Pandas is een krachtige en veelgebruikte open-sourcebibliotheek voor gegevensmanipulatie en -analyse met behulp van Python. Een van de belangrijkste kenmerken is de mogelijkheid om gegevens te groeperen met behulp van de groupby-functie door een DataFrame in groepen te splitsen op basis van een of meer kolommen en vervolgens op elk daarvan verschillende aggregatiefuncties toe te passen.

Afbeelding van Unsplash
De groupby functie is ongelooflijk krachtig, omdat u hiermee snel grote datasets kunt samenvatten en analyseren. U kunt bijvoorbeeld een gegevensset groeperen op een specifieke kolom en het gemiddelde, de som of het aantal van de resterende kolommen voor elke groep berekenen. U kunt ook op meerdere kolommen groeperen om een gedetailleerder inzicht in uw gegevens te krijgen. Bovendien kunt u aangepaste aggregatiefuncties toepassen, wat een zeer krachtig hulpmiddel kan zijn voor complexe gegevensanalysetaken.
In deze tutorial leert u hoe u de groupby-functie in Pandas kunt gebruiken om verschillende soorten gegevens te groeperen en verschillende aggregatiebewerkingen uit te voeren. Aan het einde van deze zelfstudie zou u deze functie moeten kunnen gebruiken om gegevens op verschillende manieren te analyseren en samen te vatten.
Concepten worden geïnternaliseerd als ze goed worden geoefend en dit is wat we vervolgens gaan doen, namelijk in de praktijk aan de slag gaan met Panda's groupby-functie. Het wordt aanbevolen om een Jupyter Notebook voor deze zelfstudie, omdat u bij elke stap de uitvoer kunt zien.
Genereer voorbeeldgegevens
Importeer de volgende bibliotheken:
- Panda's: Om een dataframe te maken en groeperen op toe te passen
- Willekeurig – Om willekeurige gegevens te genereren
- Pprint – Om woordenboeken af te drukken
import pandas as pd
import random
import pprint
Vervolgens initialiseren we een leeg dataframe en vullen we waarden in voor elke kolom, zoals hieronder weergegeven:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Bonustip: een schonere manier om dezelfde taak uit te voeren is door een woordenboek van alle variabelen en waarden te maken en dit later naar een dataframe te converteren.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
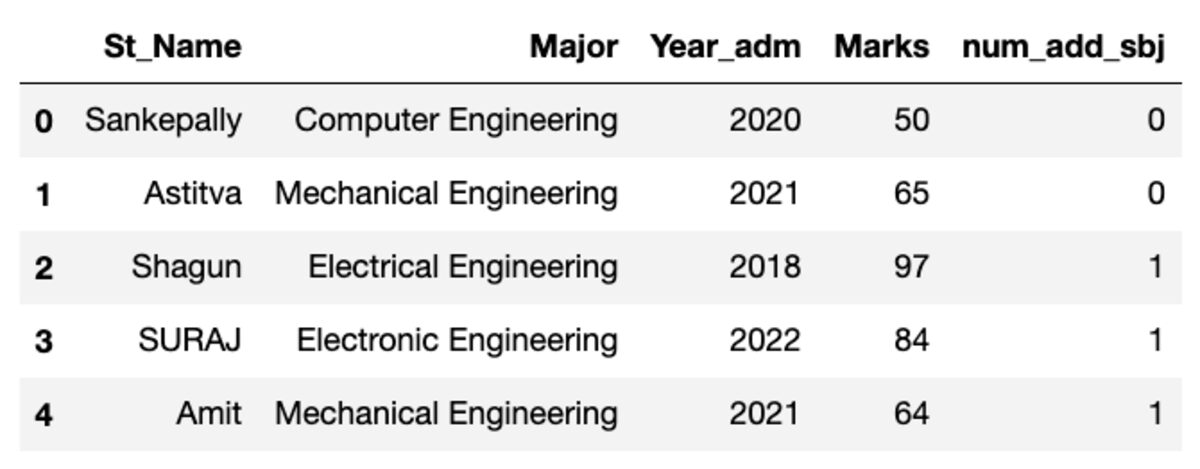
Het dataframe ziet eruit zoals hieronder weergegeven. Bij het uitvoeren van deze code komen sommige waarden niet overeen, omdat we een willekeurige steekproef gebruiken.
Groepen maken
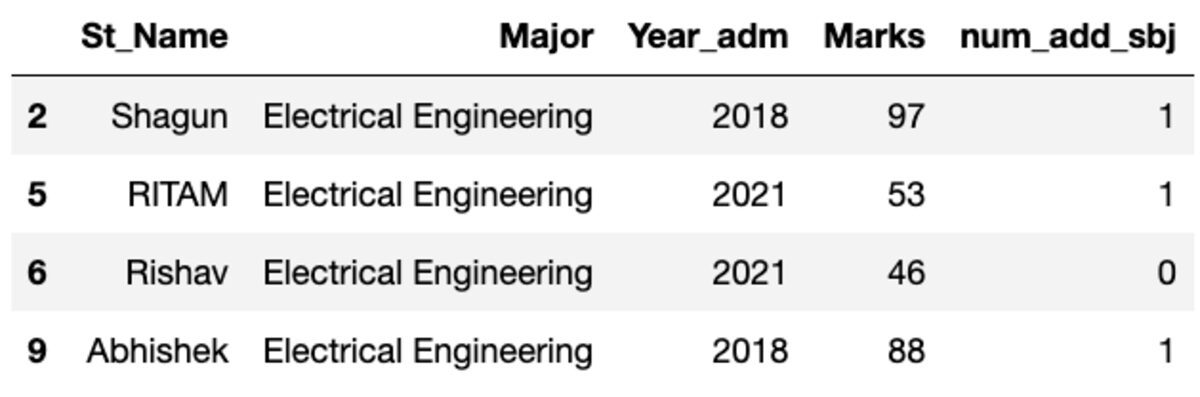
Laten we de gegevens groeperen op basis van het onderwerp 'Hoofd' en het groepsfilter toepassen om te zien hoeveel records in deze groep vallen.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Er behoren dus vier studenten tot de major Elektrotechniek.
U kunt ook op meer dan één kolom groeperen (in dit geval Major en num_add_sbj).
groups = df.groupby(['Major', 'num_add_sbj'])
Houd er rekening mee dat alle aggregatiefuncties die kunnen worden toegepast op groepen met één kolom, kunnen worden toegepast op groepen met meerdere kolommen. Laten we ons voor de rest van de zelfstudie concentreren op de verschillende typen aggregaties, waarbij we één kolom als voorbeeld gebruiken.
Laten we groepen maken met behulp van groupby in de kolom 'Major'.
groups = df.groupby('Major')Directe functies toepassen
Stel dat je de gemiddelde cijfers voor elke major wilt weten. Wat zou jij doen?
- Kies de kolom Markeringen
- Pas de gemiddelde functie toe
- Pas de rondefunctie toe om cijfers af te ronden op twee decimalen (optioneel)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Aggregaat
Een andere manier om hetzelfde resultaat te bereiken is door een aggregatiefunctie te gebruiken, zoals hieronder weergegeven:
groups['Marks'].aggregate('mean').round(2)
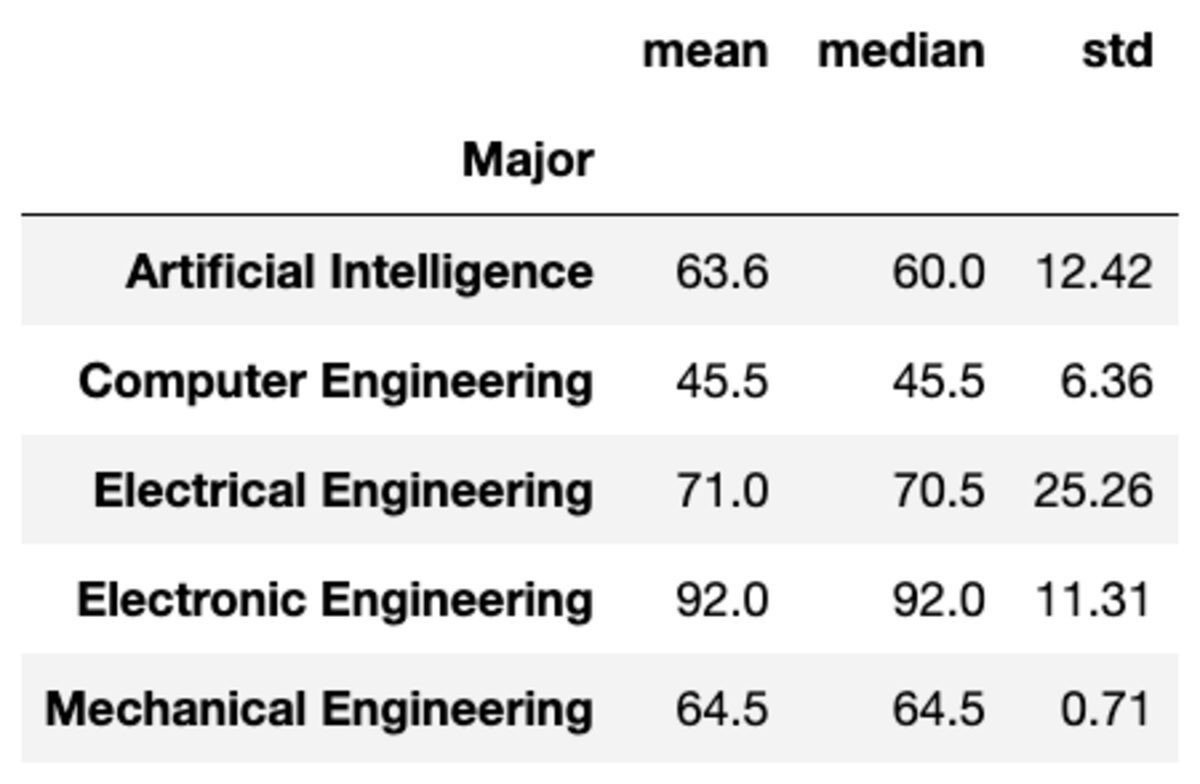
U kunt ook meerdere aggregaties op de groepen toepassen door de functies door te geven als een lijst met tekenreeksen.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
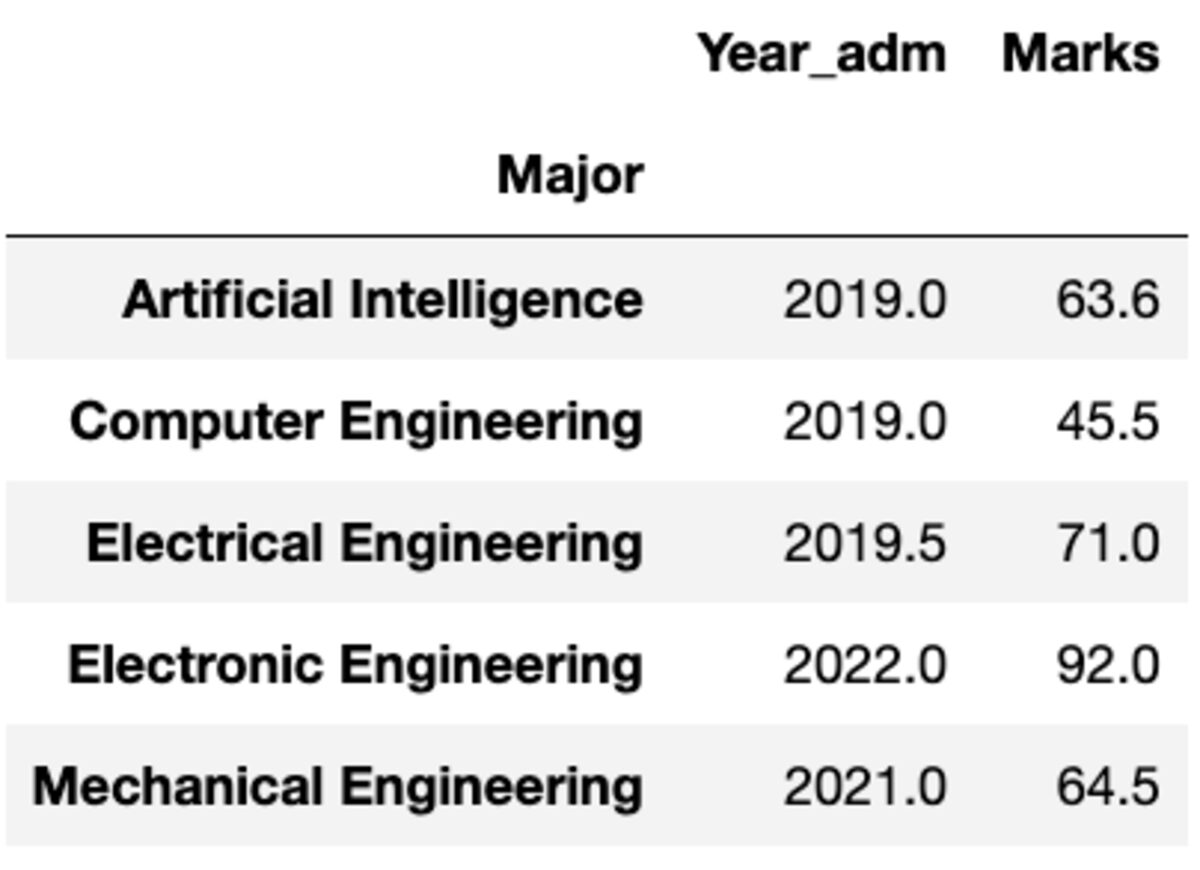
Maar wat als u een andere functie op een andere kolom moet toepassen? Maak je geen zorgen. U kunt dat ook doen door het paar {column: function} door te geven.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
transformaties
Mogelijk moet u aangepaste transformaties uitvoeren naar een bepaalde kolom, wat eenvoudig kan worden bereikt met groupby(). Laten we een standaard scalair definiëren die vergelijkbaar is met degene die beschikbaar is in de voorverwerkingsmodule van sklearn. U kunt alle kolommen transformeren door de transformatiemethode aan te roepen en de aangepaste functie door te geven.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
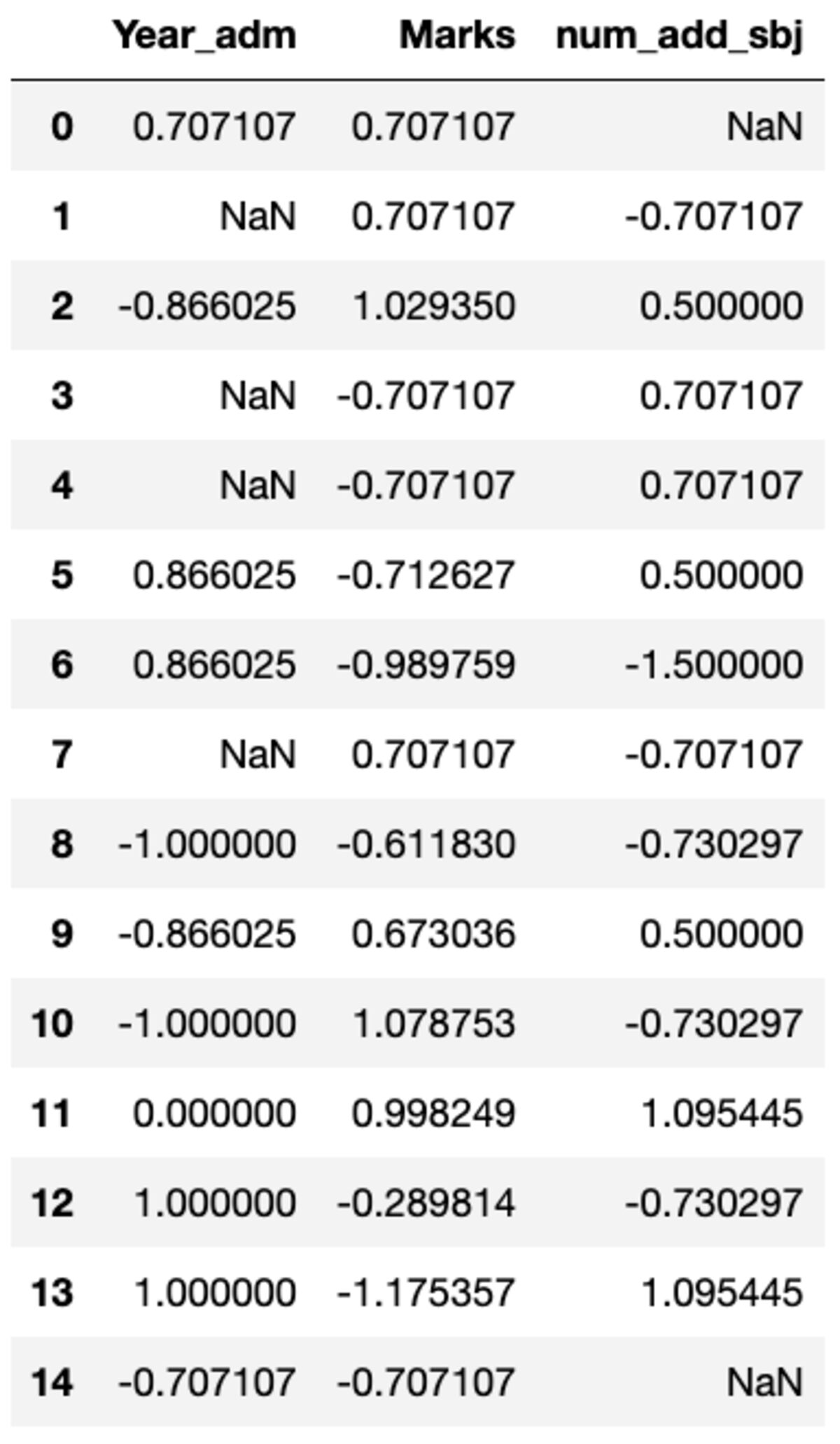
Merk op dat "NaN" groepen vertegenwoordigt met een standaardafwijking van nul.
FILTER
Misschien wil je controleren welke “Major” ondermaats presteert, dat wil zeggen degene waarbij de gemiddelde “Marks” van studenten minder dan 60 zijn. Hiervoor moet je een filtermethode toepassen op groepen met een functie erin. De onderstaande code gebruikt a lambda-functie om de gefilterde resultaten te bereiken.
groups.filter(lambda x: x['Marks'].mean() 60)

Voornaam*
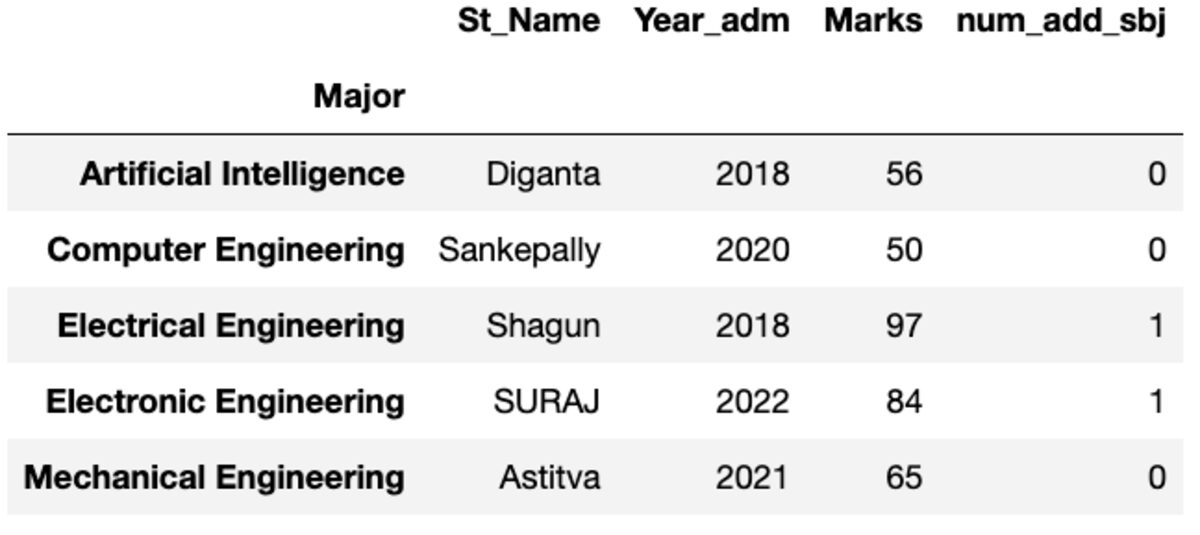
Het geeft u de eerste instantie gesorteerd op index.
groups.first()
Beschrijven
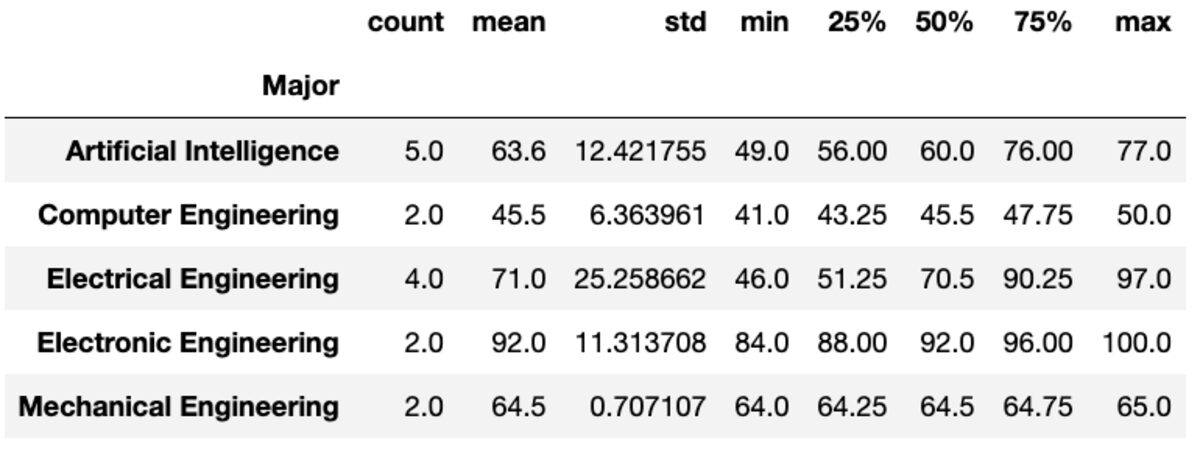
De “describe”-methode retourneert basisstatistieken zoals aantal, gemiddelde, std, min, max, etc. voor de gegeven kolommen.
groups['Marks'].describe()
Maat
Grootte retourneert, zoals de naam al doet vermoeden, de grootte van elke groep in termen van het aantal records.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64Graaf en Nunique
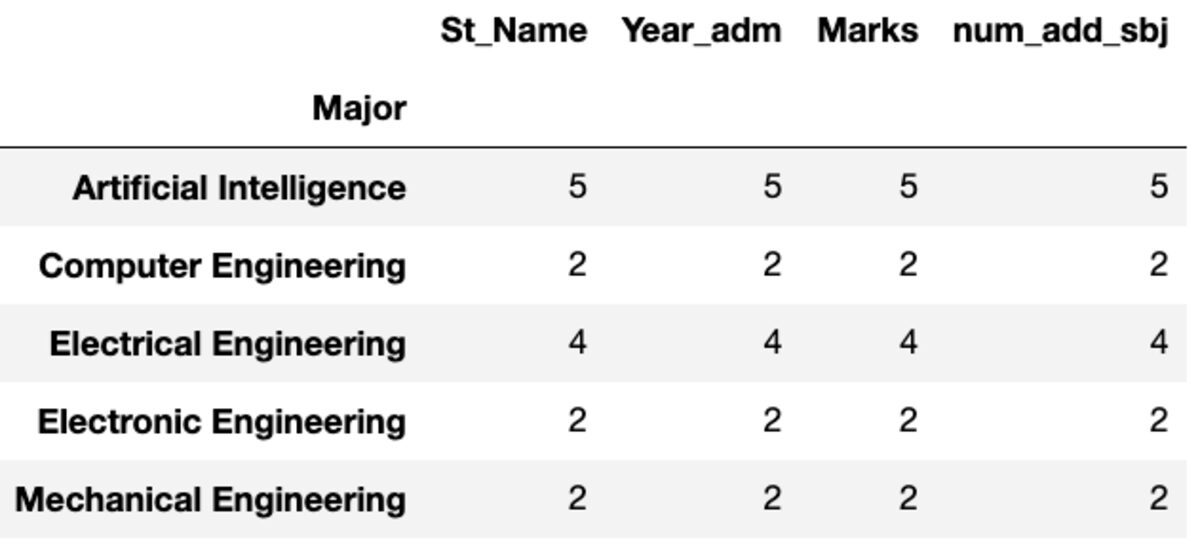
“Count” retourneert alle waarden, terwijl “Nunique” alleen de unieke waarden in die groep retourneert.
groups.count()
groups.nunique()
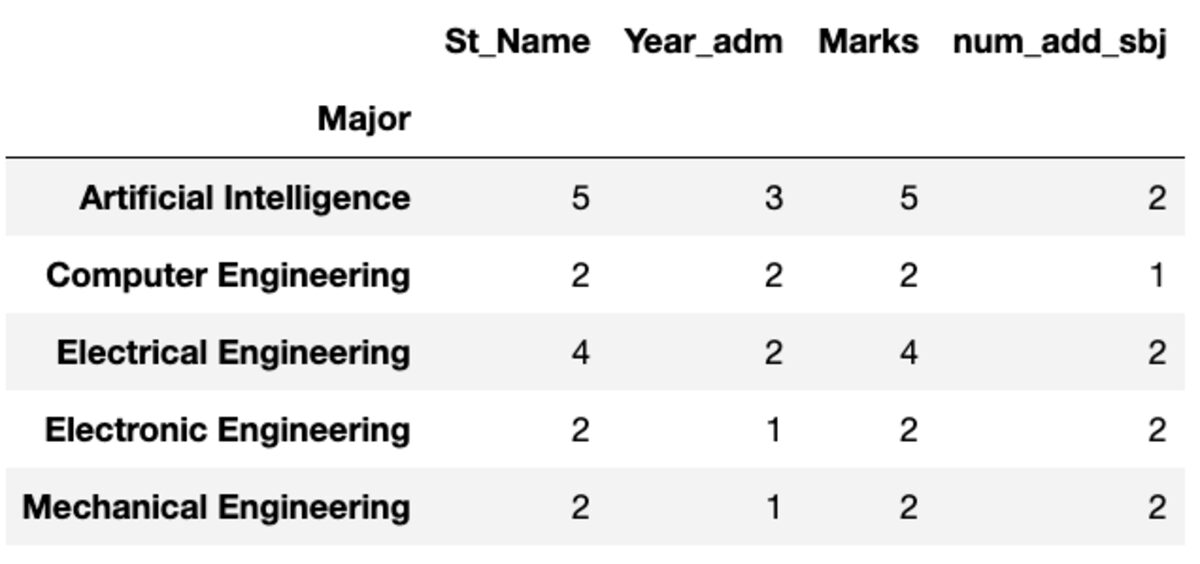
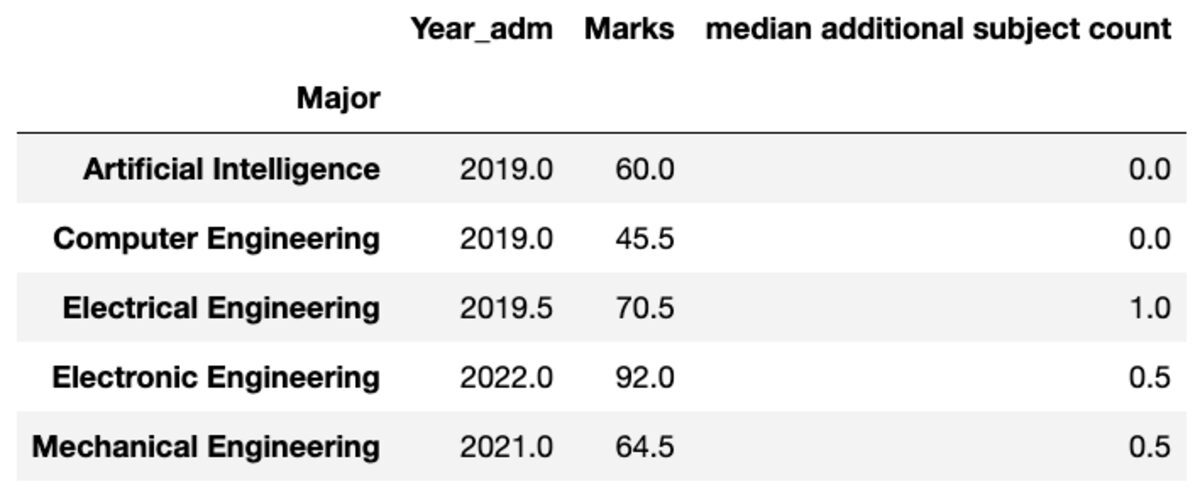
andere naam geven
U kunt de naam van de geaggregeerde kolommen ook naar eigen voorkeur hernoemen.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Wees duidelijk over het doel van de groupby: Probeert u de gegevens op één kolom te groeperen om het gemiddelde van een andere kolom te krijgen? Of probeert u de gegevens in meerdere kolommen te groeperen om het aantal rijen in elke groep te achterhalen?
- Begrijp de indexering van het dataframe: De groupby-functie gebruikt de index om de gegevens te groeperen. Als u de gegevens per kolom wilt groeperen, zorg er dan voor dat de kolom is ingesteld als index, of u kunt .set_index() gebruiken.
- Gebruik de juiste aggregatiefunctie: Het kan worden gebruikt met verschillende aggregatiefuncties zoals mean(), sum(), count(), min(), max()
- Gebruik de as_index-parameter: Wanneer ingesteld op False, vertelt deze parameter panda's om de gegroepeerde kolommen te gebruiken als gewone kolommen in plaats van als index.
U kunt groupby() ook gebruiken in combinatie met andere panda-functies zoals pivot_table(), crosstab() en cut() om meer inzichten uit uw gegevens te halen.
Een groupby-functie is een krachtig hulpmiddel voor gegevensanalyse en -manipulatie, omdat u hiermee rijen met gegevens kunt groeperen op basis van een of meer kolommen en vervolgens aggregatieberekeningen op de groepen kunt uitvoeren. De tutorial demonstreerde verschillende manieren om de groupby-functie te gebruiken met behulp van codevoorbeelden. Ik hoop dat het je inzicht geeft in de verschillende opties die ermee gepaard gaan en ook hoe ze helpen bij de data-analyse.
Vidhi Chugh is een AI-strateeg en leider op het gebied van digitale transformatie en werkt op het snijvlak van product, wetenschap en engineering om schaalbare machine learning-systemen te bouwen. Ze is een bekroonde innovatieleider, een auteur en een internationale spreker. Ze is op een missie om machine learning te democratiseren en het jargon te doorbreken zodat iedereen deel kan uitmaken van deze transformatie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- vermogen
- in staat
- Bereiken
- bereikt
- Extra
- Daarnaast
- aggregatie
- AI
- Alles
- toestaat
- analyse
- analyseren
- en
- Nog een
- toegepast
- Solliciteer
- Het toepassen van
- passend
- kunstmatig
- kunstmatige intelligentie
- auteur
- Beschikbaar
- gemiddelde
- bekroonde
- gebaseerde
- basis-
- onder
- biotechnologie
- Breken
- bouw
- berekenen
- bellen
- geval
- controle
- duidelijk
- code
- Kolom
- columns
- hoe
- complex
- computer
- Computertechniek
- en je merk te creëren
- Wij creëren
- gewoonte
- gegevens
- gegevensanalyse
- datasets
- democratiseren
- gedemonstreerd
- afwijking
- anders
- digitaal
- Digitale Transformatie
- directe
- Dont
- elk
- gemakkelijk
- effectief
- Elektrotechniek
- elektronisch
- Engineering
- etc
- iedereen
- voorbeeld
- voorbeelden
- extract
- Vallen
- Voordelen
- vullen
- filter
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- Focus
- volgend
- FRAME
- oppompen van
- functie
- functies
- voortbrengen
- krijgen
- gegeven
- geeft
- gaan
- Groep
- Groep
- hands-on
- hulp
- hoop
- Hoe
- How To
- HTML
- HTTPS
- importeren
- in
- ongelooflijk
- index
- Innovatie
- inzichten
- instantie
- verkrijgen in plaats daarvan
- Intelligentie
- Internationale
- kruispunt
- IT
- jargon
- KDnuggets
- sleutel
- Groot
- leider
- LEARN
- leren
- bibliotheken
- Bibliotheek
- Lijst
- LOOKS
- machine
- machine learning
- groot
- maken
- Manipulatie
- veel
- Match
- max
- mechanisch
- machinebouw
- Medium
- methode
- Missie
- module
- meer
- meervoudig
- naam
- namen
- Noodzaak
- volgende
- aantal
- EEN
- open source
- Operations
- Opties
- Overige
- panda's
- parameter
- deel
- bijzonder
- Voorbijgaand
- uitvoeren
- plaatsen
- Plato
- Plato gegevensintelligentie
- PlatoData
- krachtige
- Product
- biedt
- doel
- Python
- snel
- willekeurige
- aanbevolen
- archief
- regelmatig
- resterende
- vertegenwoordigt
- vereist
- REST
- resultaat
- Resultaten
- terugkeer
- Retourneren
- Richard
- ronde
- lopend
- dezelfde
- schaalbare
- WETENSCHAPPEN
- reeks
- moet
- getoond
- gelijk
- single
- Maat
- sommige
- Spreker
- specifiek
- standaard
- statistiek
- Stap voor
- Strateeg
- Student
- Leerlingen
- onderwerpen
- Stelt voor
- samenvatten
- Systems
- Taak
- taken
- vertelt
- termen
- De
- type
- naar
- tools
- Transformeren
- Transformatie
- transformaties
- zelfstudie
- types
- begrip
- unieke
- .
- Values
- divers
- manieren
- Wat
- welke
- wil
- werkzaam
- zou
- X
- jaar
- Your
- zephyrnet
- nul








