Amazon roodverschuiving is een snel, volledig beheerd clouddatawarehouse op petabyteschaal waarmee u eenvoudig en kosteneffectief al uw gegevens kunt analyseren met behulp van standaard SQL en uw bestaande business intelligence (BI)-tools. Tienduizenden klanten gebruiken Amazon Redshift tegenwoordig om exabytes aan gegevens te analyseren en analytische queries uit te voeren, waardoor dit het meest gebruikte clouddatawarehouse is. Amazon Redshift is beschikbaar in zowel serverloze als ingerichte configuraties.
Met Amazon Redshift heeft u rechtstreeks toegang tot gegevens die zijn opgeslagen in Amazon eenvoudige opslagservice (Amazon S3) met behulp van SQL-query's en voeg gegevens samen in uw datawarehouse en data lake. Met Amazon Redshift kunt u de gegevens in uw S3-datameer opvragen via een centrale AWS lijm metastore uit uw Redshift-datawarehouse.
Amazon Redshift ondersteunt het opvragen van een breed scala aan gegevensformaten, zoals CSV, JSON, Parquet en ORC, en tabelformaten zoals Apache Hudi en Delta. Amazon Redshift ondersteunt ook het opvragen van geneste gegevens met complexe gegevenstypen zoals struct, array en map.
Met deze mogelijkheid breidt Amazon Redshift uw datawarehouse op petabyte-schaal op een kosteneffectieve manier uit naar een datameer op exabyte-schaal op Amazon S3.
Apache Iceberg is het nieuwste tabelformaat dat nu in preview wordt ondersteund door Amazon Redshift. In dit bericht laten we u zien hoe u Iceberg-tabellen kunt opvragen met Amazon Redshift, en hoe u Iceberg-ondersteuning en -opties kunt verkennen.
Overzicht oplossingen
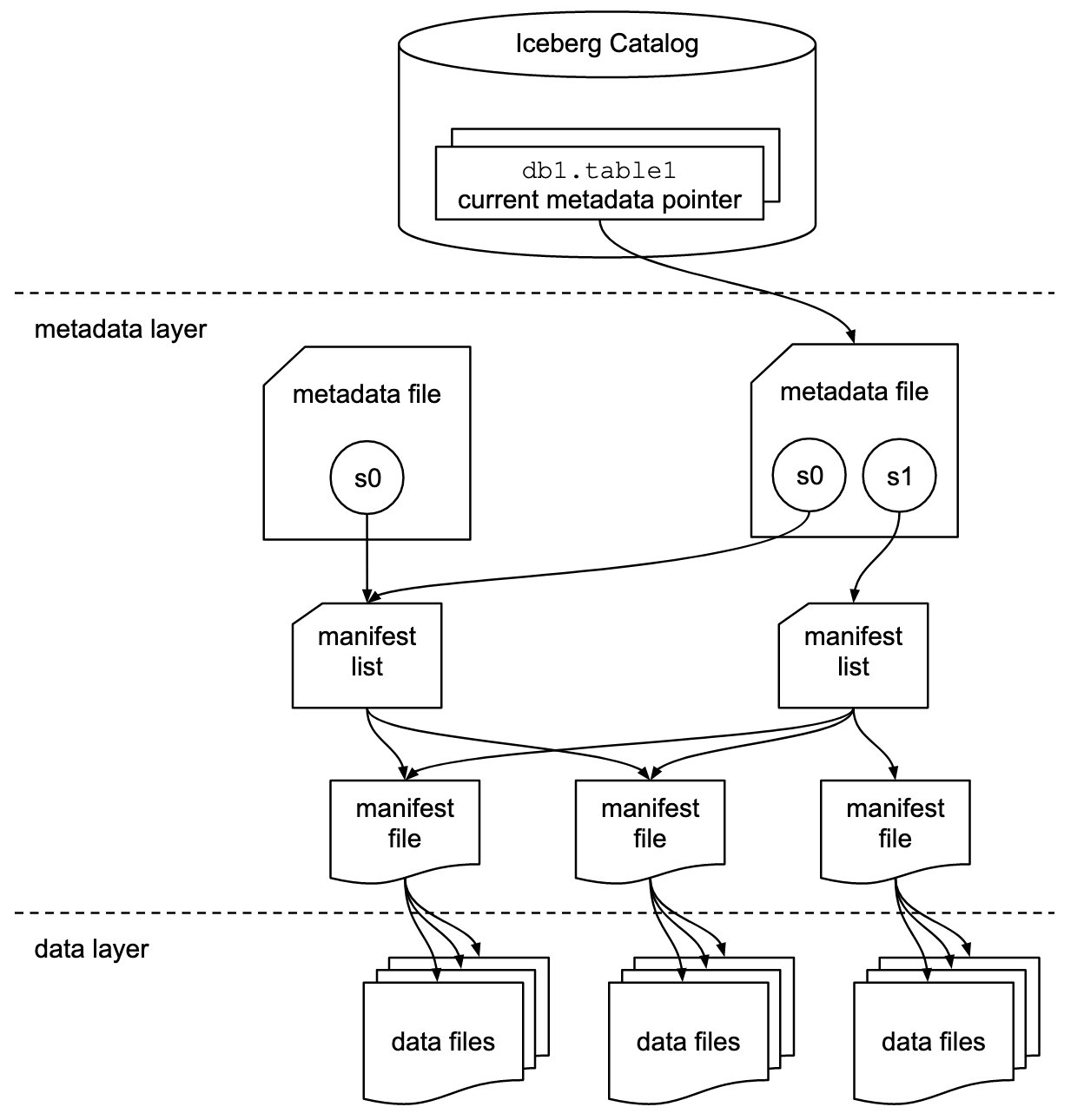
Apache-ijsberg is een open tabelformaat voor zeer grote analytische datasets op petabyte-schaal. Iceberg beheert grote verzamelingen bestanden als tabellen en ondersteunt moderne analytische data lake-bewerkingen zoals invoegen, bijwerken, verwijderen en tijdreizen op recordniveau. De Iceberg-specificatie maakt naadloze tabelevolutie mogelijk, zoals schema- en partitie-evolutie, en het ontwerp is geoptimaliseerd voor gebruik op Amazon S3.
Iceberg slaat de metadata-aanwijzer op voor alle metadatabestanden. Wanneer een SELECT-query een Iceberg-tabel leest, gaat de query-engine eerst naar de Iceberg-catalogus en haalt vervolgens de invoer op van de locatie van het nieuwste metadatabestand, zoals weergegeven in het volgende diagram.
Amazon Redshift biedt nu ondersteuning voor Apache Iceberg-tabellen, waardoor data lake-klanten alleen-lezen analysequery's op een transactioneel consistente manier kunnen uitvoeren. Hierdoor kunt u uw tabellen op transactionele datameren eenvoudig beheren en onderhouden.
Amazon Redshift ondersteunt de eigen schema- en partitie-evolutiemogelijkheden van Apache Iceberg met behulp van de AWS-lijmgegevenscatalogus, waardoor de noodzaak wordt geëlimineerd om tabeldefinities te wijzigen om nieuwe partities toe te voegen of om grote hoeveelheden gegevens te verplaatsen en te verwerken om het schema van een bestaande data lake-tabel te wijzigen. Amazon Redshift gebruikt de kolomstatistieken die zijn opgeslagen in de metagegevens van de Apache Iceberg-tabel om de queryplannen te optimaliseren en de bestandsscans te verminderen die nodig zijn om query's uit te voeren.
In dit bericht gebruiken we de Openbare dataset voor gele taxi's van de NYC Taxi & Limousine Commission als onze brongegevens. De dataset bevat databestanden in Apache Parket formaat op Amazon S3. We gebruiken Amazone Athene om deze Parquet-gegevensset te converteren en vervolgens te gebruiken Amazon Roodverschuivingsspectrum om query's uit te voeren op en deel te nemen aan een lokale Redshift-tabel, verwijderingen en updates op rijniveau uit te voeren en partitie-evolutie uit te voeren, allemaal gecoördineerd via de AWS Glue Data Catalog in een S3-datameer.
Voorwaarden
U moet de volgende vereisten hebben:
Converteer Parquet-gegevens naar een ijsbergtabel
Voor dit bericht heb je de Openbare dataset voor gele taxi's van de NYC Taxi & Limousine Commission verkrijgbaar in Iceberg-formaat. U kunt de bestanden downloaden en vervolgens Athena gebruiken om de Parquet-gegevensset naar een Iceberg-tabel te converteren, of ernaar verwijzen Bouw een Apache Iceberg-datameer met Amazon Athena, Amazon EMR en AWS Glue blogpost om de ijsbergtafel te maken.
In dit bericht gebruiken we Athena om de gegevens te converteren. Voer de volgende stappen uit:
- Download de bestanden via de vorige link of gebruik de AWS-opdrachtregelinterface (AWS CLI) om de bestanden van de openbare S3-bucket voor het jaar 2020 en 2021 naar uw S3-bucket te kopiëren met behulp van de volgende opdracht:
Raadpleeg voor meer informatie De Amazon Redshift CLI instellen.
- Maak een database
Icebergdben maak een tabel met Athena die naar de Parquet-indelingsbestanden verwijst met behulp van de volgende instructie: - Valideer de gegevens in de Parquet-tabel met behulp van de volgende SQL:

- Maak een ijsbergtabel in Athena met de volgende code. Hieronder ziet u de tabeltype-eigenschappen als een ijsbergtabel met Parquet-indeling en pittige compressie
create tablestelling. U moet de S3-locatie bijwerken voordat u de SQL uitvoert. Merk ook op dat de ijsbergtabel is gepartitioneerd met deYearsleutel. - Nadat u de tabel hebt gemaakt, laadt u de gegevens in de Iceberg-tabel met behulp van de eerder geladen Parquet-tabel
nyc_taxi_yellow_parquetmet de volgende SQL: - Wanneer de SQL-instructie voltooid is, valideert u de gegevens in de ijsbergtabel
nyc_taxi_yellow_iceberg. Deze stap is vereist voordat u naar de volgende stap gaat. - U kunt met de volgende opdracht valideren dat de tabel nyc_taxi_gold_iceberg de tabel met ijsbergindeling heeft en is gepartitioneerd in de kolom Jaar:



Maak een extern schema in Amazon Redshift
In deze sectie laten we zien hoe u een extern schema in Amazon Redshift kunt maken dat naar de AWS Glue-database verwijst icebergdb om de ijsbergtabel te bevragen nyc_taxi_yellow_iceberg die we in de vorige sectie zagen met Athena.
Log in op de Roodverschuiving via Query-editor v2 of een SQL-client en voer de volgende opdracht uit (merk op dat de AWS Glue-database icebergdb en regio-informatie wordt gebruikt):

Voor meer informatie over het maken van externe schema's in Amazon Redshift raadpleegt u extern schema maken
Nadat u het externe schema hebt gemaakt spectrum_iceberg_schema, kunt u de Iceberg-tabel opvragen in Amazon Redshift.
Query's uitvoeren op de Iceberg-tabel in Amazon Redshift
Voer de volgende query uit in Query Editor v2. Let daar op spectrum_iceberg_schema is de naam van het externe schema dat is gemaakt in Amazon Redshift en nyc_taxi_yellow_iceberg is de tabel in de AWS Glue-database die in de query wordt gebruikt:
De uitvoer van de querygegevens in de volgende schermafbeelding laat zien dat de AWS Glue-tabel met Iceberg-indeling kan worden opgevraagd met behulp van Redshift Spectrum.

Bekijk het uitlegplan voor het opvragen van de ijsbergtabel
U kunt de volgende query gebruiken om de uitvoer van het uitlegplan op te halen, waaruit blijkt dat de indeling is ICEBERG:

Valideer updates voor gegevensconsistentie
Nadat de update op de Iceberg-tabel is voltooid, kunt u Amazon Redshift opvragen om de transactioneel consistente weergave van de gegevens te zien. Laten we een query uitvoeren door a te kiezen vendorid en voor een bepaalde haal- en brengservice:

Update vervolgens de waarde van passenger_count naar 4 en trip_distance tot 9.4 voor een vendorid en bepaalde ophaal- en afleverdata in Athena:

Voer ten slotte de volgende query uit in Query Editor v2 om de bijgewerkte waarde van te zien passenger_count en trip_distance:
Zoals te zien is in de volgende schermafbeelding, zijn de updatebewerkingen op de Iceberg-tabel beschikbaar in Amazon Redshift.

Creëer een uniforme weergave van de lokale tabel en historische gegevens in Amazon Redshift
Als moderne data-architectuurstrategie kunt u historische gegevens of minder vaak gebruikte gegevens in het datameer organiseren en vaak gebruikte gegevens in het Redshift-datawarehouse bewaren. Dit biedt de flexibiliteit om analyses op schaal te beheren en de meest kosteneffectieve architectuuroplossing te vinden.
In dit voorbeeld laden we gegevens van twee jaar in een roodverschuivingstabel; de rest van de gegevens blijft op het S2-datameer omdat die dataset minder vaak wordt opgevraagd.
- Gebruik de volgende code om twee jaar aan gegevens in het
nyc_taxi_yellow_recenttabel in Amazon Redshift, afkomstig uit de Iceberg-tabel:
- Vervolgens kunt u de gegevens van de afgelopen twee jaar uit de ijsbergtabel verwijderen met behulp van de volgende opdracht in Athena, omdat u de gegevens in de vorige stap in een roodverschuivingstabel hebt geladen:

Nadat je deze stappen hebt voltooid, bevat de Redshift-tabel twee jaar aan gegevens en staat de rest van de gegevens in de Iceberg-tabel in Amazon S2.
- Maak een weergave met behulp van de
nyc_taxi_yellow_icebergIJsbergtafel ennyc_taxi_yellow_recenttabel in Amazon Redshift: - Voer nu een query uit op de weergave. Afhankelijk van de filteromstandigheden scant Redshift Spectrum de ijsberggegevens, de roodverschuivingstabel of beide. De volgende voorbeeldquery retourneert een aantal records uit elk van de brontabellen door beide tabellen te scannen:

Partitie evolutie
IJsberg gebruikt verborgen scheidingswanden, wat betekent dat u niet handmatig partities voor uw Apache Iceberg-tabellen hoeft toe te voegen. Nieuwe partitiewaarden of nieuwe partitiespecificaties (partitiekolommen toevoegen of verwijderen) in Apache Iceberg-tabellen worden automatisch gedetecteerd door Amazon Redshift en er is geen handmatige bewerking nodig om partities in de tabeldefinitie bij te werken. Het volgende voorbeeld laat dit zien.
In ons voorbeeld als de ijsbergtafel nyc_taxi_yellow_iceberg was oorspronkelijk verdeeld per jaar en later de kolom vendorid is toegevoegd als een extra partitiekolom, dan kan Amazon Redshift naadloos de Iceberg-tabel opvragen nyc_taxi_yellow_iceberg met twee verschillende partitieschema's over een bepaalde periode.

Overwegingen bij het opvragen van Iceberg-tabellen met Amazon Redshift
Houd tijdens de preview-periode rekening met het volgende wanneer u Amazon Redshift met Iceberg-tabellen gebruikt:
- Alleen ijsbergtabellen die zijn gedefinieerd in de AWS Glue Data Catalog worden ondersteund.
- CREATE of ALTER externe tabelopdrachten worden niet ondersteund, wat betekent dat de Iceberg-tabel al in een AWS Glue-database zou moeten bestaan.
- Tijdreisquery's worden niet ondersteund.
- IJsbergversies 1 en 2 worden ondersteund. Voor meer details over versies in Iceberg-formaat, zie Formaatversies.
- Voor een lijst met ondersteunde gegevenstypen met ijsbergtabellen raadpleegt u Ondersteunde gegevenstypen met Apache Iceberg-tabellen (preview).
- De prijzen voor het opvragen van een Iceberg-tabel zijn hetzelfde als voor toegang tot andere gegevensformaten met Amazon Redshift.
Voor aanvullende details over overwegingen voor het voorbeeld van tabellen met ijsbergindeling, raadpleegt u Apache Iceberg-tabellen gebruiken met Amazon Redshift (preview).
Klanten feedback
“Tinuiti, het grootste onafhankelijke prestatiemarketingbedrijf, verwerkt dagelijks grote hoeveelheden data en moet een robuuste data lake- en datawarehouse-strategie hebben zodat onze marktinformatieteams al onze klantgegevens op een gemakkelijke, betaalbare, veilige manier kunnen opslaan en analyseren. en op een robuuste manier”, zegt Justin Manus, Chief Technology Officer bij Tinuiti. “De ondersteuning van Amazon Redshift voor Apache Iceberg-tabellen in ons datameer, de enige bron van waarheid, pakt een cruciale uitdaging aan bij het optimaliseren van de prestaties en toegankelijkheid en vereenvoudigt onze data-integratiepijplijnen verder om toegang te krijgen tot alle gegevens die uit verschillende bronnen worden opgenomen en om onze merkpotentieel van klanten.”
Conclusie
In dit bericht hebben we je een voorbeeld laten zien van het bevragen van een ijsbergtabel in Redshift met behulp van bestanden die zijn opgeslagen in Amazon S3, gecatalogiseerd als een tabel in de AWS Glue Data Catalog, en hebben we enkele van de belangrijkste functies gedemonstreerd, zoals efficiënt bijwerken en verwijderen op rijniveau, en de schema-evolutie-ervaring waarmee gebruikers de kracht van big data kunnen ontsluiten met behulp van Athena.
U kunt Amazon Redshift gebruiken om query's uit te voeren op data lake-tabellen in verschillende bestanden en tabelformaten, zoals Apache Hudi en Delta meer, en nu met Apache-ijsberg (preview), dat extra opties biedt voor uw moderne behoeften op het gebied van data-architectuur.
We hopen dat dit je een goed startpunt geeft voor het opvragen van Iceberg-tabellen in Amazon Redshift.
Over de auteurs
 Rohit Bansal is een Analytics Specialist Solutions Architect bij AWS. Hij is gespecialiseerd in Amazon Redshift en werkt samen met klanten om analyseoplossingen van de volgende generatie te bouwen met behulp van andere AWS Analytics-services.
Rohit Bansal is een Analytics Specialist Solutions Architect bij AWS. Hij is gespecialiseerd in Amazon Redshift en werkt samen met klanten om analyseoplossingen van de volgende generatie te bouwen met behulp van andere AWS Analytics-services.
 Satish Sathiya is Senior Product Engineer bij Amazon Redshift. Hij is een fervent big data-enthousiasteling die samenwerkt met klanten over de hele wereld om succes te behalen en te voldoen aan hun behoeften op het gebied van datawarehousing en data lake-architectuur.
Satish Sathiya is Senior Product Engineer bij Amazon Redshift. Hij is een fervent big data-enthousiasteling die samenwerkt met klanten over de hele wereld om succes te behalen en te voldoen aan hun behoeften op het gebied van datawarehousing en data lake-architectuur.
 Ranjan Burman is een Analytics Specialist Solutions Architect bij AWS. Hij is gespecialiseerd in Amazon Redshift en helpt klanten schaalbare analytische oplossingen te bouwen. Hij heeft meer dan 16 jaar ervaring in verschillende database- en datawarehousing-technologieën. Hij heeft een passie voor het automatiseren en oplossen van klantproblemen met cloudoplossingen.
Ranjan Burman is een Analytics Specialist Solutions Architect bij AWS. Hij is gespecialiseerd in Amazon Redshift en helpt klanten schaalbare analytische oplossingen te bouwen. Hij heeft meer dan 16 jaar ervaring in verschillende database- en datawarehousing-technologieën. Hij heeft een passie voor het automatiseren en oplossen van klantproblemen met cloudoplossingen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Over
- toegang
- geraadpleegde
- de toegankelijkheid
- toegang
- Bereiken
- over
- toevoegen
- toegevoegd
- Extra
- adressen
- betaalbaar
- Alles
- toestaat
- al
- ook
- Amazone
- Amazone Athene
- Amazon EMR
- Amazon Web Services
- hoeveelheden
- an
- analytisch
- Analytisch
- analytics
- analyseren
- en
- elke
- apache
- architectuur
- ZIJN
- rond
- reeks
- AS
- At
- webmaster.
- automatiseren
- Beschikbaar
- AWS
- AWS lijm
- basis
- omdat
- vaardigheden
- wezen
- Groot
- Big data
- verbindend
- Blog
- zowel
- merk
- bouw
- bedrijfsdeskundigen
- business intelligence
- by
- CAN
- mogelijkheden
- bekwaamheid
- catalogus
- centraal
- zeker
- uitdagen
- verandering
- chef
- Chief Technology Officer
- klant
- Cloud
- code
- collecties
- Kolom
- columns
- compleet
- complex
- voorwaarden
- Overwegen
- overwegingen
- consequent
- bevat
- converteren
- gecoördineerd
- kostenefficient
- en je merk te creëren
- aangemaakt
- Wij creëren
- kritisch
- klant
- klantgegevens
- Klanten
- dagelijks
- gegevens
- gegevens integratie
- Datameer
- datawarehouse
- Database
- datasets
- Data
- Standaard
- gedefinieerd
- definitie
- definities
- Delta
- tonen
- gedemonstreerd
- demonstreert
- Afhankelijk
- Design
- gegevens
- gedetecteerd
- Dev
- anders
- direct
- Dont
- verdubbelen
- Download
- elk
- gemakkelijk
- En het is heel gemakkelijk
- editor
- doeltreffend
- beide
- elimineren
- maakt
- Motor
- ingenieur
- enthousiast
- toegang
- Ether (ETH)
- Evolutie
- voorbeeld
- bestaan
- bestaand
- ervaring
- Verklaren
- Verken
- strekt
- extern
- extra
- SNELLE
- Voordelen
- Dien in
- Bestanden
- filter
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Stevig
- Voornaam*
- Flexibiliteit
- volgend
- Voor
- formaat
- vaak
- oppompen van
- geheel
- verder
- krijgen
- geeft
- wereldbol
- Goes
- groot
- Groep
- Handvaten
- Hebben
- he
- helpt
- historisch
- hoop
- Hoe
- How To
- HTML
- http
- HTTPS
- if
- in
- onafhankelijk
- informatie
- integratie
- Intelligentie
- in
- IT
- HAAR
- mee
- jpg
- json
- Justin
- Houden
- sleutel
- meer
- Groot
- grootste
- Achternaam*
- later
- laatste
- LEARN
- minder
- als
- LIMIT
- Lijn
- LINK
- Lijst
- laden
- lokaal
- plaats
- onderhouden
- MERKEN
- maken
- beheer
- beheerd
- beheert
- manier
- handboek
- handmatig
- kaart
- Markt
- Marketing
- middel
- Maak kennis met
- Metadata
- Modern
- meer
- meest
- beweging
- bewegend
- Dan moet je
- naam
- inheemse
- Noodzaak
- nodig
- behoeften
- New
- volgende
- volgende generatie
- geen
- nota
- nu
- aantal
- NYC
- of
- Officier
- on
- open
- operatie
- Operations
- Optimaliseer
- geoptimaliseerde
- optimaliseren
- Opties
- or
- oorspronkelijk
- Overige
- onze
- uitgang
- over
- pagina
- hartstochtelijk
- uitvoeren
- prestatie
- periode
- plan
- plannen
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- Post
- potentieel
- energie
- vereisten
- Voorbeschouwing
- vorig
- die eerder
- problemen
- Product
- vastgoed
- biedt
- publiek
- queries
- lezing
- archief
- verminderen
- regio
- verwijderen
- vervangen
- nodig
- REST
- Retourneren
- robuust
- lopen
- lopend
- dezelfde
- zagen
- zegt
- schaalbare
- Scale
- aftasten
- het scannen
- scant
- regelingen
- naadloos
- naadloos
- sectie
- beveiligen
- zien
- senior
- Serverless
- Diensten
- reeks
- moet
- tonen
- vertoonde
- getoond
- Shows
- Eenvoudig
- single
- oplossing
- Oplossingen
- Het oplossen van
- sommige
- bron
- bronnen
- Sourcing XNUMX
- specialist
- specialiseert
- specificatie
- bril
- Spectrum
- SQL
- standaard
- Start
- Statement
- statistiek
- Stap voor
- Stappen
- mediaopslag
- shop
- opgeslagen
- winkels
- Strategie
- Draad
- succes
- dergelijk
- ondersteuning
- ondersteunde
- steunen
- tafel
- teams
- Technologies
- Technologie
- tienen
- neem contact
- dat
- De
- De Bron
- hun
- harte
- Deze
- dit
- duizenden kosten
- Door
- niet de tijd of
- Tijdreizen
- tijdstempel
- naar
- vandaag
- tools
- transactionele
- reizen
- waarheid
- twee
- type dan:
- types
- unified
- unie
- openen
- bijwerken
- bijgewerkt
- updates
- Gebruik
- .
- gebruikt
- gebruikers
- toepassingen
- gebruik
- BEVESTIG
- waarde
- Values
- variëteit
- divers
- zeer
- via
- Bekijk
- volumes
- Magazijn
- Warehousing
- was
- Manier..
- we
- web
- webservices
- wanneer
- welke
- WIE
- breed
- wijd
- wil
- Met
- Bedrijven
- jaar
- jaar
- u
- Your
- zephyrnet