Bij de post Introductie van de AWS ProServe Hadoop Migration Delivery Kit TCO-tool, introduceerden we de AWS ProServe Hadoop Migration Delivery Kit (HMDK) TCO-tool en de voordelen van het migreren van on-premise Hadoop-workloads naar Amazon EMR. In dit bericht duiken we diep in de tool en doorlopen we alle stappen van logopname, transformatie, visualisatie en architectuurontwerp om TCO te berekenen.
Overzicht oplossingen
Laten we kort ingaan op de belangrijkste functies van de HMDK TCO-tool. De tool biedt een YARN-logboekverzamelaar om verbinding te maken met Hadoop Resource Manager om YARN-logboeken te verzamelen. Een op Python gebaseerde Hadoop-werklastanalysator, de YARN-loganalysator genaamd, onderzoekt Hadoop-applicaties. Amazon QuickSight dashboards tonen de resultaten van de analysator. Dezelfde resultaten versnellen ook het ontwerp van toekomstige EMR-instanties. Bovendien genereert een TCO-calculator de TCO-schatting van een geoptimaliseerd EMR-cluster om de migratie te vergemakkelijken.
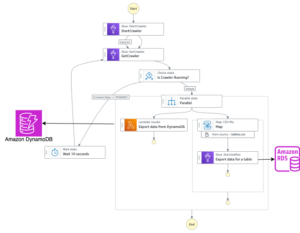
Laten we nu eens kijken hoe de tool werkt. Het volgende diagram illustreert de end-to-end workflow.

In de volgende paragrafen doorlopen we de vijf hoofdstappen van de tool:
- Verzamel YARN-taakgeschiedenislogboeken.
- Transformeer de taakgeschiedenislogboeken van JSON naar CSV.
- Analyseer de taakgeschiedenislogboeken.
- Ontwerp een EMR-cluster voor migratie.
- Bereken de TCO.
Voorwaarden
Voordat u aan de slag gaat, moet u ervoor zorgen dat u aan de volgende voorwaarden voldoet:
- Kloon het hadoop-migration-assessment-tco-repository.
- Installeer Python 3 op uw lokale computer.
- Heb een AWS-account met toestemming ingeschakeld AWS Lambda, QuickSight (Enterprise-editie), en AWS CloudFormatie.
Verzamel YARN-taakgeschiedenislogboeken
Eerst voer je een GAREN log verzamelaar, start-collector.sh, op uw lokale computer. Met deze stap worden Hadoop YARN-logboeken verzameld en op uw lokale computer geplaatst. Het script verbindt uw lokale computer met het Hadoop primaire knooppunt en communiceert met Resource Manager. Vervolgens haalt het de taakgeschiedenisinformatie op (YARN-logboeken van applicatiebeheerders) door de YARN ResourceManager-toepassings-API aan te roepen.
Voordat u de YARN-logboekverzamelaar uitvoert, moet u de verbinding configureren en tot stand brengen (HTTP: 8088 of HTTPS: 8090; de laatste wordt aanbevolen) om de toegankelijkheid van YARN ResourceManager en ingeschakelde YARN Timeline Server te verifiëren (Timeline Server v1 of later worden ondersteund ). Mogelijk moet u het verzamelinterval en bewaarbeleid van de YARN-logboeken definiëren. Om ervoor te zorgen dat u opeenvolgende YARN-logboeken verzamelt, kunt u een cron-taak gebruiken om de logboekverzamelaar in een geschikt tijdsinterval te plannen. Voor een Hadoop-cluster met 2,000 dagelijkse applicaties en de instelling garen.resourcemanager.max-completed-applications ingesteld op 1,000, moet u in theorie de logboekverzamelaar minstens twee keer uitvoeren om alle YARN-logboeken te krijgen. Daarnaast raden we aan om ten minste 7 dagen YARN-logboeken te verzamelen voor het analyseren van holistische workloads.
Raadpleeg voor meer informatie over het configureren en plannen van de logboekverzamelaar de garen-log-collector GitHub repo.
Transformeer de logboeken van de YARN-taakgeschiedenis van JSON naar CSV
Nadat u YARN-logboeken hebt verkregen, voert u een YARN-logorganizer uit, garen-log-organizer.py, een parser om op JSON gebaseerde logboeken om te zetten in CSV-bestanden. Deze CSV-uitvoerbestanden zijn de invoer voor de YARN-loganalysator. De parser heeft ook andere mogelijkheden, waaronder het sorteren van gebeurtenissen op tijd, het verwijderen van dedicates en het samenvoegen van meerdere logboeken.
Raadpleeg voor meer informatie over het gebruik van de YARN-logorganizer de garen-log-organizer GitHub repo.
Analyseer de logboeken van de YARN-taakgeschiedenis
Vervolgens start u de YARN-loganalyse om de YARN-logboeken in CSV-indeling te analyseren.
Met QuickSight kunt u YARN-loggegevens visualiseren en analyses uitvoeren op basis van de datasets die zijn gegenereerd door vooraf gebouwde dashboardsjablonen en een widget. De widget maakt automatisch QuickSight-dashboards in het doel-AWS-account, dat is geconfigureerd in een CloudFormation-sjabloon.
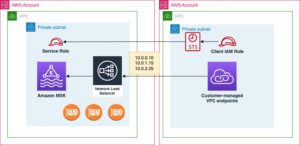
Het volgende diagram illustreert de HMDK TCO-architectuur.

De YARN-loganalysator biedt vier belangrijke functionaliteiten:
- Upload getransformeerde YARN-taakgeschiedenislogboeken in CSV-indeling (bijvoorbeeld
cluster_yarn_logs_*.csv) Om Amazon eenvoudige opslagservice (Amazon S3) emmers. Deze CSV-bestanden zijn de uitvoer van de YARN-logorganizer. - Maak een manifest JSON-bestand (bijvoorbeeld
yarn-log-manifest.json) voor QuickSight en upload het naar de S3-bucket: - Implementeer QuickSight-dashboards met behulp van een CloudFormation-sjabloon in YAML-indeling. Kies na het implementeren het pictogram Vernieuwen totdat u de status van de stapel ziet als
CREATE_COMPLETE. Deze stap maakt datasets op QuickSight-dashboards in uw AWS-doelaccount.
- Op het QuickSight-dashboard vindt u inzichten in de geanalyseerde Hadoop-workloads uit verschillende grafieken. Deze inzichten helpen u bij het ontwerpen van toekomstige EMR-instanties voor migratieversnelling, zoals in de volgende stap wordt gedemonstreerd.

Ontwerp een EMR-cluster voor migratie
De resultaten van de YARN-loganalyse helpen u inzicht te krijgen in de daadwerkelijke Hadoop-workloads op het bestaande systeem. Deze stap versnelt het ontwerpen van toekomstige EMR-instanties voor migratie door gebruik te maken van een Excel-sjabloon. De sjabloon bevat een checklist voor het uitvoeren van werklastanalyse en capaciteitsplanning:
- Worden de toepassingen die op het cluster worden uitgevoerd op de juiste manier gebruikt met hun huidige capaciteit?
- Wordt het cluster op een bepaald moment belast of niet? Zo ja, wanneer is de tijd?
- Welke typen toepassingen en engines (zoals MR, TEZ of Spark) worden op het cluster uitgevoerd en wat is het resourcegebruik voor elk type?
- Worden de uitvoeringscycli van verschillende taken (realtime, batch, ad hoc) in één cluster uitgevoerd?
- Worden er taken uitgevoerd in regelmatige batches, en zo ja, wat zijn deze planningsintervallen? (Bijvoorbeeld elke 10 minuten, 1 uur, 1 dag.) Heeft u banen die gedurende een lange periode veel middelen verbruiken?
- Zijn er banen die prestatieverbetering nodig hebben?
- Monopoliseren specifieke organisaties of individuen het cluster?
- Werken er gemengde ontwikkel- en beheertaken in één cluster?
Nadat u de checklist hebt voltooid, begrijpt u beter hoe u de toekomstige architectuur ontwerpt. Om de kosteneffectiviteit van het EMR-cluster te optimaliseren, geeft de volgende tabel algemene richtlijnen voor het kiezen van het juiste type EMR-cluster en Amazon Elastic Compute-cloud (Amazon EC2) familie.

Om het juiste clustertype en de juiste instantiefamilie te kiezen, moet u verschillende analyseronden uitvoeren tegen YARN-logboeken op basis van verschillende criteria. Laten we eens kijken naar enkele belangrijke statistieken.
Timeline
U kunt werklastpatronen vinden op basis van het aantal Hadoop-applicaties dat in een tijdvenster wordt uitgevoerd. De dag- of uurgrafieken 'Aantal records per starttijd' bieden bijvoorbeeld de volgende inzichten:
- In dagelijkse tijdreeksgrafieken vergelijkt u het aantal toepassingsruns tussen werkdagen en feestdagen, en tussen kalenderdagen. Als de cijfers vergelijkbaar zijn, betekent dit dat het dagelijkse gebruik van het cluster vergelijkbaar is. Als de afwijking daarentegen groot is, is het aandeel ad-hocfuncties aanzienlijk. U kunt ook de mogelijke wekelijkse of maandelijkse banen op bepaalde dagen uitzoeken. In de situatie zie je eenvoudig specifieke dagen in een week of een maand met een hoge werkdrukconcentratie.
- In tijdreeksgrafieken per uur begrijpt u verder hoe applicaties worden uitgevoerd in vensters per uur. U kunt piek- en daluren op een dag vinden.
Gebruikers
De YARN-logboeken bevatten de gebruikers-ID van elke toepassing. Deze informatie helpt u te begrijpen wie een aanvraag indient in een wachtrij. Op basis van de statistieken van individuele en geaggregeerde applicatieruns per wachtrij en per gebruiker, kunt u de bestaande werklastverdeling per gebruiker bepalen. Gewoonlijk hebben gebruikers van hetzelfde team gedeelde wachtrijen. Soms hebben meerdere teams gedeelde wachtrijen. Bij het ontwerpen van wachtrijen voor gebruikers beschikt u nu over inzichten die u helpen bij het ontwerpen en distribueren van toepassingsworkloads die evenwichtiger zijn verdeeld over wachtrijen dan voorheen.
Toepassingstypen
U kunt workloads segmenteren op basis van verschillende toepassingstypen (zoals Hive, Spark, Presto of HBase) en engines uitvoeren (zoals MR, Spark of Tez). Gebruik CPU-geoptimaliseerde instanties voor rekenintensieve workloads, zoals MapReduce- of Hive-on-MR-taken. Voor geheugenintensieve workloads zoals Hive-on-TEZ-, Presto- en Spark-taken gebruikt u voor geheugen geoptimaliseerde instanties.
Verstreken tijd
U kunt applicaties categoriseren op runtime. De ingesloten CloudFormation-sjabloon maakt automatisch een verstrekenGroup-veld aan in een QuickSight-dashboard. Dit maakt een belangrijke functie mogelijk waarmee u langlopende taken kunt observeren in een van de vier grafieken op QuickSight-dashboards. Daarom kunt u voor deze grote opdrachten op maat gemaakte toekomstige architecturen ontwerpen.
De bijbehorende QuickSight-dashboards bevatten vier grafieken. U kunt inzoomen op elk diagram dat aan één groep is gekoppeld.
| Groep Telefoon Nummer |
Runtime/verstreken tijd van een taak |
| 1 | Minder dan 10 minuten |
| 2 | Tussen 10 minuten en 30 minuten |
| 3 | tussen 30 minuten en 1 uur |
| 4 | Meer dan 1 uur |
In het diagram van groep 4 kunt u zich concentreren op het nauwkeurig onderzoeken van grote taken op basis van verschillende statistieken, waaronder gebruiker, wachtrij, toepassingstype, tijdlijn, resourcegebruik, enzovoort. Op basis van deze overweging hebt u mogelijk speciale wachtrijen op een cluster of een speciaal EMR-cluster voor grote taken. Ondertussen kunt u kleine opdrachten naar gedeelde wachtrijen sturen.
Resources
Op basis van verbruikspatronen (CPU, geheugen) kiest u de juiste grootte en familie van EC2-instanties voor prestaties en kosteneffectiviteit. Voor rekenintensieve toepassingen raden we exemplaren van CPU-geoptimaliseerde families aan. Voor geheugenintensieve toepassingen worden de voor geheugen geoptimaliseerde instantiefamilies aanbevolen.
Bovendien kunt u, op basis van de aard van de werklast van de applicatie en het gebruik van resources in de loop van de tijd, kiezen voor een permanent of tijdelijk EMR-cluster, Amazon EPD op EKSof Amazon EMR Serverloos.
Na het analyseren van YARN-logboeken op basis van verschillende statistieken, bent u klaar om toekomstige EMR-architecturen te ontwerpen. De volgende tabel bevat voorbeelden van voorgestelde EMR-clusters. Meer details vindt u in de geoptimaliseerde-tco-calculator GitHub repo.

Bereken TCO
Ten slotte voert u op uw lokale computer tco-input-generator.py uit om YARN-taakgeschiedenislogboeken op uurbasis samen te voegen voordat u een Excel-sjabloon gebruikt om de geoptimaliseerde TCO te berekenen. Deze stap is cruciaal omdat de resultaten de Hadoop-workloads simuleren in toekomstige EMR-instanties.
De voorwaarde voor TCO-simulatie is dat deze wordt uitgevoerd tco-input-generator.py, die elk uur geaggregeerde logboeken genereert. Vervolgens opent u een Excel-sjabloonbestand om macro's in te schakelen en voert u uw invoer in groene cellen in voor het berekenen van de TCO. Met betrekking tot de invoergegevens voert u de werkelijke gegevensgrootte in zonder replicatie en de hardwarespecificaties (vCore, mem) van het primaire Hadoop-knooppunt en de gegevensknooppunten. U moet ook eerder gegenereerde geaggregeerde logboeken per uur selecteren en uploaden. Nadat u de TCO-simulatievariabelen hebt ingesteld, zoals Regio, EC2-type, Amazon EMR hoge beschikbaarheid, engine-effect, Amazon EC2 en Amazon EBS-korting (EDP), Amazon S3-volumekorting, lokale valutakoers en EMR EC2-taak/kernprijsverhouding en prijs/uur, berekent de TCO-simulator automatisch de optimale kosten van toekomstige EMR-instanties op Amazon EC2. De volgende screenshots tonen een voorbeeld van HMDK TCO-resultaten.

Raadpleeg voor aanvullende informatie en instructies voor HMDK TCO-berekeningen de geoptimaliseerde-tco-calculator GitHub repo.
Opruimen
Nadat u alle stappen hebt voltooid en het testen hebt voltooid, voert u de volgende stappen uit om resources te verwijderen om kosten te voorkomen:
- Kies op de AWS CloudFormation-console de stapel die u hebt gemaakt.
- Kies Verwijder.
- Kies Stapel verwijderen.
- Vernieuw de pagina totdat u de status ziet
DELETE_COMPLETE. - Verwijder op de Amazon S3-console de S3-bucket die u hebt gemaakt.
Conclusie
De AWS ProServe HMDK TCO-tool vermindert aanzienlijk de inspanningen voor migratieplanning, de tijdrovende en uitdagende taken van het beoordelen van uw Hadoop-workloads. Met de HMDK TCO-tool duurt het assessment doorgaans 2-3 weken. U kunt ook de berekende TCO van toekomstige EMR-architecturen bepalen. Met de HMDK TCO-tool krijgt u snel inzicht in uw workloads en patronen in het gebruik van resources. Met de inzichten die door de tool worden gegenereerd, bent u uitgerust om optimale toekomstige EMR-architecturen te ontwerpen. In veel gebruikssituaties levert een TCO van 1 jaar van de geoptimaliseerde gerefactorde architectuur aanzienlijke kostenbesparingen op (64-80% reductie) op rekenkracht en opslag, in vergelijking met lift-and-shift Hadoop-migraties.
Voor meer informatie over het versnellen van uw Hadoop-migraties naar Amazon EMR en de HMDK CTO-tool, raadpleegt u de Hadoop Migration Delivery Kit TCO GitHub-opslagplaats, of neem contact op met AWS-HMDK@amazon.com.
Over de auteurs
 Sungyoul-park is Senior Practice Manager bij AWS ProServe. Hij helpt klanten hun bedrijf te innoveren met AWS Analytics-, IoT- en AI/ML-services. Hij is gespecialiseerd in big data-diensten en -technologieën en is geïnteresseerd in het samen bouwen aan bedrijfsresultaten voor klanten.
Sungyoul-park is Senior Practice Manager bij AWS ProServe. Hij helpt klanten hun bedrijf te innoveren met AWS Analytics-, IoT- en AI/ML-services. Hij is gespecialiseerd in big data-diensten en -technologieën en is geïnteresseerd in het samen bouwen aan bedrijfsresultaten voor klanten.
 Jiseong Kim is Senior Data Architect bij AWS ProServe. Hij werkt voornamelijk met zakelijke klanten om data lake-migratie en -modernisering te helpen, en biedt begeleiding en technische assistentie bij big data-projecten zoals Hadoop, Spark, datawarehousing, real-time dataverwerking en grootschalige machine learning. Hij begrijpt ook hoe hij technologieën moet toepassen om big data-problemen op te lossen en een goed ontworpen data-architectuur te bouwen.
Jiseong Kim is Senior Data Architect bij AWS ProServe. Hij werkt voornamelijk met zakelijke klanten om data lake-migratie en -modernisering te helpen, en biedt begeleiding en technische assistentie bij big data-projecten zoals Hadoop, Spark, datawarehousing, real-time dataverwerking en grootschalige machine learning. Hij begrijpt ook hoe hij technologieën moet toepassen om big data-problemen op te lossen en een goed ontworpen data-architectuur te bouwen.
 George Zhao is Senior Data Architect bij AWS ProServe. Hij is een ervaren analytisch leider die samenwerkt met AWS-klanten om moderne data-oplossingen te leveren. Hij is ook een ProServe Amazon EMR-domeinspecialist die ProServe-consultants adviseert over best practices en leveringskits voor Hadoop naar Amazon EMR-migraties. Zijn interessegebieden zijn datameren en de levering van moderne data-architectuur in de cloud.
George Zhao is Senior Data Architect bij AWS ProServe. Hij is een ervaren analytisch leider die samenwerkt met AWS-klanten om moderne data-oplossingen te leveren. Hij is ook een ProServe Amazon EMR-domeinspecialist die ProServe-consultants adviseert over best practices en leveringskits voor Hadoop naar Amazon EMR-migraties. Zijn interessegebieden zijn datameren en de levering van moderne data-architectuur in de cloud.
 Kalen Zhang was de Global Segment Tech Lead van Partner Data and Analytics bij AWS. Als vertrouwd adviseur op het gebied van data en analyse stelde ze strategische initiatieven voor datatransformatie samen, leidde data- en analysewerklastmigratie en moderniseringsprogramma's en versnelde klantmigratietrajecten met partners op schaal. Ze is gespecialiseerd in gedistribueerde systemen, enterprise data management, geavanceerde analyses en grootschalige strategische initiatieven.
Kalen Zhang was de Global Segment Tech Lead van Partner Data and Analytics bij AWS. Als vertrouwd adviseur op het gebied van data en analyse stelde ze strategische initiatieven voor datatransformatie samen, leidde data- en analysewerklastmigratie en moderniseringsprogramma's en versnelde klantmigratietrajecten met partners op schaal. Ze is gespecialiseerd in gedistribueerde systemen, enterprise data management, geavanceerde analyses en grootschalige strategische initiatieven.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- in staat
- Over
- versnellen
- versneld
- versnelt
- versnellen
- versnelling
- de toegankelijkheid
- Account
- over
- Ad
- toevoeging
- Extra
- Extra informatie
- Daarnaast
- vergevorderd
- adviseur
- Na
- tegen
- AI / ML
- Alles
- Amazone
- Amazon EC2
- Amazon EMR
- onder
- analyse
- analytics
- analyseren
- het analyseren van
- en
- api
- Aanvraag
- toepassingen
- Solliciteer
- op gepaste wijze
- architectuur
- GEBIED
- beoordeling
- Hulp
- geassocieerd
- webmaster.
- beschikbaarheid
- AWS
- AWS CloudFormatie
- gebaseerde
- basis
- omdat
- wezen
- betekent
- BEST
- 'best practices'
- Betere
- tussen
- Groot
- Big data
- kort
- bouw
- Gebouw
- bedrijfsdeskundigen
- berekenen
- berekend
- berekent
- het berekenen van
- Agenda
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- bellen
- mogelijkheden
- Inhoud
- gevallen
- Cellen
- zeker
- uitdagend
- tabel
- Grafieken
- Kies
- het kiezen van
- Cloud
- TROS
- verzamelen
- Het verzamelen van
- Collectie
- verzamelaar
- verzamelt
- COM
- vergelijkbaar
- vergelijken
- vergeleken
- compleet
- Berekenen
- concentreren
- concentratie
- Gedrag
- uitvoeren
- Verbinden
- versterken
- verbindt
- opeenvolgend
- overweging
- troosten
- consultants
- consumptie
- bevat
- Overeenkomend
- Kosten
- kostenbesparingen
- Kosten
- CPU
- aangemaakt
- creëert
- criteria
- cruciaal
- CTO
- curated
- Valuta
- Actueel
- klant
- Klanten
- cycli
- dagelijks
- dashboards
- gegevens
- Datameer
- gegevensbeheer
- gegevensverwerking
- datasets
- dag
- dagen
- toegewijd aan
- deep
- diepe duik
- leveren
- levering
- gedemonstreerd
- het inzetten
- Design
- ontwerpen
- gegevens
- Bepalen
- Ontwikkeling
- afwijking
- anders
- Korting
- verdelen
- verdeeld
- gedistribueerde systemen
- distributie
- domein
- beneden
- gedurende
- elk
- gemakkelijk
- ebs
- editie
- effect
- effectiviteit
- inspanningen
- ingebed
- in staat stellen
- ingeschakeld
- maakt
- eind tot eind
- Motor
- Motoren
- verzekeren
- Enter
- Enterprise
- zakelijke klanten
- uitgerust
- oprichten
- Ether (ETH)
- EVENTS
- Alle
- voorbeeld
- voorbeelden
- Excel
- bestaand
- ervaren
- faciliterende
- gezinnen
- familie
- Kenmerk
- Voordelen
- veld-
- Figuur
- Dien in
- Bestanden
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- afmaken
- volgend
- formaat
- oppompen van
- functionaliteiten
- verder
- toekomst
- Algemeen
- gegenereerde
- genereert
- krijgen
- het krijgen van
- GitHub
- Globaal
- Groen
- Groep
- richtlijnen
- Hadoop
- Hardware
- hulp
- helpt
- Hoge
- geschiedenis
- Bijenkorf
- vakantie
- holistische
- HOURS
- Hoe
- How To
- HTML
- HTTPS
- ICON
- verbetering
- in
- omvatten
- Inclusief
- individueel
- individuen
- informatie
- initiatieven
- innoveren
- invoer
- inzichten
- instantie
- instructies
- belang
- belangen
- geïntroduceerd
- iot
- IT
- Jobomschrijving:
- Vacatures
- Journeys
- json
- sleutel
- uitrusting
- meer
- Groot
- grootschalig
- lancering
- leiden
- leider
- LEARN
- leren
- LED
- Led gegevens
- lijsten
- laden
- lokaal
- lang
- lange tijd
- Kijk
- lot
- machine
- machine learning
- macro's
- Hoofd
- maken
- management
- manager
- Managers
- veel
- middel
- Ondertussen
- Geheugen
- samen te voegen
- Metriek
- migratie
- minuten
- gemengd
- Modern
- modernisering
- Maand
- maandelijks
- meer
- meervoudig
- NATUUR
- Noodzaak
- volgende
- knooppunt
- knooppunten
- aantal
- nummers
- waarnemen
- het verkrijgen van
- EEN
- open
- werkzaam
- operatie
- optimale
- geoptimaliseerde
- optimaliseren
- optimum
- organisaties
- Overige
- bijzonder
- partner
- partners
- patronen
- Hoogtepunt
- uitvoeren
- prestatie
- periode
- toestemming
- plaatsen
- planning
- Plato
- Plato gegevensintelligentie
- PlatoData
- beleidsmaatregelen
- mogelijk
- Post
- praktijk
- praktijken
- vereisten
- die eerder
- prijsstelling
- primair
- Voorafgaand
- problemen
- verwerking
- Programma's
- projecten
- gepast
- voorgestelde
- zorgen voor
- biedt
- Python
- snel
- tarief
- verhouding
- bereiken
- klaar
- real-time
- realtime gegevens
- adviseren
- aanbevolen
- archief
- vermindert
- met betrekking tot
- regio
- regelmatig
- het verwijderen van
- kopiëren
- hulpbron
- Resources
- Resultaten
- behoud
- rondes
- lopen
- lopend
- dezelfde
- Bespaar geld
- Scale
- rooster
- screenshots
- secties
- segment
- senior
- -Series
- Diensten
- reeks
- het instellen van
- verscheidene
- gedeeld
- tonen
- showcase
- aanzienlijke
- aanzienlijk
- gelijk
- Eenvoudig
- simulatie
- simulator
- situatie
- Maat
- Klein
- So
- Oplossingen
- OPLOSSEN
- sommige
- Vonk
- specialist
- specialiseert
- Specialiteit
- specifiek
- specificaties
- stack
- gestart
- statistiek
- Status
- Stap voor
- Stappen
- mediaopslag
- strategisch
- voorleggen
- dergelijk
- ondersteunde
- system
- Systems
- tafel
- op maat gemaakt
- neemt
- doelwit
- taken
- team
- teams
- tech
- Technisch
- Technologies
- sjabloon
- templates
- Testen
- De
- De toekomst
- hun
- daarom
- Door
- niet de tijd of
- Tijdreeksen
- tijdrovend
- tijdlijn
- naar
- samen
- tools
- Transformeren
- Transformatie
- getransformeerd
- waar
- vertrouwde
- types
- voor
- begrijpen
- begrip
- begrijpt
- Gebruik
- .
- Gebruiker
- gebruikers
- doorgaans
- divers
- controleren
- visualisatie
- volume
- wandel
- Warehousing
- week
- per week
- weken
- Wat
- Wat is
- welke
- WIE
- ruiten
- zonder
- workflow
- werkzaam
- Bedrijven
- YAML
- Your
- zephyrnet