Dit is een gezamenlijk bericht dat is geschreven door AWS en Voxel51. Voxel51 is het bedrijf achter FiftyOne, de open-source toolkit voor het bouwen van hoogwaardige datasets en computer vision-modellen.
Een winkelbedrijf bouwt een mobiele app om klanten te helpen kleding te kopen. Om deze app te maken, hebben ze een hoogwaardige dataset nodig met kledingafbeeldingen, gelabeld met verschillende categorieën. In dit bericht laten we zien hoe je een bestaande dataset kunt hergebruiken via datacleaning, preprocessing en pre-labeling met een zero-shot classificatiemodel in Eenenvijftig, en deze labels aanpassen met Amazon SageMaker Grondwaarheid.
U kunt Ground Truth en FiftyOne gebruiken om uw project voor het labelen van gegevens te versnellen. We illustreren hoe u de twee applicaties naadloos samen kunt gebruiken om gelabelde datasets van hoge kwaliteit te creëren. Voor ons voorbeeld use case werken we met de Fashion200K-gegevensset, uitgebracht op ICCV 2017.
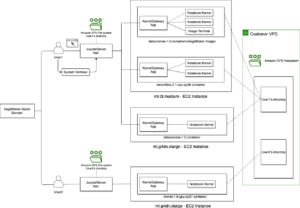
Overzicht oplossingen
Ground Truth is een volledig self-service en beheerde service voor het labelen van data die datawetenschappers, machine learning (ML)-engineers en onderzoekers in staat stelt om hoogwaardige datasets te bouwen. Eenenvijftig by Voxel 51 is een open-source toolkit voor het samenstellen, visualiseren en evalueren van computer vision datasets, zodat u betere modellen kunt trainen en analyseren door uw use cases te versnellen.
In de volgende secties laten we zien hoe u het volgende kunt doen:
- Visualiseer de dataset in FiftyOne
- Reinig de dataset met filtering en deduplicatie van afbeeldingen in FiftyOne
- Voorlabel de opgeschoonde gegevens met zero-shot classificatie in FiftyOne
- Label de kleinere samengestelde dataset met Ground Truth
- Injecteer gelabelde resultaten van Ground Truth in FiftyOne en bekijk gelabelde resultaten in FiftyOne
Gebruik case-overzicht
Stel dat u een winkelbedrijf heeft en een mobiele applicatie wilt bouwen om gepersonaliseerde aanbevelingen te doen om gebruikers te helpen beslissen wat ze moeten dragen. Uw potentiële gebruikers zijn op zoek naar een applicatie die hen vertelt welke kledingstukken in hun kast goed bij elkaar passen. Je ziet hier een kans: als je goede outfits kunt herkennen, kun je die gebruiken om nieuwe kledingstukken aan te bevelen die een aanvulling vormen op de kleding die een klant al heeft.
U wilt het de eindgebruiker zo gemakkelijk mogelijk maken. Idealiter hoeft iemand die uw applicatie gebruikt alleen foto's te maken van de kleding in zijn kledingkast, en uw ML-modellen werken hun magie achter de schermen uit. U kunt een model voor algemeen gebruik trainen of een model afstemmen op de unieke stijl van elke gebruiker met enige vorm van feedback.
Eerst moet u echter vaststellen welk type kleding de gebruiker vastlegt. Is het een overhemd? Een broek? Of iets anders? Je wilt immers waarschijnlijk geen outfit aanbevelen die meerdere jurken of meerdere hoeden heeft.
Om deze eerste uitdaging aan te pakken, wil je een trainingsdataset genereren die bestaat uit afbeeldingen van verschillende kledingstukken met verschillende patronen en stijlen. Om met een beperkt budget te prototypen, wil je bootstrap gebruiken met een bestaande dataset.
Om het proces in dit bericht te illustreren en u door het proces te leiden, gebruiken we de Fashion200K-dataset die is vrijgegeven op ICCV 2017. Het is een gevestigde en veel geciteerde dataset, maar deze is niet direct geschikt voor uw gebruiksscenario.
Hoewel kledingstukken zijn gelabeld met categorieën (en subcategorieën) en een verscheidenheid aan nuttige tags bevatten die zijn ontleend aan de originele productbeschrijvingen, worden de gegevens niet systematisch gelabeld met patroon- of stijlinformatie. Uw doel is om van deze bestaande dataset een robuuste trainingsdataset te maken voor uw kledingclassificatiemodellen. U moet de gegevens opschonen en het labelschema uitbreiden met stijllabels. En dat wil je snel en met zo min mogelijk kosten doen.
Download de gegevens lokaal
Download eerst het zip-bestand women.tar en de map labels (met al zijn submappen) volgens de instructies in de Fashion200K dataset GitHub-repository. Nadat je ze allebei hebt uitgepakt, maak je een bovenliggende map fashion200k en verplaats je de labels en de vrouwenmappen hierin. Gelukkig zijn deze afbeeldingen al bijgesneden tot de selectiekaders voor objectdetectie, zodat we ons kunnen concentreren op classificatie in plaats van ons zorgen te maken over objectdetectie.
Ondanks de "200K" in zijn naam, bevat de vrouwenlijst die we hebben geëxtraheerd 338,339 afbeeldingen. Om de officiële dataset van Fashion200K te genereren, hebben de auteurs van de dataset meer dan 300,000 producten online gecrawld, en alleen producten met beschrijvingen die meer dan vier woorden bevatten, haalden de selectie. Voor onze doeleinden, waar de productbeschrijving niet essentieel is, kunnen we alle gecrawlde afbeeldingen gebruiken.
Laten we eens kijken hoe deze gegevens zijn georganiseerd: in de vrouwenmap zijn afbeeldingen gerangschikt op artikeltype op het hoogste niveau (rokken, tops, broeken, jassen en jurken) en op subcategorie van het artikeltype (blouses, t-shirts, lange mouwen). toppen).
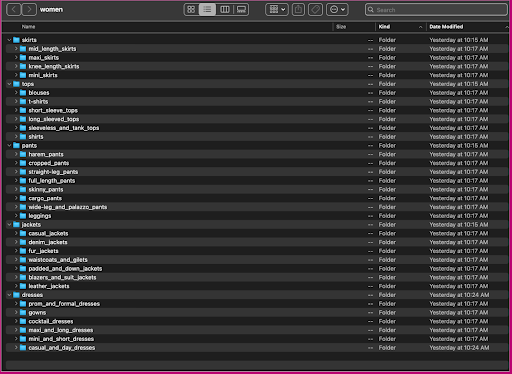
Binnen de subcategorie directories is er een subdirectory voor elke productvermelding. Elk van deze bevat een variabel aantal afbeeldingen. De subcategorie cropped_pants bevat bijvoorbeeld de volgende productvermeldingen en bijbehorende afbeeldingen.
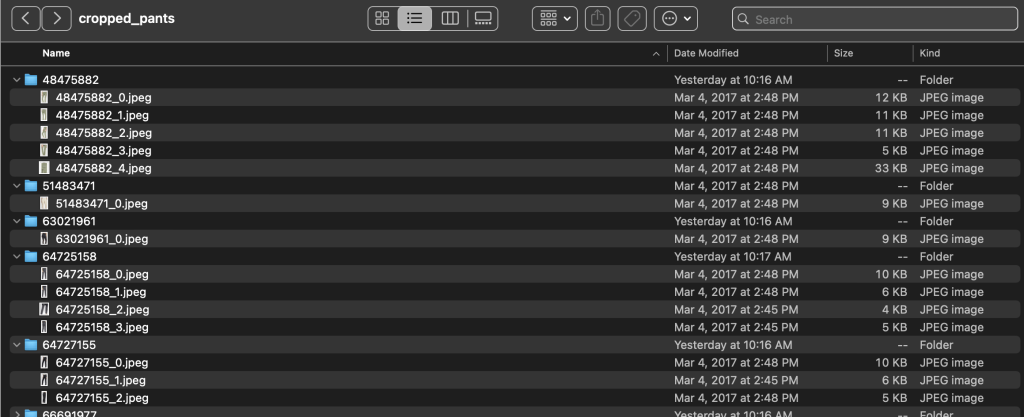
De map Labels bevat een tekstbestand voor elk artikeltype op het hoogste niveau, voor zowel trein- als testsplitsingen. Binnen elk van deze tekstbestanden is een aparte regel voor elke afbeelding, met het relatieve bestandspad, een score en tags uit de productbeschrijving.
Omdat we de dataset een nieuwe bestemming geven, combineren we alle trein- en testbeelden. Deze gebruiken we om een hoogwaardige applicatiespecifieke dataset te genereren. Nadat we dit proces hebben voltooid, kunnen we de resulterende dataset willekeurig splitsen in nieuwe trein- en testsplitsingen.
Injecteer, bekijk en beheer een dataset in FiftyOne
Als je dit nog niet hebt gedaan, installeer dan open-source FiftyOne met behulp van pip:
Een best practice is om dit te doen binnen een nieuwe virtuele (venv of conda) omgeving. Importeer vervolgens de relevante modules. Importeer de basisbibliotheek, fiftyone, de FiftyOne Brain, die ingebouwde ML-methoden heeft, de FiftyOne Zoo, van waaruit we een model zullen laden dat zero-shot-labels voor ons zal genereren, en het ViewField, waarmee we de gegevens in onze dataset:
U wilt ook de glob- en os Python-modules importeren, die ons zullen helpen werken met paden en patroonovereenkomsten over directory-inhoud:
Nu zijn we klaar om de dataset in FiftyOne te laden. Eerst maken we een dataset met de naam fashion200k en maken deze persistent, waardoor we de resultaten van rekenintensieve bewerkingen kunnen opslaan, zodat we die hoeveelheden maar één keer hoeven te berekenen.
We kunnen nu alle subcategoriemappen doorlopen en alle afbeeldingen in de productmappen toevoegen. We voegen een FiftyOne-classificatielabel toe aan elk voorbeeld met de veldnaam article_type, gevuld met de artikelcategorie op het hoogste niveau van de afbeelding. We voegen ook zowel categorie- als subcategorie-informatie toe als tags:
Op dit punt kunnen we onze dataset in de FiftyOne-app visualiseren door een sessie te starten:
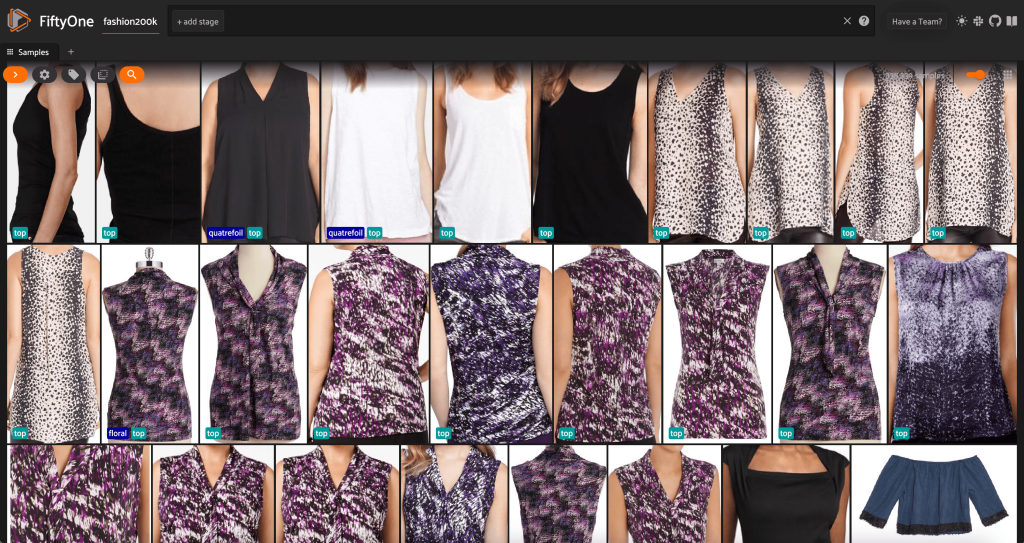
We kunnen ook een samenvatting van de dataset in Python afdrukken door te draaien print(dataset):
We kunnen ook de tags van de labels directory naar de voorbeelden in onze dataset:
Als we naar de data kijken, worden een paar dingen duidelijk:
- Sommige afbeeldingen zijn vrij korrelig en hebben een lage resolutie. Dit komt waarschijnlijk omdat deze afbeeldingen zijn gegenereerd door initiële afbeeldingen bij te snijden in selectiekaders voor objectdetectie.
- Sommige kleding wordt door een persoon gedragen en sommige worden op zichzelf gefotografeerd. Deze details zijn ingekapseld door de
viewpointeigendom. - Veel van de afbeeldingen van hetzelfde product lijken erg op elkaar, dus in het begin zal het opnemen van meer dan één afbeelding per product niet veel voorspellende kracht hebben. De eerste afbeelding van elk product (eindigend op
_0.jpeg) is het schoonst.
In eerste instantie willen we misschien ons classificatiemodel voor kledingstijlen trainen op een gecontroleerde subset van deze afbeeldingen. Hiervoor gebruiken we hoge resolutie afbeeldingen van onze producten en beperken we ons zicht tot één representatief staal per product.
Eerst filteren we de afbeeldingen met een lage resolutie eruit. Wij gebruiken de compute_metadata() methode om de breedte en hoogte van een afbeelding in pixels te berekenen en op te slaan voor elke afbeelding in de dataset. Wij zetten dan de FiftyOne in ViewField om afbeeldingen uit te filteren op basis van de minimaal toegestane waarden voor breedte en hoogte. Zie de volgende code:
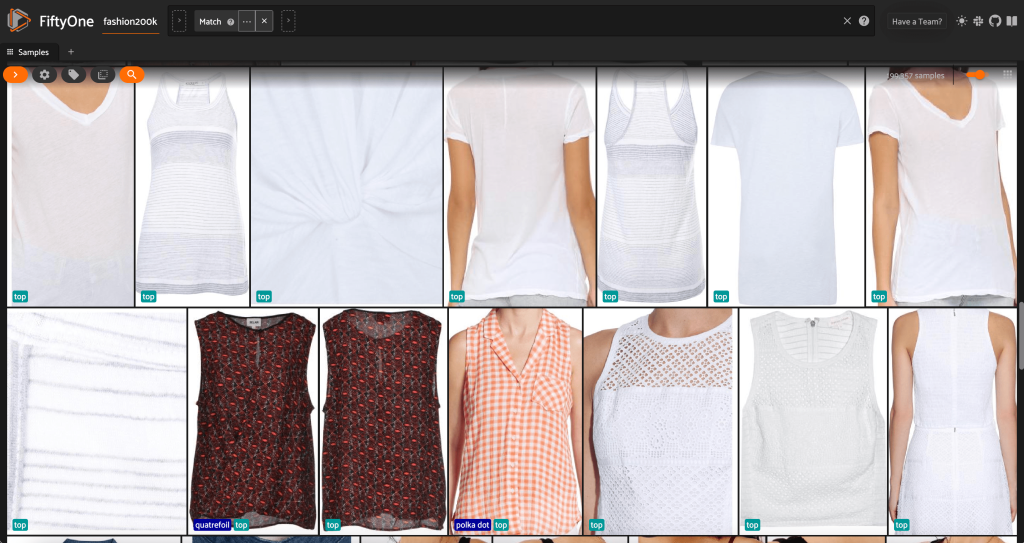
Deze subset met hoge resolutie heeft iets minder dan 200,000 monsters.
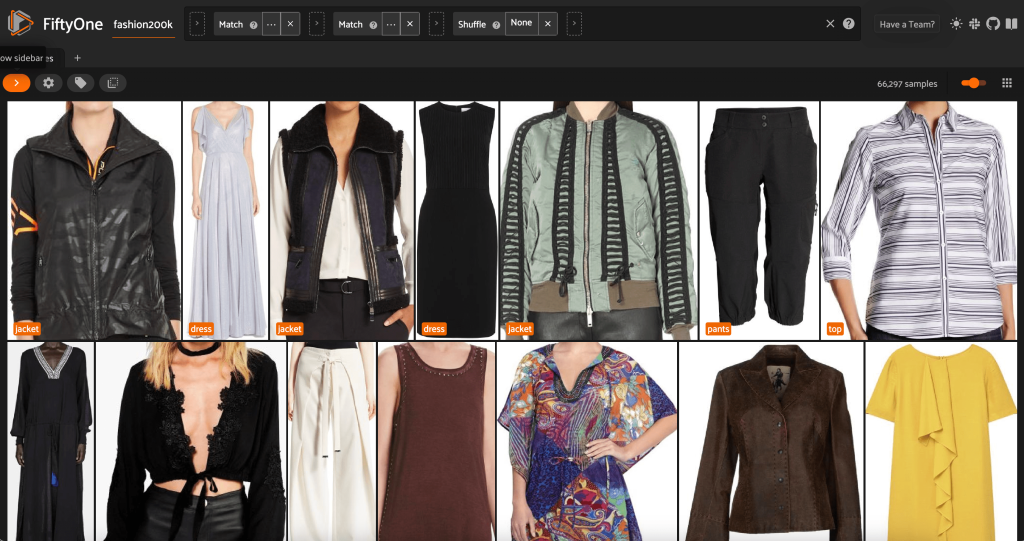
Vanuit deze weergave kunnen we een nieuwe weergave in onze dataset maken met slechts één representatief monster (maximaal) voor elk product. Wij gebruiken de ViewField nogmaals, patroonvergelijking voor bestandspaden die eindigen op _0.jpeg:
Laten we een willekeurig geschudde volgorde van afbeeldingen in deze subset bekijken:
Verwijder overbodige afbeeldingen in de dataset
Deze weergave bevat 66,297 afbeeldingen, of iets meer dan 19% van de originele dataset. Als we echter naar het uitzicht kijken, zien we dat er veel zeer vergelijkbare producten zijn. Het behouden van al deze kopieën zal waarschijnlijk alleen maar meer kosten opleveren voor onze labeling- en modeltraining, zonder merkbare verbetering van de prestaties. Laten we in plaats daarvan de bijna-duplicaten verwijderen om een kleinere dataset te maken die nog steeds dezelfde kracht heeft.
Omdat deze afbeeldingen geen exacte duplicaten zijn, kunnen we niet controleren op pixelgewijze gelijkheid. Gelukkig kunnen we FiftyOne Brain gebruiken om ons te helpen onze dataset op te schonen. We berekenen met name een inbedding voor elke afbeelding (een lager-dimensionale vector die de afbeelding vertegenwoordigt) en zoeken vervolgens naar afbeeldingen waarvan de inbeddingsvectoren dicht bij elkaar liggen. Hoe dichter de vectoren, hoe meer de afbeeldingen op elkaar lijken.
We gebruiken een CLIP-model om voor elke afbeelding een 512-dimensionale inbeddingsvector te genereren en deze inbeddingen op te slaan in de veldinbeddingen op de monsters in onze dataset:
Vervolgens berekenen we de nabijheid tussen inbeddingen, met behulp van cosinus gelijkenis, en beweren dat elke twee vectoren waarvan de gelijkenis groter is dan een bepaalde drempel, waarschijnlijk bijna duplicaten zijn. Cosinusovereenkomstscores liggen in het bereik [0, 1], en als we naar de gegevens kijken, lijkt een drempelscore van thresh=0.5 ongeveer goed te zijn. Nogmaals, dit hoeft niet perfect te zijn. Een paar bijna dubbele afbeeldingen zullen onze voorspellende kracht waarschijnlijk niet verpesten, en het weggooien van een paar niet-dubbele afbeeldingen heeft geen wezenlijke invloed op de prestaties van het model.
We kunnen de vermeende duplicaten bekijken om te verifiëren dat ze inderdaad overbodig zijn:
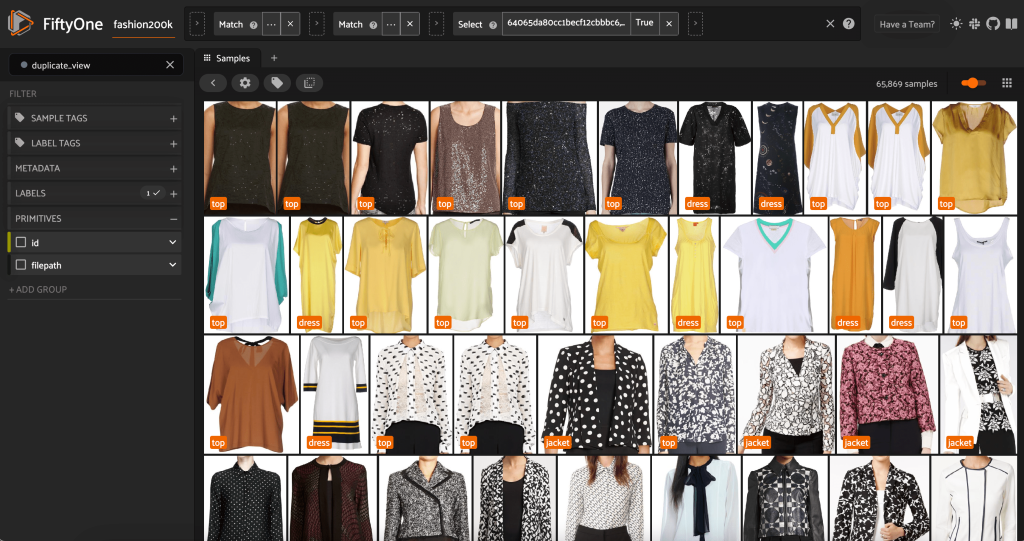
Als we tevreden zijn met het resultaat en geloven dat deze afbeeldingen inderdaad bijna duplicaten zijn, kunnen we één monster uit elke set vergelijkbare monsters kiezen om te behouden en de andere negeren:
Deze weergave heeft nu 3,729 afbeeldingen. Door de gegevens op te schonen en een hoogwaardige subset van de Fashion200K-dataset te identificeren, stelt FiftyOne ons in staat onze focus te beperken van meer dan 300,000 afbeeldingen tot iets minder dan 4,000, wat neerkomt op een vermindering met 98%. Alleen al het gebruik van inbeddingen om bijna dubbele afbeeldingen te verwijderen, bracht ons totale aantal overwogen afbeeldingen met meer dan 90% terug, met weinig of geen effect op modellen die op deze gegevens moeten worden getraind.
Voordat we deze subset vooraf labelen, kunnen we de gegevens beter begrijpen door de inbeddingen die we al hebben berekend te visualiseren. We kunnen de ingebouwde FiftyOne Brain gebruiken compute_visualization() methode, die gebruik maakt van de UMAP-techniek (uniforme manifold approximation) om de 512-dimensionale inbeddingsvectoren in een tweedimensionale ruimte te projecteren, zodat we ze kunnen visualiseren:
Wij openen een nieuwe Inbeddingen paneel in de FiftyOne-app en kleuren op artikeltype, en we kunnen zien dat deze inbeddingen grofweg coderen voor een notie van artikeltype (onder andere!).
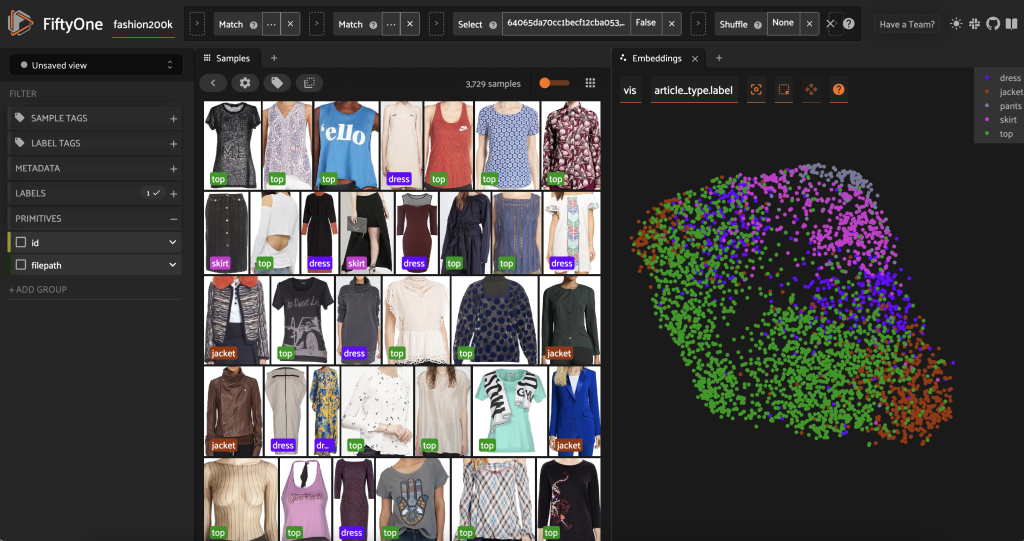
Nu zijn we klaar om deze gegevens vooraf te labelen.
Door deze zeer unieke afbeeldingen met hoge resolutie te inspecteren, kunnen we een behoorlijke eerste lijst met stijlen genereren om als klassen te gebruiken in onze pre-labeling zero-shot classificatie. Ons doel bij het vooraf labelen van deze afbeeldingen is niet noodzakelijkerwijs elke afbeelding correct te labelen. Het is eerder ons doel om een goed startpunt te bieden voor menselijke annotators, zodat we tijd en kosten voor het labelen kunnen verminderen.
We kunnen dan een zero-shot classificatiemodel voor deze toepassing instantiëren. We gebruiken een CLIP-model, een model voor algemeen gebruik dat is getraind op zowel afbeeldingen als natuurlijke taal. We instantiëren een CLIP-model met de tekstprompt 'Kleding in de stijl', zodat het model bij een afbeelding de klasse uitvoert waarvoor 'Kleding in de stijl [klasse]' het beste past. CLIP is niet getraind op retail- of modespecifieke gegevens, dus dit zal niet perfect zijn, maar het kan u wel besparen op label- en annotatiekosten.
We passen dit model vervolgens toe op onze gereduceerde deelverzameling en slaan de resultaten op in een article_style veld:
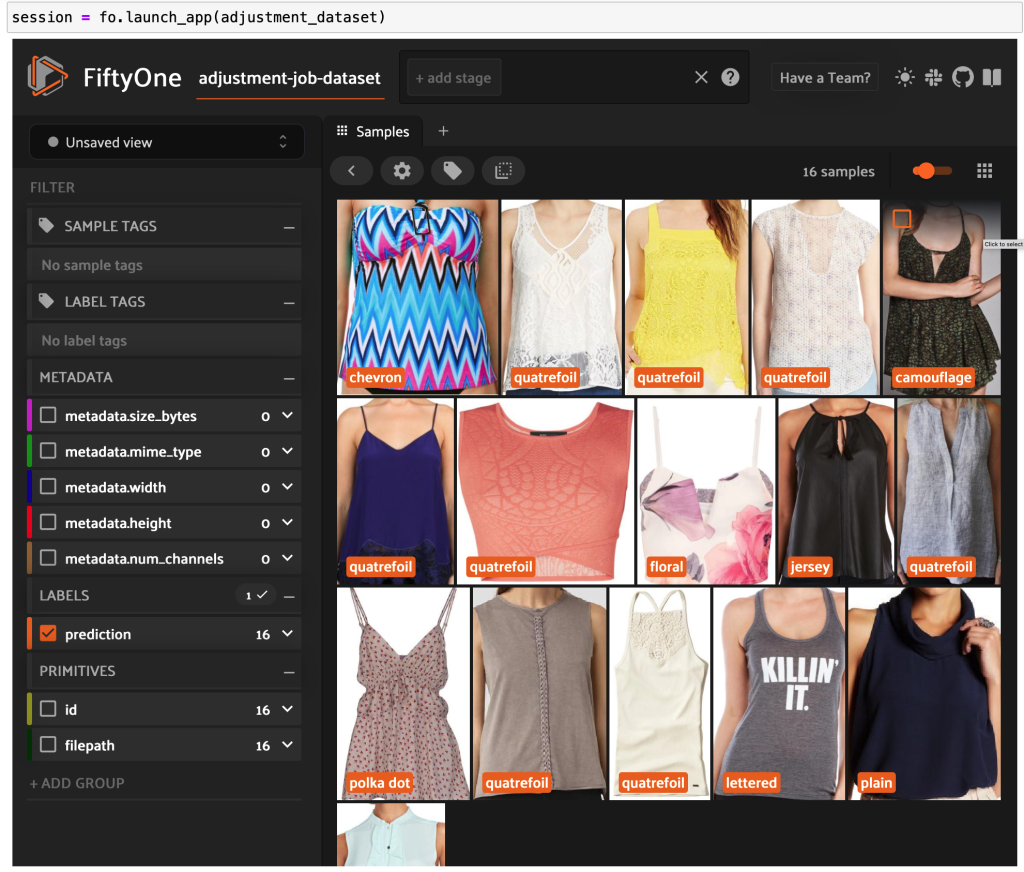
Door de FiftyOne-app opnieuw te starten, kunnen we de afbeeldingen visualiseren met deze voorspelde stijllabels. We sorteren op voorspellingsvertrouwen, dus we bekijken eerst de meest zelfverzekerde stijlvoorspellingen:
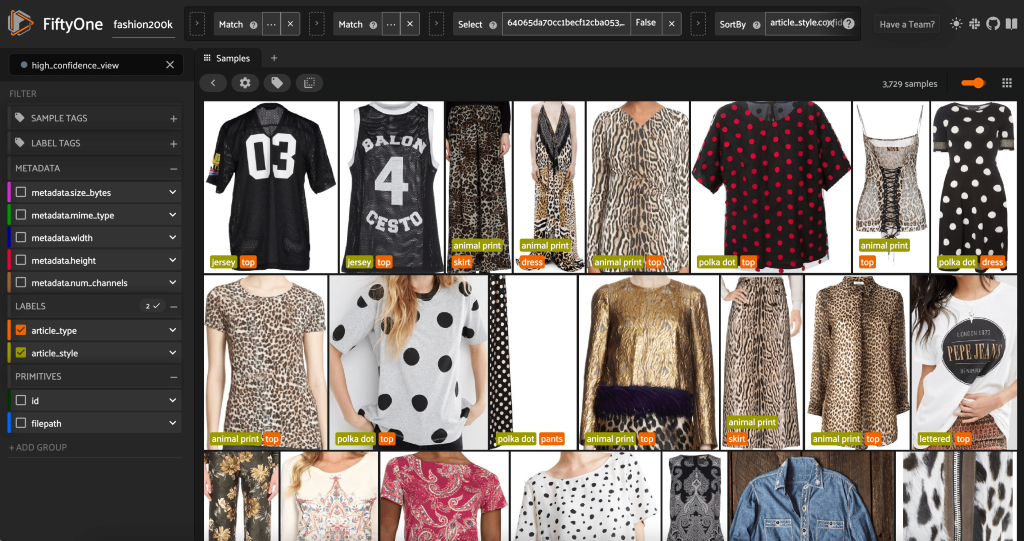
We kunnen zien dat de meest betrouwbare voorspellingen lijken te zijn voor de stijlen 'jersey', 'dierenprint', 'polka dot' en 'letters'. Dit is logisch, omdat deze stijlen relatief verschillend zijn. Het lijkt er ook op dat de voorspelde stijllabels grotendeels kloppen.
We kunnen ook kijken naar de voorspellingen met de laagste betrouwbaarheid:
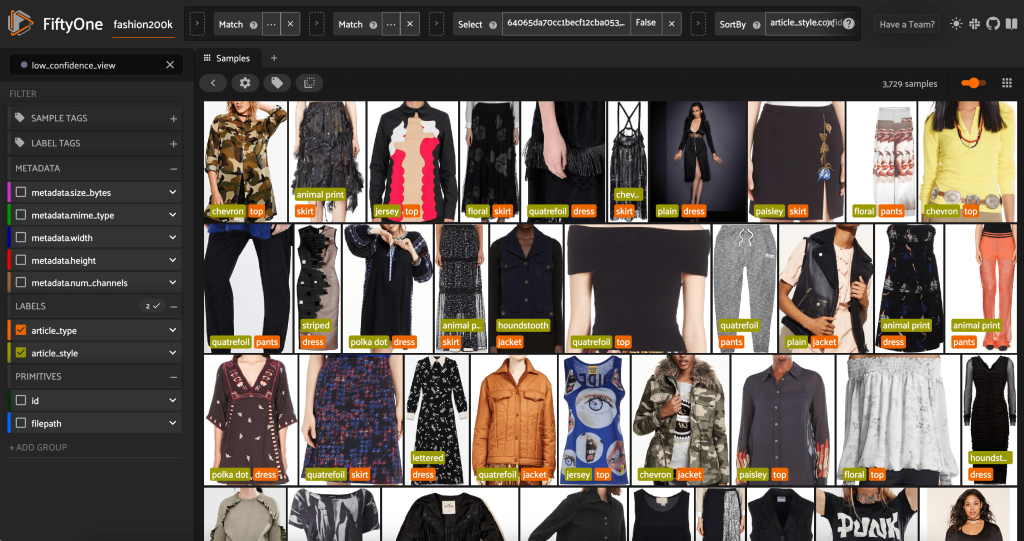
Voor sommige van deze afbeeldingen staat de juiste stijlcategorie in de verstrekte lijst en is het kledingstuk onjuist gelabeld. De eerste afbeelding in het raster moet bijvoorbeeld duidelijk 'camouflage' zijn en niet 'chevron'. In andere gevallen passen de producten echter niet netjes in de stijlcategorieën. De jurk in de tweede afbeelding op de tweede rij is bijvoorbeeld niet bepaald 'gestreept', maar gegeven dezelfde labelopties kan een menselijke annotator ook in conflict zijn geraakt. Terwijl we onze dataset uitbouwen, moeten we beslissen of we randgevallen zoals deze willen verwijderen, nieuwe stijlcategorieën willen toevoegen of de dataset willen uitbreiden.
Exporteer de definitieve dataset uit FiftyOne
Exporteer de definitieve dataset met de volgende code:
We kunnen een kleinere dataset, bijvoorbeeld 16 afbeeldingen, naar de map exporteren 200kFashionDatasetExportResult-16Images. We maken er een Ground Truth-aanpassingstaak mee:
Upload de herziene dataset, converteer het labelformaat naar Ground Truth, upload naar Amazon S3 en maak een manifestbestand voor de aanpassingstaak
We kunnen de labels in de dataset converteren zodat ze overeenkomen met de uitvoermanifestschema van een Ground Truth bounding box-taak en upload de afbeeldingen naar een Amazon eenvoudige opslagservice (Amazon S3) emmer om een Aanpassingstaak van Ground Truth:
Upload het manifestbestand naar Amazon S3 met de volgende code:
Maak gecorrigeerde gestileerde labels met Ground Truth
Om uw gegevens te annoteren met stijllabels met behulp van Ground Truth, voltooit u de nodige stappen om een labeltaak voor begrenzingskaders te starten door de procedure te volgen die wordt beschreven in de Aan de slag met Ground Truth gids met de dataset in dezelfde S3-bucket.
- Maak op de SageMaker-console een Ground Truth-labeltaak.
- Kies het Voer gegevenssetlocatie in om het manifest te zijn dat we in de voorgaande stappen hebben gemaakt.
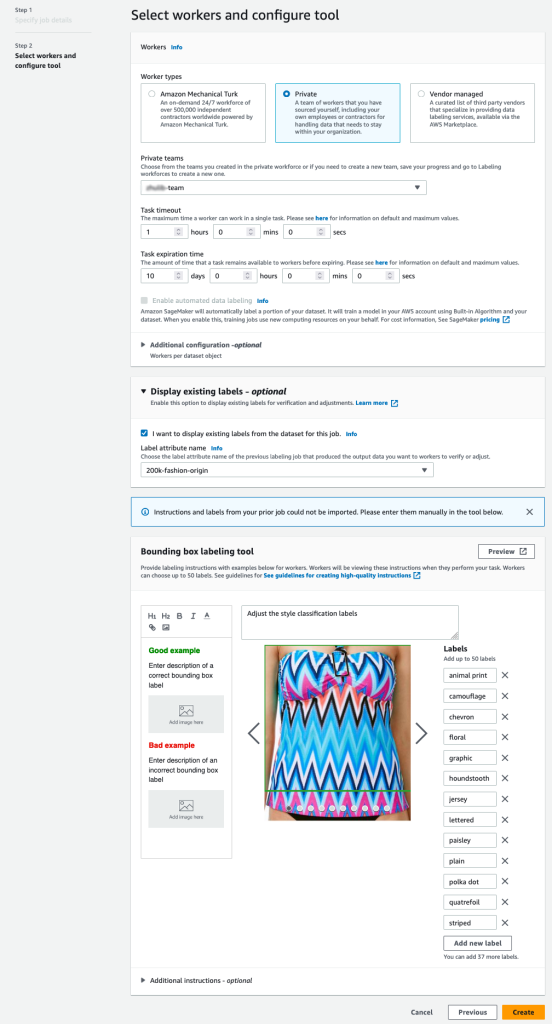
- Geef een S3-pad op voor Output dataset locatie.
- Voor IAM-rol, kiezen Voer een aangepaste IAM-rol in RNA, voer dan de rol ARN in.
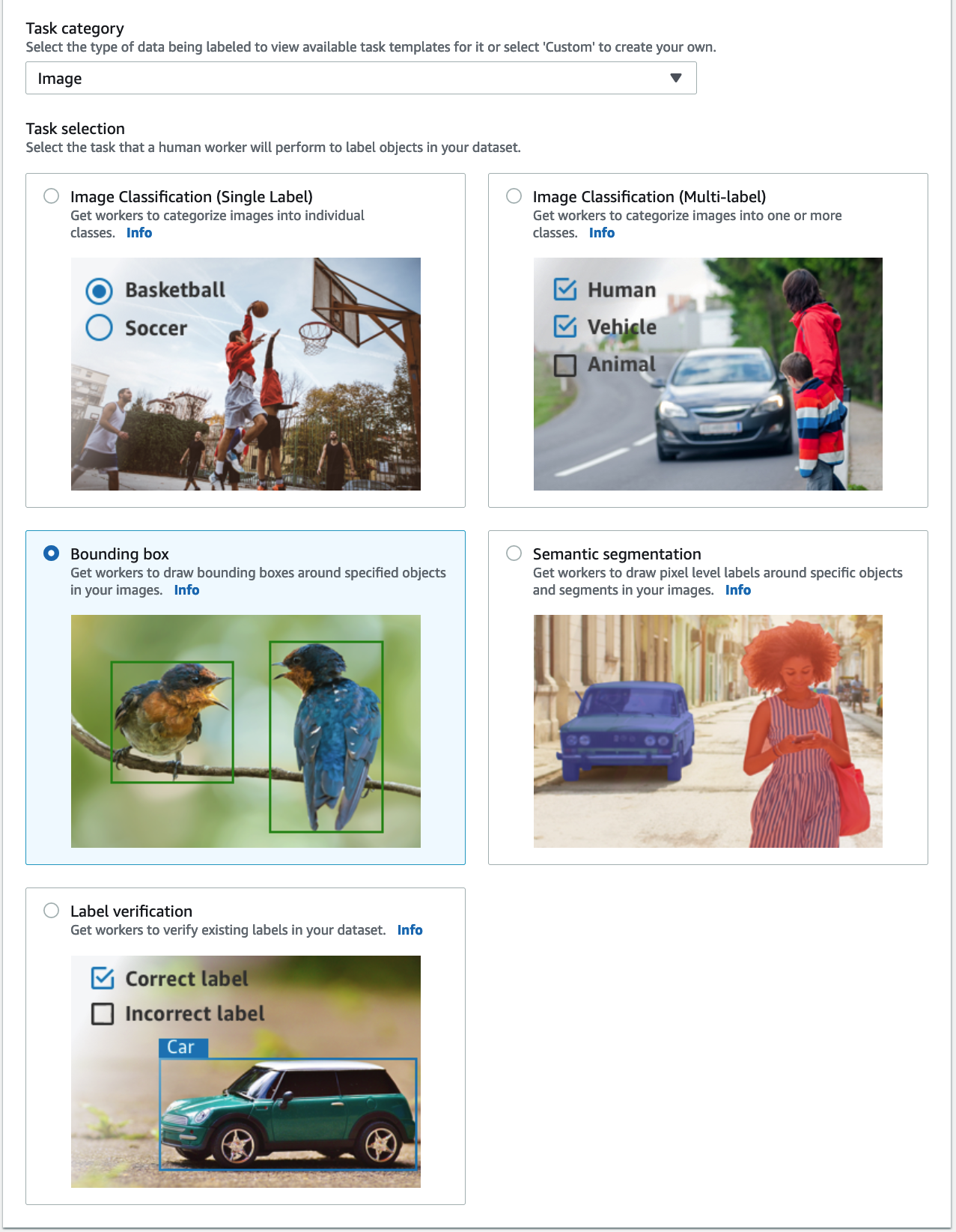
- Voor Taakcategorie, kiezen Beeld en selecteer Begrenzingsvak.
- Kies Volgende.
- In het Werknemers sectie, kies het type personeel dat u wilt gebruiken.
U kunt een personeelsbestand selecteren via Amazon Mechanical Turk, externe leveranciers of uw eigen privépersoneel. Zie voor meer informatie over uw personeelsopties Creëer en beheer arbeidskrachten. - Uitvouwen Weergaveopties voor bestaande labels en selecteer Ik wil bestaande labels uit de dataset voor deze taak weergeven.
- Voor Labelkenmerk naam, kies de naam uit uw manifest die overeenkomt met de labels die u wilt weergeven voor aanpassing.
U ziet alleen labelkenmerknamen voor labels die overeenkomen met het taaktype dat u in de vorige stappen hebt geselecteerd. - Voer handmatig de labels in voor Labeltool voor begrenzingsvakken.
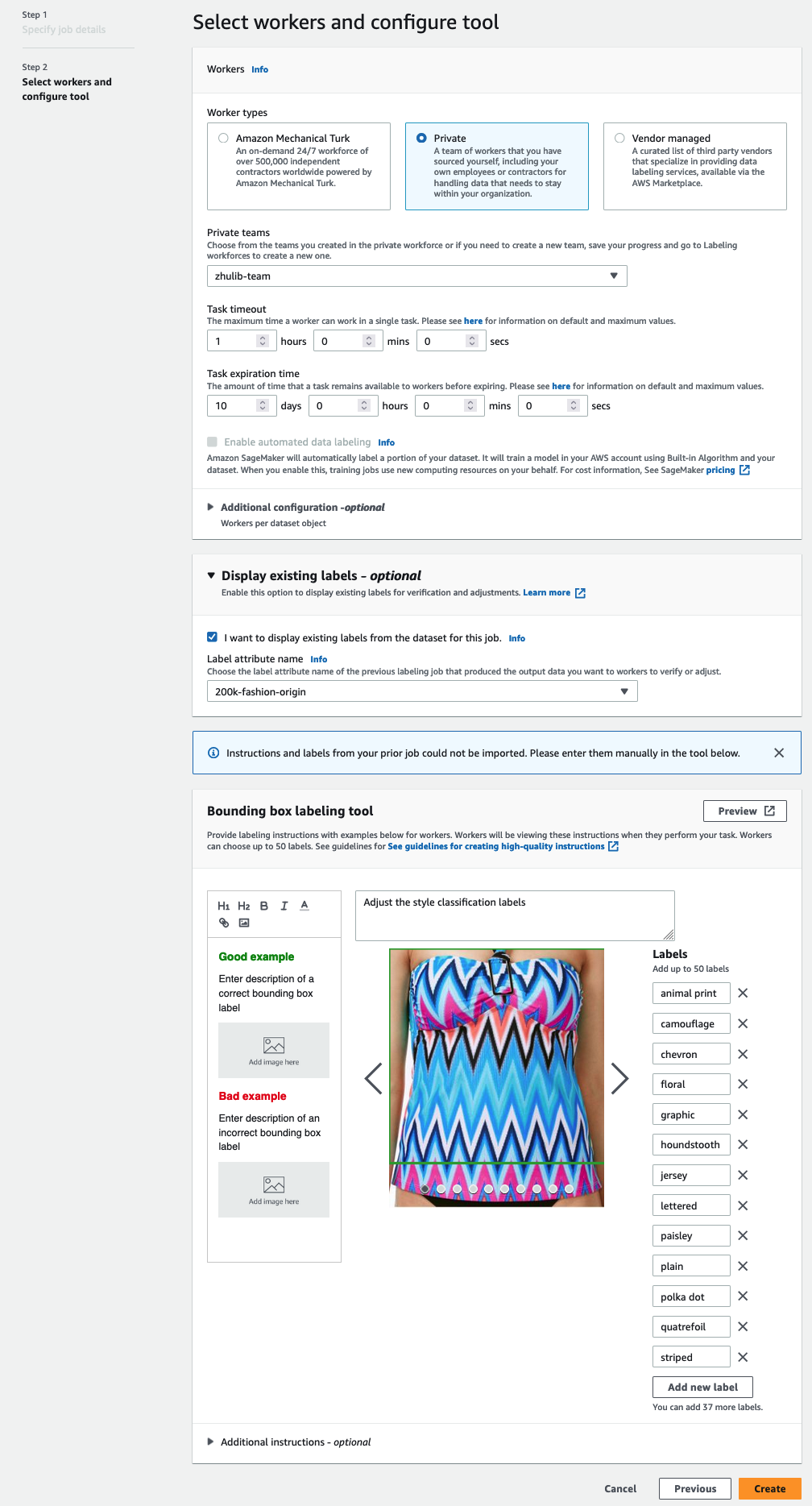 De labels moeten dezelfde labels bevatten die in de openbare dataset worden gebruikt. U kunt nieuwe labels toevoegen. De volgende schermafbeelding laat zien hoe u de werknemers kunt kiezen en de tool kunt configureren voor uw labeltaak.
De labels moeten dezelfde labels bevatten die in de openbare dataset worden gebruikt. U kunt nieuwe labels toevoegen. De volgende schermafbeelding laat zien hoe u de werknemers kunt kiezen en de tool kunt configureren voor uw labeltaak.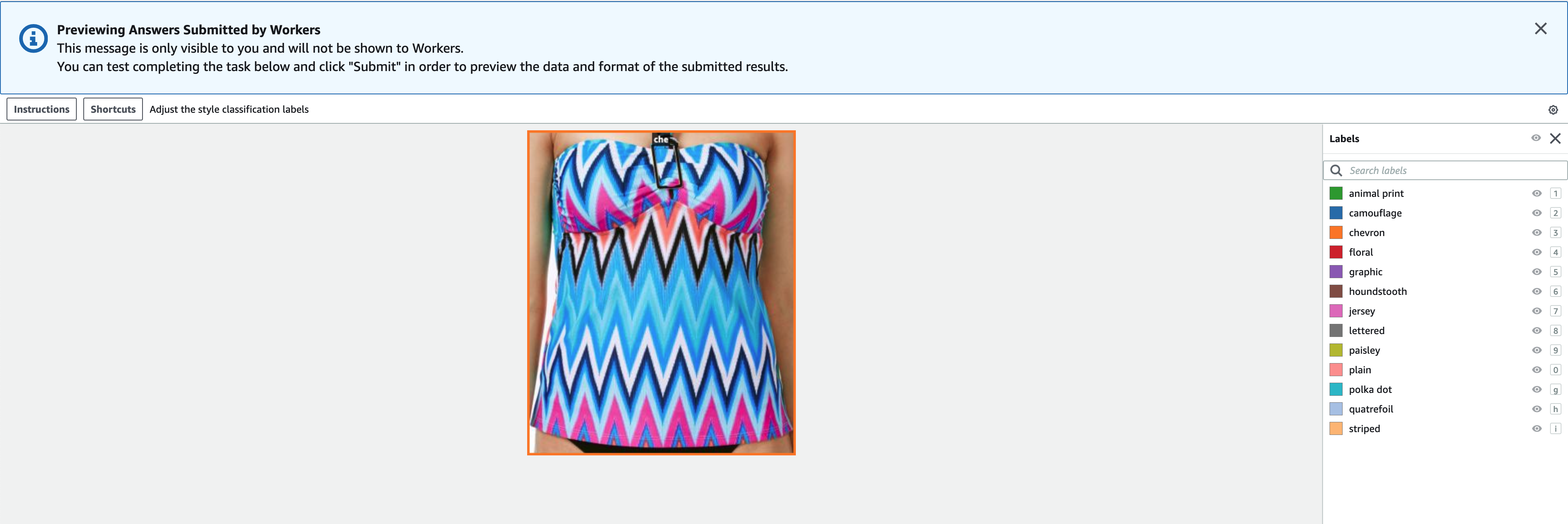
- Kies Voorbeschouwing om een voorbeeld van de afbeelding en originele annotaties te bekijken.
We hebben nu een labelopdracht gemaakt in Ground Truth. Nadat onze taak is voltooid, kunnen we de nieuw gegenereerde gelabelde gegevens in FiftyOne laden. Ground Truth produceert uitvoergegevens in een Ground Truth-uitvoermanifest. Zie voor meer informatie over het uitvoermanifestbestand Bounding Box-taakuitvoer. De volgende code toont een voorbeeld van deze indeling van het uitvoermanifest:
Bekijk gelabelde resultaten van Ground Truth in FiftyOne
Nadat de taak is voltooid, downloadt u het uitvoermanifest van de labeltaak van Amazon S3.
Lees het uitvoermanifestbestand:
Maak een FiftyOne-dataset en converteer de manifestregels naar voorbeelden in de dataset:
U kunt nu gelabelde gegevens van hoge kwaliteit van Ground Truth in FiftyOne bekijken.
Conclusie
In deze post hebben we laten zien hoe je datasets van hoge kwaliteit kunt bouwen door de kracht van te combineren Eenenvijftig by Voxel 51, een open-source toolkit waarmee u uw dataset kunt beheren, volgen, visualiseren en cureren, en Ground Truth, een service voor het labelen van gegevens waarmee u de datasets die nodig zijn voor het trainen van ML-systemen efficiënt en nauwkeurig kunt labelen door toegang te bieden tot meerdere ingebouwde -in taaksjablonen en toegang tot een divers personeelsbestand via Mechanical Turk, externe leveranciers of uw eigen privépersoneel.
We raden u aan om deze nieuwe functionaliteit uit te proberen door een FiftyOne-instantie te installeren en de Ground Truth-console te gebruiken om aan de slag te gaan. Voor meer informatie over Ground Truth, zie Label gegevens, Veelgestelde vragen over Amazon SageMaker-gegevenslabelsEn AWS Blog over machine learning.
Maak contact met de Machine Learning & AI-gemeenschap als u vragen of feedback heeft!
Word lid van de FiftyOne-community!
Sluit je aan bij de duizenden ingenieurs en datawetenschappers die FiftyOne al gebruiken om enkele van de meest uitdagende problemen op het gebied van computervisie op te lossen!
Over de auteurs
Shalendra Chabra is momenteel Head of Product Management voor Amazon SageMaker Human-in-the-Loop (HIL) Services. Eerder was Shalendra de incubator en leider van Language and Conversational Intelligence voor Microsoft Teams Meetings, was EIR bij Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing bij Bespreek.io, Head of Product and Marketing bij Clipboard (overgenomen door Salesforce) en Lead Product Manager bij Swype (overgenomen door Nuance). In totaal heeft Shalendra geholpen bij het bouwen, verzenden en op de markt brengen van producten die meer dan een miljard levens hebben geraakt.
Jacob Marks is een Machine Learning Engineer en Developer Evangelist bij Voxel51, waar hij helpt transparantie en duidelijkheid te brengen in de data van de wereld. Voordat hij bij Voxel51 kwam, richtte Jacob een startup op om opkomende muzikanten te helpen contact te leggen en creatieve inhoud te delen met fans. Daarvoor werkte hij bij Google X, Samsung Research en Wolfram Research. In een vorig leven was Jacob een theoretisch natuurkundige en promoveerde hij aan Stanford, waar hij kwantumfasen van materie onderzocht. In zijn vrije tijd houdt Jacob van klimmen, hardlopen en sciencefictionromans lezen.
Jason Corso is mede-oprichter en CEO van Voxel51, waar hij de strategie stuurt om transparantie en duidelijkheid te brengen in de gegevens van de wereld door middel van ultramoderne flexibele software. Hij is ook hoogleraar Robotica, Elektrotechniek en Computerwetenschappen aan de Universiteit van Michigan, waar hij zich richt op geavanceerde problemen op het snijvlak van computervisie, natuurlijke taal en fysieke platforms. In zijn vrije tijd brengt Jason graag tijd door met zijn gezin, lezen, in de natuur zijn, bordspellen spelen en allerlei creatieve activiteiten ondernemen.
Brian Moore is mede-oprichter en CTO van Voxel51, waar hij de technische strategie en visie leidt. Hij is gepromoveerd in Electrical Engineering aan de Universiteit van Michigan, waar zijn onderzoek was gericht op efficiënte algoritmen voor grootschalige machine learning-problemen, met een bijzondere nadruk op computer vision-toepassingen. In zijn vrije tijd houdt hij van badminton, golf, wandelen en spelen met zijn tweelingbroer Yorkshire Terriers.
Zhuling Bai is Software Development Engineer bij Amazon Web Services. Ze werkt aan de ontwikkeling van grootschalige gedistribueerde systemen om machine learning-problemen op te lossen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- : heeft
- :is
- :niet
- :waar
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Over
- versnellen
- versnellen
- versneller
- toegang
- accuraat
- nauwkeurig
- verworven
- activiteiten
- toevoegen
- toe te voegen
- adres
- gecorrigeerd
- Aanpassing
- Na
- weer
- AI
- Alexa
- algoritmen
- Alles
- toestaat
- alleen
- al
- ook
- Amazone
- amazone alexa
- Amazon Sage Maker
- Amazon SageMaker Grondwaarheid
- Amazon Web Services
- onder
- an
- analyseren
- en
- dier
- elke
- gebruiken
- Aanvraag
- toepassingen
- Solliciteer
- passend
- ZIJN
- geregeld
- dit artikel
- artikelen
- AS
- geassocieerd
- At
- auteurs
- weg
- AWS
- baseren
- gebaseerde
- BE
- omdat
- worden
- geweest
- vaardigheden
- achter
- Achter de schermen
- wezen
- geloofd wie en wat je bent
- BEST
- Betere
- tussen
- Miljard
- boord
- Gezelschapsspelletjes
- BOT
- Bootstrap
- zowel
- Box camera's
- dozen
- Hersenen
- Breken
- brengen
- bracht
- begroting
- bouw
- Gebouw
- ingebouwd
- maar
- kopen
- by
- CAN
- Het vastleggen
- geval
- gevallen
- categorieën
- Categorie
- ceo
- uitdagen
- uitdagend
- controle
- Kies
- helderheid
- klasse
- klassen
- classificatie
- Schoonmaak
- duidelijk
- duidelijk
- klant
- Beklimming
- Sluiten
- dichterbij
- kleren
- Kleding
- Mede-oprichter
- code
- combineren
- combineren
- afstand
- Aanvulling
- compleet
- het invullen van
- Berekenen
- computer
- Computer Science
- Computer visie
- Computer Vision-toepassingen
- vertrouwen
- zeker
- Verbinden
- overweging
- bestaande uit
- troosten
- bevat
- content
- inhoud
- gecontroleerd
- spraakzaam
- converteren
- kopieën
- Kern
- gecorrigeerd
- komt overeen
- Kosten
- Kosten
- en je merk te creëren
- aangemaakt
- Creatieve
- Geloofsbrieven
- CTO
- curated
- curating
- Op dit moment
- gewoonte
- klant
- Klanten
- Snijden
- op het randje
- gegevens
- datasets
- beslissen
- tonen
- Denim
- diepte
- beschrijving
- gegevens
- Opsporing
- Ontwikkelaar
- het ontwikkelen van
- Ontwikkeling
- anders
- direct
- directories
- Display
- onderscheiden
- verdeeld
- gedistribueerde systemen
- diversen
- do
- Nee
- Hond
- doen
- gedaan
- Dont
- DOT
- beneden
- Download
- duplicaten
- e
- elk
- En het is heel gemakkelijk
- rand
- effect
- doeltreffend
- efficiënt
- Elektrotechniek
- inbedding
- opkomende
- nadruk
- telt
- machtigt
- ingekapseld
- aanmoedigen
- einde
- ingenieur
- Engineering
- Ingenieurs
- Enter
- Milieu
- gelijkheid
- essentieel
- gevestigd
- Ether (ETH)
- evalueren
- Evangelist
- precies
- voorbeeld
- bestaand
- exporteren
- tamelijk
- familie
- <p></p>
- feedback
- weinig
- Fictie
- veld-
- Velden
- Dien in
- Bestanden
- filter
- filtering
- finale
- Voornaam*
- geschikt
- flexibel
- Focus
- gericht
- richt
- volgend
- Voor
- formulier
- formaat
- Gelukkig
- Opgericht
- vier
- Gratis
- oppompen van
- geheel
- functionaliteit
- Spellen
- voor algemeen gebruik
- voortbrengen
- gegenereerde
- krijgen
- GitHub
- Geven
- gegeven
- doel
- golfen
- goed
- Kopen Google Reviews
- meer
- Raster
- Ground
- Groep
- gids
- gelukkig
- Hebben
- he
- hoofd
- Hoogte
- hulp
- geholpen
- nuttig
- helpt
- hier
- hoogwaardige
- hoge-resolutie
- hoogst
- zeer
- wandelen
- zijn
- houdt
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- menselijk
- i
- IAM
- ID
- identificeren
- het identificeren van
- ids
- if
- beeld
- afbeeldingen
- Impact
- importeren
- het verbeteren van
- in
- Anders
- Inclusief
- onjuist
- geïncubeerd
- informatie
- eerste
- eerste
- installeren
- installeren
- instantie
- verkrijgen in plaats daarvan
- instructies
- Intelligentie
- kruispunt
- in
- IT
- HAAR
- Jersey
- Jobomschrijving:
- aansluiting
- gewricht
- json
- voor slechts
- Houden
- houden
- label
- etikettering
- labels
- taal
- grootschalig
- lancering
- lancering
- leiden
- Leads
- LEARN
- leren
- minst
- LED
- links
- Laten we
- Bibliotheek
- Life
- als
- Waarschijnlijk
- LIMIT
- Beperkt
- Lijn
- lijnen
- Lijst
- vermelding
- Meldingen
- Elke kleine stap levert grote resultaten op!
- Lives
- laden
- Kijk
- op zoek
- lot
- Laag
- machine
- machine learning
- gemaakt
- magie
- maken
- MERKEN
- beheer
- beheerd
- management
- manager
- veel
- kaart
- Markt
- Marketing
- Match
- matching
- wezenlijk
- Materie
- Mei..
- mechanisch
- Media
- vergaderingen
- meta
- Metadata
- methode
- methoden
- Michigan
- Microsoft
- Microsoft teams
- macht
- minimum
- ML
- Mobile
- Applicatie voor de mobiele telefoon
- model
- modellen
- Modules
- meer
- meest
- beweging
- veel
- meervoudig
- musici
- Dan moet je
- naam
- Genoemd
- namen
- Naturel
- Natuurlijke taal
- NATUUR
- Nabij
- nodig
- noodzakelijk
- Noodzaak
- behoeften
- New
- merkbaar
- notie
- nu
- Shade
- aantal
- object
- Objectdetectie
- objecten
- of
- officieel
- on
- eens
- EEN
- online.
- Slechts
- open
- open source
- Operations
- kansen
- Opties
- or
- Georganiseerd
- origineel
- OS
- Overige
- Overig
- onze
- uit
- geschetst
- uitgang
- over
- het te bezitten.
- bezit
- Packs
- gepaarde
- deel
- bijzonder
- verleden
- pad
- Patronen
- patronen
- prestatie
- persoon
- Gepersonaliseerde
- Fasen van materie
- Fysiek
- kiezen
- Foto's
- PLAID
- Eenvoudig
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- punt
- bevolkte
- mogelijk
- Post
- energie
- praktijk
- voorspeld
- voorspelling
- Voorspellingen
- Voorbeschouwing
- vorig
- die eerder
- Voorafgaand
- privaat
- waarschijnlijk
- problemen
- Product
- product management
- product manager
- Producten
- Hoogleraar
- project
- eigendom
- aanstaande
- prototype
- zorgen voor
- mits
- het verstrekken van
- publiek
- stempel
- doeleinden
- Python
- Quantum
- Contact
- snel
- reeks
- liever
- lezing
- klaar
- adviseren
- aanbevelingen
- verminderen
- Gereduceerd
- reductie
- relatief
- uitgebracht
- relevante
- verwijderen
- vertegenwoordiger
- vertegenwoordigen
- nodig
- onderzoek
- onderzoekers
- Resolutie
- beperken
- resultaat
- verkregen
- Resultaten
- <HR>Retail
- terugkeer
- beoordelen
- bevrijden
- robotica
- robuust
- Rol
- ruw
- RIJ
- ruïneren
- lopend
- sagemaker
- Zei
- verkoopsteam
- dezelfde
- Samsung
- Bespaar
- Scenes
- Wetenschap
- Science Fiction
- wetenschappers
- partituur
- naadloos
- Tweede
- sectie
- secties
- zien
- lijken
- lijkt
- gekozen
- zin
- apart
- service
- Diensten
- Sessie
- reeks
- Delen
- ze
- moet
- tonen
- Shows
- SIM
- gelijk
- Eenvoudig
- kleinere
- So
- Software
- software development
- OPLOSSEN
- sommige
- Iemand
- iets
- Tussenruimte
- besteden
- Uitgaven
- spleet
- splits
- stanford
- begin
- gestart
- Start
- startup
- start-versneller
- state-of-the-art
- Stappen
- Still
- mediaopslag
- shop
- Strategie
- stijl
- stijlen
- OVERZICHT
- ondersteunde
- Systems
- Nemen
- Taak
- teams
- Technisch
- TechStars
- vertelt
- templates
- proef
- neem contact
- dat
- De
- hun
- Ze
- harte
- theoretisch
- Er.
- Deze
- ze
- spullen
- denken
- van derden
- dit
- duizenden kosten
- drempel
- Door
- Het werpen
- niet de tijd of
- naar
- samen
- tools
- toolkit
- top
- hoogste niveau
- Tops
- Totaal
- aangeraakt
- spoor
- Trainen
- getraind
- Trainingen
- Transformeren
- Transparantie
- waar
- waarheid
- BEURT
- twee
- type dan:
- types
- voor
- begrijpen
- unieke
- universiteit-
- Universiteit van Michigan
- bijwerken
- us
- .
- use case
- gebruikt
- Gebruiker
- gebruikers
- gebruik
- Values
- variëteit
- divers
- vendors
- controleren
- zeer
- via
- Bekijk
- Virtueel
- visie
- willen
- was
- we
- web
- webservices
- GOED
- waren
- Wat
- wanneer
- of
- welke
- Wikipedia
- wil
- Met
- binnen
- zonder
- Dames
- woorden
- Mijn werk
- werkte
- werknemers
- Workforce
- Bedrijven
- s werelds
- zorgen
- zou
- schrijven
- X
- u
- Your
- zephyrnet
- Postcode
- ZOO