Amazon roodverschuiving is een volledig beheerd cloud-datawarehouse op petabyte-schaal dat door tienduizenden klanten wordt gebruikt om elke dag exabytes aan gegevens te verwerken om hun analysewerklast te ondersteunen. U kunt uw gegevens structureren, bedrijfsprocessen meten en snel waardevolle inzichten krijgen door een dimensionaal model te gebruiken. Amazon Redshift biedt ingebouwde functies om het proces van modellering, orkestratie en rapportage vanuit een dimensionaal model te versnellen.
In dit bericht bespreken we hoe u een dimensionaal model implementeert, met name de Kimball-methodiek. We bespreken implementatiedimensies en feiten binnen Amazon Redshift. We laten zien hoe u extract, transform en load (ELT) uitvoert, een integratieproces dat erop gericht is de onbewerkte gegevens van een datameer in een staging-laag te krijgen om de modellering uit te voeren. Over het algemeen geeft het bericht je een duidelijk inzicht in het gebruik van dimensionale modellering in Amazon Redshift.
Overzicht oplossingen
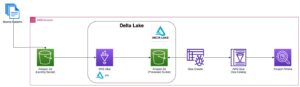
Het volgende diagram illustreert de oplossingsarchitectuur.

In de volgende paragrafen bespreken en demonstreren we eerst de belangrijkste aspecten van het dimensionale model. Daarna maken we een datamart met behulp van Amazon Redshift met een dimensionaal datamodel inclusief dimensie- en feitentabellen. Gegevens worden geladen en geënsceneerd met behulp van de COPY opdracht, worden de gegevens in de dimensies geladen met behulp van de MERGE statement, en feiten worden gekoppeld aan de dimensies waar inzichten aan worden ontleend. We plannen het laden van de dimensies en feiten met behulp van de Amazon Redshift Query-editor V2. Als laatste gebruiken we Amazon QuickSight om inzicht te krijgen in de gemodelleerde gegevens in de vorm van een QuickSight-dashboard.
Voor deze oplossing gebruiken we een voorbeelddataset (genormaliseerd) van Amazon Redshift voor de verkoop van kaartjes voor evenementen. Voor dit bericht hebben we de dataset verkleind voor eenvoud en demonstratiedoeleinden. De volgende tabellen tonen voorbeelden van de gegevens voor kaartverkoop en locaties.


Volgens de Kimball-methodiek voor dimensionale modellering, zijn er vier belangrijke stappen bij het ontwerpen van een dimensionaal model:
- Identificeer het bedrijfsproces.
- Verklaar de kern van uw gegevens.
- Identificeer en implementeer de dimensies.
- Identificeer en implementeer de feiten.
Daarnaast voegen we een vijfde stap toe voor demonstratiedoeleinden, namelijk het rapporteren en analyseren van zakelijke gebeurtenissen.
Voorwaarden
Voor deze walkthrough moet u aan de volgende vereisten voldoen:
Identificeer het bedrijfsproces
Eenvoudig gezegd is het identificeren van het bedrijfsproces het identificeren van een meetbare gebeurtenis die gegevens binnen een organisatie genereert. Meestal hebben bedrijven een soort operationeel bronsysteem dat hun gegevens in onbewerkt formaat genereert. Dit is een goed uitgangspunt om verschillende bronnen voor een bedrijfsproces te identificeren.
Het bedrijfsproces wordt dan voortgezet als een data mart in de vorm van dimensies en feiten. Als we naar onze eerder genoemde voorbeelddataset kijken, kunnen we duidelijk zien dat het bedrijfsproces bestaat uit de verkopen voor een bepaald evenement.
Een veel gemaakte fout is het gebruik van afdelingen van een bedrijf als het bedrijfsproces. De gegevens (bedrijfsproces) moeten over verschillende afdelingen worden geïntegreerd, in dit geval heeft marketing toegang tot de verkoopgegevens. Het identificeren van het juiste bedrijfsproces is van cruciaal belang. Als u deze stap verkeerd uitvoert, kan dit van invloed zijn op de hele datamart (het kan ertoe leiden dat de korrel wordt gedupliceerd en dat er onjuiste statistieken in de eindrapporten staan).
Verklaar de kern van uw gegevens
Het declareren van de korrel is het uniek identificeren van een record in uw gegevensbron. Het graan wordt gebruikt in de feitentabel om de gegevens nauwkeurig te meten en u in staat te stellen verder op te rollen. In ons voorbeeld kan dit een regelitem zijn in het verkoopbedrijfsproces.
In onze use case kan een verkoop op unieke wijze worden geïdentificeerd door te kijken naar het transactietijdstip waarop de verkoop plaatsvond; dit zal het meest atomaire niveau zijn.

Identificeer en implementeer de dimensies
Uw dimensietabel beschrijft uw feitentabel en de bijbehorende attributen. Wanneer u de beschrijvende context van uw bedrijfsproces identificeert, slaat u de tekst op in een aparte tabel, rekening houdend met de feitentabel. Bij het samenvoegen van de dimensietabel met de feitentabel mag er slechts één rij aan de feitentabel zijn gekoppeld. In ons voorbeeld gebruiken we de volgende tabel om te scheiden in een dimensietabel; deze velden beschrijven de feiten die we gaan meten.
Bij het ontwerpen van de structuur van het dimensionale model (het schema), kunt u ofwel een ster or sneeuwvlok schema. De structuur moet nauw aansluiten bij het bedrijfsproces; daarom past een sterschema het beste bij ons voorbeeld. De volgende afbeelding toont ons Entity Relationship Diagram (ERD).

In de volgende secties beschrijven we de stappen om de dimensies te implementeren.
Stage de brongegevens
Voordat we de dimensietabel kunnen maken en laden, hebben we brongegevens nodig. Daarom plaatsen we de brongegevens in een staging- of tijdelijke tabel. Dit wordt vaak de staging laag, de onbewerkte kopie van de brongegevens. Om dit in Amazon Redshift te doen, gebruiken we de COPY commando om de gegevens te laden uit de openbare S3-bucket met dimensionale modellering in amazon-redshift op de us-east-1 Regio. Merk op dat het COPY-commando een AWS Identiteits- en toegangsbeheer (IAM) rol mee toegang tot Amazon S3. De rol moet zijn gekoppeld aan de cluster. Voer de volgende stappen uit om de brongegevens te stagen:
- Maak de
venuebrontabel:
- Laad de locatiegegevens:
- Maak de
salesbrontabel:
- Laad de verkoopbrongegevens:
- Maak de
calendartafel:
- Laad de kalendergegevens:
Maak de maattabel
Het ontwerpen van de dimensietabel kan afhangen van uw zakelijke vereisten. Moet u bijvoorbeeld wijzigingen in de gegevens in de loop van de tijd bijhouden? Er zijn zeven verschillende soorten dimensies. Voor ons voorbeeld gebruiken we soort 1 omdat we geen historische veranderingen hoeven bij te houden. Voor meer informatie over type 2, zie Vereenvoudig het laden van gegevens in Type 2 langzaam veranderende dimensies in Amazon Redshift. De dimensietabel wordt gedenormaliseerd met een primaire sleutel, een surrogaatsleutel en een paar toegevoegde velden om wijzigingen in de tabel aan te geven. Zie de volgende code:
Een paar opmerkingen over het maken van de dimensietabel:
- De veldnamen worden omgezet in bedrijfsvriendelijke namen
- Onze belangrijkste sleutel is
VenueID, die we gebruiken om op unieke wijze een locatie te identificeren waar de verkoop plaatsvond - Er worden twee extra rijen toegevoegd, die aangeven wanneer een record is ingevoegd en bijgewerkt (om wijzigingen bij te houden)
- We gebruiken een AUTO-distributiestijl om Amazon Redshift de verantwoordelijkheid te geven om de distributiestijl te kiezen en aan te passen
Een andere belangrijke factor om rekening mee te houden bij dimensionaal modelleren is het gebruik van vervangende sleutels. Surrogaatsleutels zijn kunstmatige sleutels die worden gebruikt bij dimensionale modellering om elk record in een dimensietabel uniek te identificeren. Ze worden doorgaans gegenereerd als een opeenvolgend geheel getal en hebben geen enkele betekenis in het zakelijke domein. Ze bieden verschillende voordelen, zoals het garanderen van uniciteit en het verbeteren van de prestaties in joins, omdat ze doorgaans kleiner zijn dan natuurlijke sleutels en als surrogaatsleutels ze niet in de loop van de tijd veranderen. Dit stelt ons in staat om consistent te zijn en feiten en dimensies gemakkelijker te verbinden.
In Amazon Redshift worden surrogaatsleutels meestal gemaakt met behulp van het IDENTITY-sleutelwoord. De voorgaande instructie CREATE maakt bijvoorbeeld een dimensietabel met een VenueSkey vervangende sleutel. De VenueSkey kolom wordt automatisch gevuld met unieke waarden als er nieuwe rijen aan de tabel worden toegevoegd. Deze kolom kan vervolgens worden gebruikt om de locatietafel aan te sluiten op de FactSaleTransactions tafel.
Enkele tips voor het ontwerpen van surrogaatsleutels:
- Gebruik een klein gegevenstype met een vaste breedte voor de surrogaatsleutel. Dit zal de prestaties verbeteren en de opslagruimte verminderen.
- Gebruik het sleutelwoord IDENTITY of genereer de surrogaatsleutel met een sequentiële of GUID-waarde. Dit zorgt ervoor dat de surrogaatsleutel uniek is en niet kan worden gewijzigd.
Laad de dimtabel met MERGE
Er zijn talloze manieren om uw dimtafel te laden. Er moet rekening worden gehouden met bepaalde factoren, bijvoorbeeld prestaties, gegevensvolume en misschien SLA-laadtijden. Met de MERGE instructie, voeren we een upsert uit zonder dat we meerdere insert- en update-opdrachten hoeven op te geven. U kunt de MERGE verklaring in a opgeslagen procedure om de gegevens in te vullen. Vervolgens plant u de opgeslagen procedure om programmatisch uit te voeren via de query-editor, die we later in dit bericht demonstreren. De volgende code maakt een opgeslagen procedure genaamd SalesMart.DimVenueLoad:
Een paar opmerkingen over het laden van dimensies:
- Wanneer een record voor het eerst wordt ingevoegd, worden de ingevoegde datum en de bijgewerkte datum ingevuld. Wanneer waarden veranderen, worden de gegevens bijgewerkt en de bijgewerkte datum weerspiegelt de datum waarop deze is gewijzigd. De ingevoerde datum blijft behouden.
- Omdat de gegevens door zakelijke gebruikers zullen worden gebruikt, moeten we eventuele NULL-waarden vervangen door meer bedrijfsgeschikte waarden.
Identificeer en implementeer de feiten
Nu we hebben verklaard dat ons graan de gebeurtenis is van een verkoop die op een bepaald tijdstip plaatsvond, zal onze feitentabel de numerieke feiten voor ons bedrijfsproces opslaan.
We hebben de volgende numerieke feiten geïdentificeerd om te meten:
- Aantal verkochte tickets per verkoop
- Commissie voor de verkoop
Implementatie van het feit
Er zijn drie soorten feitentabellen (transactiefeitentabel, periodieke momentopname feitentabel en cumulatieve momentopname feitentabel). Elk dient een andere kijk op het bedrijfsproces. Voor ons voorbeeld gebruiken we een transactiefeitentabel. Voer de volgende stappen uit:
- Maak de feitentabel
Er wordt een ingevoegde datum met een standaardwaarde toegevoegd, die aangeeft of en wanneer een record is geladen. U kunt dit gebruiken bij het opnieuw laden van de feitentabel om de reeds geladen gegevens te verwijderen om duplicaten te voorkomen.
Het laden van de feitentabel bestaat uit een eenvoudige invoegopdracht die uw bijbehorende dimensies samenvoegt. Wij sluiten aan bij de DimVenue tabel die is gemaakt, die onze feiten beschrijft. Het is best practice, maar optioneel om te hebben kalender datum dimensies, waarmee de eindgebruiker door de feitentabel kan navigeren. Gegevens kunnen worden geladen wanneer er een nieuwe verkoop is, of dagelijks; hier komt de ingevoegde datum of laaddatum van pas.
We laden de feitentabel met behulp van een opgeslagen procedure en gebruiken een datumparameter.
- Maak de opgeslagen procedure met de volgende code. Om dezelfde gegevensintegriteit te behouden die we hebben toegepast bij het laden van dimensies, vervangen we NULL-waarden, indien aanwezig, door meer bedrijfsgeschikte waarden:
- Laad de gegevens door de procedure aan te roepen met de volgende opdracht:
Plan het laden van gegevens
We kunnen het modelleringsproces nu automatiseren door de opgeslagen procedures te plannen in Amazon Redshift Query Editor V2. Voer de volgende stappen uit:
- We noemen eerst de dimensiebelasting en nadat de dimensiebelasting succesvol is uitgevoerd, begint het feitbelasting:
Als het laden van de dimensie mislukt, wordt het laden van feiten niet uitgevoerd. Dit zorgt voor consistentie in de gegevens omdat we de feitentabel niet willen laden met verouderde dimensies.
- Kies om de belasting te plannen Plan in Query-editor V2.

- We plannen dat de query elke dag om 5:00 uur wordt uitgevoerd.
- Optioneel kunt u storingsmeldingen toevoegen door in te schakelen Amazon eenvoudige meldingsservice (Amazon SNS) meldingen.

Rapporteer en analyseer de gegevens in Amazon Quicksight
QuickSight is een business intelligence-service die het gemakkelijk maakt om inzichten te leveren. Als volledig beheerde service kunt u met QuickSight eenvoudig interactieve dashboards maken en publiceren die vervolgens vanaf elk apparaat toegankelijk zijn en in uw applicaties, portalen en websites kunnen worden geïntegreerd.
Met onze datamart presenteren we de feiten visueel in de vorm van een dashboard. Raadpleeg om aan de slag te gaan en QuickSight in te stellen Een gegevensset maken met behulp van een database die niet automatisch wordt ontdekt.
Nadat u uw gegevensbron in QuickSight hebt gemaakt, voegen we de gemodelleerde gegevens (datamart) samen op basis van onze surrogaatsleutel skey. Deze dataset gebruiken we om de datamart te visualiseren.

Ons einddashboard bevat de inzichten van de datamart en beantwoordt kritische zakelijke vragen, zoals de totale commissie per locatie en datums met de hoogste verkopen. De volgende schermafbeelding toont het eindproduct van de datamart.

Opruimen
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u alle bronnen die u als onderdeel van dit bericht hebt gemaakt.
Conclusie
We hebben nu met succes een datamart geïmplementeerd met behulp van onze DimVenue, DimCalendar en FactSaleTransactions tafels. Ons magazijn is niet compleet; aangezien we de datamart kunnen uitbreiden met meer feiten en meer marts kunnen implementeren, en naarmate het bedrijfsproces en de vereisten in de loop van de tijd groeien, zal het datawarehouse dat ook doen. In dit bericht gaven we een end-to-end beeld van het begrijpen en implementeren van dimensionale modellering in Amazon Redshift.
Ga aan de slag met je Amazon roodverschuiving dimensionaal model vandaag.
Over de auteurs
 Bernardus Verster is een ervaren cloud-engineer met jarenlange ervaring in het creëren van schaalbare en efficiënte datamodellen, het definiëren van data-integratiestrategieën en het waarborgen van data-governance en -beveiliging. Hij is gepassioneerd door het gebruik van gegevens om inzichten te genereren, terwijl hij aansluit bij zakelijke vereisten en doelstellingen.
Bernardus Verster is een ervaren cloud-engineer met jarenlange ervaring in het creëren van schaalbare en efficiënte datamodellen, het definiëren van data-integratiestrategieën en het waarborgen van data-governance en -beveiliging. Hij is gepassioneerd door het gebruik van gegevens om inzichten te genereren, terwijl hij aansluit bij zakelijke vereisten en doelstellingen.
 Abishek Pan is een WWSO-specialist SA-Analytics die werkt met klanten uit de publieke sector van AWS India. Hij werkt samen met klanten om een datagestuurde strategie te definiëren, diepgaande sessies te geven over gebruiksscenario's voor analyse en schaalbare en performante analytische toepassingen te ontwerpen. Hij heeft 12 jaar ervaring en is gepassioneerd door databases, analyse en AI/ML. Hij is een fervent reiziger en probeert de wereld vast te leggen met zijn cameralens.
Abishek Pan is een WWSO-specialist SA-Analytics die werkt met klanten uit de publieke sector van AWS India. Hij werkt samen met klanten om een datagestuurde strategie te definiëren, diepgaande sessies te geven over gebruiksscenario's voor analyse en schaalbare en performante analytische toepassingen te ontwerpen. Hij heeft 12 jaar ervaring en is gepassioneerd door databases, analyse en AI/ML. Hij is een fervent reiziger en probeert de wereld vast te leggen met zijn cameralens.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Over
- versnellen
- toegang
- geraadpleegde
- nauwkeurig
- over
- Handelen
- toevoegen
- toegevoegd
- Extra
- Na
- AI / ML
- richten
- uitlijnen
- toelaten
- toestaat
- al
- am
- Amazone
- Amazon Web Services
- an
- analyse
- Analytisch
- analytics
- analyseren
- en
- beantwoorden
- elke
- toepassingen
- toegepast
- passend
- architectuur
- ZIJN
- kunstmatig
- AS
- aspecten
- geassocieerd
- At
- attributen
- auto
- automatiseren
- webmaster.
- vermijd
- AWS
- b
- gebaseerde
- BE
- omdat
- beginnen
- betekent
- BEST
- ingebouwd
- bedrijfsdeskundigen
- business intelligence
- Bedrijfsproces
- bedrijfsprocessen
- maar
- by
- Agenda
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- bellen
- camera
- CAN
- vangen
- geval
- gevallen
- Veroorzaken
- zeker
- verandering
- veranderd
- Wijzigingen
- veranderende
- karakter
- lasten
- Kies
- duidelijk
- duidelijk
- van nabij
- Cloud
- code
- Kolom
- komt
- commissie
- Gemeen
- Bedrijven
- afstand
- compleet
- Overwegen
- consequent
- bestaat uit
- verband
- te corrigeren
- kon
- en je merk te creëren
- aangemaakt
- creëert
- Wij creëren
- het aanmaken
- kritisch
- Klanten
- dagelijks
- dashboards
- dashboards
- gegevens
- gegevens integratie
- Datameer
- datawarehouse
- Gegevensgestuurde
- Datagedreven Strategie
- Database
- databanken
- Datum
- Data
- datetime
- dag
- deep
- diepe duik
- Standaard
- het definiëren van
- leveren
- tonen
- afdelingen
- Afgeleid
- beschrijven
- Design
- ontwerpen
- detail
- apparaat
- anders
- Afmeting
- Afmeting
- bespreken
- onderscheiden
- distributie
- do
- domein
- gedaan
- Dont
- beneden
- rit
- duplicaten
- elk
- Vroeger
- gemakkelijk
- En het is heel gemakkelijk
- editor
- doeltreffend
- beide
- ingebed
- in staat stellen
- waardoor
- einde
- eind tot eind
- houdt zich bezig
- ingenieur
- verzekeren
- waarborgt
- zorgen
- Geheel
- entiteit
- Ether (ETH)
- Event
- EVENTS
- Alle
- elke dag
- voorbeeld
- voorbeelden
- Uitvouwen
- ervaring
- ervaren
- Media
- extract
- feit
- factor
- factoren
- feiten
- mislukt
- Storing
- Voordelen
- weinig
- veld-
- Velden
- vijfde
- Figuur
- filter
- finale
- Voornaam*
- eerste keer
- geschikt
- gericht
- volgend
- Voor
- formulier
- formaat
- vier
- oppompen van
- geheel
- verder
- toekomst
- Krijgen
- voortbrengen
- gegenereerde
- genereert
- krijgen
- het krijgen van
- Geven
- gegeven
- goed
- bestuur
- Groeien
- handig
- Hebben
- he
- hoogst
- zijn
- historisch
- vakantie
- Hoe
- How To
- HTML
- http
- HTTPS
- IAM
- geïdentificeerd
- identificeren
- het identificeren van
- Identiteit
- if
- illustreert
- Impact
- uitvoeren
- geïmplementeerd
- uitvoering
- belangrijk
- verbeteren
- het verbeteren van
- in
- Inclusief
- Indië
- aangeven
- wat aangeeft
- info
- inzichten
- geïntegreerde
- integratie
- integriteit
- Intelligentie
- interactieve
- in
- IT
- HAAR
- mee
- toegetreden
- aansluiting
- Sluit zich aan bij
- jpg
- Houden
- houden
- sleutel
- toetsen
- meer
- taal
- later
- laatste
- lagen
- links
- lens
- Laten we
- Niveau
- Lijn
- laden
- het laden
- ladingen
- gelegen
- op zoek
- gemaakt
- MERKEN
- beheerd
- Marketing
- op elkaar afgestemd
- betekenis
- maatregel
- vermeld
- gaan
- Metriek
- denken
- fout
- model
- modellering
- modellering
- modellen
- Maand
- meer
- meest
- meervoudig
- namen
- Naturel
- OP DEZE WEBSITE VIND JE
- Noodzaak
- nodig
- behoeften
- New
- Opmerkingen
- notificatie
- meldingen
- nu
- vele
- doelstellingen
- of
- bieden
- vaak
- on
- Slechts
- operationele
- or
- organisatie
- onze
- over
- totaal
- parameter
- deel
- hartstochtelijk
- voor
- uitvoeren
- prestatie
- misschien
- periodiek
- plaats
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- bevolkte
- Post
- energie
- praktijk
- vereisten
- presenteren
- primair
- procedures
- procedures
- processen
- Product
- zorgen voor
- mits
- biedt
- publiek
- publiceren
- doeleinden
- Contact
- snel
- verhogen
- Rauw
- ruwe data
- record
- archief
- verminderen
- verwezen
- weerspiegelt
- regio
- verwantschap
- stoffelijk overschot
- verwijderen
- vervangen
- verslag
- Rapportage
- Rapporten
- Voorwaarden
- Resources
- verantwoordelijkheid
- Rol
- Rollen
- RIJ
- lopen
- loopt
- sale
- verkoop
- dezelfde
- Voorbeeldgegevensset
- schaalbare
- rooster
- scheduling
- secties
- sector
- veiligheid
- zien
- apart
- bedient
- service
- Diensten
- sessies
- reeks
- verscheidene
- moet
- tonen
- Shows
- Eenvoudig
- eenvoud
- single
- Langzaam
- Klein
- kleinere
- Momentopname
- So
- uitverkocht
- oplossing
- sommige
- bron
- bronnen
- Tussenruimte
- specialist
- specifiek
- specifiek
- Stadium
- regie
- Ster
- gestart
- Start
- Statement
- Stap voor
- Stappen
- mediaopslag
- shop
- opgeslagen
- strategieën
- Strategie
- structuur
- geslaagd
- Met goed gevolg
- dergelijk
- system
- tafel
- tijdelijk
- tienen
- termen
- neem contact
- dat
- De
- De Bron
- de wereld
- hun
- harte
- Er.
- daarom
- Deze
- ze
- dit
- duizenden kosten
- Door
- ticket
- kaartverkoop
- tickets
- niet de tijd of
- keer
- tijdstempel
- tips
- naar
- vandaag
- samen
- nam
- Totaal
- spoor
- transactie
- Transformeren
- getransformeerd
- reiziger
- type dan:
- types
- typisch
- begrip
- unieke
- uniek
- uniciteit
- onbekend
- bijwerken
- bijgewerkt
- us
- Gebruik
- .
- use case
- gebruikt
- gebruikers
- toepassingen
- gebruik
- doorgaans
- waardevol
- waarde
- Values
- divers
- Venue
- reilen en zeilen
- via
- Bekijk
- volume
- walkthrough
- willen
- Magazijn
- was
- manieren
- we
- web
- webservices
- websites
- week
- wanneer
- welke
- en
- wil
- Met
- binnen
- zonder
- werkzaam
- wereld
- Verkeerd
- jaar
- jaar
- u
- Your
- zephyrnet