Terwijl OpenAI ChatGPT alle zuurstof uit de 24-uurs nieuwscyclus zuigt, heeft Google stilletjes een nieuw AI-model onthuld dat video's kan genereren wanneer video-, beeld- en tekstinvoer wordt gegeven. De nieuwe Google Dreamix AI-video-editor brengt gegenereerde video nu dichter bij de realiteit.
Volgens het onderzoek dat op GitHub is gepubliceerd, bewerkt Dreamix de video op basis van een video en een tekstprompt. De resulterende video behoudt zijn trouw aan kleur, houding, objectgrootte en camerahouding, wat resulteert in een tijdelijk consistente video. Op dit moment kan Dreamix geen video's genereren op basis van een prompt, maar het kan bestaand materiaal gebruiken en de video aanpassen met behulp van tekstprompts.
Google gebruikt videodiffusiemodellen voor Dreamix, een benadering die met succes is toegepast voor de meeste videobeeldbewerking die we zien in beeld-AI's zoals DALL-E2 of de open-source Stable Diffusion.
De aanpak houdt in dat de ingevoerde video sterk wordt gereduceerd, kunstmatige ruis wordt toegevoegd en vervolgens wordt verwerkt in een videodiffusiemodel, dat vervolgens een tekstprompt gebruikt om er een nieuwe video van te genereren die sommige eigenschappen van de originele video behoudt en andere opnieuw weergeeft volgens naar de tekstinvoer.
Het videodiffusiemodel biedt een veelbelovende toekomst die een nieuw tijdperk kan inluiden voor het werken met video's.

In de onderstaande video verandert Dreamix bijvoorbeeld de etende aap (links) in een dansende beer (rechts) gezien de prompt "Een beer die danst en springt op vrolijke muziek, zijn hele lichaam beweegt."
In een ander voorbeeld hieronder gebruikt Dreamix een enkele foto als sjabloon (zoals in beeld-naar-video) en een object wordt er vervolgens van geanimeerd in een video via een prompt. Ook in de nieuwe scène of een latere time-lapse-opname zijn camerabewegingen mogelijk.
In een ander voorbeeld verandert Dreamix de orang-oetan in een plas water (links) in een orang-oetan met oranje haar die baadt in een prachtige badkamer.
“Hoewel diffusiemodellen met succes zijn toegepast voor beeldbewerking, zijn er maar heel weinig werken die dit hebben gedaan voor videobewerking. We presenteren de eerste op diffusie gebaseerde methode die in staat is om op tekst gebaseerde bewegings- en uiterlijkbewerking van algemene video's uit te voeren."
Volgens de onderzoekspaper van Google gebruikt Dreamix een videodiffusiemodel om op het moment van inferentie de spatiotemporele informatie met lage resolutie van de originele video te combineren met nieuwe informatie met hoge resolutie die is gesynthetiseerd om af te stemmen op de begeleidende tekstprompt.
Google zei dat het deze aanpak heeft gekozen omdat "het verkrijgen van high-fidelity van de originele video vereist dat een deel van de hoge-resolutie-informatie behouden blijft. We voegen een voorbereidende fase toe van het verfijnen van het model op de originele video, waardoor de betrouwbaarheid aanzienlijk wordt verbeterd."
Hieronder vindt u een video-overzicht van hoe Dreamix werkt.
[Ingesloten inhoud]
Hoe Dreamix-videoverspreidingsmodellen werken
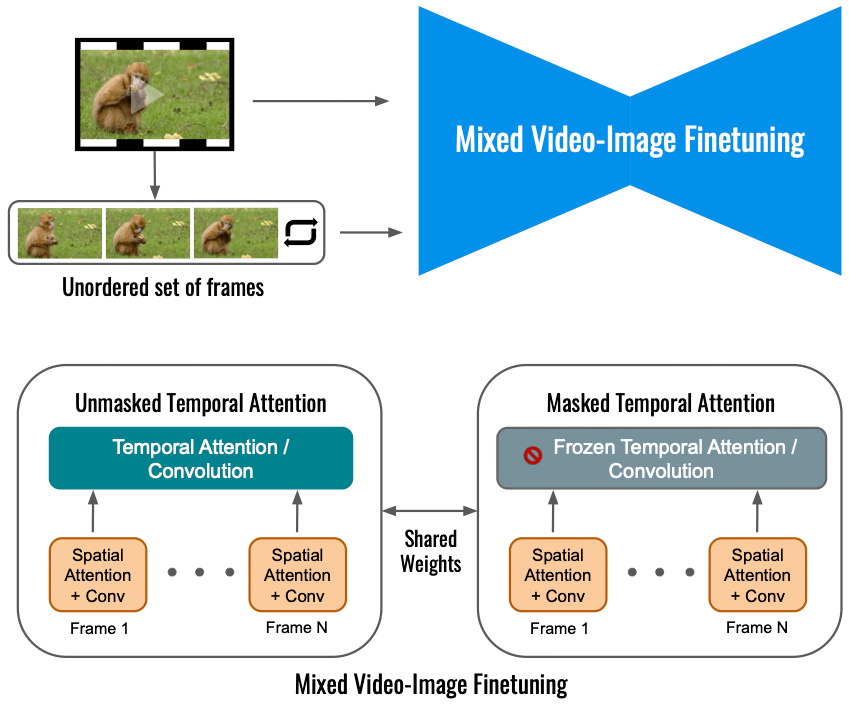
Volgens Google beperkt het verfijnen van het videodiffusiemodel voor Dreamix alleen op de invoervideo de mate van bewegingsverandering. In plaats daarvan gebruiken we een gemengd objectief dat naast het oorspronkelijke objectief (linksonder) ook de ongeordende reeks frames verfijnt. Dit wordt gedaan door gebruik te maken van "gemaskeerde temporele aandacht", waardoor wordt voorkomen dat de temporele aandacht en convolutie worden verfijnd (rechtsonder). Hiermee kunt u beweging toevoegen aan een statische video.
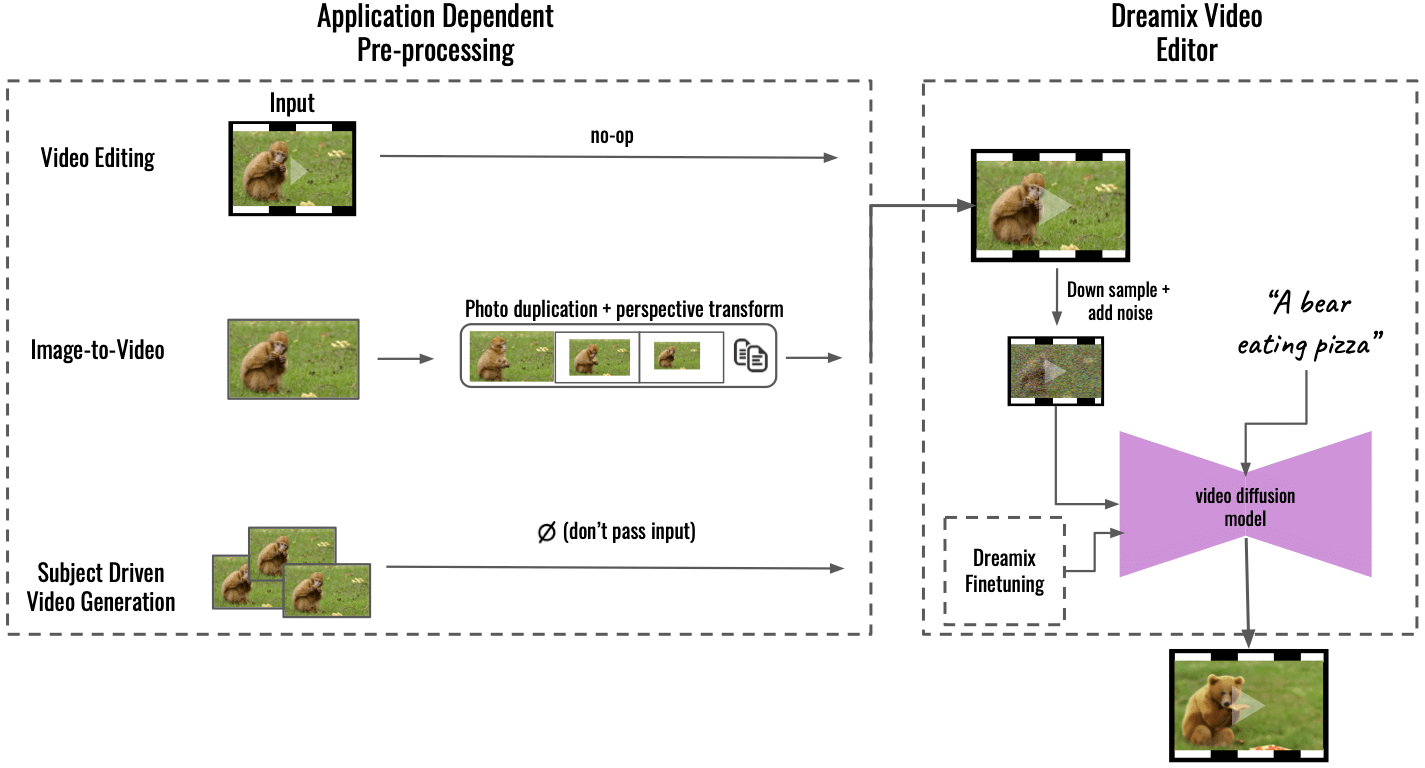
“Onze methode ondersteunt meerdere toepassingen door toepassingsafhankelijke voorbewerking (links), waarbij de ingevoerde inhoud wordt omgezet in een uniform videoformaat. Voor beeld-naar-video wordt het invoerbeeld gedupliceerd en getransformeerd met behulp van perspectieftransformaties, waardoor een grove video wordt gesynthetiseerd met wat camerabeweging. Voor onderwerpgestuurde videogeneratie wordt de invoer weggelaten - alleen fijnafstemming zorgt voor de getrouwheid. Deze grove video wordt vervolgens bewerkt met onze algemene "Dreamix Video Editor" (rechts): we corrumperen de video eerst door downsampling en vervolgens voegen we ruis toe. Vervolgens passen we het verfijnde tekstgestuurde videodiffusiemodel toe, dat de video opschaalt naar de uiteindelijke spatiotemporele resolutie, "schreef Dream op GitHub.
Hieronder kunt u het onderzoeksartikel lezen.
Google Dreamix- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- in staat
- Volgens
- AI
- een video
- AI-powered
- Alles
- toestaat
- alleen
- en
- Nog een
- toepassingen
- toegepast
- Solliciteer
- nadering
- kunstmatig
- aandacht
- gebaseerde
- Beer
- prachtige
- omdat
- wezen
- onder
- lichaam
- het stimuleren
- Onder
- Brengt
- camera
- kan niet
- verzorging
- verandering
- ChatGPT
- dichterbij
- kleur
- combineren
- consequent
- content
- Wij creëren
- cyclus
- Dansen
- Verspreiding
- droom
- editor
- ingebed
- Tijdperk
- voorbeeld
- bestaand
- weinig
- trouw
- finale
- Voornaam*
- gevolgd
- formaat
- oppompen van
- toekomst
- Algemeen
- voortbrengen
- gegenereerde
- generatie
- gif
- GitHub
- gegeven
- Kopen Google Reviews
- Haar
- hard
- hoge-resolutie
- Hoe
- Echter
- HTTPS
- beeld
- afbeeldingen
- in
- informatie
- invoer
- verkrijgen in plaats daarvan
- IT
- lanceert
- grenzen
- onderhoudt
- materiaal
- max
- methode
- gemengd
- model
- modellen
- wijzigen
- moment
- meest
- beweging
- bewegingen
- bewegend
- meervoudig
- Muziek
- New
- nieuws
- Geluid
- object
- doel van de persoon
- Aanbod
- open source
- OpenAI
- Oranje
- origineel
- Overig
- overzicht
- Zuurstof
- Papier
- uitvoeren
- perspectief
- Plato
- Plato gegevensintelligentie
- PlatoData
- zwembad
- mogelijk
- presenteren
- het voorkomen van
- verwerking
- veelbelovend
- vastgoed
- gepubliceerde
- rustig
- Lees
- Realiteit
- opname
- vermindering
- vereist
- onderzoek
- Resolutie
- verkregen
- behoudende
- Zei
- scène
- reeks
- aanzienlijk
- single
- Maat
- So
- sommige
- stabiel
- Stadium
- volgend
- Met goed gevolg
- dergelijk
- steunen
- Nemen
- sjabloon
- De
- niet de tijd of
- naar
- transformaties
- getransformeerd
- onthuld
- .
- via
- Video
- Video's
- Water
- welke
- werkzaam
- Bedrijven
- youtube
- zephyrnet











