Afbeelding door Freepik
Conversationele AI verwijst naar virtuele agenten en chatbots die menselijke interacties nabootsen en mensen bij een gesprek kunnen betrekken. Het gebruik van conversationele AI is hard op weg een manier van leven te worden – van het vragen aan Alexa tot “zoek het dichtstbijzijnde restaurant” om Siri te vragen “maak een herinnering aan,” virtuele assistenten en chatbots worden vaak gebruikt om vragen van consumenten te beantwoorden, klachten op te lossen, reserveringen te maken en nog veel meer.
Het ontwikkelen van deze virtuele assistenten vergt aanzienlijke inspanningen. Het begrijpen en aanpakken van de belangrijkste uitdagingen kan het ontwikkelingsproces echter stroomlijnen. Ik heb mijn ervaring uit de eerste hand met het creëren van een volwassen chatbot voor een rekruteringsplatform gebruikt als referentiepunt om de belangrijkste uitdagingen en de bijbehorende oplossingen uit te leggen.
Om een conversationele AI-chatbot te bouwen, kunnen ontwikkelaars raamwerken zoals RASA, Amazon's Lex of Google's Dialogflow gebruiken om chatbots te bouwen. De meesten geven de voorkeur aan RASA wanneer ze aangepaste wijzigingen plannen of wanneer de bot zich in de volwassen fase bevindt, omdat het een open-sourceframework is. Ook andere raamwerken zijn geschikt als uitgangspunt.
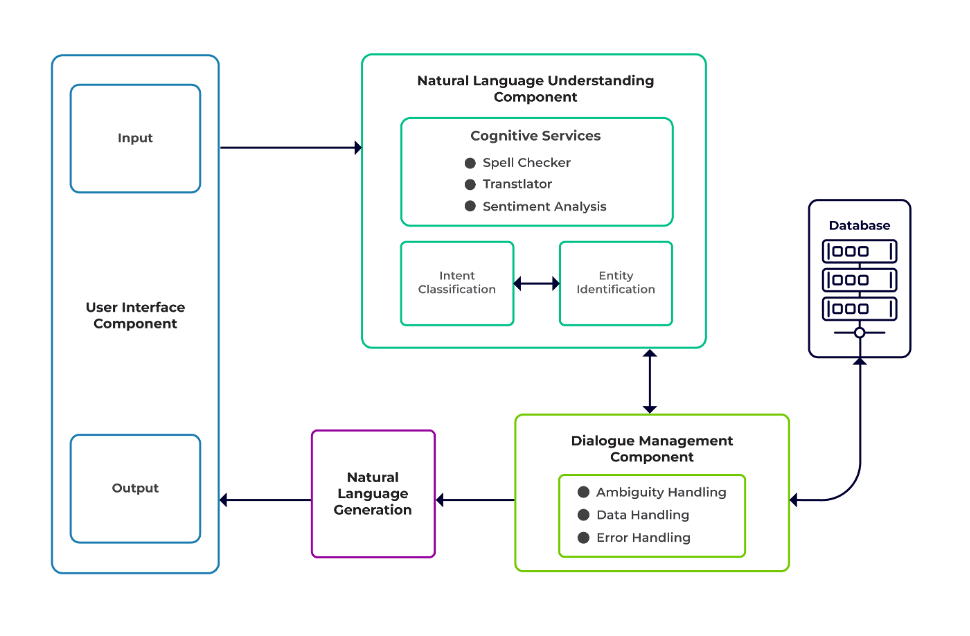
De uitdagingen kunnen worden geclassificeerd als drie belangrijke componenten van een chatbot.
Natuurlijk taalbegrip (NLU) is het vermogen van een bot om de menselijke dialoog te begrijpen. Het voert intentieclassificatie, entiteitsextractie uit en haalt antwoorden op.
Dialoogmanager is verantwoordelijk voor een reeks acties die moeten worden uitgevoerd op basis van de huidige en eerdere reeks gebruikersinvoer. Het neemt intenties en entiteiten als input (als onderdeel van het vorige gesprek) en identificeert de volgende reactie.
Natuurlijke taalgeneratie (NLG) is het proces waarbij geschreven of gesproken zinnen worden gegenereerd op basis van gegeven gegevens. Het kadert het antwoord in, dat vervolgens aan de gebruiker wordt gepresenteerd.
Afbeelding van Talentica Software
Niet genoeg data
Wanneer ontwikkelaars veelgestelde vragen of andere ondersteuningssystemen vervangen door een chatbot, krijgen ze een behoorlijke hoeveelheid trainingsgegevens. Maar hetzelfde gebeurt niet als ze de bot helemaal opnieuw maken. In dergelijke gevallen genereren ontwikkelaars op synthetische wijze trainingsgegevens.
Wat te doen?
Een op sjablonen gebaseerde datagenerator kan een behoorlijke hoeveelheid gebruikersvragen voor training genereren. Zodra de chatbot klaar is, kunnen projecteigenaren deze aan een beperkt aantal gebruikers beschikbaar stellen om de trainingsgegevens te verbeteren en deze gedurende een bepaalde periode te upgraden.
Ongepaste modelselectie
De juiste modelselectie en trainingsgegevens zijn van cruciaal belang om de beste intentie- en entiteitsextractieresultaten te verkrijgen. Ontwikkelaars trainen chatbots meestal in een specifieke taal en domein, en de meeste beschikbare vooraf getrainde modellen zijn vaak domeinspecifiek en getraind in een enkele taal.
Er kunnen zich ook gevallen van gemengde talen voordoen waarbij mensen polyglot zijn. Ze kunnen zoekopdrachten in een gemengde taal invoeren. In een door Frankrijk gedomineerde regio kunnen mensen bijvoorbeeld een type Engels gebruiken dat een mix is van zowel Frans als Engels.
Wat te doen?
Het gebruik van modellen die in meerdere talen zijn getraind, zou het probleem kunnen verminderen. Een vooraf getraind model zoals LaBSE (Taal-agnostische Bert-zininbedding) kan in dergelijke gevallen nuttig zijn. LaBSE is in meer dan 109 talen getraind in een zinsgelijkenis-taak. Het model kent al soortgelijke woorden in een andere taal. In ons project werkte het heel goed.
Onjuiste extractie van entiteiten
Chatbots hebben entiteiten nodig om te identificeren naar wat voor soort gegevens de gebruiker zoekt. Deze entiteiten omvatten tijd, plaats, persoon, item, datum, enz. Bots kunnen er echter niet in slagen een entiteit uit natuurlijke taal te identificeren:
Dezelfde context maar verschillende entiteiten. Bots kunnen bijvoorbeeld een plaats als een entiteit verwarren wanneer een gebruiker 'Naam van studenten uit IIT Delhi' typt en vervolgens 'Naam van studenten uit Bengaluru'.
Scenario's waarin de entiteiten met weinig vertrouwen verkeerd worden voorspeld. Een bot kan IIT Delhi bijvoorbeeld identificeren als een stad met weinig vertrouwen.
Gedeeltelijke entiteitsextractie door machine learning-model. Als een gebruiker 'studenten van IIT Delhi' typt, kan het model 'IIT' alleen als entiteit identificeren in plaats van 'IIT Delhi'.
Invoer van één woord zonder context kan de machine learning-modellen in verwarring brengen. Een woord als ‘Rishikesh’ kan bijvoorbeeld zowel de naam van een persoon als een stad betekenen.
Wat te doen?
Het toevoegen van meer trainingsvoorbeelden zou een oplossing kunnen zijn. Maar er is een limiet waarna het toevoegen van meer niet zou helpen. Bovendien is het een eindeloos proces. Een andere oplossing zou kunnen zijn om regex-patronen te definiëren met behulp van vooraf gedefinieerde woorden om entiteiten te helpen extraheren met een bekende reeks mogelijke waarden, zoals stad, land, enz.
Modellen delen een lager vertrouwen wanneer ze niet zeker zijn over de voorspelling van entiteiten. Ontwikkelaars kunnen dit gebruiken als trigger om een aangepaste component aan te roepen die de onzekere entiteit kan corrigeren. Laten we het bovenstaande voorbeeld bekijken. Als IIT Delhi wordt voorspeld als een stad met weinig vertrouwen, dan kan de gebruiker er altijd naar zoeken in de database. Nadat de voorspelde entiteit niet is gevonden in de Plaats tabel, zou het model naar andere tabellen gaan en het uiteindelijk in de Instituut tabel, resulterend in entiteitscorrectie.
Verkeerde intentieclassificatie
Aan elk gebruikersbericht is een bepaalde intentie verbonden. Omdat intenties de volgende acties van een bot afleiden, is het correct classificeren van gebruikersquery's met intentie van cruciaal belang. Ontwikkelaars moeten echter intenties identificeren met minimale verwarring tussen intenties. Anders kunnen er gevallen ontstaan die door verwarring worden verstoord. Bijvoorbeeld, "Toon mij openstaande vacatures” versus “Toon mij openstaande kandidaten”.
Wat te doen?
Er zijn twee manieren om verwarrende zoekopdrachten van elkaar te onderscheiden. Ten eerste kan een ontwikkelaar een subintentie introduceren. Ten tweede kunnen modellen vragen afhandelen op basis van geïdentificeerde entiteiten.
Een domeinspecifieke chatbot moet een gesloten systeem zijn waarin hij duidelijk moet identificeren waartoe hij in staat is en wat hij niet kan. Ontwikkelaars moeten de ontwikkeling in fasen uitvoeren terwijl ze plannen maken voor domeinspecifieke chatbots. In elke fase kunnen ze de niet-ondersteunde functies van de chatbot identificeren (via niet-ondersteunde intentie).
Ze kunnen ook identificeren wat de chatbot niet aankan met een ‘buiten bereik’-intentie. Maar er kunnen gevallen zijn waarin de bot in de war raakt vanwege niet-ondersteunde en buiten het bereik vallende bedoelingen. Voor dergelijke scenario's moet er een terugvalmechanisme aanwezig zijn waarbij, als het intentievertrouwen onder een drempelwaarde ligt, het model goed kan werken met een terugvalintentie om verwarringsgevallen op te lossen.
Zodra de bot de bedoeling van het bericht van een gebruiker identificeert, moet hij een antwoord terugsturen. Bot bepaalt de reactie op basis van een bepaalde reeks gedefinieerde regels en verhalen. Een regel kan bijvoorbeeld zo simpel als volslagen zijn "Goedemorgen" wanneer de gebruiker begroet "Hoi". Meestal bestaan gesprekken met chatbots echter uit vervolginteractie, en hun reacties zijn afhankelijk van de algehele context van het gesprek.
Wat te doen?
Om dit aan te pakken, worden chatbots gevoed met echte gespreksvoorbeelden, Stories genaamd. Gebruikers communiceren echter niet altijd zoals bedoeld. Een volwassen chatbot moet met al dit soort afwijkingen netjes omgaan. Ontwerpers en ontwikkelaars kunnen dit garanderen als ze zich bij het schrijven van verhalen niet alleen op een gelukkig pad concentreren, maar ook op een ongelukkig pad werken.
De betrokkenheid van gebruikers bij chatbots is sterk afhankelijk van de reacties van de chatbots. Gebruikers kunnen hun interesse verliezen als de reacties te robotachtig of te vertrouwd zijn. Het kan bijvoorbeeld zijn dat een gebruiker een antwoord als “Je hebt een verkeerde zoekopdracht getypt” niet leuk vindt voor een verkeerde invoer, ook al is het antwoord correct. Het antwoord hier komt niet overeen met de persoonlijkheid van een assistent.
Wat te doen?
De chatbot fungeert als assistent en moet een specifieke persoonlijkheid en tone of voice hebben. Ze moeten gastvrij en bescheiden zijn, en ontwikkelaars moeten hun gesprekken en uitingen dienovereenkomstig ontwerpen. De reacties mogen niet robotachtig of mechanisch klinken. De bot zou bijvoorbeeld kunnen zeggen: “Sorry, het lijkt erop dat ik geen details heb. Kunt u uw vraag opnieuw typen?' om een verkeerde invoer aan te pakken.
Op LLM (Large Language Model) gebaseerde chatbots zoals ChatGPT en Bard zijn baanbrekende innovaties en hebben de mogelijkheden van conversationele AI’s verbeterd. Ze zijn niet alleen goed in het voeren van open, mensachtige gesprekken, maar kunnen ook verschillende taken uitvoeren, zoals het samenvatten van teksten, het schrijven van alinea's, enz., wat voorheen alleen door specifieke modellen kon worden bereikt.
Een van de uitdagingen bij traditionele chatbotsystemen is het categoriseren van elke zin in intenties en het dienovereenkomstig bepalen van de reactie. Deze aanpak is niet praktisch. Reacties als ‘Sorry, ik kon je niet bereiken’ zijn vaak irritant. Intentless chatbotsystemen zijn de weg vooruit, en LLM's kunnen dit werkelijkheid maken.
LLM's kunnen gemakkelijk state-of-the-art resultaten behalen op het gebied van algemeen benoemde entiteitsherkenning, behoudens bepaalde domeinspecifieke entiteitsherkenning. Een gemengde benadering van het gebruik van LLM's met elk chatbotframework kan een volwassener en robuuster chatbotsysteem inspireren.
Met de nieuwste ontwikkelingen en voortdurend onderzoek op het gebied van conversationele AI worden chatbots elke dag beter. Gebieden zoals het uitvoeren van complexe taken met meerdere bedoelingen, zoals ‘Boek een vlucht naar Mumbai en regel een taxi naar Dadar’, krijgen veel aandacht.
Binnenkort zullen er gepersonaliseerde gesprekken plaatsvinden op basis van de kenmerken van de gebruiker om de gebruiker betrokken te houden. Als een bot bijvoorbeeld merkt dat de gebruiker ontevreden is, stuurt hij het gesprek door naar een echte agent. Bovendien kunnen deep learning-technieken zoals ChatGPT, met de steeds toenemende hoeveelheid chatbotgegevens, automatisch antwoorden genereren op vragen met behulp van een kennisbank.
Suman Saurav is een datawetenschapper bij Talentica Software, een softwareproductontwikkelingsbedrijf. Hij is een alumnus van NIT Agartala met meer dan 8 jaar ervaring in het ontwerpen en implementeren van revolutionaire AI-oplossingen met behulp van NLP, Conversational AI en Generative AI.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- : heeft
- :is
- :niet
- :waar
- 8
- a
- vermogen
- Over
- boven
- dienovereenkomstig
- Bereiken
- bereikt
- over
- acties
- toe te voegen
- Daarnaast
- adres
- aanpakken
- vooruitgang
- Na
- Agent
- agenten
- AI
- AI chatbot
- Alexa
- Alles
- al
- ook
- oud-leerling
- altijd
- bedragen
- an
- en
- Nog een
- beantwoorden
- elke
- nadering
- ZIJN
- gebieden
- AS
- vragen
- Assistent
- assistenten
- geassocieerd
- At
- aandacht
- webmaster.
- Beschikbaar
- vermijd
- terug
- baseren
- gebaseerde
- BE
- worden
- wezens
- onder
- BEST
- Betere
- Bot
- zowel
- bots
- bouw
- maar
- by
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- CAN
- kan niet
- mogelijkheden
- in staat
- gevallen
- categoriseren
- zeker
- uitdagingen
- Wijzigingen
- kenmerken
- Chatbot
- chatbots
- ChatGPT
- Plaats
- classificatie
- geklasseerd
- duidelijk
- CLOSED
- afstand
- klachten
- complex
- bestanddeel
- componenten
- begrijpen
- vertrouwen
- verward
- verwarrend
- verwarring
- Overwegen
- verband
- doorlopend
- Gesprek
- spraakzaam
- conversatie AI
- conversaties
- te corrigeren
- correct
- Overeenkomend
- kon
- Land
- cursus
- en je merk te creëren
- Wij creëren
- cruciaal
- Actueel
- gewoonte
- gegevens
- data scientist
- Database
- Datum
- dag
- fatsoenlijk
- Beslissen
- deep
- diepgaand leren
- bepalen
- gedefinieerd
- Delhi
- afhangen
- Derive
- Design
- ontwerpers
- ontwerpen
- gegevens
- Ontwikkelaar
- ontwikkelaars
- Ontwikkeling
- dialoogstroom
- Dialoog
- anders
- onderscheiden
- do
- Nee
- domein
- Dont
- elk
- Vroeger
- gemakkelijk
- inspanning
- inbedding
- Eindeloos
- toegewijd
- bezig
- engagement
- Engels
- verhogen
- Enter
- entiteiten
- entiteit
- etc
- Zelfs
- uiteindelijk
- steeds groter
- Alle
- elke dag
- voorbeeld
- voorbeelden
- ervaring
- Verklaren
- extract
- extractie
- FAIL
- bij gebreke
- vertrouwd
- SNELLE
- Voordelen
- Fed
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- vondsten
- vlucht
- Focus
- Voor
- Naar voren
- Achtergrond
- frameworks
- Frans
- oppompen van
- Algemeen
- voortbrengen
- het genereren van
- generatie
- generatief
- generatieve AI
- generator
- krijgen
- het krijgen van
- gegeven
- goed
- garantie
- handvat
- Behandeling
- gebeuren
- gelukkig
- Hebben
- met
- he
- hard
- hulp
- nuttig
- hier
- Hoe
- How To
- Echter
- HTTPS
- menselijk
- nederig
- i
- geïdentificeerd
- identificeert
- identificeren
- if
- uitvoering
- verbeterd
- in
- omvatten
- innovaties
- invoer
- ingangen
- inspireren
- instantie
- verkrijgen in plaats daarvan
- bestemde
- aandachtig
- interactie
- wisselwerking
- interacties
- belang
- in
- voorstellen
- IT
- jpg
- voor slechts
- KDnuggets
- Houden
- sleutel
- Soort
- kennis
- bekend
- weet
- taal
- Talen
- Groot
- laatste
- leren
- Life
- als
- LIMIT
- Beperkt
- verliezen
- Laag
- te verlagen
- machine
- machine learning
- groot
- maken
- maken
- Match
- volwassen
- Mei..
- me
- gemiddelde
- mechanisch
- mechanisme
- Bericht
- macht
- minimaal
- mengen
- gemengd
- model
- modellen
- meer
- Bovendien
- meest
- veel
- meervoudig
- Mumbai
- Dan moet je
- my
- naam
- Genoemd
- Naturel
- Natuurlijke taal
- volgende
- NLG
- nlp
- nlu
- geen
- aantal
- of
- vaak
- on
- eens
- Slechts
- open
- open source
- or
- Overige
- anders-
- onze
- over
- totaal
- eigenaren
- deel
- pad
- paden
- patronen
- Mensen
- uitvoeren
- uitgevoerd
- presteert
- periode
- persoon
- Gepersonaliseerde
- fase
- fasen
- plaats
- plan
- planning
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- dan
- punt
- positie
- bezitten
- mogelijk
- PRAKTISCH
- voorspeld
- voorspelling
- de voorkeur geven
- gepresenteerd
- vorig
- probleem
- gaan
- Product
- productontwikkeling
- project
- queries
- Contact
- R
- rasa
- klaar
- vast
- Realiteit
- werkelijk
- erkenning
- werving
- verminderen
- referentie
- verwijst
- regio
- vertrouwen
- herinnering
- vervangen
- vereisen
- vereist
- onderzoek
- oplossen
- antwoord
- reacties
- verantwoordelijk
- verkregen
- Resultaten
- revolutionair
- robuust
- Regel
- reglement
- dezelfde
- ervaren
- scenario's
- Wetenschapper
- krassen
- Ontdek
- zoeken
- lijkt
- selectie
- sturen
- zin
- bedient
- reeks
- Delen
- moet
- gelijk
- Eenvoudig
- sinds
- single
- siri
- Software
- oplossing
- Oplossingen
- sommige
- Geluid
- specifiek
- gesproken
- Stadium
- Start
- state-of-the-art
- Blog
- gestroomlijnd
- Leerlingen
- wezenlijk
- dergelijk
- geschikt
- ondersteuning
- Ondersteunende systemen
- zeker
- synthetisch
- system
- Systems
- T
- tafel
- Nemen
- neemt
- Taak
- taken
- technieken
- tekst
- neem contact
- dat
- De
- hun
- Ze
- harte
- Er.
- Deze
- ze
- dit
- toch?
- drie
- drempel
- niet de tijd of
- naar
- TONE
- Tone of Voice
- ook
- traditioneel
- Trainen
- getraind
- Trainingen
- leiden
- twee
- type dan:
- types
- begrip
- upgrade
- .
- gebruikt
- Gebruiker
- gebruikers
- gebruik
- doorgaans
- Values
- via
- Virtueel
- Stem
- vs
- W
- Manier..
- manieren
- verwelkomen
- GOED
- Wat
- wanneer
- telkens als
- welke
- en
- wil
- Met
- Woord
- woorden
- Mijn werk
- werkte
- zou
- het schrijven van
- geschreven
- Verkeerd
- jaar
- u
- Your
- zephyrnet