Afbeelding door redacteur
Klantsentimentanalyse is het proces waarbij machine learning (ML) wordt gebruikt om de intentie en mening van klanten over een merk te ontdekken op basis van klantfeedback die wordt gegeven in recensies, forums, enquêtes, enzovoort. Sentimentanalyse van gegevens over klantervaringen geeft bedrijven diepgaand inzicht in motivaties achter aankoopbeslissingen, de patronen in veranderend merksentiment op basis van tijdlijnen of gebeurtenissen, en analyse van de marktkloof die kunnen helpen bij het verbeteren van producten en diensten.
Inhoudsopgave:
- Wat is klantsentimentanalyse?
- Hoe verzamel je data voor klantsentimentanalyse?
- Hoe sentimentscores worden afgeleid uit klantfeedback
- Conclusie
Sentimentanalyse verfijnt klantfeedbackgegevens om specifiek te identificeren emoties of gevoelens. In grote lijnen zijn deze positief, negatief of neutraal. Maar binnen deze parameters kan een sentimentanalysemodel dat wordt aangedreven door ML-taken zoals natuurlijke taalverwerking (NLP) en semantische analyse die de semantische en syntactische aspecten van woorden kan vinden, ook helpen bij het vinden van verschillende soorten negatief sentiment.
Het kan bijvoorbeeld helpen om verschillende sentimentscores te geven op basis van woorden die verschillende negatieve emoties aanduiden, zoals angst, teleurstelling, spijt, woede, enzovoort. Hetzelfde is het geval met positieve microsentimenten.
Een dergelijke fijnmazige emotie-mining in combinatie met een op aspecten gebaseerde analyse van de ervaring van een klant met een merk kan van het grootste belang zijn. Als u bijvoorbeeld het sentiment kent op basis van aspecten als prijs, gemak, aankoopgemak, klantenservice, enz., Krijgt u bruikbare inzichten waarop u kunt vertrouwen om de juiste beslissingen te nemen als het gaat om kwaliteitscontrole en productverbetering.
Een zeer belangrijk onderdeel van het verkrijgen van gerichte en inzichtelijke informatie over merksentiment is het hebben van betrouwbare klantfeedbackgegevens. Hier zijn vijf essentiële manieren waarop u dergelijke gegevens kunt verzamelen.
1. Reacties en video's op sociale media
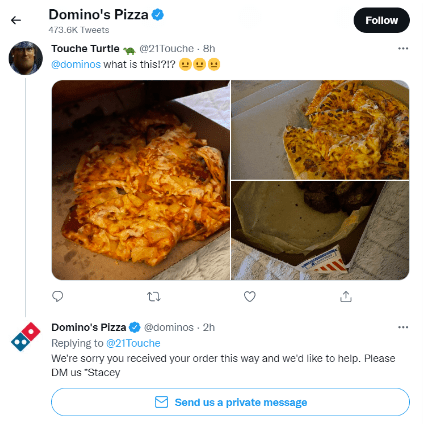
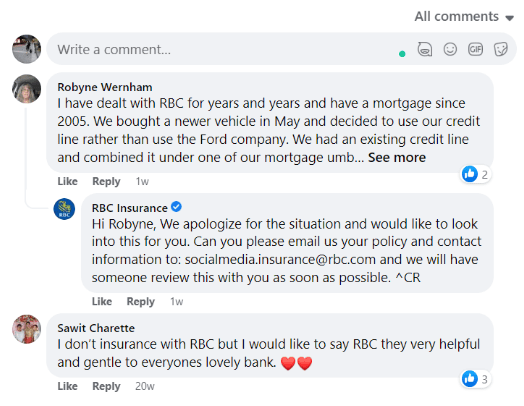
Luisteren naar sociale media is een van de manieren waarop u actuele feedback van klanten over uw merk kunt krijgen, die zowel uw product als uw service omvat. Een model voor sentimentanalyse dat reacties op sociale media en video-inhoud kan verwerken en evalueren, is de perfecte keuze om deze gegevensbron te benutten.
Met zo'n tool benut je gegevens voor analyse van het klantsentiment, van sociale mediasites met veel tekst zoals Twitter tot op video gebaseerde sites zoals TikTok of Instagram. Dit geeft je een groot voordeel, want niet alle social media platformen zijn one-size-fits-all als het gaat om klant keuzes.
Terwijl klanten bijvoorbeeld voornamelijk Twitter gebruiken om rechtstreeks met een merk in contact te komen, is het bekend dat Facebook-gebruikers gedetailleerde opmerkingen achterlaten over een bedrijf waarmee ze verbonden zijn. Dit sterke contrast is te wijten aan factoren zoals de aard van het bedrijf, leeftijd, geografische locatie, digitaal gebruik, enzovoort.
Onderstaande voorbeelden laten zien hoe klanten reacties achterlaten op de twee verschillende social media kanalen.
Een ander groot voordeel van sentimentanalyse op sociale media is dat u ook influencers op sociale media kunt vinden die bij u passen en een geweldige aanvulling kunnen zijn op uw digitale marketingstrategie. Influencers kosten de helft van de investering die nodig is voor het inhuren van een PR-bureau of het inhuren van beroemdheden.
Ook vertrouwen mensen productrecensies en aanbevelingen van influencers aan wie ze kunnen betrekking hebben. Dit is waar, of je nu een stagiair bent die op zoek is naar professionele stylingtips of een vader van vier kinderen die op zoek is naar de beste opties in mobiele telefoons voor tieners. Dit is hoe data science en ML helpen bij het vinden van de juiste TikTok Influencer voor een bedrijf.
2. Ga verder dan kwantitatieve enquêtes zoals NPS, CES of CSAT
Klantfeedbackstatistieken zoals net promoter score (NPS), customer effort score (CES) of sterbeoordelingen kunnen u in één oogopslag vertellen of mensen tevreden zijn met uw bedrijf of niet. Maar dit geeft u niet echt zakelijk inzicht.
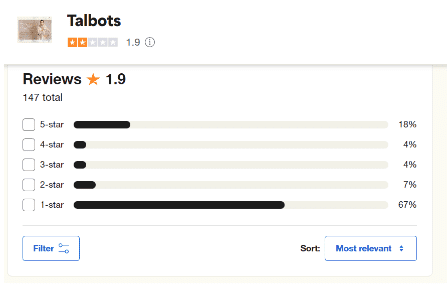
Om echte inzichten in het klantsentiment te krijgen, moet u verder gaan dan kwantitatieve statistieken. En daarvoor moet u opmerkingen en enquêteantwoorden met een open einde analyseren die geen vast antwoord hebben. Hierdoor kunnen klanten vrij stromende opmerkingen schrijven, die u inzicht kunnen geven in aspecten van uw bedrijf waarvan u zich niet eens bewust was.
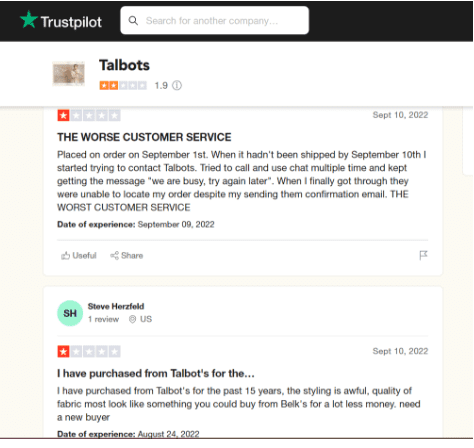
In het bovenstaande voorbeeld kunnen we zien dat klanten het bedrijf een beoordeling van 1 ster hebben gegeven. Maar bij het lezen van de commentaren realiseren we ons dat de redenen achter de negatieve gevoelens heel anders zijn.
Terwijl de ene klant ontevreden is over de online klantenservice van het bedrijf, vermeldt de andere dat hoewel ze al lang klant zijn, de daling van de kwaliteit en de nieuwe prijzen de reden zijn waarom ze misschien niet meer bij hen kopen.
Dit zijn bruikbare inzichten, waarbij een bedrijf precies weet waar verbetering moet worden aangebracht om klanttevredenheid en loyaliteit te behouden. Als u verder gaat dan alleen numerieke statistieken, kunt u deze inzichten krijgen.
3. Analyseer recensies van klantenforums en websites
Een andere uitstekende manier om diverse klantfeedbackgegevens te verkrijgen, is door productbeoordelingswebsites zoals GoogleMyBusiness en forums zoals Reddit te doorzoeken. Belangrijk is dat het verkrijgen van inzichten uit verschillende gegevensbronnen u betere inzichten kan geven vanwege het type publiek dat door verschillende platforms wordt uitgenodigd.
Reddit wordt bijvoorbeeld vooral gebruikt door klanten die meer gepassioneerd zijn over een onderwerp of product, omdat ze op het forum uitgebreide discussies kunnen voeren. Terwijl Amazon-recensies of Google-recensies meestal worden gebruikt door informele klanten die graag een recensie willen achterlaten, hetzij op aandringen van het bedrijf, hetzij vanwege de goede of slechte ervaring die ze hebben gehad.
Deze ML-gestuurde technische inzichten ontleend aan beoordelingen op Disney World in Florida afgeleid van opmerkingen van klanten op Reddit en Google illustreren dit punt verder.
4. Voice of customer (VoC) data uit niet-traditionele bronnen
Niet-traditionele bronnen van klantfeedbackgegevens zoals geschiedenis van chatbots, e-mails van klanten, transcripties van klantenondersteuning, enzovoort, zijn uitstekende bronnen om inzichten in klantervaringen op te doen. Een voordeel van deze bronnen is dat al deze gegevens al beschikbaar zijn in uw Customer Relationship Management (CRM)-tools.
Wanneer u deze gegevens kunt verzamelen en analyseren, kunt u veel onderliggende problemen ontdekken die zelfs met goed geplande klantonderzoeken of het luisteren naar sociale media mogelijk niet naar voren kunnen komen.
5. Analyseer nieuws en podcasts
Nieuwsgegevens die uit zowel artikelen als nieuwsvideo's en podcasts bestaan, kunnen u gedetailleerde inzichten geven in merkprestaties en -perceptie. Marktfeedback van nieuwsbronnen kan een bedrijf helpen bij effectieve public relations (PR)-activiteiten voor merkreputatiebeheer.
Het kan ook helpen bij concurrentieanalyses op basis van branchetrends die een sentimentanalysemodel kan extraheren uit merkervaringsgegevens in nieuwsartikelen of video's, en kan hen helpen het gedrag van consumenten te begrijpen.
Om te illustreren hoe sentiment wordt geëxtraheerd en scores worden berekend, laten we nieuwsbronnen nemen als de essentiële bron van klantfeedback en kijken hoe een ML-model dergelijke gegevens zal analyseren.
1. Verzamelen van de gegevens
Om de meest nauwkeurige resultaten te krijgen, moeten we alle openbaar beschikbare nieuwsbronnen gebruiken. Denk hierbij aan nieuws van televisiezenders, online magazines en andere publicaties, radio-uitzendingen, podcasts, video's etc.
Er zijn twee manieren waarop dit kan worden gedaan. We uploaden de gegevens rechtstreeks via Live News API's zoals Google News API, ESPN Headlines-API, BBC News-API, en anderen zoals zij. Of we uploaden ze handmatig naar het ML-model dat we gebruiken door de opmerkingen en artikelen in een .csv-bestand te downloaden.
2. Gegevens verwerken met ML-taken
Het model verwerkt nu de gegevens en identificeert de verschillende formaten: tekst, video of audio. In het geval van tekst is het proces vrij eenvoudig. Het model extraheert alle tekst inclusief emoticons en hashtags. In het geval van podcasts, radio-uitzendingen en video's is audiotranscriptie via spraak-naar-tekstsoftware vereist. Ook deze gegevens worden vervolgens naar de tekstanalysepijplijn gestuurd.
Eenmaal in de pijplijn zorgen natuurlijke taalverwerking (NLP), benoemde entiteitsherkenning (NER), semantische classificatie, enz. ervoor dat belangrijke aspecten, thema's en onderwerpen uit de gegevens worden geëxtraheerd en gegroepeerd, zodat ze kunnen worden geanalyseerd op sentiment.
3. Sentiment analyseren
Nu de tekst is gescheiden, wordt elk thema, aspect en entiteit geanalyseerd op sentiment en wordt de sentimentscore berekend. Dit kan op drie manieren worden gedaan: de methode voor het tellen van woorden, de methode voor de lengte van zinnen en de verhouding tussen positieve en negatieve woorden.
Laten we deze zin als voorbeeld nemen. “Stadionbezoekers merkten op dat de stoelen goed waren. Volgens de Daily Herald leken de kaartjes echter te duur, gezien het feit dat er geen seizoenspassen beschikbaar waren en velen zelfs onbeschoft personeel aan de kassa tegenkwamen.”
Laten we aannemen dat daarna tokenization, tekstnormalisatie (verwijderen van niet-tekstuele gegevens), woordstammen (het stamwoord vinden) en stopwoordverwijdering (verwijderen van overtollige woorden), krijgen we de volgende scores voor negatief en positief sentiment.
Positief – Goed – 1(+ 0.07)
Negatief - duur (- 0.5), onbeleefd (- 0.7) - 2
Laten we nu de sentimentscores berekenen met behulp van de drie bovengenoemde methoden.
Methode voor het tellen van woorden
Dit is de eenvoudigste manier waarop de sentimentscore kan worden berekend. Bij deze methode verminderen we de negatieve van de positieve gebeurtenissen (1 – 2 = -1)
De sentimentscore van het bovenstaande voorbeeld is dus -1.
Zin-lengte methode
Het aantal positieve woorden wordt afgetrokken van de negatieve woorden. Het resultaat wordt vervolgens gedeeld door het totale aantal woorden in de tekst. Omdat de aldus verkregen score erg klein kan zijn en in veel decimalen kan volgen, wordt deze vaak vermenigvuldigd met een enkel cijfer. Dit wordt gedaan zodat de scores groter zijn en dus gemakkelijker te begrijpen en te vergelijken. In het geval van ons voorbeeld zal de score zijn.
1-2/42 = -0.0238095
Verhouding negatief-positief aantal woorden
Het totale aantal positieve woorden wordt gedeeld door het totale aantal negatieve woorden. Het resultaat wordt vervolgens met 1 opgeteld. Dit is evenwichtiger dan andere benaderingen, vooral in het geval van grote hoeveelheden gegevens.
1/2+1 = 0.33333
4. Visualisatie van inzichten
Zodra de gegevens zijn geanalyseerd op sentiment, worden de inzichten gepresenteerd op een visualisatiedashboard, zodat u de intelligentie kunt begrijpen die uit alle gegevens is verkregen. U kunt op tijdlijn gebaseerde sentimentanalyses bekijken, evenals die op basis van gebeurtenissen zoals productlanceringen, schommelingen op de aandelenmarkt, persberichten, bedrijfsverklaringen, nieuwe prijzen, enz.
Deze op aspecten gebaseerde inzichten kunnen van ongelooflijke waarde voor u zijn bij het plannen van uw marketing- en groeistrategieën.
AI en datawetenschap zijn van immens belang voor marketingactiviteiten, vooral in een tijdperk van constante innovatie en veranderende marktdynamiek. Analyse van het klantsentiment, aangestuurd door klantfeedbackgegevens die rechtstreeks van hen zijn gebruikt, kan u alle middelen geven die u nodig hebt om ervoor te zorgen dat u een duurzame marketingstrategie heeft voor voortdurende groei.
Martin Ostrovski is de oprichter en CEO van Repustate. Hij is gepassioneerd door AI, ML en NLP. Hij bepaalt de strategie, het stappenplan en de functiedefinitie voor Repustate's Global Text Analytics API, Sentiment Analysis, Deep Search en Named Entity Recognition-oplossingen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2022/12/collect-data-customer-sentiment-analysis.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-collect-data-for-customer-sentiment-analysis
- 1
- 7
- a
- in staat
- Over
- boven
- Volgens
- accuraat
- activiteiten
- toegevoegd
- toevoeging
- Voordeel
- Na
- agentschap
- AI
- Alles
- toestaat
- al
- Amazone
- hoeveelheden
- analyse
- analytics
- analyseren
- het analyseren van
- en
- Angst
- api
- APIs
- benaderingen
- artikelen
- verschijning
- aspecten
- geassocieerd
- gehoor
- audio
- Beschikbaar
- slecht
- gebaseerde
- omdat
- achter
- onder
- BEST
- Wedden
- Betere
- Verder
- groter
- Bill
- merk
- briljant
- breed
- bedrijfsdeskundigen
- ondernemingen
- Buying
- berekend
- Kan krijgen
- geval
- business casual outfit
- Beroemdheid
- mobiele telefoons
- ceo
- Ces
- veranderende
- kanalen
- keuzes
- classificatie
- verzamelen
- gecombineerde
- opmerkingen
- afstand
- Bedrijf
- vergelijken
- concurrent
- begrijpen
- constante
- consument
- content
- inhoud
- voortgezet
- contrast
- onder controle te houden
- gemak
- Kosten
- Counter
- CRM
- Actueel
- klant
- klantervaring
- Klanttevredenheid
- Klantenservice
- Klantenservice
- Klanten
- dagelijks
- dashboards
- gegevens
- data science
- beslissingen
- deep
- Afgeleid
- gedetailleerd
- DEED
- anders
- digitaal
- digitale marketing
- direct
- Onthul Nu
- discussies
- Disney
- diversen
- Verdeeld
- Nee
- gedreven
- dynamica
- elk
- gemakkelijker
- effectief
- inspanning
- beide
- elimineren
- e-mails
- emoties
- Endorsements
- geheel
- entiteit
- Tijdperk
- vooral
- essentieel
- etc
- schatten
- Zelfs
- EVENTS
- precies
- voorbeeld
- voorbeelden
- uitstekend
- ervaring
- extract
- extracten
- factoren
- tamelijk
- Vallen
- Kenmerk
- feedback
- Dien in
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- het vinden van
- geschikt
- vast
- Florida
- schommelingen
- volgen
- volgend
- Forbes
- Forum
- forums
- oprichter
- oppompen van
- verder
- Krijgen
- verzameling
- geografisch
- krijgen
- het krijgen van
- Geven
- gegeven
- geeft
- oogopslag
- Globaal
- Go
- Goes
- gaan
- goed
- Kopen Google Reviews
- groot
- Helft
- gelukkig
- met
- Headlines
- hulp
- hier
- Markeer
- Verhuring
- Hoe
- How To
- Echter
- HTML
- HTTPS
- identificeert
- identificeren
- belang
- belangrijk
- verbetering
- in
- omvat
- Inclusief
- ongelooflijk
- -industrie
- invloed
- influencers
- Innovatie
- inzicht
- inzichten
- op instagram
- Intelligentie
- aandachtig
- interactie
- investering
- uitnodigt
- problemen
- IT
- journalistiek
- sleutel
- blijven
- bekend
- taal
- Groot
- lanceert
- leren
- Verlof
- Hefboomwerking
- Het luisteren
- leven
- plaats
- op zoek
- Loyaliteit
- machine
- machine learning
- gemaakt
- tijdschriften
- onderhouden
- maken
- management
- handmatig
- veel
- Markt
- Marketing
- Media
- vermeldt
- methode
- methoden
- Metriek
- macht
- Mijnbouw
- ML
- model
- meer
- meest
- motivaties
- vermenigvuldigd
- Genoemd
- Naturel
- Natural Language Processing
- NATUUR
- Noodzaak
- negatief
- netto
- Neutraal
- New
- nieuws
- nlp
- aantal
- EEN
- online.
- Advies
- Opties
- bestellen
- Overige
- Overig
- parameters
- deel
- passes
- hartstochtelijk
- patronen
- Mensen
- perceptie
- prestatie
- telefoons
- pijpleiding
- plaatsen
- plan
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- podcasts
- punt
- positief
- pr
- gepresenteerd
- pers
- Persberichten
- prijs
- prijsstelling
- Prime
- processen
- verwerking
- Product
- Product-reviews
- professioneel
- publiek
- publicaties
- inkomsten
- kwaliteit
- kwantitatief
- Radio
- waardering
- waarderingen
- verhouding
- lezing
- vast
- realiseren
- redenen
- erkenning
- verminderen
- spijt
- betrekkingen
- verwantschap
- Releases
- betrouwbaar
- verwijdering
- het verwijderen van
- reputatie
- vereisen
- antwoord
- resultaat
- Resultaten
- beoordelen
- Recensies
- roadmap
- wortel
- dezelfde
- tevredenheid
- Wetenschap
- Ontdek
- Seizoen
- gesegregeerde
- zin
- sentiment
- service
- Sets
- VERSCHUIVEN
- tonen
- Eenvoudig
- single
- Locaties
- Klein
- So
- Social
- social media
- sociale media beïnvloeders
- social media platforms
- Software
- Oplossingen
- bron
- bronnen
- specifiek
- spraak-naar-tekst
- Medewerkers
- Ster
- sterk
- verklaringen
- voorraad
- beurs
- stop
- strategieën
- Strategie
- onderwerpen
- dergelijk
- ondersteuning
- Enquête
- duurzaam
- Nemen
- doelgerichte
- taken
- Technisch
- Tieners
- televisie
- De
- thema
- drie
- Door
- ticket
- tickets
- tiktok
- tips
- naar
- ook
- tools
- tools
- onderwerpen
- Totaal
- Trends
- waar
- Trust
- X
- types
- die ten grondslag liggen
- begrijpen
- us
- Gebruik
- .
- gebruikers
- waarde
- Video
- Video's
- visualisatie
- vitaal
- Stem
- manieren
- websites
- Wat
- of
- welke
- en
- WIE
- wil
- binnen
- Woord
- woorden
- wereld
- zou
- schrijven
- Your
- zephyrnet