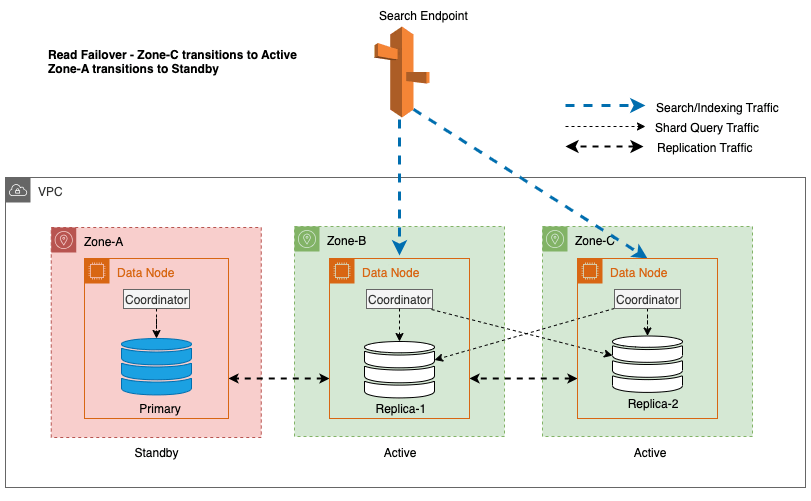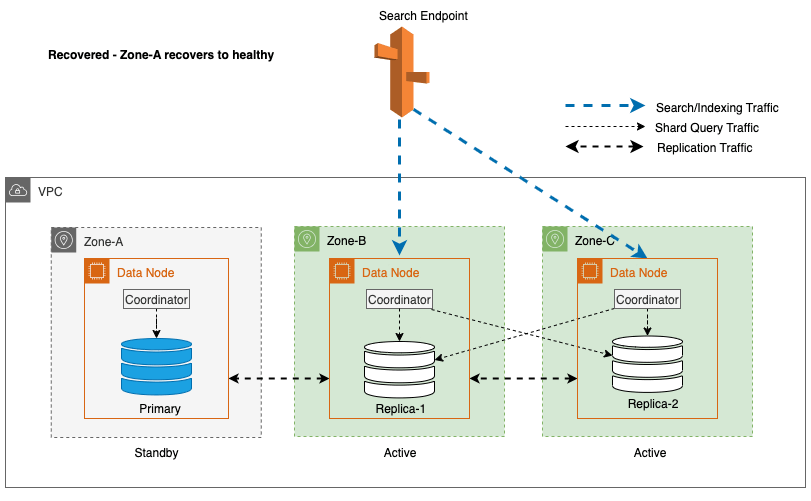
Multi-AZ met Standby implementeert OpenSearch Service-domeininstanties over drie Beschikbaarheidszones, waarbij twee zones zijn aangewezen als actief en één als stand-by. Deze configuratie zorgt voor consistente prestaties, zelfs in het geval van zonestoringen, door dezelfde capaciteit in alle zones te behouden. Belangrijk is dat deze standby-zone volgt op a statisch stabiel ontwerp, waardoor de noodzaak voor capaciteitsvoorziening of gegevensverplaatsing tijdens storingen wordt geëlimineerd.
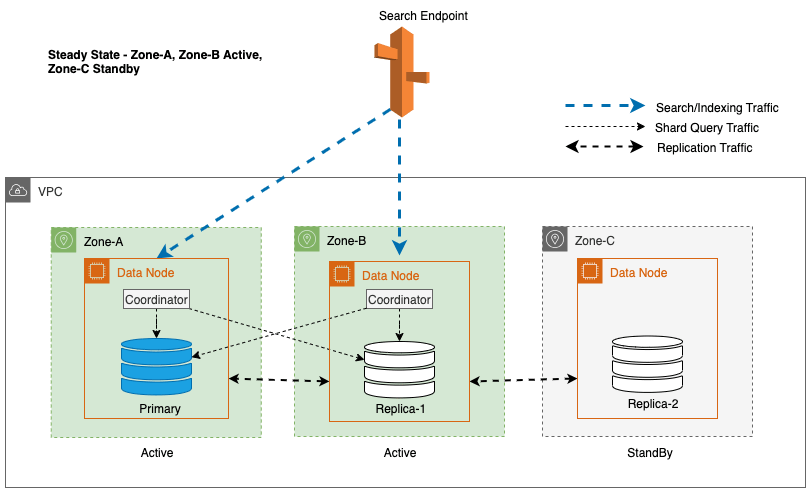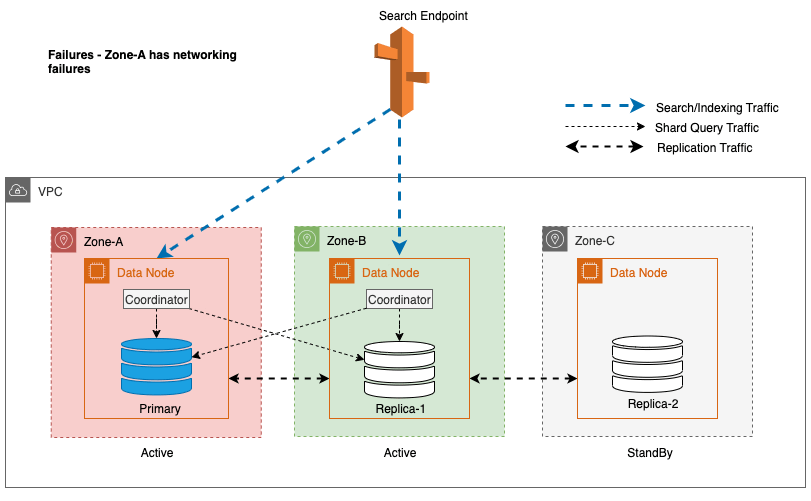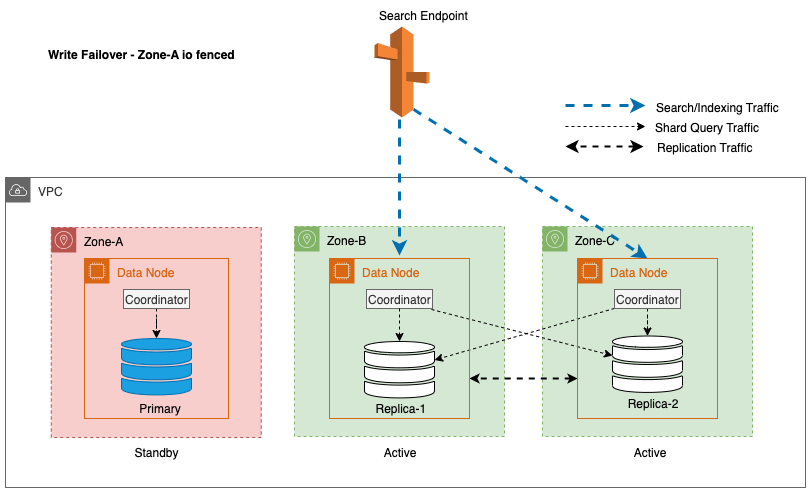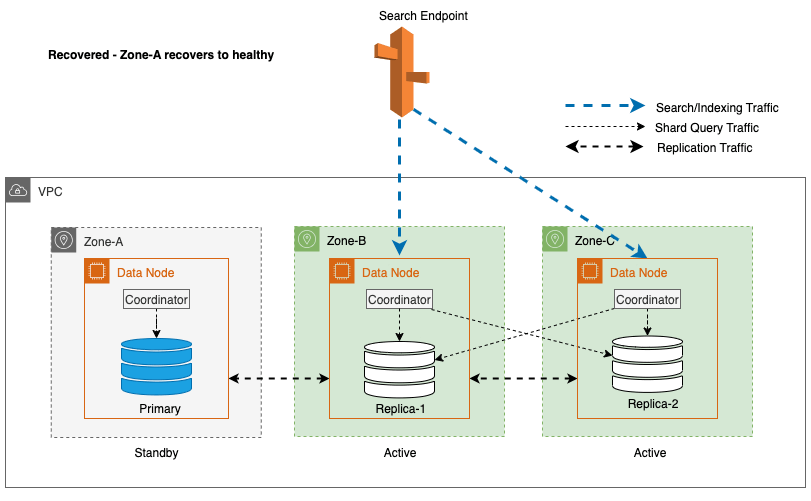
Tijdens normale bewerkingen verwerkt de actieve zone het coördinatorverkeer voor zowel lees- als schrijfaanvragen, evenals Shard-queryverkeer. De standby-zone ontvangt daarentegen alleen replicatieverkeer. OpenSearch Service maakt gebruik van een synchroon replicatieprotocol voor schrijfverzoeken. Hierdoor kan de service een stand-byzone onmiddellijk naar de actieve status brengen in het geval van een storing (gemiddelde tijd tot failover <= 1 minuut), ook wel een zonale failover. De voorheen actieve zone wordt vervolgens gedegradeerd naar de standby-modus en er beginnen hersteloperaties om de gezonde toestand te herstellen.
Zoekverkeerroutering en failover om hoge beschikbaarheid te garanderen
In een OpenSearch Service-domein: a coördinator is elk knooppunt dat HTTP(S)-verzoeken afhandelt, met name indexerings- en zoekverzoeken. In een Multi-AZ met Standby-domein fungeren de dataknooppunten in de actieve zone als coördinatoren voor zoekaanvragen.
Tijdens de queryfase van een zoekaanvraag bepaalt de coördinator welke shards moeten worden opgevraagd en verzendt hij een aanvraag naar het gegevensknooppunt dat als host fungeert voor de shard-kopie. De query wordt lokaal op elke Shard uitgevoerd en de overeenkomende documenten worden geretourneerd naar het coördinatorknooppunt. Het coördinatorknooppunt, dat verantwoordelijk is voor het verzenden van de aanvraag naar knooppunten die shard-kopieën bevatten, voert het proces in twee stappen uit. Ten eerste wordt er een iterator gemaakt die de volgorde definieert waarin knooppunten moeten worden opgevraagd voor een shard-kopie, zodat het verkeer uniform over de shard-kopieën wordt verdeeld. Vervolgens wordt het verzoek naar de betreffende knooppunten verzonden.
Om een geordende lijst met knooppunten te maken die moeten worden opgevraagd voor een Shard-kopie, gebruikt het coördinatorknooppunt verschillende algoritmen. Deze algoritmen omvatten round-robin-selectie, adaptieve replicaselectie, op voorkeuren gebaseerde shardroutering en gewogen round-robin.
Voor Multi-AZ met Stand-by wordt het gewogen round-robin-algoritme gebruikt voor de selectie van shard-kopieën. Bij deze benadering wordt aan actieve zones een gewicht van 1 toegewezen, en aan de standby-zone een gewicht van 0. Dit zorgt ervoor dat er geen leesverkeer naar dataknooppunten in de standby-beschikbaarheidszone wordt verzonden.
De gewichten worden opgeslagen in metagegevens van de clusterstatus als een JSON-object:
Zoals te zien is in de volgende schermafbeelding, is de us-east-1b Regio heeft zijn zonestatus als StandBy, wat aangeeft dat de gegevensknooppunten in deze Beschikbaarheidszone zich in de standby-status bevinden en geen zoek- of indexeringsverzoeken ontvangen van de load balancer.

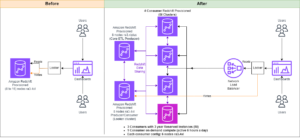
Om een stabiele werking te behouden, wordt de standby-beschikbaarheidszone elke 30 minuten gerouleerd, zodat alle netwerkonderdelen in de beschikbaarheidszones worden gedekt. Deze proactieve aanpak verifieert de beschikbaarheid van leespaden, waardoor de veerkracht van het systeem tijdens potentiële storingen verder wordt vergroot. Het volgende diagram illustreert deze architectuur.
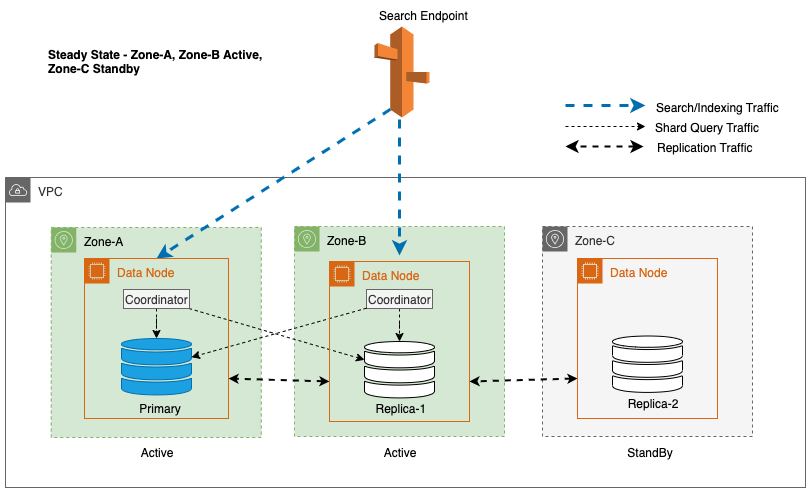
In het voorgaande diagram heeft Zone-C een gewogen round-robin-gewicht ingesteld op nul. Dit zorgt ervoor dat de dataknooppunten in de standby-zone geen indexerings- of zoekverkeer ontvangen. Wanneer de coördinator gegevensknooppunten opvraagt voor shard-kopieën, gebruikt deze een gewogen round-robin-gewicht om te beslissen in welke volgorde de knooppunten moeten worden opgevraagd. Omdat het gewicht voor de standby Availability Zone nul is, worden er geen coördinatorverzoeken verzonden.
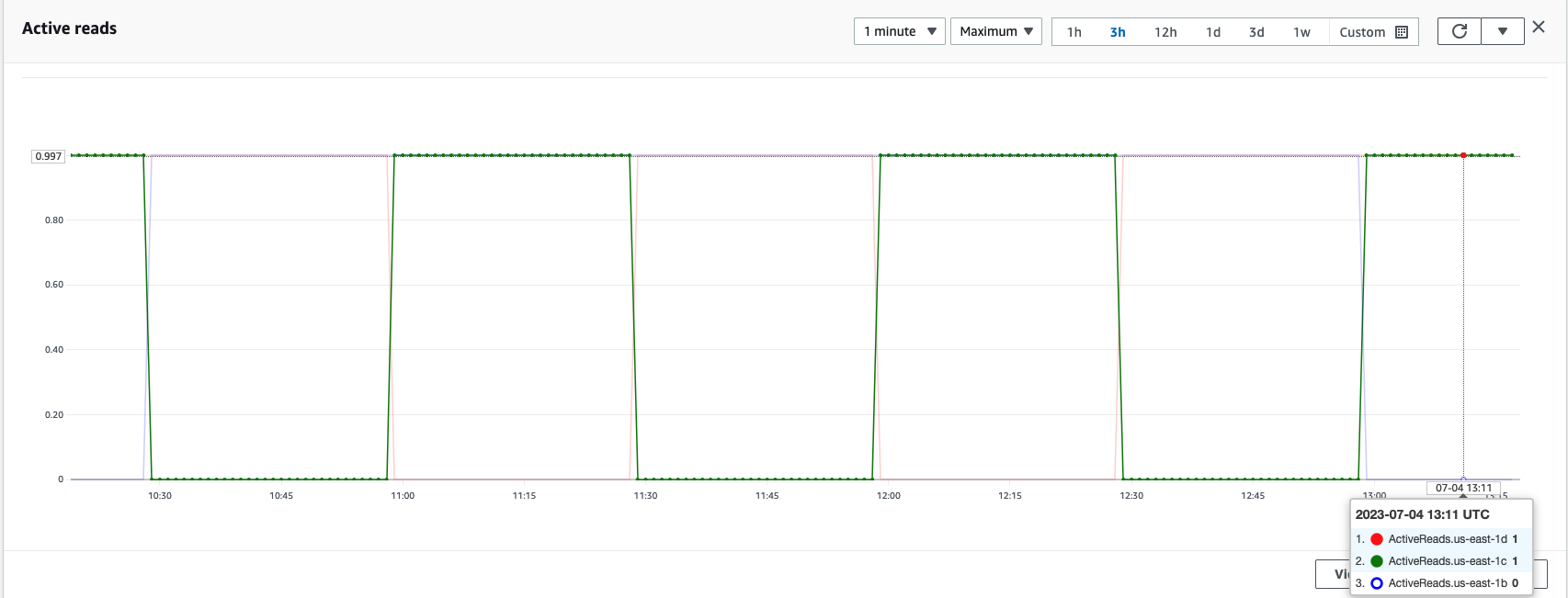
In een OpenSearch Service-cluster kunnen de actieve en stand-byzones op elk moment worden gecontroleerd met behulp van de rotatiestatistieken van de Beschikbaarheidszone, zoals weergegeven in de volgende schermafbeelding.
Tijdens zone-uitval schakelt de standby-beschikbaarheidszone naadloos over naar de fail-open-modus voor zoekaanvragen. Dit betekent dat het Shard-queryverkeer wordt doorgestuurd naar alle Beschikbaarheidszones, zelfs die in stand-by, wanneer een gezonde Shard-kopie niet beschikbaar is in de actieve Beschikbaarheidszone. Deze fail-open-aanpak beschermt zoekaanvragen tegen verstoring tijdens storingen, waardoor een continue service wordt gegarandeerd. Het volgende diagram illustreert deze architectuur.
In het voorgaande diagram wordt tijdens de stabiele status het Shard-queryverkeer verzonden naar het gegevensknooppunt in de actieve Beschikbaarheidszones (Zone-A en Zone-B). Als gevolg van knooppuntfouten in Zone-A kan de standby-beschikbaarheidszone (Zone-C) niet worden geopend om Shard-queryverkeer op te nemen, zodat er geen enkele impact is op de zoekaanvragen. Uiteindelijk wordt Zone-A als ongezond gedetecteerd en schakelt de lees-failover de stand-by naar Zone-A.
Hoe failover zorgt voor hoge beschikbaarheid tijdens schrijfstoornissen
Het replicatiemodel van de OpenSearch Service volgt een primair back-upmodel, gekenmerkt door zijn synchrone aard, waarbij bevestiging van alle shard-kopieën noodzakelijk is voordat een schrijfverzoek aan de gebruiker kan worden bevestigd. Een opmerkelijk nadeel van dit replicatiemodel is de gevoeligheid voor vertragingen in het geval van een verstoring in het schrijfpad. Deze systemen vertrouwen op een actief leiderknooppunt om fouten of vertragingen te identificeren en deze informatie vervolgens naar alle knooppunten te verzenden. De tijd die nodig is om deze problemen te detecteren (gemiddelde tijd om te detecteren) en ze vervolgens op te lossen (gemiddelde tijd om te repareren) bepaalt grotendeels hoe lang het systeem in een verstoorde toestand zal functioneren. Bovendien kan elke netwerkgebeurtenis die de communicatie tussen zones beïnvloedt, schrijfverzoeken aanzienlijk belemmeren vanwege de synchrone aard van replicatie.
OpenSearch Service maakt gebruik van een intern knooppunt-tot-knooppunt-communicatieprotocol voor het repliceren van schrijfverkeer en het coördineren van metadata-updates via een gekozen leider. Bijgevolg zou het in stand-by zetten van de zone die stress ervaart, het probleem van schrijfstoornissen niet effectief aanpakken.
Zonale schrijffailover: replicatieverkeer tussen zones wordt afgesloten
Voor Multi-AZ met Stand-by is zonale schrijffailover een effectieve aanpak om potentiële prestatieproblemen die worden veroorzaakt door onvoorziene gebeurtenissen, zoals zonefouten en netwerkgebeurtenissen, te beperken. Deze aanpak omvat een elegante verwijdering van knooppunten in de getroffen zone uit het cluster, waardoor inkomend en uitgaand verkeer tussen zones effectief wordt afgesloten. Door het replicatieverkeer tussen zones te scheiden, kan de impact van zonefouten binnen de getroffen zone worden beperkt. Dit zorgt voor een meer voorspelbare ervaring voor klanten en zorgt ervoor dat het systeem betrouwbaar blijft werken.
Sierlijke schrijffailover
De orkestratie van een schrijffailover binnen OpenSearch Service wordt uitgevoerd door het gekozen leiderknooppunt via een goed gedefinieerd mechanisme. Dit mechanisme omvat een consensusprotocol voor publicatie van de clusterstatus, waardoor unanieme overeenstemming tussen alle knooppunten wordt gegarandeerd om (te allen tijde) één enkele zone aan te wijzen voor ontmanteling. Belangrijk is dat metagegevens met betrekking tot de getroffen zone op alle knooppunten worden gerepliceerd om de persistentie ervan te garanderen, zelfs tijdens een volledige herstart in het geval van een storing.
Bovendien zorgt het leiderknooppunt voor een soepele en sierlijke overgang door de knooppunten in de getroffen zones in eerste instantie gedurende 5 minuten op stand-by te zetten voordat de I/O-afrastering wordt gestart. Deze doelbewuste aanpak voorkomt dat nieuw coördinatorverkeer of Shard-queryverkeer naar de knooppunten binnen de getroffen zone wordt geleid. Hierdoor kunnen deze knooppunten hun lopende taken op een elegante manier voltooien en geleidelijk alle verzoeken aan boord afhandelen voordat ze buiten dienst worden gesteld. Het volgende diagram illustreert deze architectuur.
Bij het implementeren van een schrijffailover voor een leiderknooppunt volgt OpenSearch Service deze belangrijke stappen:
- Abdicatie van de leider – Als het leiderknooppunt zich toevallig in een zone bevindt die is gepland voor een schrijffailover, zorgt het systeem ervoor dat het leiderknooppunt vrijwillig zijn leiderschapsrol neerlegt. Deze afstand wordt gecontroleerd uitgevoerd en het gehele proces wordt overgedragen aan een ander in aanmerking komend knooppunt, dat vervolgens de benodigde acties op zich neemt.
- Voorkom de herverkiezing van de leider die zal worden ontmanteld – Om de herverkiezing van een leider uit een zone die is gemarkeerd voor schrijffailover te voorkomen, neemt het in aanmerking komende leidersknooppunt, wanneer het de schrijffailoveractie initieert, maatregelen om ervoor te zorgen dat eventuele leidersknooppunten die buiten gebruik moeten worden gesteld, niet deelnemen aan verdere verkiezingen. Dit wordt bereikt door het uit te sluiten leiderknooppunt uit te sluiten van de stemconfiguratie, waardoor effectief wordt voorkomen dat het gaat stemmen tijdens een kritieke fase van de werking van het cluster.
Metagegevens met betrekking tot de failover-zone voor schrijven worden opgeslagen in de clusterstatus en deze informatie wordt als volgt gepubliceerd naar alle knooppunten in het gedistribueerde OpenSearch Service-cluster:
De volgende schermafbeelding laat zien dat tijdens een netwerkvertraging in een zone schrijffailover helpt bij het herstellen van de beschikbaarheid.
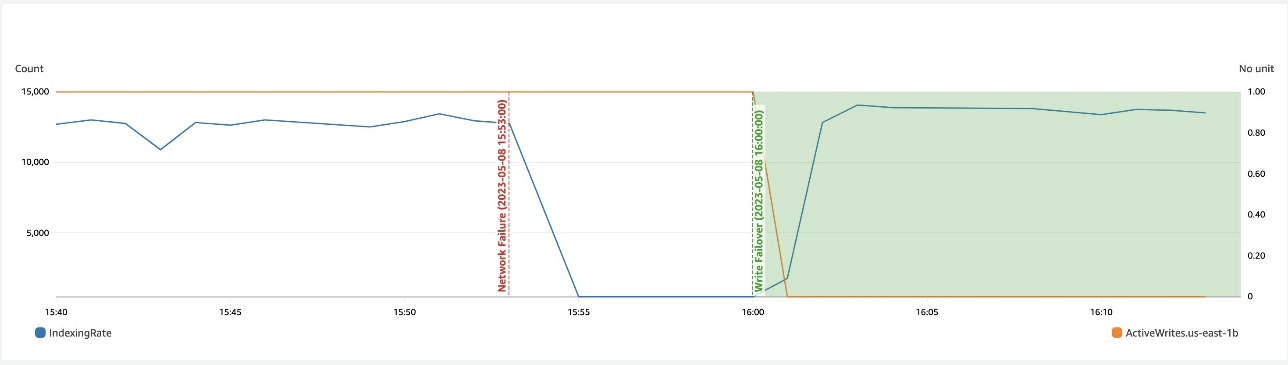
Zoneherstel na failover bij schrijven
Het proces van zonale herinbedrijfstelling speelt een cruciale rol in de herstelfase na een zonale schrijffailover. Nadat de getroffen zone is hersteld en als stabiel wordt beschouwd, zullen de knooppunten die eerder buiten gebruik zijn gesteld weer lid worden van het cluster. Deze herinbedrijfstelling vindt doorgaans plaats binnen een tijdsbestek van 2 minuten nadat de zone opnieuw in gebruik is genomen.
Hierdoor kunnen ze synchroniseren met hun peer-knooppunten en wordt het herstelproces voor replica-shards in gang gezet, waardoor het cluster effectief in de gewenste staat wordt hersteld.
Conclusie
De introductie van OpenSearch Service Multi-AZ met Standby biedt bedrijven een krachtige oplossing om hoge beschikbaarheid en consistente prestaties voor kritieke werklasten te realiseren. Met deze implementatieoptie kunnen bedrijven de veerkracht van hun infrastructuur vergroten, de clusterconfiguratie en -beheer vereenvoudigen en best practices afdwingen. Met functies zoals gewogen round-robin shard-kopieselectie, proactieve failover-mechanismen en fail-open standby-beschikbaarheidszones, zorgt OpenSearch Service Multi-AZ met Standby voor een betrouwbare en efficiënte zoekervaring voor veeleisende bedrijfsomgevingen.
Voor meer informatie over Multi-AZ met Stand-by, zie Amazon OpenSearch-service onder de motorkap: Multi-AZ met stand-by.
Over de auteur
 Anshu Agarwal is een Senior Software Engineer die werkt aan AWS OpenSearch bij Amazon Web Services. Ze is gepassioneerd door het oplossen van problemen met betrekking tot het bouwen van schaalbare en zeer betrouwbare systemen.
Anshu Agarwal is een Senior Software Engineer die werkt aan AWS OpenSearch bij Amazon Web Services. Ze is gepassioneerd door het oplossen van problemen met betrekking tot het bouwen van schaalbare en zeer betrouwbare systemen.
 Rishab Nahata is een Software Engineer die werkt aan OpenSearch bij Amazon Web Services. Hij is gefascineerd door het oplossen van problemen in gedistribueerde systemen. Hij levert een actieve bijdrage aan OpenSearch.
Rishab Nahata is een Software Engineer die werkt aan OpenSearch bij Amazon Web Services. Hij is gefascineerd door het oplossen van problemen in gedistribueerde systemen. Hij levert een actieve bijdrage aan OpenSearch.
 Bukhtawar Khan is een hoofdingenieur die werkt aan de Amazon OpenSearch Service. Hij is geïnteresseerd in gedistribueerde en autonome systemen. Hij levert een actieve bijdrage aan OpenSearch.
Bukhtawar Khan is een hoofdingenieur die werkt aan de Amazon OpenSearch Service. Hij is geïnteresseerd in gedistribueerde en autonome systemen. Hij levert een actieve bijdrage aan OpenSearch.
 Ranjith Ramachandra is een Engineering Manager die werkt aan Amazon OpenSearch Service bij Amazon Web Services.
Ranjith Ramachandra is een Engineering Manager die werkt aan Amazon OpenSearch Service bij Amazon Web Services.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- : heeft
- :is
- :niet
- :waar
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Over
- Bereiken
- bereikt
- erkend
- over
- Handelen
- Actie
- acties
- actieve
- adaptieve
- Daarnaast
- adres
- beïnvloed
- Na
- Overeenkomst
- algoritme
- algoritmen
- Alles
- toelaten
- Amazone
- Amazon Web Services
- onder
- an
- en
- Nog een
- elke
- nadering
- architectuur
- ZIJN
- AS
- toegewezen
- At
- autonoom
- autonome systemen
- beschikbaarheid
- bewustzijn
- AWS
- backup
- balancer
- BE
- omdat
- geweest
- vaardigheden
- wezen
- BEST
- 'best practices'
- tussen
- zowel
- uitzenden
- Gebouw
- ondernemingen
- by
- CAN
- Inhoud
- gedragen
- veroorzaakt
- gekarakteriseerde
- lading
- gecontroleerd
- TROS
- Communicatie
- Communicatie
- compleet
- Configuratie
- Overeenstemming
- bijgevolg
- beschouwd
- consequent
- troosten
- bevatte
- blijft
- doorlopend
- bijdragen
- inzender
- gecontroleerd
- coördineren
- Coördinator
- coördinatoren
- kopieën
- bedekt
- en je merk te creëren
- creëert
- kritisch
- cruciaal
- Klanten
- snijdend
- gegevens
- beslissen
- deep
- diepe duik
- definieert
- vertragingen
- delven
- veeleisende
- inzet
- ontplooit
- aangewezen
- ontworpen
- gewenste
- opsporen
- gedetecteerd
- bepaalt
- gerichte
- Ontwrichting
- verdeeld
- gedistribueerde systemen
- duiken
- do
- documenten
- domein
- domeinen
- Dont
- beneden
- twee
- duur
- gedurende
- elk
- effectief
- effectief
- doeltreffend
- gekozen
- verkiezingen
- geschikt
- elimineren
- ingeschakeld
- maakt
- afdwingen
- ingenieur
- Engineering
- verhogen
- verbeterde
- verbeteren
- verzekeren
- waarborgt
- zorgen
- Enterprise
- Geheel
- omgevingen
- vooral
- Ether (ETH)
- Zelfs
- Event
- EVENTS
- uiteindelijk
- Alle
- Exclusief
- ervaring
- het ervaren van
- Verken
- mislukt
- Storing
- mislukkingen
- Kenmerk
- Voordelen
- schermen
- Voornaam*
- volgend
- volgt
- Voor
- FRAME
- oppompen van
- vol
- verder
- gif
- Bevallig
- geleidelijk
- garantie
- hand
- handvat
- Handvaten
- gebeurt
- he
- gezond
- helpt
- Hoge
- zeer
- kap
- Hosting
- Hoe
- http
- HTTPS
- identificeren
- if
- illustreert
- Impact
- beïnvloed
- verslechtering
- uitvoering
- belangrijker
- in
- omvatten
- wat aangeeft
- informatie
- Infrastructuur
- eerste
- ingewijden
- initiëren
- gevallen
- geïnteresseerd
- intern
- in
- geïntroduceerd
- Introductie
- gaat
- kwestie
- problemen
- IT
- HAAR
- jpg
- json
- sleutel
- bekend
- grotendeels
- leider
- Leadership
- als
- Lijst
- laden
- plaatselijk
- gelegen
- lang
- onderhouden
- behoud van
- beheerd
- management
- manager
- manier
- gemarkeerd
- op elkaar afgestemd
- gemiddelde
- middel
- maatregelen
- mechanisme
- mechanismen
- Metadata
- Metriek
- minuut
- minuten
- Verzachten
- Mode
- model
- meer
- beweging
- NATUUR
- noodzakelijk
- Noodzaak
- netwerk
- netwerken
- New
- geen
- knooppunt
- knooppunten
- opvallend
- object
- of
- korting
- on
- EEN
- lopend
- Slechts
- open
- besturen
- operatie
- Operations
- Keuze
- or
- orkestratie
- bestellen
- Overige
- uit
- storing
- outages
- over
- deelnemen
- onderdelen
- hartstochtelijk
- pad
- paden
- turen
- prestatie
- volharding
- fase
- plaatsing
- Plato
- Plato gegevensintelligentie
- PlatoData
- speelt
- Post
- potentieel
- krachtige
- praktijken
- voorafgaat
- Voorspelbaar
- voorkomen
- het voorkomen van
- voorkomt
- die eerder
- primair
- Principal
- Proactieve
- problemen
- promoten
- protocol
- zorgen voor
- biedt
- Publicatie
- gepubliceerde
- Putting
- queries
- Lees
- ontvangen
- ontvangt
- onlangs
- Herstellen
- herstellende
- na een training
- verwijzen
- regio
- regelmatig
- verwant
- relevante
- betrouwbaarheid
- betrouwbaar
- vertrouwen
- resterende
- verwijdering
- reparatie
- antwoord
- gerepliceerd
- kopiëren
- te vragen
- verzoeken
- nodig
- veerkracht
- veerkrachtig
- oplossen
- verantwoordelijk
- herstellen
- herstelde
- het herstellen van
- Rol
- routing
- lopen
- loopt
- s
- waarborgen
- dezelfde
- schaalbare
- gepland
- naadloos
- Ontdek
- selectie
- verzending
- verzendt
- senior
- verzonden
- service
- Diensten
- reeks
- ze
- getoond
- aanzienlijk
- eenvoud
- vereenvoudigen
- single
- Vertragen
- vertragingen
- glad
- So
- Software
- Software Engineer
- oplossing
- Het oplossen van
- stabiel
- Land
- Status
- vast
- Stappen
- opgeslagen
- spanning
- Hierop volgend
- geslaagd
- gevoeligheid
- system
- Systems
- Nemen
- ingenomen
- neemt
- taken
- dat
- De
- hun
- Ze
- harte
- Er.
- Deze
- dit
- die
- drie
- Door
- niet de tijd of
- keer
- naar
- tolerantie
- verkeer
- overgang
- BEURT
- twee
- typisch
- voor
- die ten grondslag liggen
- onvoorzien
- updates
- gebruikt
- Gebruiker
- toepassingen
- gebruik
- maakt gebruik van
- divers
- vrijwillig
- Stemming
- we
- web
- webservices
- gewicht
- GOED
- goed gedefinieerd
- waren
- wanneer
- welke
- en
- wil
- Met
- binnen
- werkzaam
- Bedrijven
- schrijven
- zephyrnet
- nul
- zones