이 기사에서 우리는 배울 것입니다 CPU 전용 컴퓨터에서 GPT4All 모델을 배포하고 사용하는 방법 (나는 사용하고 맥북 프로 (MacBook Pro) GPU 없이!)

컴퓨터에서 GPT4All 사용 — 저자의 그림
이 기사에서는 로컬 컴퓨터 GPT4All(강력한 LLM)에 설치하고 Python으로 문서와 상호 작용하는 방법을 알아봅니다. PDF 또는 온라인 기사 모음은 질문/답변에 대한 지식 기반이 됩니다.
에서 공식 홈페이지 GPT4All 그것은 다음과 같이 설명됩니다. 무료로 사용할 수 있고 로컬에서 실행되는 개인 정보 보호 챗봇입니다. GPU나 인터넷이 필요하지 않습니다.
GTP4All은 교육 및 배포를 위한 생태계입니다. 강한 및 사용자 정의 실행되는 대규모 언어 모델 장소 상에서 소비자 등급 CPU에서.
당사의 GPT4All 모델은 다운로드하여 GPT4All 오픈 소스 생태계 소프트웨어에 연결할 수 있는 4GB 파일입니다. 노믹 AI 고품질의 안전한 소프트웨어 에코시스템을 촉진하여 개인과 조직이 로컬에서 자체 대규모 언어 모델을 쉽게 교육하고 구현할 수 있도록 노력합니다.
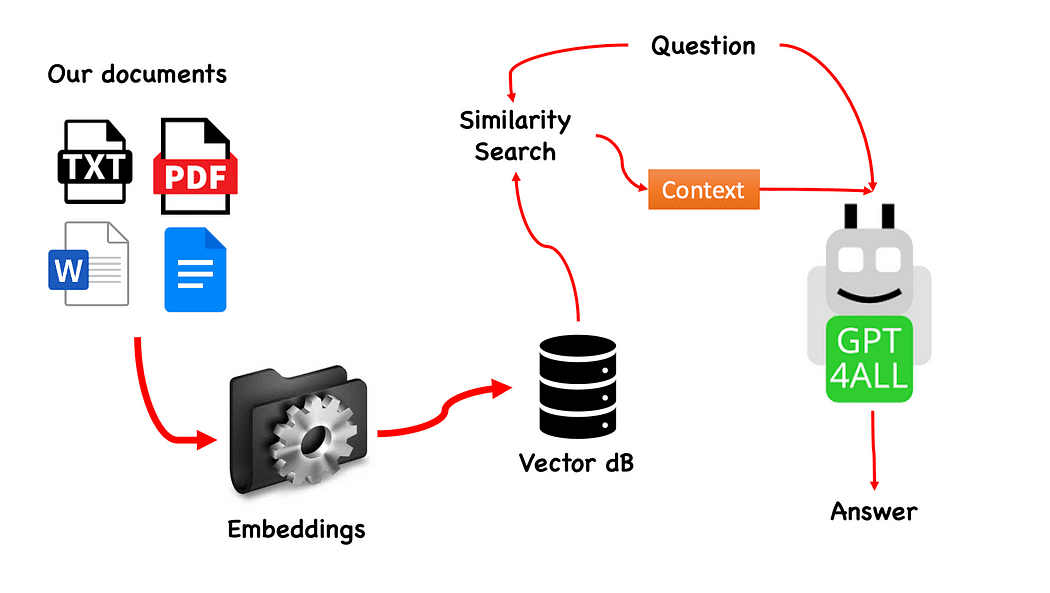
GPT4All을 사용한 QnA의 워크플로 — 작성자가 생성
프로세스는 매우 간단하며(알고 있는 경우) 다른 모델에서도 반복할 수 있습니다. 단계는 다음과 같습니다.
- GPT4All 모델 로드
- 사용 랭체인 문서 검색 및 로드
- 임베딩으로 소화할 수 있는 작은 덩어리로 문서 분할
- FAISS를 사용하여 임베딩으로 벡터 데이터베이스 생성
- GPT4All에 전달하려는 질문을 기반으로 벡터 데이터베이스에서 유사성 검색(의미 검색)을 수행합니다. 문맥 우리의 질문에
- 질문과 맥락을 GPT4All에 다음과 같이 입력하세요. 랭체인 대답을 기다리십시오.
그래서 우리에게 필요한 것은 임베딩입니다. 임베딩은 텍스트, 문서, 이미지, 오디오 등의 정보 조각을 숫자로 표현한 것입니다. 이 표현은 임베딩되는 내용의 의미론적 의미를 캡처하며 이것이 바로 우리에게 필요한 것입니다. 이 프로젝트에서는 무거운 GPU 모델에 의존할 수 없으므로 Alpaca 기본 모델을 다운로드하여 다음에서 사용합니다. 랭체인 전에, LlamaCpp임베딩. 괜찮아요! 모든 것이 단계별로 설명됩니다.
가상 환경 생성
예를 들어 GPT4ALL_Fabio(이름 입력…)와 같이 새 Python 프로젝트를 위한 새 폴더를 만듭니다.
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabio다음으로 새로운 Python 가상 환경을 만듭니다. 둘 이상의 Python 버전이 설치된 경우 원하는 버전을 지정합니다. 이 경우 Python 3.10과 연결된 기본 설치를 사용합니다.
python3 -m venv .venv명령 python3 -m venv .venv 이라는 새 가상 환경을 만듭니다. .venv (점은 venv라는 숨겨진 디렉토리를 생성합니다).
가상 환경은 격리된 Python 설치를 제공하므로 시스템 전체 Python 설치 또는 다른 프로젝트에 영향을 주지 않고 특정 프로젝트에 대한 패키지 및 종속성을 설치할 수 있습니다. 이러한 격리는 일관성을 유지하고 서로 다른 프로젝트 요구 사항 간의 잠재적인 충돌을 방지하는 데 도움이 됩니다.
가상 환경이 생성되면 다음 명령을 사용하여 활성화할 수 있습니다.
source .venv/bin/activate 
활성화된 가상 환경
설치할 라이브러리
우리가 만들고 있는 프로젝트에는 너무 많은 패키지가 필요하지 않습니다. 다음 사항만 필요합니다.
- GPT4All에 대한 파이썬 바인딩
- 문서와 상호 작용하는 Langchain
LangChain은 언어 모델로 구동되는 애플리케이션을 개발하기 위한 프레임워크입니다. 이를 통해 API를 통해 언어 모델을 호출할 수 있을 뿐만 아니라 언어 모델을 다른 데이터 소스에 연결하고 언어 모델이 해당 환경과 상호 작용할 수 있습니다.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4LangChain의 경우 버전도 지정했음을 알 수 있습니다. 이 라이브러리는 최근에 많은 업데이트를 받고 있으므로 설정이 내일도 제대로 작동하는지 확인하려면 제대로 작동하는 버전을 지정하는 것이 좋습니다. 구조화되지 않음은 pdf 로더에 대한 필수 종속성이며 피 테서 랙트 및 pdf2이미지 뿐만 아니라.
주의사항: GitHub 리포지토리에는 requirements.txt 파일이 있습니다. JL ADCR) 이 프로젝트와 관련된 모든 버전. 다음 명령을 사용하여 기본 프로젝트 파일 디렉토리에 다운로드한 후 한 번에 설치를 수행할 수 있습니다.
pip install -r requirements.txt기사의 끝에서 나는 문제 해결 섹션. GitHub 리포지토리에는 이러한 모든 정보가 포함된 업데이트된 READ.ME도 있습니다.
일부는 라이브러리에는 Python 버전에 따라 사용 가능한 버전이 있습니다. 가상 환경에서 실행 중입니다.
PC에서 모델 다운로드
이것은 정말 중요한 단계입니다.
프로젝트를 위해서는 확실히 GPT4All이 필요합니다. Nomic AI에 설명된 프로세스는 정말 복잡하며 (나처럼) 우리 모두가 가지고 있지 않은 하드웨어가 필요합니다. 그래서 여기 모델에 대한 링크입니다 이미 변환되어 사용할 준비가 되었습니다. 다운로드를 클릭하십시오.
GPT4All 모델 다운로드
서론에서 간략하게 설명했듯이 임베딩을 위한 모델, 분쇄 없이 CPU에서 실행할 수 있는 모델도 필요합니다. 클릭 alpaca-native-7B-ggml을 다운로드하려면 여기 링크 이미 4비트로 변환되었으며 임베딩을 위한 모델로 사용할 준비가 되었습니다.

옆에 있는 다운로드 화살표를 클릭합니다. ggml-모델-q4_0.bin
임베딩이 필요한 이유는 무엇입니까? 순서도에서 기억한다면 지식 기반에 대한 문서를 수집한 후 필요한 첫 번째 단계는 포함 그들을. 이 Alpaca 모델의 LLamaCPP 임베딩은 작업에 완벽하게 맞으며 이 모델도 매우 작습니다(4Gb). 그런데 QnA에 Alpaca 모델을 사용할 수도 있습니다!
업데이트 2023.05.25: Mani Windows 사용자가 llamaCPP 임베딩을 사용하는 데 문제가 있습니다. 이것은 주로 Python 패키지 llama-cpp-python을 설치하는 동안 다음과 같이 발생하기 때문에 발생합니다.
pip install llama-cpp-pythonpip 패키지는 소스 라이브러리에서 컴파일할 것입니다. Windows에는 일반적으로 컴퓨터에 기본적으로 CMake 또는 C 컴파일러가 설치되어 있지 않습니다. 하지만 해결책이 있다고 걱정하지 마세요
Windows에서 llamaEmbeddings와 함께 LangChain에 필요한 llama-cpp-python 설치 실행 CMake C 컴파일러는 기본적으로 설치되지 않으므로 소스에서 빌드할 수 없습니다.
Xtools 및 Linux를 사용하는 Mac 사용자의 경우 일반적으로 C 컴파일러는 이미 OS에서 사용할 수 있습니다.
문제를 방지하려면 미리 준수한 휠을 사용해야 합니다..
여기로 가라. https://github.com/abetlen/llama-cpp-python/releases
아키텍처 및 Python 버전에 맞는 휠을 찾습니다. Weels 버전 0.1.49를 사용해야 합니다. 더 높은 버전은 호환되지 않기 때문입니다.
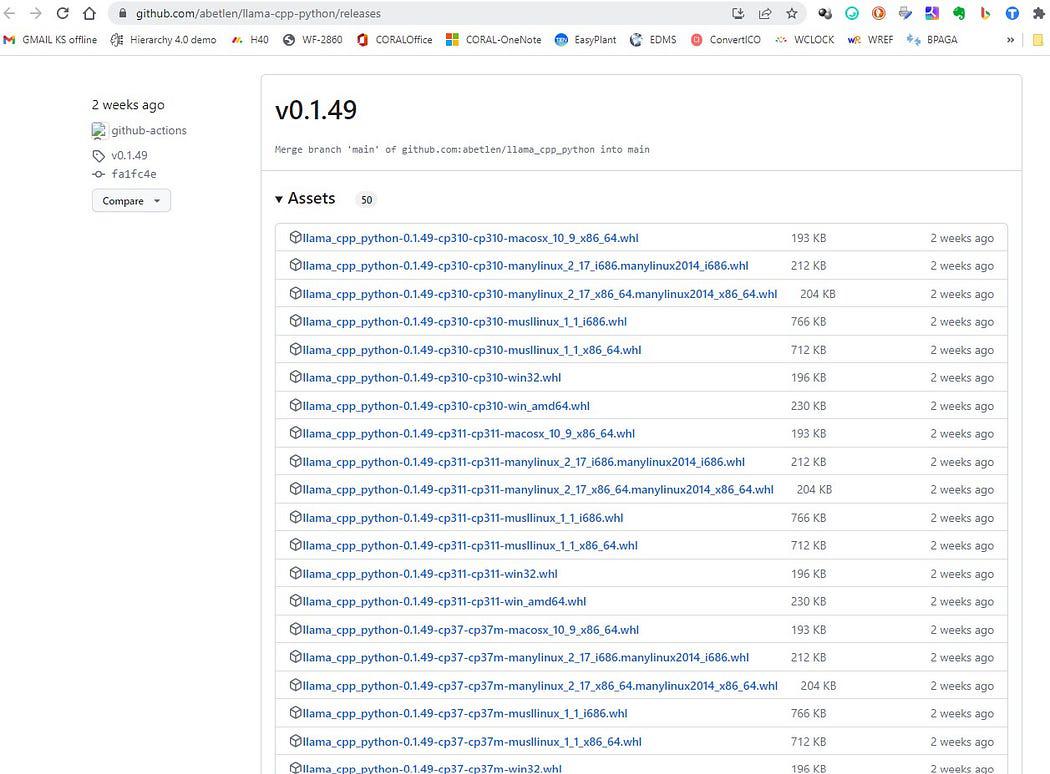
스크린 샷 : https://github.com/abetlen/llama-cpp-python/releases
제 경우에는 Windows 10, 64비트, Python 3.10이 있습니다.
그래서 내 파일은 llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl입니다.
다운로드 후 아래와 같이 모델 디렉토리에 두 모델을 넣어야 합니다.

디렉토리 구조 및 모델 파일을 저장할 위치
우리는 GPT 모델과의 상호 작용을 제어하고 싶기 때문에 Python 파일을 생성해야 합니다. pygpt4all_test.py), 종속성을 가져오고 모델에 지침을 제공합니다. 당신은 그것이 아주 쉽다는 것을 알게 될 것입니다.
from pygpt4all.models.gpt4all import GPT4All이것은 우리 모델의 파이썬 바인딩입니다. 이제 전화를 걸어 물어볼 수 있습니다. 창의적인 것을 시도해 봅시다.
모델에서 콜백을 읽는 함수를 만들고 GPT4All에 문장을 완성하도록 요청합니다.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)첫 번째 명령문은 프로그램에 모델을 찾을 위치를 알려주는 것입니다(위 섹션에서 수행한 작업을 기억하세요).
두 번째 명령문은 모델에게 응답을 생성하고 "옛날 옛적에" 프롬프트를 완료하도록 요청하는 것입니다.
실행하려면 가상 환경이 여전히 활성화되어 있는지 확인하고 다음을 실행하십시오.
python3 pygpt4all_test.py모델의 로딩 텍스트와 문장 완성이 보여야 합니다. 하드웨어 리소스에 따라 약간의 시간이 걸릴 수 있습니다.
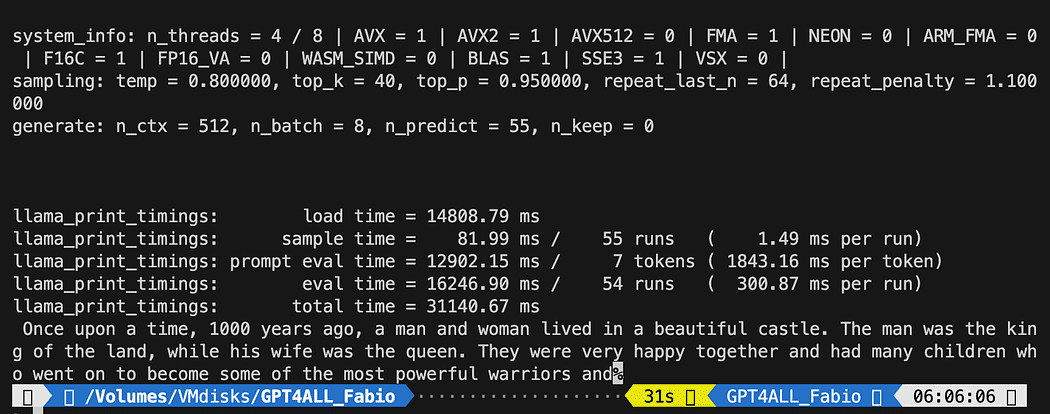
결과는 귀하의 것과 다를 수 있습니다... 하지만 우리에게 중요한 것은 이것이 작동하고 있으며 LangChain을 사용하여 몇 가지 고급 항목을 만들 수 있다는 것입니다.
참고 (2023.05.23 업데이트): pygpt4all과 관련된 오류가 발생하면 이 항목의 문제 해결 섹션에서 제공한 솔루션을 확인하십시오. 라즈니쉬 아가르왈 or 오스카 정.
LangChain 프레임워크는 정말 놀라운 라이브러리입니다. 그것은 제공합니다 구성 요소들 사용하기 쉬운 방식으로 언어 모델과 작업할 수 있으며 다음을 제공합니다. 쇠사슬. 체인은 특정 사용 사례를 가장 잘 달성하기 위해 특정 방식으로 이러한 구성 요소를 조립하는 것으로 생각할 수 있습니다. 이는 사람들이 특정 사용 사례를 쉽게 시작할 수 있는 상위 수준의 인터페이스를 위한 것입니다. 이 체인은 또한 사용자 지정이 가능하도록 설계되었습니다.
다음 파이썬 테스트에서 우리는 프롬프트 템플릿. 언어 모델은 텍스트를 입력으로 사용합니다. 이 텍스트를 일반적으로 프롬프트라고 합니다. 일반적으로 이것은 단순히 하드코딩된 문자열이 아니라 템플릿, 몇 가지 예 및 사용자 입력의 조합입니다. LangChain은 프롬프트를 쉽게 구성하고 작업할 수 있도록 여러 클래스와 기능을 제공합니다. 우리도 어떻게 할 수 있는지 봅시다.
새 파이썬 파일을 만들고 호출하십시오. my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])우리는 GPT 모델과 직접 상호 작용할 수 있도록 LangChain에서 프롬프트 템플릿과 체인 및 GPT4All llm 클래스를 가져왔습니다.
그런 다음 이전과 같이 llm 경로를 설정한 후 콜백 관리자를 인스턴스화하여 쿼리에 대한 응답을 포착할 수 있습니다.
템플릿을 만드는 것은 정말 쉽습니다. 설명서 튜토리얼 우리는 이런 것을 사용할 수 있습니다…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])XNUMXD덴탈의 이 템플릿 변수는 모델과의 상호 작용 구조를 포함하는 여러 줄 문자열입니다. 중괄호 안에 외부 변수를 템플릿에 삽입합니다. 문제.
변수이기 때문에 하드 코딩된 질문인지 사용자 입력 질문인지 결정할 수 있습니다. 여기에 두 가지 예가 있습니다.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")테스트 실행을 위해 사용자 입력 항목에 주석을 달 것입니다. 이제 템플릿, 질문 및 언어 모델을 함께 연결하기만 하면 됩니다.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)가상 환경이 여전히 활성화되어 있는지 확인하고 다음 명령을 실행하십시오.
python3 my_langchain.py나와 다른 결과를 얻을 수 있습니다. 놀라운 점은 GPT4All이 답을 얻기 위해 노력하는 전체 추론을 볼 수 있다는 것입니다. 질문을 조정하면 더 나은 결과를 얻을 수도 있습니다.
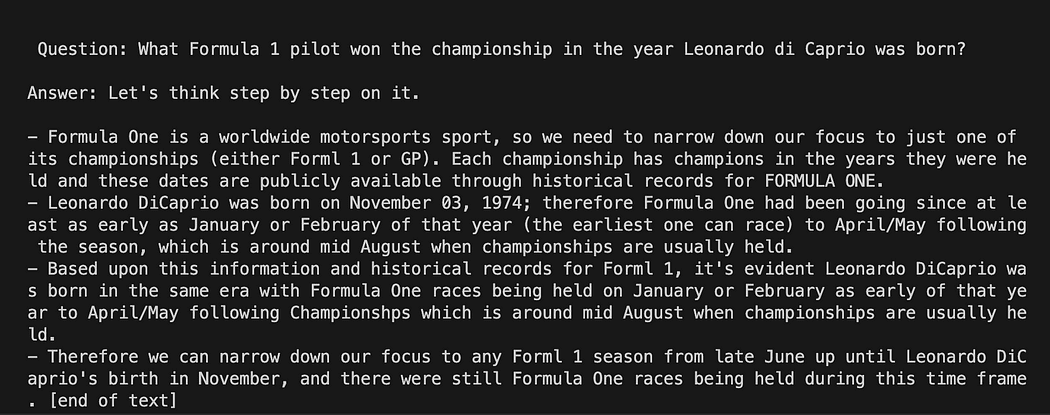
GPT4All에 프롬프트 템플릿이 있는 Langchain
여기에서 놀라운 부분을 시작합니다. GPT4All을 질문에 답하는 챗봇으로 사용하여 문서와 대화할 것이기 때문입니다.
단계의 순서, 참조 GPT4All을 사용한 QnA 워크플로우, pdf 파일을 로드하여 청크로 만드는 것입니다. 그런 다음 임베딩을 위한 벡터 저장소가 필요합니다. 우리는 정보 검색을 위해 벡터 저장소에 청크 문서를 공급해야 하며 그런 다음 LLM 쿼리의 컨텍스트로 이 데이터베이스의 유사성 검색과 함께 포함할 것입니다.
이를 위해 FAISS에서 직접 FAISS를 사용할 것입니다. 랭체인 도서관. FAISS는 대규모 고차원 데이터 컬렉션에서 유사한 항목을 빠르게 찾을 수 있도록 설계된 Facebook AI Research의 오픈 소스 라이브러리입니다. 데이터 세트 내에서 가장 유사한 항목을 더 쉽고 빠르게 찾을 수 있도록 인덱싱 및 검색 방법을 제공합니다. 단순화하기 때문에 특히 편리합니다. 정보 검색 생성된 데이터베이스를 로컬에 저장할 수 있습니다. 즉, 첫 번째 생성 후 추가 사용을 위해 매우 빠르게 로드됩니다.
벡터 인덱스 db 생성
새 파일을 만들고 호출하십시오. my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetime첫 번째 라이브러리는 이전에 사용한 것과 동일합니다. 랭체인 벡터 저장소 인덱스 생성을 위해 LlamaCpp임베딩 Alpaca 모델(4비트로 양자화되고 cpp 라이브러리로 컴파일됨) 및 PDF 로더와 상호 작용합니다.
임베딩용 경로와 텍스트 생성용 경로로 LLM을 로드해 보겠습니다.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)테스트를 위해 모든 pfd 파일을 읽을 수 있는지 살펴보겠습니다. 첫 번째 단계는 각 단일 문서에서 사용할 3개의 함수를 선언하는 것입니다. 첫 번째는 추출된 텍스트를 덩어리로 분할하는 것이고, 두 번째는 메타데이터(예: 페이지 번호 등)로 벡터 인덱스를 만드는 것이고 마지막은 유사성 검색을 테스트하기 위한 것입니다(나중에 더 자세히 설명하겠습니다).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources이제 문서에 대한 인덱스 생성을 테스트할 수 있습니다. 문서 디렉토리: 모든 PDF 파일을 거기에 넣어야 합니다. 랭체인 파일 형식에 관계없이 전체 폴더를 로드하는 방법도 있습니다. 후처리가 복잡하기 때문에 LaMini 모델에 대한 다음 기사에서 다룰 것입니다.

내 문서 디렉토리에는 4개의 pdf 파일이 있습니다.
목록의 첫 번째 문서에 기능을 적용합니다.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)첫 번째 줄에서 우리는 os 라이브러리를 사용하여 pdf 파일 목록 문서 디렉토리 내부. 그런 다음 첫 번째 문서(문서_목록[0]) 문서 폴더에서 랭체인, 청크로 분할한 다음 다음을 사용하여 벡터 데이터베이스를 만듭니다. 야마 임베딩
보시다시피 우리는 pyPDF 방법. 이것은 파일을 하나씩 로드해야 하기 때문에 사용 시간이 조금 더 길지만 다음을 사용하여 PDF를 로드합니다. pypdf 문서 배열로 각 문서가 페이지 콘텐츠와 메타데이터를 포함하는 배열을 가질 수 있습니다. page 숫자. 이는 쿼리를 통해 GPT4All에 제공할 컨텍스트의 소스를 알고 싶을 때 정말 편리합니다. 다음은 readthedocs의 예입니다.
스크린 샷 : 랭체인 문서
터미널에서 명령을 사용하여 Python 파일을 실행할 수 있습니다.
python3 my_knowledge_qna.py임베딩을 위해 모델을 로드한 후 인덱싱을 위해 작업 중인 토큰을 볼 수 있습니다. 특히 저처럼 CPU에서만 실행하는 경우 시간이 걸리므로 놀라지 마십시오(8분 소요).
첫 번째 벡터 db 완성
내가 설명했듯이 pyPDF 방법은 느리지만 유사성 검색을 위한 추가 데이터를 제공합니다. 모든 파일을 반복하기 위해 서로 다른 데이터베이스를 병합할 수 있는 FAISS의 편리한 방법을 사용합니다. 이제 우리가 하는 일은 위의 코드를 사용하여 첫 번째 db를 생성하는 것입니다( db0) 및 for 루프를 사용하여 목록에서 다음 파일의 인덱스를 생성하고 즉시 다음과 병합합니다. db0.
코드는 다음과 같습니다. 날짜시간.날짜시간.지금() 종료 시간과 시작 시간의 델타를 인쇄하여 작업에 소요된 시간을 계산합니다(싫으면 제거할 수 있음).
병합 지침은 다음과 같습니다.
# merge dbi with the existing db0
db0.merge_from(dbi)마지막 지침 중 하나는 데이터베이스를 로컬에 저장하는 것입니다. 전체 생성은 심지어 몇 시간이 걸릴 수 있으므로(보유한 문서 수에 따라 다름) 한 번만 수행하면 정말 좋습니다!
# Save the databasae locally
db0.save_local("my_faiss_index")여기에 전체 코드가 있습니다. 폴더에서 직접 인덱스를 로드하는 GPT4All과 상호 작용할 때 많은 부분에 주석을 달 것입니다.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  파이썬 파일을 실행하는 데 22분이 걸렸습니다.
파이썬 파일을 실행하는 데 22분이 걸렸습니다.
문서에 대해 GPT4All에 질문하세요.
이제 우리는 여기에 있습니다. 인덱스가 있으면 로드할 수 있고 프롬프트 템플릿을 사용하여 GPT4All에 질문에 답하도록 요청할 수 있습니다. 하드 코딩된 질문으로 시작한 다음 입력 질문을 반복합니다.
다음 코드를 파이썬 파일에 넣습니다. db_loading.py 터미널에서 명령으로 실행하십시오. 파이썬3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])인쇄된 텍스트는 쿼리와 가장 일치하는 3개의 소스 목록이며 문서 이름과 페이지 번호도 제공합니다.
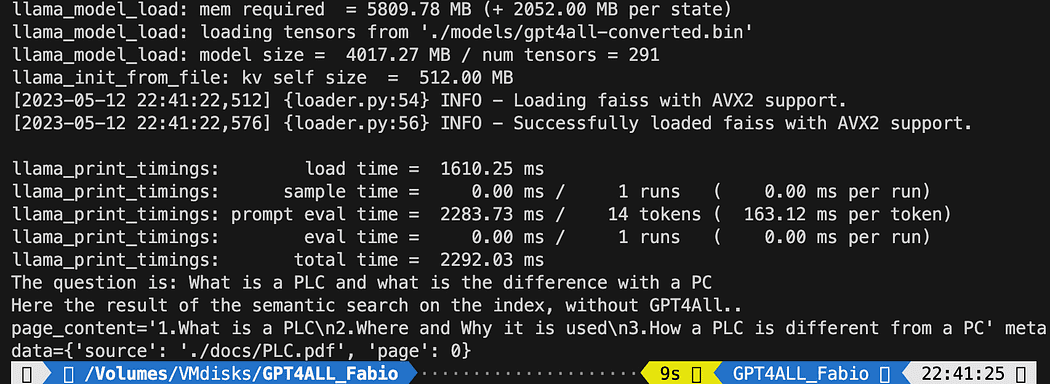
파일을 실행한 시맨틱 검색 결과 db_loading.py
이제 프롬프트 템플릿을 사용하여 쿼리의 컨텍스트로 유사성 검색을 사용할 수 있습니다. 3개의 함수 뒤에 모든 코드를 다음으로 바꿉니다.
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))실행 후 다음과 같은 결과를 얻을 수 있습니다(다를 수 있음). 놀라운 아니오!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.줄을 대체할 사용자 입력 질문을 원하는 경우
question = "What is a PLC and what is the difference with a PC"다음과 같이 :
question = input("Your question: ")실험할 시간입니다. 문서와 관련된 모든 주제에 대해 다양한 질문을 하고 결과를 확인하세요. 확실히 프롬프트와 템플릿에는 개선의 여지가 많습니다. 영감을 얻으려면 여기. 하지만 랭체인 문서는 정말 놀랍습니다(따라갈 수 있습니다!!).
기사의 코드를 따르거나 확인할 수 있습니다. 내 github 저장소.
파비오 마트리카르디 교육자, 교사, 엔지니어 및 학습 애호가. 그는 15년 동안 어린 학생들을 가르쳤으며 현재 Key Solution Srl에서 신입 사원을 교육하고 있습니다. 그는 2010년에 산업 자동화 엔지니어로 제 경력을 시작했습니다. XNUMX대 때부터 프로그래밍에 열정적이었던 그는 무언가를 실현하기 위한 소프트웨어 및 휴먼 머신 인터페이스 구축의 아름다움을 발견했습니다. 가르치고 코칭하는 것은 제 일상의 일부일 뿐만 아니라 최신 관리 기술을 갖춘 열정적인 리더가 되는 방법을 공부하고 배우는 것입니다. 전체 엔지니어링 라이프사이클에서 기계 학습 및 인공 지능을 사용하여 더 나은 설계, 예측 시스템 통합을 향한 여정에 저와 함께 하십시오.
실물. 허가를 받아 다시 게시했습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- EVM 금융. 탈중앙화 금융을 위한 통합 인터페이스. 여기에서 액세스하십시오.
- 퀀텀미디어그룹. IR/PR 증폭. 여기에서 액세스하십시오.
- PlatoAiStream. Web3 데이터 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :있다
- :이다
- :아니
- :어디
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15년
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- 능력
- 할 수 있는
- 소개
- 위의
- 달성
- 행동
- 활성화
- 추가
- 또한
- 추가
- 많은
- 에 영향을 미치는
- 후
- AI
- 인공 지능 연구
- All
- 수
- 수
- 이미
- 또한
- am
- 놀라운
- an
- 분석
- 및
- 답변
- 어떤
- API를
- 어플리케이션
- 신청
- 아키텍처
- 있군요
- 배열
- 기사
- 기사
- 인조의
- 인공 지능
- AS
- 관련
- At
- 오디오
- 자동화
- 자동적으로
- 자동화
- 가능
- 피하기
- 기지
- 기반으로
- BE
- 뷰티
- 때문에
- 된
- 전에
- 존재
- 이하
- BEST
- 더 나은
- 사이에
- 그 너머
- 큰
- BIN
- 제본
- 비트
- 타고난
- 간단히
- 가져
- 빌드
- 건물
- 내장
- 버스를
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- 계산하다
- 전화
- 라는
- 통화
- CAN
- 생산 능력
- 캡처
- 채용
- 나르다
- 케이스
- 잡아라
- CD
- 어떤
- 확실히
- 체인
- 쇠사슬
- 선수권 대회
- 채팅 봇
- ChatGPT
- 검사
- 화학
- 수업
- 수업
- 클릭
- 코칭
- 암호
- 코드
- 수집
- 수집
- 컬렉션
- 결합
- 본문
- 일반적으로
- 소통
- 의사 소통
- 호환
- 완전한
- 진행완료
- 완성
- 복잡한
- 복잡한
- 구성 요소들
- 컴퓨터
- 컴퓨터
- 연결하기
- 연결
- 건설 중의
- 소비자
- 이 포함되어 있습니다
- 함유량
- 문맥
- 제어
- 제어 장치
- 컨트롤
- 편리한
- 변환
- 수
- 엄호
- CPU
- 만들
- 만든
- 생성
- 만들기
- 창조
- 창조적 인
- 임계
- 맞춤형
- 매일
- 데이터
- 데이터베이스
- 데이터베이스
- 날짜
- 날짜 시간
- 결정하다
- 태만
- 한정된
- 델타
- 의존
- 의존
- 따라
- 배포
- 기술 된
- 디자인
- 설계
- 원하는
- 개발
- 장치
- 디바이스
- DID
- 차이
- 다른
- 소화 할 수있는
- 디지털
- 직접
- 발견
- 발견
- do
- 문서
- 선적 서류 비치
- 서류
- 하지
- 들린
- 한
- 말라
- DOT
- 다운로드
- 운전
- ...동안
- 마다
- 쉽게
- 용이하게
- 쉽게
- 생태계
- 생태계
- 노력
- 포함
- 임베디드
- 임베딩
- 직원
- 가능
- end
- 기사
- 엔지니어링
- 엔터 버튼
- 매니아
- 전체의
- 환경
- 오류
- 특히
- 등
- 에테르 (ETH)
- 조차
- 모두
- 정확하게
- 예
- 예
- 실행
- 현존하는
- 실험
- 설명
- 설명
- 설명
- 외부
- 페이스메이크업
- 페이스북
- 을 용이하게
- 마주보고
- FAST
- 빠른
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- Find
- 끝
- 먼저,
- 맞게
- 흐름
- 따라
- 다음에
- 수행원
- 다음
- 럭셔리
- 형태
- 체재
- 공식
- 수식 1
- 뼈대
- 에
- 기능
- 기능
- 추가
- 생성
- 생성
- 세대
- 얻을
- GitHub의
- 주기
- 주어진
- 제공
- 기부
- 가는
- 좋은
- GPU
- 학년
- 처리
- 발생
- 하드
- 하드웨어
- 있다
- he
- 무거운
- 도움이
- 여기에서 지금 확인해 보세요.
- 숨겨진
- 높은
- 더 높은
- 진료 시간
- 방법
- How To
- HTML
- HTTP
- HTTPS
- 사람의
- i
- ICS
- if
- 형상
- 바로
- 구현
- import
- 중대한
- 개량
- in
- 포함
- 색인
- 색인
- 개인
- 산업
- 공업 자동화
- 산업
- 정보
- 입력
- 입출력
- 입력
- 설치
- 설치
- 예
- 명령
- 완성
- 인텔리전스
- 예정된
- 상호 작용하는
- 상호 작용
- 인터페이스
- 인터페이스
- 인터넷
- 으로
- 개요
- 외딴
- 격리
- IT
- 항목
- 되풀이
- 그
- 일
- 어울리다
- 여행
- 다만
- 너 겟츠
- 키
- 알아
- 지식
- 언어
- 넓은
- 성
- 후에
- 리더
- 배우기
- 레벨
- 도서관
- 도서관
- 생활
- wifecycwe
- 처럼
- 라인
- LINK
- 링크드인
- 리눅스
- 명부
- 작은
- 하중
- 짐을 싣는 사람
- 로드
- 지방의
- 장소 상에서
- 논리
- 긴
- 이상
- 보기
- 롯
- 맥
- 기계
- 기계 학습
- 기계
- 본관
- 주로
- 유지하다
- 확인
- 관리
- 구축
- 매니저
- 관리자
- 제조
- .
- XNUMX월..
- 의미
- 방법
- 메모리
- 병합
- 합병
- 메타 데이터
- 방법
- 방법
- 신경
- 분
- 모델
- 모델
- 배우기
- 가장
- 여러
- 절대로 필요한 것
- my
- name
- 출신
- 필요
- 네트워크
- 신제품
- 다음 것
- 지금
- 번호
- 숫자
- 대상
- of
- 제공
- on
- 일단
- ONE
- 온라인
- 만
- 오픈 소스
- 조작
- 행정부
- or
- 주문
- 조직
- OS
- 기타
- 우리의
- 아웃
- 출력
- 위에
- 자신의
- 꾸러미
- 패키지
- 페이지
- 평행
- 부품
- 특별한
- 특별히
- 패스
- 열렬한
- 통로
- PC
- 사람들
- 수행
- 허가
- 확인
- .
- 조각
- 조종사
- 식물
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- PLC
- 부디
- 플러그
- 포트
- 위치
- 게시하다
- 가능성
- 힘
- 발전소
- powered
- 강한
- 사전
- 예방
- 인쇄
- 인쇄
- 문제
- 방법
- 처리
- 프로세스
- 프로그램
- 프로그램
- 프로그램 작성
- 진행
- 프로젝트
- 프로젝트
- 프로토콜
- 제공
- 목적
- 놓다
- Python
- 품질
- 문제
- 문의
- 빨리
- 차라리
- 읽기
- 준비
- 정말
- 전수
- 최근에
- 참조
- 의미
- 관계없이
- 레지스터들
- 관련
- 신뢰성
- 의지하다
- 기억
- 제거
- 반복
- 교체
- 신고
- 저장소
- 대표
- 필수
- 요구조건 니즈
- 필요
- 연구
- 제품 자료
- 응답
- 응답
- 결과
- 결과
- return
- 방
- 달리기
- 달리는
- s
- 안전
- 같은
- 찜하기
- 절약
- 대본
- 검색
- 수색
- 둘째
- 섹션
- 안전해야합니다.
- 참조
- 센서
- 문장
- 순서
- 일련의
- 설정
- 설치
- 몇몇의
- 샷
- 영상을
- 표시
- 비슷한
- 단순, 간단, 편리
- 간단히
- 이후
- 단일
- 기술
- 작은
- So
- 소프트웨어
- 해결책
- 일부
- 무언가
- 출처
- 지우면 좋을거같음 . SM
- 전문
- 특별히
- 구체적인
- 지정
- 분열
- Spot
- 스타트
- 시작
- 시작 중
- 성명서
- Status
- 단계
- 단계
- 아직도
- 저장
- 끈
- 구조
- 학생들
- 공부
- 이러한
- 체계
- 받아
- 이야기
- 작업
- 선생
- 교육
- 십대
- 이 템플릿
- 단말기
- test
- 시운전
- 지원
- 텍스트 생성
- 보다
- 그
- XNUMXD덴탈의
- 그들의
- 그들
- 그때
- 그곳에.
- Bowman의
- 그들
- 생각
- 이
- 생각
- 을 통하여
- 도처에
- 시간
- 에
- 함께
- 토큰
- 내일
- 너무
- 했다
- 화제
- 이상의 주제
- 방향
- Train
- 시도
- 두
- 유형
- 전형적인
- 일반적으로
- 업데이트
- 업데이트
- ...에
- us
- 용법
- USB
- 사용
- 유스 케이스
- 익숙한
- 사용자
- 사용자
- 사용
- 보통
- 사용
- 여러
- 확인
- 버전
- 대단히
- 를 통해
- 온라인
- W3
- 기다리다
- 필요
- 였다
- 방법..
- 방법
- we
- 웹 사이트
- 잘
- 뭐
- 바퀴
- 언제
- 어느
- 누구
- why
- 크게
- 의지
- 창
- Windows 사용자
- 과
- 이내
- 없이
- 원
- 작업
- 일하는
- year
- 년
- 당신
- 젊은
- 너의
- 제퍼 넷










