Twee recente, op software gebaseerde algoritmische technologieën – autonoom rijden (ADAS/AD) en generatieve AI (GenAI) – houden de halfgeleidertechniekgemeenschap wakker.
Terwijl ADAS op niveau 2 en niveau 3 op koers liggen, zijn ADAS op niveau 4 en 5 verre van realiteit, waardoor het enthousiasme en de financiële middelen voor durfkapitaal afnemen. Tegenwoordig krijgt GenAI de aandacht en investeren durfkapitaalfondsen gretig miljarden dollars.
Beide technologieën zijn gebaseerd op moderne, complexe algoritmen. De verwerking van hun training en gevolgtrekking heeft een aantal kenmerken gemeen, sommige van cruciaal belang, andere belangrijk maar niet essentieel: zie tabel I.

De opmerkelijke softwarevooruitgang in deze technologieën is tot nu toe niet gerepliceerd door ontwikkelingen in algoritmische hardware om de uitvoering ervan te versnellen. De modernste algoritmische processors beschikken bijvoorbeeld niet over de prestaties om ChatGPT-4-vragen in één of twee seconden te beantwoorden tegen een kostprijs van ¢2 per zoekopdracht, de maatstaf die is vastgesteld door Google Search, of om de enorme gegevens te verwerken verzameld door de AD-sensoren in minder dan 20 milliseconden.
Dat is totdat de Franse startup VSORA denkkracht investeerde om het geheugenknelpunt aan te pakken dat bekend staat als de geheugenmuur.
De Herinneringsmuur
De geheugenmuur van de CPU werd voor het eerst beschreven door Wulf en McKee in 1994. Sindsdien is geheugentoegang het knelpunt van de computerprestaties geworden. De vooruitgang in de prestaties van de processor wordt niet weerspiegeld in de voortgang van de geheugentoegang, waardoor processors steeds langer moeten wachten op gegevens die door het geheugen worden aangeleverd. Uiteindelijk daalt de processorefficiëntie ver onder de 100% benutting.
Om dit probleem op te lossen heeft de halfgeleiderindustrie een hiërarchische geheugenstructuur met meerdere niveaus gecreëerd met meerdere cacheniveaus dichter bij de processor, waardoor de hoeveelheid verkeer met de langzamere hoofd- en externe geheugens wordt verminderd.
De prestaties van AD- en GenAI-processors zijn meer dan andere typen computerapparatuur afhankelijk van een grote geheugenbandbreedte.
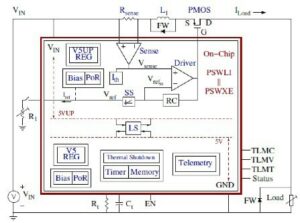
VSORA, opgericht in 2015 om zich te richten op 5G-toepassingen, heeft een gepatenteerde architectuur uitgevonden die de hiërarchische geheugenstructuur samenvouwt in een groot, strak gekoppeld geheugen (TCM) met hoge bandbreedte waartoe in één klokcyclus toegang wordt verkregen.
Vanuit het perspectief van de processorkernen ziet en gedraagt de TCM zich als een zee van registers in de hoeveelheid MBytes versus kBytes van daadwerkelijke fysieke registers. De mogelijkheid om in één cyclus toegang te krijgen tot elke geheugencel in de TMC levert een hoge uitvoeringssnelheid, lage latentie en een laag stroomverbruik op. Het vereist ook minder siliciumoppervlak. Het laden van nieuwe gegevens uit het externe geheugen in de TCM terwijl de huidige gegevens worden verwerkt, heeft geen invloed op de systeemdoorvoer. Kortom, de architectuur maakt door het ontwerp een benutting van meer dan 80% van de verwerkingseenheden mogelijk. Toch is er een mogelijkheid om cache- en kladblokgeheugen toe te voegen als een systeemontwerper dat wenst. Zie figuur 1.
")
Door een registerachtige geheugenstructuur die in vrijwel alle geheugens in alle toepassingen is geïmplementeerd, kan het voordeel van de VSORA-geheugenbenadering niet genoeg worden benadrukt. Doorgaans leveren geavanceerde GenAI-processors een efficiëntie van één cijfer. Een GenAI-processor met een nominale doorvoer van één Petaflops met nominale prestaties maar een efficiëntie van minder dan 5% levert bijvoorbeeld bruikbare prestaties van minder dan 50 Teraflops. In plaats daarvan bereikt de VSORA-architectuur een meer dan 10 keer grotere efficiëntie.
VSORA's algoritmische versnellers
VSORA introduceerde twee klassen algoritmische versnellers: de Tyr-familie voor AD-toepassingen en de Jotunn-familie voor GenAI-versnelling. Beide leveren een geweldige doorvoer, minimale latentie en een laag stroomverbruik in een kleine siliciumvoetafdruk.
Met een nominale prestatie van maximaal drie Petaflops beschikken ze over een typische implementatie-efficiëntie van 50-80%, ongeacht het algoritmetype, en een piekstroomverbruik van 30 Watt/Petaflops. Dit zijn geweldige eigenschappen die nog door geen enkele concurrerende AI-versneller zijn gerapporteerd.
Tyr en Jotunn zijn volledig programmeerbaar en integreren AI- en DSP-mogelijkheden, zij het in verschillende hoeveelheden, en ondersteunen on-the-fly selectie van rekenkunde van 8-bit tot 64-bit, op basis van gehele getallen of drijvende komma's. Hun programmeerbaarheid herbergt een universum van algoritmen, waardoor ze algoritme-agnostisch zijn. Er worden ook verschillende soorten sparsity ondersteund.
De kenmerken van VSORA-processors zorgen ervoor dat ze voorop lopen in het competitieve algoritmische verwerkingslandschap.
VSORA-ondersteunende software
VSORA heeft een uniek compilatie-/validatieplatform ontworpen dat is afgestemd op de hardwarearchitectuur om ervoor te zorgen dat de complexe, krachtige SoC-apparaten voldoende softwareondersteuning hebben.
Bedoeld om de algoritmische ontwerper in de cockpit te plaatsen, levert een reeks hiërarchische verificatie-/validatieniveaus – ESL, hybride, RTL en gate – drukknopfeedback aan de algoritmische ingenieur als reactie op ontwerpruimteverkenningen. Dit helpt hem of haar bij het selecteren van het beste compromis tussen prestaties, latentie, kracht en oppervlakte. Programmeercode die op een hoog abstractieniveau is geschreven, kan op transparante wijze voor de gebruiker in kaart worden gebracht, gericht op verschillende verwerkingskernen.
Interfacing tussen kernen kan worden geïmplementeerd binnen hetzelfde silicium, tussen chips op dezelfde PCB of via een IP-verbinding. Synchronisatie tussen kernen wordt automatisch beheerd tijdens de compilatie en vereist geen realtime softwarebewerkingen.
Wegversperring naar L4/L5-autonoom rijden en generatieve AI-inferentie aan de rand
Een succesvolle oplossing moet ook in-field programmeerbaarheid omvatten. Algoritmen evolueren snel, gedreven door nieuwe ideeën die van de ene op de andere dag verouderd zijn. De mogelijkheid om een algoritme in het veld te upgraden is een opmerkelijk voordeel.
Hoewel hyperscale bedrijven enorme computerparken hebben samengesteld met een groot aantal van hun krachtigste processors om geavanceerde software-algoritmen te kunnen verwerken, is de aanpak alleen praktisch voor training, niet voor gevolgtrekkingen aan de rand.
De training is doorgaans gebaseerd op 32-bits of 64-bits drijvende-kommaberekeningen die grote gegevensvolumes genereren. Het vereist geen strenge latentie en tolereert een hoog stroomverbruik en aanzienlijke kosten.
Inferentie aan de rand wordt doorgaans uitgevoerd op basis van 8-bits drijvende-kommaberekeningen die iets minder hoeveelheden gegevens genereren, maar compromisloze latentie, een laag energieverbruik en lage kosten vereisen.
Impact van energieverbruik op latentie en efficiëntie
Het stroomverbruik in CMOS-IC's wordt gedomineerd door gegevensbeweging en niet door gegevensverwerking.
Een onderzoek van Stanford University onder leiding van professor Mark Horowitz toonde aan dat het stroomverbruik van geheugentoegang ordes van grootte meer energie verbruikt dan eenvoudige digitale logische berekeningen. Zie tabel II.

AD- en GenAI-accelerators zijn uitstekende voorbeelden van apparaten die worden gedomineerd door dataverkeer en die een uitdaging vormen om het energieverbruik binnen de perken te houden.
Conclusie
AD- en GenAI-gevolgtrekking vormen niet-triviale uitdagingen om succesvolle implementaties te bereiken. VSORA kan een uitgebreide hardwareoplossing en ondersteunende software leveren om aan alle kritische vereisten te voldoen om AD L4/L5 en GenAI-achtige GPT-4-versnelling te verwerken tegen commercieel haalbare kosten.
Meer details over VSORA en zijn Tyr en Jotunn zijn te vinden op www.vsora.com.
Over Lauro Rizzatti
Lauro Rizzatti is bedrijfsadviseur van VSORA, een innovatieve startup die silicium IP-oplossingen en siliciumchips aanbiedt, en een bekende verificatieconsulent en branche-expert op het gebied van hardware-emulatie. Voorheen bekleedde hij functies in management, productmarketing, technische marketing en engineering.
Lees ook:
Soitec ontwikkelt de toekomst van de halfgeleiderindustrie
ISO 21434 voor Cybersecurity-bewuste SoC-ontwikkeling
Voorspellend onderhoud in de context van functionele veiligheid in de automobielsector
Deel dit bericht via:
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://semiwiki.com/automotive/336201-long-standing-roadblock-to-viable-l4-l5-autonomous-driving-and-generative-ai-inference-at-the-edge/
- : heeft
- :is
- :niet
- $UP
- 000
- 1
- 10
- 1800
- 1994
- 20
- 30
- 50
- 5G
- a
- vermogen
- Over
- abstractie
- versnellen
- versnelling
- versneller
- versnellers
- toegang
- geraadpleegde
- toegang
- Bereiken
- Bereikt
- over
- Handelingen
- daadwerkelijk
- Ad
- ADA's
- toevoegen
- adres
- vergevorderd
- vooruitgang
- Voordeel
- adviseur
- invloed hebben op
- AI
- algoritme
- algoritmische
- algoritmen
- Alles
- toestaat
- ook
- bedragen
- hoeveelheden
- an
- en
- beantwoorden
- elke
- toepassingen
- nadering
- architectuur
- ZIJN
- GEBIED
- Kunst
- AS
- At
- aandacht
- attributen
- webmaster.
- automotive
- autonoom
- bandbreedte
- gebaseerde
- basis-
- Eigenlijk
- BE
- worden
- geweest
- onder
- criterium
- BEST
- tussen
- miljarden
- zowel
- bedrijfsdeskundigen
- maar
- by
- cache
- CAN
- kan niet
- mogelijkheden
- hoofdstad
- veroorzakend
- cel
- uitdagen
- uitdagingen
- chips
- klassen
- Klok
- Cockpit
- code
- stort in
- commercieel
- gemeenschap
- Bedrijven
- concurrerend
- complex
- ingewikkeld
- uitgebreid
- compromis
- berekeningen
- Berekenen
- computergebruik
- versterken
- consultant
- consumptie
- bevatten
- verband
- Kosten
- Kosten
- gepaard
- CPU
- aangemaakt
- kritisch
- Actueel
- op het randje
- cyclus
- gegevens
- gegevensverwerking
- leveren
- geleverd
- levert
- dicht
- afhankelijk
- beschreven
- Design
- ontworpen
- leesmaatjes
- gegevens
- systemen
- anders
- digitaal
- cijfers
- do
- doet
- dollar
- gedreven
- aandrijving
- Val
- Drops
- gretig
- rand
- doeltreffendheid
- beide
- einde
- energie-niveau
- Energieverbruik
- ingenieur
- Engineering
- verzekeren
- enthousiasme
- ESL
- essentieel
- gevestigd
- OOIT
- ontwikkelen
- voorbeeld
- voorbeelden
- uitvoering
- expert
- extern
- familie
- ver
- Boerderijen
- feedback
- weinig
- veld-
- Figuur
- Voornaam*
- drijvend
- Footprint
- Voor
- Voorhoede
- gevonden
- Opgericht
- Frans
- oppompen van
- geheel
- functioneel
- toekomst
- genereert
- generatief
- generatieve AI
- Kopen Google Reviews
- Google Search
- meer
- handvat
- Hardware
- Hebben
- he
- Held
- helpt
- haar
- Hoge
- hoge performantie
- hoogst
- hem
- Horowitz
- http
- HTTPS
- reusachtig
- Hybride
- i
- ICS
- ideeën
- if
- ii
- uitvoering
- implementaties
- geïmplementeerd
- belangrijk
- opgelegde
- in
- omvatten
- -industrie
- Industrie-expert
- innovatieve
- instantie
- verkrijgen in plaats daarvan
- integreren
- in
- geïntroduceerd
- Uitgevonden
- Investeren
- investeerde
- IP
- IT
- HAAR
- jpg
- sprongen
- houden
- bekend
- Landschap
- Groot
- Wachttijd
- LED
- minder
- Niveau
- niveaus
- als
- het laden
- logica
- al lang bestaand
- langer
- LOOKS
- Laag
- Hoofd
- onderhoud
- maken
- beheerd
- management
- mandaten
- Mark
- Marketing
- massief
- max-width
- Maak kennis met
- Memories
- Geheugen
- milliseconden
- minimaal
- Modern
- geld
- meer
- beweging
- meervoudig
- massa's
- New
- nacht
- bekend
- opmerkelijk
- nu
- verouderd
- of
- het aanbieden van
- on
- EEN
- Slechts
- Operations
- or
- bestellen
- orders
- Overige
- Overig
- over
- gedurende de nacht
- overschat
- innovatief
- Hoogtepunt
- voor
- percentage
- prestatie
- uitgevoerd
- perspectief
- Fysiek
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- Overvloed
- punt
- posities
- mogelijkheid
- Post
- energie
- PRAKTISCH
- die eerder
- Prime
- probleem
- verwerkt
- verwerking
- Gegevensverwerker
- processors
- Product
- Hoogleraar
- programmeerbare
- Programming
- Voortgang
- Voortbewegen
- zetten
- queries
- reeks
- snel
- Lees
- real-time
- Realiteit
- recent
- vermindert
- achteloos
- register
- opmerkelijk
- gerepliceerd
- gemeld
- vereisen
- Voorwaarden
- vereist
- antwoord
- dezelfde
- SEA
- Ontdek
- seconden
- zien
- selectie
- halfgeleider
- sensor
- verscheidene
- Delen
- Aandelen
- moet
- vertoonde
- Silicium
- sinds
- single
- Klein
- So
- Software
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- enigszins
- bron
- Tussenruimte
- snelheid
- besteed
- stanford
- Stanford University
- startup
- Land
- state-of-the-art
- Stellar
- Still
- gestroomlijnd
- streng
- structuur
- Studie
- wezenlijk
- geslaagd
- ondersteuning
- ondersteunde
- Ondersteuning
- synchronisatie
- system
- tafel
- op maat gemaakt
- doelwit
- targeting
- Technisch
- Technologies
- neem contact
- dat
- De
- De toekomst
- hun
- Ze
- Er.
- Deze
- ze
- dit
- drie
- Door
- doorvoer
- strak
- niet de tijd of
- keer
- naar
- vandaag
- spoor
- traditioneel
- verkeer
- Trainingen
- transparant
- twee
- type dan:
- types
- typisch
- typisch
- unieke
- eenheden
- Universum
- universiteit-
- tot
- upgrade
- bruikbaar
- Gebruiker
- gebruik
- VC's
- onderneming
- venture capital
- Verificatie
- Tegen
- via
- rendabel
- virtueel
- volumes
- wachten
- Gevel
- was
- Manier..
- GOED
- wanneer
- en
- breed
- wensen
- Met
- binnen
- geschreven
- nog
- opbrengsten
- zephyrnet