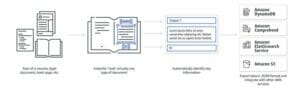
오늘부터 사용할 수 있습니다. Amazon SageMaker 자동 조종 장치 최대 100GB의 대용량 데이터 세트에 대한 회귀 및 분류 작업을 처리합니다. 또한 이제 데이터 세트를 CSV 또는 아파치 마루 콘텐츠 유형.
기업은 그 어느 때보다 많은 데이터를 생성하고 있습니다. 이러한 대규모 데이터 세트에서 인사이트를 생성하여 비즈니스 의사 결정을 내리는 데 대한 해당 수요가 증가하고 있습니다. 그러나 이러한 대규모 데이터 세트에서 최신 기계 학습(ML) 알고리즘을 성공적으로 교육하는 것은 어려울 수 있습니다. Autopilot은 이 프로세스를 자동화하고 최대 100GB의 대규모 데이터 세트에서 자동화된 기계 학습(AutoML)을 실행하기 위한 원활한 환경을 제공합니다.
Autopilot은 다음과 같은 경우 희귀 클래스를 유지하면서 지원되는 최대 제한에 맞게 자동으로 대규모 데이터 세트를 서브샘플링합니다. 수업 불균형. 클래스 불균형은 특히 대규모 데이터 세트를 처리할 때 ML에서 인식해야 하는 중요한 문제입니다. 거래의 극히 일부만이 사기일 것으로 예상되는 사기 탐지 데이터 세트를 고려하십시오. 이 경우 Autopilot은 사기가 아닌 대다수 클래스의 트랜잭션만 서브샘플링하고 드문 클래스의 사기 트랜잭션을 보존합니다.
Autopilot을 사용하여 AutoML 작업을 실행하면 서브샘플링에 대한 모든 관련 정보가 아마존 클라우드 워치. 다음에 대한 로그 그룹으로 이동합니다. /aws/sagemaker/ProcessingJobs, AutoML 작업의 이름을 검색하고 다음을 포함하는 CloudWatch 로그 스트림을 선택합니다. -db- 그 이름으로.
많은 고객이 대규모 데이터 세트를 저장하기 위해 Parquet 콘텐츠 유형을 선호합니다. 이는 일반적으로 압축 특성, 고급 데이터 구조 지원, 효율성 및 저비용 운영 때문입니다. 이 데이터는 종종 최대 수십 또는 수백 GB에 이를 수 있습니다. 이제 이러한 Parquet 데이터 세트를 Autopilot으로 직접 가져올 수 있습니다. API를 사용하거나 다음으로 이동할 수 있습니다. 아마존 세이지 메이커 스튜디오 클릭 몇 번으로 Autopilot 작업을 만들 수 있습니다. Parquet 데이터 세트의 입력 위치를 단일 파일 또는 매니페스트 파일로 지정된 여러 파일로 지정할 수 있습니다. Autopilot은 데이터 세트의 콘텐츠 유형을 자동으로 감지하고 구문 분석하며 의미 있는 기능을 추출하고 여러 ML 알고리즘을 교육합니다.
당신은 우리를 사용하여 시작할 수 있습니다 샘플 노트 Parquet 데이터 세트에서 Autopilot을 사용하여 AutoML을 실행하기 위한 것입니다.
저자에 관하여
 H. 푸르칸 보즈쿠르트, 기계 학습 엔지니어, Amazon SageMaker Autopilot.
H. 푸르칸 보즈쿠르트, 기계 학습 엔지니어, Amazon SageMaker Autopilot.
 발레리오 페로네, 응용 과학 관리자, Amazon SageMaker Autopilot.
발레리오 페로네, 응용 과학 관리자, Amazon SageMaker Autopilot.