이미지로 jcomp on Freepik
시계열은 데이터 과학 분야의 고유한 데이터 세트입니다. 데이터는 시간-빈도(예: 매일, 매주, 매월 등)로 기록되며 각 관찰은 서로 관련됩니다. 시계열 데이터는 시간 경과에 따라 데이터에 발생하는 상황을 분석하고 향후 예측을 생성하려는 경우에 유용합니다.
시계열 예측은 과거 시계열 데이터를 기반으로 미래 예측을 생성하는 방법입니다. 시계열 예측에는 다음과 같은 많은 통계적 방법이 있습니다. 아리마 or 지수 평활화.
시계열 예측은 비즈니스에서 자주 발생하므로 데이터 과학자가 시계열 모델을 개발하는 방법을 아는 것이 좋습니다. 이 기사에서는 널리 사용되는 두 가지 예측 Python 패키지를 사용하여 시계열을 예측하는 방법을 배웁니다. 통계 모델 및 예언자. 그것에 들어가자.
XNUMXD덴탈의 통계 모델 Python 패키지는 시계열 예측 모델을 포함한 다양한 통계 모델을 제공하는 오픈 소스 패키지입니다. 예제 데이터 세트로 패키지를 사용해 봅시다. 이 문서에서는 디지털 통화 시계열 Kaggle(CC0: 퍼블릭 도메인)의 데이터.
데이터를 정리하고 가지고 있는 데이터 세트를 살펴보겠습니다.
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
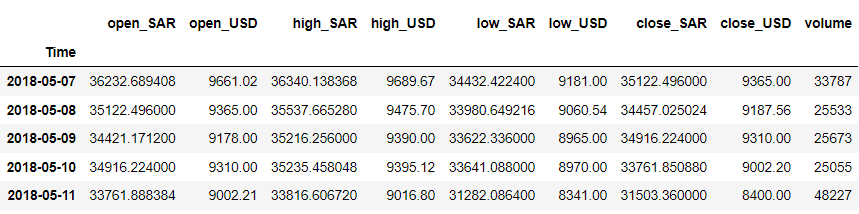
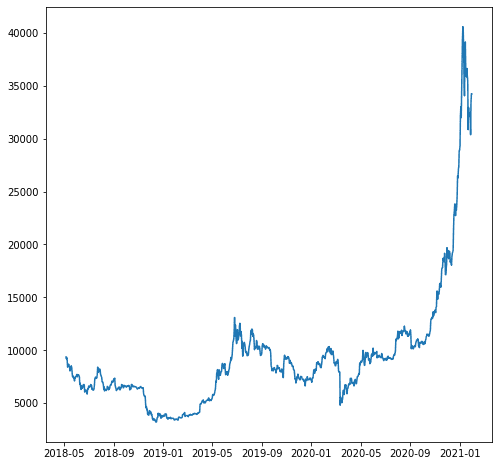
예를 들어 'close_USD' 변수를 예측한다고 가정해 보겠습니다. 시간 경과에 따른 데이터 패턴을 살펴보겠습니다.
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
위의 데이터를 기반으로 예측 모델을 구축해 보겠습니다. 모델링하기 전에 데이터를 학습 데이터와 테스트 데이터로 분할해 보겠습니다.
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
시계열 데이터이기 때문에 무작위로 데이터를 분할하지 않고 순서를 유지해야 합니다. 대신 이전 데이터의 학습 데이터와 최신 데이터의 테스트 데이터를 사용하려고 합니다.
statsmodels를 사용하여 예측 모델을 만들어 보겠습니다. 그만큼 통계 모델 많은 시계열 모델 API를 제공하지만 여기서는 ARIMA 모델을 예로 사용합니다.
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
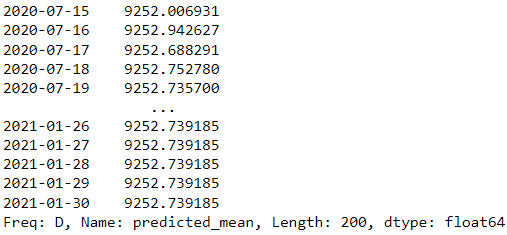
위의 예에서는 statsmodels의 ARIMA 모델을 예측 모델로 사용하고 다음 200일을 예측하려고 합니다.
모델 결과가 좋은가요? 그것들을 평가해 봅시다. 시계열 모델 평가는 일반적으로 시각화 그래프를 사용하여 MAE(Mean Absolute Error), RMSE(Root Mean Square Error) 및 MAPE(Mean Absolute Percentage Error)와 같은 회귀 메트릭으로 실제 및 예측을 비교합니다.
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
위의 점수는 괜찮아 보이지만 시각화했을 때 어떻게 되는지 봅시다.
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
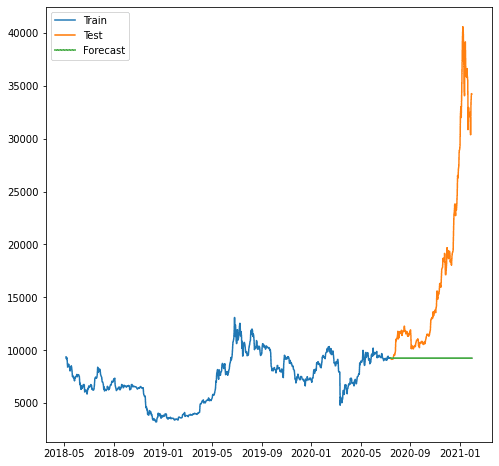
보시다시피 모델이 증가 추세를 예측할 수 없기 때문에 예측이 더 나빴습니다. 우리가 사용하는 모델 ARIMA는 예측하기에는 너무 단순해 보입니다.
statsmodels 이외의 다른 모델을 사용해 보는 것이 더 나을 수도 있습니다. Facebook의 유명한 예언자 패키지를 사용해 봅시다.
예언자 계절 효과가 있는 데이터에서 가장 잘 작동하는 시계열 예측 모델 패키지입니다. 또한 Prophet은 누락된 데이터와 이상값을 처리할 수 있기 때문에 강력한 예측 모델로 간주되었습니다.
Prophet 패키지를 사용해 봅시다. 먼저 패키지를 설치해야 합니다.
pip install prophet
그런 다음 예측 모델 학습을 위한 데이터 세트를 준비해야 합니다. Prophet에는 특정 요구 사항이 있습니다. 시간 열의 이름은 'ds'로, 값은 'y'로 지정해야 합니다.
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
데이터가 준비되면 데이터를 기반으로 예측 예측을 생성해 보겠습니다.
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
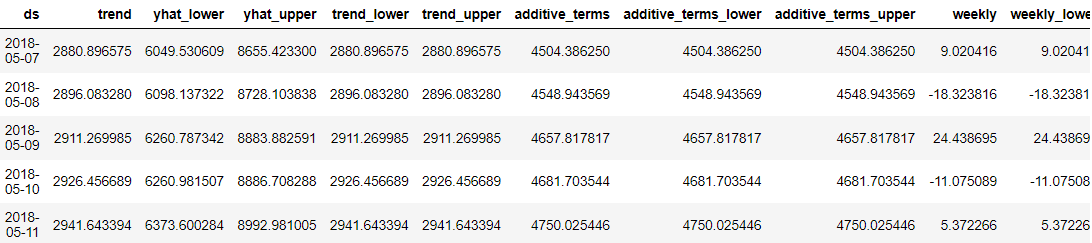
Prophet의 장점은 모든 예측 데이터 포인트가 사용자가 이해할 수 있도록 자세히 설명되어 있다는 것입니다. 그러나 데이터만으로는 결과를 이해하기 어렵다. 따라서 Prophet을 사용하여 시각화할 수 있습니다.
model.plot(predictions)
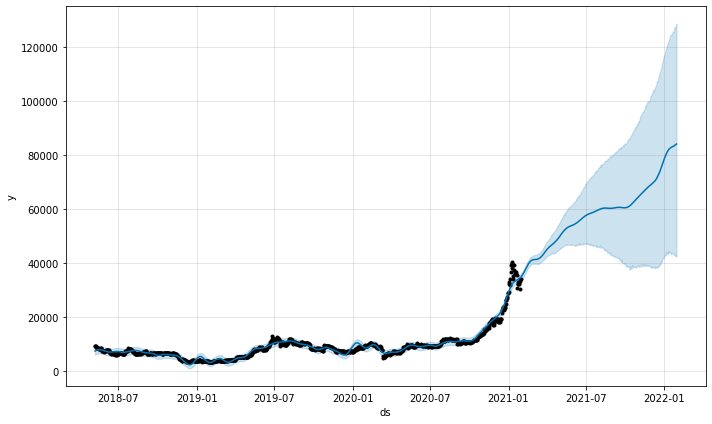
모델의 예측 플롯 기능은 예측이 얼마나 신뢰할 수 있는지 알려줍니다. 위의 플롯에서 예측이 상승 추세를 보이지만 불확실성이 증가함에 따라 예측이 길어지는 것을 볼 수 있습니다.
다음 기능을 사용하여 예측 구성요소를 검토할 수도 있습니다.
model.plot_components(predictions)
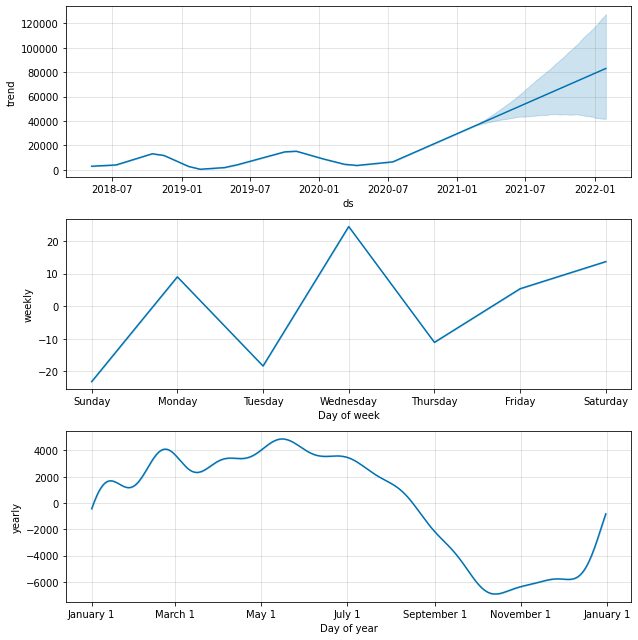
기본적으로 연간 및 주간 계절성으로 데이터 추세를 얻습니다. 데이터에 어떤 일이 발생하는지 설명하는 좋은 방법입니다.
Prophet 모델도 평가할 수 있습니까? 전적으로. Prophet에는 사용할 수 있는 진단 측정이 포함되어 있습니다. 시계열 교차 검증. 이 방법은 과거 데이터의 일부를 사용하고 컷오프 지점까지의 데이터를 사용할 때마다 모델을 적합합니다. 그런 다음 선지자는 예측을 실제 예측과 비교할 것입니다. 코드를 사용해 봅시다.
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
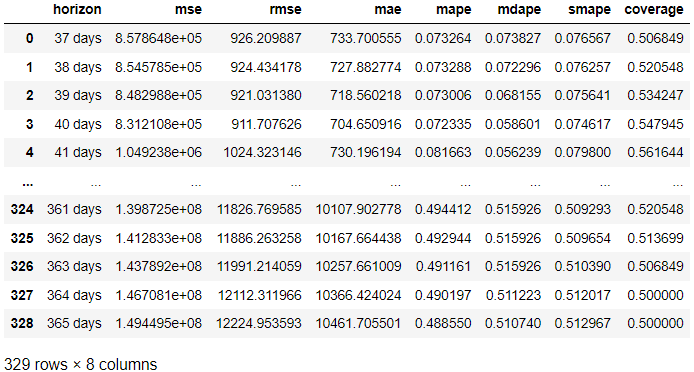
위의 결과에서 각 예보일의 예보와 실제 결과를 비교하여 평가한 결과를 얻었습니다. 다음 코드를 사용하여 결과를 시각화하는 것도 가능합니다.
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
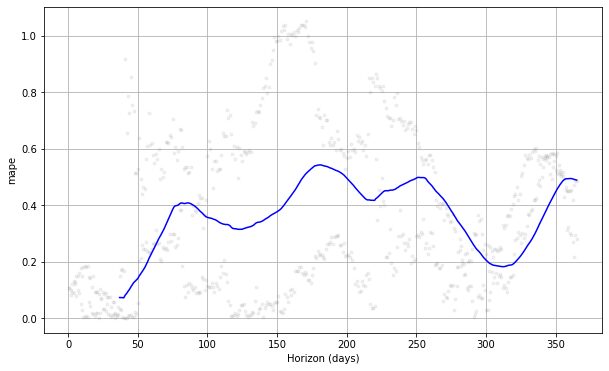
위의 플롯을 보면 예측 오차가 날짜에 따라 달라지며 일부 지점에서 50% 오차를 달성할 수 있음을 알 수 있습니다. 이렇게 하면 오류를 수정하기 위해 모델을 추가로 조정할 수 있습니다. 당신은 확인할 수 있습니다 선적 서류 비치 추가 탐색을 위해.
예측은 비즈니스에서 발생하는 일반적인 경우 중 하나입니다. 예측 모델을 개발하는 쉬운 방법 중 하나는 statsforecast 및 Prophet Python 패키지를 사용하는 것입니다. 이 기사에서는 예측 모델을 만들고 statsforecast 및 Prophet을 사용하여 이를 평가하는 방법을 알아봅니다.
코넬리우스 유다 위자야 데이터 과학 보조 관리자 및 데이터 작성자입니다. Allianz Indonesia에서 풀타임으로 일하는 동안 그는 소셜 미디어와 글쓰기 미디어를 통해 Python 및 데이터 팁을 공유하는 것을 좋아합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :이다
- $UP
- 1
- 11
- 7
- 8
- 9
- a
- 소개
- 위의
- 절대
- 절대적으로
- 달성
- 획득한
- 알리안츠
- 분석하다
- 과
- 다른
- API
- 있군요
- 기사
- AS
- 조수
- At
- 기반으로
- BE
- 때문에
- 전에
- 유익한
- BEST
- 더 나은
- 사이에
- 빌드
- 사업
- by
- 계산하다
- CAN
- 가지 경우
- CC0
- 검사
- 암호
- 단
- 열
- 공통의
- 비교
- 비교
- 구성 요소들
- 자신감
- 고려
- 수
- 적용 범위
- 만들
- 환율
- 매일
- 데이터
- 데이터 과학
- 데이터 과학자
- 날짜
- 일
- 일
- dc
- 태만
- 상세한
- 개발
- 도메인
- 말라
- e
- 마다
- 이전
- 효과
- 오류
- 등
- 평가
- 평가
- 모든
- 예
- 설명
- 탐구
- 페이스북
- 유명한
- 들
- 끝
- 먼저,
- 맞게
- 수정
- 수행원
- 럭셔리
- 예보
- 에
- 기능
- 추가
- 미래
- 얻을
- GitHub의
- 좋은
- 그래프
- 큰
- 핸들
- 발생
- 하드
- 있다
- 역사적인
- 수평선
- 방법
- How To
- 그러나
- HTML
- HTTPS
- import
- in
- 포함
- 포함
- 증가
- 증가
- 색인
- 인도네시아 공화국
- 처음에는
- 설치
- 를 받아야 하는 미국 여행자
- IT
- JPG
- 너 겟츠
- 알아
- 최근
- 배우다
- 링크드인
- 이상
- 보기
- 봐라.
- 확인
- 매니저
- .
- 매트플롯립
- 미디어
- 방법
- 방법
- 통계
- 수도
- 누락
- 모델
- 모델링
- 모델
- 월
- 이름
- 필요
- 요구
- 다음 것
- numpy
- 획득
- of
- 제공
- on
- ONE
- 오픈 소스
- 주문
- 기타
- 외부
- 꾸러미
- 패키지
- 팬더
- 매개 변수
- 부품
- 무늬
- tỷ lệ phần trăm
- 수행
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 포인트 적립
- 전철기
- 인기 문서
- 가능한
- 예측
- 예측
- 예측
- Prepare
- 제공
- 제공
- 공개
- Python
- 준비
- 기록
- 되돌아옴
- 관련
- 요구 사항
- 결과
- 결과
- 강력한
- 뿌리
- 과학
- 과학자
- 것
- 연속
- 세트
- 공유
- 단순, 간단, 편리
- So
- 사회적
- 소셜 미디어
- 일부
- 구체적인
- 분열
- 광장
- 통계적인
- 이러한
- 받아
- test
- 그
- XNUMXD덴탈의
- 그들
- 시간
- 시계열
- 도움말
- 에
- 너무
- Train
- 트레이닝
- 경향
- 불확실성
- 이해
- 유일한
- 이름 없음
- 상승
- us
- 사용
- 사용자
- 보통
- 가치 있는
- 가치
- 여러
- 를 통해
- 심상
- 방법..
- 주간
- 잘
- 뭐
- 동안
- 위키 백과
- 의지
- 과
- 이내
- 일하는
- 일
- 겠지
- 작가
- 쓰기
- 너의
- 제퍼 넷