
20 september 2023
Fundamentele modellen (FM's) markeren het begin van een nieuw tijdperk in machinaal leren (ML) en kunstmatige intelligentie (AI), wat leidt tot een snellere ontwikkeling van AI die kan worden aangepast aan een breed scala aan downstream-taken en kan worden verfijnd voor een scala aan toepassingen.
Nu het steeds belangrijker wordt om gegevens te verwerken op de plek waar er wordt gewerkt, maakt het bedienen van AI-modellen aan de rand van de onderneming vrijwel realtime voorspellingen mogelijk, terwijl tegelijkertijd wordt voldaan aan de eisen op het gebied van gegevenssoevereiniteit en privacy. Door het combineren van de IBM watsonx data- en AI-platformmogelijkheden voor FM's met edge computing kunnen bedrijven AI-workloads uitvoeren voor FM-finetuning en -inferentie aan de operationele edge. Hierdoor kunnen ondernemingen AI-implementaties aan de edge schalen, waardoor de implementatietijd en -kosten worden verkort en de responstijden sneller zijn.
Zorg ervoor dat je alle afleveringen in deze reeks blogposts over edge computing bekijkt:
Wat zijn fundamentele modellen?
Fundamentele modellen (FM's), die op grote schaal worden getraind op een brede reeks ongelabelde gegevens, zijn de drijvende kracht achter de modernste toepassingen van kunstmatige intelligentie (AI). Ze kunnen worden aangepast aan een breed scala aan downstream-taken en worden afgestemd op een scala aan toepassingen. Moderne AI-modellen, die specifieke taken in één domein uitvoeren, maken plaats voor FM’s omdat ze algemener leren en over domeinen en problemen heen werken. Zoals de naam al doet vermoeden, kan een FM de basis vormen voor veel toepassingen van het AI-model.
FM’s pakken twee belangrijke uitdagingen aan die bedrijven ervan weerhouden de adoptie van AI op te schalen. Ten eerste produceren bedrijven een enorme hoeveelheid ongelabelde gegevens, waarvan slechts een fractie is gelabeld voor AI-modeltraining. Ten tweede is deze label- en annotatietaak uiterst mensintensief en vergt vaak enkele honderden uren van de tijd van een vakdeskundige. Dit maakt het onbetaalbaar om over verschillende gebruiksscenario’s heen te schalen, omdat hiervoor legers van MKB-bedrijven en data-experts nodig zijn. Door enorme hoeveelheden ongelabelde gegevens te verwerken en zelfbeheerde technieken te gebruiken voor modeltraining, hebben FM's deze knelpunten weggenomen en de weg vrijgemaakt voor grootschalige adoptie van AI binnen de hele onderneming. Deze enorme hoeveelheden gegevens die in elk bedrijf aanwezig zijn, wachten erop om te worden vrijgegeven om inzichten te genereren.
Wat zijn grote taalmodellen?
Grote taalmodellen (LLM's) zijn een klasse fundamentele modellen (FM) die bestaan uit lagen van neurale netwerken die zijn getraind op deze enorme hoeveelheden ongelabelde gegevens. Ze gebruiken zelfgestuurde leeralgoritmen om verschillende taken uit te voeren natuurlijke taalverwerking (NLP) taken uitvoeren op manieren die vergelijkbaar zijn met de manier waarop mensen taal gebruiken (zie figuur 1).
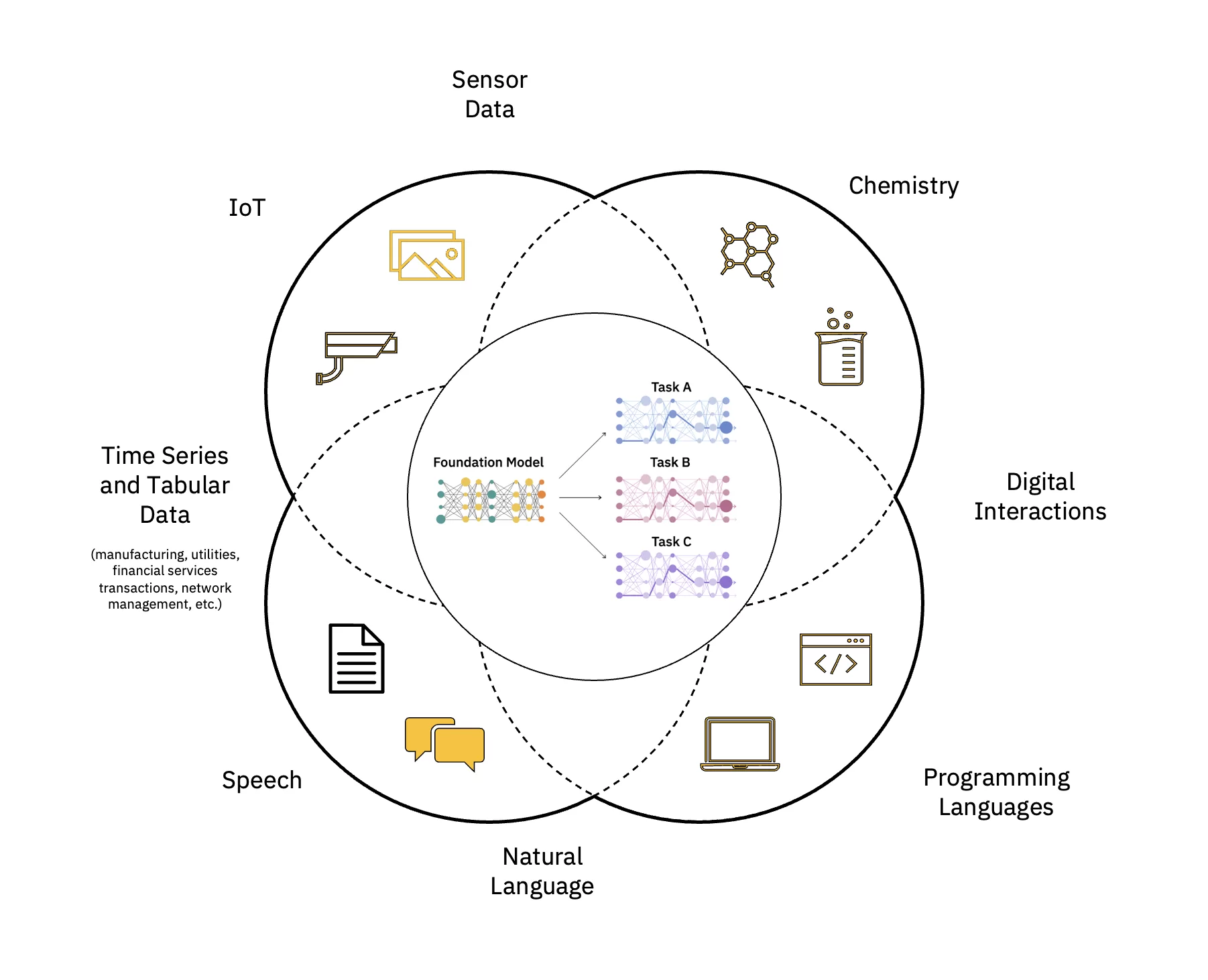
Schaal en versnel de impact van AI
Er zijn verschillende stappen voor het bouwen en implementeren van een fundamenteel model (FM). Deze omvatten data-inname, dataselectie, datavoorverwerking, FM-pre-training, modelafstemming op een of meer downstream-taken, inferentieservice, en data- en AI-modelbeheer en levenscyclusbeheer – die allemaal kunnen worden omschreven als FMOps.
Om bij dit alles te helpen, biedt IBM bedrijven de nodige tools en mogelijkheden om de kracht van deze FM's te benutten IBM watsonx, een bedrijfsklaar AI- en dataplatform dat is ontworpen om de impact van AI in een onderneming te vergroten. IBM Watsonx bestaat uit het volgende:
- IBM watsonx.ai brengt nieuw generatieve AI mogelijkheden – mogelijk gemaakt door FM's en traditionele machine learning (ML) – in een krachtige studio die de AI-levenscyclus bestrijkt.
- IBM watsonx.data is een geschikte dataopslag gebouwd op een open lakehouse-architectuur om de AI-workloads voor al uw gegevens, waar dan ook, te schalen.
- IBM watsonx.governance is een end-to-end geautomatiseerde AI-levenscyclusbeheertoolkit die is gebouwd om verantwoorde, transparante en verklaarbare AI-workflows mogelijk te maken.
Een andere belangrijke vector is het toenemende belang van computergebruik aan de rand van de onderneming, zoals industriële locaties, productievloeren, winkels, telecom-randlocaties, enz. Meer specifiek maakt AI aan de rand van de onderneming de verwerking van gegevens mogelijk waar werk voor wordt uitgevoerd. bijna realtime analyse. De enterprise edge is waar enorme hoeveelheden bedrijfsgegevens worden gegenereerd en waar AI waardevolle, actuele en bruikbare zakelijke inzichten kan bieden.
Het bedienen van AI-modellen aan de edge maakt vrijwel realtime voorspellingen mogelijk, terwijl wordt voldaan aan de eisen op het gebied van datasoevereiniteit en privacy. Dit vermindert aanzienlijk de latentie die vaak gepaard gaat met het verwerven, verzenden, transformeren en verwerken van inspectiegegevens. Door aan de edge te werken, kunnen we gevoelige bedrijfsgegevens beschermen en de kosten voor gegevensoverdracht verlagen met snellere responstijden.
Het opschalen van AI-implementaties aan de edge is echter geen gemakkelijke taak te midden van uitdagingen die verband houden met data (heterogeniteit, volume en regelgeving) en beperkte middelen (compute, netwerkconnectiviteit, opslag en zelfs IT-vaardigheden). Deze kunnen grofweg in twee categorieën worden beschreven:
- Tijd/kosten om te implementeren: Elke implementatie bestaat uit verschillende lagen hardware en software die voorafgaand aan de implementatie moeten worden geïnstalleerd, geconfigureerd en getest. Tegenwoordig kan een serviceprofessional wel een week of twee nodig hebben voor de installatie op elke locatie, Dit beperkt ernstig hoe snel en kosteneffectief ondernemingen implementaties binnen hun organisatie kunnen opschalen.
- Beheer van dag 2: Het enorme aantal geïmplementeerde randen en de geografische locatie van elke implementatie kunnen het vaak onbetaalbaar maken om op elke locatie lokale IT-ondersteuning te bieden om deze implementaties te monitoren, te onderhouden en bij te werken.
Edge AI-implementaties
IBM heeft een edge-architectuur ontwikkeld die deze uitdagingen aanpakt door een geïntegreerd hardware/software (HW/SW)-apparaatmodel naar edge-AI-implementaties te brengen. Het bestaat uit verschillende sleutelparadigma’s die de schaalbaarheid van AI-implementaties ondersteunen:
- Op beleid gebaseerde, zero-touch provisioning van de volledige softwarestack.
- Continue monitoring van de gezondheid van het edge-systeem
- Mogelijkheden om software-/beveiligings-/configuratie-updates te beheren en naar talloze edge-locaties te pushen, allemaal vanuit een centrale cloudgebaseerde locatie voor dagelijks beheer.
Een gedistribueerde hub-and-spoke-architectuur kan worden gebruikt om AI-implementaties van ondernemingen aan de rand te schalen, waarbij een centrale cloud of een bedrijfsdatacenter als hub fungeert en het edge-in-a-box-apparaat als spaak op een edge-locatie fungeert.. Dit hub-and-spoke-model, dat zich uitstrekt over hybride cloud- en edge-omgevingen, illustreert het beste de balans die nodig is om de middelen die nodig zijn voor FM-activiteiten optimaal te benutten (zie figuur 2).
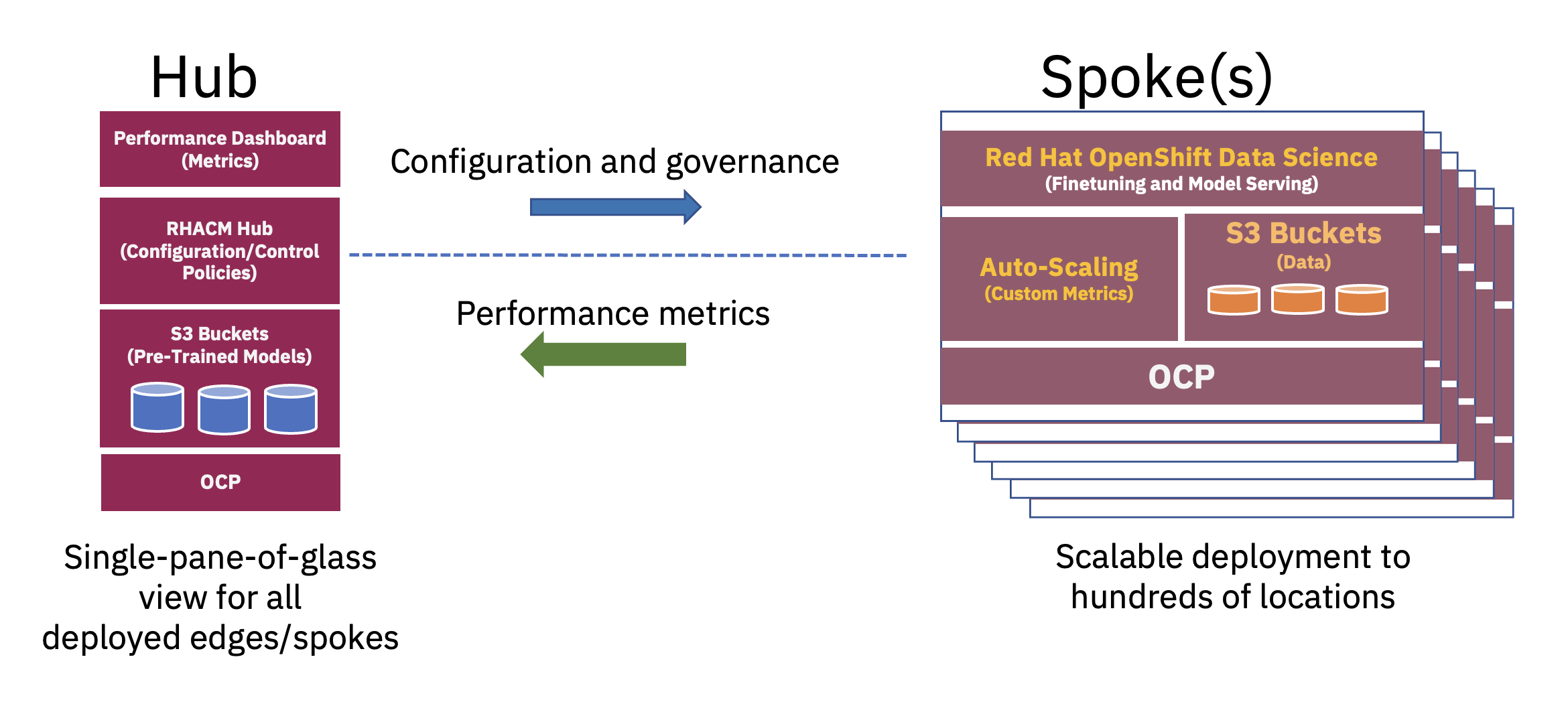
Voortraining van deze basismodellen voor grote talen (LLM's) en andere soorten basismodellen met behulp van zelfbeheerde technieken op enorme ongelabelde datasets vereist vaak aanzienlijke rekenbronnen (GPU) en kan het beste worden uitgevoerd op een hub. De vrijwel onbeperkte computerbronnen en grote datastapels die vaak in de cloud worden opgeslagen, maken het vooraf trainen van grote parametermodellen en voortdurende verbetering van de nauwkeurigheid van deze basismodellen mogelijk.
Aan de andere kant kan het afstemmen van deze basis-FM's op downstream-taken (waarvoor slechts enkele tientallen of honderden gelabelde datamonsters en het leveren van gevolgtrekkingen nodig zijn) worden bereikt met slechts een paar GPU's aan de rand van de onderneming. Hierdoor kunnen gevoelige gelabelde gegevens (of bedrijfskroonjuweelgegevens) veilig binnen de operationele omgeving van de onderneming blijven, terwijl ook de kosten voor gegevensoverdracht worden verlaagd.
Met behulp van een full-stack-aanpak voor het implementeren van applicaties naar de edge, kan een datawetenschapper de modellen verfijnen, testen en implementeren. Dit kan in één enkele omgeving worden bereikt, terwijl de ontwikkelingslevenscyclus voor het aanbieden van nieuwe AI-modellen aan de eindgebruikers wordt verkort. Platforms zoals Red Hat OpenShift Data Science (RHODS) en de onlangs aangekondigde Red Hat OpenShift AI bieden tools om snel productieklare AI-modellen te ontwikkelen en in te zetten. gedistribueerde cloud en edge-omgevingen.
Ten slotte vermindert het bedienen van het verfijnde AI-model aan de rand van de onderneming aanzienlijk de latentie die vaak gepaard gaat met het verwerven, verzenden, transformeren en verwerken van gegevens. Door de pre-training in de cloud te ontkoppelen van fijnafstemming en inferentie aan de edge, worden de totale operationele kosten verlaagd door de benodigde tijd en de kosten voor gegevensverplaatsing die gepaard gaan met een inferentietaak te verminderen (zie figuur 3).
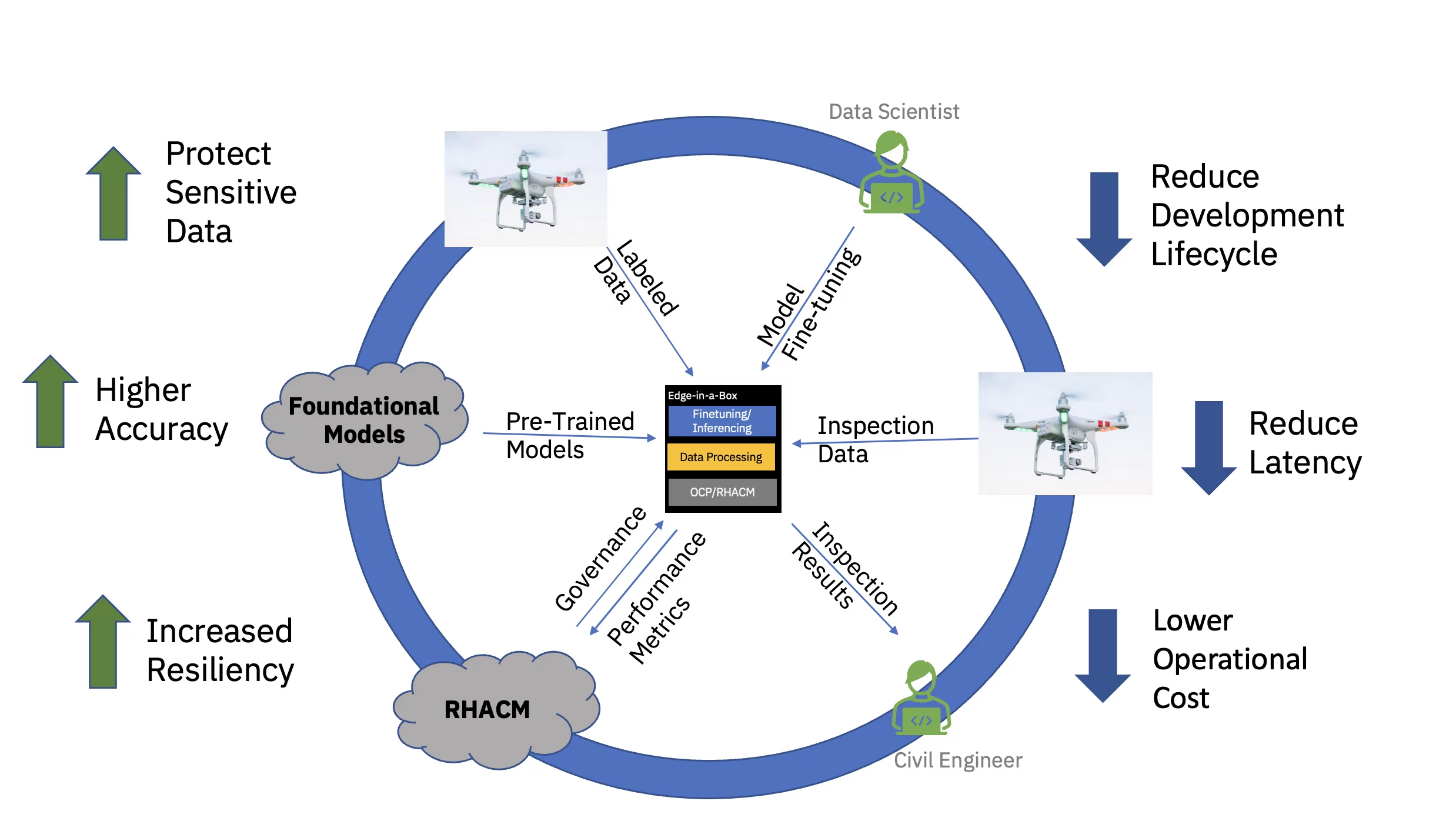
Om deze waardepropositie end-to-end te demonstreren, werd een voorbeeldig, op vision-transformatoren gebaseerd funderingsmodel voor civiele infrastructuur (vooraf getraind met behulp van openbare en op maat gemaakte branchespecifieke datasets) verfijnd en ingezet voor gevolgtrekking op een rand met drie knooppunten (spaak)cluster. De softwarestack omvatte het Red Hat OpenShift Container Platform en Red Hat OpenShift Data Science. Dit edge-cluster was ook verbonden met een exemplaar van de Red Hat Advanced Cluster Management for Kubernetes (RHACM)-hub die in de cloud draaide.
Zero-touch-voorziening
Op beleid gebaseerde, zero-touch provisioning werd uitgevoerd met Red Hat Advanced Cluster Management for Kubernetes (RHACM) via beleid en plaatsingstags, die specifieke edge-clusters binden aan een reeks softwarecomponenten en configuraties. Deze softwarecomponenten – die zich over de volledige stack uitstrekken en rekenkracht, opslag, netwerk en de AI-werklast omvatten – werden geïnstalleerd met behulp van verschillende OpenShift-operators, het leveren van de vereiste applicatieservices en S3 Bucket (opslag).
Het vooraf getrainde fundamentele model (FM) voor civiele infrastructuur werd verfijnd via een Jupyter Notebook binnen Red Hat OpenShift Data Science (RHODS) met behulp van gelabelde gegevens om zes soorten defecten op betonnen bruggen te classificeren. De inferentiebediening van deze verfijnde FM werd ook gedemonstreerd met behulp van een Triton-server. Bovendien werd monitoring van de gezondheid van dit edge-systeem mogelijk gemaakt door observatiestatistieken van de hardware- en softwarecomponenten via Prometheus te aggregeren naar het centrale RHACM-dashboard in de cloud. Bedrijven in de civiele infrastructuur kunnen deze FM's op hun edge-locaties inzetten en drone-beelden gebruiken om defecten bijna in realtime te detecteren, waardoor de tijd tot inzicht wordt versneld en de kosten voor het verplaatsen van grote hoeveelheden high-definition gegevens van en naar de cloud worden verlaagd.
Samengevat
De combinatie van IBM watsonx data- en AI-platformmogelijkheden voor funderingsmodellen (FM's) met een edge-in-a-box-apparaat stellen bedrijven in staat AI-workloads uit te voeren voor FM-verfijning en -inferentie aan de operationele rand. Dit apparaat kan complexe gebruiksscenario's out-of-the-box aan en bouwt het hub-and-spoke-framework voor gecentraliseerd beheer, automatisering en zelfbediening. Edge FM-implementaties kunnen worden teruggebracht van weken naar uren met herhaalbaar succes, hogere veerkracht en beveiliging.
Meer informatie over fundamentele modellen
Zorg ervoor dat je alle afleveringen in deze reeks blogposts over edge computing bekijkt:
Meer van Cloud




- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.ibm.com/blog/foundational-models-at-the-edge/
- : heeft
- :is
- :niet
- :waar
- $UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Over
- versnellen
- toegang
- volbracht
- nauwkeurigheid
- acquisitie
- over
- Handelingen
- aangepast
- Daarnaast
- adres
- adressen
- Adoptie
- vergevorderd
- vooruitgang
- ADVERTISING
- AI
- AI goedkeuring
- AI-modellen
- AI-platform
- Steun
- algoritmen
- Alles
- toelaten
- toestaat
- ook
- Te midden van
- bedragen
- hoeveelheden
- amp
- an
- analyse
- analytics
- en
- aangekondigd
- elke
- overal
- Aanvraag
- toepassingen
- nadering
- architectuur
- ZIJN
- reeks
- dit artikel
- kunstmatig
- kunstmatige intelligentie
- Kunstmatige intelligentie (AI)
- AS
- geassocieerd
- At
- auteur
- geautomatiseerde
- Automatisering
- Beschikbaar
- Laan
- terug
- Balance
- Bank
- Banken
- baseren
- BE
- omdat
- worden
- worden
- geweest
- Begin
- wezen
- geloofd wie en wat je bent
- BEST
- binden
- Blog
- Blog Posts
- blogs
- zowel
- Box camera's
- bruggen
- Bringing
- Brengt
- breed
- breed
- Gebouw
- bouwt
- bebouwd
- bedrijfsdeskundigen
- by
- CAN
- mogelijkheden
- hoofdstad
- Het vastleggen
- carbon
- kaart
- Kaarten
- gevallen
- KAT
- categorieën
- Veroorzaken
- Centreren
- centraal
- Centrale bank
- centrale bank digitale valuta
- gecentraliseerde
- keten
- uitdagingen
- verandering
- veranderende
- controle
- keuzes
- cirkels
- CIS
- burgerlijk
- klasse
- classificeren
- duidelijk
- klanten
- van nabij
- Cloud
- TROS
- kleur
- kleurrijk
- combineren
- concurrerend
- complex
- ingewikkeldheid
- nakoming
- componenten
- Berekenen
- computergebruik
- Configuratie
- geconfigureerd
- gekoppeld blijven
- Connectiviteit
- bestaat uit
- Containers
- voortzetten
- onder controle te houden
- Kosten
- Kosten
- kon
- aan het bedekken
- cryptogeld
- CSS
- valuta's
- gewoonte
- klant
- klantervaring
- Klanten
- dashboards
- gegevens
- Data Center
- Gegevensplatform
- data science
- data scientist
- datasets
- Datum
- toegewijd aan
- Standaard
- definities
- leveren
- tonen
- gedemonstreerd
- implementeren
- ingezet
- het inzetten
- inzet
- implementaties
- beschreven
- beschrijving
- ontworpen
- ontwikkelen
- ontwikkelde
- Ontwikkeling
- digitaal
- digitale valuta's
- digitalisering
- Ontwrichting
- verstorend
- Verstoorders
- verdeeld
- wijk
- domein
- domeinen
- gedaan
- rit
- aandrijving
- dar
- elk
- En het is heel gemakkelijk
- ecosysteem
- rand
- edge computing
- ELEVATE
- verhoogd
- in staat stellen
- maakt
- einde
- eind tot eind
- ingenieur
- Engineering
- Enter
- Enterprise
- bedrijven
- inkomend
- Milieu
- omgevingen
- Tijdperk
- vooral
- etc
- Ether (ETH)
- Zelfs
- EVENTS
- Alle
- evolueerde
- Onderzoeken
- voorbeelden
- uitvoeren
- bestaan
- afrit
- duur
- ervaring
- deskundigen
- Uitleg over AI
- uitleggen
- verlenging
- uiterst
- factoren
- SNELLE
- sneller
- weinig
- veld-
- Figuur
- financieel
- Financiële instellingen
- financiering
- Voornaam*
- vloeren
- volgen
- volgend
- fonts
- Voor
- Voorhoede
- gevonden
- Foundation
- fractie
- Achtergrond
- oppompen van
- vol
- Volledige stapel
- Bovendien
- algemeen
- gegenereerde
- generator
- geografisch
- Geopolitiek
- Vrijgevigheid
- Globaal
- wereldhandel
- bestuur
- GPU
- GPU's
- Raster
- hand
- handvat
- Hardware
- hoed
- Hebben
- Gezondheid
- Hoogte
- hulp
- het helpen van
- helpt
- hoge kwaliteit
- hoger
- zeer
- geschiedenis
- gastheer
- HOURS
- Hoe
- How To
- Echter
- HTTPS
- Naaf
- Mensen
- Honderden
- Hybride
- hybride cloud
- IBM
- IBM Cloud
- ICO
- ICON
- illustreert
- beeld
- Impact
- belang
- verbetering
- in
- omvatten
- inclusief
- meer
- in toenemende mate
- index
- industrieel
- industrieën
- -industrie
- branchespecifiek
- inflatie
- Buiging
- Buigpunt
- beïnvloed
- Infrastructuur
- initiatief
- Innovatie
- innovatieve
- ingangen
- inzichten
- instantie
- instellingen
- geïntegreerde
- Intelligentie
- intrinsiek
- de invoering
- IT
- IT-ondersteuning
- Journeys
- jpg
- springen
- Jupyter Notebook
- voor slechts
- eentje maar
- gehouden
- sleutel
- Kubernetes
- etikettering
- taal
- Groot
- grotendeels
- Wachttijd
- laatste
- Legkippen
- leidend
- LEARN
- leren
- Hefboomwerking
- levenscyclus van uw product
- als
- grenzeloos
- linux
- lokaal
- lokaal
- plaats
- locaties
- lang
- Kijk
- machine
- machine learning
- gemaakt
- onderhouden
- maken
- MERKEN
- beheer
- management
- productie
- veel
- het merken
- massief
- meester
- Materie
- max-width
- mechanismen
- methoden
- Metriek
- Min
- minimaliseren
- minuten
- ML
- Mobile
- model
- modellen
- Modern
- modernisering
- moderniseren
- monitor
- Grensverkeer
- meer
- beweging
- bewegend
- naam
- Navigatie
- Nabij
- noodzakelijk
- Noodzaak
- nodig
- behoeften
- netwerk
- New
- volgende
- nlp
- notitieboekje
- niets
- nu
- aantal
- vele
- of
- het aanbieden van
- vaak
- on
- EEN
- Slechts
- open
- geopend
- operationele
- Operations
- exploitanten
- geoptimaliseerde
- or
- organisatie
- Overige
- onze
- uit
- totaal
- Paketten
- pagina
- parameter
- betaling
- Betaalmethoden
- betalingen
- uitvoeren
- uitgevoerd
- PHP
- plaatsing
- platform
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- inpluggen
- punt
- beleidsmaatregelen door te lezen.
- beleidsmaatregelen
- positie
- mogelijk
- Post
- Berichten
- potentieel
- energie
- krachtige
- Voorspellingen
- Voorafgaand
- privacy
- privaat
- problemen
- verwerking
- produceren
- professioneel
- voorstel
- zorgen voor
- publiek
- Duwen
- reeks
- snel
- lezing
- real-time
- onlangs
- record
- opname
- Rood
- Red Hat
- verminderen
- Gereduceerd
- vermindert
- vermindering
- reglement
- Regelgevers
- regelgevers
- verwant
- verwijderd
- herhaalbare
- vereisen
- nodig
- Voorwaarden
- vereiste
- onderzoek
- Resources
- antwoord
- verantwoordelijk
- responsive
- <HR>Retail
- Stijgen
- robots
- lopen
- lopend
- veilig
- dezelfde
- Schaalbaarheid
- Scale
- schaal ai
- scaling
- Wetenschap
- Wetenschapper
- scherm
- scripts
- Tweede
- vast
- veiligheid
- zien
- te zien
- selectie
- Zelfbediening
- gevoelig
- seo
- September
- -Series
- server
- service
- Diensten
- serveer-
- Sessie
- sessies
- reeks
- verscheidene
- Delen
- tonen
- aanzienlijke
- aanzienlijk
- gelijk
- sinds
- Singapore
- single
- enkele omgeving
- website
- Locaties
- ZES
- vaardigheden
- Klein
- EMS
- MKB
- Software
- software componenten
- oplossing
- soevereiniteit
- Tussenruimte
- overspannen
- specifiek
- specifiek
- Gesponsorde
- stack
- begin
- state-of-the-art
- blijven
- Stappen
- mediaopslag
- shop
- opgeslagen
- winkels
- Storm
- studio
- onderwerpen
- succes
- dergelijk
- Stelt voor
- leveren
- toeleveringsketen
- ondersteuning
- zeker
- system
- Nemen
- ingenomen
- Taak
- taken
- technieken
- Technologie
- Telecom
- Temenos
- tienen
- Terraform
- getest
- Testen
- dat
- De
- hun
- thema
- Er.
- Deze
- ze
- dit
- Door
- niet de tijd of
- actuele
- keer
- Titel
- naar
- vandaag
- samen
- toolkit
- tools
- top
- handel
- traditioneel
- Trainen
- getraind
- Trainingen
- overdracht
- Transformeren
- Transformatie
- transformaties
- transparant
- Triton
- X
- twee
- type dan:
- types
- ontketende
- bijwerken
- updates
- URL
- us
- .
- gebruikt
- gebruikers
- gebruik
- gebruik maken van
- gebruikt
- waardevol
- waarde
- waarde voorstel
- variëteit
- divers
- groot
- via
- Bekijk
- virtueel
- volume
- volumes
- W
- Het wachten
- Portemonnee
- was
- Wave
- Manier..
- manieren
- we
- week
- weken
- Wat
- Wat is
- wanneer
- welke
- en
- WIE
- Waarom
- breed
- Grote range
- Met
- binnen
- vrouw
- WordPress
- Mijn werk
- workflows
- werkzaam
- zou
- geschreven
- Your
- zephyrnet











