Inleiding tot tabelextractie
De hoeveelheid gegevens die wordt verzameld, neemt met de dag drastisch toe met een groeiend aantal applicaties, software en online platforms.
Om deze gigantische gegevens productief te kunnen verwerken/ontsluiten, is het noodzakelijk om waardevolle tools voor het extraheren van informatie te ontwikkelen.
Een van de deelgebieden die aandacht vraagt in het veld Informatie-extractie is het extraheren van tabellen uit afbeeldingen of het detecteren van tabelgegevens uit formulieren, PDF's en documenten.
Tabel Extractie is de taak van het detecteren en ontleden van tabelinformatie in een document.

Stel je voor dat je veel documenten hebt met tabelgegevens die je moet extraheren voor verdere verwerking. Conventioneel kunt u ze handmatig (op papier) kopiëren of in Excel-bladen laden.
Met tabel-OCR-software kunt u echter automatisch tabellen detecteren en alle tabelgegevens in één keer uit documenten extraheren. Dit scheelt veel tijd en nabewerking.
In dit artikel bekijken we eerst hoe Nanonets automatisch tabellen uit afbeeldingen of documenten kan extraheren. Vervolgens behandelen we enkele populaire DL-technieken om tabellen in documenten te detecteren en te extraheren.
Wilt u tabelgegevens extraheren uit facturen, kwitanties of een ander type document? Bekijk Nanonets' PDF-tabelextractor om tabelgegevens te extraheren. Plan een demo voor meer informatie over automatiseren tafel extractie.
Inhoudsopgave
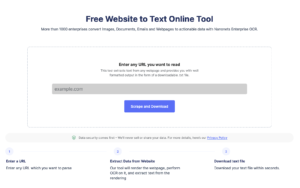
Tabel uit afbeelding extraheren met Nanonets Table OCR
-
Aanmelden voor een gratis Nanonets-account
- Upload afbeeldingen/bestanden naar Nanonets Table OCR-model
- Nanonets detecteert en extraheert automatisch alle tabelgegevens
- Bewerk en bekijk de gegevens (indien nodig)
- Exporteer de verwerkte data als Excel, csv of JSON
Willen gegevens uit PDF schrapen documenten, converteer PDF-tabel naar Excel or tafelextractie automatiseren? Ontdek hoe Nanonetten PDF-schraper or PDF-parser kan uw bedrijf productiever maken.
Nanonets Tabel OCR API

De Nanonets OCR-API kunt u eenvoudig OCR-modellen bouwen. U hoeft zich geen zorgen te maken over het voorverwerken van uw afbeeldingen of u hoeft zich geen zorgen te maken over het matchen van sjablonen of het bouwen van op regels gebaseerde engines om de nauwkeurigheid van uw OCR-model te vergroten.
U kunt uw gegevens uploaden, annoteren, het model instellen om te trainen en wachten op het krijgen van voorspellingen via een browsergebaseerde gebruikersinterface zonder een enkele regel code te schrijven, u zorgen te maken over GPU's of de juiste architecturen voor uw tabeldetectie te vinden met behulp van deep learning-modellen.
U kunt ook de JSON-reacties van elke voorspelling verkrijgen om deze te integreren met uw eigen systemen en door machine learning aangedreven apps te bouwen die zijn gebouwd op ultramoderne algoritmen en een sterke infrastructuur.
https://nanonets.com/documentation/
Heeft uw bedrijf te maken met data- of tekstherkenning in digitale documenten, pdf's of afbeeldingen? Heb je je afgevraagd hoe je tabelgegevens kunt extraheren, extraheer tekst uit afbeeldingen , extraheer gegevens uit PDF or extraheer tekst uit PDF nauwkeurig en efficiënt?
Wie vindt tabelextractie nuttig
Zoals besproken in de vorige sectie, worden tabellen vaak gebruikt om gegevens in een schoon formaat weer te geven. We kunnen ze zo vaak zien op verschillende gebieden, van het organiseren van ons werk door gegevens in tabellen te structureren tot het opslaan van enorme activa van bedrijven. Er zijn veel organisaties die dagelijks met miljoenen tafels te maken hebben. Om dergelijke moeizame taken van alles handmatig doen te vergemakkelijken, moeten we onze toevlucht nemen tot snellere technieken. Laten we een paar use-cases bespreken waarbij: tabellen extraheren kan essentieel zijn:

Persoonlijke use-cases
De tafel extractie proces kan ook nuttig zijn voor kleine gevallen van persoonlijk gebruik. Soms leggen we documenten vast op de mobiele telefoon en kopiëren we ze later naar onze computers. In plaats van dit proces te gebruiken, kunnen we de documenten direct vastleggen en opslaan als bewerkbare formaten in onze aangepaste sjablonen. Hieronder staan een paar gebruiksscenario's over hoe we tafelextractie in onze persoonlijke routine kunnen inpassen:
Documenten naar telefoon scannen: We maken vaak afbeeldingen van belangrijke tabellen op de telefoon en slaan ze op, maar met de techniek voor het extraheren van tabellen kunnen we de afbeeldingen van de tabellen vastleggen en deze rechtstreeks in tabelvorm opslaan, hetzij in Excel- of Google-bladen. Hiermee hoeven we niet naar afbeeldingen te zoeken of de inhoud van de tabel naar nieuwe bestanden te kopiëren, maar kunnen we direct de geïmporteerde tabellen gebruiken en aan de geëxtraheerde informatie gaan werken.
Documenten naar HTML: Op webpagina's vinden we heel veel informatie die wordt gepresenteerd in tabellen. Ze helpen ons in vergelijking met de data en geven ons overzichtelijk snel een overzicht van de cijfers. Door het extractieproces van tabellen te gebruiken, kunnen we PDF-documenten of JPG / PNG-afbeeldingen scannen en de informatie rechtstreeks in een op maat gemaakt, zelf ontworpen tabelformaat laden. We kunnen verder scripts schrijven om extra tabellen toe te voegen op basis van de bestaande tabellen, en daarmee de informatie digitaliseren. Dit helpt ons bij het bewerken van de inhoud en versnelt het opslagproces.
Cases voor industrieel gebruik
Er zijn verschillende industrieën over de hele wereld die enorm draaien op papierwerk en documentatie, vooral in de bank- en verzekeringssector. Van het opslaan van klantgegevens tot het verzorgen van de behoeften van de klant, tabellen worden veel gebruikt. Deze informatie wordt weer als document (hard copy) doorgegeven aan verschillende vestigingen voor goedkeuringen, waarbij miscommunicatie soms kan leiden tot fouten bij het ophalen van informatie uit tabellen. In plaats daarvan maakt het gebruik van automatisering ons leven veel gemakkelijker. Zodra de eerste gegevens zijn vastgelegd en goedgekeurd, kunnen we die documenten direct in tabellen scannen en verder werken aan de gedigitaliseerde gegevens. Laat staan door het verminderen van tijdverbruik en storingen, we kunnen de klanten informeren over de tijd en locatie waar de informatie wordt verwerkt. Dit zorgt dus voor betrouwbaarheid van de gegevens en vereenvoudigt onze manier van opereren. Laten we nu eens kijken naar de andere mogelijke use-cases:
Kwaliteitscontrole: Kwaliteitscontrole is een van de kerndiensten die de topindustrieën bieden. Het gebeurt meestal in eigen huis en voor de stakeholders. Als onderdeel hiervan zijn er veel feedbackformulieren die van consumenten worden verzameld om feedback over de geleverde service te extraheren. In industriële sectoren gebruiken ze tabellen om dagelijkse checklists en aantekeningen te maken om te zien hoe de productielijnen werken. Al deze kunnen gemakkelijk op één plek worden gedocumenteerd door middel van tabelextractie.
Track van activa: In de verwerkende industrie gebruiken mensen hardgecodeerde tabellen om gefabriceerde entiteiten bij te houden, zoals staal, ijzer, plastic, enz. Elk gefabriceerd artikel is gelabeld met een uniek nummer waarin ze tabellen gebruiken om bij te houden welke artikelen elke dag worden vervaardigd en geleverd. Automatisering kan veel tijd en middelen helpen besparen in termen van misplaatsingen of inconsistente gegevens.
Zakelijk gebruik
Er zijn verschillende bedrijfstakken die draaien op Excel-sheets en offline formulieren. Maar op een bepaald moment is het moeilijk om door deze bladen en formulieren te zoeken. Als we deze tabellen handmatig invoeren, is dat tijdrovend en is de kans groot dat gegevens verkeerd worden ingevoerd. Daarom is het extraheren van tabellen een beter alternatief om zakelijke gebruiksscenario's op te lossen, zoals hieronder zijn er maar weinig.
Factuur Automatisering: Er zijn veel kleinschalige en grootschalige industrieën waarvan: facturen worden nog steeds in tabelvorm gegenereerd. Deze bieden geen goed beveiligde belastingaangiften. Om dergelijke hindernissen te overwinnen, kunnen we tabelextractie gebruiken om alles te converteren facturen in een bewerkbaar formaat en upgrade ze daardoor naar een nieuwere versie.
Formulierautomatisering: Online formulieren verstoren deze beproefde methode door bedrijven te helpen de informatie te verzamelen die ze nodig hebben en deze tegelijkertijd te verbinden met andere softwareplatforms die in hun workflow zijn ingebouwd. Naast het verminderen van de noodzaak voor handmatige gegevensinvoer (met geautomatiseerde gegevensinvoer) en vervolg-e-mails, kan tabelextractie de kosten van afdrukken, verzenden, opslaan, ordenen en vernietigen van de traditionele papieren alternatieven elimineren.
Heeft u een OCR-probleem in gedachten? Wil je digitaliseren facturen, pdf's of kentekenplaten? Ga naar Nanonetten en bouw gratis OCR-modellen!
Diep leren in actie
Deep learning maakt deel uit van de bredere familie van machine learning-methoden op basis van kunstmatige neurale netwerken.
Neuraal netwerk is een raamwerk dat de onderliggende relaties in de gegeven gegevens herkent via een proces dat de werking van het menselijk brein nabootst. Ze hebben verschillende kunstmatige lagen waar de gegevens doorheen gaan, waar ze leren over functies. Er zijn verschillende architecturen zoals Convolution NNs, Recurrent NNs, Autoencoders, Generative Adversarial NNs om verschillende soorten data te verwerken. Deze zijn complex maar geven hoge prestaties weer om problemen in realtime aan te pakken. Laten we nu eens kijken naar het onderzoek dat is uitgevoerd op het gebied van tabelextractie met behulp van neurale netwerken en laten we ze ook kort bespreken.
TafelNet
Inleiding: TableNet is een moderne deep learning-architectuur die werd voorgesteld door een team van TCS Research year in het jaar 2019. De belangrijkste motivatie was om informatie uit gescande tabellen te extraheren via mobiele telefoons of camera's.
Ze stelden een oplossing voor die een nauwkeurige detectie van het tabelgebied in een afbeelding omvat en vervolgens het detecteren en extraheren van informatie uit de rijen en kolommen van de gedetecteerde tabel.
Gegevensset: De gebruikte dataset was Marmot. Het heeft 2000 pagina's in pdf-formaat die zijn verzameld met de bijbehorende grondwaarheden. Dit geldt ook voor Chinese pagina's. Koppeling - http://www.icst.pku.edu.cn/cpdp/sjzy/index.htm
architectuur: De architectuur is gebaseerd op Long et al., een encoder-decodermodel voor semantische segmentatie. Hetzelfde encoder/decoder-netwerk wordt gebruikt als de FCN-architectuur voor tabelextractie. De afbeeldingen worden voorbewerkt en aangepast met behulp van de Tesseract OCR.
Het model wordt in twee fasen afgeleid door de input te onderwerpen aan deep learning-technieken. In de eerste fase hebben ze de gewichten van een voorgetraind VGG-19-netwerk gebruikt. Ze hebben de volledig verbonden lagen van het gebruikte VGG-netwerk vervangen door 1 × 1 Convolutionele lagen. Alle convolutionele lagen worden gevolgd door de ReLU-activering en een uitvallaag met waarschijnlijkheid 0.8. Ze noemen de tweede fase het gedecodeerde netwerk dat uit twee takken bestaat. Dit is volgens de intuïtie dat het kolomgebied een subset is van het tabelgebied. Aldus kan het enkele coderingsnetwerk de actieve gebieden met een grotere nauwkeurigheid filteren met behulp van functies van zowel tabel- als kolomgebieden. De output van het eerste netwerk wordt gedistribueerd naar de twee vestigingen. In de eerste tak worden twee convolutiebewerkingen toegepast en wordt de laatste feature map opgeschaald om te voldoen aan de originele beeldafmetingen. In de andere tak voor het detecteren van kolommen is er een extra convolutielaag met een ReLU-activeringsfunctie en een uitvallaag met dezelfde uitvalkans als eerder vermeld. De feature maps worden up-bemonsterd met behulp van fractioneel gestapelde convoluties na een (1 × 1) convolutielaag. Hieronder ziet u een afbeelding van de architectuur:

Uitgangen: Nadat de documenten met behulp van het model zijn verwerkt, worden de maskers van tabellen en kolommen gegenereerd. Deze maskers worden gebruikt om de tabel en de kolomgebieden uit de afbeelding te filteren. Met behulp van de Tesseract OCR wordt de informatie uit de gesegmenteerde regio's gehaald. Hieronder ziet u een afbeelding met de maskers die worden gegenereerd en later uit de tabellen worden gehaald:

Ze stelden ook hetzelfde model voor dat is verfijnd met ICDAR, dat beter presteerde dan het originele model. De Recall, Precision en F1-Score van het verfijnde model zijn respectievelijk 0.9628, 0.9697, 0.9662. Het oorspronkelijke model heeft de geregistreerde statistieken van 0.9621, 0.9547, 0.9583 in dezelfde volgorde. Laten we nu een duik nemen in nog een architectuur.
DiepDeSRT
Papier: DeepDeSRT: Deep Learning voor detectie en structuurherkenning van tabellen in documentafbeeldingen
Inleiding: DeepDeSRT is een neuraal netwerkraamwerk dat wordt gebruikt om de tabellen in de documenten of afbeeldingen te detecteren en te begrijpen. Het heeft twee oplossingen zoals vermeld in de titel:
- Het biedt een op diep leren gebaseerde oplossing voor tabeldetectie in documentafbeeldingen.
- Het stelt een nieuwe op deep learning gebaseerde benadering voor voor het herkennen van tabelstructuren, dwz het identificeren van rijen, kolommen en celposities in de gedetecteerde tabellen.
Het voorgestelde model is volledig op gegevens gebaseerd, het vereist geen heuristieken of metadata van de documenten of afbeeldingen. Een belangrijk voordeel met betrekking tot de training is dat ze geen gebruik maakten van grote trainingsdatasets, maar dat ze het concept van transfer learning en domeinaanpassing gebruikten voor zowel tabeldetectie als tabelstructuurherkenning.
Gegevensset: De gebruikte dataset is een ICDAR 2013-dataset voor tafelcompetities met 67 documenten met in totaal 238 pagina's.
architectuur:
- Tafeldetectie Het voorgestelde model gebruikte Fast RCNN als het basiskader voor het detecteren van de tabellen. De architectuur is opgesplitst in twee verschillende delen. In het eerste deel hebben ze regiovoorstellen gegenereerd op basis van het inputbeeld van een zogenaamd regiovoorstelnetwerk (RPN). In het tweede deel classificeerden ze de regio's met behulp van Fast-RCNN. Om deze architectuur te ondersteunen, gebruikten ze ZFNet en de gewichten van VGG-16.
- Structuurherkenning Nadat een tabel met succes is gedetecteerd en de locatie ervan bekend is bij het systeem, is de volgende uitdaging bij het begrijpen van de inhoud het herkennen en lokaliseren van de rijen en kolommen die de fysieke structuur van de tabel vormen. Daarom hebben ze een volledig verbonden netwerk gebruikt met de gewichten van VGG-16 dat informatie uit de rijen en kolommen haalt. Hieronder staan de resultaten van DeepDeSRT:
Uitgangen:


Uit evaluatieresultaten blijkt dat DeepDeSRT beter presteert dan state-of-the-art methoden voor tafeldetectie en structuurherkenning en tot 1 F96.77-metingen behaalt van 91.44% en 2015% voor tafeldetectie en structuurherkenning.
Grafiek neurale netwerken
Papier: Heroverweging van tabelherkenning met behulp van Graph Neural Networks
Inleiding: In dit onderzoek hebben de auteurs van Deep Learning Laboratory, National Center of Artificial Intelligence (NCAI) Graph Neural Networks voorgesteld voor het extraheren van informatie uit tabellen. Ze voerden aan dat grafieknetwerken een meer natuurlijke keuze zijn voor deze problemen en onderzochten twee op gradiënt gebaseerde neurale grafieknetwerken verder.
Dit voorgestelde model combineert de voordelen van beide convolutionele neurale netwerken voor het extraheren van visuele kenmerken en grafieknetwerken voor het omgaan met de probleemstructuur.
Gegevensset: De auteurs stelden een nieuwe grote synthetisch gegenereerde dataset voor van 0.5 miljoen tabellen verdeeld in vier categorieën.
- Afbeeldingen zijn eenvoudige afbeeldingen zonder samenvoeging en met linialen
- Afbeeldingen hebben verschillende soorten randen, inclusief het af en toe ontbreken van linialen
- Introduceert het samenvoegen van cellen en kolommen
- De camera legde beelden vast met de lineaire perspectieftransformatie
architectuur: Ze gebruikten een ondiep convolutioneel netwerk dat de respectieve convolutionele kenmerken genereert. Als de ruimtelijke afmetingen van de uitvoerfuncties niet hetzelfde zijn als het invoerbeeld, verzamelen ze posities die lineair worden verkleind, afhankelijk van de verhouding tussen de invoer- en uitvoerdimensies, en sturen ze deze naar een interactienetwerk dat twee grafische netwerken heeft die bekend staan als DGCNN. en GravNet. De parameters van het grafische netwerk zijn hetzelfde als het originele CNN. Uiteindelijk hebben ze een runtime-paarsteekproef gebruikt om de geëxtraheerde inhoud te classificeren die intern het op Monte Carlo gebaseerde algoritme gebruikte. Hieronder staan de outputs:
Uitgangen:

Hieronder vindt u de nauwkeurigheidsnummers in tabelvorm die worden gegenereerd door de netwerken voor vier categorieën van het netwerk zoals weergegeven in de dataset sectie:

CGAN's en genetische algoritmen
Inleiding: In dit onderzoek gebruikten de auteurs een top-down benadering in plaats van een bottom-up benadering (lijnen integreren in cellen, rijen of kolommen).
Bij deze methode, gebruikmakend van een generatief vijandig netwerk, brachten ze het tabelbeeld in kaart in een gestandaardiseerde 'skeletachtige' tafelvorm. Deze skelettabel geeft de geschatte rij- en kolomranden aan zonder de tabelinhoud. Vervolgens passen ze de renderings van kandidaat-latente tabelstructuren aan de skeletstructuur aan met behulp van een afstandsmeting die is geoptimaliseerd door een genetisch algoritme.
Gegevensset: De auteurs gebruikten hun eigen dataset met 4000 tabellen.
architectuur: Het voorgestelde model bestaat uit twee delen. In het eerste deel worden de invoerbeelden geabstraheerd in skelettabellen met behulp van een conditioneel generatief vijandelijk neuraal netwerk. Een GAN heeft weer twee netwerken, de generator die willekeurige samples genereert en een discriminator die vertelt of de gegenereerde afbeeldingen nep of origineel zijn. Generator G is een encoder-decodernetwerk waar een invoerbeeld door een reeks progressief downsampling-lagen wordt geleid tot een bottleneck-laag waar het proces wordt omgekeerd. Om voldoende informatie door te geven aan de decoderingslagen, wordt een U-Net-architectuur met skip-verbindingen gebruikt en wordt een skip-verbinding toegevoegd tussen lagen i en n - i via aaneenschakeling, waarbij n het totale aantal lagen is en i het laagnummer in de encoder. Voor de discriminator D wordt een PatchGAN-architectuur gebruikt. Dit benadeelt de outputbeeldstructuur op de schaal van patches. Deze produceren de uitvoer als een skelettafel.
In het tweede deel optimaliseren ze de aanpassing van de latente datastructuren van de kandidaat aan het gegenereerde skeletbeeld met behulp van een maat voor de afstand tussen elke kandidaat en het skelet. Dit is hoe de tekst in de afbeeldingen wordt geëxtraheerd. Hieronder ziet u een afbeelding van de architectuur:

uitgang: De geschatte tabelstructuren worden geëvalueerd door te vergelijken - Rij- en kolomnummer, positie linksboven, rijhoogtes en kolombreedtes
Het genetische algoritme gaf 95.5% nauwkeurigheid rijgewijs en 96.7% nauwkeurigheid kolomgewijs bij het extraheren van informatie uit de tabellen.

Noodzaak om documenten te digitaliseren, ontvangsten or facturen maar te lui om te coderen? Ga naar Nanonetten en bouw gratis OCR-modellen!
[Code] Traditionele benaderingen
In deze sectie leren we het proces van het extraheren van informatie uit tabellen met behulp van Deep Learning en OpenCV. Je kunt deze uitleg zien als een inleiding, maar het bouwen van state-of-the-art modellen zal veel ervaring en oefening vergen. Dit zal u helpen de basisprincipes te begrijpen van hoe we computers kunnen trainen met verschillende mogelijke benaderingen en algoritmen.
Om het probleem nauwkeuriger te begrijpen, definiëren we enkele basistermen die in het hele artikel zullen worden gebruikt:
- Tekst: bevat een string en vijf attributen (boven, links, breedte, hoogte, lettertype)
- Lijn: bevat tekstobjecten waarvan wordt aangenomen dat ze in het originele bestand op dezelfde regel staan
- Enkele lijn: line-object met slechts één tekstobject.
- Meerdere regels: line-object met meer dan één tekstobject.
- Meerdere regels Blok: een reeks doorlopende objecten met meerdere regels.
- Rij: Horizontale blokken in de tafel
- Kolom: Verticale blokken in de tafel
- Cel: het snijpunt van een rij en kolom
- Cel - Opvulling: de interne opvulling of ruimte in de cel.
Tafeldetectie met OpenCV
We gebruiken traditionele computer vision-technieken om informatie uit de gescande tabellen te halen. Hier is onze pijplijn; we vangen de gegevens in eerste instantie op (de tabellen waaruit we de informatie moeten extraheren) met behulp van normale camera's en vervolgens met behulp van computervisie proberen we de randen, randen en cellen te vinden. We gebruiken verschillende filters en contouren, en we zullen de kernkenmerken van de tabellen benadrukken.
We hebben een afbeelding van een tafel nodig. We kunnen dit op een telefoon vastleggen of een bestaande afbeelding gebruiken. Hieronder staat het codefragment,
file = r’table.png’
table_image_contour = cv2.imread(file, 0)
table_image = cv2.imread(file)
Hier hebben we dezelfde afbeelding afbeelding twee variabelen geladen omdat we de tabel_afbeelding_contour bij het tekenen van onze gedetecteerde contouren op de geladen afbeelding. Hieronder ziet u de afbeelding van de tabel die we in ons programma gebruiken:

We zullen een techniek gebruiken genaamd Drempelwaarde voor omgekeerde afbeelding die de gegevens in de gegeven afbeelding verbetert.
ret, thresh_value = cv2.threshold( table_image_contour, 180, 255, cv2.THRESH_BINARY_INV)
Een andere belangrijke voorbewerkingsstap is afbeelding dilatatie. Dilatatie is een eenvoudige wiskundige bewerking die wordt toegepast op binaire afbeeldingen (zwart en wit) die geleidelijk de grenzen van gebieden van voorgrondpixels vergroot (dat wil zeggen witte pixels, meestal).
kernel = np.ones((5,5),np.uint8)
dilated_value = cv2.dilate(thresh_value,kernel,iterations = 1)
In OpenCV gebruiken we de methode, vindContouren om de contouren in de huidige afbeelding te verkrijgen. Deze methode heeft drie argumenten, de eerste is de gedilateerde afbeelding (de afbeelding die wordt gebruikt om de gedilateerde afbeelding te genereren is table_image_contour - de methode findContours ondersteunt alleen binaire afbeeldingen), de tweede is de cv2.RETR_TREE die ons vertelt om de modus voor het ophalen van contouren te gebruiken, de derde is de cv2.CHAIN_APPROX_SIMPLE dat is de modus voor contourbenadering. De vindContouren pakt twee waarden uit, daarom voegen we nog een variabele toe met de naam hiërarchie. Wanneer de beelden zijn genest, stralen contouren onderlinge afhankelijkheid uit. Om dergelijke relaties weer te geven, wordt hiërarchie gebruikt.
contours, hierarchy = cv2.findContours( dilated_value, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
De contouren geven aan waar de gegevens precies in de afbeelding aanwezig zijn. Nu herhalen we de contourenlijst die we in de vorige stap hebben berekend en berekenen de coördinaten van de rechthoekige vakken zoals waargenomen in de originele afbeelding met behulp van de methode, cv2.boundingRect. In de laatste iteratie hebben we die vakken op de originele afbeelding table_image geplaatst met behulp van de methode, cv2.rechthoek ().
for cnt in contours: x, y, w, h = cv2.boundingRect(cnt) # bounding the images if y < 50: table_image = cv2.rectangle(table_image, (x, y), (x + w, y + h), (0, 0, 255), 1) Dit is onze laatste stap. Hier gebruiken we de methode genoemdVenster om onze tabel weer te geven met de geëxtraheerde inhoud en contouren erin ingebed. Hieronder staat het codefragment:
plt.imshow(table_image)
plt.show()
cv2.namedWindow('detecttable', cv2.WINDOW_NORMAL)

Verander de waarde van y in 300 in het bovenstaande codefragment, dit wordt uw uitvoer:

Nadat u de tabellen hebt geëxtraheerd, kunt u elke contouruitsnede uitvoeren via de tesseract OCR-engine, waarvan u de tutorial kunt vinden hier. Zodra we kaders van elke tekst hebben, kunnen we ze clusteren op basis van hun x- en y-coördinaten om af te leiden tot welke corresponderende rij en kolom ze behoren.
Daarnaast is er de mogelijkheid om PDFMiner te gebruiken om uw pdf-documenten om te zetten in HTML-bestanden die we kunnen ontleden met behulp van reguliere expressies om uiteindelijk onze tabellen te krijgen. Hier is hoe je het kunt doen.
PDFMiner en Regex parseren
Om informatie uit kleinere documenten te extraheren, kost het tijd om deep learning-modellen te configureren of computervisie-algoritmen te schrijven. In plaats daarvan kunnen we reguliere expressies in Python gebruiken om extraheer tekst uit de PDF-documenten. Onthoud ook dat deze techniek niet werkt voor afbeeldingen. We kunnen dit alleen gebruiken om informatie uit HTML-bestanden of PDF-documenten te extraheren. Dit komt omdat, wanneer u een reguliere expressie gebruikt, u de inhoud moet matchen met de bron en informatie moet extraheren. Met afbeeldingen kun je de tekst niet matchen en zullen de reguliere expressies mislukken. Laten we nu met een eenvoudig PDF-document werken en informatie uit de tabellen daarin halen. Hieronder de afbeelding:

In de eerste stap laden we de pdf in ons programma. Zodra dat is gebeurd, converteren we de PDF naar HTML zodat we direct reguliere expressies kunnen gebruiken en daardoor inhoud uit de tabellen kunnen extraheren. Hiervoor gebruiken we de module pdfmijnwerker. Dit helpt om inhoud uit PDF te lezen en om te zetten in een HTML-bestand.
Hieronder staat het codefragment:
from pdfminer.pdfinterp import PDFResourceManager from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.converter import HTMLConverter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from cStringIO import StringIO
import re def convert_pdf_to_html(path): rsrcmgr = PDFResourceManager() retstr = StringIO() codec = 'utf-8' laparams = LAParams() device = HTMLConverter(rsrcmgr, retstr, codec=codec, laparams=laparams) fp = file(path, 'rb') interpreter = PDFPageInterpreter(rsrcmgr, device) password = "" maxpages = 0 #is for all caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages,password=password,caching=caching, check_extractable=True): interpreter.process_page(page) fp.close() device.close() str = retstr.getvalue() retstr.close() return str
Codetegoeden: zevros
We hebben veel modules geïmporteerd, waaronder reguliere expressie en PDF-gerelateerde bibliotheken. In de methode converteer_pdf_naar_html, we sturen het pad van het pdf-bestand dat naar een html-bestand moet worden geconverteerd. De uitvoer van de methode is een HTML-string, zoals hieronder wordt weergegeven:
'<span style="font-family: XZVLBD+GaramondPremrPro-LtDisp; font-size:12px">Changing Echoesn<br>7632 Pool Station Roadn<br>Angels Camp, CA 95222n<br>(209) 785-3667n<br>Intake: (800) 633-7066n<br>SA </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> TX DT BU </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> RS RL OP PH </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> CO CJ n<br></span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> SF PI </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> AH SPn<br></span></div>' Reguliere expressie is een van de lastigste en coolste programmeertechnieken die worden gebruikt voor het matchen van patronen. Deze worden veel gebruikt in verschillende toepassingen, bijvoorbeeld voor het formatteren van code, webscraping en validatiedoeleinden. Laten we, voordat we beginnen met het extraheren van inhoud uit onze HTML-tabellen, snel een paar dingen leren over reguliere expressies.
Deze bibliotheek biedt verschillende ingebouwde methoden om patronen te matchen en te zoeken. Hieronder staan er een paar:
import re # Match the pattern in the string
re.match(pattern, string) # Search for a pattern in a string
re.search(pattern, string) # Finds all the pattern in a string
re.findall(pattern, string) # Splits string based on the occurrence of pattern
re.split(pattern, string, [maxsplit=0] # Search for the pattern and replace it with the given string
re.sub(pattern, replace, string)
Tekens / uitdrukkingen die u gewoonlijk in reguliere uitdrukkingen ziet, zijn onder meer:
- [AZ] - elke hoofdletter
- d - cijfer
- w - woordteken (letters, cijfers en onderstrepingstekens)
- s - witruimte (spaties, tabs en witruimte)
Om een bepaald patroon in HTML te ontdekken, gebruiken we reguliere expressies en schrijven we vervolgens patronen dienovereenkomstig. We splitsen de gegevens eerst zodanig dat de adresblokken worden gescheiden in afzonderlijke blokken in overeenstemming met de programmanaam (ANGELS CAMP, APPLE VALLEY, enz.):
pattern = '(?<=<span style="font-family: XZVLBD+GaramondPremrPro-LtDisp; font-size:12px">)(.*?)(?=<br></span></div>)' for programinfo in re.finditer(pattern, biginputstring, re.DOTALL): do looping stuff…
Later vinden we de programmanaam, stad, staat en postcode die altijd hetzelfde patroon volgen (tekst, komma, tweecijferige hoofdletters, 5 cijfers (of 5 cijfers, koppelteken, vier cijfers) - deze zijn aanwezig in het PDF-bestand dat we beschouwden als input). Controleer het volgende codefragment:
# To identify the program name
programname = re.search('^(?!<br>).*(?=\n)', programinfo.group(0))
# since some programs have odd characters in the name we need to escape
programname = re.escape(programname) citystatezip =re.search('(?<=>)([a-zA-Zs]+, [a-zA-Zs]{2} d{5,10})(?=\n)', programinfo.group(0))
mainphone =re.search('(?<=<br>)(d{3}) d{3}-d{4}x{0,1}d{0,}(?=\n)', programinfo.group(0))
altphones = re.findall('(?<=<br>)[a-zA-Zs]+: (d{3}) d{3}-d{4}x{0,1}d{0,}(?=\n)(?=\n)', programinfo.group(0)) Dit is een eenvoudig voorbeeld waarin wordt uitgelegd hoe we informatie uit PDF-bestanden extraheren met behulp van een reguliere expressie. Nadat we alle vereiste informatie hebben geëxtraheerd, laden we deze gegevens in een CSV-bestand.
def createDirectory(instring, outpath, split_program_pattern): i = 1 with open(outpath, 'wb') as csvfile: filewriter = csv.writer(csvfile, delimiter=',' , quotechar='"', quoting=csv.QUOTE_MINIMAL) # write the header row filewriter.writerow(['programname', 'address', 'addressxtra1', 'addressxtra2', 'city', 'state', 'zip', 'phone', 'altphone', 'codes']) # cycle through the programs for programinfo in re.finditer(split_program_pattern, instring, re.DOTALL): print i i=i+1 # pull out the pieces programname = getresult(re.search('^(?!<br>).*(?=\n)', programinfo.group(0))) programname = re.escape(programname) # some facilities have odd characters in the name
Dit is dus een eenvoudig voorbeeld waarin wordt uitgelegd hoe u uw geëxtraheerde HTML naar een CSV-bestand kunt pushen. Eerst maken we een CSV-bestand, zoeken al onze attributen en pushen ze één voor één in hun respectievelijke kolommen. Hieronder ziet u een screenshot:

Soms lijken de hierboven besproken technieken gecompliceerd en vormen ze uitdagingen voor de programmeurs, als de tabellen toch genest en complex zijn. Hier bespaart het kiezen van een CV of Deep Learning-model veel tijd. Laten we eens kijken welke nadelen en uitdagingen het gebruik van deze traditionele methoden belemmeren.
Uitdagingen met traditionele methoden
In deze sectie zullen we diepgaand leren over waar de tabelextractieprocessen zouden kunnen mislukken, en zullen we de manieren begrijpen om deze obstakels te overwinnen met behulp van moderne methoden die voortkomen uit Deep Learning. Dit proces is echter geen cakewalk. De reden hiervoor is dat tabellen meestal niet overal constant blijven. Ze hebben verschillende structuren om de gegevens weer te geven, en de gegevens in tabellen kunnen meertalig zijn met verschillende opmaakstijlen (tekenstijl, kleur, tekengrootte en hoogte). Om een robuust model te bouwen, moet men zich daarom bewust zijn van al deze uitdagingen. Gewoonlijk omvat dit proces drie stappen: tabeldetectie, extractie en conversie. Laten we de problemen in alle fasen een voor een identificeren:
Tafeldetectie
In deze fase identificeren we waar de tabellen precies aanwezig zijn in de gegeven invoer. De invoer kan van elk formaat zijn, zoals afbeeldingen, PDF / Word-documenten en soms video's. We gebruiken verschillende technieken en algoritmen om de tabellen te detecteren, hetzij door lijnen of door coördinaten. In sommige gevallen kunnen we tabellen zonder randen tegenkomen, waarbij we voor verschillende methoden moeten kiezen. Naast deze zijn hier nog een paar andere uitdagingen:
- Beeldtransformatie: Beeldtransformatie is een primaire stap bij het detecteren van labels. Dit omvat het verbeteren van de gegevens en randen in de tabel. We moeten de juiste voorbewerkingsalgoritmen kiezen op basis van de gegevens in de tabel. Als we bijvoorbeeld met afbeeldingen werken, moeten we drempels en randdetectoren toepassen. Deze transformatiestap helpt ons om de inhoud nauwkeuriger te vinden. In sommige gevallen kunnen de contouren fout gaan en slagen de algoritmen er niet in om het beeld te verbeteren. Daarom is het van cruciaal belang om de juiste stappen voor beeldtransformatie en voorbewerking te kiezen.
- Beeldkwaliteit: Wanneer we tabellen scannen voor informatie-extractie, moeten we ervoor zorgen dat deze documenten in helderdere omgevingen worden gescand, wat zorgt voor afbeeldingen van goede kwaliteit. Als de lichtomstandigheden slecht zijn, kunnen CV- en DL-algoritmen de tabellen in de opgegeven ingangen mogelijk niet detecteren. Als we deep learning gebruiken, moeten we ervoor zorgen dat de dataset consistent is en een goede set standaardafbeeldingen bevat. Als we deze modellen gebruiken op tafels in oud verfrommeld papier, dan moeten we eerst de ruis in die afbeeldingen voorbewerken en elimineren.
- Verscheidenheid aan structurele lay-outs en sjablonen: Alle tafels zijn niet uniek. Een cel kan zich uitstrekken over meerdere cellen, zowel verticaal als horizontaal, en combinaties van overspannende cellen kunnen een groot aantal structurele variaties creëren. Sommige benadrukken ook kenmerken van tekst, en tabellijnen kunnen van invloed zijn op de manier waarop de structuur van de tabel wordt begrepen. Horizontale lijnen of vetgedrukte tekst kunnen bijvoorbeeld meerdere kopteksten van de tabel benadrukken. De structuur van de tabel definieert visueel de relaties tussen cellen. Visuele relaties in tabellen maken het moeilijk om de gerelateerde cellen computationeel te vinden en er informatie uit te halen. Daarom is het belangrijk om algoritmen te bouwen die robuust zijn in het omgaan met verschillende structuren van tabellen.
- Celopvulling, marges, randen: Dit zijn de essentie van elke tafel: vullingen, marges en randen zullen niet altijd hetzelfde zijn. Sommige tafels hebben veel opvulling in de cellen, en andere niet. Het gebruik van afbeeldingen van goede kwaliteit en voorbewerkingsstappen zal het tabelextractieproces soepel laten verlopen.
Tabel Extractie
Dit is de fase waarin de informatie wordt geëxtraheerd nadat de tabellen zijn geïdentificeerd. Er zijn veel factoren met betrekking tot hoe de inhoud is gestructureerd en welke inhoud in de tabel aanwezig is. Daarom is het belangrijk om alle uitdagingen te begrijpen voordat men een algoritme bouwt.
- Dichte inhoud: De inhoud van de cellen kan numeriek of tekstueel zijn. De tekstuele inhoud is echter meestal compact en bevat dubbelzinnige korte stukjes tekst met het gebruik van acroniemen en afkortingen. Om tabellen te begrijpen, moet de tekst ondubbelzinnig zijn en moeten afkortingen en acroniemen worden uitgebreid.
- Verschillende lettertypen en formaten: Lettertypen hebben meestal verschillende stijlen, kleuren en hoogtes. We moeten ervoor zorgen dat deze generiek en gemakkelijk te identificeren zijn. Er zijn maar weinig lettertypefamilies, vooral degene die onder cursief of handgeschreven vallen, zijn een beetje moeilijk te extraheren. Daarom helpt het gebruik van een goed lettertype en de juiste opmaak het algoritme om de informatie nauwkeuriger te identificeren.
- Meerdere pagina-pdf's en pagina-einden: De tekstregel in tabellen is gevoelig voor een vooraf gedefinieerde drempel. Ook met overspannende cellen over meerdere pagina's, wordt het moeilijk om de tabellen te identificeren. Op een pagina met meerdere tafels is het moeilijk om verschillende tabellen van elkaar te onderscheiden. Schaarse en onregelmatige tafels zijn moeilijk om mee te werken. Daarom moeten grafische regels en inhoudslay-out samen worden gebruikt als belangrijke bronnen voor het spotten van tabelregio's.
Tafelconversie
De laatste fase omvat het converteren van de geëxtraheerde informatie uit tabellen om ze te compileren als een bewerkbaar document, hetzij in Excel, hetzij met behulp van andere software. Laten we een paar uitdagingen leren kennen.
- Lay-outs instellen: Wanneer verschillende formaten tabellen worden geëxtraheerd uit gescande documenten, hebben we een goede tabelopmaak nodig om de inhoud naar binnen te drukken. Soms slaagt het algoritme er niet in om informatie uit de cellen te extraheren. Daarom is het ontwerpen van een goede lay-out ook even belangrijk.
- Verscheidenheid aan waardepresentatiepatronen: Waarden in cellen kunnen worden gepresenteerd met behulp van verschillende syntactische representatiepatronen. Beschouw de tekst in de tabel als 6 ± 2. Het algoritme kan die specifieke informatie mogelijk niet converteren. Daarom vereist het extraheren van numerieke waarden kennis van mogelijke presentatiepatronen.
- Vertegenwoordiging voor visualisatie: De meeste weergave-indelingen voor tabellen, zoals opmaaktalen waarin tabellen kunnen worden beschreven, zijn ontworpen voor visualisatie. Daarom is het een uitdaging om tabellen automatisch te verwerken.
Dit zijn de uitdagingen waarmee we worden geconfronteerd tijdens het extractieproces van de tafel met behulp van traditionele technieken. Laten we nu eens kijken hoe we deze kunnen overwinnen met behulp van Deep Learning. Er wordt veel onderzoek naar gedaan in verschillende sectoren.
Noodzaak om documenten, bonnen of . te digitaliseren facturen maar te lui om te coderen? Ga naar Nanonetten en bouw gratis OCR-modellen!
Samengevat
In dit artikel hebben we uitgebreid ingegaan op het extraheren van informatie uit tabellen. We hebben gezien hoe moderne technologieën zoals Deep Learning en Computer Vision alledaagse taken kunnen automatiseren door robuuste algoritmen te bouwen die nauwkeurige resultaten opleveren. In de eerste paragrafen hebben we geleerd over de rol van tabelextractie bij het vergemakkelijken van de taken van individuen, industrieën en bedrijfssectoren, en hebben we ook gebruiksscenario's bekeken die dieper ingaan op het extraheren van tabellen uit PDF's/HTML, formulierautomatisering, factuur Automatisering, enz. We hebben een algoritme gecodeerd met behulp van Computer Vision om de positie van informatie in de tabellen te vinden met behulp van drempel-, dilatatie- en contourdetectietechnieken. We hebben de uitdagingen besproken waarmee we te maken kunnen krijgen tijdens de tabeldetectie-, extractie- en conversieprocessen bij het gebruik van de conventionele technieken, en vermeld hoe deep learning ons kan helpen deze problemen op te lossen. Ten slotte hebben we enkele neurale netwerkarchitecturen beoordeeld en hun manieren begrepen om tabelextractie te bereiken op basis van de gegeven trainingsgegevens.
update:
Meer leesmateriaal toegevoegd over verschillende benaderingen in tabeldetectie en informatie-extractie met behulp van deep learning.
- &
- 2019
- 67
- Over
- Volgens
- dienovereenkomstig
- accuraat
- verwerven
- over
- actieve
- Extra
- adres
- Voordeel
- algoritme
- algoritmen
- Alles
- alternatief
- alternatieven
- altijd
- bedragen
- angels
- Apple
- toepassingen
- Solliciteer
- nadering
- apps
- architectuur
- argumenten
- Kunst
- dit artikel
- kunstmatig
- kunstmatige intelligentie
- Activa
- aandacht
- attributen
- auteurs
- automatiseren
- Automatisering
- achtergrond
- Bankieren
- vaardigheden
- wezen
- onder
- betekent
- Beetje
- Zwart
- grens
- breaks
- browser
- bouw
- Gebouw
- bouwt
- bedrijfsdeskundigen
- ondernemingen
- Bellen
- camera's
- kandidaat
- hoofdstad
- vangen
- gevallen
- uitdagen
- uitdagingen
- uitdagend
- Chinese
- keuze
- Kies
- Plaats
- CNN
- code
- verzamelen
- Kolom
- combinaties
- Bedrijven
- concurrentie
- compleet
- complex
- computer
- computers
- concept
- gekoppeld blijven
- Wij verbinden
- versterken
- aansluitingen
- consequent
- Consumenten
- consumptie
- bevat
- content
- inhoud
- onder controle te houden
- Camper ombouw
- Kern
- Overeenkomend
- deksel
- en je merk te creëren
- credits
- gewas
- cruciaal
- gewoonte
- Klanten
- gegevens
- dag
- transactie
- omgang
- geleverd
- Afhankelijk
- beschreven
- ontworpen
- ontwerpen
- detail
- gegevens
- gedetecteerd
- Opsporing
- ontwikkelen
- apparaat
- DEED
- anders
- moeilijk
- digitaal
- digitaliseren
- cijfers
- direct
- bespreken
- afstand
- verdeeld
- documenten
- domein
- beneden
- nadelen
- tekening
- gedurende
- rand
- efficiënt
- elimineren
- ingebed
- eind tot eind
- Motor
- ingevoerd
- entiteiten
- vooral
- essentieel
- essentials
- geschat
- etc
- alles
- voorbeeld
- Excel
- bestaand
- uitgebreid
- ervaring
- uitdrukkingen
- extracten
- Gezicht
- factoren
- nep
- gezinnen
- familie
- SNELLE
- sneller
- Kenmerk
- Voordelen
- feedback
- filters
- Tot slot
- het vinden van
- vondsten
- Voornaam*
- First Look
- geschikt
- volgen
- volgend
- formulier
- formaat
- formulieren
- gevonden
- Achtergrond
- Gratis
- functie
- Fundamentals
- verder
- voortbrengen
- generatief
- generator
- het krijgen van
- goed
- Kopen Google Reviews
- Groeiend
- Behandeling
- hoofd
- Hoogte
- hulp
- nuttig
- het helpen van
- helpt
- hier
- hiërarchie
- Hoge
- Markeer
- Horizontaal
- Hoe
- How To
- Echter
- HTTPS
- reusachtig
- menselijk
- Horden
- identificeren
- het identificeren van
- beeld
- belangrijk
- omvatten
- omvat
- Inclusief
- Laat uw omzet
- meer
- individuen
- industrieel
- industrieën
- informatie
- Infrastructuur
- invoer
- verzekering
- integreren
- Intelligentie
- wisselwerking
- kruispunt
- problemen
- IT
- kennis
- bekend
- labels
- Talen
- Groot
- lagen
- leiden
- LEARN
- geleerd
- leren
- Bibliotheek
- Lijn
- LINK
- Lijst
- laden
- plaats
- lang
- machine
- machine learning
- MERKEN
- handboek
- handmatig
- productie
- kaart
- Maps
- Mark
- Maskers
- Match
- matching
- materiaal
- wiskunde
- maatregel
- vermeld
- methoden
- Metriek
- macht
- miljoen
- miljoenen
- denken
- Mobile
- mobiele telefoon
- mobieltjes
- model
- modellen
- Maand
- meer
- meest
- meervoudig
- nationaal
- Naturel
- noodzakelijk
- behoeften
- netwerk
- netwerken
- Geluid
- een
- Opmerkingen
- aantal
- nummers
- offline
- online.
- online platforms
- operatie
- Operations
- Optimaliseer
- geoptimaliseerde
- Keuze
- bestellen
- organisaties
- Georganiseerd
- organiserende
- Overige
- totaal
- het te bezitten.
- Papier
- deel
- bijzonder
- Wachtwoord
- Patches
- Patronen
- Mensen
- prestatie
- persoonlijk
- perspectief
- fase
- telefoons
- Fysiek
- plastic
- platforms
- punt
- zwembad
- arm
- Populair
- positie
- mogelijk
- energie
- praktijk
- Precies
- voorspelling
- Voorspellingen
- presenteren
- presentatie
- vorig
- primair
- probleem
- problemen
- processen
- verwerking
- produceren
- productie
- Programma
- Programmeurs
- Programming
- Programma's
- voorstel
- voorgestelde
- zorgen voor
- biedt
- doeleinden
- kwaliteit
- Quick
- snel
- RE
- lezing
- real-time
- herkennen
- erkent
- vermindering
- met betrekking tot
- regelmatig
- Relaties
- blijven
- vervangen
- vertegenwoordigen
- vertegenwoordiging
- vereisen
- nodig
- vereist
- onderzoek
- toevlucht
- Resultaten
- terugkeer
- beoordelen
- lopen
- Scale
- aftasten
- Ontdek
- Sectoren
- segmentatie
- -Series
- service
- Diensten
- reeks
- verscheidene
- Bermuda's
- getoond
- Eenvoudig
- sinds
- Maat
- Klein
- So
- Software
- solide
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- Tussenruimte
- ruimten
- spleet
- splits
- standaard
- begin
- Land
- state-of-the-art
- bepaald
- verklaringen
- station
- mediaopslag
- shop
- sterke
- gestructureerde
- stijl
- Hierop volgend
- Met goed gevolg
- steunen
- system
- Systems
- het nemen
- taken
- belasting
- team
- technieken
- Technologies
- vertelt
- templates
- De Bron
- daarom
- drempel
- Door
- overal
- niet de tijd of
- tijdrovend
- keer
- Titel
- samen
- tools
- top
- spoor
- traditioneel
- Trainingen
- overdracht
- Transformatie
- TX
- types
- typisch
- ui
- voor
- begrijpen
- begrip
- begrijpelijk
- unieke
- us
- .
- doorgaans
- bevestiging
- waarde
- divers
- versie
- Video's
- visie
- visualisatie
- W
- wachten
- web
- Wat
- en
- binnen
- zonder
- Mijn werk
- werkzaam
- het schrijven van
- X
- jaar
- youtube