By David Wendt en Gregory Kimbal
Efficiënte verwerking van stringdata is essentieel voor veel data science-toepassingen. Om waardevolle informatie uit stringgegevens te extraheren, RAPIDS libcudf biedt krachtige tools voor het versnellen van stringdatatransformaties. libcudf is een C++ GPU DataFrame-bibliotheek die wordt gebruikt voor het laden, samenvoegen, aggregeren en filteren van gegevens.
In de gegevenswetenschap vertegenwoordigen tekenreeksgegevens spraak, tekst, genetische sequenties, logboekregistratie en vele andere soorten informatie. Bij het werken met stringdata voor machine learning en feature engineering, moeten de data regelmatig worden genormaliseerd en getransformeerd voordat ze kunnen worden toegepast op specifieke use cases. libcudf biedt zowel algemene API's als hulpprogramma's aan de apparaatzijde om een breed scala aan aangepaste tekenreeksbewerkingen mogelijk te maken.
Dit bericht laat zien hoe u op vakkundige wijze stringkolommen kunt transformeren met de libcudf-API voor algemene doeleinden. U krijgt nieuwe kennis over hoe u topprestaties kunt ontgrendelen met behulp van aangepaste kernels en libcudf-hulpprogramma's aan de apparaatzijde. Dit bericht leidt u ook door voorbeelden van hoe u het GPU-geheugen het beste kunt beheren en efficiënt libcudf-kolommen kunt bouwen om uw stringtransformaties te versnellen.
libcudf slaat stringgegevens op in het apparaatgeheugen met behulp van Pijl formaat, die tekenreekskolommen vertegenwoordigt als twee onderliggende kolommen: chars and offsets (Figuur 1).
De chars kolom bevat de tekenreeksgegevens als UTF-8-gecodeerde tekenbytes die aaneengesloten in het geheugen worden opgeslagen.
De offsets kolom bevat een oplopende reeks van gehele getallen die byteposities zijn die het begin van elke individuele string binnen de chars data-array aangeven. Het laatste offset-element is het totale aantal bytes in de kolom met tekens. Dit betekent de grootte van een individuele string op een rij i is gedefinieerd als (offsets[i+1]-offsets[i]).
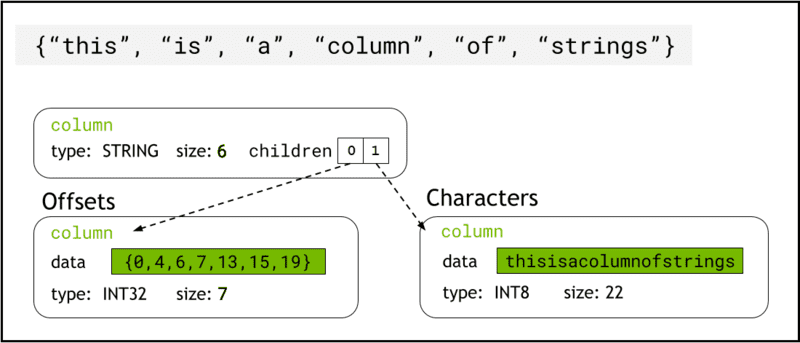 Figuur 1. Schematische weergave van hoe Arrow-formaat strings kolommen vertegenwoordigt
Figuur 1. Schematische weergave van hoe Arrow-formaat strings kolommen vertegenwoordigt chars en offsets onderliggende kolommen
Om een voorbeeld van een tekenreekstransformatie te illustreren, beschouwen we een functie die twee kolommen met invoertekenreeksen ontvangt en één geredigeerde kolom met uitvoertekenreeksen produceert.
De invoergegevens hebben de volgende vorm: een kolom "namen" met voor- en achternaam gescheiden door een spatie en een kolom "zichtbaarheid" met de status "openbaar" of "privé".
We stellen de "redact"-functie voor die werkt op de invoergegevens om uitvoergegevens te produceren die bestaan uit de eerste initiaal van de achternaam gevolgd door een spatie en de volledige voornaam. Als de overeenkomstige zichtbaarheidskolom echter "privé" is, moet de uitvoertekenreeks volledig worden geredigeerd als "X X".
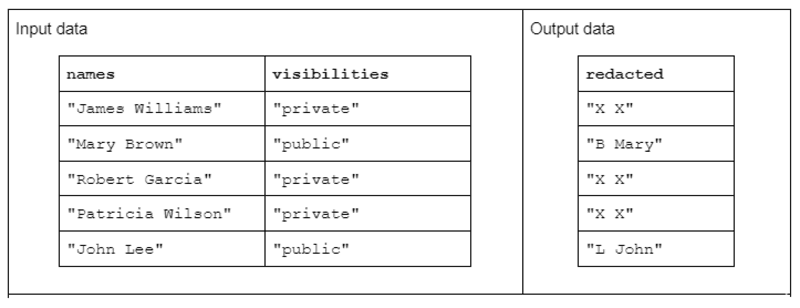 Tabel 1. Voorbeeld van een "geredigeerde" tekenreekstransformatie die namen en zichtbaarheidstekenreekskolommen als invoer ontvangt en gedeeltelijk of volledig geredigeerde gegevens als uitvoer
Tabel 1. Voorbeeld van een "geredigeerde" tekenreekstransformatie die namen en zichtbaarheidstekenreekskolommen als invoer ontvangt en gedeeltelijk of volledig geredigeerde gegevens als uitvoer
Ten eerste kan stringtransformatie worden bereikt met behulp van de libcudf strings-API. De API voor algemeen gebruik is een uitstekend startpunt en een goede basis voor het vergelijken van prestaties.
De API-functies werken op een hele stringkolom, starten ten minste één kernel per functie en wijzen één thread per string toe. Elke thread verwerkt een enkele rij gegevens parallel over de GPU en voert een enkele rij uit als onderdeel van een nieuwe uitvoerkolom.
Volg deze stappen om de redact-voorbeeldfunctie te voltooien met behulp van de algemene API:
- Converteer de stringkolom "zichtbaarheid" naar een Booleaanse kolom met behulp van
contains - Maak een nieuwe kolom met tekenreeksen uit de kolom Namen door "XX" te kopiëren wanneer het overeenkomstige rij-item in de booleaanse kolom "false" is
- Splits de "geredigeerde" kolom in voornaam- en achternaamkolommen
- Snijd het eerste teken van de achternaam als initialen van de achternaam
- Bouw de uitvoerkolom door de kolom met de laatste initialen en de kolom met de voornamen samen te voegen met een spatie ("") als scheidingsteken.
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Deze aanpak duurt ongeveer 3.5 ms op een A6000 met 600 rijen gegevens. Dit voorbeeld gebruikt contains, copy_if_else, split, slice_strings en concatenate om een aangepaste tekenreekstransformatie uit te voeren. Een profileringsanalyse met Nsight-systemen blijkt dat de split functie neemt de langste tijd in beslag, gevolgd door slice_strings en concatenate.
Afbeelding 2 toont profileringsgegevens van Nsight Systems van het geredigeerde voorbeeld, waarbij end-to-end stringverwerking wordt getoond met tot ~600 miljoen elementen per seconde. De regio's komen overeen met NVTX-bereiken die aan elke functie zijn gekoppeld. Lichtblauwe reeksen komen overeen met perioden waarin CUDA-kernels actief zijn.
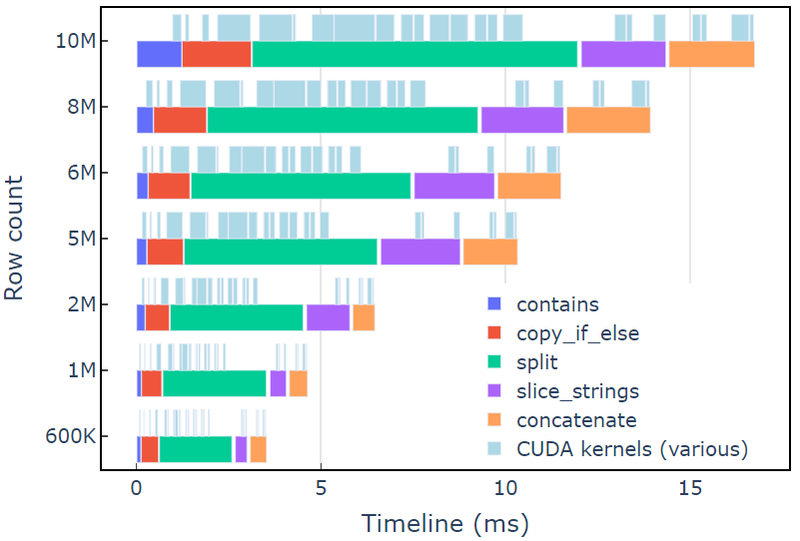 Afbeelding 2. Profileringsgegevens van Nsight Systems van het redactievoorbeeld
Afbeelding 2. Profileringsgegevens van Nsight Systems van het redactievoorbeeld
De libcudf strings API is een snelle en efficiënte toolkit voor het transformeren van strings, maar soms moeten prestatiekritische functies nog sneller werken. Een belangrijke bron van extra werk in de libcudf strings API is het creëren van ten minste één nieuwe stringkolom in het globale apparaatgeheugen voor elke API-aanroep, waardoor de mogelijkheid ontstaat om meerdere API-aanroepen te combineren in een aangepaste kernel.
Prestatiebeperkingen in malloc-oproepen van de kernel
Eerst bouwen we een aangepaste kernel om de redact-voorbeeldtransformatie te implementeren. Bij het ontwerpen van deze kernel moeten we in gedachten houden dat libcudf strings-kolommen onveranderlijk zijn.
Strings-kolommen kunnen niet op hun plaats worden gewijzigd omdat de tekenbytes aaneengesloten worden opgeslagen en eventuele wijzigingen in de lengte van een string zouden de offsetgegevens ongeldig maken. Daarom, de redact_kernel aangepaste kernel genereert een nieuwe strings-kolom door een libcudf-kolomfabriek te gebruiken om beide te bouwen offsets en chars onderliggende kolommen.
Bij deze eerste benadering wordt de uitvoertekenreeks voor elke rij gemaakt in dynamisch apparaatgeheugen met behulp van een malloc-aanroep in de kernel. De aangepaste kerneluitvoer is een vector van apparaataanwijzers naar elke rij-uitvoer, en deze vector dient als invoer voor een strings-kolomfabriek.
De aangepaste kernel accepteert een cudf::column_device_view om toegang te krijgen tot de strings kolomgegevens en gebruikt de element methode om a . terug te geven cudf::string_view die de tekenreeksgegevens vertegenwoordigt op de opgegeven rij-index. De uitvoer van de kernel is een vector van het type cudf::string_view dat verwijzingen bevat naar het geheugen van het apparaat dat de uitvoerstring bevat en de grootte van die string in bytes.
De cudf::string_view klasse is vergelijkbaar met de klasse std::string_view, maar is specifiek geïmplementeerd voor libcudf en verpakt een vaste lengte van karaktergegevens in apparaatgeheugen gecodeerd als UTF-8. Het heeft veel van dezelfde functies (find en substr functies, bijvoorbeeld) en beperkingen (geen null-terminator) als de std tegenhanger. EEN cudf::string_view vertegenwoordigt een tekenreeks die is opgeslagen in het geheugen van het apparaat en dus kunnen we deze hier gebruiken om het geheugen van de malloc op te nemen voor een uitvoervector.
Mallok-kernel
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Dit lijkt misschien een redelijke benadering, totdat de prestaties van de kernel worden gemeten. Deze aanpak duurt ongeveer 108 ms op een A6000 met 600 rijen aan gegevens - meer dan 30x langzamer dan de bovenstaande oplossing met behulp van de libcudf strings API.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Het belangrijkste knelpunt is de malloc/free oproepen binnen de twee kernels hier. Het CUDA dynamische apparaatgeheugen vereist malloc/free roept een kernel op om te worden gesynchroniseerd, waardoor parallelle uitvoering ontaardt in sequentiële uitvoering.
Vooraf toewijzen van werkgeheugen om knelpunten te elimineren
Elimineer de malloc/free knelpunt door het vervangen van de malloc/free roept de kernel op met vooraf toegewezen werkgeheugen voordat de kernel wordt gestart.
Voor het redactievoorbeeld mag de uitvoergrootte van elke tekenreeks in dit voorbeeld niet groter zijn dan de invoertekenreeks zelf, aangezien de logica alleen tekens verwijdert. Daarom kan een geheugenbuffer voor een enkel apparaat worden gebruikt met dezelfde grootte als de invoerbuffer. Gebruik de ingevoerde offsets om elke rijpositie te lokaliseren.
Om toegang te krijgen tot de offsets van de strings-kolom, moet het cudf::column_view met een cudf::strings_column_view en het noemen van zijn offsets_begin methode. De grootte van de chars onderliggende kolom is ook toegankelijk via de chars_size methode. Dan een rmm::device_uvector is vooraf toegewezen voordat de kernel wordt aangeroepen om de tekenuitvoergegevens op te slaan.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Vooraf toegewezen kernel
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
De kernel voert een vector uit van cudf::string_view objecten die worden doorgegeven aan de cudf::make_strings_column fabrieks functie. De tweede parameter van deze functie wordt gebruikt voor het identificeren van null-items in de uitvoerkolom. De voorbeelden in dit bericht hebben geen null-items, dus een nullptr-placeholder cudf::string_view{nullptr,0} is gebruikt.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Deze aanpak duurt ongeveer 1.1 ms op een A6000 met 600 gegevensrijen en is daarmee meer dan 2x beter dan de basislijn. De geschatte verdeling wordt hieronder weergegeven:
redact_kernel 66us make_strings_column 400us
De resterende tijd wordt doorgebracht in cudaMalloc, cudaFree, cudaMemcpy, wat typerend is voor de overhead voor het beheer van tijdelijke instanties van rmm::device_uvector. Deze methode werkt goed als alle uitvoerstrings gegarandeerd even groot of kleiner zijn dan de invoerstrings.
Over het algemeen is het overschakelen naar een bulktoewijzing van werkgeheugen met RAPIDS RMM een aanzienlijke verbetering en een goede oplossing voor een aangepaste tekenreeksfunctie.
Optimalisatie van het maken van kolommen voor snellere rekentijden
Is er een manier om dit nog verder te verbeteren? Het knelpunt is nu de cudf::make_strings_column fabrieksfunctie die de kolomcomponenten met twee strings bouwt, offsets en chars, van de vector van cudf::string_view voorwerpen.
In libcudf zijn veel fabrieksfuncties opgenomen voor het bouwen van stringkolommen. De fabrieksfunctie die in de vorige voorbeelden is gebruikt, duurt a cudf::device_span of cudf::string_view objecten en construeert vervolgens de kolom door a gather op de onderliggende tekengegevens om de offsets en onderliggende tekenkolommen te bouwen. EEN rmm::device_uvector is automatisch converteerbaar naar een cudf::device_span zonder gegevens te kopiëren.
Als de vector van karakters en de vector van offsets echter rechtstreeks worden gebouwd, kan een andere fabrieksfunctie worden gebruikt, die eenvoudigweg de stringkolom maakt zonder dat een verzameling nodig is om de gegevens te kopiëren.
De sizes_kernel maakt een eerste passage over de invoergegevens om de exacte uitvoergrootte van elke uitvoerrij te berekenen:
Geoptimaliseerde kernel: deel 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
De uitvoerformaten worden vervolgens geconverteerd naar offsets door een in-place uit te voeren exclusive_scan. Merk op dat de offsets vector is gemaakt met names.size()+1 elementen. De laatste invoer is het totale aantal bytes (alle formaten bij elkaar opgeteld) terwijl de eerste invoer 0 is. Deze worden beide afgehandeld door de exclusive_scan telefoongesprek. De grootte van de chars kolom wordt opgehaald uit de laatste invoer van de offsets kolom om de tekenvector te bouwen.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
De redact_kernel logica is nog steeds grotendeels hetzelfde, behalve dat het de uitvoer accepteert d_offsets vector om de uitvoerlocatie van elke rij op te lossen:
Geoptimaliseerde kernel: deel 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
De grootte van de uitvoer d_chars kolom wordt opgehaald uit de laatste invoer van de d_offsets kolom om de tekenvector toe te wijzen. De kernel start met de vooraf berekende offsets-vector en retourneert de bevolkte karakters-vector. Ten slotte maakt de libcudf strings column factory de output strings kolommen.
Deze cudf::make_strings_column factory-functie bouwt de strings-kolom op zonder een kopie van de gegevens te maken. De offsets gegevens en chars gegevens hebben al het juiste, verwachte formaat en deze fabriek verplaatst eenvoudigweg de gegevens van elke vector en creëert de kolomstructuur eromheen. Eenmaal voltooid, de rmm::device_uvectors For offsets en chars zijn leeg, hun gegevens zijn verplaatst naar de uitvoerkolom.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Deze aanpak kost ongeveer 300 us (0.3 ms) op een A6000 met 600 rijen gegevens en is meer dan 2x beter dan de vorige aanpak. Dat merk je misschien sizes_kernel en redact_kernel delen veel van dezelfde logica: één keer om de grootte van de uitvoer te meten en vervolgens nog een keer om de uitvoer te vullen.
Vanuit het oogpunt van codekwaliteit is het voordelig om de transformatie te herstructureren als een apparaatfunctie die wordt aangeroepen door zowel de groottes als de redact-kernels. Vanuit prestatieperspectief zou het u misschien verbazen dat de rekenkosten van de transformatie twee keer worden betaald.
De voordelen voor geheugenbeheer en het efficiënter maken van kolommen wegen vaak op tegen de rekenkosten van het twee keer uitvoeren van de transformatie.
Tabel 2 toont de rekentijd, het aantal kernels en de verwerkte bytes voor de vier oplossingen die in dit bericht worden besproken. "Total kernel launches" geeft het totale aantal gelanceerde kernels weer, inclusief zowel reken- als helper-kernels. "Totaal verwerkte bytes" is de cumulatieve DRAM-lees- en schrijfdoorvoer en "minimum verwerkte bytes" is een gemiddelde van 37.9 bytes per rij voor onze testingangen en -uitgangen. De ideale "geheugenbandbreedte beperkte" case gaat uit van 768 GB/s bandbreedte, de theoretische piekdoorvoer van de A6000.
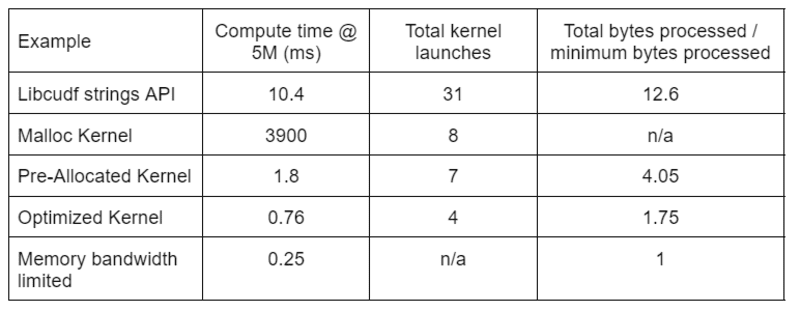 Tabel 2. Bereken tijd, aantal kernels en verwerkte bytes voor de vier oplossingen die in dit bericht worden besproken
Tabel 2. Bereken tijd, aantal kernels en verwerkte bytes voor de vier oplossingen die in dit bericht worden besproken
"Optimized Kernel" biedt de hoogste verwerkingscapaciteit vanwege het verminderde aantal kernellanceringen en het lagere aantal verwerkte bytes. Met efficiënte aangepaste kernels daalt het totale aantal lanceringen van de kernel van 31 naar 4 en het totale aantal verwerkte bytes van 12.6x naar 1.75x van de invoer plus uitvoergrootte.
Als gevolg hiervan behaalt de aangepaste kernel een >10x hogere verwerkingscapaciteit dan de strings-API voor algemeen gebruik voor de redact-transformatie.
De geheugenresource van de pool in RAPIDS-geheugenbeheer (RMM) is een ander hulpmiddel dat u kunt gebruiken om de prestaties te verbeteren. De bovenstaande voorbeelden gebruiken de standaard "CUDA-geheugenresource" voor het toewijzen en vrijmaken van algemeen apparaatgeheugen. De tijd die nodig is om werkgeheugen toe te wijzen, voegt echter een aanzienlijke latentie toe tussen de stappen van de stringtransformaties. De "pool-geheugenresource" in RMM vermindert latentie door vooraf een grote pool geheugen toe te wijzen en tijdens de verwerking naar behoefte subtoewijzingen toe te wijzen.
Met de CUDA-geheugenresource toont "Optimized Kernel" een versnelling van 10x-15x die begint af te nemen bij hogere rijen als gevolg van de toenemende toewijzingsgrootte (Afbeelding 3). Het gebruik van de poolgeheugenresource beperkt dit effect en handhaaft 15x-25x versnellingen ten opzichte van de libcudf strings API-benadering.
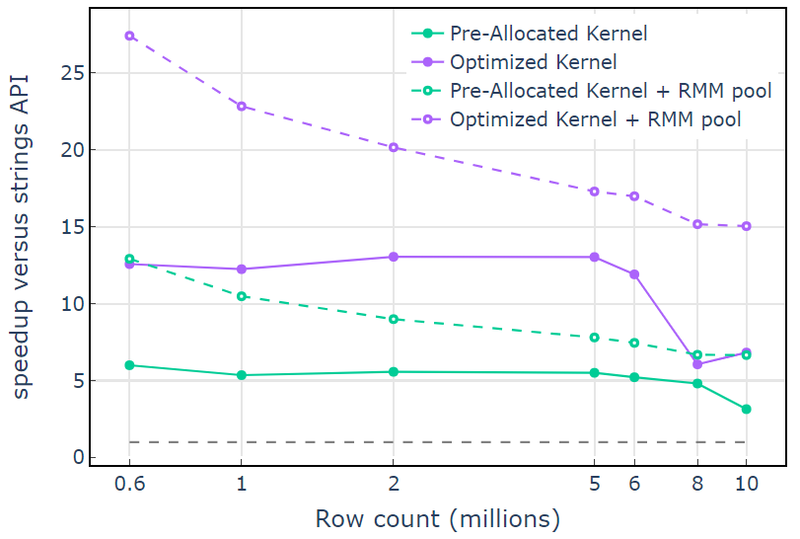 Afbeelding 3. Versnelling van de aangepaste kernels "Pre-Allocated Kernel" en "Optimized Kernel" met de standaard CUDA-geheugenresource (vast) en de pool-geheugenresource (onderbroken), versus de libcudf-tekenreeks-API met de standaard CUDA-geheugenresource
Afbeelding 3. Versnelling van de aangepaste kernels "Pre-Allocated Kernel" en "Optimized Kernel" met de standaard CUDA-geheugenresource (vast) en de pool-geheugenresource (onderbroken), versus de libcudf-tekenreeks-API met de standaard CUDA-geheugenresource
Met de poolgeheugenresource wordt een end-to-end geheugendoorvoer aangetoond die de theoretische limiet voor een two-pass algoritme nadert. "Optimized Kernel" bereikt een doorvoersnelheid van 320-340 GB/s, gemeten aan de hand van de grootte van de invoer plus de grootte van de uitvoer en de rekentijd (Afbeelding 4).
De two-pass-benadering meet eerst de grootte van de uitvoerelementen, wijst geheugen toe en stelt vervolgens het geheugen in met de uitvoer. Gegeven een two-pass verwerkingsalgoritme, presteert de implementatie in "Optimized Kernel" dicht bij de limiet van de geheugenbandbreedte. "End-to-end geheugendoorvoer" wordt gedefinieerd als de invoer plus uitvoergrootte in GB gedeeld door de rekentijd. *RTX A6000 geheugenbandbreedte (768 GB/s).
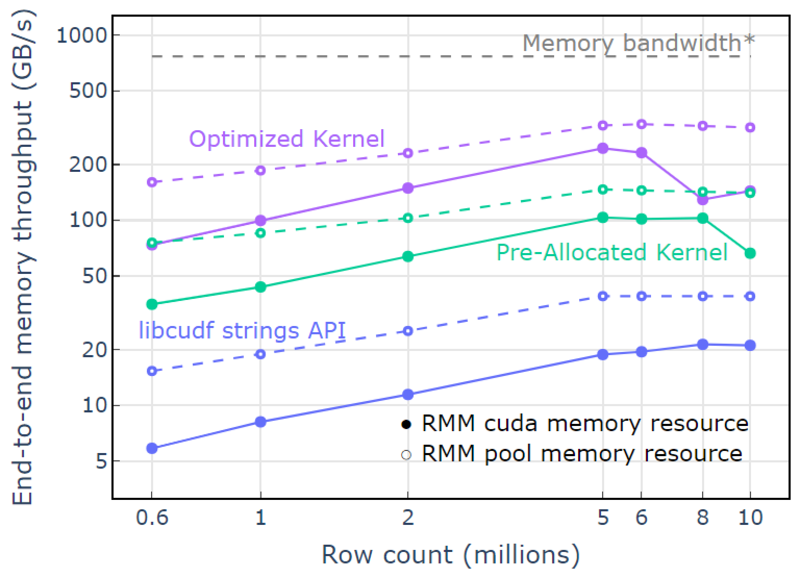 Afbeelding 4. Geheugendoorvoer voor "Optimized Kernel", "Pre-Allocated Kernel" en "libcudf strings API" als een functie van het aantal invoer-/uitvoerrijen
Afbeelding 4. Geheugendoorvoer voor "Optimized Kernel", "Pre-Allocated Kernel" en "libcudf strings API" als een functie van het aantal invoer-/uitvoerrijen
Dit bericht demonstreert twee benaderingen voor het schrijven van efficiënte stringgegevenstransformaties in libcudf. De algemene API van libcudf is snel en duidelijk voor ontwikkelaars en levert goede prestaties. libcudf biedt ook hulpprogramma's aan de apparaatzijde die zijn ontworpen voor gebruik met aangepaste kernels, in dit voorbeeld voor >10x snellere prestaties.
Pas je kennis toe
Om aan de slag te gaan met RAPIDS cuDF, gaat u naar de stroomversnelling/cudf GitHub-opslagplaats. Als u cuDF en libcudf nog niet hebt geprobeerd voor uw tekenreeksverwerkingsworkloads, raden we u aan de nieuwste release te testen. Dockercontainers zijn bedoeld voor zowel releases als nachtelijke builds. Conda-pakketten zijn ook beschikbaar om het testen en implementeren eenvoudiger te maken. Als u cuDF al gebruikt, raden we u aan om het nieuwe tekenreekstransformatievoorbeeld uit te voeren door te bezoeken rapidsai/cudf/tree/HEAD/cpp/examples/strings op GitHub.
David Wendt is een senior systeemsoftware-ingenieur bij NVIDIA die C++/CUDA-code ontwikkelt voor RAPIDS. David heeft een masterdiploma in elektrotechniek van de Johns Hopkins University.
Gregory Kimbal is software engineering manager bij NVIDIA en werkt in het RAPIDS-team. Gregory leidt de ontwikkeling van libcudf, de CUDA/C++-bibliotheek voor kolomvormige gegevensverwerking die RAPIDS cuDF aandrijft. Gregory is gepromoveerd in toegepaste natuurkunde aan het California Institute of Technology.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Over
- boven
- versnellen
- Accepteert
- toegang
- geraadpleegde
- volbracht
- over
- toegevoegd
- Voegt
- algoritme
- Alles
- ken toe
- toewijzing
- al
- bedragen
- analyse
- en
- Nog een
- apache
- api
- APIs
- toepassingen
- toegepast
- nadering
- benaderingen
- naderen
- rond
- reeks
- geassocieerd
- auto
- webmaster.
- Beschikbaar
- gemiddelde
- bandbreedte
- Baseline
- omdat
- vaardigheden
- wezen
- onder
- heilzaam
- betekent
- BEST
- tussen
- Blauw
- Storing
- buffer
- bouw
- Gebouw
- bouwt
- bebouwd
- C + +
- Californië
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- bellen
- oproepen
- kan niet
- geval
- gevallen
- veroorzakend
- Wijzigingen
- karakter
- tekens
- kind
- klasse
- Sluiten
- code
- Kolom
- columns
- combineren
- vergelijken
- compleet
- Voltooid
- componenten
- berekening
- Berekenen
- Overwegen
- bestaande uit
- bouwen
- bevat
- converteren
- geconverteerd
- kopiëren
- Overeenkomend
- Kosten
- en je merk te creëren
- aangemaakt
- creëert
- het aanmaken
- gewoonte
- gegevens
- gegevensverwerking
- data science
- David
- Standaard
- Mate
- levert
- gedemonstreerd
- inzet
- ontworpen
- ontwerpen
- ontwikkelaars
- het ontwikkelen van
- Ontwikkeling
- apparaat
- anders
- direct
- besproken
- Verdeeld
- havenarbeider
- Val
- gedurende
- dynamisch
- elk
- gemakkelijker
- effect
- doeltreffend
- efficiënt
- Elektrotechniek
- geeft je de mogelijkheid
- elimineren
- in staat stellen
- aanmoedigen
- eind tot eind
- ingenieur
- Engineering
- Geheel
- toegang
- Ether (ETH)
- Zelfs
- alles
- voorbeeld
- voorbeelden
- uitstekend
- Behalve
- uitvoering
- verwacht
- extern
- extra
- extract
- fabriek
- SNELLE
- sneller
- Kenmerk
- Voordelen
- Figuur
- filtering
- finale
- Tot slot
- Voornaam*
- vast
- volgen
- gevolgd
- volgend
- formulier
- formaat
- Gratis
- vaak
- oppompen van
- voor
- geheel
- functie
- functies
- verder
- Krijgen
- Algemeen
- genereert
- krijgen
- GitHub
- gegeven
- Globaal
- goed
- GPU
- gegarandeerde
- Handvaten
- met
- hier
- hoger
- hoogst
- houdt
- Hoe
- How To
- Echter
- HTML
- HTTPS
- ideaal
- het identificeren van
- onveranderlijk
- uitvoeren
- uitvoering
- geïmplementeerd
- verbeteren
- verbetering
- verbetert
- in
- inclusief
- Inclusief
- Laat uw omzet
- meer
- index
- individueel
- informatie
- eerste
- invoer
- Instituut
- intern
- IT
- zelf
- Johns Hopkins
- Johns Hopkins University
- aansluiting
- KDnuggets
- Houden
- sleutel
- kennis
- label
- Groot
- groter
- Achternaam*
- Wachttijd
- laatste
- nieuwste release
- gelanceerd
- lanceert
- lancering
- Leads
- leren
- Lengte
- Bibliotheek
- licht
- LIMIT
- beperkingen
- het laden
- plaats
- machine
- machine learning
- Hoofd
- onderhoudt
- maken
- MERKEN
- maken
- beheer
- management
- manager
- beheren
- veel
- meester
- het beheersen van
- Match
- middel
- maatregel
- maatregelen
- Geheugen
- methode
- macht
- miljoen
- denken
- meer
- efficiënter
- beweegt
- MS
- meervoudig
- naam
- namen
- Noodzaak
- nodig
- New
- aantal
- Nvidia
- objecten
- compenseren
- EEN
- opening
- besturen
- exploiteert
- Operations
- kansen
- Overige
- betaald
- Parallel
- parameter
- deel
- voorbij
- Hoogtepunt
- prestatie
- uitvoerend
- presteert
- periodes
- toestemming
- perspectief
- Fysica
- plaats
- Plato
- Plato gegevensintelligentie
- PlatoData
- plus
- punt
- zwembad
- bevolkte
- positie
- posities
- Post
- krachtige
- bevoegdheden
- vorig
- verwerking
- produceren
- profilering
- voorstellen
- mits
- biedt
- publiek
- doel
- kwaliteit
- reeks
- Bereikt
- Lees
- redelijk
- ontvangt
- record
- Gereduceerd
- vermindert
- Refactoren
- weerspiegelt
- regio
- los
- Releases
- resterende
- vertegenwoordigen
- vertegenwoordigt
- hulpbron
- resultaat
- terugkeer
- Retourneren
- RIJ
- lopen
- lopend
- dezelfde
- Wetenschap
- Tweede
- senior
- Volgorde
- bedient
- Sets
- Delen
- moet
- getoond
- Shows
- aanzienlijke
- gelijk
- eenvoudigweg
- sinds
- single
- Maat
- maten
- kleinere
- So
- Software
- Software Engineer
- software engineering
- solide
- oplossing
- Oplossingen
- bron
- Tussenruimte
- specifiek
- specifiek
- gespecificeerd
- toespraak
- snelheid
- besteed
- spleet
- begin
- gestart
- Start
- Status
- Stappen
- Still
- shop
- opgeslagen
- winkels
- eenvoudig
- stream
- structuur
- verwonderd
- Systems
- neemt
- team
- Technologie
- tijdelijk
- proef
- Testen
- De
- hun
- theoretisch
- daarom
- Door
- doorvoer
- niet de tijd of
- naar
- samen
- tools
- toolkit
- tools
- Totaal
- Transformeren
- Transformatie
- transformaties
- getransformeerd
- transformeren
- tv
- types
- typisch
- die ten grondslag liggen
- universiteit-
- openen
- ontgrendelen
- us
- .
- utilities
- waardevol
- Waardevolle informatie
- Tegen
- zichtbaarheid
- zichtbaar
- vitaal
- welke
- en
- breed
- Grote range
- wil
- binnen
- zonder
- Mijn werk
- werkzaam
- Bedrijven
- zou
- schrijven
- het schrijven van
- X
- Your
- zephyrnet










