2020년 XNUMX월 AWS는 Amazon EMR 관리형 확장. EMR 관리형 조정을 사용하여 클러스터에 대한 최소 및 최대 컴퓨팅 제한을 지정하면 Amazon EMR이 최적의 성능 및 리소스 활용을 위해 클러스터 크기를 자동으로 조정합니다. EMR Managed Scaling은 주요 워크로드 관련 메트릭을 지속적으로 모니터링하고 최상의 리소스 활용을 위해 클러스터 크기를 최적화하는 알고리즘을 사용합니다. 기능이 완벽하게 관리되므로 버전 업그레이드 없이도 알고리즘 개선이 즉시 실현됩니다. Amazon EMR은 사용량이 가장 많을 때 클러스터를 확장하고 유휴 기간 동안 점진적으로 축소하여 비용을 절감하고 최상의 성능을 위해 클러스터 용량을 최적화할 수 있습니다.
2022년 내내 EMR Managed Scaling 알고리즘을 여러 가지로 개선했습니다. 이러한 개선 사항을 통해 EMR Managed Scaling으로 활성화된 클러스터의 경우 활용도가 최대 15% 향상되고 총 비용이 최대 19% 추가로 절감되는 것을 관찰했습니다. 2022년 5.34.0월 중순부터 Amazon EMR 버전 6.4.0 이상을 사용하는 클러스터와 신규 및 기존 클러스터 모두에 대해 Amazon EMR 버전 XNUMX 이상을 사용하는 클러스터에 대해 EMR 관리형 확장 기능이 기본적으로 활성화되었습니다. 또한 기능이 완전히 관리되는 경우 기본적으로 새로운 최적화된 Managed Scaling 알고리즘을 얻게 되며 사용자 측에서 조치를 취할 필요가 없습니다.
아래 목록은 EMR Managed Scaling에 대해 활성화한 몇 가지 주요 개선 사항입니다.
- EMR 클러스터의 대상 축소로 클러스터 활용도 향상
- 다음을 사용하여 중간 셔플 데이터를 저장하는 인스턴스의 축소를 방지하여 비용 절감 Spark Shuffle 데이터 인식
- EMR 클러스터의 점진적 확장으로 클러스터 활용도 향상 및 비용 절감
고객 성공 사례
향상된 EMR Managed Scaling 알고리즘이 기술 기업의 비용 절감에 어떻게 도움이 되었는지:
예를 통해 비용 절감을 설명하기 위해 Amazon EMR을 많이 사용하여 Spark를 사용하여 Kafka와 S3 간의 실시간 청구 데이터를 처리하는 기술 기업용 EMR 클러스터를 살펴보았습니다. EMR 버전 5.35로 영구 EMR 클러스터를 실행하고 EMR 관리형 조정이 켜져 있습니다. 다음 Amazon CloudWatch 대시보드는 21월 XNUMX일부터 향상된 Managed Scaling 알고리즘이 어떻게 프로비저닝되었는지 보여줍니다. (요청된 총 노드) 유사한 작업 프로필에 대해 70개의 노드를 프로비저닝한 이전 관리형 확장 알고리즘과 비교하여 단 179개의 노드. 작업을 실행하기 위해 프로비저닝된 리소스 수가 적을수록 EMR 클러스터의 총 비용이 낮아집니다.
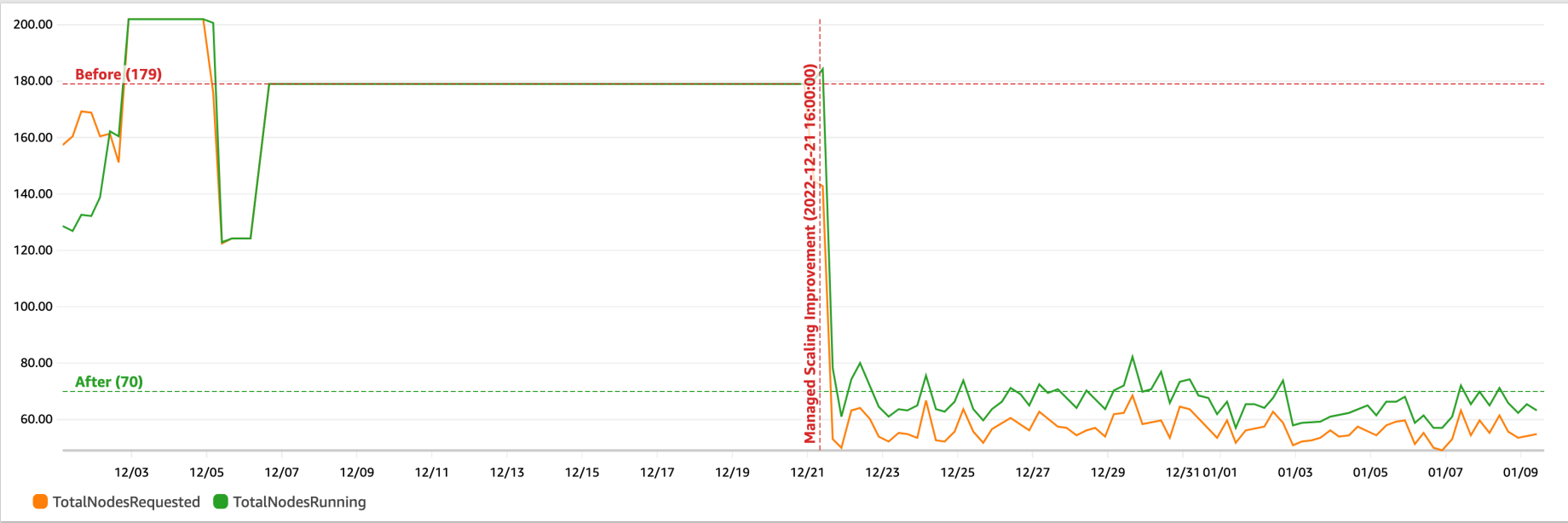
향상된 EMR Managed Scaling 알고리즘이 광고 기업의 비용 절감에 어떻게 도움이 되었는지:
또한 데이터 분석 전략에 Amazon EMR을 활용하고 Spark를 사용하여 배치 ETL 작업을 실행하는 광고 기업용 EMR 클러스터도 살펴보았습니다. EMR 버전 6.5에서 클러스터를 실행하고 EMR Managed Scaling을 켭니다. 다음 Amazon CloudWatch 대시보드는 15월 XNUMX일부터 향상된 Managed Scaling 알고리즘이 어떻게 프로비저닝되었는지 보여줍니다(요청된 총 단위) 유사한 작업 프로필에 대해 41개의 노드를 프로비저닝한 이전 관리형 확장 알고리즘과 비교하여 86개의 노드만 있습니다.
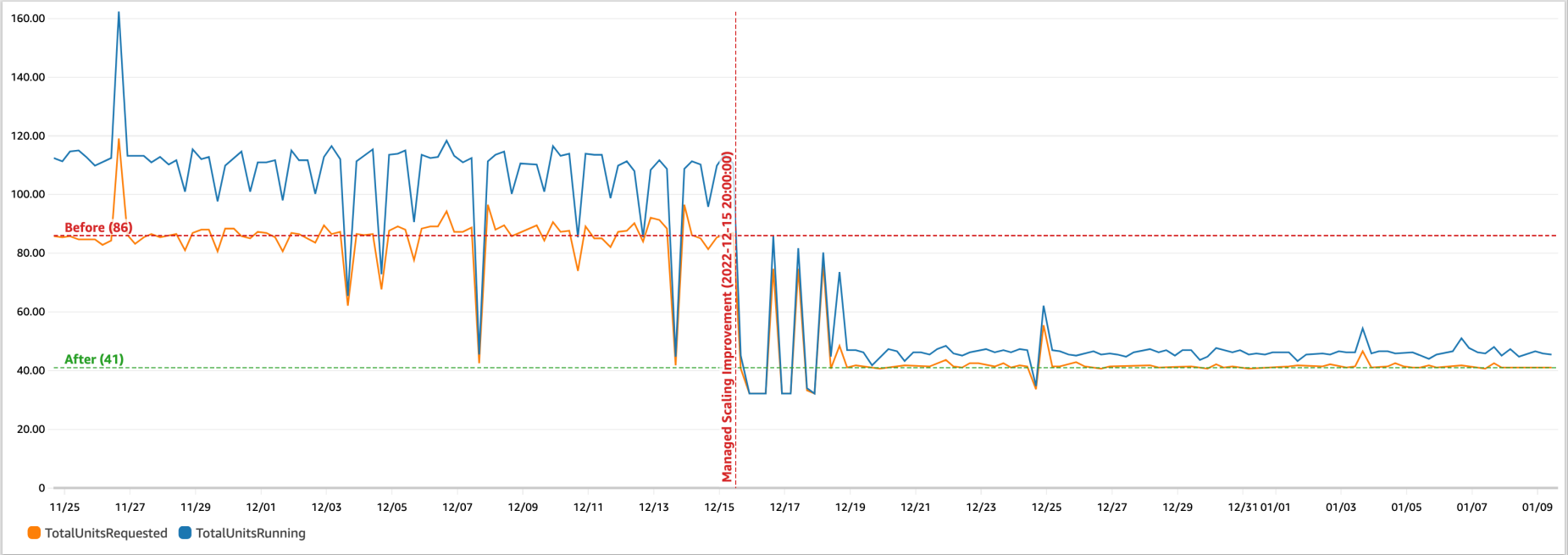
EMR 클러스터의 비용 절감 및 활용도 향상 예측:
클러스터 비용 절감:
EMR Managed Scaling 기능 향상으로 EMR 클러스터의 예상 비용 절감액을 보려면 아래 단계를 따르십시오.
- 열기 CloudWatch 지표 콘솔 그리고, 아래 EMR, 귀하의 검색
ClusterId. - EMR에 사용할 수 있는 지표 목록에서 다음 두 가지 지표를 선택합니다.
- 실행 용량 – Managed Scaling 정책에서 지정한 단위 유형에 따라 "실행 중인 총 유닛”또는“TotalNodes실행 중"또는"총VCPU실행 중".
- 관리형 조정에서 요청한 용량 – Managed Scaling 정책에서 지정한 단위 유형에 따라 "요청된 총 단위”또는“요청된 총 노드 수"또는"총VCPU요청됨".
- CloudWatch 대시보드에 두 지표를 모두 표시합니다.
- 3년 2022월부터 2023년 XNUMX월 사이의 XNUMX개월로 기간을 선택하여 이전 Managed Scaling 알고리즘과 비교할 때 향상된 Managed Scaling 알고리즘의 개선 사항을 확인하십시오.
클러스터 활용도 향상:
EMR Managed Scaling 개선 사항으로 EMR 클러스터 활용도의 개선 사항을 추정하려면 아래 단계를 따르십시오.
- CloudWatch 지표 콘솔을 열고 아래에서 EMR, 귀하의 검색
ClusterId. - EMR에 사용할 수 있는 지표 목록에서 "YARNMemoryAvailablePercentage” 미터법.
- YARN이 활용하는 메모리를 도출하려면 “Add Math → Start with empty expression”과 같은 수식을 추가합니다.
- 새 수학 표현식의 경우 다음을 설정합니다. 레이블=원사활용 설정하다 세부 정보=100-YARNMemoryAvailablePercentage.
- 클러스터 활용 지표를 CloudWatch 대시보드에 표시합니다.
- 3년 2022월부터 2023년 XNUMX월 사이의 XNUMX개월로 기간을 선택하여 이전 Managed Scaling 알고리즘과 비교할 때 향상된 Managed Scaling 알고리즘의 개선 사항을 확인하십시오.
무엇 향후 계획
새로운 EMR 릴리스가 나올 때마다 Managed Scaling 알고리즘을 계속 조정하여 EMR Managed Scaling으로 클러스터를 확장할 때 고객 경험을 개선할 것입니다.
결론
이 게시물에서는 EMR Managed Scaling에서 출시한 주요 개선 사항에 대한 개요를 제공했습니다. 이러한 개선 사항을 통해 클러스터 활용도가 최대 15% 향상되고 클러스터 비용이 최대 19% 감소한 것을 관찰했습니다. 2022년 5.34.0월 중순부터 이러한 개선 사항은 Amazon EMR 버전 6.4.0 이상 및 Amazon EMR 버전 XNUMX 이상을 사용하는 EMR 클러스터에 대해 기본적으로 활성화되었습니다. EMR Managed Scaling이 완전히 관리되는 기능이므로 기본적으로 최적화된 새로운 EMR Managed Scaling 알고리즘을 얻게 되며 사용자 측에서 조치를 취할 필요가 없습니다.
EMR 관리형 조정에 대해 자세히 알아보고 시작하려면 EMR 관리형 조정 설명서 페이지.
저자에 관하여
 수샨트 마지티아 Amazon Web Services의 EMR 수석 제품 관리자입니다.
수샨트 마지티아 Amazon Web Services의 EMR 수석 제품 관리자입니다.
 비샬 비야스 Amazon Web Services의 EMR 선임 소프트웨어 엔지니어입니다.
비샬 비야스 Amazon Web Services의 EMR 선임 소프트웨어 엔지니어입니다.
 매튜 림 AWS의 수석 솔루션 아키텍처 관리자입니다.
매튜 림 AWS의 수석 솔루션 아키텍처 관리자입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/reduce-amazon-emr-cluster-costs-by-up-to-19-with-new-enhancements-in-amazon-emr-managed-scaling/
- 2020
- 2022
- 2023
- 70
- 84
- a
- 동작
- 광고
- 연산
- 아마존
- 아마존 EMR
- Amazon Web Services
- 분석
- 와
- 발표
- 아키텍처
- 자동적으로
- 유효성
- 가능
- AWS
- 기반으로
- 이하
- BEST
- 사이에
- 청구
- 생산 능력
- 클러스터
- 비교
- 완전히
- 계산
- 콘솔에서
- 끊임없이
- 계속
- 비용
- 비용 절감
- 비용
- 고객
- 고객 경험
- 계기반
- 데이터
- 데이터 분석
- XNUMX월
- 태만
- 아래 (down)
- ...동안
- 사용 가능
- 기사
- 강화
- Enterprise
- 견적
- 예상
- 에테르 (ETH)
- 모든
- 예
- 실행
- 현존하는
- 경험
- 특색
- 따라
- 수행원
- FRAME
- 에
- 추가
- 일반
- 얻을
- 주어진
- 점진적
- 무겁게
- 도움
- 방법
- HTML
- HTTPS
- 유휴
- 바로
- 개선
- 개선하는
- 개량
- in
- 중간의
- IT
- 일월
- 일
- 작업
- 카프카
- 키
- 시작
- 배우다
- 레버리지
- 제한
- 명부
- 보고
- 만든
- 관리
- 매니저
- math
- 최고
- 메모리
- 메트릭
- 통계
- 최저한의
- 모니터
- 개월
- 배우기
- 여러
- 필요
- 필요
- 신제품
- 노드
- 십일월
- 번호
- 최적의
- 최적화
- 최적화
- 최적화
- 개요
- 퍼센트
- 성능
- 미문
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 부디
- 정책
- 게시하다
- 방지
- 너무 이른
- 교장
- 방법
- 프로덕트
- 제품 관리자
- 프로필
- 제공
- 현실
- 실시간
- 깨달은
- 감소
- 감소
- 감소
- 공개
- 요청하신
- 의지
- 자료
- 달리기
- 저금
- 규모
- 확장
- 스케일링
- 검색
- 연장자
- 서비스
- 세트
- 쇼
- 셔플
- 비슷한
- 크기
- 소프트웨어
- 소프트웨어 엔지니어
- 해결책
- 일부
- 불꽃
- 지정
- 스타트
- 시작
- 시작 중
- 단계
- 저장
- 전략
- 성공
- 이러한
- 대상
- Technology
- XNUMXD덴탈의
- 그들의
- 그것에 의하여
- 시간
- 에
- 금액
- 아래에
- 단위
- 단위
- 업그레이드
- 사용
- 버전
- 관측
- 웹
- 웹 서비스
- 어느
- 의지
- 없이
- 너의
- 제퍼 넷