Onderzoekers blijven nieuwe modelarchitecturen ontwikkelen voor algemene machine learning-taken (ML). Een van die taken is afbeeldingsclassificatie, waarbij afbeeldingen als invoer worden geaccepteerd en het model probeert de afbeelding als geheel te classificeren met objectlabeluitvoer. Met veel modellen die tegenwoordig beschikbaar zijn die deze beeldclassificatietaak uitvoeren, kan een ML-beoefenaar vragen stellen als: "Welk model moet ik verfijnen en vervolgens implementeren om de beste prestaties op mijn dataset te bereiken?" En een ML-onderzoeker kan vragen stellen als: "Hoe kan ik mijn eigen eerlijke vergelijking van meerdere modelarchitecturen maken met een gespecificeerde dataset terwijl ik hyperparameters voor training en computerspecificaties, zoals GPU's, CPU's en RAM, beheers?" De eerste vraag gaat over modelselectie in verschillende modelarchitecturen, terwijl de laatste vraag gaat over het benchmarken van getrainde modellen tegen een testdataset.
In dit bericht zie je hoe de TensorFlow-beeldclassificatie algoritme van Amazon SageMaker JumpStart kan de implementaties vereenvoudigen die nodig zijn om deze vragen aan te pakken. Samen met de uitvoeringsdetails in een corresponderende bijvoorbeeld Jupyter-notebook, heb je tools beschikbaar om modelselectie uit te voeren door pareto-grenzen te verkennen, waarbij het verbeteren van één prestatiemaatstaf, zoals nauwkeurigheid, niet mogelijk is zonder een andere maatstaf, zoals doorvoer, te verslechteren.
Overzicht oplossingen
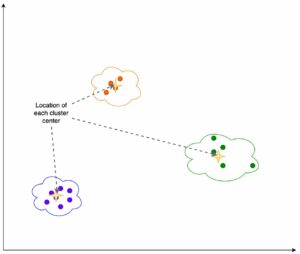
De volgende afbeelding illustreert de wisselwerking tussen modelselectie voor een groot aantal beeldclassificatiemodellen die nauwkeurig zijn afgesteld op de Caltech-256 dataset, een uitdagende set van 30,607 real-world afbeeldingen verspreid over 256 objectcategorieën. Elk punt vertegenwoordigt een enkel model, puntgroottes worden geschaald met betrekking tot het aantal parameters waaruit het model bestaat, en de punten hebben een kleurcode op basis van hun modelarchitectuur. De lichtgroene punten vertegenwoordigen bijvoorbeeld de EfficientNet-architectuur; elk lichtgroen punt is een andere configuratie van deze architectuur met uniek afgestemde modelprestatiemetingen. De figuur toont het bestaan van een pareto-grens voor modelselectie, waarbij hogere nauwkeurigheid wordt ingeruild voor lagere doorvoer. Uiteindelijk hangt de keuze van een model langs de pareto-grens, of de set pareto-efficiënte oplossingen, af van de prestatie-eisen van uw modelimplementatie.
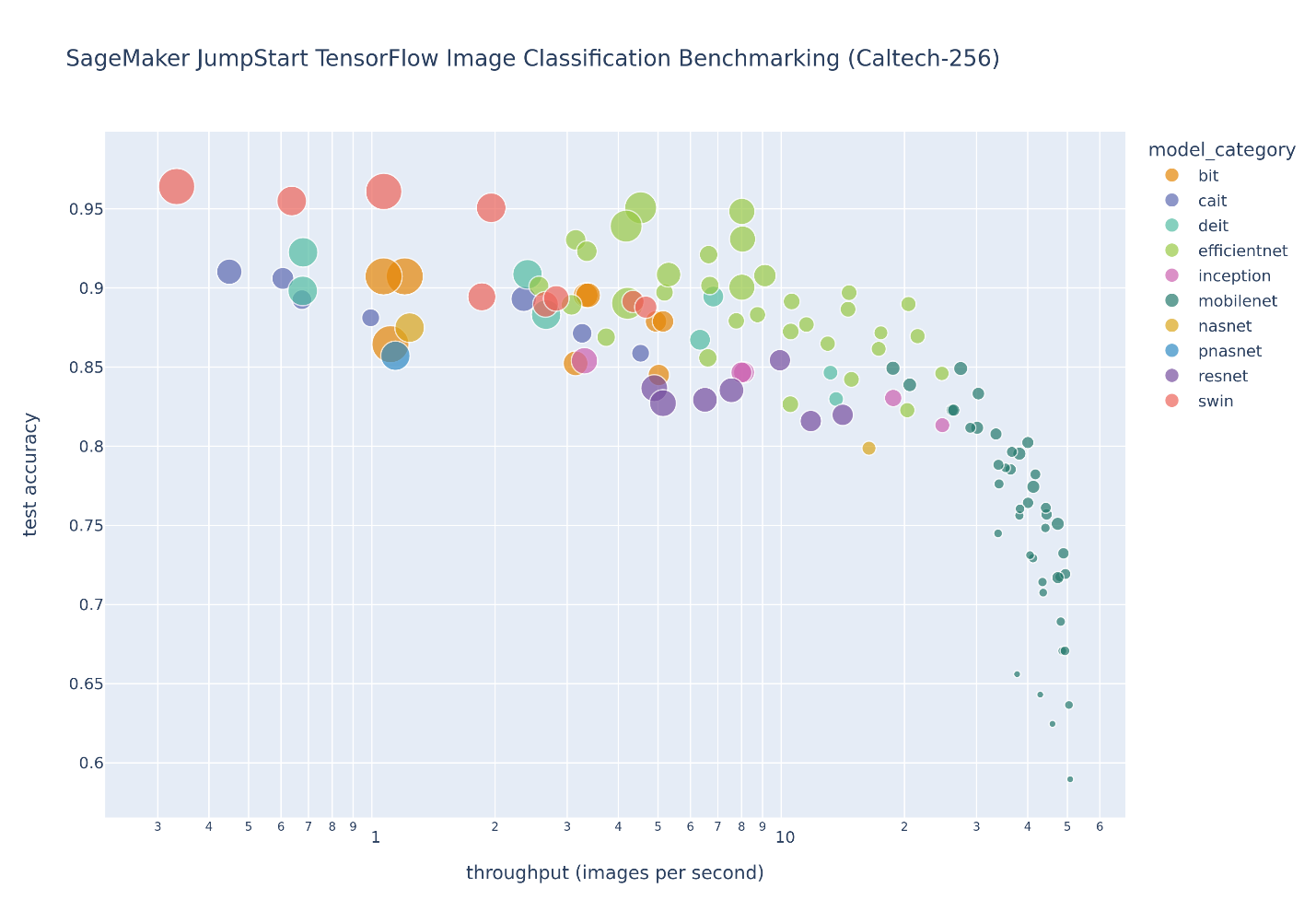
Als u de testnauwkeurigheid en testdoorvoergrenzen van belang observeert, wordt de reeks pareto-efficiënte oplossingen op de voorgaande afbeelding geëxtraheerd in de volgende tabel. Rijen worden zo gesorteerd dat de testdoorvoer toeneemt en de testnauwkeurigheid afneemt.
| Modelnaam | Aantal parameters | Nauwkeurigheid testen | Test top 5 nauwkeurigheid | Doorvoer (afbeeldingen/s) | Duur per Epoch(s) |
| swin-grote-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-grote-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| efficiëntnet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| efficiëntnet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| efficiëntnet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| efficiëntnet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| efficiëntnet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| efficiëntnet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| efficiëntnet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobielnet-v3-groot-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobielnet-v3-groot-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobielnet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobielnet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobielnet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobielnet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobielnet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobielnet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobielnet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobielnet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobielnet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobielnet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
Dit bericht bevat details over hoe u op grote schaal kunt implementeren Amazon Sage Maker benchmarking en modelselectietaken. Eerst introduceren we JumpStart en de ingebouwde TensorFlow-algoritmen voor beeldclassificatie. Vervolgens bespreken we implementatieoverwegingen op hoog niveau, zoals JumpStart-hyperparameterconfiguraties, metrische extractie van Amazon CloudWatch-logboeken, en het starten van asynchrone afstemmingsafstemmingstaken. Ten slotte behandelen we de implementatieomgeving en parametrisering die leiden tot de pareto-efficiënte oplossingen in de voorgaande tabel en figuur.
Inleiding tot JumpStart TensorFlow-beeldclassificatie
JumpStart biedt fijnafstemming en implementatie met één klik van een breed scala aan vooraf getrainde modellen voor populaire ML-taken, evenals een selectie van end-to-end-oplossingen die veelvoorkomende zakelijke problemen oplossen. Deze functies nemen het zware werk uit elke stap van het ML-proces weg, waardoor het gemakkelijker wordt om modellen van hoge kwaliteit te ontwikkelen en de tijd tot implementatie wordt verkort. De JumpStart-API's stelt u in staat om een uitgebreide selectie vooraf getrainde modellen programmatisch te implementeren en af te stemmen op uw eigen datasets.
De JumpStart-modelhub biedt toegang tot een groot aantal TensorFlow-beeldclassificatiemodellen die overdrachtsleren en fijnafstemming op aangepaste datasets mogelijk maken. Op het moment van schrijven bevat de JumpStart-modelhub 135 TensorFlow-beeldclassificatiemodellen voor een verscheidenheid aan populaire modelarchitecturen van TensorFlow-hub, om resterende netwerken op te nemen (ResNet), MobielNet, EfficiëntNet, Inception, Zoeknetwerken voor neurale architectuur (NASNet), grote overdracht (Beetje), verschoven venster (Zwijn) transformatoren, klasse-aandacht in beeldtransformatoren (Cait) en data-efficiënte beeldtransformatoren (DeiT).
Elke modelarchitectuur bestaat uit enorm verschillende interne structuren. ResNet-modellen maken bijvoorbeeld gebruik van skip-verbindingen om substantieel diepere netwerken mogelijk te maken, terwijl op transformator gebaseerde modellen zelf-aandachtsmechanismen gebruiken die de intrinsieke plaats van convolutieoperaties elimineren ten gunste van meer globale receptieve velden. Naast de diverse functiesets die deze verschillende structuren bieden, heeft elke modelarchitectuur verschillende configuraties die de grootte, vorm en complexiteit van het model binnen die architectuur aanpassen. Dit resulteert in honderden unieke beeldclassificatiemodellen die beschikbaar zijn op de JumpStart-modelhub. Gecombineerd met ingebouwde overdrachtsleer- en inferentiescripts die veel SageMaker-functies omvatten, is de JumpStart API een geweldig startpunt voor ML-beoefenaars om snel aan de slag te gaan met het trainen en implementeren van modellen.
Verwijzen naar Leren overdragen voor TensorFlow-beeldclassificatiemodellen in Amazon SageMaker en het volgende voorbeeld notebook om meer te weten te komen over SageMaker TensorFlow-beeldclassificatie, inclusief het uitvoeren van gevolgtrekkingen op een vooraf getraind model en het verfijnen van het vooraf getrainde model op een aangepaste dataset.
Overwegingen bij de selectie van grootschalige modellen
Modelselectie is het proces van het selecteren van het beste model uit een reeks kandidaat-modellen. Dit proces kan worden toegepast op modellen van hetzelfde type met verschillende parametergewichten en op modellen van verschillende typen. Voorbeelden van modelselectie tussen modellen van hetzelfde type zijn onder meer het aanpassen van hetzelfde model met verschillende hyperparameters (bijvoorbeeld leersnelheid) en het vroegtijdig stoppen om te voorkomen dat modelgewichten te veel in de treindataset passen. Modelselectie voor modellen van verschillende typen omvat het selecteren van de beste modelarchitectuur (bijvoorbeeld Swin vs. MobileNet) en het selecteren van de beste modelconfiguraties binnen een enkele modelarchitectuur (bijvoorbeeld mobilenet-v1-025-128 vs mobilenet-v3-large-100-224).
De overwegingen die in deze sectie worden beschreven, maken al deze modelselectieprocessen op een validatiegegevensset mogelijk.
Selecteer hyperparameterconfiguraties
TensorFlow-beeldclassificatie in JumpStart heeft een groot aantal beschikbaar hyperparameters die het gedrag van het leerscript voor overdracht uniform kan aanpassen voor alle modelarchitecturen. Deze hyperparameters hebben betrekking op gegevensaugmentatie en voorverwerking, optimalisatiespecificatie, overfittingcontroles en trainbare laagindicatoren. U wordt aangemoedigd om de standaardwaarden van deze hyperparameters zo nodig aan te passen voor uw toepassing:
Voor deze analyse en het bijbehorende notitieblok worden alle hyperparameters ingesteld op standaardwaarden, behalve de leersnelheid, het aantal tijdperken en de specificatie voor vroegtijdig stoppen. Leertempo wordt aangepast als een categorische parameter Door de Automatische afstemming van SageMaker-modellen functie. Omdat elk model unieke standaard hyperparameterwaarden heeft, bevat de discrete lijst met mogelijke leersnelheden zowel de standaard leersnelheid als een vijfde van de standaard leersnelheid. Hierdoor worden twee trainingstaken gestart voor één taak voor het afstemmen van hyperparameters en wordt de trainingstaak met de best gerapporteerde prestaties op de validatiegegevensset geselecteerd. Omdat het aantal tijdperken is ingesteld op 10, wat groter is dan de standaard hyperparameterinstelling, komt de geselecteerde beste trainingstaak niet altijd overeen met het standaard leertempo. Ten slotte wordt een vroegtijdig stopcriterium gebruikt met een geduld, of het aantal tijdperken om door te gaan met trainen zonder verbetering, van drie tijdperken.
Een standaard hyperparameterinstelling die van bijzonder belang is, is train_only_on_top_layer, waar, indien ingesteld op True, zijn de functie-extractielagen van het model niet nauwkeurig afgestemd op de verstrekte trainingsdataset. De optimizer traint alleen parameters in de bovenste volledig verbonden classificatielaag met output-dimensionaliteit die gelijk is aan het aantal klasselabels in de dataset. Deze hyperparameter is standaard ingesteld op True, wat een instelling is die is gericht op overdrachtsleren op kleine datasets. Mogelijk hebt u een aangepaste dataset waarbij de extractie van functies uit de pre-training op de ImageNet-dataset niet voldoende is. In deze gevallen moet u instellen train_only_on_top_layer naar False. Hoewel deze instelling de trainingstijd verlengt, haalt u er meer betekenisvolle kenmerken uit voor uw interesseprobleem, waardoor de nauwkeurigheid toeneemt.
Meetgegevens extraheren uit CloudWatch-logboeken
Het JumpStart TensorFlow-algoritme voor beeldclassificatie registreert op betrouwbare wijze een verscheidenheid aan statistieken tijdens de training die toegankelijk zijn voor SageMaker Estimator en HyperparameterTuner-objecten. De constructeur van een SageMaker Estimator een metric_definitions trefwoordargument, dat kan worden gebruikt om de trainingstaak te evalueren door een lijst met woordenboeken met twee sleutels te bieden: Naam voor de naam van de metriek, en Regex voor de reguliere expressie die wordt gebruikt om de metriek uit de logboeken te extraheren. De begeleidende notitieboekje toont de uitvoeringsdetails. De volgende tabel geeft een overzicht van de beschikbare statistieken en bijbehorende reguliere expressies voor alle JumpStart TensorFlow-beeldclassificatiemodellen.
| Metrische naam | Regular Expression |
| aantal parameters | "- Aantal parameters: ([0-9\.]+)" |
| aantal trainbare parameters | "- Aantal trainbare parameters: ([0-9\.]+)" |
| aantal niet-trainbare parameters | "- Aantal niet-trainbare parameters: ([0-9\.]+)" |
| train dataset-metriek | f”- {metrisch}: ([0-9\.]+)” |
| validatie dataset-metriek | f”- val_{metrisch}: ([0-9\.]+)” |
| meetgegevensset testen | f”- Test {metrisch}: ([0-9\.]+)” |
| trein duur | “- Totale trainingsduur: ([0-9\.]+)” |
| treinduur per tijdperk | “- Gemiddelde trainingsduur per tijdvak: ([0-9\.]+)” |
| test evaluatie latentie | "- Testevaluatielatentie: ([0-9\.]+)" |
| testlatentie per monster | "- Gemiddelde testlatentie per sample: ([0-9\.]+)" |
| doorvoer testen | "- Gemiddelde testdoorvoer: ([0-9\.]+)" |
Het ingebouwde overdrachtsleerscript biedt binnen deze definities een verscheidenheid aan trein-, validatie- en testgegevenssetstatistieken, zoals weergegeven door de f-string-vervangingswaarden. De exacte beschikbare statistieken variëren op basis van het type classificatie dat wordt uitgevoerd. Alle gecompileerde modellen hebben een loss metriek, die wordt weergegeven door een cross-entropieverlies voor een binair of categorisch classificatieprobleem. De eerste wordt gebruikt als er één klassenlabel is; de laatste wordt gebruikt als er twee of meer klassenlabels zijn. Als er slechts één klasselabel is, worden de volgende metrieken berekend, gelogd en kunnen worden geëxtraheerd via de f-string reguliere expressies in de voorgaande tabel: aantal terecht positieven (true_pos), aantal valse positieven (false_pos), aantal echt negatieven (true_neg), aantal fout-negatieven (false_neg), precision, recall, oppervlakte onder de ROC-curve (receiver operating Characteristic) (auc), en het gebied onder de precisie-terugroepcurve (PR) (prc). Evenzo, als er zes of meer klassenlabels zijn, wordt een top-5 nauwkeurigheidsmetriek (top_5_accuracy) kan ook worden berekend, gelogd en geëxtraheerd via de voorgaande reguliere expressies.
Tijdens de training worden statistieken opgegeven voor een SageMaker Estimator worden verzonden naar CloudWatch Logs. Wanneer de training is voltooid, kunt u een beroep doen op de SageMaker BeschrijvingTrainingJob API en inspecteer de FinalMetricDataList toets het JSON-antwoord in:
Deze API vereist dat alleen de taaknaam aan de query wordt verstrekt, dus na voltooiing kunnen statistieken worden verkregen in toekomstige analyses, zolang de naam van de trainingstaak op de juiste manier wordt geregistreerd en kan worden hersteld. Voor deze modelselectietaak worden taaknamen voor het afstemmen van hyperparameters opgeslagen en daaropvolgende analyses koppelen een HyperparameterTuner object met de naam van de afstemmingstaak, extraheer de beste trainingstaaknaam uit de gekoppelde hyperparameter-tuner en roep vervolgens de DescribeTrainingJob API zoals eerder beschreven om statistieken te verkrijgen die zijn gekoppeld aan de beste trainingstaak.
Start asynchrone afstemmingsafstemmingstaken
Raadpleeg de overeenkomstige notitieboekje voor implementatiedetails over het asynchroon starten van taken voor het afstemmen van hyperparameters, waarbij gebruik wordt gemaakt van de standaardbibliotheek van Python gelijktijdige futures module, een interface op hoog niveau voor asynchroon lopende callables. In deze oplossing zijn verschillende SageMaker-gerelateerde overwegingen geïmplementeerd:
- Elk AWS-account is aangesloten bij SageMaker-servicequota. U dient uw huidige limieten te bekijken om uw resources volledig te benutten en indien nodig een verhoging van de resourcelimiet aan te vragen.
- Frequente API-aanroepen om veel gelijktijdige hyperparameter-afstemmingstaken te maken, kunnen overschrijdt de Python SDK-snelheid en genereert beperkingsuitzonderingen. Een oplossing hiervoor is het maken van een SageMaker Boto3-client met een aangepaste configuratie voor opnieuw proberen.
- Wat gebeurt er als uw script een fout tegenkomt of als het script wordt gestopt voordat het is voltooid? Voor zo'n grote modelselectie of benchmarkonderzoek kunt u namen van afstemmingstaken vastleggen en gemaksfuncties bieden herbevestig hyperparameter tuning jobs die al bestaan:
Analyse details en discussie
De analyse in dit bericht voert overdrachtsleren uit voor model-ID's in het JumpStart TensorFlow-beeldclassificatie-algoritme op de Caltech-256-dataset. Alle trainingstaken zijn uitgevoerd op de SageMaker-trainingsinstantie ml.g4dn.xlarge, die een enkele NVIDIA T4 GPU bevat.
De testgegevensset wordt aan het einde van de training geëvalueerd op het trainingsexemplaar. Modelselectie wordt uitgevoerd voorafgaand aan de evaluatie van de testdataset om modelgewichten in te stellen op het tijdperk met de beste validatiesetprestaties. Testdoorvoer is niet geoptimaliseerd: de batchgrootte van de dataset is ingesteld op de standaard trainingshyperparameterbatchgrootte, die niet is aangepast om het GPU-geheugengebruik te maximaliseren; gerapporteerde testdoorvoer is inclusief laadtijd van gegevens omdat de dataset niet vooraf in de cache is opgeslagen; en gedistribueerde inferentie over meerdere GPU's wordt niet gebruikt. Om deze redenen is deze doorvoer een goede relatieve meting, maar de daadwerkelijke doorvoer is sterk afhankelijk van de implementatieconfiguraties van uw inferentie-eindpunt voor het getrainde model.
Hoewel de JumpStart-modelhub veel typen architectuur voor beeldclassificatie bevat, wordt deze pareto-grens gedomineerd door geselecteerde Swin-, EfficientNet- en MobileNet-modellen. Swin-modellen zijn groter en relatief nauwkeuriger, terwijl MobileNet-modellen kleiner, relatief minder nauwkeurig en geschikt zijn voor de beperkte middelen van mobiele apparaten. Het is belangrijk op te merken dat deze grens afhankelijk is van verschillende factoren, waaronder de exacte gebruikte dataset en de geselecteerde hyperparameters voor fijnafstemming. Het kan zijn dat uw aangepaste dataset een andere set pareto-efficiënte oplossingen oplevert en dat u langere trainingstijden wenst met verschillende hyperparameters, zoals meer gegevensvergroting of meer fijnafstemming dan alleen de bovenste classificatielaag van het model.
Conclusie
In dit bericht hebben we laten zien hoe u grootschalige modelselectie of benchmarkingtaken kunt uitvoeren met behulp van de JumpStart-modelhub. Deze oplossing kan u helpen bij het kiezen van het beste model voor uw behoeften. We moedigen je aan om dit uit te proberen en te verkennen oplossing op je eigen dataset.
Referenties
Meer informatie is beschikbaar op de volgende bronnen:
Over de auteurs
 Dr Kyle Ulrich is een Applied Scientist met de Ingebouwde algoritmen van Amazon SageMaker team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
Dr Kyle Ulrich is een Applied Scientist met de Ingebouwde algoritmen van Amazon SageMaker team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
 Dr Ashish Khetan is een Senior Applied Scientist met Ingebouwde algoritmen van Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij promoveerde aan de University of Illinois Urbana Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
Dr Ashish Khetan is een Senior Applied Scientist met Ingebouwde algoritmen van Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij promoveerde aan de University of Illinois Urbana Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- Over
- toegang
- beschikbaar
- Account
- nauwkeurigheid
- accuraat
- Bereiken
- over
- actieve
- toevoeging
- adres
- adressen
- gecorrigeerd
- Aangesloten
- tegen
- algoritme
- algoritmen
- Alles
- al
- Hoewel
- altijd
- Amazone
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- analyse
- en
- Nog een
- api
- Aanvraag
- toegepast
- op gepaste wijze
- architectuur
- GEBIED
- argument
- geassocieerd
- hechten
- pogingen
- Automatisch
- Beschikbaar
- gemiddelde
- AWS
- gebaseerde
- Bayesian
- omdat
- vaardigheden
- wezen
- BEST
- Groot
- ingebouwd
- bedrijfsdeskundigen
- oproepen
- kandidaat
- gevallen
- categorieën
- uitdagend
- karakteristiek
- Kies
- klasse
- classificatie
- classificeren
- klant
- gecombineerde
- Gemeen
- vergelijking
- compleet
- Voltooid
- voltooiing
- ingewikkeldheid
- computer
- Computer visie
- Zorgen
- conferenties
- Configuratie
- gekoppeld blijven
- aansluitingen
- overwegingen
- beperkingen
- bevat
- voortzetten
- het regelen van
- controles
- gemak
- Overeenkomend
- deksel
- en je merk te creëren
- Actueel
- curve
- gewoonte
- gegevens
- datasets
- diepere
- Standaard
- afhankelijk
- implementeren
- het inzetten
- inzet
- diepte
- beschreven
- beschrijving
- gegevens
- ontwikkelen
- systemen
- anders
- bespreken
- verdeeld
- diversen
- Nee
- Hertog
- Duke universiteit
- gedurende
- elk
- Vroeger
- Vroeg
- gemakkelijker
- doeltreffend
- beide
- elimineren
- in staat stellen
- aanmoedigen
- aangemoedigd
- eind tot eind
- Endpoint
- Milieu
- tijdperk
- tijdperken
- fout
- Ether (ETH)
- schatten
- geëvalueerd
- evaluatie
- voorbeeld
- voorbeelden
- Behalve
- Verken
- Verkennen
- uitdrukkingen
- extract
- extractie
- factoren
- eerlijk
- Favor
- Kenmerk
- Voordelen
- Velden
- Figuur
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- fitting
- volgend
- Voormalig
- oppompen van
- Grens
- Frontiers
- geheel
- functies
- toekomst
- Futures
- voortbrengen
- krijgen
- gegeven
- Globaal
- goed
- GPU
- GPU's
- groot
- meer
- Groen
- gebeurt
- hard
- hulp
- helpt
- high-level
- hoogwaardige
- hoger
- Hoe
- How To
- HTML
- HTTPS
- Naaf
- Honderden
- Hyperparameter afstemmen
- ICLR
- Illinois
- beeld
- Afbeeldingsclassificatie
- IMAGEnet
- afbeeldingen
- uitvoeren
- uitvoering
- geïmplementeerd
- belang
- belangrijk
- verbetering
- het verbeteren van
- in
- omvatten
- omvat
- Inclusief
- Laat uw omzet
- Verhoogt
- meer
- indicatoren
- informatie
- invoer
- instantie
- belang
- belangen
- Interface
- intern
- intrinsiek
- voorstellen
- IT
- Jobomschrijving:
- Vacatures
- json
- sleutel
- toetsen
- label
- labels
- Groot
- grootschalig
- groter
- Wachttijd
- lanceert
- lancering
- lagen
- Legkippen
- leidend
- LEARN
- leren
- facelift
- licht
- LIMIT
- grenzen
- Lijst
- lijsten
- het laden
- lang
- langer
- uit
- machine
- machine learning
- maken
- veel
- Maximaliseren
- zinvolle
- maten
- Geheugen
- metriek
- Metriek
- ML
- Mobile
- mobiele toestellen
- model
- modellen
- module
- meer
- meervoudig
- naam
- namen
- noodzakelijk
- nodig
- behoeften
- netwerken
- Neural
- NeurIPS
- New
- notitieboekje
- aantal
- Nvidia
- object
- objecten
- waarnemen
- verkrijgen
- verkregen
- EEN
- werkzaam
- Operations
- geoptimaliseerde
- geschetst
- het te bezitten.
- papieren
- parameter
- parameters
- bijzonder
- Geduld
- uitvoeren
- prestatie
- presteert
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- punten
- Populair
- mogelijk
- Post
- mogelijk
- pr
- voorkomen
- Voorafgaand
- probleem
- problemen
- processen
- zorgen voor
- mits
- biedt
- het verstrekken van
- gepubliceerde
- Python
- vraag
- Contact
- snel
- RAM
- tarief
- Tarieven
- echte wereld
- redenen
- vermindering
- regelmatig
- relatief
- verwijderen
- gemeld
- vertegenwoordigen
- vertegenwoordigd
- vertegenwoordigt
- te vragen
- nodig
- Voorwaarden
- vereist
- onderzoek
- onderzoeker
- Resolutie
- hulpbron
- Resources
- antwoord
- Resultaten
- lopen
- lopend
- sagemaker
- dezelfde
- schaalbare
- Wetenschapper
- scripts
- sdk
- Ontdek
- sectie
- gekozen
- selecteren
- selectie
- senior
- -Series
- service
- Sessie
- reeks
- Sets
- het instellen van
- verscheidene
- Vorm
- moet
- Shows
- evenzo
- vereenvoudigen
- simultaan
- single
- ZES
- Maat
- maten
- Klein
- kleinere
- So
- oplossing
- Oplossingen
- OPLOSSEN
- specificatie
- specificaties
- gespecificeerd
- standaard
- gestart
- statistisch
- Stap voor
- gestopt
- stoppen
- opgeslagen
- Studie
- volgend
- wezenlijk
- dergelijk
- voldoende
- geschikt
- tafel
- doelgerichte
- Taak
- taken
- team
- tensorflow
- proef
- De
- hun
- daarbij
- drie
- doorvoer
- niet de tijd of
- Tijdreeksen
- keer
- naar
- vandaag
- samen
- tools
- top
- top 5
- Totaal
- Trainen
- getraind
- Trainingen
- overdracht
- transformers
- waar
- types
- Tenslotte
- voor
- unieke
- universiteit-
- Gebruik
- .
- gebruik maken van
- gebruikt
- bevestiging
- Values
- variëteit
- groot
- via
- Bekijk
- visie
- welke
- en
- breed
- wil
- binnen
- zonder
- zou
- het schrijven van
- Your
- zephyrnet